Claude Code 智能体架构与 Skill 使用方式
一、背景澄清
Claude Code 的源代码并非正式开源,而是 2026 年 3 月因 npm 发布包中误打包了 source map 文件而意外泄露。代码"可见"不等于"可用"------复制或使用其代码违反许可证。
但 Skill 体系本身是官方公开的开放标准,可合法使用。
二、核心概念:Agent = Model + Harness
Harness 是模型之外的一切基础设施。模型是马,Harness 是缰绳、马鞍和马具------不让马变得更强,而是把马的能量引导到正确方向。
Claude Code 的完整架构:
Agent 循环 + 工具 + 按需 Skill 加载 + 上下文压缩 + 子 Agent 生成 + 任务系统 + 团队协调 + 并行执行 + 权限治理
每个组件都是 Harness 机制,没有一个是"智能"本身。智能在模型里,Harness 让智能变得可用。
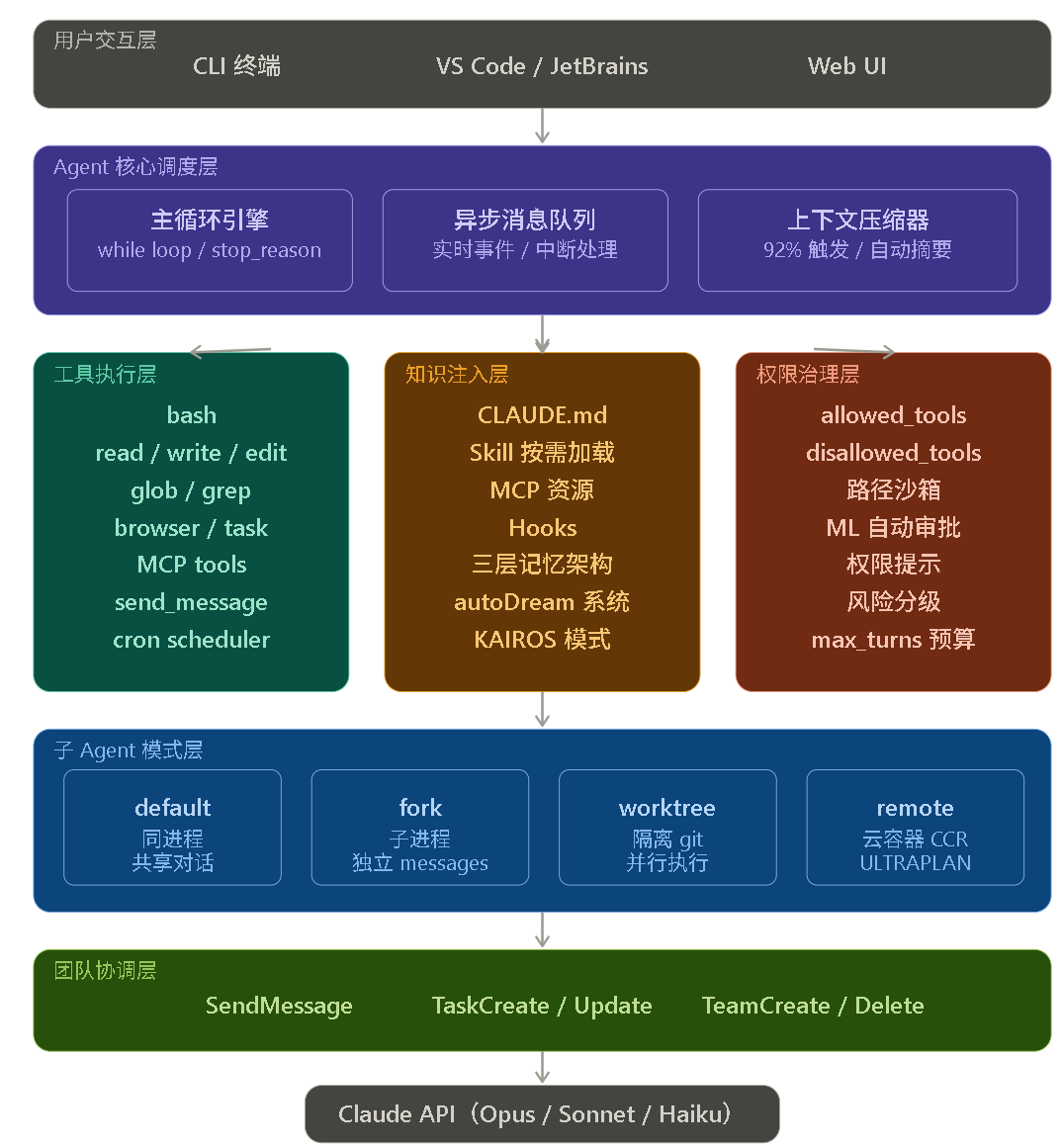
Claude Code 完整架构图
架构分为六层,自上而下依次是:用户交互层(CLI / IDE / Web)→ Agent 核心调度层(主循环 + 消息队列 + 压缩器)→ 三个并行支柱(工具执行层 / 知识注入层 / 权限治理层)→ 子 Agent 模式层(default / fork / worktree / remote)→ 团队协调层(消息传递 / 任务板)→ 底层 Claude API。
每一层都是 Harness 的一部分,没有任何一层自身包含"智能"。
三、核心算法:30 行代码的 Agent 循环
python
while True:
response = client.messages.create(
model="claude-opus-4-6",
messages=messages,
tools=TOOLS,
max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return # 模型决定停止 → 任务完成
results = []
for block in response.content:
if block.type == "tool_use":
output = run_tool(block.name, block.input)
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
messages.append({"role": "user", "content": results})这就是全部核心。messages 列表是唯一的状态源,模型在每轮看到完整历史后自主决策下一步。决策在模型里发生,Harness 只负责执行和传递。
四、工作流 vs Skill-Based Agent:本质区别
| 维度 | 传统工作流 | Skill-Based Agent |
|---|---|---|
| 决策者 | 开发者(提前硬编码) | 模型(运行时推理) |
| 结构 | 有向图/状态机 | while 循环 |
| 处理意外 | 只能处理预见到的情况 | 实时自适应 |
| 灵活性 | 低,改流程改代码 | 高,改提示词即可 |
| 可调试性 | 高 | 中 |
导航比喻:工作流是给一张详细路线图(先经过 A,再到 B,再到 C);Skill Agent 是给规则和工具(遇到泥路用越野模式,不许撞人,目的地是颐和园,出发)。
关键差异:工作流里,思考已经提前完成了(开发者完成),固化在代码中;Agent 里,思考是实时进行的(模型完成)。
五、Skill 是什么
Skill 是一个 Markdown 文件,写的是自然语言指令,不是代码接口。你把重复性的工作流程或规则写成说明书,Claude 在需要时自动加载并遵守。
文件位置:
~/.claude/skills/skill名/SKILL.md # 全局,所有项目可用
项目目录/.claude/skills/skill名/SKILL.md # 仅当前项目文件结构:
markdown
---
name: skill名 # 触发命令名(/skill名)
description: 触发说明 # Claude 据此判断何时加载
user-invocable: true/false # 是否允许用户手动调用
disable-model-invocation: true # 是否禁止 Claude 自动触发
---
# 以下是正文:Claude 加载后实际执行的指令
...加载机制 :启动时每个 Skill 只消耗约 100 tokens 做相关性判断,被选中后再加载完整内容(< 5k tokens),附属资源按需加载。渐进式披露,不浪费上下文。
Skill 加载时序图
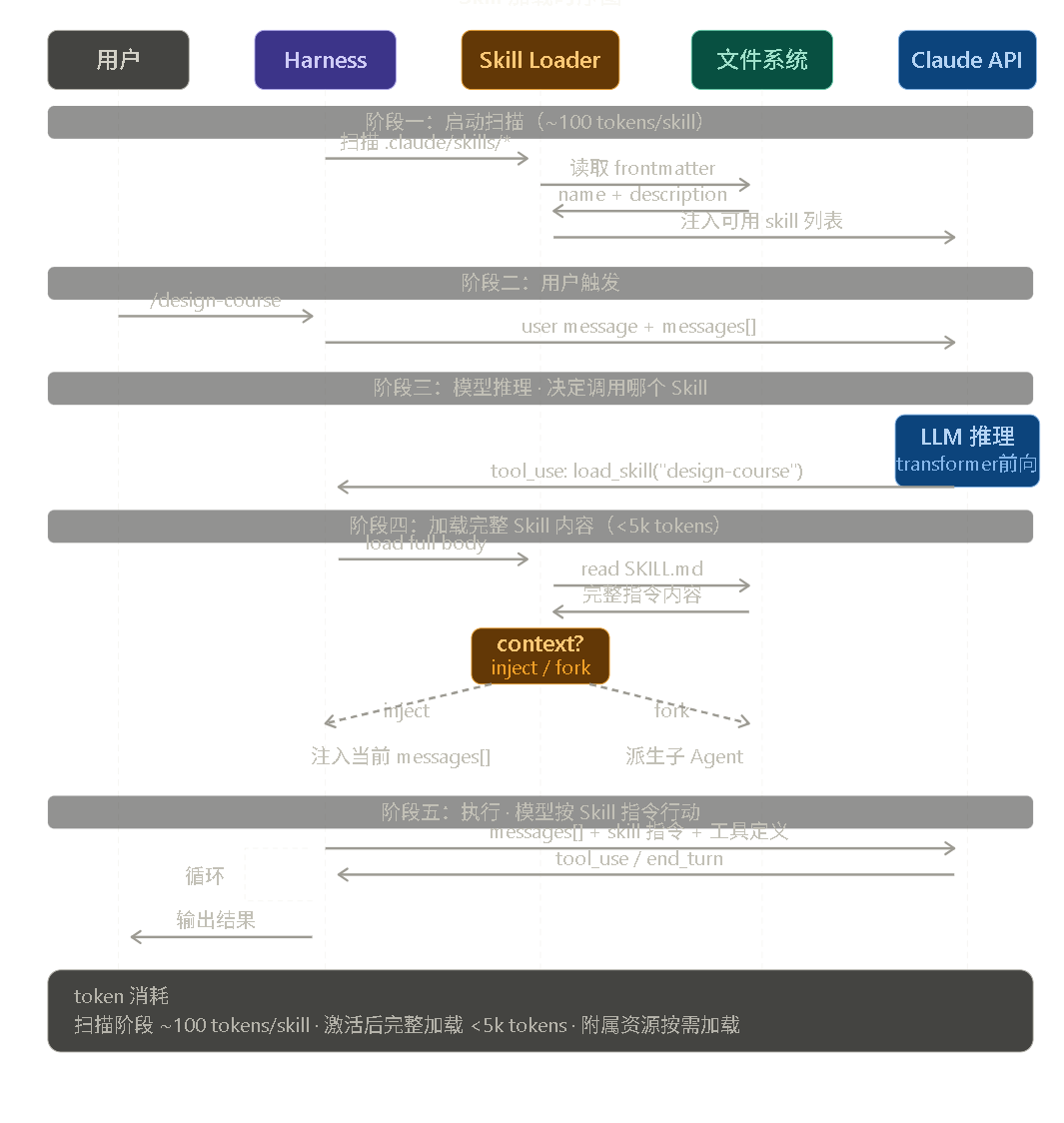
完整流程分五个阶段:
- 启动扫描 :Harness 让 Skill Loader 扫描所有
SKILL.md的 frontmatter,把 name + description 注入模型上下文(每个约 100 tokens)。 - 用户触发 :用户输入
/skill名或自然语言,Harness 将消息连同上下文发给模型。 - 模型推理 :模型通过 transformer 前向传播决定调用哪个 Skill,发出
tool_use: load_skill(...)请求------没有任何算法路由,纯 LLM 推理。 - 加载完整内容 :Skill Loader 读取对应
SKILL.md正文,根据context字段决定 inject(注入当前 messages)还是 fork(派生子 Agent)。 - 执行 :模型在丰富上下文中按 Skill 指令行动,通过工具调用与 Harness 循环交互,直到
end_turn。
六、Skill 的两种类型
流程型 Skill:定义"先做什么、再做什么"
markdown
---
name: design-course
description: 执行课程设计方案的完整流程。当用户说"设计课程"时使用。
---
## 阶段一:信息收集
1. 读取 data/curriculum/ 下的培养方案
2. 读取 data/job-competency/ 下的岗位能力数据
3. 如果缺少数据文件,列出清单等用户补充
⏸️ 等待用户确认基本信息
## 阶段二:KSA 拆分
...规则型 Skill:定义"无论做什么都必须遵守什么"
markdown
---
name: ksa-rules
description: KSA能力拆分规则。进行能力分析、任务拆解时自动应用。
user-invocable: false
---
## 知识(K)的描述规则
- 用名词短语,不用动词开头
- 粒度:一个 K 节点 = 一次课(2学时)能讲完的内容
- 格式:K-编号 | 知识名称 | 所属领域 | 认知层次
正确:K-01 | 线性回归的损失函数原理 | 监督学习 | 理解
错误:✗ "学习线性回归"(太模糊)✗ "机器学习"(粒度太大)
## 技能(S)的描述规则
- 用布鲁姆动词开头:实现、使用、对比、调试、设计...
- 粒度:一个 S 节点 = 一个可独立布置的实验/作业
...核心区别:流程型是导航地图,规则型是交通法规。开车时你按地图走,同时必须遵守交规。两者分离的好处:可以单独调整规则而不影响流程,也可以换流程但复用同一套规则。
七、课程设计案例:完整 Skill 架构
以"设计课程方案(含岗位能力图谱 + 资源挂接)"为例:
.claude/skills/
├── course-design/ # 🔵 流程型:主流程(唯一一个)
├── ksa-rules/ # 🔴 规则型:KSA拆分标准
├── curriculum-rules/ # 🔴 规则型:课程体系对接规则
├── resource-mapping-rules/ # 🔴 规则型:资源挂接规则
├── output-format/ # 🔴 规则型:输出文档规范
└── quality-gate/ # 🔴 规则型:质量红线运行时协同方式:
你输入:/design-course 机器学习
Claude 加载 course-design(流程型)→ 开始阶段一
│
├── 读取数据时 → curriculum-rules 自动生效
│ (先修关系处理、学时约束、课程边界判定)
│
├── 拆分 KSA 时 → ksa-rules 自动生效
│ (K用名词短语、S用布鲁姆动词、A必须可培养)
│
├── 挂接资源时 → resource-mapping-rules 自动生效
│ (每个K至少1个video+1个quiz、禁止超5个同类型)
│
├── 生成文档时 → output-format 自动生效
│ (9个章节、表格列固定、文件命名规范)
│
└── 全程 → quality-gate 自动生效
(数据不可编造、4个必须暂停的人机协作检查点)Agent 自主规划执行顺序(信息收集 → KSA拆分 → 筛选子集 → 挂接资源 → 生成方案),没有任何代码硬编码这个顺序,完全由模型在循环中实时推理决定。
八、Tool 的接口设计:JSON Schema
与 Skill 不同,Tool 是 Claude 可调用的函数接口,通过 JSON Schema 定义:
python
{
"name": "query_curriculum_system",
"description": (
"查询已有课程体系,返回培养方案、课程列表、先修关系等。"
"适用场景:需要了解已有课程体系时调用。" # 告诉模型何时用
),
"input_schema": {
"type": "object",
"properties": {
"major": {"type": "string", "description": "专业名称,如'人工智能'"},
"level": {"type": "string", "enum": ["本科", "专科", "研究生"]},
"keyword": {"type": "string", "description": "可选的关键词过滤"}
},
"required": ["major"] # 必填字段
}
}description 字段是给模型读的决策线索,properties 是参数说明,required 是必填约束。工具之间的数据流动(如上游输出的 graph_id 传入下游)由模型在对话历史中自行"看到并传递",不需要代码硬连接。
九、混合架构:自主度的旋钮
Agent 不是非此即彼,而是一个频谱:
高速公路 → 跟导航走 # 确定性工作流(Tool直接调用)
城市道路 → 按交规自主开 # 规则约束下的 Agent(Skill + ReAct)
越野地带 → 看着方向自己走 # 完全自主探索(开放式 Agent)控制旋钮:
disable-model-invocation: true:只有用户能触发此 Skill(适合有副作用的流程)user-invocable: false:只有 Claude 能触发(适合背景知识型规则)allowed_tools/disallowed_tools:精细控制可用工具集max_turns:限制循环轮次防失控
已有工作流可以直接包装为 Tool,Agent 在 ReAct 循环中自主决定何时调用它、传什么参数、对结果满不满意要不要重试。这就是新旧范式的融合点。
十、写好 Skill 的核心原则
description 写触发场景,不写功能名:
yaml
# ❌ 模糊
description: 帮助设计课程
# ✅ 清晰
description: 辅助设计教学大纲。当用户提到"设计课程"、"教学大纲"、"课程规划"时使用。正文写步骤和规则,不写解释: 把"做什么"和"需要知道什么"分离,步骤在 SKILL.md,大量参考数据放 references/ 子文件夹。
人机协作用显式暂停点: 在正文中写 ⏸️ 等待用户确认后才能继续,这是控制协作节奏的方式------不靠代码控制流程,靠自然语言告诉 Claude 什么时候等人。
规则型 Skill 的最大价值:写一次,全程自动生效。 不需要每次对话重复提醒"记得用类型标注"、"别用字符串拼接SQL"------这些固化在 Skill 里,Claude 自动遵守。
总结
| 概念 | 核心一句话 |
|---|---|
| Harness | 模型之外的一切基础设施,让智能变得可用 |
| Agent 循环 | 一个 while 循环 + 工具执行 + 结果回传,30行核心 |
| Skill | 写给 Claude 的 Markdown 说明书,按需自动加载 |
| 流程型 Skill | 定义顺序,是导航地图 |
| 规则型 Skill | 定义约束,是交通法规 |
| 混合架构 | 工作流包装为 Tool,Agent 在循环中自主决定何时调用 |
最核心的洞察:最好的 Agent 产品,是由那些理解"自己的工作是做 Harness 而非 Intelligence"的工程师构建的。模型负责"想",Harness 负责"做"------这种分离,让同一套代码可以应对完全不同的任务,区别只在 Skill 定义和系统提示词。