Collection
- 集合概述
-
- 1.什么是集合
- 2.集合存储的是什么
- 3.在java中每一个不同的集合,底层会对应不同的数据类型,往不同的集合中存储元素,就是将数据放到了不同的数据结构中
- [4.集合在java JDK的哪个包下](#4.集合在java JDK的哪个包下)
- 5.集合的继承结构
- 6.在java中集合分为两大类:
- 7.Collection接口常用方法
- 8.List接口特有的方法
集合概述
1.什么是集合
数组就是一个集合,集合实际上就是一个容器,能容纳其他类型的数据
2.集合存储的是什么
集合不能直接存储基本数据类型和java对象,集合中存储的是java对象的内存地址(引用)
java
list.add(100);//自动装箱Integer注意:
集合在java中本身是一个容器,一个对象
集合在任何时候存储的都是"引用"
3.在java中每一个不同的集合,底层会对应不同的数据类型,往不同的集合中存储元素,就是将数据放到了不同的数据结构中
java
new ArrayList();//底层是一个数组
new LinkedList();//底层是一个链表
new TreeSet();//底层是一个二叉树4.集合在java JDK的哪个包下
java.util.*
所有集合类和集合接口都在这个包下
5.集合的继承结构
5.1关于Collection集合的继承结构
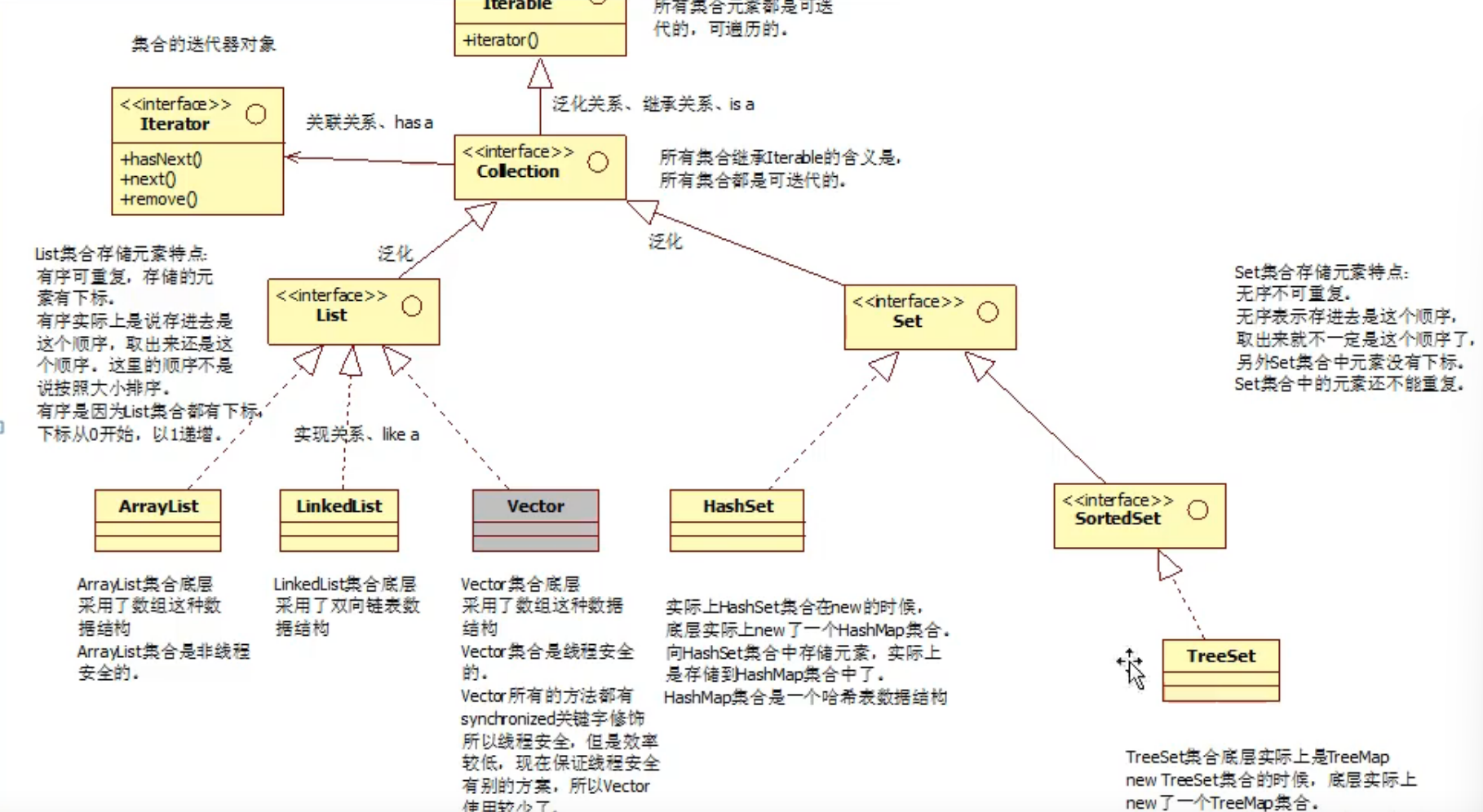
接口Iterator:集合的迭代器对象
iterator()是接口Collection父接口Iterable的方法,Collection可以拿来用,返回迭代器对象Iterator
Iterator it = "Collection对象".iterator();
Iterator有三个方法
hasNext()
next()
remove()
接口List和Set继承Collection
List集合存储元素的特点:
有序(存进去是什么顺序取出来就是什么顺序)可重复,元素有下标
Set集合存储元素的特点:
无序不可重复,无下标
List的常用实现类
ArrayList
LinkedList
Vector:底层采用数组,是线程安全的,其下的所有方法都带有关键字synchronized修饰(表示线程安全),但效率低,因为保证线程安全有别的方案,所以使用较少
Set的常用实现类
HashSet:底层实际是HashMap集合,采用哈希表数据结构
TreeSet:底层实际是TreeMap集合,采用二叉树数据结构
接口SortedSet继承Set,其下有实现类TreeSet
SortedSet中的元素不按插入顺序存储,而是按元素的自然顺序或指定比较器的顺序自动排序存储,即无序不可重复但自动排序
5.2关于Map集合的继承结构
Map集合和Collection集合没有关系,Map集合以键值对方式存储元素,存储对象地址,存储key元素无序不可重复
接口Map的常用实现类
HashMap:非线程安全的,底层是哈希表数据结构
Hashtable:线程安全的,其下所有方法带有synchronized,较少用,底层是哈希表数据结构
Properties是Hashtable的子类,是线程安全的,采用键值对方式存储元素,且key和value只支持String类型,被称为属性类
接口SortedMap继承Map,放在该集合下的key无序不可重复,但自动排序(由小到大),其下有实现类TreeMap
TreeMap底层是二叉树
6.在java中集合分为两大类:
一类是单个方式存储元素
单个方式存储元素,这一类集合中父接口:java.util.Collection;
一类是以键值对的方式存储元素
这一类集合中超级接口:java.util.Map;
7.Collection接口常用方法
7.1.Collection的存储类型
没有使用泛型前,Collection中可以存储Object的所有子类型,使用泛型后只能存储某个具体类型
7.2.Collection中的常用方法
boolean add(Object e)
int size()
void clear()
boolean contains(Object o)
boolean remove(Object o)
boolean isEmpty()
Object\[\] toArray()
Collection c = new ArrayList();
//添加元素
c.add(100);//自动装箱
c.add(new Object());
//获取集合中元素的个数
System.out.println(c.size());
//清空集合
c.clear();
//判断集合中是否包含某一元素
System.out.println(c.contains(100));
//删除集合中某一元素
c.add(10);
c.remove(10);
//判断集合是否为空
System.out.println(c.isEmpty());
//将集合转换成数组
Object[] objs = c.toArray();7.3.关于集合遍历
以下遍历方式是Collection通用的一种方式,Map不能用
java
Collection c = new HashSet();
c.add(111);
c.add("abc");
//对集合进行遍历/迭代
//1.获取集合对象的迭代器对象
Iterator it = c.iterator();//注意当集合发生变化时,迭代器必须重新获取,否则会出现异常
//2.通过迭代器对象进行遍历
/*
迭代器一开始并不指向第一个元素
迭代器对象Iterator的方法
boolean hasNext()如果还有元素可以迭代返回true
Object next()返回迭代的下一个元素
*/
while(it.hasNext()){
Object obj = it.next();//next方法的返回值类型必须是Object
System.out.println(obj);//存进去是什么类型取出来就是什么类型
}7.4.深入contains方法
java
String s1 = new String("abc");
c.add(s1);
String s2 = new String("abc");
boolean bl = c.contains(s2);//true因为contains调用了equals,而String类的equals被重写,比较的是内容而不是内存地址
注意:
如果你测试的类没有重写equals方法,那contains的equals方法比较的就是内存地址,那返回的结果就会是false
java
class Student{
private String name;
public Student()
{}
public Student(String name){
this.name = name;
}
}
Student stu1 = new Student("zhangsan");
c.add(stu1);
Student stu2 = new Student("zhangsan");
System.out.println(c.contains(stu2));//这样就会返回false
//如果你对student类进行equals方法的重写,用equals比较两个name来判断两个类是否为同一个的话,就可以返回true7.5.深入remove方法
remove和contains一样,都调用了equals方法,所以用法及注意事项可以参考contains
java
String s1 = new String("abc");
c.add(s1);
String s2 = new String("abc");
boolean bl = c.remove(s2);//true,这样s1就被删掉了
System.out.println(c.isEmpty());//true注意就是需要迭代时,要注意迭代器的时效性,集合发生变化要对迭代器进行更新
java
Collection c = new HashSet();
c.add(111);
c.add("abc");
Iterator it = c.iterator();//注意当集合发生变化时,迭代器必须重新获取,否则会出现异常
/*
迭代器一开始并不指向第一个元素
迭代器对象Iterator的方法
boolean hasNext()如果还有元素可以迭代返回true
Object next()返回迭代的下一个元素
*/
while(it.hasNext()){
Object obj = it.next();//next方法的返回值类型必须是Object
/*如果我们要删除元素。这样做的话
c.remove(obj);//集合发生了变化,会出现异常
//或者你也可以每次删完都更新一次迭代器
it = c.iterator();//这样也能实现功能,但是每次都更新迭代器会影响效率,所以建议直接用下面的方法
*/
//而Iterator本身就有一个remove方法用来删除迭代器当前指向的元素,用这个方法就不会出现异常了
it.remove(obj);
System.out.println(obj);//存进去是什么类型取出来就是什么类型
}
System.out.println(c.size());8.List接口特有的方法
List集合存储元素的特点:有序可重复
void add(int index,E element)//在集合指定位置插入元素
E get(int index)//获取指定位置的元素
int indexOf(Object o)//获取指定对象第一次出现的下标
int lastIndexOf(Object o)//获取指定对象最后一次出现的下标
E remove(int index)//删除指定下标位置的元素
E set(int index,E element)//修改指定位置的元素
没用泛型的话就将E当成Object就行
java
List myList = new ArrayList();
//void add(int index,E element)
myList.add(200)
myList.add(300)
myList.add(300)
myList.add(0,100)//这样插入的结果就是100,200,300,300
//E get(int index)同时可以用这个方法进行集合元素的迭代遍历,List特有,Set没有
myList.get(2);//300
//int indexOf(Object o)
myList.indexOf(300);//2
//int lastIndexOf(Object o)
myList.lastIndexOf(300);//3
//E remove(int index)
myList.remove(3);
//E set(int index,E element)
myList.set(0,1);//100->1ArrayList
ArrayList集合底层是Object\[\]数组
ArrayList集合默认的初始化容量是10(底层先创建长度为0的数组,当添加第一个元素的时候初始化容量为10)
准确描述:
对于JDK 1.8+:
new ArrayList() → 底层创建空数组 {}
第一次调用add()方法时,才会将数组容量初始化为10
这是一种懒加载优化,减少内存占用
对于JDK 1.7及以前:
new ArrayList() → 直接创建长度为10的数组
无论是否添加元素,都占用10个元素的空间
指定初始化容量
java
List l1 = new ArrayList(20);//指定容量为20ArrayList集合的扩容:
当要添加元素时发现容量不足时,集合增长至原容量的1.5倍(会进行边界条件处理,增加的容量只算整数,小数部分舍弃)
二进制位运算
>>1:将二进制数向右移一位,也就是变成原先的0.5倍,而ArrayList扩容就是增加原先容量(二进制)右移一位的容量
数组优点
检索效率高,往末尾添加元素效率很高
数组缺点
随机增删元素效率低
除了无参和整数参的构造方法构造数组外也可以用另一种构造方法,也就是将其他集合转换成List集合
java
Collection c = new HashSet();
c.add(100);
c.add(200);
List l3 = new ArrayList(c);LinkedList链表
LinkedList集合的底层采用双向链表结构
单链表中的节点node
节点是链表的基本单元
每一个节点都有两个属性
1.存储的数据
2.下一个节点的内存地址
链表优点
随机增删元素效率高,因为不会涉及到大量元素的移动
链表缺点
查询效率低,每次查询元素都需要从头遍历
双链表与单链表类似,只不过双向链表的node多了一个属性:上一个节点的内存地址
Vector
底层也是一个数组
初始化容量为10
是线程安全的
怎么扩容
添加元素容量不足时,容量变为原容量的双倍
怎么将一个线程不安全的ArrayList转换成线程安全的呢
使用集合工具类
java.util.Collections
注意区分
java.util.Collection是集合接口
java.util.Collections是集合工具类
java
List l1 = new ArrayList();
//变成线程安全的
Collections.synchronizedList(l1);
//此时l1就是线程安全的了
l1.add(100);
l1.add(200);
//排序
Collections.sort(l1);