一.RAG模型的过程
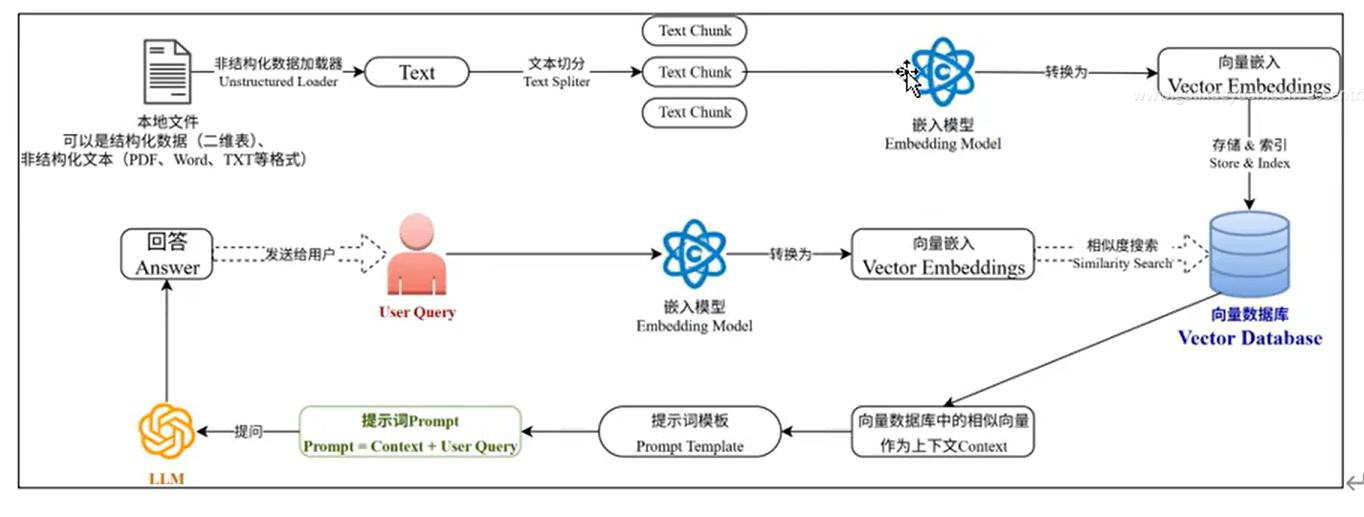
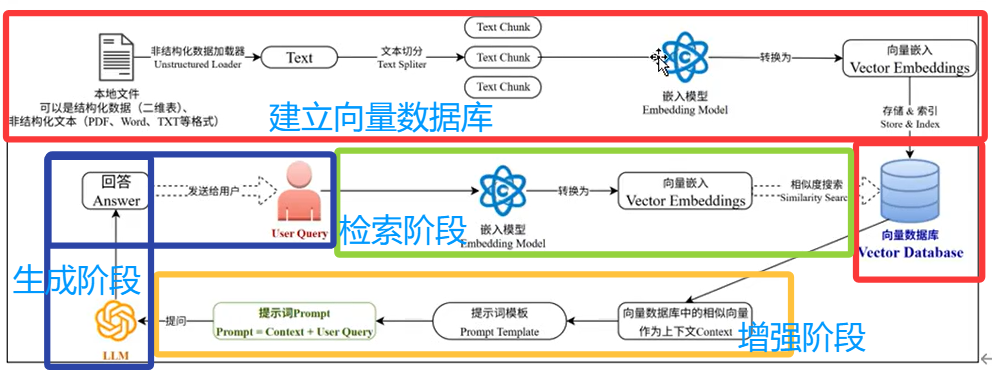
1.1 阶段一: 建立向量数据库(离线建库,只做一次)
- 加载数据 :用「非结构化数据加载器」,把本地的 PDF/Word/TXT/Excel 等文件,统一提取成纯文本(Text)。
- 例子:把《公司差旅管理制度》《报销规范》等文档,全部读成纯文字。
- 文本切分 :用「文本切分工具(Text Splitter)」,把长文本切成语义完整的小文本块(Text Chunk),比如每段 500 字左右。
- 作用:避免文本太长,嵌入模型处理不了,同时保证检索精度。
- 向量嵌入 :用「嵌入模型(Embedding Model)」,把每个文本块转换成一串数字(向量 Embeddings)。
- 大白话:给每段文字生成「数字身份证」,语义越像,向量越接近。
- 存储索引 :把所有向量 + 原文,存进向量数据库,做好索引。
- 作用:后续用户提问时,能一秒从海量数据里找到最相关的内容。
阶段核心作用:
把「人类能看懂的文档」,变成「AI 能快速检索的向量库」,为后续问答做准备。
1.2 阶段 2:检索阶段(用户提问后第一步)
对应图中绿框 ,是 RAG 的「搜索环节」,核心是从向量库中找到和用户问题最相关的资料。
1.2.1 完整流程:
- 用户提问(User Query):员工问「我去北京出差 3 天,审批流程是什么?」
- 问题向量化 :用和建库时完全相同的嵌入模型 ,把用户问题也转换成向量。
- 关键:必须用同一个模型,否则向量空间不一致,检索会完全失效。
- 相似度搜索 :拿着问题的向量,去向量数据库里,做余弦相似度搜索,捞出最相关的 Top3/Top5 文本块。
- 例子:匹配到「出差审批流程」「申请时限」这两段最相关的制度原文。
1.2.2 阶段核心作用:
精准筛选出和用户问题相关的知识,过滤无关内容,为大模型提供「靠谱的参考资料」。
1.3 阶段 3:增强阶段(Prompt 工程核心)
对应图中黄框 ,是 RAG 的「灵魂环节」,核心是把检索到的资料,变成大模型能理解、能遵守的 Prompt,也就是「检索增强」的核心。
1.3.1 完整流程:
- 组装上下文:把检索到的相似向量对应的原文,作为「上下文 Context」。
- 套用提示词模板 :用提前写好的 Prompt 模板,把「上下文 + 用户问题」拼成完整的 Prompt。
- 模板就是你学的「提示词五要素」,核心要求:只基于上下文回答,不准瞎编。
- 示例: 【参考资料】:{检索到的差旅制度原文}【用户问题】:我去北京出差 3 天,审批流程是什么?请严格基于参考资料回答,不得编造任何信息。
- 生成最终 Prompt :
Prompt = Context + User Query,发给大模型。
1.3.2 阶段核心作用:
用「提示词约束」+「上下文注入」,强制大模型只从给定资料里回答,彻底解决幻觉问题,这就是「增强」的本质。
1.4 阶段 4:生成阶段(最终输出)
对应图中蓝框 ,是 RAG 的「收尾环节」,核心是大模型基于参考资料,生成最终回答。
完整流程:
- 大模型推理(LLM) :大模型拿到 Prompt,只根据参考资料,生成符合要求的回答。
- 例子:大模型根据制度,准确告诉你审批流程、申请时限,不会乱编公司没有的规则。
- 返回给用户:把生成的回答,原样返回给提问的员工,完成一次问答。
阶段核心作用:
把「结构化的参考资料」,转换成「自然、通顺、符合人类习惯的回答」,完成从「知识检索」到「智能问答」的闭环。