目录
前言
在前面的章节中,学习了List系列集合,我们知道List系列集合添加的元素是有序、可重复、有索引的,而今天要学习的Set系列集合与List系列集合添加的元素的特点恰恰相反,是无序、不重复、无索引的。
但在实际开发中,我们经常会遇到这样的需求:"名单里不能有重复的身份证号" 、"抽奖名单里每个人只能中一次奖" 。如果用 List 去做,我们需要写繁琐的 if(!list.contains(e)) 判断,效率极低。因此我们应该使用Set系列集合
一、Set系列集合
1.Set集合的特点
- 无序:存取顺序不一致
- 不重复:可以去除重复
- 无索引:没有带索引的方法,所以不能用普通for来循环遍历,也不能通过索引来获取元素
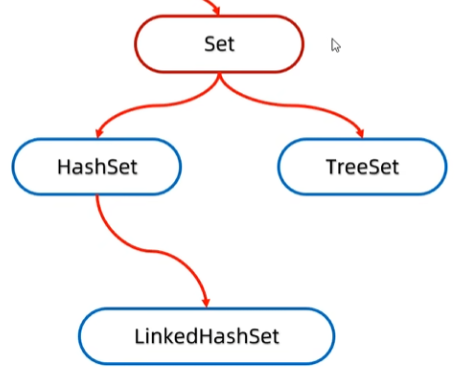
2.Set集合的实现类
-
HashSet:无序、不重复、无索引
-
LinkedHashSet:有序、不重复、无索引
-
TreeSet:可排序、不重复、无索引
Set接口中的方法基本上与Collection的API一致。
二、HashSet
1.哈希表和哈希值
- HashSet集合底层采取哈希表存储数据。
- 哈希表是一种对增删改查数据性能都较好的结构。
哈希表的组成:
- JDK8之前:数组+链表
- JDK8开始:数组+链表+红黑树
哈希值:
- 对象的整数表现形式。
- 根据hashCode方法计算出来的int类型的整数。
- 该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算。
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值。
对象的哈希值的特点:
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的。
- 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的。
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能是一样的。(哈希碰撞)
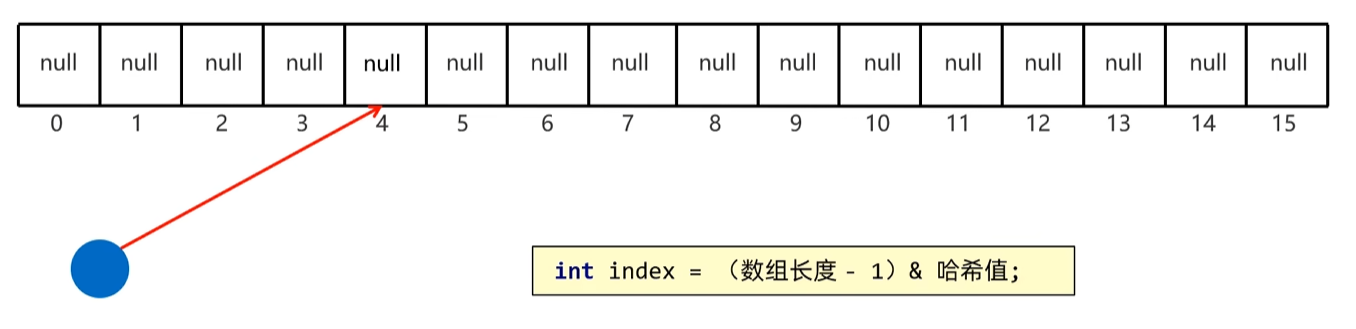
为什么要转换为哈希值?
哈希表底层是由数组组成的,如果我们要存储数据,我们需要计算这个数据的哈希值,根据哈希值选择应该存入的位置,因此当我们存入的数据类型为引用数据类型时,我们需要把具体的对象转换为整数,才能匹配哈希表的存储格式。
2.hashCode()方法
①当没有重写hashCode()方法时
java
public class Test {
public static void main(String[] args) {
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("zhangsan", 23);
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
}
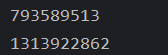
}尽管两个对象的属性值相同,但所输出的两个哈希值是完全不同的:
②当重写了hashCode()方法时
Idea提供了自动重写hashCode的快捷方式:
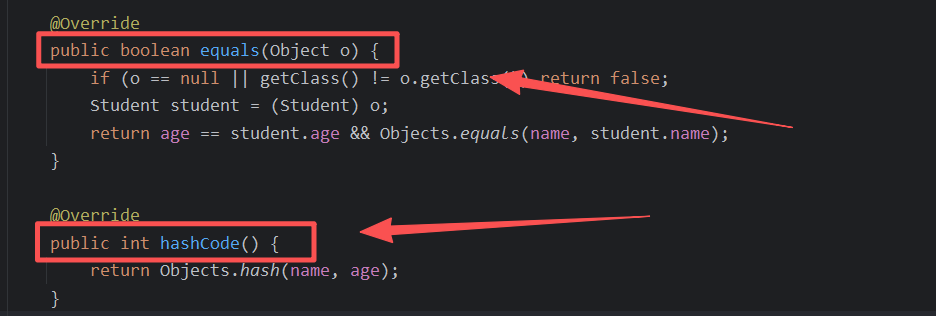
此时再运行上面那段代码,所输出的哈希值是相同的。
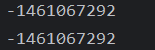
③哈希碰撞
属性值不同,得到的哈希值却相同。


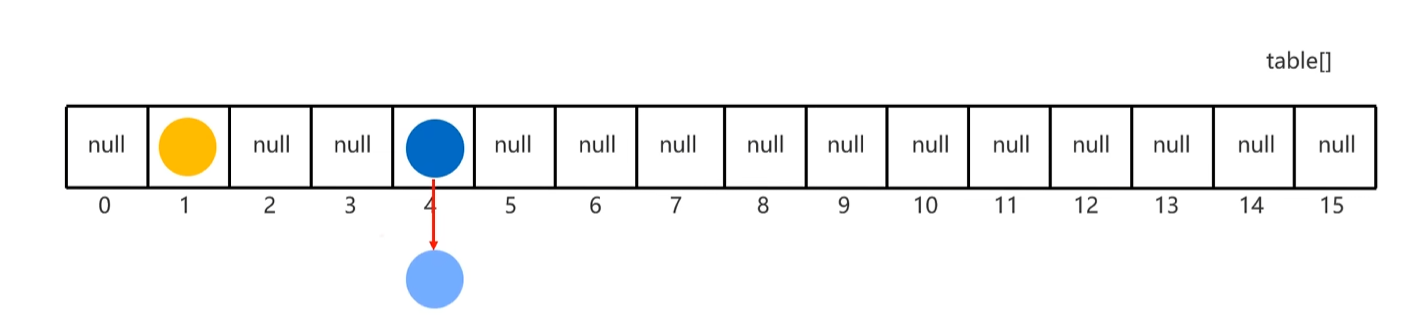
3.HashSet底层原理
①创建一个默认长度为16,默认加载因子为0.75的数组,数组名为table
②根据元素的哈希值根数组的长度计算出应该存入的位置
③判断当前位置是否为null,如果是null直接存入
④如果位置不为null,表示有元素,则调用equals方法比较属性值
⑤一样:不存 不一样:存入数组形成链表
JDK8以前:新元素存入数组,老元素挂在新元素下面
JDK8以后:新元素直接挂在老元素下面
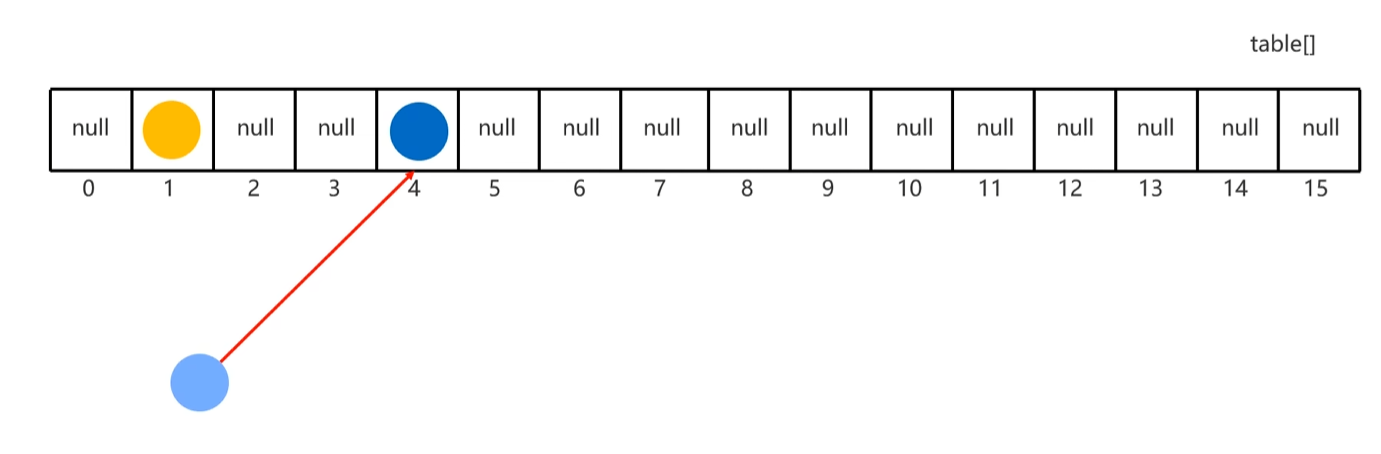
JDK8以前:
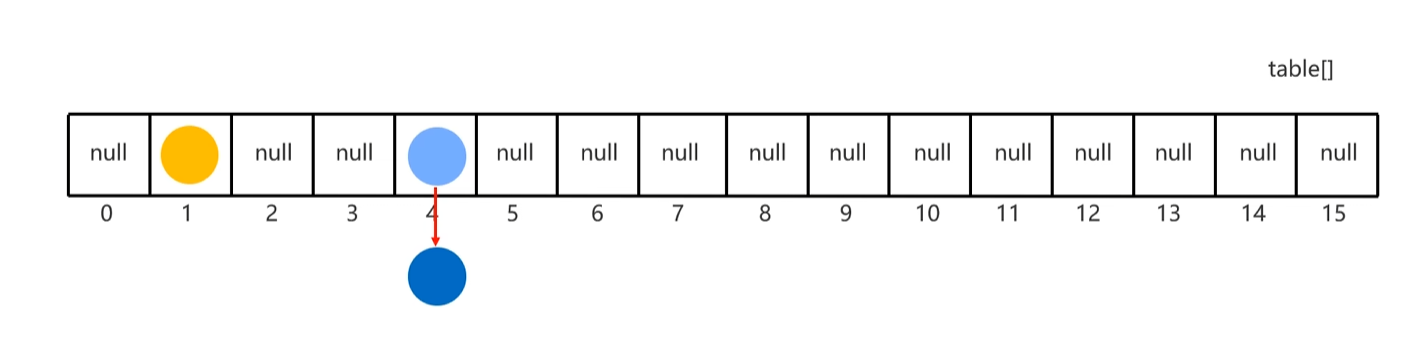
JDK8以后:
加载因子的作用:
也就是数组的占用率,当table数组当中的16*0.75=12个位置已经被占用后,会对该数组进行两倍的扩容,也就是扩容到16*2=32的长度。
另一种情况:
当链表长度大于8而且数组长度大于等于64,链表就会转换为红黑树来存储。
4.案例
创建多个学生对象,要求学生对象的属性值相同时,我们认为是同一个对象
java
public class Test {
public static void main(String[] args) {
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("zhangsan", 23);
Student s3 = new Student("lisi", 24);
Student s4 = new Student("wangwu", 25);
HashSet<Student> hs = new HashSet<>();
System.out.println(hs.add(s1));
System.out.println(hs.add(s2));
System.out.println(hs.add(s3));
System.out.println(hs.add(s4));
System.out.println(hs);
}
}
三、LinkedHashSet
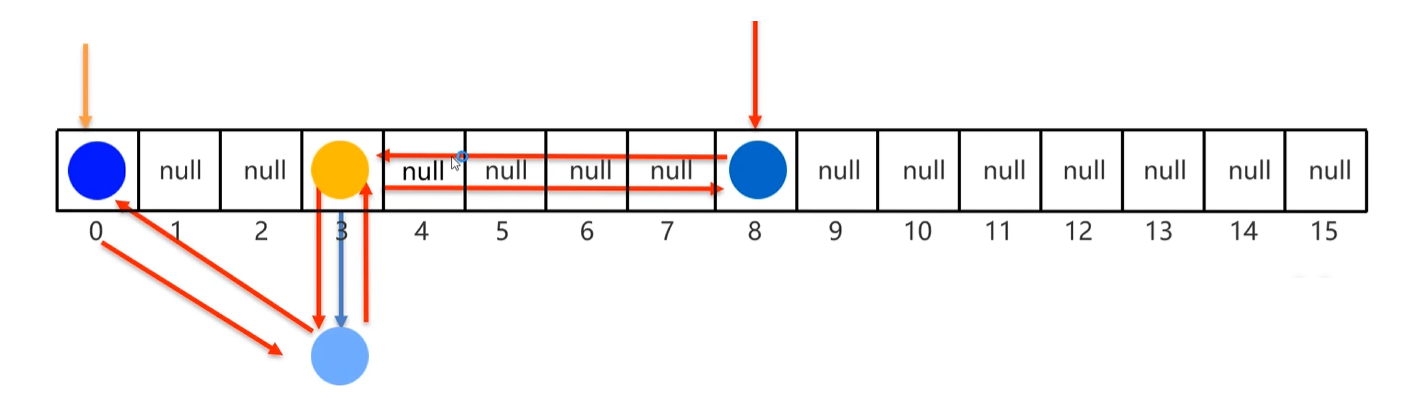
1.底层原理
- 有序、不重复、无索引
- 有序是指存取的顺序是一致的。
- 原理:底层数据结构依旧是哈希表,只是每个元素又额外的多了一个双链表的机制记录存取的顺序。
2.LinkedHashSet是如何保证有序的?
每存入一个节点,都会和前一个节点互相记录地址值。
在遍历时就和普通的HashSet不同了,LinkedHashSet遍历方式是通过双向链表来遍历的,通过第一个添加的元素也就是头节点依次向后遍历。
3.案例
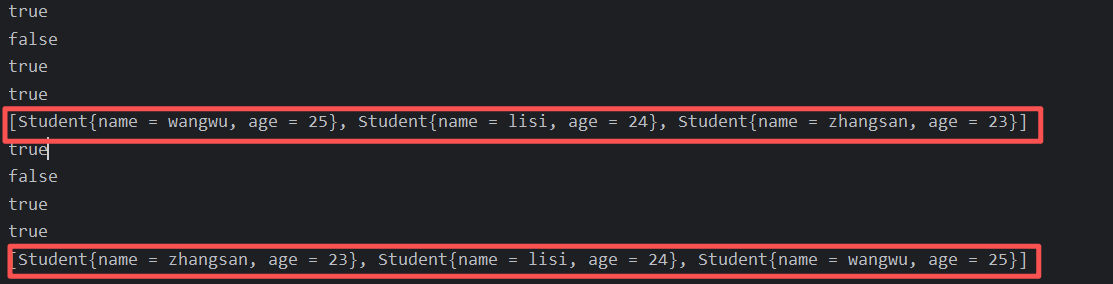
java
public class Test {
public static void main(String[] args) {
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("zhangsan", 23);
Student s3 = new Student("lisi", 24);
Student s4 = new Student("wangwu", 25);
HashSet<Student> hs = new HashSet<>();
System.out.println(hs.add(s1));
System.out.println(hs.add(s2));
System.out.println(hs.add(s3));
System.out.println(hs.add(s4));
System.out.println(hs);
LinkedHashSet<Student> lhs = new LinkedHashSet<>();
System.out.println(lhs.add(s1));
System.out.println(lhs.add(s2));
System.out.println(lhs.add(s3));
System.out.println(lhs.add(s4));
System.out.println(lhs);
}
}
总结
在开发中,我们的选择逻辑应该是怎么样的?
- 默认首选HashSet,它的增删查改效率是最高的。
- 需要顺序选LinkedHashSet:比如处理日志或展现用户操作轨迹。
- 需要排序选TreeSet:比如成绩榜单、按时间排序的消息。
😀😀