一、前言
在前面的"图像卷积"和"卷积层"中,我们已经知道了卷积最基本的计算过程:
-
卷积核在输入上滑动
-
每次看一个局部区域
-
做逐元素相乘再求和
-
最终得到输出特征图
同时我们也发现了一个很明显的现象:
卷积之后,输出尺寸通常会变小。
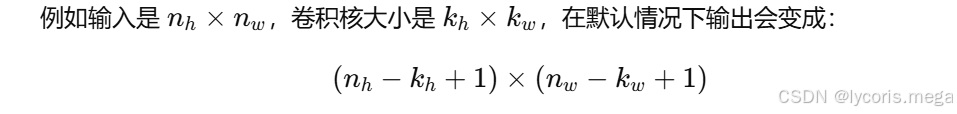
这意味着:
-
如果卷积核比较大,输出会缩得很快
-
如果堆很多层卷积,特征图可能很快就变得很小
-
边缘位置的信息也更容易被不断"吃掉"
这时候就会自然出现两个问题:
1. 能不能让卷积后输出别缩得那么快?
这就需要 填充(padding)。
2. 能不能让卷积核每次走得更快一点?
这就需要 步幅(stride)。
所以这一节"填充和步幅"的核心就是:
控制卷积输出尺寸,以及控制卷积核在输入上的移动方式。
这一节非常重要,因为后面几乎所有 CNN 结构都离不开它。
二、为什么卷积后尺寸会不断变小
我们先回顾最基础的情况。

这说明:
如果没有额外处理,卷积会非常快地压缩空间尺寸。
这在某些情况下是有用的,但很多时候我们并不希望缩得这么快。
三、什么是填充(Padding)
所谓填充,就是在输入图像的边缘补上一圈额外的值,通常补 0。

所以你可以把填充理解成:
在卷积之前,先给输入边界"加外框"。
这样做之后,卷积核在边缘就有更多可滑动的位置,输出尺寸就不会缩得那么快。
四、为什么需要填充
填充最主要有两个作用。
1. 控制输出尺寸
这是最直接的作用。
如果不填充,卷积一次就会让尺寸变小;
如果适当填充,就可以:
-
保持输出尺寸不变
-
或者让尺寸减小得更慢
这在深层网络里非常重要。
2. 更公平地利用边缘信息
如果不填充,图像边缘像素参与卷积的次数会比中间像素少很多。
例如中间区域可以被卷积核覆盖很多次,
但边缘和角落位置因为靠近边界,能参与计算的机会少。
这意味着:
不填充时,模型天然更"重视中间、忽视边缘"。
而加了填充之后,边缘区域也能更多次参与卷积计算,信息利用更均衡。
五、最常见的填充值为什么是 0
在 CNN 中,最常见的是 零填充(zero padding),也就是在边界补 0。
为什么常用 0?
1. 简单直接
实现最方便,也最容易统一处理。
2. 不引入额外强信息
补 0 相当于"这里没有额外内容",不会人为制造太强的边界模式。
3. 在实践中效果通常足够好
所以大家用得最多。
当然,理论上也可以补:
-
常数
-
边缘复制值
-
镜像值
但在深度学习基础阶段,你先把 零填充 理解透就足够了。
六、一个最直观的例子:为什么 padding 能保尺寸

这就是最经典的"保持尺寸不变"的 padding 设置。
七、一般的输出尺寸公式(带 padding)

八、什么时候能让输出尺寸不变
这是特别重要的一点,也是最常考、最常用的结论。

例如:
1. 3×3 卷积核
每边填充 1
2. 5×5 卷积核
每边填充 2
3. 7×7 卷积核
每边填充 3
这就是为什么在 CNN 中:
-
3×3 卷积常配 padding=1
-
5×5 卷积常配 padding=2
因为这样最方便保持尺寸。
九、为什么卷积核通常喜欢用奇数尺寸
你会发现在实际 CNN 中,卷积核经常是:
-
3×3
-
5×5
-
7×7
而不是 2×2、4×4。
原因之一就是:
奇数尺寸更容易设置对称中心。
例如 3×3 核有一个很清晰的中心点,padding 后也容易保持输入输出对齐。
如果是 2×2 核,就没有一个特别明确的中心,设计起来不如奇数卷积核自然。
所以在实践中,奇数卷积核更常见。
十、什么是步幅(Stride)
如果说 padding 解决的是"边界和尺寸缩小太快"的问题,
那么 stride 解决的则是:
卷积核每次移动多远。
前面默认情况下,我们都认为卷积核是一次移动 1 格。
这其实就是:
stride = 1
如果设置:
stride = 2
就表示卷积核每次不再走 1 格,而是跨 2 格再计算下一次。
所以 stride 可以理解成:
卷积核滑动时的步子大小。
十一、为什么需要 stride
步幅最主要的作用是:
1. 控制输出尺寸缩小速度
步幅越大,输出尺寸越小得快。
2. 降低计算量
因为卷积核停留的位置变少了,计算次数也就少了。
3. 实现下采样
stride > 1 时,卷积层本身就带有"压缩空间分辨率"的效果。
所以 stride 本质上是在做一种:
带参数的下采样。
这和后面的池化层有些相似,但它是通过卷积来完成的。
十二、一个直观例子理解 stride
假设输入是:
5 \\times 5
卷积核是:
3 \\times 3
情况一:stride = 1
卷积核可以滑动的位置是:
-
横向 3 个
-
纵向 3 个
所以输出是:
3 \\times 3
情况二:stride = 2
卷积核每次跨 2 格移动,位置就少了很多。
输出大小会变成:
2 \\times 2
这说明:
步幅变大后,输出尺寸缩小得更快。
十三、一般的输出尺寸公式(带 stride)
如果输入大小为:

十四、为什么公式里会有"向下取整"
因为卷积核滑动时,必须完整落入输入范围内。
如果最后剩下一点点位置不够卷积核完整放下,那就不能算一个新的输出位置。
所以公式里要向下取整。
这也意味着:
有时候步幅和尺寸不整除时,最后一部分输入可能不会被完全利用。
十五、padding 和 stride 经常一起考虑
在实际 CNN 设计中,padding 和 stride 几乎总是一起出现的,因为它们共同决定:
-
输出尺寸
-
特征图缩小速度
-
信息保留程度
-
计算量大小
你可以这样理解:
padding
决定边界怎么处理、是否保尺寸
stride
决定卷积核走得快不快、输出缩得快不快
所以卷积层的空间行为,本质上就是由这两个量一起控制的。
十六、PyTorch 中怎么设置 padding 和 stride
在 PyTorch 中,二维卷积层这样写:
from torch import nn
conv2d = nn.Conv2d(
in_channels=1,
out_channels=1,
kernel_size=3,
padding=1,
stride=1
)这里:
-
kernel_size=3:3×3 卷积核 -
padding=1:四周各补 1 圈 0 -
stride=1:每次移动 1 格
如果想让卷积下采样更快,可以写:
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)这就表示:
-
保留边界信息
-
但每次跨 2 格移动
-
输出尺寸会缩小
十七、一个适合 的代码示例
基础代码:
import torch
from torch import nn
# 输入形状:(batch_size, channels, height, width)
X = torch.rand(1, 1, 8, 8)
# 1. 3x3卷积,padding=1,stride=1
conv1 = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=1)
Y1 = conv1(X)
print("Y1 shape:", Y1.shape) # 仍然是 8x8
# 2. 3x3卷积,padding=1,stride=2
conv2 = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
Y2 = conv2(X)
print("Y2 shape:", Y2.shape) # 会缩小
# 3. 5x5卷积,padding=2,stride=1
conv3 = nn.Conv2d(1, 1, kernel_size=5, padding=2, stride=1)
Y3 = conv3(X)
print("Y3 shape:", Y3.shape) # 仍然是 8x8通过这段代码你可以很清楚看到:
-
padding控制是否保尺寸 -
stride控制输出缩小速度
十八、为什么说 padding=1 对 3×3 卷积特别常见

十九、stride=2 为什么经常用来下采样
因为 stride=2 很自然地让输出空间尺寸大约减半。
例如输入 8×8,3×3 卷积,padding=1,stride=2,输出会变成大约 4×4。
这样做的好处是:
-
特征图更小
-
计算量下降
-
感受野增长更快
所以在现代 CNN 中,stride=2 常常被用来替代部分池化操作或者作为下采样手段。
二十、padding 和 stride 的直观类比
如果你想更形象一点理解,可以这样类比:
padding 像什么?
像给图像四周加了一圈"缓冲边框"。
stride 像什么?
像卷积核走路时迈多大的步子。
于是:
-
padding 决定边上有没有空间让你多站几次
-
stride 决定你下一步跨多远
这个类比其实挺直观的。
二十一、这一节最容易混淆的几个点
1. padding 不是缩小尺寸,而是帮助控制尺寸
它通常让输出不要缩得太快,甚至可以保持不变。
2. stride 不是卷积核大小
stride 是卷积核每次滑动的距离。
3. 卷积核大小和 stride 是两个完全不同的概念
-
kernel_size:窗口多大
-
stride:窗口走多远
4. padding=1 不是永远保尺寸
只有在卷积核大小合适时,比如 3×3,padding=1 才正好保尺寸。
5. stride 大了输出会更小
因为卷积核停留的位置更少了。
二十二、这一节的核心思想
如果让我用一句话总结"填充和步幅"这一节,我会写成:
padding 用来控制边界和输出尺寸,stride 用来控制卷积核移动速度和下采样强度。
这句话你可以直接记住。
因为它把这一节最关键的两个角色分工说得非常清楚:
-
padding:补边界,保信息,控尺寸
-
stride:跨步走,降分辨率,减计算
二十三、我对这一节的理解
学这一节之前,我对 padding 和 stride 的感觉比较像"卷积里的附加参数",好像只是 API 里顺手一填的东西。
但真正理解之后我才发现:
它们不是边角料,而是卷积层空间行为的核心控制器。
同样一个卷积核,如果:
-
padding 不同
-
stride 不同
那么输出尺寸、信息保留方式、特征图变化速度都会完全不一样。
也就是说,卷积层不是只有"卷积核内容"重要,
卷积核怎么走、边界怎么补,同样非常关键。
二十四、结语
"填充和步幅"是学习卷积神经网络时非常重要的一节。
因为从这一节开始,我们不再只是会"算卷积",而是开始能真正控制卷积层的输出尺寸和空间行为。
通过这一节,我们应该真正弄清楚:
-
为什么卷积会让输出变小
-
padding 为什么能保尺寸
-
stride 为什么能实现下采样
-
输出尺寸公式应该怎么理解
-
为什么 3×3 卷积经常配 padding=1
把这些基础打牢,后面再学习多输入输出通道、池化层、LeNet,就会轻松很多。
二十五、重点速记版
1. 什么是 padding
在输入边缘补值,通常补 0。
2. padding 的主要作用是什么
控制输出尺寸、保护边缘信息。
3. 什么是 stride
卷积核每次滑动的步长。
4. stride 的主要作用是什么
控制输出尺寸缩小速度和下采样强度。
5. 3×3 卷积想保尺寸,padding 应该设多少
padding = 1
6. 为什么 stride=2 常用于下采样
因为它会让输出空间尺寸大约减半。

以上就是我对《动手学深度学习》中 填充和步幅 这一节的学习整理。
这一节虽然不像"卷积层"那样听起来很核心,但实际上它对卷积网络的结构设计影响非常大。因为卷积核不只是"算什么"重要,"怎么走"和"边界怎么处理"同样非常重要。
我觉得这一节最值得记住的一点就是:padding 和 stride 不是附属参数,而是卷积层空间尺寸控制的关键。把这一点想清楚,后面学池化层、多通道卷积和经典 CNN 结构时,会顺很多。