JVM简介
JVM是Java Virtual Machine的简称,意味Java虚拟机
虚拟机是指通过软件模拟的具有完整硬件功能的,运行在一个完全隔离的环境中的完整计算机系统
常见的虚拟机:JVM,VMware,Virtual Box
JVM和其他两个虚拟机的区别:
1.VMwave与VirtualBox是通过软件模拟物理CPU的指令集,物理系统重会有很多的寄存器
2.JVM则是通过软件模拟JAVA字节码的指令集,JVM中只是主要保留了PC寄存器,其他的寄存器都进行了裁剪
JVM是一台被定制过的现实中不存在的计算机
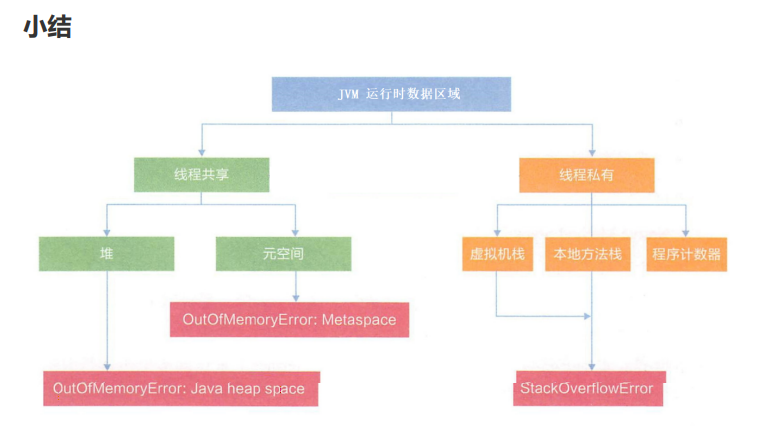
JVM内存区域划分
首先我们要了解为什么要划分区域?
JVM Java虚拟机 仿照真实的机器 真实的操作系统进行设计
真实的操作系统中,对于进程的地址空间是进行了分区域的设计,JVM仿照了操作系统的情况,也进行了分区域的设计
JVM内存空间划分,就相当于JVM进程自身从操作系统中申请到内存空间,再把内存进行不同功能分配
JVM具体是怎么划分的?
核心区域有四个:
1.程序计数器(内存空间),很小的区域,只是用来记录当前指令执行到哪个地址了
2.元数据区 保存当前类被加载好的数据
.Java-->.class-->加载到内存中,要想运行这个代码,就需要把class加载到内存里面(类加载)
3.栈 保存方法的调用关系
4.堆 保存new的对象的
此处的栈和堆和数据结构中的栈和堆没啥关系
栈(线程私有的)
栈保存方法的调用的关系写代码的时候坑定有方法调用,当方法执行完毕,返回到调用位置,继续往后走(栈这个空间不是很大,一般就是十几MB,可以通过JVM初始参数的配置修改)
但又一些情况可能会出现栈溢出
本地方法栈中有C++中的方法栈桢,JVM本身就是由C++实现的,C++栈桢中就有一个方法构造了JAVA的栈
下图说明了C++方法栈,本地方法栈和JVM栈的关系

堆(线程共享)
堆的作用:保存new的对象的
比如Test t=new Test()
如果t是一个局部变量,那么t就在栈上
如果t是一个成员变量,t就是在堆上
如果t是一个静态成员变量,那么t就在元数据区
堆是JVM中最大的空间区域了 往集合类里面添加元素,也是往堆上添加,如果堆上的元素不再使用的话,就需要被释放掉(垃圾回收)
堆里面分为两个区域:新生代和老生代 新生代放新创建的对象,当经过一定GC次数之后还存活的对象会放入老生代 新生代中有三个区域:一个Endn+两个Survivor(s0/s1)
这里具体我们会在垃圾回收机制中详细展开
程序计数器(线程私有)
程序计数器的作用:用来记录当前线程执行的行号的
程序计数器是一块比较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器
程序计数器内存区域是唯一一个在JVM规范中没规定任何OOM情况的区域!
元数据区
元数据包含产量池,方法原信息,klass类原信息
元信息指定就是一些属性,比如类叫啥名字,是不是public,继承自哪些类,实现了哪些接口,方法叫啥名字,参数有几个,都叫啥,都是啥类型,返回值是啥类型
常量池:常见的常量池 String常量池,Integer也有常量池
方法元信息和Klass类元信息都是类对象提供的
元数据区和堆,整个JAVA进程共用一份,程序计数器和栈,一个进程可能有多份(每个线程都有一份)
类加载机制
类加载 .class=>类对象
类加载本身是一个复杂的事情,面试角度,类加载主要关心两个方面:
1.类加载步骤有哪些
2.类加载中的"双亲委派模型"是咋回事
类加载的步骤
三个大的阶段,其中第二个阶段又分成了三个步骤,一共是5个步骤
a.加载:找到.class文件,根据类的全限定名(包名+类名)打开文件,读取文件内容到内存里
b.验证:解析,校验 .class文件读到的内容是否是合法的,并且把这里的内容转换成结构化的数据
c.准备:给类对象申请内存空间,此处申请的内存空间,就相当于全0的空间
d.解析:针对字符串常量,进行初始化
字符串常量,本身就包含在.class文件中,就需要.class文件里解析出来的字符串常量放到内存空间里(元数据区,常量池中)
e.初始化:针对刚才谈到的类对象进行最终的初始化,针对类对象的各种属性进行填充,包括类中的静态成员,如果这个类还有父类,父类还没有加载的,也会触发父类的类加载
类加载的触发时机->?一个进程中,一个类的加载,只会触发一次
懒汉模式/懒加载 用到那个类,就会触发那个类的加载
1.构造这个类的实例 2.调用/使用类静态属性/静态方法
3.使用某个类的时候,如果他的父类还没有加载,也会触发父类的加载
类加载中的"双亲委派模型"
双亲委派模型,描述了类加载中,根据全限定类名,找到.class文件的过程,更准确的说,是"单亲委派模型/父亲委派模型"
类加载器:JVM中专门的模块,负责类加载,JVM默认通过了三种类加载器
1.BootstrapClassLoader
2.ExtensionClassLoader
3.ApplicationClassLoader
此处所说的父子关系不是父类子类,而是通过parent这样的引用指向
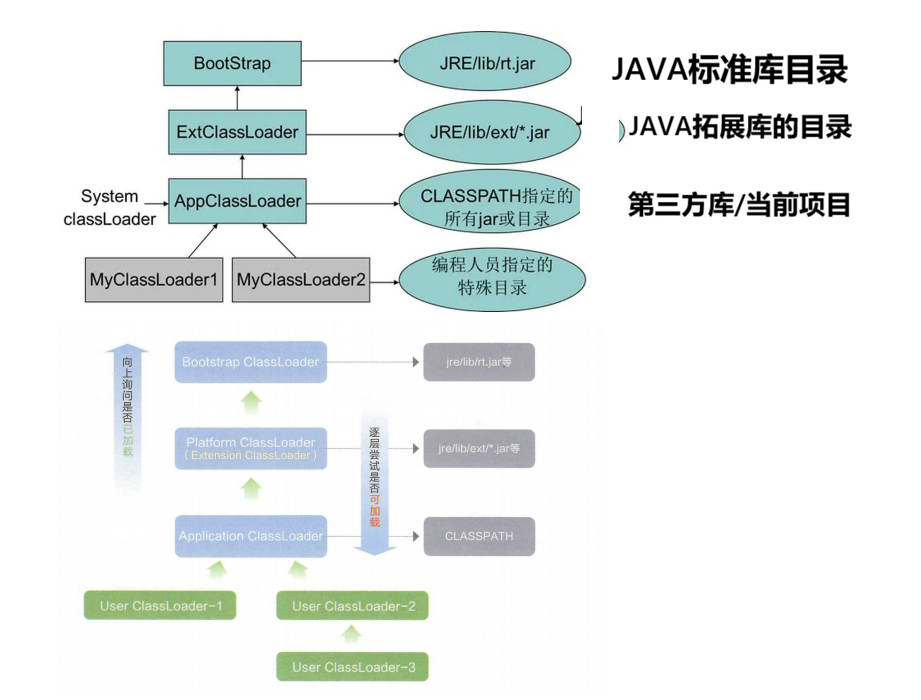
这三个类加载器首当其冲的是进行"找.class文件"的环节
双亲委派模型的过程:
进行类加载,通过全限定类名,找.class的时候,就会从ApplicationClassLoader作为入口开始,然后把加载类这样的任务,委托给父类来进行,ExtensionClassLoader也不会立即进行进行查找,而是也委托给父类来进行,BootstrapClassLoader也想委托给父亲,但由于无父亲,只能自己进行类加载,根据类名,找标准库返回,是否存在匹配的.class文件,BootstrapClassLoader没有找到,再把任务还给孩子ExtensionClassLoader,接下来ExtensionClassLoader负责进行查找,找到就加载,没找到就把任务还给孩子ApplicationClassLoader,找到就加载,找不到就抛出异常
这一套流程是为了约定优先级,收到一个类名之后,一定是先在标准库中找,再拓展库找,最后在第三方库找
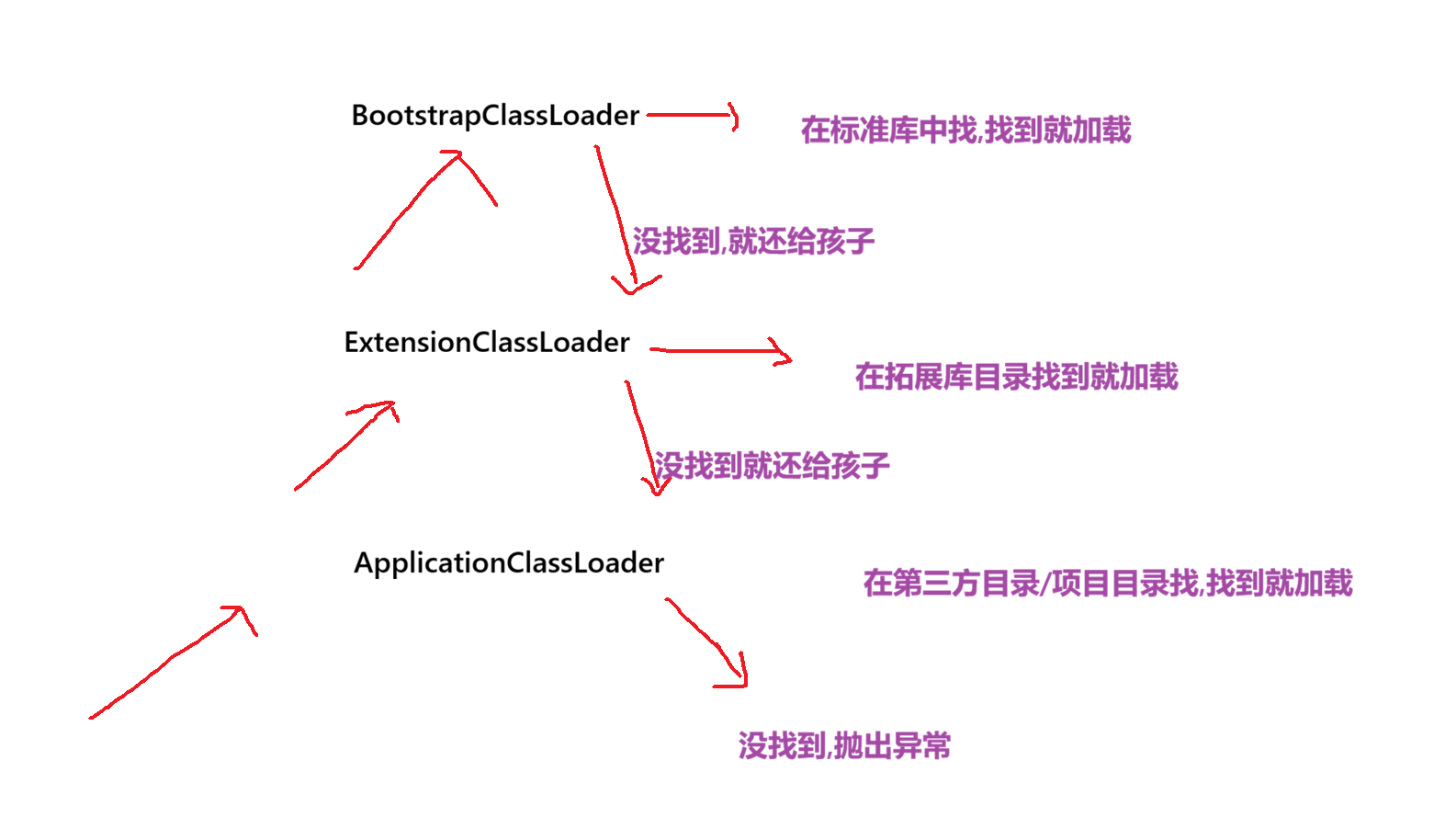
上述三个类加载器是JVM自带的,程序员是可以自定义类加载器
当你自定义的时候,就可以把你的类加载器,放到双亲委派模型,也可以不放到里面
垃圾回收GC
什么是GC
JAVA中释放内存的手段,C语言中申请内存malloc,申请之后一定要手动调用free进行释放,否则会出现内存泄漏
手动释放内存,太麻烦了,太容易出错了,JAVA引入垃圾回收,进行自动释放 JVM会自动识别出,某个内存是不是后续不再使用了,自动释放
为什么C++不引入GC?
GC的代价C++不愿意承担,程序运行的效率产生影响 GC还有一个问题STW(Stop The World)
C++追求(与C兼容,极致性能) C++有智能指针,一定程度上缓解了内存泄露问题
是否有办法既不用操心内存释放,又不影响程序性能
Rust(通过严格的编译器检查,来对代码中的内存问题进行校验 但有一些代价,语法十分复杂)
在JAVA17及以上版本,可以做到让STW大部分情况下<1ms的时间
GC回收JVM中堆内存区域(程序计数器线程销毁自然释放 栈方法执行结束,栈桢自然就结束,随之释放 元数据区 类对象,一般不会释放 堆 创建很多新对象,也有旧对象消亡)
说是回收内存,本质上回收对象
GC工作流程
1.找到垃圾(不再使用的对象)
2.释放垃圾(对应的内促释放掉)
1.找到垃圾(不再使用的对象)
1)引入计数(Python PHP采用了这个方法)
每次进行引用赋值时,都会自动触发引用计数的修改,通过引用计数记录有多少个引用
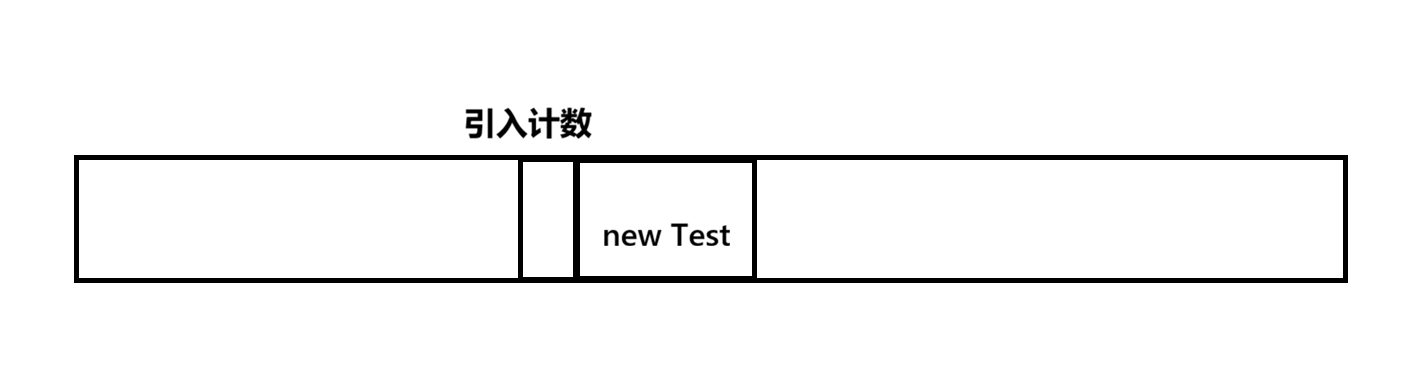
这个整数就表示当前对象有多少个引用指向他
缺陷:1.内存消耗的可能更多(尤其是对象本身比较小) 2.可能会出现"循环引用"这样的问题
2)可达性分析(JAVA采用了这个方案)
引入计数是空间开销 可达性分析是用时间换空间
可达性分析,很像树或图结构的遍历(深度优先遍历/广度优先)
1.以代码中的一些特定对象,作为遍历的"起点"=>GCRoots
1)栈上的局部变量(引用类型) 2)常量池引用指向的对象 3)静态成员(引用类型)
2.尽可能的进行遍历,判定某个对象是否能访问到
3.每次访问一个对象,都会把这个对象标记为可达
当完成所有的对象遍历后,未被标记成"可达"对象就是"不可达"
通过可达性分析,知道了哪些是可达的,剩下的就是不可达的*也就是要回收的垃圾
每隔一段时间,就会触发一次这样的可达性分析的遍历
当知道了哪些对象是垃圾,如何进行释放呢?
1.标记清除
把垃圾对象的内存,直接进行释放 但这样会产生内存碎片问题

这些空闲空间是不连续的,但我们申请空间是申请连续内存的(这样的话这些内存也没法使用)
2.复制算法
一次只使用其中的一半的空间,把不是垃圾的对象,拷贝到另一侧,然后再把另一侧给整体释放

缺点:1.内存的空间利用率很低 2.一旦不是垃圾的对象较多,复制的成本就会很高(尤其是这样的对象中包含大的对象的时候)
3.标记-整理
优点:解决内存碎片&保证内存利用率
类似顺序表的搬运,缺点是内存搬运数据的开销挺大的复制成本仍然存在
C++标准库给出的答案是:自由链表(本质上针对内存不同大小分别管理)
JAVA标准库给出的答案是:分代回收(把上面的1 2 3 主要是2 3结合起来,扬长避短)
代-->对象的年龄 GC的轮次
某个对象,经过一轮GC可达性分析后,不是垃圾,此时对象的年龄就加一(初始年龄是0)
新生代(年龄小的对象) 老年代(年龄大的对象)
针对不同的年龄的对象采用不同的策略
如果一个对象年龄较小,这个对象就很可能快速挂掉
如果一个对象年龄较大,这个对象就可能继续存在
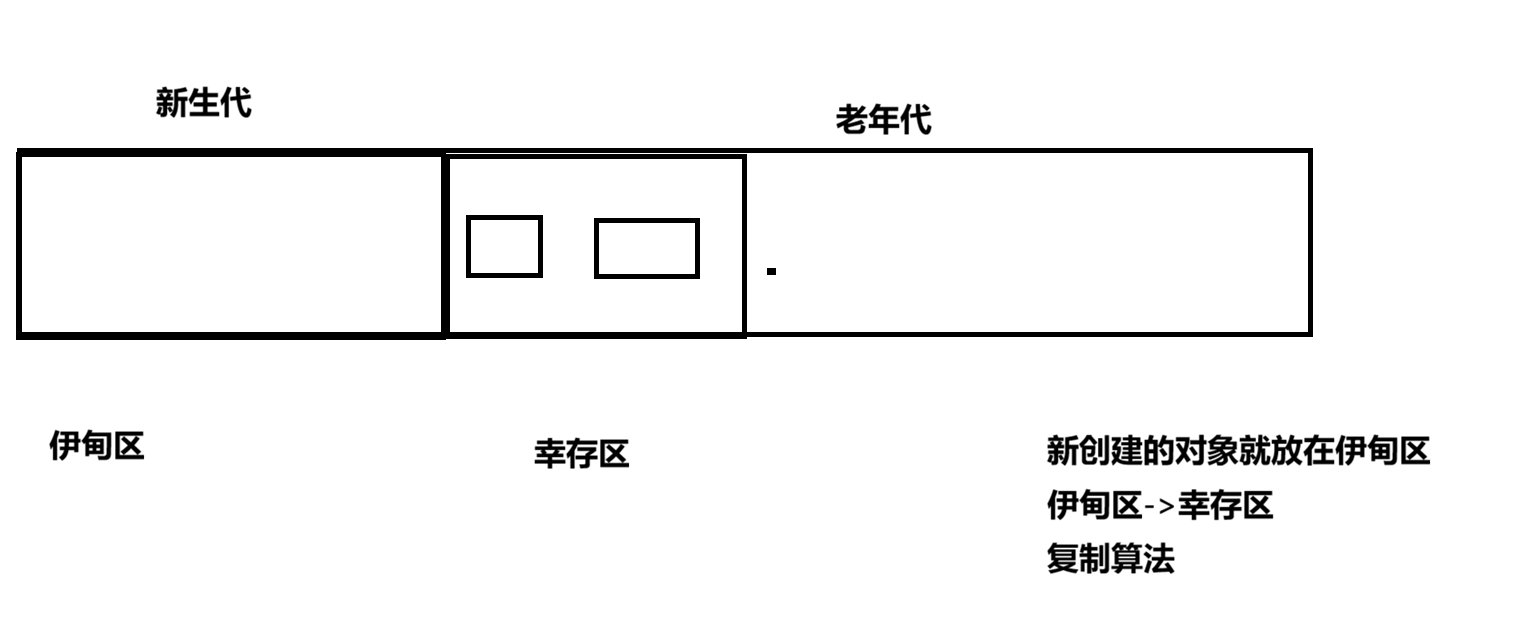
幸存区的对象,也要进行GC的算法,
每一轮GC都会 消灭大部分的对象,剩余对象再次通过复制算法,复制到另一个幸存区,
如果这个对象在幸存区经历了多次复制,都存活下来的,就会晋升到老年代
在老年代标记整理,在新生代复制算法
如果某个对象特别大,就会直接进入老年代