论文:Trick-GS: A Balanced Bag of Tricks for Efficient Gaussian Splatting
作者:Anil Armagan 等,Samsung R&D Institute UK
方向:3D Gaussian Splatting、端侧 3D 重建、模型压缩、快速训练
Introduction
3D Gaussian Splatting(3DGS)已经成为当前神经渲染和三维重建中非常重要的表示方式。相比 NeRF,3DGS 具有训练收敛快、渲染速度快、重建质量高等优势,因此在 3D 重建、VR/AR、多媒体和机器人感知等方向中被大量使用。
但 3DGS 也有一个非常明显的问题:模型太大。一个场景往往包含几十万到数百万个 Gaussian,每个 Gaussian 又包含位置、尺度、旋转、不透明度、颜色以及球谐函数 SH 系数等参数。论文指出,一个 3D Gaussian primitive 通常包含 59 个参数,这会导致磁盘存储、训练显存、渲染负载都比较高。对于手机、AR 眼镜、机器人等资源受限设备,这一点非常不友好。
本文的目标很明确:
不是重新设计一个全新的 3DGS 表示,而是系统分析已有高效 3DGS 技术,并将其中有效策略组合成一个更均衡的高效 3DGS pipeline:Trick-GS。
论文最终实现了相比 vanilla 3DGS:训练速度最高约 2×,模型体积最高约 40× 更小,渲染速度最高约 2×,同时保持相近重建精度。

Related Works
论文将高效 3DGS 相关工作主要分成三类:
1. Storage Efficient GS
存储高效的 3DGS 方法主要从两个方向入手:
-
减少 Gaussian 数量,例如 pruning;
-
减少每个 Gaussian 的属性数量,例如 SH masking、颜色压缩、量化等。
此外,也有方法使用 Vector Quantization、bit quantization、anchor-based Gaussian、Octree、tri-plane 等结构来降低存储。
分析:
-
这类方法关注的是"模型压缩";
-
但单纯压缩可能带来重建质量下降;
-
对端侧部署而言,存储压缩非常关键,但不能只看 MB,还要看训练时间和渲染 FPS。
2. Fast-converging GS
3DGS 通常需要针对每个场景单独训练,因此训练时间是核心指标。已有工作通过优化 SH 更新、改进 rasterizer 或 CUDA kernel 来加速训练。论文中 Trick-GS 也采用了类似思想,例如将 0 阶 SH 与高阶 SH 分离,高阶 SH 不需要每一步都更新。
分析:
-
3DGS 的训练效率不仅影响科研实验速度,也影响在线建图和端侧重建;
-
如果一个方法只能离线训练几十分钟甚至几小时,实际产品化会比较困难。
3. Fast-rendering GS
虽然 3DGS 本身渲染已经很快,但如果 Gaussian 数量过多,渲染时排序、tile rasterization、alpha blending 仍然会带来负担。减少 Gaussian 数量、减少无效 Gaussian、优化 rasterizer 都能提升 FPS。
Method
Trick-GS 的核心思想可以概括为:
不发明单一"大招",而是把多个经过验证的 trick 组合起来,在训练时间、模型大小、渲染速度和重建质量之间取得更好的平衡。
论文主要采用了以下几个技术模块。
1. Pruning with Volume Masking
这一部分的目的是学习一个 mask,用于判断哪些 Gaussian 可以被移除。
具体做法是:
为每个 Gaussian 学习一个 mask 参数,然后作用在 opacity 和 scale 上。训练过程中通过 sigmoid + straight-through estimator 得到近似二值 mask,最后根据阈值将不重要的 Gaussian prune 掉。
分析:
-
scale 很小、opacity 很低的 Gaussian 往往对最终图像贡献有限;
-
直接保留这些 Gaussian 会增加存储和渲染负担;
-
mask 学习比手工阈值更灵活,因为它可以随训练过程自适应判断哪些 primitive 不重要。
2. Pruning with Significance of Gaussians
除了基于体积和 opacity 的 pruning,论文还采用了 significance score pruning。
直观理解:
如果一个 Gaussian 很少被训练图像中的 ray 命中,或者虽然被命中但 opacity 和体积贡献很小,那么它对最终渲染影响有限,可以删除。
论文将 Gaussian 是否被 ray 命中、opacity 和 Gaussian volume 结合起来计算 significance score,并在训练过程中按一定比例 prune。
分析:
-
volume masking 偏向局部属性;
-
significance pruning 更关注全局渲染贡献;
-
两者结合可以避免只看某一个指标导致误删或漏删。
3. Spherical Harmonic Masking
3DGS 中 SH 系数用于表达 view-dependent color,也就是视角相关颜色。但并不是每个 Gaussian 都需要完整的高阶 SH 表达。
例如:
-
漫反射区域可能只需要低阶颜色;
-
高光、金属、透明或强视角相关区域才更依赖高阶 SH。
Trick-GS 为每个 Gaussian 的每个 SH band 学习 mask,训练结束后删除不必要的 SH band。论文指出,SH band masking 可以显著降低存储需求。
分析:
-
这一步不是减少 Gaussian 数量,而是减少每个 Gaussian 的参数量;
-
对模型压缩非常重要,因为 SH 系数在 3DGS 参数中占比较大;
-
这也说明 3DGS 压缩不能只盯着"删点",还应该考虑"删属性"。
4. Progressive Training
Progressive Training 是本文非常重要的一组策略。论文采用了三种 progressive 方式。
4.1 Progressive Blurring
训练早期对图像进行 blur,只让模型先学习低频结构;随着训练推进,逐渐减小 blur kernel,让模型恢复高频细节。论文认为这可以减少 floating artifacts,并帮助模型收敛到更好的局部最优。
分析:
-
这类似 coarse-to-fine 训练;
-
先学大结构,再学细节;
-
对 SfM 初始化不佳或场景复杂时尤其有用。
4.2 Progressive Resolution
训练初期使用低分辨率图像,随后逐渐提升到原始分辨率。论文中从较低分辨率开始训练,可以降低训练时间,同时帮助模型先捕获全局结构,再恢复局部细节。
实验中,progressive resolution 对树枝、背景细结构恢复有明显帮助。论文 Fig.4 显示,相比 vanilla 3DGS,采用 progressive resolution 后细小结构更稳定。

4.3 Progressive Gaussian Scale
论文还在 rasterization 阶段调整 Gaussian 的投影尺度,让训练早期 Gaussian 覆盖更大区域,从而获得更稳定的梯度;后期再逐渐恢复细粒度表达。
分析:
-
progressive scale 本质上也是 low-frequency first;
-
早期 Gaussian 更大,能更快学习粗结构;
-
后期 Gaussian 变细,负责表达细节。
5. Accelerated Training
Trick-GS 还采用训练加速策略:
-
将 0 阶 SH 与高阶 SH 分离;
-
高阶 SH 不必每一步更新,而是每 16 次迭代更新一次;
-
使用优化 CUDA kernel 加速 SSIM loss 计算;
-
将 11×11 的 2D Gaussian kernel 替换为两个较小的 1D kernel,并融合卷积输出计算 SSIM。
分析:
-
这是工程优化,但很关键;
-
论文不是只做算法设计,也关注实际训练瓶颈;
-
对端侧和快速实验非常有价值。
Experiments
论文在三个经典数据集上评估:
-
Mip-NeRF 360;
-
Tanks&Temples;
-
Deep Blending。
评价指标包括:
-
PSNR;
-
SSIM;
-
LPIPS;
-
Storage;
-
Training Time;
-
FPS;
-
Gaussian 数量。
实验设置上,论文遵循 3DGS 的真实场景设置,使用 SfM points 和 camera poses,每 8 张图像取 1 张作为测试集,训练 30K iterations,并在 RTX 3090 上进行公平比较。
实验结果分析
在 Mip-NeRF 360 上,vanilla 3DGS 存储约 770 MB,训练时间约 23.83 min,FPS 约 142;Trick-GS 存储约 39 MB,训练时间约 15.41 min,FPS 约 222,PSNR 为 27.16,与 vanilla 3DGS 的 27.56 接近。
在 Tanks&Temples 上,Trick-GS 存储约 20 MB,训练时间约 10.56 min,FPS 约 298,相比 vanilla 3DGS 的 431 MB、14.69 min、172 FPS,压缩和渲染效率优势明显。
在 Deep Blending 上,Trick-GS 存储约 25 MB,训练时间约 13.11 min,FPS 约 260;vanilla 3DGS 则为 664 MB、25.29 min、121 FPS。
论文总结称,Trick-GS-small 在三个数据集上相比 vanilla 3DGS 实现约 23× 压缩、1.7× 训练加速和 2× FPS 提升,但会有轻微精度损失;Trick-GS 则牺牲部分效率,换取更好的精度平衡。
Ablation Study
消融实验是这篇论文比较值得看的部分。
论文在 Mip-NeRF 360 的 bicycle 场景上分析了不同 trick 的贡献:
-
Gaussian blurring 可以在几乎不损失精度的情况下 prune 掉接近一半 Gaussian;
-
progressive downsampling 能降低训练时间和 Gaussian 数量;
-
significance pruning 对 storage 降低贡献最大;
-
Gaussian masking 能降低训练过程峰值 Gaussian 数量;
-
progressive Gaussian scale 有助于提升精度。
分析:
-
单个 trick 并不是万能的;
-
多个 trick 之间存在互补关系;
-
Trick-GS 的优势不是某一个模块特别强,而是整体组合比较均衡。
这也是论文标题中 "Balanced Bag of Tricks" 的核心含义。
创新点与技术亮点
1. 从"提出新结构"转向"系统组合有效策略"
很多 3DGS 压缩工作会提出新的表示结构,例如 anchor、octree、hash-grid、codebook 等。Trick-GS 的路线不同:它基本保持 3DGS 表示不变,而是通过训练策略、mask pruning、SH masking 和工程加速来提升效率。论文也明确说明,该方法没有通过 anchor points 或显式结构改变 3DGS,而主要依赖训练阶段策略。
这一点很实用,因为它更容易集成进现有 3DGS pipeline。
2. 同时优化训练、存储和渲染
很多压缩方法只强调模型大小,或者只强调 FPS。Trick-GS 的价值在于它同时考虑:
-
training time;
-
disk storage;
-
rendering FPS;
-
reconstruction quality;
-
peak Gaussian count。
这对端侧部署更加合理。论文 Fig.2 显示,Trick-GS 在训练过程中不会像部分方法那样让 Gaussian 数量急剧增长,因此对低显存设备更友好。
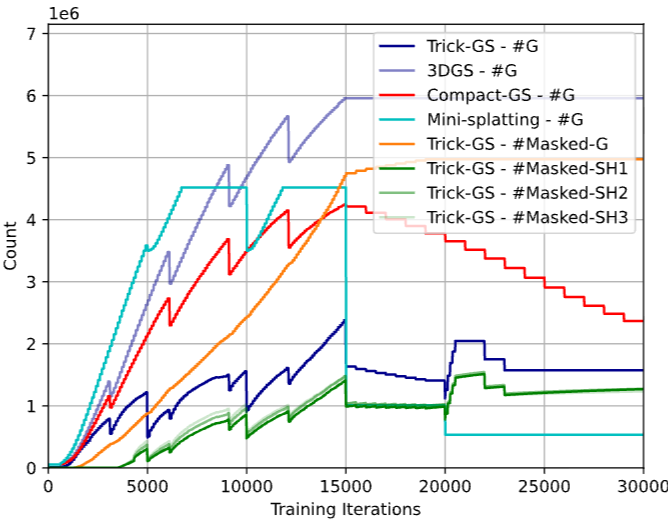
3. SH Masking 的收益非常直接
SH 参数在 3DGS 中占比很高。如果每个 Gaussian 都使用完整高阶 SH,会带来大量冗余。Trick-GS 通过学习每个 Gaussian 是否需要对应 SH band,实现更细粒度压缩。
这点值得借鉴:
3DGS 优化不仅要减少点,还要减少每个点的表达复杂度。
4. Progressive Training 对重建结构有正向作用
论文不仅说明 progressive training 能加速,还展示了其对细结构恢复的帮助。例如树枝、背景结构等 challenging regions,采用 progressive strategy 后更加稳定。
这说明 coarse-to-fine 训练不仅是效率技巧,也具有正则化效果。
值得借鉴的地方
1. 做 3DGS 系统时,不要只优化一个指标
如果只追求模型小,可能 PSNR/LPIPS 明显下降;如果只追求精度,模型可能过大;如果只追求 FPS,训练时间和存储未必理想。
Trick-GS 的思路是构建一个多目标平衡系统:
-
精度可以略降,但不能明显崩;
-
模型大小要大幅下降;
-
训练时间要降低;
-
渲染 FPS 要提升;
-
训练过程中的 Gaussian 峰值数量也要控制。
这对实际工程非常重要。
2. Progressive 策略非常适合 3DGS
3DGS 对初始化比较敏感,SfM 点云质量不好时容易出现 floating artifacts。先低频、后高频的训练方式能缓解这个问题。
在自己的 3DGS 实验中,可以尝试:
-
低分辨率开始训练;
-
训练初期加入 blur;
-
逐步提升分辨率;
-
控制 Gaussian scale;
-
后期再 densification 或精细化。
3. Pruning 应该结合多个维度
只看 opacity 可能误删;只看 scale 也可能误删;只看 ray hit 次数又可能忽略局部细节。
Trick-GS 结合了:
-
volume mask;
-
opacity;
-
scale;
-
ray hit significance;
-
SH band mask。
这说明高质量 pruning 应该是多指标、多阶段的。
4. 工程优化同样重要
论文中的 accelerated training 并不复杂,但效果实用:
-
高阶 SH 低频更新;
-
CUDA kernel 优化 SSIM;
-
half precision 存储。
这些工程策略可能没有复杂理论,但对训练时间和部署成本有直接影响。
局限性分析
1. 方法本质上是"组合技巧",理论原创性有限
Trick-GS 的很多组件来自已有工作,例如 pruning、progressive training、SH masking、accelerated rasterization 等。论文的创新更偏系统集成与经验验证,而不是提出全新的 3D 表示或新优化理论。
这并不是缺点,但需要明确:
它的贡献主要是工程化、系统化、组合优化。
2. 超参数较多
Trick-GS 中涉及很多阈值和 schedule:
-
mask threshold;
-
SH mask threshold;
-
pruning percentile;
-
pruning 次数;
-
blur kernel decay;
-
resolution schedule;
-
progressive scale schedule;
-
densification timing。
这些超参数可能对不同场景敏感。论文结论中也提到未来需要根据设备需求自动化选择 compact learning system。
3. 没有彻底解决自动化部署问题
论文证明 Trick-GS 可以根据需求调整精度、大小、训练速度,但目前仍需要人工设定策略。对于真实端侧应用,更理想的方式应该是:
-
给定设备显存;
-
给定目标 FPS;
-
给定最大模型大小;
-
自动搜索 Trick-GS 配置。
这部分论文尚未完成。
4. 后处理压缩仍有提升空间
论文尝试过进一步后处理,例如将模型压缩到更小,但 PSNR 会下降约 0.33 dB,因此作者将 codebook learning、Huffman encoding 等后处理压缩留作未来工作。
这说明 Trick-GS 当前主要依赖训练期压缩,而不是完整的编码压缩系统。
5. 实验仍主要集中在常见 benchmark
论文使用 Mip-NeRF 360、Tanks&Temples、Deep Blending,这些是合理 benchmark,但对真实端侧场景仍不够充分。例如:
-
手机端实时重建;
-
AR 眼镜低功耗渲染;
-
动态场景;
-
大规模室外长期建图;
-
内存极小设备上的训练与渲染。
这些还需要进一步验证。
总结
Trick-GS 是一篇非常工程实用的 3DGS 高效化论文。它没有试图完全重构 3DGS,而是从已有高效技术中筛选出有效策略,并将它们组合成一个均衡 pipeline。
它的核心价值在于:
-
用 progressive training 提升训练效率和结构稳定性;
-
用 Gaussian pruning 减少 primitive 数量;
-
用 SH masking 减少单个 Gaussian 的参数冗余;
-
用 accelerated training 优化训练时间;
-
在模型大小、训练速度、渲染 FPS 和重建质量之间取得较好平衡。
从结果看,Trick-GS 相比 vanilla 3DGS 可以达到约 23× 存储压缩、1.7× 训练加速和 2× FPS 提升,同时保持接近的重建质量。
个人认为,这篇论文最值得学习的不是某一个 trick,而是它的系统思路:
端侧 3DGS 不应该只追求最高 PSNR,而应该围绕真实设备约束,在精度、速度、存储和显存之间做整体设计。
对于做 3DGS-SLAM、端侧重建、AR/VR 场景表示压缩的同学,这篇论文非常值得参考。