1. 文档目的
本文专门说明当前仓库里,deploy/model_wrappers.py、onnx_test/run_linemod_hybrid_ort.py、onnx_test/run_linemod_hybrid_trt.py 三者之间是怎么配合工作的。
本文讨论的是部署测试链,不讨论训练。
当前仓库的真实测试结构不是:
- 整个 PVN3D 一次性转成一个 ONNX
- 整个 PVN3D 一次性转成一个 TensorRT engine
而是:
- 用
model_wrappers.py把完整 PVN3D 拆成三个阶段 - 把能稳定导出的两段导出为
ONNX - 再把 ONNX 转成
TensorRT engine - PointNet2 保留原生
PyTorch + CUDA Extension - 用 ORT 或 TRT 脚本把整条链重新接起来做 LINEMOD 测试
这也是当前目录中以下三份代码同时存在的原因:
2. 当前测试链的核心结论
当前可行的测试主线是:
rgb_backbone走ONNX Runtime或TensorRTPointNet2继续走原生PyTorch CUDA Extensionfusion_head走ONNX Runtime或TensorRTpose solver继续走仓库原有的 LINEMOD 求解逻辑
因此当前存在两条混合测试链:
- ORT 版:
rgb_backbone.onnx -> PointNet2 Native CUDA -> fusion_head.onnx - TRT 版:
rgb_backbone.engine -> PointNet2 Native CUDA -> fusion_head.engine
这两条链验证的是同一套部署拆分边界,只是中间执行后端不同。
3. 为什么必须拆成三段
3.1 根因在 PointNet2
PVN3D 里最难直接导出的部分不是 CNN,也不是最终预测头,而是 PointNet2。
PointNet2 当前依赖本地编译的 CUDA 扩展与自定义算子,这类算子不属于标准 ONNX 算子集合,也不是 TensorRT 当前可以直接解析的通用层。
所以当前阶段不能指望:
- "整网直接导 ONNX"
- "整网直接转 TRT"
3.2 当前拆分边界
当前拆分边界固定为三段:
rgb -> out_rgb, rgb_segcld_rgb_nrm -> pcld_embout_rgb, choose, pcld_emb -> pred_kp_of, pred_rgbd_seg, pred_ctr_of
其中:
- 第 1 段可以导成
rgb_backbone.onnx/rgb_backbone.engine - 第 2 段只能继续保留原生 CUDA
- 第 3 段可以导成
fusion_head.onnx/fusion_head.engine
这不是为了代码整洁,而是为了先把能稳定落地的部分落地。
4. 产物之间的关系
可以把当前产物链看成:
checkpointmodel_wrappers.pyONNXTensorRT engineORT/TRT 混合测试
对应关系如下:
weights/*.pth.tar
由 model_wrappers.py 加载- wrapper 拆分后导出:
deploy/models/onnx_ape/rgb_backbone.onnxdeploy/models/onnx_ape/fusion_head.onnx
- ONNX 再构建成:
deploy/models/engine_ape/rgb_backbone.enginedeploy/models/engine_ape/fusion_head.engine
- 最终由测试脚本把这些产物与 PointNet2 原生 CUDA 拼回完整推理链
5. model_wrappers.py 代码解析
文件:
这个文件不负责导出,也不负责最终测试。它负责定义部署边界。
5.1 load_checkpoint
职责:
- 归一化 checkpoint 路径
- 加载 checkpoint
- 提取
state_dict - 去掉可能存在的
module.前缀
这里还有一个容器里已经遇到过的兼容性点:
ycb_pvn3d_best.pth.tar可以直接用torch.loadape_pvn3d_best.pth.tar可能是pickle格式
所以当前实现是:
- 先尝试
torch.load - 如果遇到
Invalid magic number - 自动回退到
pickle.load
这一步解决的是"同样叫 .pth.tar,但底层保存格式不完全一致"的问题。
5.2 build_full_model
职责:
- 按
num_classes、num_points构建完整 PVN3D - 挂载 checkpoint
- 移到目标设备
- 切到
eval()
后续所有 wrapper 都建立在这一步生成的完整模型之上。
5.3 RGBBackboneWrapper
输入:
rgb
输出:
out_rgbrgb_seg
对应代码逻辑很直接:
python
out_rgb, rgb_seg = self.cnn(rgb)
return out_rgb, rgb_seg这一段的特点是算子标准、结构清晰,所以适合先导出。
5.4 PointNet2NativeWrapper
输入:
pointcloud
输出:
pcld_emb
代码本身也很直接:
python
return self.pointnet2(pointcloud)但它背后的实现依赖 CUDA 扩展,这就是为什么它不能直接并入当前 ONNX / TRT 主线。
5.5 FusionHeadWrapper
输入:
out_rgbchoosepcld_emb
输出:
pred_kp_ofpred_rgbd_segpred_ctr_of
这一段做的事情有三步:
- 把
out_rgb拉平并按照choose抽取像素特征 - 和
pcld_emb做rgbd_feat融合 - 通过三个 head 输出关键点偏移、分割和中心点偏移
这里最关键的输入不是 rgb,而是已经对齐好的:
out_rgbchoosepcld_emb
这也是 ORT/TRT 测试脚本都必须显式处理 choose 的原因。
5.6 build_split_wrappers
这是整个部署测试链的工厂函数。
它一次性返回:
full_modelrgb_backbonepointnet2_nativefusion_headgather_rgb_feature
当前 ORT 和 TRT 两个测试脚本都依赖这个统一约定。
6. 当前 tar 权重的两个作用
当前混合测试链里,weights/*.pth.tar 不是只起一个作用,而是同时承担两件事。
6.1 给 PointNet2 Native CUDA 提供参数
当前 PointNet2 还没有转成 ONNX,也没有转成 TensorRT。
所以无论是 ORT 测试脚本还是 TRT 测试脚本,都必须先从 tar 权重构建完整 PVN3D,再从里面取出:
pointnet2_native
这部分权重的作用是:
- 让原生
PyTorch + CUDA Extension路径能够正常前向 - 把
cld_rgb_nrm转成pcld_emb - 作为 ONNX / TRT 两段子图之间的桥接段
如果没有这部分权重,当前混合链就缺中间这一段,ORT 和 TRT 都接不起来。
6.2 给 full_model 提供基线,用于精度对比
当前两个测试脚本里还会用同一个 tar 权重再构建:
full_model
这个 full_model 不是当前部署链实际执行的一部分,而是原始完整 PyTorch 模型基线。
它的作用是把原始完整模型输出和以下结果做对比:
- ORT 混合推理结果
- TRT 混合推理结果
对比项主要包括:
pred_kp_ofpred_rgbd_segpred_ctr_of
这样可以检查:
- ONNX 子图导出后是否出现明显数值漂移
- TensorRT engine 接入后是否出现异常偏差
- 输入裁剪、点数重采样、
choose重映射是否破坏了对齐关系
6.3 为什么当前还不能完全脱离 tar
这也是为什么当前 ORT/TRT 测试还不能算"完全脱离 PyTorch 的纯部署态"。
当前 tar 权重仍然负责:
- 支撑未转换的
PointNet2 Native CUDA - 提供完整 PyTorch 基线做精度对照
只有当 PointNet2 也被替换为部署后端,或者不再需要 full_model 做对照时,tar 在测试链里的作用才会进一步缩小。
7. ORT 测试脚本解析
文件:
这个脚本的职责不是单独测 ONNX 文件能不能加载,而是验证:
- 两个 ONNX 子图
- 一段原生 CUDA
- 一套 LINEMOD pose solver
能不能被重新拼成一条完整链路。
6.1 输入参数的意义
关键参数如下:
--cls
指定 LINEMOD 目标物体,例如ape--checkpoint
用于构建pointnet2_native和full_model--rgb-onnx
指向rgb_backbone.onnx--fusion-onnx
指向fusion_head.onnx--num-points
必须和导出时保持一致,当前是4096--height
当前固定为480--width
当前固定为624--crop-left
当前通常是8,用于把原始640宽图裁到624
6.2 为什么脚本里要先解析绝对路径
脚本内部会:
python
os.chdir(PVN3D_ROOT)这样做是为了兼容仓库里仍然依赖相对路径的 LINEMOD 旧工具代码。
如果不先把以下参数解析成仓库根目录下的绝对路径:
--checkpoint--rgb-onnx--fusion-onnx--output
那么用户从仓库根目录传入的相对路径,在 chdir 之后就会被带偏。
这就是之前相对路径找不到文件的原因。
6.3 预处理阶段
核心函数:
crop_and_resample_linemod_sample
它做了两件必须的事:
- 把 RGB 从
640裁到624 - 把点数从原始数量重采样到
4096
与此同时,它还必须同步处理:
chooselabelskp_targ_ofstctr_targ_ofst
这里尤其重要的是 choose。
choose 记录的是点与图像像素的对应关系。一旦 RGB 被裁剪,像素索引坐标系就变了,所以 choose 必须重映射到新的 624 宽图坐标上。
这也是 crop_left 参数存在的原因。
6.4 ONNX Runtime 部分
脚本通过:
make_sessionrun_rgb_backbonerun_fusion_head
分别执行两个 ONNX 子图。
具体顺序是:
rgb -> rgb_backbone.onnx -> out_rgb, rgb_segcld_rgb_nrm -> pointnet2_native -> pcld_embout_rgb + choose + pcld_emb -> fusion_head.onnx -> pred_*
其中 ONNX Runtime 输入输出主要走 numpy。
6.5 为什么还要构建 full_model
ORT 脚本不仅构建 pointnet2_native,还会构建 full_model。
目的不是重复推理,而是为了可选的 PyTorch 数值对比。
这个对比用于判断:
- ONNX 导出后数值是否偏离过大
- 裁剪与重采样是否破坏了输入对齐
choose重映射是否正确
8. TRT 测试脚本解析
文件:
TRT 脚本和 ORT 脚本在整体流程上是一致的,差异只在中间两段执行后端。
7.1 输入参数的意义
关键参数和 ORT 版基本一致,只是:
--rgb-engine
替换了--rgb-onnx--fusion-engine
替换了--fusion-onnx
其余像 --cls、--checkpoint、--num-points、--crop-left 的语义不变。
7.2 TrtEngineRunner 的职责
TRT 脚本的核心类是:
TrtEngineRunner
它负责:
- 读取
.engine - 反序列化 engine
- 创建 execution context
- 根据 binding 信息准备输入输出 tensor
- 调
execute_async_v2
7.3 为什么脚本不依赖 pycuda
当前实现直接使用:
torch.cudatorch.Tensor.data_ptr()
把 GPU 内存地址传给 TensorRT。
也就是说:
- 输入 tensor 由
torch分配 - 输出 tensor 也由
torch分配 - TensorRT 只消费和写入这些指针
这样做的好处是:
- 不额外引入
pycuda - 不额外引入
cupy - 可以直接复用当前容器里已经工作的 PyTorch CUDA 环境
7.4 TRT 脚本为什么也要构建 pointnet2_native 和 full_model
原因和 ORT 版一致:
pointnet2_native负责补上当前不能转 TensorRT 的那一段full_model负责做可选的 PyTorch 数值对比
因此 TRT 脚本不是"纯 TensorRT 整网推理",而是"TensorRT + Native CUDA"的混合推理。
9. ORT 和 TRT 两个脚本的共同约束
8.1 都依赖同一组部署边界
无论是 ORT 版还是 TRT 版,都必须接受同一组中间张量约定:
rgb_backbone输出out_rgbpointnet2_native输出pcld_embfusion_head输入out_rgb, choose, pcld_emb
只要这个张量契约变了,两个测试脚本都要一起改。
8.2 都依赖同一组输入尺寸
当前已验证的输入配置是:
height=480width=624num_points=4096crop_left=8
这些值不是任意选择的,而是已经和当前导出产物绑定。
8.3 都依赖同一类 checkpoint / 类别语义
对 LINEMOD 单物体流程来说:
num_classes通常固定为2
但这不表示导出产物能跨物体复用。
例如从 ape 换到 can 时,通常仍然是:
bash
--num-classes 2但下面这些都要换:
- checkpoint
- ONNX 目录
- engine 目录
--cls
10. 推荐测试顺序
当前不建议一上来就只看 TRT。
推荐顺序是:
- 先确认
model_wrappers.py可以正确加载 checkpoint 并完成拆分 - 先导出 ONNX
- 先跑 ORT 混合测试
- 再构建 TensorRT engine
- 再跑 TRT 混合测试
原因很直接:
- ORT 更容易定位图结构与输入输出问题
- TRT 更适合做最终部署验证
- 先 ORT 后 TRT,排错成本最低
11. Graphviz 图
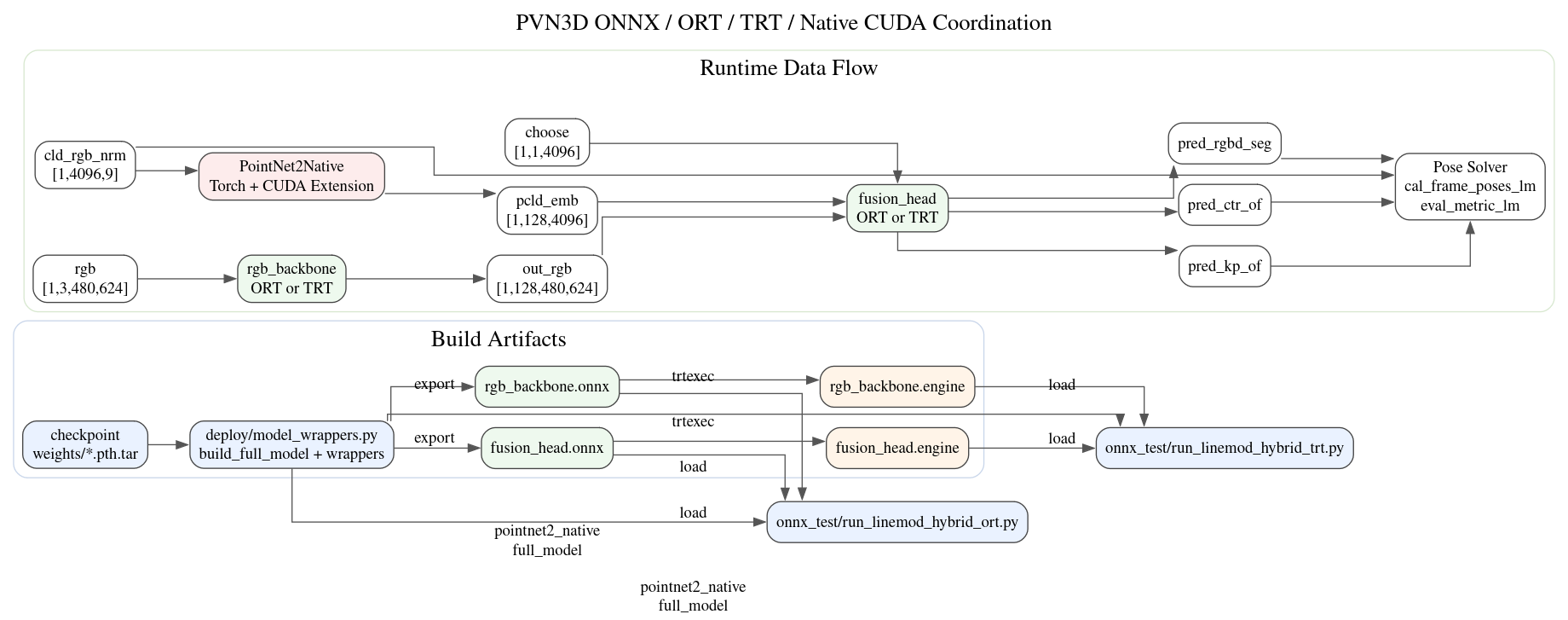
10.2 图的阅读方式
这张图包含两层信息:
- 构建产物关系
- 运行时数据流关系
构建产物关系说明:
- checkpoint 先进入
model_wrappers.py - wrapper 拆分后导出 ONNX
- ONNX 再转 TensorRT engine
- ORT/TRT 测试脚本分别消费这些产物
运行时数据流说明:
rgb进入rgb_backbonecld_rgb_nrm进入PointNet2Nativeout_rgb + choose + pcld_emb进入fusion_headpred_*再进入 pose solver
12. 当前结论
当前三份代码的职责边界已经比较清晰:
- model_wrappers.py
负责定义部署拆分边界,并提供统一的子模块构造方式 - run_linemod_hybrid_ort.py
负责验证 ONNX Runtime 版混合链 - run_linemod_hybrid_trt.py
负责验证 TensorRT engine 版混合链
它们共同构成了当前 PVN3D 的部署测试主线:
- 先拆模型
- 再导出 ONNX
- 先用 ORT 校验子图与联调逻辑
- 再转 TensorRT engine
- 最后用 TRT 验证更接近部署形态的混合推理链