Linux 物联网网关主控系统-Linux主控部分(二)
- 一、程序、进程概念
-
- [1.C 源码到进程的完整转化流程](#1.C 源码到进程的完整转化流程)
- [2.C 源码编译后在 ELF 文件中的段划分](#2.C 源码编译后在 ELF 文件中的段划分)
- [3.ELF 文件核心说明](#3.ELF 文件核心说明)
- [4.ELF 到进程:进程的内存布局](#4.ELF 到进程:进程的内存布局)
- 5.程序与进程的核心定义及区别
- 6.总结
- [二、进程操作、5 状态](#二、进程操作、5 状态)
-
- 1.进程的两种启动方式
- 2.进程管理核心常用命令
- [3.进程的 5 种核心运行状态](#3.进程的 5 种核心运行状态)
- 4.进程的两种执行模式
- 5.进程的内核管理结构:task_struct
- 三、Linux进程系统调用
-
- [一、进程创建:fork () & vfork ()](#一、进程创建:fork () & vfork ())
-
- [1. fork () 核心](#1. fork () 核心)
- [2. vfork () 核心](#2. vfork () 核心)
- [二、程序替换:exec 函数族](#二、程序替换:exec 函数族)
- [三、进程退出:exit () & _exit ()](#三、进程退出:exit () & _exit ())
- [四、子进程回收:wait () & waitpid ()](#四、子进程回收:wait () & waitpid ())
一、程序、进程概念
1.C 源码到进程的完整转化流程
C 源程序通过编译、链接、执行三步,从静态文件转化为操作系统中运行的进程,各阶段产物及说明如下:
1.源程序:用户编写的.c后缀文件,是静态的代码文本;
2.目标文件:编译器输出结果,.o/.obj后缀,为 ELF 格式中间文件;
3.可执行文件:链接器将目标文件与 C 语言函数库链接后的产物,.exe后缀(Linux 下无默认后缀,仍为 ELF 格式);
4.进程:操作系统将可执行文件加载到内存(RAM)中执行后,形成的动态执行环境。
辅助文件:头文件(.h),包含函数声明、预处理语句,用于访问外部函数,编译阶段参与处理但不生成可执行代码。
2.C 源码编译后在 ELF 文件中的段划分

3.ELF 文件核心说明
ELF 是 Executable and Linkable Format(可执行与可链接格式)的缩写,是 Linux/Unix 类系统中标准的二进制文件格式,也是文档中核心提及的文件格式,Linux 下的可执行文件、.o 目标文件、共享库、coredump 文件等,均采用 ELF 格式,是连接「静态文件」到「内存中运行的进程」的关键载体。
4.ELF 到进程:进程的内存布局
操作系统将 ELF 文件加载到内存后,形成进程映像,其内存空间划分为三大核心段(用户空间),与 ELF 段对应且新增运行时专属区域,核心布局及存储内容:
1.正文段:对应 ELF 的.text段,存放被执行的机器指令,共享且只读;
2.用户数据段:包含 ELF 的.data、.rodata、.bss段,以及动态分配的内存(如malloc申请的空间),存放全局变量、常数等;
3.堆栈段:分为栈(stack)和堆(heap),栈存放函数返回地址、函数参数、局部变量,为进程私有;堆为动态内存分配区域(malloc/free操作);
4.共享库区域:映射系统共享库(如libc.so),为多个进程共享,减少内存占用。
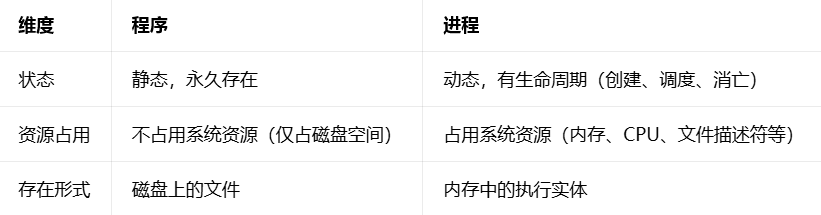
5.程序与进程的核心定义及区别
6.总结
「静态的程序文件」怎么一步步变成「Linux 系统中动态运行的进程」
第一层:先明确「你写的代码」到「跑起来的程序」,会生成哪些关键文件
你在 Linux 下写 C 代码,从敲完.c文件开始,到能执行,会产生4 类核心文件,各有各的作用,只有 2 类是 Linux 专属的 ELF 格式,这是基础:
1.源程序(.c)+ 头文件(.h):你亲手写的纯文本文件,.c是核心代码,.h是辅助的函数声明,俩都是 "文本文档",无格式,只用来给编译器 "读";
2.目标文件(.o):编译器读完.c/.h后,输出的中间文件,已经不是纯文本了,是ELF 格式(Linux 的标准二进制格式);
3.可执行文件:链接器把.o文件和系统的 C 函数库(比如 printf、malloc 这些函数的实现)拼起来的产物,Linux 下无后缀,也是 ELF 格式(Windows 才是.exe),这是能直接在 Linux 里敲命令执行的文件。
第二层:关键的「ELF 格式」是干嘛的?
ELF 是 Linux 的 "通用二进制文件标准",上面说的.o目标文件、可执行文件,都得按这个标准来做。
它的核心作用就一个:让 Linux 的编译器、链接器、操作系统能 "互相看懂" 文件。
-编译器输出.o时按 ELF 来,链接器才知道怎么拼;
-可执行文件按 ELF 来,操作系统才知道怎么把文件加载到内存、怎么执行里面的指令。
同时 ELF 还把文件分成了.text(代码)、.data(已初始化变量)等段,让内存加载时更有条理。
第三层:「可执行文件」怎么变成「进程」?进程和程序到底有啥不一样?
这是这部分的核心重点,也是最容易混的地方:
1.可执行文件 → 进程:你在终端敲./可执行文件,Linux 操作系统会把这个 ELF 格式的可执行文件,加载到电脑的内存(RAM) 中,再给它分配 CPU、文件描述符等系统资源,此时内存中这个动态跑起来的执行环境,就是进程;
2.程序 vs 进程:静态文件 vs 动态运行体
-程序:就是磁盘上的文件(.c、.h、.o、可执行文件都算),是静态的,放在磁盘上不占内存 / CPU,永远存在;
-进程:是动态的,只有可执行文件被加载到内存后才会产生,有 "生老病死"(创建→运行→消亡),运行时会占用内存、CPU 等系统资源,是 Linux 系统实际调度、执行的最小单位。
二、进程操作、5 状态
1.进程的两种启动方式
Linux 中进程启动分为手工启动和调度启动,覆盖手动操作和系统自动执行场景,是实际开发 / 使用中启动进程的核心方式:
- 手工启动
由用户在终端输入命令直接启动,支持前台运行和后台运行两种形式:
- 前台运行:直接输入命令,如ls、./a.out,进程占用当前终端,关闭终端则进程终止;
- 后台运行:命令后加&,如./run &,进程在后台运行,不占用当前终端,可继续在终端执行其他操作。
- 调度启动
系统根据用户事先的设定自动、定时启动进程,无需手动干预,核心工具:
- at:在指定时刻执行一次相关进程(一次性调度);
- crontab:周期性执行相关进程(如每天凌晨 1 点执行脚本,循环调度)。
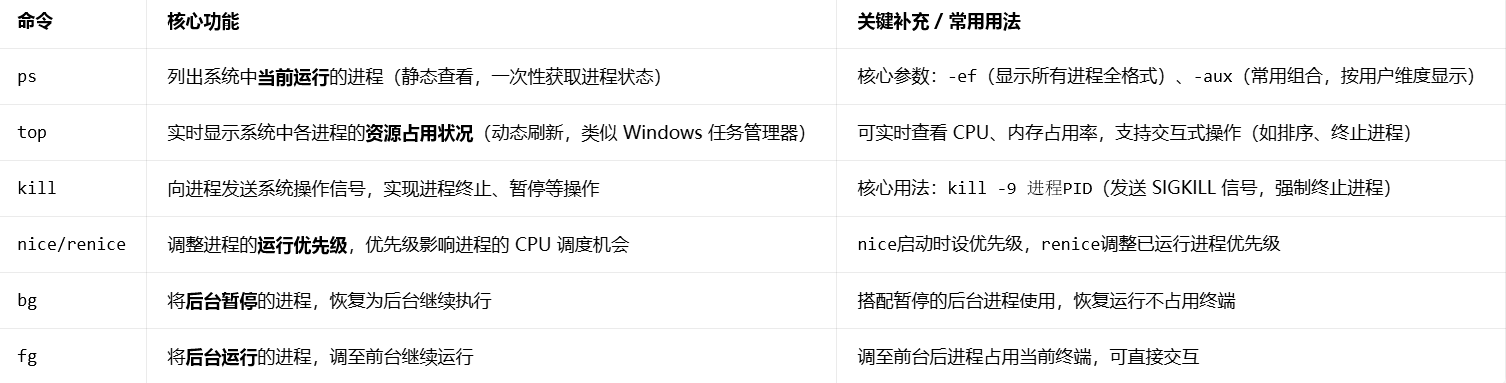
2.进程管理核心常用命令
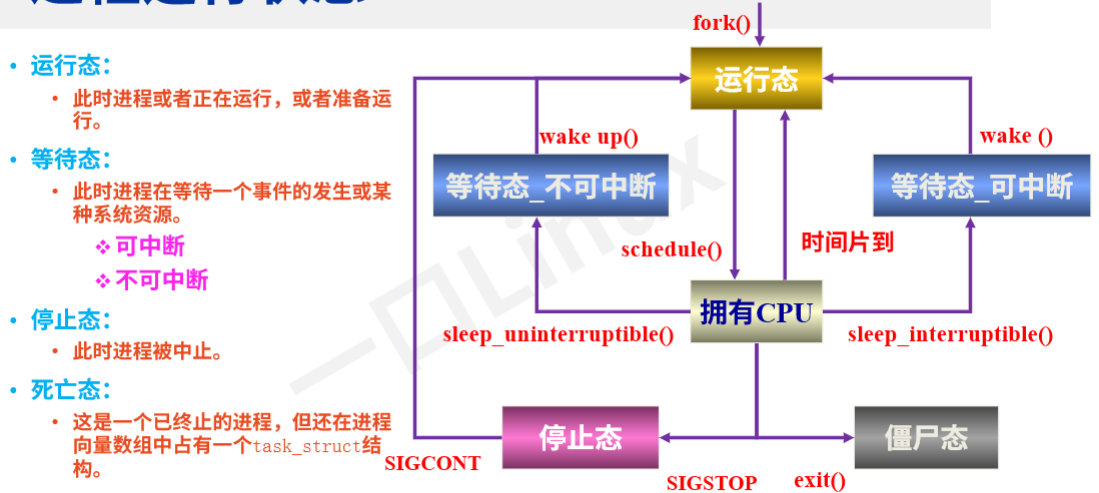
3.进程的 5 种核心运行状态

僵尸态属于死亡态
4.进程的两种执行模式
进程的执行模式分为用户模式(用户态)和内核模式(内核态),本质是 CPU 的权限分级,决定进程能访问的系统资源范围,是 Linux 进程权限管理的核心:
- 用户模式(用户态)
进程运行在用户空间,权限受限;
只能访问用户态的内存和资源,无法直接访问内核空间、硬件资源(如 CPU 指令集、I/O 空间);
普通进程的常规执行(如执行 C 代码、调用普通函数)均在用户态。 - 内核模式(内核态)
进程运行在内核空间,拥有最高权限;
可无限制访问所有 CPU 指令集、全部内存和 I/O 空间,执行内核函数;
进程进入内核态的唯一方式:中断或系统调用(如fork()、read()、write()等系统调用)。 - 模式切换关系
用户态进程 → (中断 / 系统调用)→ 内核态进程(执行内核操作)→ 操作完成 → 回到用户态继续执行。
5.进程的内核管理结构:task_struct

三、Linux进程系统调用
一、进程创建:fork () & vfork ()
1. fork () 核心
c
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);返回值(fork 的核心特点:一次调用,两次返回)
0:子进程中返回
大于 0 的整数:父进程中返回,返回值为子进程的 PID
-1:创建失败,可通过perror("fork")查看错误原因
子进程与父进程的继承 / 区别
继承:进程上下文、堆栈、内存信息、打开的文件描述符、信号设置、优先级、工作目录等几乎所有资源
区别:① 各自 PID/PPID 不同;② 父进程的锁不继承;③ 子进程未决告警清除、未决信号集置空
衍生问题:僵尸进程 & 孤儿进程僵尸进程:子进程退出,父进程未调用 wait/waitpid回收其退出状态,子进程残留 task_struct,成为僵尸进程(占用内核资源)
孤儿进程:父进程先于子进程退出,子进程被init/upstart进程收养,由收养进程自动回收,无资源泄漏问题
2. vfork () 核心
设计目的:解决 fork全量拷贝地址空间的效率问题
核心机制:采用写时拷贝(copy-on-write),父子进程共享物理内存,仅当子进程修改内存数据时,才会拷贝父进程资源
关键特性:vfork 创建的子进程会阻塞父进程,直到子进程调用 exec/exit 后,父进程才会继续执行
二、程序替换:exec 函数族
- 核心作用
在当前进程中,用新的可执行程序替换原进程的代码段、数据段、堆栈段;替换后,原进程除PID外,所有内容被覆盖,新程序从 main 函数开始执行。 - 适用场景
进程无继续执行的意义,需执行新程序时直接调用;
父进程 fork 创建子进程后,在子进程中调用 exec,实现 "创建新进程执行新程序" 的效果(fork+exec 是 Linux 创建新进程的经典组合)。

c
#include <stdio.h>
#include <unistd.h> // execlp 头文件
int main()
{
// execlp 成功无返回,失败返回-1
if (execlp("ps", "ps", "-ef", NULL) < 0)
{
perror("execlp error!");
return 1; // 失败时返回非0
}
return 0;
}
c
#include <stdio.h>
#include <unistd.h> // fork, execvp, getpid, sleep 头文件
#include <sys/types.h>// pid_t 类型头文件
#include <sys/wait.h> // wait 头文件(可选,用于回收子进程)
int main(int argc, char *argv[])
{
pid_t pid;
printf("Parent process start, PID = %d\n", getpid());
pid = fork();
if (pid == 0)
{
// ========== 子进程区域:执行程序替换 ==========
printf("Child process start, PID = %d\n", getpid());
// 1. 最常用:execvp(PATH查找+参数数组)
execvp("ls", argv); // 示例:./execv -l 等价于 ls -l
// 以下是其他exec函数的示例(注释状态,可按需打开)
// execv("/bin/ls", argv); // 全路径+参数数组
// execl("/bin/ls", "ls", "-l", "/", NULL); // 全路径+参数列表
// execlp("ls", "ls", "-al", "/", NULL); // PATH查找+参数列表
// exec调用失败才会执行到这里
perror("execvp error!");
sleep(10); // 失败后停留10秒,方便观察
return 1;
}
else if (pid != -1)
{
// ========== 父进程区域 ==========
printf("\nParent process continue, PID = %d\n", getpid());
// wait(NULL); // 可选:等待子进程结束,避免僵尸进程
}
else
{
// fork失败
perror("error fork() child process!");
return 1;
}
return 0;
}三、进程退出:exit () & _exit ()
- 头文件与原型
c
// exit:标准库函数
#include <stdlib.h>
void exit(int status);
// _exit:系统调用
#include <unistd.h>
void _exit(int status);- 核心区别(最关键:I/O 缓冲区处理)
- _exit():直接终止进程,清除进程占用的内存,销毁内核中的进程数据结构,不处理文件 I/O 缓冲区(缓冲区数据会丢失);
-exit():对_exit () 做了包装,执行流程为:调用退出处理函数 → 清理 I/O 缓冲区(将缓冲区数据写入文件) → 调用_exit () 系统调用终止进程。
四、子进程回收:wait () & waitpid ()
wait函数
调用该函数使进程阻塞,直到任一个子进程结束或者是该进程
接收到了一个信号为止。如果该进程没有子进程或者其子进程
已经结束,wait函数会立即返回。
waitpid函数
功能和wait函数类似。可以指定等待某个子进程结束以及等
待的方式(阻塞或非阻塞)