文章目录
-
-
- 安装教程:GCC安装
- [idea工具-Dev C++](#idea工具-Dev C++)
- 下载VS2022-工具
- 下载idea产品-CLion
- 创建c项目-hello
- 编译和输出文件
- 数据类型
- 定义多个变量
- 打印printf
- C语言转义字符
- C语言中的整数(short,int,long)
-
- [short 整型的长度](#short 整型的长度)
- [sizeof 操作符(获取某个数据类型的长度)](#sizeof 操作符(获取某个数据类型的长度))
- [不同整型的输出%hd %d %ld](#不同整型的输出%hd %d %ld)
- C语言中的二进制数、八进制数和十六进制数
- 二进制数、八进制数和十六进制数的输出
- C语言中的正负数及其输出
- C语言中的小数(float,double)
- [字符类型 char](#字符类型 char)
- 字符串
- 标识符定义(变量)
- 注释
- 加减乘除运算的简写
- 自增(++)和自减(--)
- 自动类型转换
- 强制类型转换
- 类型转换只是临时性的
- [printf() 的高级用法](#printf() 的高级用法)
-
- [printf() 的延迟5秒输出](#printf() 的延迟5秒输出)
- C语言scanf:读取从键盘输入的数据
- 读取字符串的说明
- 输入字符和字符串(所有函数大汇总)
- 定义常量
- [const 关键字](#const 关键字)
- [C 存储类](#C 存储类)
-
- [1 **auto** 存储类是所有局部变量默认的存储类。](#1 auto 存储类是所有局部变量默认的存储类。)
- [2 **register** 存储类](#2 register 存储类)
- [3 **static** 存储类](#3 static 存储类)
- [4 **extern** 存储类](#4 extern 存储类)
- [C语言if else语句](#C语言if else语句)
- C语言关系运算符
- 逻辑运算符(&&)(||)
-
- 1) 与运算(&&) 与运算(&&))
- 2) 或运算(||) 或运算(||))
- 3) 非运算(!) 非运算(!))
- 优先级
- [C语言switch case语句](#C语言switch case语句)
- 三目运算符
- [C语言while循环和do while循环](#C语言while循环和do while循环)
- do-while循环
- C语言for循环(for语句)
- C语言break和continue用法(跳出循环)
- C语言数组
- 无序数组的查询
- 字符串长度
- C语言字符串的输入和输出
- C语言字符串处理函数
-
- [字符串连接函数 strcat()](#字符串连接函数 strcat())
- [字符串复制函数 strcpy()](#字符串复制函数 strcpy())
- [字符串比较函数 strcmp()](#字符串比较函数 strcmp())
- C语言对数组元素进行排序(冒泡排序法)
- 对C语言数组的总结
-
- 1) 数组的定义格式为: type arrayNamelength 数组的定义格式为: type arrayName[length])
- 2) 访问数组元素的格式为: arrayNameindex 访问数组元素的格式为: arrayName[index])
- 3) 可以对数组中的单个元素赋值,也可以整体赋值,例如: 可以对数组中的单个元素赋值,也可以整体赋值,例如:)
- C语言函数详解
- C语言预处理命令是什么?
- C语言指针
-
- 一切都是地址
- 什么是指针变量
-
- 定义指针变量
- 和普通变量一样,指针变量也可以被多次写
- 指针变量连续定义
- 获取指针变量数据
- [关于 * 和 & 的谜题](#关于 * 和 & 的谜题)
- 星号`*`的总结
- C语言指针变量的运算(加法、减法和比较运算)
- C语言数组指针(指向数组的指针)
- C语言字符串指针
- C语言指针变量作为函数参数
- C语言指针作为函数返回值
- C语言二级指针
- C语言指针数组
- C语言二维数组指针
- C语言函数指针
- C语言指针的总结
- C语言结构体详解
- C语言typedef的用法
-
-
- 类型别名定义
- [typedef 还可以给数组、指针(https://c.biancheng.net/c/80/)、结构体等类型定义别名](#typedef 还可以给数组、指针、结构体等类型定义别名)
- 结构体类型定义别名:
- 指针类型定义别名:
- [typedef 和 #define 的区别](#define 的区别)
-
- C语言const的用法
-
- [const 和指针](#const 和指针)
- [const 和函数形参](#const 和函数形参)
- [const 和非 const 类型转换](#const 和非 const 类型转换)
- C语言随机数生,rand和srand用法
- C语言中的文件
-
- C语言fopen函数的用法
- [fopen() 函数的返回值](#fopen() 函数的返回值)
- [fopen() 函数的打开方式](#fopen() 函数的打开方式)
- 关闭文件
- C语言fgetc和fputc函数用法
-
- [字符读取函数 fgetc](#字符读取函数 fgetc)
- [对 EOF 的说明](#对 EOF 的说明)
- [字符写入函数 fputc](#字符写入函数 fputc)
-
安装教程:GCC安装
https://www.cnblogs.com/edisonchou/p/4656684.html
idea工具-Dev C++
https://blog.csdn.net/cnds123/article/details/124785425
下载VS2022-工具
https://c.biancheng.net/view/1740.html
下载idea产品-CLion
https://www.jetbrains.com/clion/download/#section=windows
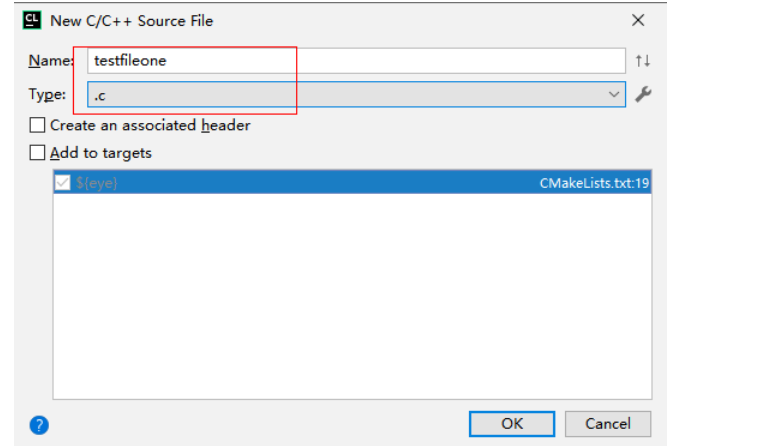
CLion使用
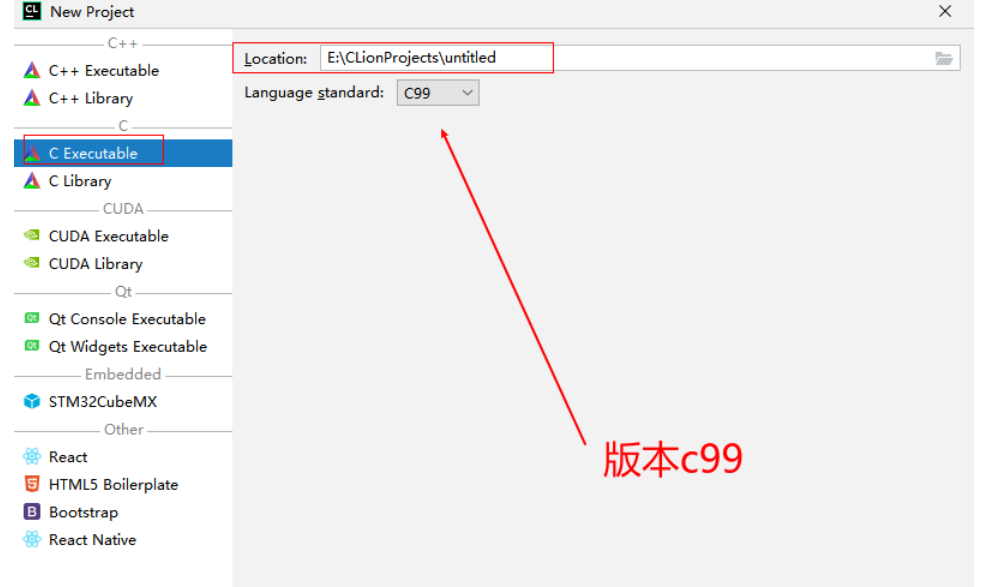
创建C文件
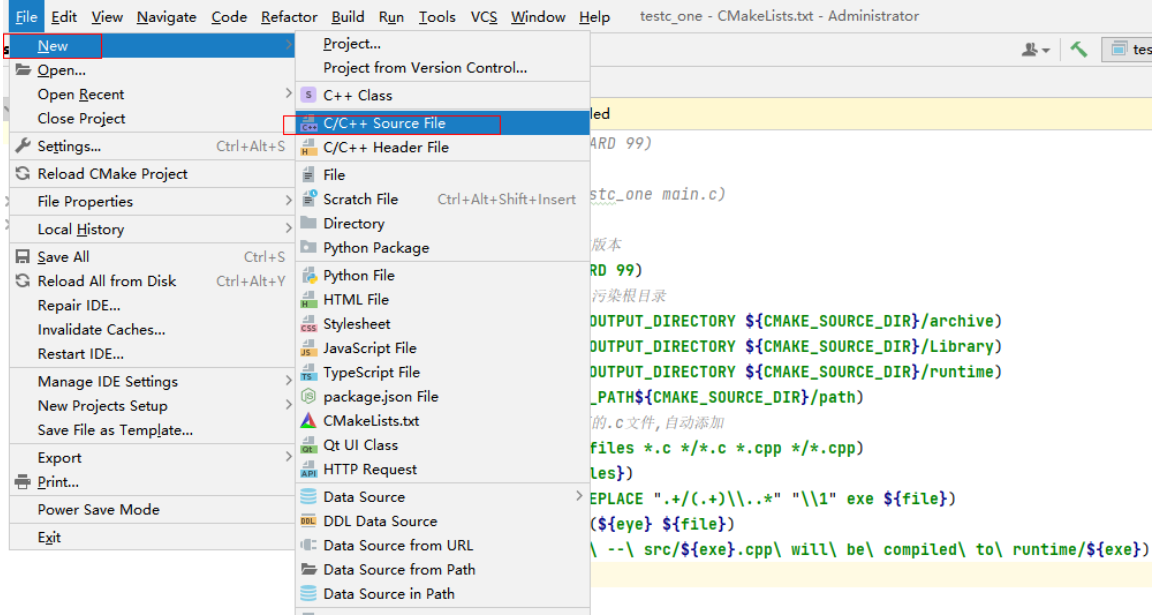
选择c,去电添加到配置文件,点击ok
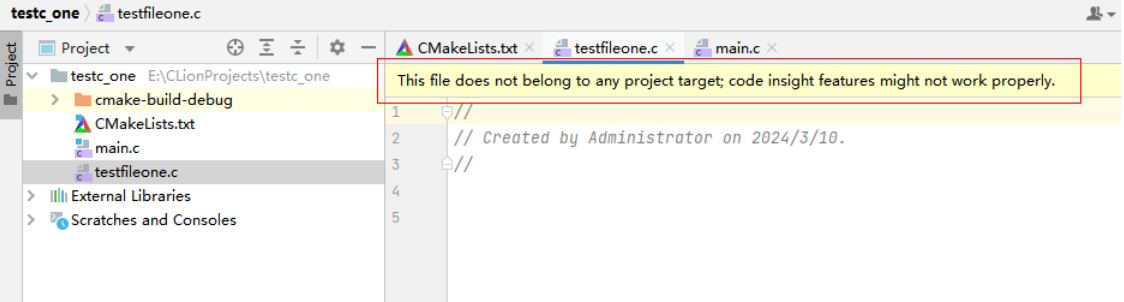
对于多个C文件可以独立运行main
cmake_minimum_required(VERSION 3.21)
project(testc_one C)
#按照书本要求设定C语言版本
set(CMAKE_C_STANDARD 99)
#设定构建运行路径.避免污染根目录
set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${CMAKE_SOURCE_DIR}/archive)
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${CMAKE_SOURCE_DIR}/Library)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_SOURCE_DIR}/runtime)
set(LIBRARY_OUTPUT_PATH ${CMAKE_SOURCE_DIR}/path)
# 遍历项目根目录下所有的.c文件,自动添加
file(GLOB_RECURSE files *.c */*.c *.cpp */*.cpp)
foreach (file ${files})
string(REGEX REPLACE ".+/(.+)\\..*" "\\1" exe ${file})
add_executable(${exe} ${file})
message(\ \ \ \ --\ src/${exe}.cpp\ will\ be\ compiled\ to\ runtime/${exe})
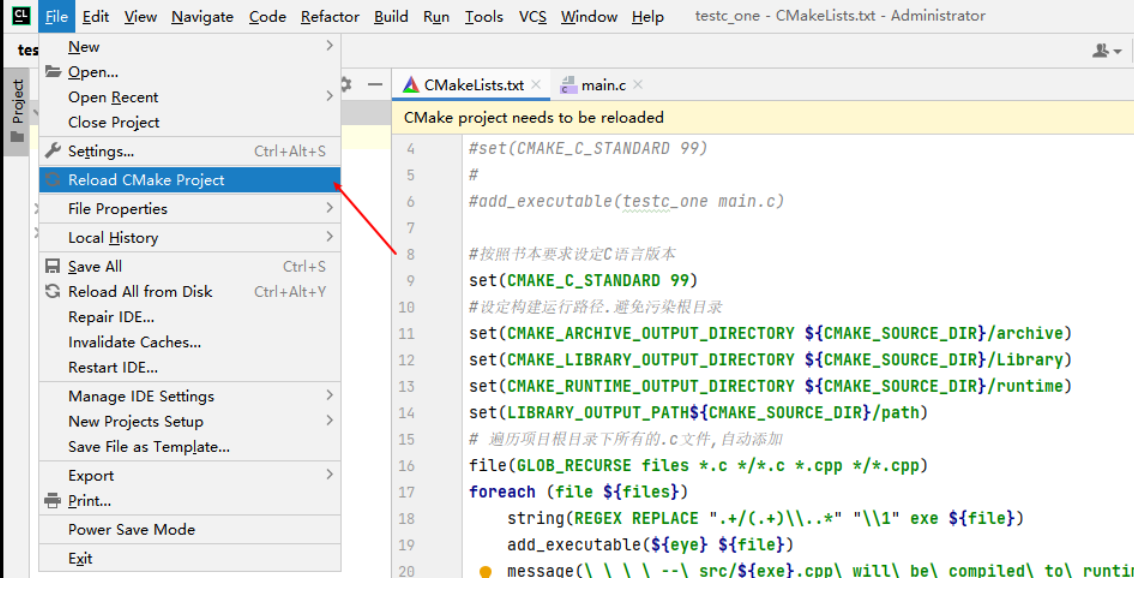
endforeach ()如图设置
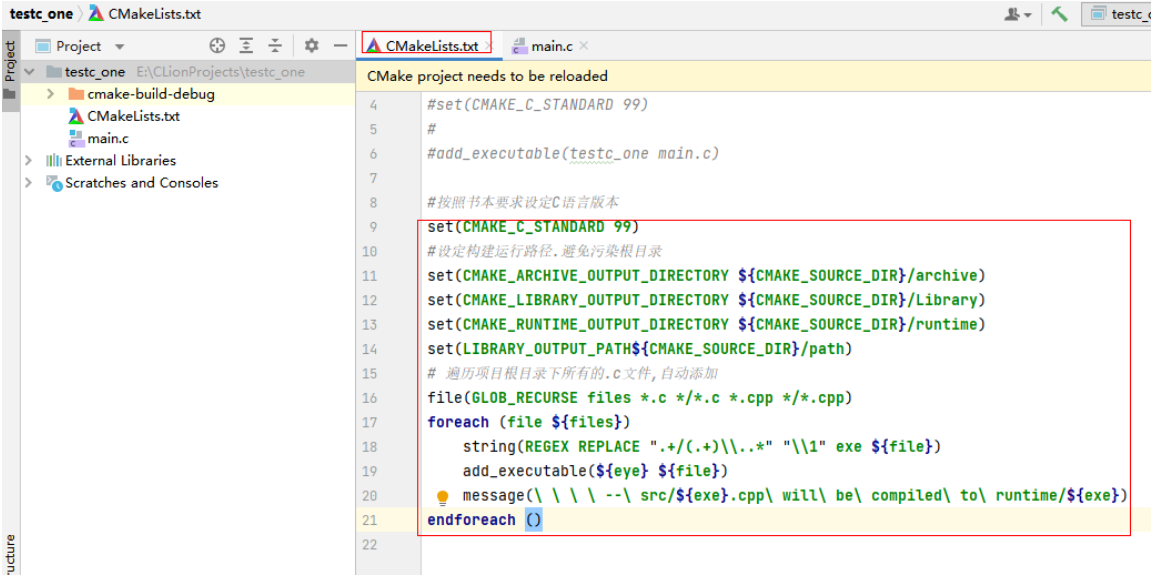
进行刷新
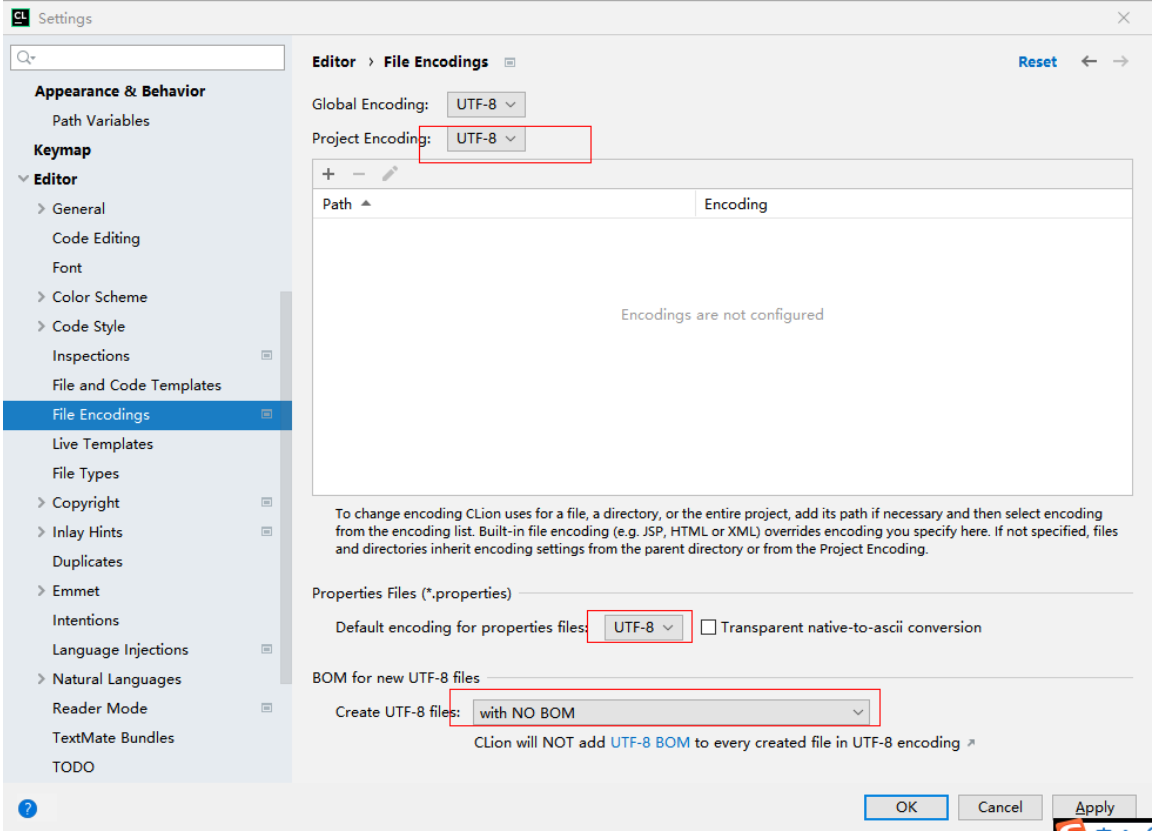
打印时候,乱码修改
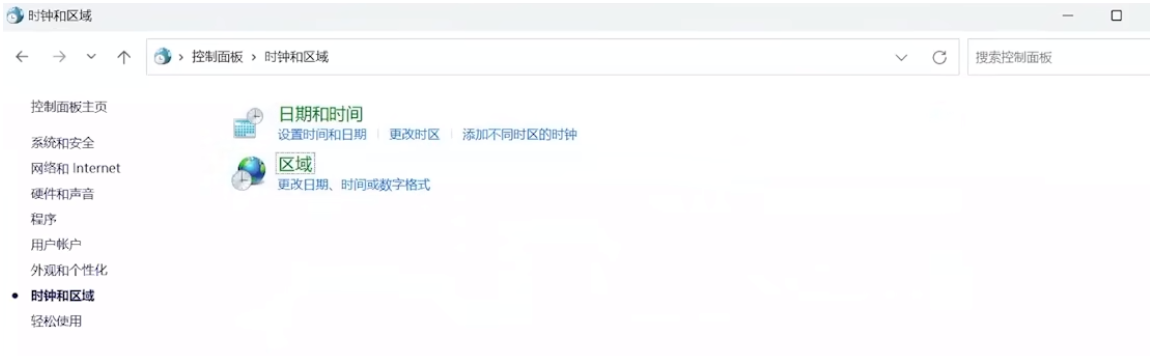
修改win系统设置
创建c项目-hello
https://zhuanlan.zhihu.com/p/43011851
puts输出
#include <stdio.h>
int main()
{
puts("C语言中文网");
return 0;
}
在 puts 函数中,可以将一个较长的字符串分割成几个较短的字符串,这样会使得长文本的格式更加整齐
#include <stdio.h>
int main()
{
puts("C语言中文网!" "C语言和C++!" "http://c.biancheng.net");
// 或者
puts(
"C语言中文网,一个学习C语言和C++的网站,他们坚持用工匠的精神来打磨每一套教程。"
"坚持做好一件事情,做到极致,让自己感动,让用户心动,这就是足以传世的作品!"
"C语言中文网的网址是:http://c.biancheng.net"
);
return 0;
}使用逗号,分隔
pow(10, 2); ---》该函数用来求10的2次方。编译和输出文件
$ gcc.exe hello.c -o hello.exe
$ hello.exe
Hello, World!数据类型
| 说 明 | 字符型 | 短整型 | 整型 | 长整型 | 单精度浮点型 | 双精度浮点型 | 无类型 |
|---|---|---|---|---|---|---|---|
| 数据类型 | char | short | int | long | float | double | void |
在32位环境中,各种数据类型的长度:
| 说 明 | 字符型 | 短整型 | 整型 | 长整型 | 单精度浮点型 | 双精度浮点型 |
|---|---|---|---|---|---|---|
| 数据类型 | char | short | int | long | float | double |
| 长 度 | 1 | 2 | 4 | 4 | 4 | 8 |
定义多个变量
int a, b, c;
float m = 10.9, n = 20.56;
char p, q = '@';打印printf
d 是 decimal 的缩写,意思是十进制数,%d 表示以十进制整数的形式输出;%d 与 abc 是对应的,也就是说,会用 abc 的值来替换 %d。
-
%c:输出一个字符。c 是 character 的简写。
-
%s:输出一个字符串。s 是 string 的简写。
-
%f:输出一个小数。f 是 float 的简写。
int abc=999;
printf("%d", abc);int abc=999;
printf("The value of abc is %d !", abc); //会在屏幕上显示:The value of abc is 999int a=100;
int b=200;
int c=300;
printf("a=%d, b=%d, c=%d", a, b, c); // 会在屏幕上显示:a=100, b=200, c=300#include <stdio.h>
int main()
{
int n = 100;
char c = '@'; //字符用单引号包围,字符串用双引号包围
float money = 93.96;
printf("n=%d, c=%c, money=%f\n", n, c, money); // 输出结果:n=100, c=@, money=93.959999
return 0;
}
C语言转义字符
https://c.biancheng.net/view/1769.html
转义字符的初衷是用于 ASCII 编码,所以它的取值范围有限:
-
八进制形式的转义字符最多后跟三个数字,也即
\ddd,最大取值是\177; -
十六进制形式的转义字符最多后跟两个数字,也即
\xdd,最大取值是\x7f。#include <stdio.h>
int main(){
puts("\x68\164\164\x70://c.biancheng.\x6e\145\x74");
return 0;
}运行结果:
http://c.biancheng.netchar d = '\x61'; //字符a
char *str1 = "\x31\x32\x33\x61\x62\x63"; //字符串"123abc"
char *str3 = "The string is: \61\62\63\x61\x62\x63" //混用八进制和十六进制形式
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) | 009 |
| \v | 垂直制表(VT) | 011 |
| ' | 单引号 | 039 |
| " | 双引号 | 034 |
| \ | 反斜杠 | 092 |
C语言中的整数(short,int,long)
int 称为整型,short 称为短整型,long 称为长整型。
int 一般占用 4 个字节(Byte)的内存,共计 32 位(Bit)。如果不考虑正负数,当所有的位都为 1 时它的值最大,为 232-1 = 4,294,967,295 ≈ 43亿,这是一个很大的数,实际开发中很少用到,而诸如 1、99、12098 等较小的数使用频率反而较高。
让整数占用更少的内存可以在 int 前边加 short ,让整数占用更多的内存可以在 int 前边加 long,例如:
short int a = 10;
short int b, c = 99;
long int m = 102023;
long int n, p = 562131;
这样 a、b、c 只占用 2 个字节的内存,而 m、n、p 可能会占用 8 个字节的内存。也可以将 int 省略,只写 short 和 long,如下所示:
short a = 10;
short b, c = 99;
long m = 102023;
long n, p = 562131;
这样的写法更加简洁,实际开发中常用。short 整型的长度
-
int 建议为一个机器字长。32 位环境下机器字长为 4 字节,64 位环境下机器字长为 8 字节。
-
short 的长度不能大于 int,long 的长度不能小于 int。
所占字节数关系为:
2 ≤ short ≤ int ≤ long
sizeof 操作符(获取某个数据类型的长度)
#include <stdio.h>
int main()
{
short a = 10;
int b = 100;
int short_length = sizeof a;
int int_length = sizeof(b);
int long_length = sizeof(long);
int char_length = sizeof(char);
printf("short=%d, int=%d, long=%d, char=%d\n", short_length, int_length, long_length, char_length);
return 0;
}在 32 位环境以及 Win64 环境下的运行结果为:
short=2, int=4, long=4, char=1不同整型的输出%hd %d %ld
-
%hd用来输出 short int 类型,hd 是 short decimal 的简写; -
%d用来输出 int 类型,d 是 decimal 的简写; -
%ld用来输出 long int 类型,ld 是 long decimal 的简写。#include <stdio.h>
int main()
{
short a = 10;
int b = 100;
long c = 9437;
printf("a=%hd, b=%d, c=%ld\n", a, b, c);
return 0;
}运行结果:
a=10, b=100, c=9437
C语言中的二进制数、八进制数和十六进制数
十进制数字不需要任何特殊的格式。但是,表示一个二进制、八进制或者十六进制数字就不一样了,为了和十进制数字区分开来,必须采用某种特殊的写法,具体来说,就是在数字前面加上特定的字符,也就是加前缀。
1) 二进制数
二进制由 0 和 1 两个数字组成,使用时必须以0b或0B(不区分大小写)开头,例如:
//合法的二进制
int a = 0b101; //换算成十进制为 5
int b = -0b110010; //换算成十进制为 -50
int c = 0B100001; //换算成十进制为 33
//非法的二进制
int m = 101010; //无前缀 0B,相当于十进制
int n = 0B410; //4不是有效的二进制数字读者请注意,标准的C语言并不支持上面的二进制写法,只是有些编译器自己进行了扩展,才支持二进制数字。换句话说,并不是所有的编译器都支持二进制数字,只有一部分编译器支持,并且跟编译器的版本有关系。
下面是实际测试的结果:
- Visual C++ 6.0 不支持。
- Visual Studio 2015 支持,但是 Visual Studio 2010 不支持;可以认为,高版本的 Visual Studio 支持二进制数字,低版本的 Visual Studio 不支持。
- GCC 4.8.2 支持,但是 GCC 3.4.5 不支持;可以认为,高版本的 GCC 支持二进制数字,低版本的 GCC 不支持。
- LLVM/Clang 支持(内嵌于 Mac OS 下的 Xcode 中)。
2)八进制
八进制由 0~7 八个数字组成,使用时必须以0开头(注意是数字 0,不是字母 o),例如
//合法的八进制数
int a = 015; //换算成十进制为 13
int b = -0101; //换算成十进制为 -65
int c = 0177777; //换算成十进制为 65535
//非法的八进制
int m = 256; //无前缀 0,相当于十进制
int n = 03A2; //A不是有效的八进制数字3) 十六进制
十六进制由数字 0~9、字母 A~F 或 a~f(不区分大小写)组成,使用时必须以0x或0X(不区分大小写)开头,例如:
//合法的十六进制
int a = 0X2A; //换算成十进制为 42
int b = -0XA0; //换算成十进制为 -160
int c = 0xffff; //换算成十进制为 65535
//非法的十六进制
int m = 5A; //没有前缀 0X,是一个无效数字
int n = 0X3H; //H不是有效的十六进制数字4) 十进制
十进制由 0~9 十个数字组成,没有任何前缀,和我们平时的书写格式一样。
二进制数、八进制数和十六进制数的输出
printf 函数输出二进制,通过转换函数可以将其它进制数字转换成二进制数字,并以字符串的形式存储,然后在 printf 函数中使用%s输出即可。
| short | int | long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
十六进制数字的表示用到了英文字母,有大小写之分,要在格式控制符中体现出来:
- %hx、%x 和 %lx 中的
x小写,表明以小写字母的形式输出十六进制数; - %hX、%X 和 %lX 中的
X大写,表明以大写字母的形式输出十六进制数。
八进制数字和十进制数字不区分大小写,所以格式控制符都用小写形式。
#include <stdio.h>
int main()
{
short a = 0b1010110; //二进制数字
int b = 02713; //八进制数字
long c = 0X1DAB83; //十六进制数字
printf("a=%ho, b=%o, c=%lo\n", a, b, c); //以八进制形似输出
printf("a=%hd, b=%d, c=%ld\n", a, b, c); //以十进制形式输出
printf("a=%hx, b=%x, c=%lx\n", a, b, c); //以十六进制形式输出(字母小写)
printf("a=%hX, b=%X, c=%lX\n", a, b, c); //以十六进制形式输出(字母大写)
return 0;
}
运行结果:
a=126, b=2713, c=7325603
a=86, b=1483, c=1944451
a=56, b=5cb, c=1dab83
a=56, b=5CB, c=1DAB83区分输出
区分不同进制数字的一个简单办法就是,在输出时带上特定的前缀。在格式控制符中加上#即可输出前缀,例如 %#x、%#o、%#lX、%#ho 等
#include <stdio.h>
int main()
{
short a = 0b1010110; //二进制数字
int b = 02713; //八进制数字
long c = 0X1DAB83; //十六进制数字
printf("a=%#ho, b=%#o, c=%#lo\n", a, b, c); //以八进制形似输出
printf("a=%hd, b=%d, c=%ld\n", a, b, c); //以十进制形式输出
printf("a=%#hx, b=%#x, c=%#lx\n", a, b, c); //以十六进制形式输出(字母小写)
printf("a=%#hX, b=%#X, c=%#lX\n", a, b, c); //以十六进制形式输出(字母大写)
return 0;
}
运行结果:
a=0126, b=02713, c=07325603
a=86, b=1483, c=1944451
a=0x56, b=0x5cb, c=0x1dab83
a=0X56, b=0X5CB, c=0X1DAB83C语言中的正负数及其输出
如果不带正负号,默认就是正数。
//负数
short a1 = -10;
short a2 = -0x2dc9; //十六进制
//正数
int b1 = +10;
int b2 = +0174; //八进制
int b3 = 22910;
//负数和正数相加
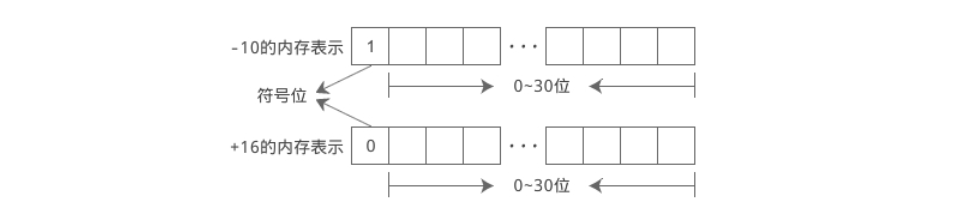
long c = (-9) + (+12);符号也是数字的一部分,以 int 为例,它占用 32 位的内存,0~30 位表示数值,31 位表示正负号。如下图所示:

C语言规定,在符号位中,用 0 表示正数,用 1 表示负数。例如 int 类型的 -10 和 +16 在内存中的表示如下:
如果不设置符号位,可以在数据类型前面加上 unsigned 关键字,例如
unsigned short a = 12;
unsigned int b = 1002;
unsigned long c = 9892320;short、int、long 中就没有符号位了,所有的位都用来表示数值,正数的取值范围更大了。使用了 unsigned 后只能表示正数,不能再表示负数了。
无符号数的输出
| unsigned short | unsigned int | unsigned long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hu | %u | %lu |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
- %d 以十进制形式输出有符号数;
- %u 以十进制形式输出无符号数;
- %o 以八进制形式输出无符号数;
- %x 以十六进制形式输出无符号数。
总结了不同类型的整数,以不同进制的形式输出时对应的格式控制符(--表示没有对应的格式控制符)。
| short | int | long | unsigned short | unsigned int | unsigned long | |
|---|---|---|---|---|---|---|
| 八进制 | -- | -- | -- | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld | %hu | %u | %lu |
| 十六进制 | -- | -- | -- | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
演示输出:
#include <stdio.h>
int main()
{
short a = 0100; //八进制
int b = -0x1; //十六进制
long c = 720; //十进制
unsigned short m = 0xffff; //十六进制
unsigned int n = 0x80000000; //十六进制
unsigned long p = 100; //十进制
//以无符号的形式输出有符号数
printf("a=%#ho, b=%#x, c=%ld\n", a, b, c);
//以有符号数的形式输出无符号类型(只能以十进制形式输出)
printf("m=%hd, n=%d, p=%ld\n", m, n, p);
return 0;
}
运行结果:
a=0100, b=0xffffffff, c=720
m=-1, n=-2147483648, p=100对于绝大多数初学者来说,b、m、n 的输出结果看起来非常奇怪,甚至不能理解。按照一般的推理,b、m、n 这三个整数在内存中的存储形式分别是:

C语言中的小数(float,double)
C语言中小数的指数形式为:
aEn 或 aen
小数的输出
小数也可以使用 printf 函数输出,包括十进制形式和指数形式,它们对应的格式控制符分别是:
-
%f 以十进制形式输出 float 类型;
-
%lf 以十进制形式输出 double 类型;
-
%e 以指数形式输出 float 类型,输出结果中的 e 小写;
-
%E 以指数形式输出 float 类型,输出结果中的 E 大写;
-
%le 以指数形式输出 double 类型,输出结果中的 e 小写;
-
%lE 以指数形式输出 double 类型,输出结果中的 E 大写。
#include <stdio.h>
#include <stdlib.h>
int main()
{
float a = 0.302;
float b = 128.101;
double c = 123;
float d = 112.64E3;
double e = 0.7623e-2;
float f = 1.23002398;
printf("a=%e \nb=%f \nc=%lf \nd=%lE \ne=%lf \nf=%f\n", a, b, c, d, e, f);return 0;}
运行结果:
a=3.020000e-01
b=128.100998
c=123.000000
d=1.126400E+05
e=0.007623
f=1.230024
对代码的说明:
-
%f 和 %lf 默认保留六位小数,不足六位以 0 补齐,超过六位按四舍五入截断。
-
将整数赋值给 float 变量时会变成小数。
%g更加智能的输出方式
以最短的方式来输出小数,让输出结果更加简练。所谓最短,就是输出结果占用最少的字符。
#include <stdio.h>
#include <stdlib.h>
int main()
{
float a = 0.00001;
float b = 30000000;
float c = 12.84;
float d = 1.229338455;
printf("a=%g \nb=%g \nc=%g \nd=%g\n", a, b, c, d);
return 0;
}运行结果:
a=1e-05
b=3e+07
c=12.84
d=1.22934
注意:
- %g 默认最多保留六位 有效数字,包括整数部分和小数 部分;%f 和 %e 默认保留六位小数,只包括小数部分。
- %g 不会在最后强加 0 来凑够有效数字的位数,而 %f 和 %e 会在最后强加 0 来凑够小数部分的位数。
数字的后缀
注意:默认的类型
一个数字,是有默认类型的:对于整数,默认是 int 类型;对于小数,默认是 double 类型。
long a = 100;
int b = 294;
float x = 52.55;
double y = 18.6;100 和 294 这两个数字默认都是 int 类型的,将 100 赋值给 a,必须先从 int 类型转换为 long 类型,而将 294 赋值给 b 就不用转换了。
52.55 和 18.6 这两个数字默认都是 double 类型的,将 52.55 赋值给 x,必须先从 double 类型转换为 float 类型,而将 18.6 赋值给 y 就不用转换了。
如果不想让数字使用默认的类型,那么可以给数字加上后缀,手动指明类型:
-
在整数后面紧跟 l 或者 L(不区分大小写)表明该数字是 long 类型;
-
在小数后面紧跟 f 或者 F(不区分大小写)表明该数字是 float 类型。
long a = 100l;
int b = 294;
short c = 32L;float x = 52.55f;
double y = 18.6F;
float z = 0.02;
加上后缀,虽然数字的类型变了,但这并不意味着该数字只能赋值给指定的类型,它仍然能够赋值给其他的类型,只要进行了一下类型转换就可以了。
小数和整数相互赋值
在C语言中,整数和小数之间可以相互赋值:
- 将一个整数赋值给小数类型,在小数点后面加 0 就可以,加几个都无所谓。
- 将一个小数赋值给整数类型,就得把小数部分丢掉,只能取整数部分,这会改变数字本来的值。注意是直接丢掉小数部分,而不是按照四舍五入取近似值。
请看下面的代码:
#include <stdio.h>
int main(){
float f = 251;
int w = 19.427;
int x = 92.78;
int y = 0.52;
int z = -87.27;
printf("f = %f, w = %d, x = %d, y = %d, z = %d\n", f, w, x, y, z);
return 0;
}运行结果:
f = 251.000000, w = 19, x = 92, y = 0, z = -87
由于将小数赋值给整数类型时会"失真",所以编译器一般会给出警告,让大家引起注意。
字符类型 char
字符类型由单引号' '包围,字符串由双引号" "包围。
#include <stdio.h>
int main() {
char a = '1';
char b = '$';
char c = 'X';
char d = ' ';
//使用 putchar 输出
putchar(a); putchar(d);
putchar(b); putchar(d);
putchar(c); putchar('\n');
//使用 printf 输出
printf("%c %c %c\n", a, b, c);
return 0;
}运行结果:
1 $ X
1 $ X
putchar 函数每次只能输出一个字符,输出多个字符需要调用多次。
字符串
两种表示形式:
char str1[] = "http://c.biancheng.net";
char *str2 = "C语言中文网";str1 和 str2 是字符串的名字,后边的[ ]和前边的*是固定的写法。初学者暂时可以认为这两种存储方式是等价的,它们都可以通过专用的 puts 函数和通用的 printf 函数输出。
完整的字符串演示:
#include <stdio.h>
int main()
{
char web_url[] = "http://c.biancheng.net";
char *web_name = "C语言中文网";
puts(web_url);
puts(web_name);
printf("%s\n%s\n", web_url, web_name);
return 0;
}标识符定义(变量)
在某个编译器中规定标识符前128位有效,当两个标识符前128位相同时,则被认为是同一个标识符。
在标识符中,大小写是有区别的,例如 BOOK 和 book 是两个不同的标识符。
以下是非法的标识符:0
- 3s 不能以数字开头
- sT 出现非法字符
- -3x 不能以减号(-)开头
- bowy-1 出现非法字符减号(-)
关键字(Keywords)是由C语言规定的具有特定意义的字符串,通常也称为保留字,例如 int、char、long、float、unsigned 等。我们定义的标识符不能与关键字相同,否则会出现错误。
注释
C语言支持单行注释和多行注释:
- 单行注释以
//开头,直到本行末尾(不能换行); - 多行注释以
/*开头,以*/结尾,注释内容可以有一行或多行。
加减乘除运算的简写
int a = 10, b = 20;
a += 10; //相当于 a = a + 10;
a *= (b-10); //相当于 a = a * (b-10);
a -= (a+20); //相当于 a = a - (a+20);自增(++)和自减(--)
自增自减的结果必须得有变量来接收,所以自增自减只能针对变量,不能针对数字,例如10++就是错误的。
++ 在变量前面和后面是有区别的:
- ++ 在前面叫做前自增(例如 ++a)。前自增先进行自增运算,再进行其他操作。
- ++ 在后面叫做后自增(例如 a++)。后自增先进行其他操作,再进行自增运算。
下面分析输出结果a1、b1、c1、d1:
int a = 10, b = 20, c = 30, d = 40;
int a1 = ++a, b1 = b++, c1 = --c, d1 = d--;
a=11, a1=11
b=21, b1=20
c=29, c1=29
d=39, d1=40-
对于
a1=++a,先执行 ++a,结果为 11,再将 11 赋值给 a1,所以 a1 的最终值为11。而 a 经过自增,最终的值也为 11。 -
对于
b1=b++,b 的值并不会立马加 1,而是先把 b 原来的值交给 b1,然后再加 1。b 原来的值为 20,所以 b1 的值也就为 20。而 b 经过自增,最终值为 21。 -
对于
c1=--c,先执行 --c,结果为 29,再将 29 赋值给c1,所以 c1 的最终值为 29。而 c 经过自减,最终的值也为 29。 -
对于
d1=d--,d 的值并不会立马减 1,而是先把 d 原来的值交给 d1,然后再减 1。d 原来的值为 40,所以 d1 的值也就为 40。而 d 经过自减,最终值为 39。
可以看出:a1=++a;会先进行自增操作,再进行赋值操作;而b1=b++;会先进行赋值操作,再进行自增操作。c1=--c;和d1=d--;也是如此。
自动类型转换
转换的规则如下:
- 转换按数据长度增加的方向进行,以保证数值不失真,或者精度不降低。例如,int 和 long 参与运算时,先把 int 类型的数据转成 long 类型后再进行运算。
- 所有的浮点运算都是以双精度进行的,即使运算中只有 float 类型,也要先转换为 double 类型,才能进行运算。
- char 和 short 参与运算时,必须先转换成 int 类型。
强制类型转换
强制类型转换的格式为:
(type_name) expression
(float) a; //将变量 a 转换为 float 类型
(int)(x+y); //把表达式 x+y 的结果转换为 int 整型
(float) 100; //将数值 100(默认为int类型)转换为 float 类型下面是一个需要强制类型转换的经典例子:
#include <stdio.h>
int main(){
int sum = 103; //总数
int count = 7; //数目
double average; //平均数
average = (double) sum / count;
printf("Average is %lf!\n", average);
return 0;
}
运行结果:
Average is 14.714286!( )的优先级高于/,对于表达式(double) sum / count,会先执行(double) sum,将 sum 转换为 double 类型,然后再进行除法运算,这样运算结果也是 double 类型,能够保留小数部分。注意不要写作(double) (sum / count),这样写运算结果将是 3.000000,仍然不能保留小数部分。
类型转换只是临时性的
无论是自动类型转换还是强制类型转换,都只是为了本次运算而进行的临时性转换,转换的结果也会保存到临时的内存空间,不会改变数据本来的类型或者值。请看下面的例子:
#include <stdio.h>
int main(){
double total = 400.8; //总价
int count = 5; //数目
double unit; //单价
int total_int = (int)total;
unit = total / count;
printf("total=%lf, total_int=%d, unit=%lf\n", total, total_int, unit);
return 0;
}
运行结果:
total=400.800000, total_int=400, unit=80.160000注意看第 6 行代码,total 变量被转换成了 int 类型才赋值给 total_int 变量,而这种转换并未影响 total 变量本身的类型和值。如果 total 的值变了,那么 total 的输出结果将变为 400.000000;如果 total 的类型变了,那么 unit 的输出结果将变为 80.000000。
printf() 的高级用法
%-9d中,d表示以十进制输出,9表示最少占9个字符的宽度,宽度不足以空格补齐,-表示左对齐。综合起来,%-9d表示以十进制输出,左对齐,宽度最小为9个字符。大家可以亲自试试%9d的输出效果。
printf("%-9d %-9d %-9d %-9d\n", d1, d2, d3, d4);
20 345 700 22printf() 的延迟5秒输出
printf() 执行结束以后数据并没有直接输出到显示器上,而是放入了缓冲区,直到遇见换行符\n才将缓冲区中的数据输出到显示器上。
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("C语言中文网\n");
sleep(5); //程序暂停5秒钟
printf("http://c.biancheng.net\n");
return 0;
}C语言scanf:读取从键盘输入的数据
在C语言中,有多个函数可以从键盘获得用户输入:
- scanf():和 printf() 类似,scanf() 可以输入多种类型的数据。
- getchar()、getche()、getch():这三个函数都用于输入单个字符。
- gets():获取一行数据,并作为字符串处理。
scanf()函数
scanf 是 scan format 的缩写,意思是格式化扫描,也就是从键盘获得用户输入,和 printf 的功能正好相反。
scanf 的变量前要带一个&符号。&称为取地址符,也就是获取变量在内存中的地址。
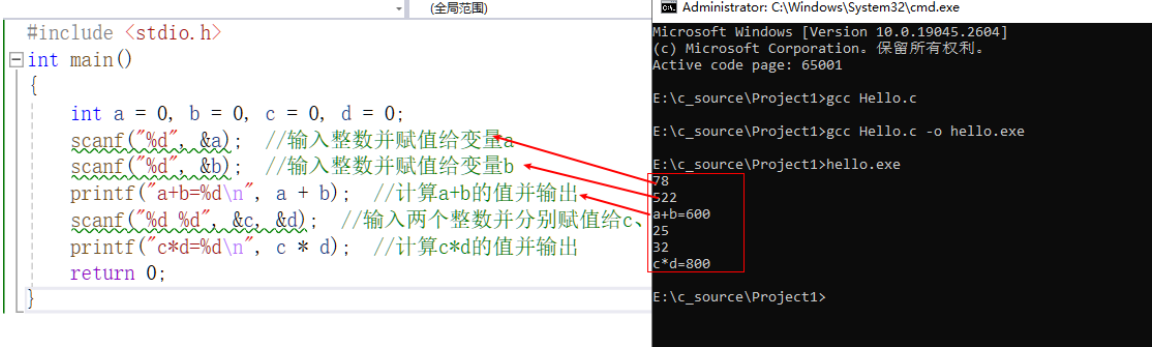
#include <stdio.h>
int main()
{
int a = 0, b = 0, c = 0, d = 0;
scanf("%d", &a); //输入整数并赋值给变量a
scanf("%d", &b); //输入整数并赋值给变量b
printf("a+b=%d\n", a+b); //计算a+b的值并输出
scanf("%d %d", &c, &d); //输入两个整数并分别赋值给c、d
printf("c*d=%d\n", c*d); //计算c*d的值并输出
return 0;
}
读取字符串的说明
char str1[] = "http://c.biancheng.net";
char *str2 = "C语言中文网";第一种形式的字符串所在的内存既有读取权限又有写入权限,第二种形式的字符串所在的内存只有读取权限,没有写入权限。printf()、puts() 等字符串输出函数只要求字符串有读取权限,而 scanf()、gets() 等字符串输入函数要求字符串有写入权限,所以,第一种形式的字符串既可以用于输出函数又可以用于输入函数,而第二种形式的字符串只能用于输出函数。
在[ ]里面要指明字符串的最大长度,如果不指明,也可以根据=后面的字符串来自动推算,此处,就是根据"http://c.biancheng.net"的长度来推算的。
scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串,请看下面的例子:
#include <stdio.h>
int main()
{
char author[30], lang[30], url[30];
scanf("%s %s", author, lang);
printf("author:%s \nlang: %s\n", author, lang);
scanf("%s", url);
printf("url: %s\n", url);
return 0;
}运行示例:
YanChangSheng C-Language↙
author:YanChangSheng
lang: C-Language
http://c.biancheng.net http://biancheng.net↙
url: http://c.biancheng.net输入字符和字符串(所有函数大汇总)
| 函数 | 缓冲区 | 头文件 | 回显 | 适用平台 |
|---|---|---|---|---|
| getchar() | 有 | stdio.h | 有 | Windows、Linux、Mac OS 等所有平台 |
| getche() | 无 | conio.h | 有 | Windows |
| getch() | 无 | conio.h | 无 | Windows |
C语言中常用的从控制台读取数据的函数有五个,它们分别是 scanf()、getchar()、getche()、getch() 和 gets()。其中 scanf()、getchar()、gets() 是标准函数,适用于所有平台;getche() 和 getch() 不是标准函数,只能用于 Windows。
scanf() 是通用的输入函数,它可以读取多种类型的数据。
getchar()、getche() 和 getch() 是专用的字符输入函数,它们在缓冲区和回显方面与 scanf() 有着不同的特性,是 scanf() 不能替代的。
gets() 是专用的字符串输入函数,与 scanf() 相比,gets() 的主要优势是可以读取含有空格的字符串。
scanf() 可以一次性读取多份类型相同或者不同的数据,getchar()、getche()、getch() 和 gets() 每次只能读取一份特定类型的数据,不能一次性读取多份数据。
定义常量
在 C 中,有两种简单的定义常量的方式:
-
使用 #define 预处理器: #define 可以在程序中定义一个常量,它在编译时会被替换为其对应的值。
-
使用 const 关键字:const 关键字用于声明一个只读变量,即该变量的值不能在程序运行时修改。
#define 常量名 常量值
#include <stdio.h>
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'int main()
{int area; area = LENGTH * WIDTH; printf("value of area : %d", area); printf("%c", NEWLINE); return 0;}
const 关键字
const 数据类型 常量名 = 常量值;下面的代码定义了一个名为MAX_VALUE的常量:
const int MAX_VALUE = 100;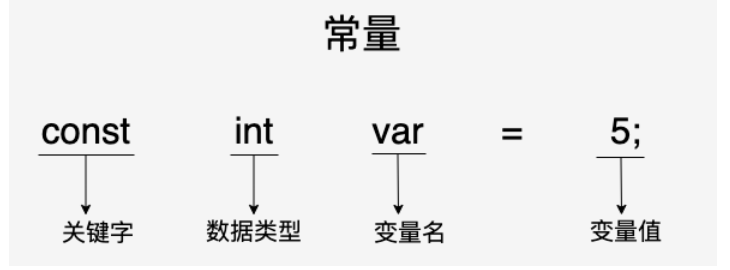
C 存储类
- auto
- register
- static
- extern
1 auto 存储类是所有局部变量默认的存储类。
定义在函数中的变量默认为 auto 存储类,这意味着它们在函数开始时被创建,在函数结束时被销毁。
{
int mount;
auto int month;
}2 register 存储类
register 存储类定义存储在寄存器,所以变量的访问速度更快,但是它不能直接取地址,因为它不是存储在 RAM 中的。在需要频繁访问的变量上使用 register 存储类可以提高程序的运行速度。
{
register int miles;
}3 static 存储类
使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
#include <stdio.h>
/* 函数声明 */
void func1(void);
static int count=10; /* 全局变量 - static 是默认的 */
int main()
{
while (count--) {
func1();
}
return 0;
}
void func1(void)
{
/* 'thingy' 是 'func1' 的局部变量 - 只初始化一次
* 每次调用函数 'func1' 'thingy' 值不会被重置。
*/
static int thingy=5;
thingy++;
printf(" thingy 为 %d , count 为 %d\n", thingy, count);
}4 extern 存储类
extern 存储类用于定义在其他文件中声明的全局变量或函数。当使用 extern 关键字时,不会为变量分配任何存储空间,而只是指示编译器该变量在其他文件中定义。
extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。当您使用 extern 时,对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。
extern 修饰符通常用于当有两个或多个文件共享相同的全局变量或函数的时候。
第一个文件:main.c
#include <stdio.h>
int count ;
extern void write_extern();
int main()
{
count = 5;
write_extern();
}第二个文件:support.c
#include <stdio.h>
extern int count;
void write_extern(void)
{
printf("count is %d\n", count);
}C语言if else语句
if(判断条件1){
语句块1
} else if(判断条件2){
语句块2
}else{
语句块n
}例如,使用多个 if else 语句判断输入的字符的类别:
#include <stdio.h>
int main(){
char c;
printf("Input a character:");
c=getchar();
if(c<32)
printf("This is a control character\n");
else if(c>='0'&&c<='9')
printf("This is a digit\n");
else if(c>='A'&&c<='Z')
printf("This is a capital letter\n");
else if(c>='a'&&c<='z')
printf("This is a small letter\n");
else
printf("This is an other character\n");
return 0;
}C语言关系运算符
if 的判断条件中使用了<=、>、!=等符号
C语言提供了以下关系运算符:
| 关系运算符 | 含 义 | 数学中的表示 |
|---|---|---|
| < | 小于 | < |
| <= | 小于或等于 | ≤ |
| > | 大于 | > |
| >= | 大于或等于 | ≥ |
| == | 等于 | = |
| != | 不等于 | ≠ |
**关系运算符的优先级低于算术运算符,高于赋值运算符。**在六个关系运算符中,<、<=、>、>=的优先级相同,高于==和!=,==和!=的优先级相同。
关系运算符的运算结果只有 0 或 1。当条件成立时结果为 1,条件不成立结果为 0。例如:
-
5>0 成立,其值为 1;
-
34-12>100 不成立,其值为 0;
-
(a=3)>(b=5) 由于3>5不成立,故其值为 0。
#include <stdio.h>
int main(){
char c='k';
int i=1, j=2, k=3;
float x=3e+5, y=0.85;
int result_1 = 'a'+5<c, result_2 = x-5.25<=x+y;
printf( "%d, %d\n", result_1, -i-2j>=k+1 );
printf( "%d, %d\n", 1<j<5, result_2 );
printf( "%d, %d\n", i+j+k==-2j, k==j==i+5 );
return 0;
}运行结果:
1, 0
1, 1
0, 0
对于含多个关系运算符 的表达式,如 kji+5,根据运算符的左结合性 ,先计算kj,该式不成立,其值为0,再计算0i+5,也不成立,故表达式值为0。
逻辑运算符(&&)(||)
逻辑运算的结果也只有"真"和"假","真"对应的值为 1,"假"对应的值为 0。
| 运算符 | 说明 | 结合性 | 举例 |
|---|---|---|---|
| && | 与运算,双目,对应数学中的"且" | 左结合 | 1&&0、(9>3)&&(b>a) |
| || | 或运算,双目,对应数学中的"或" | 左结合 | 1||0、(9>3)||(b>a) |
| ! | 非运算,单目,对应数学中的"非" | 右结合 | !a、!(2<5) |
1) 与运算(&&)
参与运算的两个表达式都为真时,结果才为真,否则为假。例如:
5&&05为真,0为假,相与的结果为假,也就是 0。
(5>0) && (4>2)5>0 的结果是1,为真,4>2结果是1,也为真,所以相与的结果为真,也就是1。
2) 或运算(||)
参与运算的两个表达式只要有一个为真,结果就为真;两个表达式都为假时结果才为假。例如:
10 || 010为真,0为假,相或的结果为真,也就是 1。
(5>0) || (5>8)5>0 的结果是1,为真,5>8 的结果是0,为假,所以相或的结果为真,也就是1。
3) 非运算(!)
参与运算的表达式为真时,结果为假;参与运算的表达式为假时,结果为真。例如:
!00 为假,非运算的结果为真,也就是 1。
!(5>0)5>0 的结果是1,为真,非运算的结果为假,也就是 0。
优先级
逻辑运算符和其它运算符优先级从低到高依次为:
赋值运算符(=) < &&和|| < 关系运算符 < 算术运算符 < 非(!)&& 和 || 低于关系运算符,! 高于算术运算符。
按照运算符的优先顺序可以得出:
- a>b && c>d 等价于 (a>b)&&(c>d)
- !b==c||d<a 等价于 ((!b)==c)||(d<a)
- a+b>c&&x+y<b 等价于 ((a+b)>c)&&((x+y)<b)
C语言switch case语句
case 后面必须是一个整数,或者是结果为整数的表达式,但不能包含任何变量。
break 是C语言中的一个关键字,专门用于跳出 switch 语句。所谓"跳出",是指一旦遇到 break,就不再执行 switch 中的任何语句,包括当前分支中的语句和其他分支中的语句;也就是说,整个 switch 执行结束了,接着会执行整个 switch 后面的代码。****
基本格式如下:
switch(表达式){
case 整型数值1: 语句 1;
case 整型数值2: 语句 2;
......
case 整型数值n: 语句 n;
default: 语句 n+1;
}下面的代码:
#include <stdio.h>
int main(){
int a;
printf("Input integer number:");
scanf("%d",&a);
switch(a){
case 1: printf("Monday\n"); break;
case 2: printf("Tuesday\n"); break;
case 3: printf("Wednesday\n"); break;
case 4: printf("Thursday\n"); break;
case 5: printf("Friday\n"); break;
case 6: printf("Saturday\n"); break;
case 7: printf("Sunday\n"); break;
default:printf("error\n"); break;
}
return 0;
}
运行结果:
Input integer number:4↙
Thursday三目运算符
条件运算符的优先级低于关系运算符和算术运算符,但高于赋值符。
其求值规则为:如果表达式1的值为真,则以表达式2 的值作为整个条件表达式的值,否则以表达式3的值作为整个条件表达式的值。
表达式1 ? 表达式2 : 表达式3
max = (a>b) ? a : b;
该语句的语义是:如a>b为真,则把a赋予max,否则把b 赋予max。条件运算符?和:是一对运算符,不能分开单独使用。
条件运算符的结合方向是自右至左。例如:
a>b ? a : c>d ? c : d;应理解为:
a>b ? a : ( c>d ? c : d );C语言while循环和do while循环
先计算"表达式"的值,当值为真(非0)时, 执行"语句块";执行完"语句块",再次计算表达式的值,如果为真,继续执行"语句块"......这个过程会一直重复,直到表达式的值为假(0),就退出循环,执行 while 后面的代码。
while循环的一般形式为:
while(表达式){
语句块
}用计算1加到100的值
#include <stdio.h>
int main(){
int i=1, sum=0;
while(i<=100){
sum+=i;
i++;
}
printf("%d\n",sum);
return 0;
}while 循环会一直执行下去,永不结束,成为"死循环"。例如:1就是true
#include <stdio.h>
int main(){
while(1){
printf("1");
}
return 0;
}循环条件不成立的话,while 循环就一次也不会执行。例如:
#include <stdio.h>
int main(){
while(0){
printf("1");
}
return 0;
}
运行程序,什么也不会输出。do-while循环
do-while循环与while循环的不同在于:它会先执行"语句块",然后再判断表达式是否为真,如果为真则继续循环;如果为假,则终止循环。因此,do-while 循环至少要执行一次"语句块"。
do-while循环的一般形式为:
do{
语句块
}while(表达式);用do-while计算1加到100的值:
#include <stdio.h>
int main(){
int i, sum=0;
i = 1; //语句①
while(i<=100 /*语句②*/ ){
sum+=i;
i++; //语句③
}
printf("%d\n",sum);
return 0;
}C语言for循环(for语句)
for 循环的一般形式为:
for(表达式1; 表达式2; 表达式3){
语句块
}
#include <stdio.h>
int main(){
int i, sum=0;
for(i=1/*语句①*/; i<=100/*语句②*/; i++/*语句③*/){
sum+=i;
}
printf("%d\n",sum);
return 0;
}省略了"表达式2(循环条件)",如果不做其它处理就会成为死循环。例如:
for(i=1; ; i++) sum=sum+i;简单表达式也可以是逗号表达式。
for( sum=0,i=1; i<=100; i++ ) sum=sum+i;
for( i=0,j=100; i<=100; i++,j-- ) k=i+j;for循环的关系表达式或逻辑表达式,可是数值或字符,只要其值非零,就执行循环体。
for( i=0; (c=getchar())!='\n'; i+=c );
或者
for( ; (c=getchar())!='\n' ; )
printf("%c",c);C语言break和continue用法(跳出循环)
当 break 关键字用于 while、for 循环时,会终止循环而执行整个循环语句后面的代码。break 关键字通常和 if 语句一起使用,即满足条件时便跳出循环。
#include <stdio.h>
int main(){
int i=1, j;
while(1){ // 外层循环
j=1;
while(1){ // 内层循环
printf("%-4d", i*j);
j++;
if(j>4) break; //跳出内层循环
}
printf("\n");
i++;
if(i>4) break; // 跳出外层循环
}
return 0;
}当 j>4 成立时,执行break;,跳出内层循环;外层循环依然执行,直到 i>4 成立,跳出外层循环。内层循环共执行了4次,外层循环共执行了1次。
continue语句
continue 语句的作用是跳过当次循环,进入下次循环。
#include <stdio.h>
int main(){
char c = 0;
while(c!='\n'){ //回车键结束循环
c=getchar();
if(c=='4' || c=='5'){ //按下的是数字键4或5
continue; //跳过当次循环,进入下次循环
}
putchar(c);
}
return 0;
}循环嵌套输出九九乘法表
#include <stdio.h>
int main(){
int i, j;
for(i=1; i<=9; i++){ //外层for循环
for(j=1; j<=i; j++){ //内层for循环
printf("%d*%d=%-2d ", i, j, i*j);
}
printf("\n");
}
return 0;
}运行结果:
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81-
当 i=1 时,内层 for 的结束条件为 j<=1,只能循环一次,输出第一行。
-
当 i=2 时,内层 for 的结束条件是 j<=2,循环两次,输出第二行。
-
当 i=3 时,内层 for 的结束条件是 j<=3,循环三次,输出第三行。
-
当 i=4、5、6... 时,以此类推。
C语言数组
放入4个整数,就得分配4个int类型的内存空间:
int a[4];
float m[12]; //定义一个长度为 12 的浮点型数组
char ch[9]; //定义一个长度为 9 的字符型数组数组中的每个元素都有一个序号,这个序号从0开始,而不是从我们熟悉的1开始,称为下标(Index)。使用数组元素时,指明下标即可,形式为:
arrayName[index]arrayName 为数组名称,index 为下标。例如,a0 表示第0个元素,a3 表示第3个元素。
a[0]=20;
a[1]=345;更改上面的代码,让用户输入 10 个数字并放入数组中:
scanf() 读取数据时需要一个地址(地址用来指明数据的存储位置),而 numsi 表示一个具体的数组元素,所以我们要在前边加 & 来获取地址。
#include <stdio.h>
int main(){
int nums[10];
int i;
//从控制台读取用户输入
for(i=0; i<10; i++){
scanf("%d", &nums[i]); //注意取地址符 &,不要遗忘哦
}
//依次输出数组元素
for(i=0; i<10; i++){
printf("%d ", nums[i]);
}
return 0;
}
运行结果:
22 18 928 5 4 82 30 10 666 888↙
22 18 928 5 4 82 30 10 666 888↙数组的初始化
定义数组的同时赋值,例如:
int a[4] = {20, 345, 700, 22};对于数组的初始化需要注意以下几点:
-
可以只给部分元素赋值。当
{ }中值的个数少于元素个数时,只给前面部分元素赋值。例如:int a[10]={12, 19, 22 , 993, 344};
表示只给 a0~a4 5个元素赋值,而后面 5 个元素自动初始化为 0。
当赋值的元素少于数组总体元素的时候,剩余的元素自动初始化为 0:
- 对于short、int、long,就是整数 0;
- 对于char,就是字符 '\0';
- 对于float、double,就是小数 0.0。
通过下面的形式将数组的所有元素初始化为 0:
int nums[10] = {0};
char str[10] = {0};
float scores[10] = {0.0};
int a[] = {1, 2, 3, 4, 5};等价于
int a[5] = {1, 2, 3, 4, 5};二维数组的定义
二维数组定义的一般形式是:
dataType arrayName[length1][length2];
int a[3][4];【实例1】一个学习小组有 5 个人,每个人有 3 门课程的考试成绩,求该小组各科的平均分和总平均分。
| -- | Math | C | English |
|---|---|---|---|
| 张涛 | 80 | 75 | 92 |
| 王正华 | 61 | 65 | 71 |
| 李丽丽 | 59 | 63 | 70 |
| 赵圈圈 | 85 | 87 | 90 |
| 周梦真 | 76 | 77 | 85 |
对于该题目,可以定义一个二维数组 a53 存放 5 个人 3 门课的成绩,定义一个一维数组 v3 存放各科平均分,再定义一个变量 average 存放总平均分。最终编程如下:
#include <stdio.h>
int main(){
int i, j; //二维数组下标
int sum = 0; //当前科目的总成绩
int average; //总平均分
int v[3]; //各科平均分
int a[5][3]; //用来保存每个同学各科成绩的二维数组
printf("Input score:\n");
for(i=0; i<3; i++){
for(j=0; j<5; j++){
scanf("%d", &a[j][i]); //输入每个同学的各科成绩
sum += a[j][i]; //计算当前科目的总成绩
}
v[i]=sum/5; // 当前科目的平均分
sum=0;
}
average = (v[0] + v[1] + v[2]) / 3;
printf("Math: %d\nC Languag: %d\nEnglish: %d\n", v[0], v[1], v[2]);
printf("Total: %d\n", average);
return 0;
}运行结果:
Input score:
80 61 59 85 76 75 65 63 87 77 92 71 70 90 85↙
Math: 72
C Languag: 73
English: 81
Total: 75
程序使用了一个嵌套循环来读取所有学生所有科目的成绩。在内层循环中依次读入某一门课程的各个学生的成绩,并把这些成绩累加起来,退出内层循环(进入外层循环)后再把该累加成绩除以 5 送入 vi 中,这就是该门课程的平均分。外层循环共循环三次,分别求出三门课各自的平均成绩并存放在数组 v 中。所有循环结束后,把 v0、v1、v2 相加除以 3 就可以得到总平均分。
二维数组的初始化(赋值)
对于数组 a53,按行分段赋值应该写作:
int a[5][3]={ {80,75,92}, {61,65,71}, {59,63,70}, {85,87,90}, {76,77,85} };按行连续赋值应该写作:
int a[5][3]={80, 75, 92, 61, 65, 71, 59, 63, 70, 85, 87, 90, 76, 77, 85};求各科的平均分和总平均分,,本例要求在初始化数组的时候直接给出成绩:
#include <stdio.h>
int main(){
int i, j; //二维数组下标
int sum = 0; //当前科目的总成绩
int average; //总平均分
int v[3]; //各科平均分
int a[5][3] = {{80,75,92}, {61,65,71}, {59,63,70}, {85,87,90}, {76,77,85}};
for(i=0; i<3; i++){
for(j=0; j<5; j++){
sum += a[j][i]; //计算当前科目的总成绩
}
v[i] = sum / 5; // 当前科目的平均分
sum = 0;
}
average = (v[0] + v[1] + v[2]) / 3;
printf("Math: %d\nC Languag: %d\nEnglish: %d\n", v[0], v[1], v[2]);
printf("Total: %d\n", average);
return 0;
}分解成一维数组:
二维数组a[3][4]可分解为三个一维数组,它们的数组名分别为 a0、a1、a2。
这三个一维数组可以直接拿来使用。这三个一维数组都有 4 个元素,比如,一维数组 a[0] 的元素为 a[0][0]、a[0][1]、a[0][2]、a[0][3]。无序数组的查询
所谓无序数组,就是数组元素的排列没有规律。无序数组元素查询的思路也很简单,就是用循环遍历数组中的每个元素,把要查询的值挨个比较一遍。请看下面的代码:
#include <stdio.h>
int main(){
int nums[10] = {1, 10, 6, 296, 177, 23, 0, 100, 34, 999};
int i, num, thisindex = -1;
printf("Input an integer: ");
scanf("%d", &num);
for(i=0; i<10; i++){
if(nums[i] == num){
thisindex = i;
break;
}
}
if(thisindex < 0){
printf("%d isn't in the array.\n", num);
}else{
printf("%d is in the array, it's index is %d.\n", num, thisindex);
}
return 0;
}运行结果:
Input an integer: 100↙
100 is in the array, it's index is 7.对有序数组的查询
查询有序数组只需要遍历其中一部分元素。例如有一个长度为 10 的整型数组,它所包含的元素按照从小到大的顺序(升序)排列,假设比较到第 4 个元素时发现它的值大于输入的数字,那么剩下的 5 个元素就没必要再比较了,肯定也大于输入的数字,这样就减少了循环的次数,提高了执行效率。
#include <stdio.h>
int main(){
int nums[10] = {0, 1, 6, 10, 23, 34, 100, 177, 296, 999};
int i, num, thisindex = -1;
printf("Input an integer: ");
scanf("%d", &num);
for(i=0; i<10; i++){
if(nums[i] == num){
thisindex = i;
break;
}else if(nums[i] > num){
break;
}
}
if(thisindex < 0){
printf("%d isn't in the array.\n", num);
}else{
printf("%d is in the array, it's index is %d.\n", num, thisindex);
}
return 0;
}只增加了一个判断语句,也就是 12~14 行。因为数组元素是升序排列的,所以当 numsi > num 时,i 后边的元素也都大于 num 了,num 肯定不在数组中了,就没有必要再继续比较了,终止循环即可。
字符串长度
用法为:
length strlen(strname);length 是使用 strlen() 后得到的字符串长度,是一个整数。
#include <stdio.h>
#include <string.h> //记得引入该头文件
int main(){
char str[] = "http://c.biancheng.net/c/";
long len = strlen(str);
printf("The lenth of the string is %ld.\n", len);
return 0;
}
运行结果:C语言字符串的输入和输出
输出
在C语言中,有两个函数可以在控制台(显示器)上输出字符串,它们分别是:
- puts():输出字符串并自动换行,该函数只能输出字符串。
- printf():通过格式控制符
%s输出字符串,不能自动换行。除了字符串,printf() 还能输出其他类型的数据。
注意,输出字符串时只需要给出名字,不能带后边的[ ]
#include <stdio.h>
int main(){
char str[] = "http://c.biancheng.net";
printf("%s\n", str); //通过字符串名字输出
printf("%s\n", "http://c.biancheng.net"); //直接输出
puts(str); //通过字符串名字输出
puts("http://c.biancheng.net"); //直接输出
return 0;
}字符串的输入
在C语言中,有两个函数可以让用户从键盘上输入字符串,它们分别是:
- scanf():通过格式控制符
%s输入字符串。除了字符串,scanf() 还能输入其他类型的数据。 - gets():直接输入字符串,并且只能输入字符串。
scanf() 和 gets() 是有区别的:
-
scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串。
-
gets() 认为空格也是字符串的一部分,只有遇到回车键时才认为字符串输入结束,所以,不管输入了多少个空格,只要不按下回车键,对 gets() 来说就是一个完整的字符串。换句话说,gets() 用来读取一整行字符串。
#include <stdio.h>
int main(){
char str1[30] = {0};
char str2[30] = {0};
char str3[30] = {0};//gets() 用法 printf("Input a string: "); gets(str1); //scanf() 用法 printf("Input a string: "); scanf("%s", str2); scanf("%s", str3); printf("\nstr1: %s\n", str1); printf("str2: %s\n", str2); printf("str3: %s\n", str3); return 0;}
运行结果:
Input a string: C C++ Java Python↙
Input a string: PHP JavaScript↙
str1: C C++ Java Python
str2: PHP
str3: JavaScriptC语言字符串处理函数
符串处理函数,可以对字符串进行输入、输出、合并、修改、比较、转换、复制、搜索等
用于输入输出的字符串函数,例如printf、puts、scanf、gets等,使用时要包含头文件stdio.h,而使用其它字符串函数要包含头文件string.h。
字符串连接函数 strcat()
trcat 是 string catenate 的缩写,意思是把两个字符串拼接在一起,语法格式为:
strcat(arrayName1, arrayName2);strcat() 将把 arrayName2 连接到 arrayName1 后面,并删除原来 arrayName1 最后的结束标志'\0'。这意味着,arrayName1 必须足够长,要能够同时容纳 arrayName1 和 arrayName2,否则会越界(超出范围)。
简单的演示:
#include <stdio.h>
#include <string.h>
int main(){
char str1[100]="The URL is ";
char str2[60];
printf("Input a URL: ");
gets(str2);
strcat(str1, str2);
puts(str1);
return 0;
}运行结果:
Input a URL: http://c.biancheng.net/cpp/u/jiaocheng/↙
The URL is http://c.biancheng.net/cpp/u/jiaocheng/
字符串复制函数 strcpy()
strcpy 是 string copy 的缩写,意思是字符串复制,也即将字符串从一个地方复制到另外一个地方,语法格式为:
strcpy(arrayName1, arrayName2);strcpy() 会把 arrayName2 中的字符串拷贝到 arrayName1 中,字符串结束标志'\0'也一同拷贝。请看下面的例子:
#include <stdio.h>
#include <string.h>
int main(){
char str1[50] = "《C语言变怪兽》";
char str2[50] = "http://c.biancheng.net/cpp/u/jiaocheng/";
strcpy(str1, str2);
printf("str1: %s\n", str1);
return 0;
}运行结果:
str1: http://c.biancheng.net/cpp/u/jiaocheng/
将 str2 复制到 str1 后,str1 中原来的内容就被覆盖了。另外,strcpy() 要求 arrayName1 要有足够的长度,否则不能全部装入所拷贝的字符串。
字符串比较函数 strcmp()
strcmp 是 string compare 的缩写,意思是字符串比较,语法格式为
strcmp(arrayName1, arrayName2);arrayName1 和 arrayName2 是需要比较的两个字符串。
字符本身没有大小之分,strcmp() 以各个字符对应的 ASCII 码值进行比较。strcmp() 从两个字符串的第 0 个字符开始比较,如果它们相等,就继续比较下一个字符,直到遇见不同的字符,或者到字符串的末尾。
返回值:若 arrayName1 和 arrayName2 相同,则返回0;若 arrayName1 大于 arrayName2,则返回大于 0 的值;若 arrayName1 小于 arrayName2,则返回小于0 的值。
#include <stdio.h>
#include <string.h>
int main(){
char a[] = "aBcDeF";
char b[] = "AbCdEf";
char c[] = "aacdef";
char d[] = "aBcDeF";
printf("a VS b: %d\n", strcmp(a, b));
printf("a VS c: %d\n", strcmp(a, c));
printf("a VS d: %d\n", strcmp(a, d));
return 0;
}运行结果:
a VS b: 32
a VS c: -31
a VS d: 0
C语言对数组元素进行排序(冒泡排序法)
以从小到大排序为例,冒泡排序的整体思想是这样的:
- 从数组头部开始,不断比较相邻的两个元素的大小,让较大的元素逐渐往后移动(交换两个元素的值),直到数组的末尾。经过第一轮的比较,就可以找到最大的元素,并将它移动到最后一个位置。
- 第一轮结束后,继续第二轮。仍然从数组头部开始比较,让较大的元素逐渐往后移动,直到数组的倒数第二个元素为止。经过第二轮的比较,就可以找到次大的元素,并将它放到倒数第二个位置。
- 以此类推,进行 n-1(n 为数组长度)轮"冒泡"后,就可以将所有的元素都排列好。
整个排序过程就好像气泡不断从水里冒出来,最大的先出来,次大的第二出来,最小的最后出来,所以将这种排序方式称为冒泡排序(Bubble Sort)。
下面我们以"3 2 4 1"为例对冒泡排序进行说明。
第一轮 排序过程
3 2 4 1 (最初)
2 3 4 1 (比较3和2,交换)
2 3 4 1 (比较3和4,不交换)
2 3 1 4 (比较4和1,交换)
第一轮结束,最大的数字 4 已经在最后面,因此第二轮排序只需要对前面三个数进行比较。
第二轮 排序过程
2 3 1 4 (第一轮排序结果)
2 3 1 4 (比较2和3,不交换)
2 1 3 4 (比较3和1,交换)
第二轮结束,次大的数字 3 已经排在倒数第二个位置,所以第三轮只需要比较前两个元素。
第三轮 排序过程
2 1 3 4 (第二轮排序结果)
1 2 3 4 (比较2和1,交换)
至此,排序结束。
#include <stdio.h>
int main(){
int nums[10] = {4, 5, 2, 10, 7, 1, 8, 3, 6, 9};
int i, j, temp;
//冒泡排序算法:进行 n-1 轮比较
for(i=0; i<10-1; i++){
//每一轮比较前 n-1-i 个,也就是说,已经排序好的最后 i 个不用比较
for(j=0; j<10-1-i; j++){
if(nums[j] > nums[j+1]){
temp = nums[j];
nums[j] = nums[j+1];
nums[j+1] = temp;
}
}
}
//输出排序后的数组
for(i=0; i<10; i++){
printf("%d ", nums[i]);
}
printf("\n");
return 0;
}冒泡优化算法
#include <stdio.h>
int main(){
int nums[10] = {4, 5, 2, 10, 7, 1, 8, 3, 6, 9};
int i, j, temp, isSorted;
//优化算法:最多进行 n-1 轮比较
for(i=0; i<10-1; i++){
isSorted = 1; //假设剩下的元素已经排序好了
for(j=0; j<10-1-i; j++){
if(nums[j] > nums[j+1]){
temp = nums[j];
nums[j] = nums[j+1];
nums[j+1] = temp;
isSorted = 0; //一旦需要交换数组元素,就说明剩下的元素没有排序好
}
}
if(isSorted) break; //如果没有发生交换,说明剩下的元素已经排序好了
}
for(i=0; i<10; i++){
printf("%d ", nums[i]);
}
printf("\n");
return 0;
}对C语言数组的总结
1) 数组的定义格式为: type arrayNamelength
2) 访问数组元素的格式为: arrayNameindex
3) 可以对数组中的单个元素赋值,也可以整体赋值,例如:
// 对单个元素赋值
int a[3];
a[0] = 3;
a[1] = 100;
a[2] = 34;
// 整体赋值(不指明数组长度)
float b[] = { 23.3, 100.00, 10, 0.34 };
// 整体赋值(指明数组长度)
int m[10] = { 100, 30, 234 };
// 字符数组赋值
char str1[] = "http://c.biancheng.net";
// 将数组所有元素都初始化为0
int arr[10] = {0};
char str2[20] = {0};C语言函数详解
prime() 的返回值是 void,return 后面不能带任何数据,直接写分号即可。
#include <stdio.h>
void prime(int n){
int is_prime = 1, i;
if(n < 0){
printf("%d is a illegal number.\n", n);
return; //return后面不带任何数据
}
for(i=2; i<n; i++){
if(n % i == 0){
is_prime = 0;
break;
}
}
if(is_prime > 0){
printf("%d is a prime number.\n", n);
}else{
printf("%d is not a prime number.\n", n);
}
}
int main(){
int num;
scanf("%d", &num);
prime(num);
return 0;
}C语言函数声明以及函数原型
C语言代码由上到下依次执行,原则上函数定义要出现在函数调用之前,否则就会报错。但在实际开发中,经常会在函数定义之前使用它们,这个时候就需要提前声明。
所谓声明(Declaration),就是告诉编译器我要使用这个函数,你现在没有找到它的定义不要紧,请不要报错,稍后我会把定义补上。
函数声明的格式非常简单,相当于去掉函数定义中的函数体,并在最后加上分号;,如下所示
dataType functionName( dataType1 param1, dataType2 param2 ... );也可以不写形参,只写数据类型:
dataType functionName( dataType1, dataType2 ... );函数声明给出了函数名、返回值类型、参数列表(重点是参数类型)等与该函数有关的信息,称为函数原型(Function Prototype)。函数原型的作用是告诉编译器与该函数有关的信息,让编译器知道函数的存在,以及存在的形式,即使函数暂时没有定义,编译器也知道如何使用它。
有了函数声明,函数定义就可以出现在任何地方了,甚至是其他文件、静态链接库、动态链接库等。
【实例1】定义一个函数 sum(),计算从 m 加到 n 的和,并将 sum() 的定义放到 main() 后面。
#include <stdio.h>
//函数声明
int sum(int m, int n); //也可以写作int sum(int, int);
int main(){
int begin = 5, end = 86;
int result = sum(begin, end);
printf("The sum from %d to %d is %d\n", begin, end, result);
printf("1!+2!+...+9!+10! = %ld\n", sum(10,20)); //%ld 用于表示一个 long int 类型的十进制整数。
return 0;
}
//函数定义
int sum(int m, int n){
int i, sum=0;
for(i=m; i<=n; i++){
sum+=i;
}
return sum;
}我们在 main() 函数中调用了 sum() 函数,编译器在它前面虽然没有发现函数定义,但是发现了函数声明,这样编译器就知道函数怎么使用了。
C语言全局变量和局部变量
注意:
函数内部的局部变量和函数外部的全局变量同名时,在当前函数这个局部作用域中,全局变量会被"屏蔽",不再起作用。也就是说,在函数内部使用的是局部变量,而不是全局变量。 变量的使用遵循就近原则,如果在当前的局部作用域中找到了同名变量,就不会再去更大的全局作用域中查找。另外,只能从小的作用域向大的作用域中去寻找变量,而不能反过来,使用更小的作用域中的变量。
局部变量
定义在函数内部的变量称为局部变量(Local Variable),它的作用域仅限于函数内部, 离开该函数后就是无效的,再使用就会报错。例如:
int f1(int a){
int b,c; //a,b,c仅在函数f1()内有效
return a+b+c;
}
int main(){
int m,n; //m,n仅在函数main()内有效
return 0;
}全局变量
在所有函数外部定义的变量称为全局变量(Global Variable),它的作用域默认是整个程序,也就是所有的源文件,包括 .c 和 .h 文件。例如:
int a, b; //全局变量
void func1(){
//TODO:
}
float x,y; //全局变量
int func2(){
//TODO:
}
int main(){
//TODO:
return 0;
}a、b、x、y 都是在函数外部定义的全局变量。C语言代码是从前往后依次执行的,由于 x、y 定义在函数 func1() 之后,所以在 func1() 内无效;而 a、b 定义在源程序的开头,所以在 func1()、func2() 和 main() 内都有效。
局部变量和全局变量的综合示例
#include <stdio.h>
int n = 10; //全局变量
void func1(){
int n = 20; //局部变量
printf("func1 n: %d\n", n);
}
void func2(int n){
printf("func2 n: %d\n", n);
}
void func3(){
printf("func3 n: %d\n", n);
}
int main(){
int n = 30; //局部变量
func1();
func2(n);
func3();
//代码块由{}包围
{
int n = 40; //局部变量
printf("block n: %d\n", n);
}
printf("main n: %d\n", n);
return 0;
}运行结果:
func1 n: 20
func2 n: 30
func3 n: 10
block n: 40
main n: 30
代码中虽然定义了多个同名变量 n,但它们的作用域不同,在内存中的位置(地址)也不同,所以是相互独立的变量,互不影响,不会产生重复定义(Redefinition)错误。
C语言规定,只能从小的作用域向大的作用域中去寻找变量,而不能反过来,使用更小的作用域中的变量。对于 main() 函数,即使代码块中的 n 离输出语句更近,但它仍然会使用 main() 函数开头定义的 n,所以输出结果是 30。
局部和全局变量的名一样,取哪个?
遵循就近原则,如果在当前的局部作用域中找到了同名变量,就不会再去更大的全局作用域中查找。另外,只能从小的作用域向大的作用域中去寻找变量,而不能反过来,使用更小的作用域中的变量。
#include <stdio.h>
int n = 10; //全局变量
void func1(){
int n = 20; //局部变量
printf("func1 n: %d\n", n);
}
void func2(int n){
printf("func2 n: %d\n", n);
}
void func3(){
printf("func3 n: %d\n", n);
}
int main(){
int n = 30; //局部变量
func1();
func2(n);
func3();
printf("main n: %d\n", n);
return 0;
}运行结果:
func1 n: 20
func2 n: 30
func3 n: 10
main n: 30
C语言块级变量:在代码块内部定义的变量
所谓代码块,就是由{ }包围起来的代码。代码块在C语言中随处可见,例如函数体、选择结构、循环结构等。不包含代码块的C语言程序根本不能运行,即使最简单的C语言程序(上节已经进行了展示)也要包含代码块。
#include <stdio.h>
int main(){
int n = 22; //编号①
//由{ }包围的代码块
{
int n = 40; //编号②
printf("block n: %d\n", n);
}
printf("main n: %d\n", n);
return 0;
}运行结果:
block n: 40
main n: 22
C语言递归函数(递归调用)
一个函数在它的函数体内调用它自身称为递归调用 ,这种函数称为递归函数。执行递归函数将反复调用其自身,每调用一次就进入新的一层,当最内层的函数执行完毕后,再一层一层地由里到外退出。
下面我们通过一个求阶乘的例子,看看递归函数到底是如何运作的。阶乘 n! 的计算公式如下:
1! = 1
2! = 2 × 1 = 2
3! = 3 × 2 × 1 = 6
5! = 5 × 4 × 3 × 2 × 1 = 120。以此类推
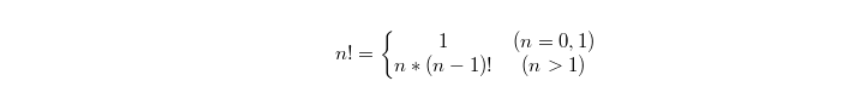
根据公式编写如下的代码:(递归函数)
#include <stdio.h>
//求n的阶乘
long factorial(int n) {
if (n == 0 || n == 1) { // 当 n==0 或 n==1 时函数才会执行结束
return 1;
}
else {
return factorial(n - 1) * n; // 递归调用
}
}
int main() {
int a;
printf("Input a number: ");
scanf("%d", &a);
printf("Factorial(%d) = %ld\n", a, factorial(a));
return 0;
}运行结果:
Input a number: 5↙
Factorial(5) = 120
factorial() 就是一个典型的递归函数。调用 factorial() 后即进入函数体,只有当 n0 或 n1 时函数才会执行结束,否则就一直调用它自身。
由于每次调用的实参为 n-1,即把 n-1 的值赋给形参 n,所以每次递归实参的值都减 1,直到最后 n-1 的值为 1 时再作递归调用,形参 n 的值也为1,递归就终止了,会逐层退出。
下表列出了逐层进入的过程:
| 层次/层数 | 实参/形参 | 调用形式 | 需要计算的表达式 | 需要等待的结果 |
|---|---|---|---|---|
| 1 | n=5 | factorial(5) | factorial(4) * 5 | factorial(4) 的结果 |
| 2 | n=4 | factorial(4) | factorial(3) * 4 | factorial(3) 的结果 |
| 3 | n=3 | factorial(3) | factorial(2) * 3 | factorial(2) 的结果 |
| 4 | n=2 | factorial(2) | factorial(1) * 2 | factorial(1) 的结果 |
| 5 | n=1 | factorial(1) | 1 | 无 |
递归的退出
当递归进入到最内层的时候,递归就结束了,就开始逐层退出了,也就是逐层执行 return 语句。
下表列出了逐层退出的过程:
| 层次/层数 | 调用形式 | 需要计算的表达式 | 从内层递归得到的结果 (内层函数的返回值) | 表达式的值 (当次调用的结果) |
|---|---|---|---|---|
| 5 | factorial(1) | 1 | 无 | 1 |
| 4 | factorial(2) | factorial(1) * 2 | factorial(1) 的返回值,也就是 1 | 2 |
| 3 | factorial(3) | factorial(2) * 3 | factorial(2) 的返回值,也就是 2 | 6 |
| 2 | factorial(4) | factorial(3) * 4 | factorial(3) 的返回值,也就是 6 | 24 |
| 1 | factorial(5) | factorial(4) * 5 | factorial(4) 的返回值,也就是 24 | 120 |
C语言预处理命令是什么?
使用库函数之前,应该用#include引入对应的头文件。这种以#号开头的命令称为预处理命令。
C语言源文件要经过编译、链接才能生成可执行程序:
1)编译(Compile)会将源文件(.c文件)转换为目标文件。对于 VC/VS,目标文件后缀为.obj;对于GCC,目标文件后缀为.o。
编译是针对单个源文件的,一次编译操作只能编译一个源文件,如果程序中有多个源文件,就需要多次编译操作。
2) 链接(Link)是针对多个文件的,它会将编译生成的多个目标文件以及系统中的库、组件等合并成一个可执行程序。假如现在要开发一个C语言程序,让它暂停 5 秒以后再输出内容,并且要求跨平台,在 Windows 和 Linux 下都能运行,怎么办呢?
这个程序的难点在于,不同平台下的暂停函数和头文件都不一样:
- Windows 平台下的暂停函数的原型是
void Sleep(DWORD dwMilliseconds)(注意 S 是大写的),参数的单位是"毫秒",位于 <windows.h> 头文件。 - Linux 平台下暂停函数的原型是
unsigned int sleep (unsigned int seconds),参数的单位是"秒",位于 <unistd.h> 头文件。
不同的平台下必须调用不同的函数,并引入不同的头文件,否则就会导致编译错误,因为 Windows 平台下没有 sleep() 函数,也没有 <unistd.h> 头文件,反之亦然。这就要求我们在编译之前,也就是预处理阶段来解决这个问题。请看下面的代码:
#include <stdio.h>
//不同的平台下引入不同的头文件
#if _WIN32 //识别windows平台
#include <windows.h>
#elif __linux__ //识别linux平台
#include <unistd.h>
#endif
int main() {
//不同的平台下调用不同的函数
#if _WIN32 //识别windows平台
Sleep(5000);
#elif __linux__ //识别linux平台
sleep(5);
#endif
puts("http://c.biancheng.net/");
return 0;
}#if、#elif、#endif 就是预处理命令,它们都是在编译之前由预处理程序来执行的。这里我们不讨论细节,只从整体上来理解。
对于 Windows 平台,预处理以后的代码变成:
#include <stdio.h>
#include <windows.h>
int main() {
Sleep(5000);
puts("http://c.biancheng.net/");
return 0;
}对于 Linux 平台,预处理以后的代码变成:
#include <stdio.h>
#include <unistd.h>
int main() {
sleep(5);
puts("http://c.biancheng.net/");
return 0;
}C语言指针

我们将内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加,对于 32 位环境,程序能够使用的内存为 4GB,最小的地址为 0,最大的地址为 0XFFFFFFFF。
如何输出一个地址:
%#X会输出一个带有0X前缀的大写十六进制数。
-
%:表示开始一个格式说明符。 -
#:表示输出的十六进制数应该带有前缀0X(大写)或0x(小写)。 -
X:表示输出的十六进制数应该使用大写字母(例如A-F)#include <stdio.h>
int main(){
int a = 100;
char str[20] = "c.biancheng.net";
printf("%#X, %#X\n", &a, str);
return 0;
}
运行结果:
0X2EDFFB5C, 0X2EDFFB40
一切都是地址
假设变量 a、b、c 在内存中的地址分别是 0X1000、0X2000、0X3000,那么加法运算c = a + b;将会被转换成类似下面的形式:
0X3000 = (0X1000) + (0X2000);表达式的意思是,取出地址 0X1000 和 0X2000 上的值,将它们相加,把相加的结果赋值给地址为 0X3000 的内存
什么是指针变量
数据在内存中的地址也称为指针,如果一个变量存储了一份数据的指针,我们就称它为指针变量。
在C语言中,允许用一个变量来存放指针,这种变量称为指针变量。指针变量的值就是某份数据的地址,这样的一份数据可以是数组、字符串、函数,也可以是另外的一个普通变量或指针变量。
定义指针变量
定义指针变量与定义普通变量非常类似,不过要在变量名前面加星号*,格式为:
datatype *name;或者
datatype *name = value;*表示这是一个指针变量,datatype表示该指针变量所指向的数据的类型 。例如:
int *p1;
int a = 100;
int *p_a = &a;在定义指针变量 p_a 的同时对它进行初始化,并将变量 a 的地址赋予它,此时 p_a 就指向了 a。值得注意的是,p_a 需要的一个地址,a 前面必须要加取地址符&,否则是不对的
和普通变量一样,指针变量也可以被多次写
//定义普通变量
float a = 99.5, b = 10.6;
char c = '@', d = '#';
//定义指针变量
float *p1 = &a;
char *p2 = &c;
//修改指针变量的值
p1 = &b;
p2 = &d;*是一个特殊符号,表明一个变量是指针变量,定义 p1、p2 时必须带*。而给 p1、p2 赋值时,因为已经知道了它是一个指针变量,就没必要多此一举再带上*,后边可以像使用普通变量一样来使用指针变量。也就是说,定义指针变量时必须带*,给指针变量赋值时不能带*。
指针变量连续定义
指针变量也可以连续定义,例如:
int *a, *b, *c; //a、b、c 的类型都是 int*注意每个变量前面都要带*。如果写成下面的形式,那么只有 a 是指针变量,b、c 都是类型为 int 的普通变量:
int *a, b, c;获取指针变量数据
指针变量存储了数据的地址,通过指针变量能够获得该地址上的数据,格式为:
*pointer;这里的*称为指针运算符,用来取得某个地址上的数据,请看下面的例子:
#include <stdio.h>
int main(){
int a = 15;
int *p = &a;
printf("%d, %d\n", a, *p); //两种方式都可以输出a的值
return 0;
}运行结果:
15, 15
虽然通过 *p 和 a 获取到的数据一样,但它们的运行过程稍有不同:a 只需要一次运算就能够取得数据,而 *p 要经过两次运算,多了一层"间接"。

程序被编译和链接后,a、p 被替换成相应的地址。使用 *p 的话,要先通过地址 0XF0A0 取得变量 p 本身的值,这个值是变量 a 的地址,然后再通过这个值取得变量 a 的数据,前后共有两次运算;而使用 a 的话,可以通过地址 0X1000 直接取得它的数据,只需要一步运算。
也就是说,使用指针是间接获取数据,使用变量名是直接获取数据,前者比后者的代价要高。
指针除了可以获取内存上的数据,也可以修改内存上的数据,例如:(修改指向值)
#include <stdio.h>
int main(){
int a = 15, b = 99, c = 222;
int *p = &a; //定义指针变量
*p = b; //通过指针变量修改内存上的数据
c = *p; //通过指针变量获取内存上的数据
printf("%d, %d, %d, %d\n", a, b, c, *p);
return 0;
}运行结果:
99, 99, 99, 99
*p 代表的是 a 中的数据,它等价于 a,可以将另外的一份数据赋值给它,也可以将它赋值给另外的一个变量。
使用指针变量时在前面加*表示获取指针指向的数据。
定义指针变量时的*和使用指针变量时的*意义完全不同,第1行代码中*用来指明 p 是一个指针变量,第2行代码中*用来获取指针指向的数据。
int *p = &a;
*p = 100;需要注意的是,给指针变量本身赋值时不能加*。修改上面的语句:第2行代码中的 p 前面就不能加*。
int *p;
p = &a;
*p = 100;指针变量也可以出现在普通变量能出现的任何表达式中,例如:
int x, y, *px = &x, *py = &y;
y = *px + 5; //表示把x的内容加5并赋给y,*px+5相当于(*px)+5
y = ++*px; //px的内容加上1之后赋给y,++*px相当于++(*px)
y = *px++; //相当于y=(*px)++
py = px; //把一个指针的值赋给另一个指针通过指针交换两个变量的值。
#include <stdio.h>
int main(){
int a = 100, b = 999, temp;
int *pa = &a, *pb = &b;
printf("a=%d, b=%d\n", a, b);
/*****开始交换*****/
temp = *pa; //将a的值先保存起来
*pa = *pb; //将b的值交给a
*pb = temp; //再将保存起来的a的值交给b
/*****结束交换*****/
printf("a=%d, b=%d\n", a, b);
return 0;
}运行结果:
a=100, b=999
a=999, b=100
关于 * 和 & 的谜题
假设有一个 int 类型的变量 a,pa 是指向它的指针,那么*&a和&*pa分别是什么意思呢?
*&a可以理解为*(&a),&a表示取变量 a 的地址(等价于 pa),*(&a)表示取这个地址上的数据(等价于 *pa),绕来绕去,又回到了原点,*&a仍然等价于 a。
&*pa可以理解为&(*pa),*pa表示取得 pa 指向的数据(等价于 a),&(*pa)表示数据的地址(等价于 &a),所以&*pa等价于 pa。
星号*的总结
星号*主要有三种用途:
- 表示乘法,例如
int a = 3, b = 5, c; c = a * b;,这是最容易理解的。 - 表示定义一个指针变量,以和普通变量区分开,例如
int a = 100; int *p = &a;。 - 表示获取指针指向的数据,是一种间接操作,例如
int a, b, *p = &a; *p = 100; b = *p;。
C语言指针变量的运算(加法、减法和比较运算)
指针变量保存的是地址,而地址本质上是一个整数,所以指针变量可以进行部分运算,例如加法、减法、比较等,请看下面的代码:
#include <stdio.h>
int main(){
int a = 10, *pa = &a, *paa = &a;
double b = 99.9, *pb = &b;
char c = '@', *pc = &c;
//最初的值
printf("&a=%#X, &b=%#X, &c=%#X\n", &a, &b, &c);
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//加法运算
pa++; pb++; pc++;
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//减法运算
pa -= 2; pb -= 2; pc -= 2;
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//比较运算
if(pa == paa){
printf("%d\n", *paa);
}else{
printf("%d\n", *pa);
}
return 0;
}
&a=0X28FF44, &b=0X28FF30, &c=0X28FF2B
pa=0X28FF44, pb=0X28FF30, pc=0X28FF2B
pa=0X28FF48, pb=0X28FF38, pc=0X28FF2C
pa=0X28FF40, pb=0X28FF28, pc=0X28FF2A
2686784从运算结果可以看出:pa、pb、pc 每次加 1,它们的地址分别增加 4、8、1,正好是 int、double、char 类型的长度;减 2 时,地址分别减少 8、16、2,正好是 int、double、char 类型长度的 2 倍。
这很奇怪,指针变量加减运算的结果跟数据类型的长度有关,而不是简单地加 1 或减 1,这是为什么呢?
以 a 和 pa 为例,a 的类型为 int,占用 4 个字节,pa 是指向 a 的指针,如下图所示:

刚开始的时候,pa 指向 a 的开头,通过 *pa 读取数据时,从 pa 指向的位置向后移动 4 个字节,把这 4 个字节的内容作为要获取的数据,这 4 个字节也正好是变量 a 占用的内存。
如果pa++;使得地址加 1 的话,就会变成如下图所示的指向关系:

这个时候 pa 指向整数 a 的中间,*pa 使用的是红色虚线画出的 4 个字节,其中前 3 个是变量 a 的,后面 1 个是其它数据的,把它们"搅和"在一起显然没有实际的意义,取得的数据也会非常怪异。
如果pa++;使得地址加 4 的话,正好能够完全跳过整数 a,指向它后面的内存,如下图所示:

数组中的所有元素在内存中是连续排列的,如果一个指针指向了数组中的某个元素,那么加 1 就表示指向下一个元素,减 1 就表示指向上一个元素。
警告不要尝试通过指针获取下一个变量的地址:反面教材
#include <stdio.h>
int main(){
int a = 1, b = 2, c = 3;
int *p = &c;
int i;
for(i=0; i<8; i++){
printf("%d, ", *(p+i) );
}
return 0;
}运行结果为:
3, -858993460, -858993460, 2, -858993460, -858993460, 1, -858993460,C语言数组指针(指向数组的指针)
遍历数组元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int len = sizeof(arr) / sizeof(int); //求数组长度
int i;
for(i=0; i<len; i++){
printf("%d ", *(arr+i) ); //*(arr+i)等价于arr[i]
}
printf("\n");
return 0;
}运行结果:
99 15 100 888 252
第 4行代码用来求数组的长度,sizeof(arr) 会获得整个数组所占用的字节数,sizeof(int) 会获得一个数组元素所占用的字节数,它们相除的结果就是数组包含的元素个数,也即数组长度。
第 7 行代码中我们使用了*(arr+i)这个表达式,arr 是数组名,指向数组的第 0 个元素,表示数组首地址, arr+i 指向数组的第 i 个元素,*(arr+i) 表示取第 i 个元素的数据,它等价于 arri。
arr 是`int*`类型的指针,每次加 1 时它自身的值会增加 sizeof(int),加 i 时自身的值会增加 sizeof(int) * i。指向数组的指针:
int arr[] = { 99, 15, 100, 888, 252 };
int *p = arr; //arr 是数组第 0 个元素的地址
arr 本身就是一个指针,可以直接赋值给指针变量 p。arr 是数组第 0 个元素的地址,所以int *p = arr;也可以写作int *p = &arr[0];。也就是说,arr、p、&arr[0] 这三种写法都是等价的,它们都指向数组第 0 个元素,或者说指向数组的开头。如果一个指针指向了数组,我们就称它为数组指针(Array Pointer)。
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int i, *p = arr, len = sizeof(arr) / sizeof(int);
for(i=0; i<len; i++){
printf("%d ", *(p+i) );
}
printf("\n");
return 0;
}。如果一个指针变量 p 指向了数组的开头,那么 p+i 就指向数组的第 i 个元素;如果 p 指向了数组的第 n 个元素,那么 p+i 就是指向第 n+i 个元素;而不管 p 指向了数组的第几个元素,p+1 总是指向下一个元素,p-1 也总是指向上一个元素。
更改上面的代码,让 p 指向数组中的第二个元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int *p = &arr[2]; //也可以写作 int *p = arr + 2;
printf("%d, %d, %d, %d, %d\n", *(p-2), *(p-1), *p, *(p+1), *(p+2) );
return 0;
}运行结果:
99, 15, 100, 888, 252
小总结:
引入数组指针后,我们就有两种方案来访问数组元素了,一种是使用下标,另外一种是使用指针。
1) 使用下标
也就是采用 arri 的形式访问数组元素。如果 p 是指向数组 arr 的指针,那么也可以使用 pi 来访问数组元素,它等价于 arri。
2) 使用指针
也就是使用 *(p+i) 的形式访问数组元素。另外数组名本身也是指针,也可以使用 *(arr+i) 来访问数组元素,它等价于 *(p+i)。
不管是数组名还是数组指针,都可以使用上面的两种方式来访问数组元素。不同的是,数组名是常量,它的值不能改变,而数组指针是变量(除非特别指明它是常量),它的值可以任意改变。也就是说,数组名只能指向数组的开头,而数组指针可以先指向数组开头,再指向其他元素。
更改上面的代码,借助自增运算符来遍历数组元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int i, *p = arr, len = sizeof(arr) / sizeof(int);
for(i=0; i<len; i++){
printf("%d ", *p++ );
}
printf("\n");
return 0;
}运行结果:
99 15 100 888 252
第 8 行代码中,*p++ 应该理解为 *(p++),每次循环都会改变 p 的值(p++ 使得 p 自身的值增加),以使 p 指向下一个数组元素。该语句不能写为 *arr++,因为 arr 是常量,而 arr++ 会改变它的值,这显然是错误的。
数组指针的谜题,p++、++p、(*p)++ 分别是什么意思?
设 p 是指向数组 arr 中第 n 个元素的指针,那么 p++、++p、(*p)++ 分别是什么意思呢?
*p++ 等价于 *(p++),表示先取得第 n 个元素的值,再将 p 指向下一个元素,上面已经进行了详细讲解。
*++p 等价于 *(++p),会先进行 ++p 运算,使得 p 的值增加,指向下一个元素,整体上相当于 *(p+1),所以会获得第 n+1 个数组元素的值。
(*p)++ 就非常简单了,会先取得第 n 个元素的值,再对该元素的值加 1。假设 p 指向第 0 个元素,并且第 0 个元素的值为 99,执行完该语句后,第 0 个元素的值就会变为 100。()C语言字符串指针
语言中没有特定的字符串类型 ,我们通常是将字符串放在一个字符数组。
#include <stdio.h>
#include <string.h>
int main(){
char str[] = "http://c.biancheng.net";
int len = strlen(str), i;
//直接输出字符串
printf("%s\n", str);
//每次输出一个字符
for(i=0; i<len; i++){
printf("%c", str[i]); //%c是char类型
}
printf("\n");
return 0;
}运行结果:
使用指针的方式来输出字符串:
#include <stdio.h>
#include <string.h>
int main(){
char str[] = "http://c.biancheng.net";
char *pstr = str;
int len = strlen(str), i;
//使用*(pstr+i)
for(i=0; i<len; i++){
printf("%c", *(pstr+i));
}
printf("\n");
//使用pstr[i]
for(i=0; i<len; i++){
printf("%c", pstr[i]);
}
printf("\n");
//使用*(str+i)
for(i=0; i<len; i++){
printf("%c", *(str+i));
}
printf("\n");
return 0;
}运行结果:
简单的方法指针指向字符串,例如:
char *str = "http://c.biancheng.net";
或者:
char *str;
str = "http://c.biancheng.net";字符串中的所有字符在内存中是连续排列的,str 指向的是字符串的第 0 个字符;我们通常将第 0 个字符的地址称为字符串的首地址。字符串中每个字符的类型都是char,所以 str 的类型也必须是char *。
输出 (指针定义的字符串) 这种字符串:
#include <stdio.h>
#include <string.h>
int main(){
char *str = "http://c.biancheng.net";
int len = strlen(str), i;
//直接输出字符串
printf("%s\n", str);
//使用*(str+i)
for(i=0; i<len; i++){
printf("%c", *(str+i));
}
printf("\n");
//使用str[i]
for(i=0; i<len; i++){
printf("%c", str[i]);
}
printf("\n");
return 0;
}运行结果:
注意:指针指向字符串和字符串数组的区别
它们最根本的区别是在内存中的存储区域不一样,字符数组存储在全局数据区或栈区,第二种形式的字符串存储在常量区。全局数据区和栈区的字符串(也包括其他数据)有读取和写入的权限,而常量区的字符串(也包括其他数据)只有读取权限,没有写入权限。
字符数组在定义后可以读取和修改每个字符,而对于第二种形式的字符串,一旦被定义后就只能读取不能修改,任何对它的赋值都是错误的。
将第二种形式的字符串称为字符串常量,意思很明显,常量只能读取不能写入。请看下面的演示:
#include <stdio.h>
int main(){
char *str = "Hello World!";
str = "I love C!"; //正确,改变了str值
str[3] = 'P'; //错误
return 0;
}这段代码能够正常编译和链接,但在运行时会出现段错误(Segment Fault)或者写入位置错误。
第4行代码是正确的,可以更改指针变量本身的指向;第5行代码是错误的,不能修改字符串中的字符。
使用字符数组还是字符串常量
只涉及到对字符串的读取,那么字符数组和字符串常量都能够满足要求;如果有写入(修改)操作,那么只能使用字符数组,不能使用字符串常量。
获取用户输入的字符串就是一个典型的写入操作,只能使用字符数组,不能使用字符串常量,请看下面的代码:
#include <stdio.h>
int main(){
char str[30];
gets(str); // 等到输入完回车才执行printf
printf("%s\n", str);
return 0;
}运行结果:
C C++
C C++
字符串变量声明总结:
C语言有两种表示字符串的方法,一种是字符数组,另一种是字符串常量,它们在内存中的存储位置不同,使得字符数组可以读取和修改,而字符串常量只能读取不能修改。
C语言指针变量作为函数参数
用指针变量作函数参数可以将函数外部的地址传递到函数内部,使得在函数内部可以操作函数外部的数据,并且这些数据不会随着函数的结束而被销毁。
常规的交换变量:
#include <stdio.h>
void swap(int a, int b){
int temp; //临时变量
temp = a;
a = b;
b = temp;
}
int main(){
int a = 66, b = 99;
swap(a, b);
printf("a = %d, b = %d\n", a, b);
return 0;
}运行结果:
a = 66, b = 99
从结果可以看出,a、b 的值并没有发生改变,交换失败。这是因为 swap() 函数内部的 a、b 和 main() 函数内部的 a、b 是不同的变量,占用不同的内存,它们除了名字一样,没有其他任何关系,swap() 交换的是它内部 a、b 的值,不会影响它外部(main() 内部) a、b 的值。
改用指针变量作参数后就很容易解决上面的问题:
#include <stdio.h>
void swap(int *p1, int *p2){
int temp; //临时变量
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
int main(){
int a = 66, b = 99;
swap(&a, &b);
printf("a = %d, b = %d\n", a, b);
return 0;
}运行结果:
a = 99, b = 66
调用 swap() 函数时,将变量 a、b 的地址分别赋值给 p1、p2,这样 *p1、*p2 代表的就是变量 a、b 本身,交换 *p1、*p2 的值也就是交换 a、b 的值。函数运行结束后虽然会将 p1、p2 销毁,但它对外部 a、b 造成的影响是"持久化"的,不会随着函数的结束而"恢复原样"。
用数组作函数参数
组是一系列数据的集合,无法通过参数将它们一次性传递到函数内部,如果希望在函数内部操作数组,必须传递数组指针。下面的例子定义了一个函数 max(),用来查找数组中值最大的元素:
#include <stdio.h>
int max(int *intArr, int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}
int main(){
int nums[6], i;
int len = sizeof(nums)/sizeof(int);
//读取用户输入的数据并赋值给数组元素
for(i=0; i<len; i++){
scanf("%d", nums+i);
}
printf("Max value is %d!\n", max(nums, len));
return 0;
}运行结果:
12 55 30 8 93 27
Max value is 93!
用数组做函数参数时,参数也能够以"真正"的数组形式给出。例如对于上面的 max() 函数,它的参数可以写成下面的形式:
int max(int intArr[6], int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}int intArr[6]好像定义了一个拥有 6 个元素的数组,调用 max() 时可以将数组的所有元素"一股脑"传递进来。
把形参简写为下面的形式:
int max(int intArr[], int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}int intArr[]虽然定义了一个数组,但没有指定数组长度,好像可以接受任意长度的数组。
不管是int intArr[6]还是int intArr[]都不会创建一个数组出来,编译器也不会为它们分配内存,实际的数组是不存在的,它们最终还是会转换为int *intArr这样的指针。这就意味着,两种形式都不能将数组的所有元素"一股脑"传递进来,大家还得规规矩矩使用数组指针。
C语言为什么不允许直接传递数组的所有元素,而必须传递数组指针呢?
参数的传递本质上是一次赋值的过程,赋值就是对内存进行拷贝。所谓内存拷贝,是指将一块内存上的数据复制到另一块内存上。
对于像 int、float、char 等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组是一系列数据的集合,数据的数量没有限制,可能很少,也可能成千上万,对它们进行内存拷贝有可能是一个漫长的过程,会严重拖慢程序的效率,为了防止技艺不佳的程序员写出低效的代码,C语言没有从语法上支持数据集合的直接赋值。
C语言指针作为函数返回值
C语言允许函数的返回值是一个指针(地址),我们将这样的函数称为指针函数。下面的例子定义了一个函数 strlong(),用来返回两个字符串中较长的一个:
#include <stdio.h>
#include <string.h>
char *strlong(char *str1, char *str2){
if(strlen(str1) >= strlen(str2)){
return str1;
}else{
return str2;
}
}
int main(){
char str1[30], str2[30], *str;
gets(str1);
gets(str2);
str = strlong(str1, str2);
printf("Longer string: %s\n", str);
return 0;
}运行结果:
C Language↙
c.biancheng.net↙
Longer string: c.biancheng.net
用指针作为函数返回值时需要注意的一点是,函数运行结束后会销毁在它内部定义的所有局部数据,包括局部变量、局部数组和形式参数,函数返回的指针请尽量不要指向这些数据,C语言没有任何机制来保证这些数据会一直有效,它们在后续使用过程中可能会引发运行时错误。请看下面的例子:
在第9~10行之间增加一个函数调用,看看会有什么效果:
#include <stdio.h>
int *func(){
int n = 100;
return &n;
}
int main(){
int *p = func(), n;
printf("c.biancheng.net\n"); //增加函数调用,改变了指针变量值
n = *p;
printf("value = %d\n", n);
return 0;
}运行结果:
value = -2
可以看到,现在 p 指向的数据已经不是原来 n 的值了,它变成了一个毫无意义的甚至有些怪异的值。与前面的代码相比,该段代码仅仅是在 *p 之前增加了一个函数调用,这一细节的不同却导致运行结果有天壤之别,究竟是为什么呢?
前面我们说函数运行结束后会销毁所有的局部数据,这个观点并没错,大部分C语言教材也都强调了这一点。但是,这里所谓的销毁并不是将局部数据所占用的内存全部抹掉,而是程序放弃对它的使用权限,弃之不理,后面的代码可以随意使用这块内存。对于上面的两个例子,func() 运行结束后 n 的内存依然保持原样,值还是 100,如果使用及时也能够得到正确的数据,如果有其它函数被调用就会覆盖这块内存,得到的数据就失去了意义。
C语言二级指针
指针可以指向一份普通类型的数据,例如 int、double、char 等,也可以指向一份指针类型的数据,例如 int *、double *、char * 等。
如果一个指针指向的是另外一个指针,我们就称它为二级指针,或者指向指针的指针。
假设有一个 int 类型的变量 a,p1是指向 a 的指针变量,p2 又是指向 p1 的指针变量,它们的关系如下图所示:

将这种关系转换为C语言代码:
int a =100;
int *p1 = &a;
int **p2 = &p1;指针变量也是一种变量,也会占用存储空间,也可以使用&获取它的地址。C语言不限制指针的级数,每增加一级指针,在定义指针变量时就得增加一个星号*。p1 是一级指针,指向普通类型的数据,定义时有一个*;p2 是二级指针,指向一级指针 p1,定义时有两个*。
如果我们希望再定义一个三级指针 p3,让它指向 p2,那么可以这样写:
int ***p3 = &p2;四级指针也是类似的道理:
int ****p4 = &p3;实际开发中会经常使用一级指针和二级指针,几乎用不到高级指针。
想要获取指针指向的数据时,一级指针加一个*,二级指针加两个*,三级指针加三个*,以此类推,请看代码:
#include <stdio.h>
int main(){
int a =100;
int *p1 = &a;
int **p2 = &p1;
int ***p3 = &p2;
printf("%d, %d, %d, %d\n", a, *p1, **p2, ***p3);
printf("&p2 = %#X, p3 = %#X\n", &p2, p3);
printf("&p1 = %#X, p2 = %#X, *p3 = %#X\n", &p1, p2, *p3);
printf(" &a = %#X, p1 = %#X, *p2 = %#X, **p3 = %#X\n", &a, p1, *p2, **p3);
return 0;
}以三级指针 p3 为例来分析上面的代码。***p3等价于*(*(*p3))。p3 得到的是 p2 的值,也即 p1 的地址; (p3) 得到的是 p1 的值,也即 a 的地址;经过三次"取值"操作后,(*(*p3)) 得到的才是 a 的值。
假设 a、p1、p2、p3 的地址分别是 0X00A0、0X1000、0X2000、0X3000,它们之间的关系可以用下图来描述:

C语言指针数组
如果一个数组中的所有元素保存的都是指针,那么我们就称它为指针数组。指针数组的定义形式一般为:
dataType *arrayName[length];[ ]的优先级高于*,该定义形式应该理解为:
dataType *(arrayName[length]);括号里面说明arrayName是一个数组,包含了length个元素,括号外面说明每个元素的类型为dataType *。
除了每个元素的数据类型不同,指针数组和普通数组在其他方面都是一样的,下面是一个简单的例子:
#include <stdio.h>
int main(){
int a = 16, b = 932, c = 100;
//定义一个指针数组
int *arr[3] = {&a, &b, &c};//也可以不指定长度,直接写作 int *arr[]
//定义一个指向指针数组的指针
int **parr = arr;
printf("%d, %d, %d\n", *arr[0], *arr[1], *arr[2]);
printf("%d, %d, %d\n", **(parr+0), **(parr+1), **(parr+2));
return 0;
}运行结果:
16, 932, 100
16, 932, 100
arr 是一个指针数组,它包含了 3 个元素,每个元素都是一个指针,在定义 arr 的同时,我们使用变量 a、b、c 的地址对它进行了初始化,这和普通数组是多么地类似。
parr 是指向数组 arr 的指针,确切地说是指向 arr 第 0 个元素的指针,它的定义形式应该理解为int *(*parr),括号中的*表示 parr 是一个指针,括号外面的int *表示 parr 指向的数据的类型。arr 第 0 个元素的类型为 int *,所以在定义 parr 时要加两个 *。
第一个 printf() 语句中,arri 表示获取第 i 个元素的值,该元素是一个指针,还需要在前面增加一个 * 才能取得它指向的数据,也即 *arri 的形式。
第二个 printf() 语句中,parr+i 表示第 i 个元素的地址,*(parr+i) 表示获取第 i 个元素的值(该元素是一个指针),**(parr+i) 表示获取第 i 个元素指向的数据。
指针数组和字符串数组结合使用,请看下面的例子:
#include <stdio.h>
int main(){
char *str[3] = {
"c.biancheng.net",
"C语言中文网",
"C Language"
};
printf("%s\n%s\n%s\n", str[0], str[1], str[2]);
return 0;
}运行结果:
C语言中文网
C Language
字符数组 str 中存放的是字符串的首地址,不是字符串本身,字符串本身位于其他的内存区域,和字符数组是分开的。也只有当指针数组中每个元素的类型都是char *时,才能像上面那样给指针数组赋值,其他类型不行。
将上面的字符串数组改成下面的形式,它们都是等价的:
#include <stdio.h>
int main(){
char *str0 = "c.biancheng.net";
char *str1 = "C语言中文网";
char *str2 = "C Language";
char *str[3] = {str0, str1, str2};
printf("%s\n%s\n%s\n", str[0], str[1], str[2]);
return 0;
}C语言二维数组指针
二维数组在概念上是二维的,有行和列
int a[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} };从概念上理解,a 的分布像一个矩阵:
0 1 2 3
4 5 6 7
8 9 10 11但在内存中,a 的分布是一维线性的,整个数组占用一块连续的内存:

C语言中的二维数组是按行排列的,也就是先存放 a0 行,再存放 a1 行,最后存放 a2 行;每行中的 4 个元素也是依次存放。数组 a 为 int 类型,每个元素占用 4 个字节,整个数组共占用 4×(3×4) = 48 个字节。
指针遍历二维数组遍历:
#include <stdio.h>
int main(){
int a[3][4]={0,1,2,3,4,5,6,7,8,9,10,11};
int(*p)[4];
int i,j;
p=a;
for(i=0; i<3; i++){
for(j=0; j<4; j++)
printf("%2d ",*(*(p+i)+j));
printf("\n");
}
return 0;
}
*(p+1)+1)表示第 1 行第 1 个元素的值。很明显,增加一个 * 表示取地址上的数据。运行结果:
0 1 2 3
4 5 6 7
8 9 10 11指针数组和二维数组指针的区别
int *(p1[5]); //指针数组,可以去掉括号直接写作 int *p1[5];
int (*p2)[5]; //二维数组指针,不能去掉括号C语言函数指针
函数指针的定义形式为:
returnType (*pointerName)(param list);注意( )的优先级高于*,第一个括号不能省略,如果写作returnType *pointerName(param list);就成了函数原型,它表明函数的返回值类型为returnType *。
用指针来实现对函数的调用:
#include <stdio.h>
//返回两个数中较大的一个
int max(int a, int b){
return a>b ? a : b;
}
int main(){
int x, y, maxval;
//定义函数指针
int (*pmax)(int, int) = max; //也可以写作int (*pmax)(int a, int b)
printf("Input two numbers:");
scanf("%d %d", &x, &y);
maxval = (*pmax)(x, y);
printf("Max value: %d\n", maxval);
return 0;
}运行结果:
Input two numbers:10 50↙
Max value: 50
第 12 行代码对函数进行了调用。pmax 是一个函数指针,在前面加 * 就表示对它指向的函数进行调用。注意( )的优先级高于*,第一个括号不能省略。
C语言指针的总结
指针(Pointer)就是内存的地址,C语言允许用一个变量来存放指针,这种变量称为指针变量。指针变量可以存放基本类型数据的地址,也可以存放数组、函数以及其他指针变量的地址。
| 定 义 | 含 义 |
|---|---|
| int *p; | p 可以指向 int 类型的数据,也可以指向类似 int arrn 的数组。 |
| int **p; | p 为二级指针,指向 int * 类型的数据。 |
| int *pn; | p 为指针数组。 的优先级高于 *,所以应该理解为 int *(pn); |
| int (*p)n; | p 为二维数组指针。 |
| int *p(); | p 是一个函数,它的返回值类型为 int *。 |
| int (*p)(); | p 是一个函数指针,指向原型为 int func() 的函数。 |
-
指针变量可以进行加减运算,例如
p++、p+i、p-=i。指针变量的加减运算并不是简单的加上或减去一个整数,而是跟指针指向的数据类型有关。 -
给指针变量赋值时,要将一份数据的地址赋给它,不能直接赋给一个整数,例如
int *p = 1000;是没有意义的,使用过程中一般会导致程序崩溃。 -
使用指针变量之前一定要初始化,否则就不能确定指针指向哪里,如果它指向的内存没有使用权限,程序就崩溃了。对于暂时没有指向的指针,建议赋值
NULL。 -
两个指针变量可以相减。如果两个指针变量指向同一个数组中的某个元素,那么相减的结果就是两个指针之间相差的元素个数。
-
数组也是有类型的,数组名的本意是表示一组类型相同的数据。在定义数组时,或者和 sizeof、& 运算符一起使用时数组名才表示整个数组,表达式中的数组名会被转换为一个指向数组的指针。
C语言结构体详解
在C语言中,可以使用**结构体(Struct)**来存放一组不同类型的数据。结构体的定义形式为:
struct 结构体名{
结构体所包含的变量或数组
};
结构体是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或数组都称为结构体的成员(Member)。
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
};stu 为结构体名,它包含了 5 个成员,分别是 name、num、age、group、score。结构体成员的定义方式与变量和数组的定义方式相同,只是不能初始化。
结构体变量
既然结构体是一种数据类型,那么就可以用它来定义变量。例如:
struct stu stu1, stu2;定义了两个变量 stu1 和 stu2,它们都是 stu 类型,都由 5 个成员组成。注意关键字struct不能少。
stu 就像一个"模板",定义出来的变量都具有相同的性质。也可以将结构体比作"图纸",将结构体变量比作"零件",根据同一张图纸生产出来的零件的特性都是一样的。
**案例:**也可以在定义结构体的同时定义结构体变量:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
} stu1, stu2;将变量放在结构体定义的最后即可。
也可以这样做书写简单,但是因为没有结构体名,后面就没法用该结构体定义新的变量。
struct{ //没有写 stu
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
} stu1, stu2;是在编译器的具体实现中,各个成员之间可能会存在缝隙,对于 stu1、stu2,成员变量 group 和 score 之间就存在 3 个字节的空白填充(见下图)。这样算来,stu1、stu2 其实占用了 17 + 3 = 20 个字节。

成员的获取和赋值
结构体和数组类似,也是一组数据的集合。数组使用下标[ ]获取单个元素,结构体使用点号.获取单个成员。获取结构体成员的一般格式为:
结构体变量名.成员名;
#include <stdio.h>
int main(){
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1;
//给结构体成员赋值
stu1.name = "Tom";
stu1.num = 12;
stu1.age = 18;
stu1.group = 'A';
stu1.score = 136.5;
//读取结构体成员的值,.1表示小数点后要显示一位数字,而f表示要格式化的数据是浮点数。
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", stu1.name, stu1.num, stu1.age, stu1.group, stu1.score);
return 0;
}运行结果:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
除了可以对成员进行逐一赋值,也可以在定义时整体赋值,例如:
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1, stu2 = { "Tom", 12, 18, 'A', 136.5 };不过整体赋值仅限于定义结构体变量的时候,在使用过程中只能对成员逐一赋值,这和数组的赋值非常类似。
需要注意的是,结构体是一种自定义的数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据,需要内存空间来存储。
C语言结构体数组
所谓结构体数组,是指数组中的每个元素都是一个结构体。在实际应用中,C语言结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个车间的职工等。
在C语言中,定义结构体数组和定义结构体变量的方式类似,请看下面的例子:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[5];表示一个班级有5个学生。
结构体数组在定义的同时也可以初始化,例如:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[5] = { // 给出数组长度
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};当对数组中全部元素赋值时,也可不给出数组长度,例如:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[] = { //也可不给出数组长度
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};查询结构体数组Wang ming 的成绩:
class[4].score;修改 Li ping 的学习小组:
class[0].group = 'B';**【示例】**计算全班学生的总成绩、平均成绩和以及 140 分以下的人数。
#include <stdio.h>
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};
int main(){
int i, num_140 = 0;
float sum = 0;
for(i=0; i<5; i++){
sum += class[i].score;
if(class[i].score < 140) num_140++;
}
printf("sum=%.2f\naverage=%.2f\nnum_140=%d\n", sum, sum/5, num_140);
return 0;
}运行结果:
sum=707.50
average=141.50
num_140=2
C语言结构体指针
当一个指针变量指向结构体时,我们就称它为**结构体指针**。
struct 结构体名 *变量名;下面是一个定义结构体指针的实例:
//结构体
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 };
//结构体指针
struct stu *pstu = &stu1;也可以在定义结构体的同时定义结构体指针:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 }, *pstu = &stu1;注意,结构体变量名和数组名不同,数组名在表达式中会被转换为数组指针,而结构体变量名不会,无论在任何表达式中它表示的都是整个集合本身,要想取得结构体变量的地址,必须在前面加&,所以给 pstu 赋值只能写作:
struct stu *pstu = &stu1;而不能写作:
struct stu *pstu = stu1;获取结构体成员
通过结构体指针可以获取结构体成员,一般形式为:
(*pointer).memberName或者:
pointer->memberName第一种写法中,.的优先级高于*,(*pointer)两边的括号不能少。如果去掉括号写作*pointer.memberName,那么就等效于*(pointer.memberName),这样意义就完全不对了。
第二种写法中,->是一个新的运算符,习惯称它为"箭头",有了它,可以通过结构体指针直接取得结构体成员;这也是->在C语言中的唯一用途。
1 结构体指针的使用:
#include <stdio.h>
int main(){
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 }, *pstu = &stu1;
//读取结构体成员的值
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", (*pstu).name, (*pstu).num, (*pstu).age, (*pstu).group, (*pstu).score);
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", pstu->name, pstu->num, pstu->age, pstu->group, pstu->score);
return 0;
}运行结果:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
2.结构体【数组】指针的使用:
#include <stdio.h>
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}stus[] = {
{"Zhou ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"Liu fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
}, *ps;
int main(){
//求数组长度
int len = sizeof(stus) / sizeof(struct stu); //长度5 总大小120字节/ 每个24字节
printf("Name\t\tNum\tAge\tGroup\tScore\t\n");
for(ps=stus; ps<stus+len; ps++){
printf("%s\t%d\t%d\t%c\t%.1f\n", ps->name, ps->num, ps->age, ps->group, ps->score);
}
return 0;
}
ps = stus; 这行代码是将结构体数组 stus 的首地址赋值给结构体指针 ps。因此,ps 现在指向 stus 数组的第一个元素。
stus + len 是一个指针运算。len 是数组 stus 的长度,也就是数组中结构体的数量。stus + len 表示从 stus 的首地址开始,跳过 len 个 stu 结构体所占用的内存大小,得到一个新的地址。这个地址指向的是 stus 数组末尾的下一个位置(即数组外的内存位置)。
Name Num Age Group Score
Zhou ping 5 18 C 145.0
Zhang ping 4 19 A 130.5
Liu fang 1 18 A 148.5
Cheng ling 2 17 F 139.0
Wang ming 3 17 B 144.5结构体指针作为函数参数
结构体变量名代表的是整个集合本身,作为函数参数时传递的整个集合,也就是所有成员,而不是像数组一样被编译器转换成一个指针。如果结构体成员较多,尤其是成员为数组时,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速。
计算全班学生的总成绩、平均成绩和以及 140 分以下的人数:
#include <stdio.h>
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}stus[] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};
void average(struct stu *ps, int len); // 定义结构体指针作形参
int main(){
int len = sizeof(stus) / sizeof(struct stu);
average(stus, len);
return 0;
}
void average(struct stu *ps, int len){
int i, num_140 = 0;
float average, sum = 0;
for(i=0; i<len; i++){
sum += (ps + i) -> score;
if((ps + i)->score < 140) num_140++;
}
printf("sum=%.2f\naverage=%.2f\nnum_140=%d\n", sum, sum/5, num_140);
}运行结果:
sum=707.50
average=141.50
num_140=2
C语言枚举类型
在实际编程中,有些数据的取值往往是有限的,只能是非常少量的整数,并且最好为每个值都取一个名字,以方便在后续代码中使用,比如一个星期只有七天,一年只有十二个月,一个班每周有六门课程等。
以每周七天为例,我们可以使用#define命令来给每天指定一个名
#include <stdio.h>
#define Mon 1
#define Tues 2
#define Wed 3
#define Thurs 4
#define Fri 5
#define Sat 6
#define Sun 7
int main(){
int day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}运行结果:
5↙
Friday
#define命令虽然能解决问题,但也带来了不小的副作用,导致宏名过多,代码松散,看起来总有点不舒服。C语言提供了一种枚举(Enum)类型,能够列出所有可能的取值,并给它们取一个名字。
枚举类型的定义形式为:
enum typeName{ valueName1, valueName2, valueName3, ...... };enum是一个新的关键字,专门用来定义枚举类型,这也是它在C语言中的唯一用途;typeName是枚举类型的名字;valueName1, valueName2, valueName3, ......是每个值对应的名字的列表。注意最后的;不能少。
例如,列出一个星期有几天:
enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun };
可以看到,我们仅仅给出了名字,却没有给出名字对应的值,这是因为枚举值默认从 0 开始,往后逐个加 1(递增);也就是说,week 中的 Mon、Tues ...... Sun 对应的值分别为 0、1 ...... 6。我们也可以给每个名字都指定一个值:
enum week{ Mon = 1, Tues = 2, Wed = 3, Thurs = 4, Fri = 5, Sat = 6, Sun = 7 };更为简单的方法是只给第一个名字指定值:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };
这样枚举值就从 1 开始递增,跟上面的写法是等效的。枚举是一种类型,通过它可以定义枚举变量:
enum week a, b, c;可以在定义枚举类型的同时定义变量:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } a, b, c;有了枚举变量,就可以把列表中的值赋给它:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };
enum week a = Mon, b = Wed, c = Sat;或者:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } a = Mon, b = Wed, c = Sat;【示例】判断用户输入的是星期几:
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}运行结果:
4↙
Thursday
需要注意的两点是:
-
枚举列表中的 Mon、Tues、Wed 这些标识符的作用范围是全局的(严格来说是 main() 函数内部),不能再定义与它们名字相同的变量。
-
Mon、Tues、Wed 等都是常量,不能对它们赋值,只能将它们的值赋给其他的变量。
对于上面的代码**,在编译的某个时刻**会变成类似下面的样子:
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day;
scanf("%d", &day);
switch(day){
case 1: puts("Monday"); break;
case 2: puts("Tuesday"); break;
case 3: puts("Wednesday"); break;
case 4: puts("Thursday"); break;
case 5: puts("Friday"); break;
case 6: puts("Saturday"); break;
case 7: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}Mon、Tues、Wed 这些名字都被替换成了对应的数字。这意味着,Mon、Tues、Wed 等都不是变量,它们不占用数据区(常量区、全局数据区、栈区和堆区)的内存,而是直接被编译到命令里面,放到代码区,所以不能用&取得它们的地址。这就是枚举的本质。
case 关键字后面必须是一个整数,或者是结果为整数的表达式,但不能包含任何变量,正是由于 Mon、Tues、Wed 这些名字最终会被替换成一个整数,所以它们才能放在 case 后面。
枚举类型变量需要存放的是一个整数,我猜测它的长度和 int 应该相同,下面来验证一下:
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day = Mon;
printf("%d, %d, %d, %d, %d\n", sizeof(enum week), sizeof(day), sizeof(Mon), sizeof(Wed), sizeof(int) );
return 0;
}运行结果:
4, 4, 4, 4, 4
C语言共用体
通过前面的讲解,我们知道结构体(Struct)是一种构造类型或复杂类型,它可以包含多个类型不同的成员。在C语言中,还有另外一种和结构体非常类似的语法,叫做共用体(Union),它的定义格式为:
union 共用体名{
成员列表
};
共用体有时也被称为联合或者联合体,这也是 Union 这个单词的本意。区别:
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
共用体创建变量,例如:
union data{
int n;
char ch;
double f;
};
union data a, b, c;面是先定义共用体,再创建变量,也可以在定义共用体的同时创建变量:
union data{
int n;
char ch;
double f;
} a, b, c;如果不再定义新的变量,也可以将共用体的名字省略:
union{
int n;
char ch;
double f;
} a, b, c;共用体 data 中,成员 f 占用的内存最多,为 8 个字节,所以 data 类型的变量(也就是 a、b、c)也占用 8 个字节的内存,请看下面的演示:
共用体的应用
共用体在一般的编程中应用较少,在单片机中应用较多。对于 PC 机,经常使用到的一个实例是: 现有一张关于学生信息和教师信息的表格。学生信息包括姓名、编号、性别、职业、分数,教师的信息包括姓名、编号、性别、职业、教学科目。请看下面的表格:
| Name | Num | Sex | Profession | Score / Course |
|---|---|---|---|---|
| HanXiaoXiao | 501 | f | s | 89.5 |
| YanWeiMin | 1011 | m | t | math |
| LiuZhenTao | 109 | f | t | English |
| ZhaoFeiYan | 982 | m | s | 95.0 |
f 和 m 分别表示女性和男性,s 表示学生,t 表示教师。可以看出,学生和教师所包含的数据是不同的。现在要求把这些信息放在同一个表格中,并设计程序输入人员信息然后输出。
如果把每个人的信息都看作一个结构体变量的话,那么教师和学生的前 4 个成员变量是一样的,第 5 个成员变量可能是 score 或者 course。当第 4 个成员变量的值是 s 的时候,第 5 个成员变量就是 score;当第 4 个成员变量的值是 t 的时候,第 5 个成员变量就是 course。
#include <stdio.h>
#include <stdlib.h>
#define TOTAL 4 //人员总数
struct{
char name[20];
int num;
char sex;
char profession;
union{
float score;
char course[20];
} sc;
} bodys[TOTAL];
int main(){
int i;
//输入人员信息
for(i=0; i<TOTAL; i++){
printf("Input info: ");
scanf("%s %d %c %c", bodys[i].name, &(bodys[i].num), &(bodys[i].sex), &(bodys[i].profession));
if(bodys[i].profession == 's'){ //如果是学生
scanf("%f", &bodys[i].sc.score);
}else{ //如果是老师
scanf("%s", bodys[i].sc.course);
}
fflush(stdin);
}
//输出人员信息
printf("\nName\t\tNum\tSex\tProfession\tScore / Course\n");
for(i=0; i<TOTAL; i++){
if(bodys[i].profession == 's'){ //如果是学生
printf("%s\t%d\t%c\t%c\t\t%f\n", bodys[i].name, bodys[i].num, bodys[i].sex, bodys[i].profession, bodys[i].sc.score);
}else{ //如果是老师
printf("%s\t%d\t%c\t%c\t\t%s\n", bodys[i].name, bodys[i].num, bodys[i].sex, bodys[i].profession, bodys[i].sc.course);
}
}
return 0;
}运行结果:
Input info: HanXiaoXiao 501 f s 89.5↙
Input info: YanWeiMin 1011 m t math↙
Input info: LiuZhenTao 109 f t English↙
Input info: ZhaoFeiYan 982 m s 95.0↙
Name Num Sex Profession Score / Course
HanXiaoXiao 501 f s 89.500000
YanWeiMin 1011 m t math
LiuZhenTao 109 f t English
ZhaoFeiYan 982 m s 95.000000
C语言位域
有些数据在存储时并不需要占用一个完整的字节,只需要占用一个或几个二进制位即可。例如开关只有通电和断电两种状态,用 0 和 1 表示足以,也就是用一个二进位。正是基于这种考虑,C语言又提供了一种叫做位域的数据结构。
在结构体定义时,我们可以指定某个成员变量所占用的二进制位数(Bit),这就是位域。请看下面的例子:
struct bs{
unsigned m;
unsigned n: 4;
unsigned char ch: 6;
};:后面的数字用来限定成员变量占用的位数。成员 m 没有限制,根据数据类型即可推算出它占用 4 个字节(Byte)的内存。成员 n、ch 被:后面的数字限制,不能再根据数据类型计算长度,它们分别占用 4、6 位(Bit)的内存。
n、ch 的取值范围非常有限,数据稍微大些就会发生溢出,请看下面的例子:
#include <stdio.h>
int main(){
struct bs{
unsigned m;
unsigned n: 4;
unsigned char ch: 6;
} a = { 0xad, 0xE, '$'};
//第一次输出
printf("%#x, %#x, %c\n", a.m, a.n, a.ch);
//更改值后再次输出
a.m = 0xb8901c;
a.n = 0x2d;
a.ch = 'z';
printf("%#x, %#x, %c\n", a.m, a.n, a.ch);
return 0;
}运行结果:
0xad, 0xe, $
0xb8901c, 0xd, :
对于 n 和 ch,第一次输出的数据是完整的,第二次输出的数据是残缺的。
第一次输出时,n、ch 的值分别是 0xE、0x24('$' 对应的 ASCII 码为 0x24),换算成二进制是 1110、10 0100,都没有超出限定的位数,能够正常输出。
第二次输出时,n、ch 的值变为 0x2d、0x7a('z' 对应的 ASCII 码为 0x7a),换算成二进制分别是 10 1101、111 1010,都超出了限定的位数。超出部分被直接截去,剩下 1101、11 1010,换算成十六进制为 0xd、0x3a(0x3a 对应的字符是 :)。
C语言标准规定,位域的宽度不能超过它所依附的数据类型的长度。通俗地讲,成员变量都是有类型的,这个类型限制了成员变量的最大长度,:后面的数字不能超过这个长度。
例如上面的 bs,n 的类型是 unsigned int,长度为 4 个字节,共计 32 位,那么 n 后面的数字就不能超过 32;ch 的类型是 unsigned char,长度为 1 个字节,共计 8 位,那么 ch 后面的数字就不能超过 8。
总结上面案例:
位域技术就是在成员变量所占用的内存中选出一部分位宽来存储数据。
在 ANSI C 中,这几种数据类型是 int、signed int 和 unsigned int(int 默认就是 signed int);到了 C99,_Bool 也被支持了但编译器在具体实现时都进行了扩展,额外支持了 char、signed char、unsigned char 以及 enum 类型,所以上面的代码虽然不符合C语言标准,但它依然能够被编译器支持。
位域的存储
https://c.biancheng.net/view/2037.html位域的具体存储规则如下:
-
当相邻成员的类型相同时,如果它们的位宽之和小于类型的 sizeof 大小,那么后面的成员紧邻前一个成员存储,直到不能容纳为止;如果它们的位宽之和大于类型的 sizeof 大小,那么后面的成员将从新的存储单元开始,其偏移量为类型大小的整数倍。
#include <stdio.h>
int main(){
struct bs{
unsigned m: 6;
unsigned n: 12;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
return 0;
}
运行结果:
4
m、n、p 的类型都是 unsigned int,sizeof 的结果为 4 个字节(Byte),也即 32 个位(Bit)。m、n、p 的位宽之和为 6+12+4 = 22,小于 32,所以它们会挨着存储,中间没有缝隙。
如果将成员 m 的位宽改为 22,那么输出结果将会是 8,因为 22+12 = 34,大于 32,n 会从新的位置开始存储,相对 m 的偏移量是 sizeof(unsigned int),也即 4 个字节。
C语言位运算
所谓位运算,就是对一个比特(Bit)位进行操作。在《数据在内存中的存储》一节中讲到,比特(Bit)是一个电子元器件,8个比特构成一个字节(Byte),它已经是粒度最小的可操作单元了。
C语言提供了六种位运算符:
| 运算符 | & | | | ^ | ~ | << | >> |
|---|---|---|---|---|---|---|
| 说明 | 按位与 | 按位或 | 按位异或 | 取反 | 左移 | 右移 |
按位与运算(&)
一个比特(Bit)位只有 0 和 1 两个取值,只有参与&运算的两个位都为 1 时,结果才为 1,否则为 0。例如1&1为 1,0&0为 0,1&0也为 0,这和逻辑运算符&&非常类似。
C语言中不能直接使用二进制,&两边的操作数可以是十进制、八进制、十六进制,它们在内存中最终都是以二进制形式存储,&就是对这些内存中的二进制位进行运算。其他的位运算符也是相同的道理。
例如,9 & 5可以转换成如下的运算:
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
& 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0001 (1 在内存中的存储)也就是说,按位与运算会对参与运算的两个数的所有二进制位进行&运算,9 & 5的结果为 1。
又如,-9 & 5可以转换成如下的运算:
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
& 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)-9 & 5的结果是 5。
按位与示例:
#include <stdio.h>
int main(){
int n = 0X8FA6002D;
printf("%d, %d, %X\n", 9 & 5, -9 & 5, n & 0XFFFF);
return 0;
}运行结果:
1, 5, 2D
按位或运算(|)
参与|运算的两个二进制位有一个为 1 时,结果就为 1,两个都为 0 时结果才为 0。例如1|1为1,0|0为0,1|0为1,这和逻辑运算中的||非常类似。
例如,9 | 5可以转换成如下的运算:
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
| 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1101 (13 在内存中的存储)9 | 5的结果为 13。
又如,-9 | 5可以转换成如下的运算:
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
| 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)-9 | 5的结果是 -9。
按位或示例:
#include <stdio.h>
int main(){
int n = 0X2D;
printf("%d, %d, %X\n", 9 | 5, -9 | 5, n | 0XFFFF0000);
return 0;
}
运行结果:按位异或运算(^)
参与^运算两个二进制位不同时,结果为 1,相同时结果为 0。例如0^1为1,0^0为0,1^1为0。
例如,9 ^ 5可以转换成如下的运算:
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
^ 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1100 (12 在内存中的存储)9 ^ 5的结果为 12。
又如,-9 ^ 5可以转换成如下的运算:
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
^ 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0010 (-14 在内存中的存储)-9 ^ 5的结果是 -14。
按位异或示例:
#include <stdio.h>
int main(){
unsigned n = 0X0A07002D;
printf("%d, %d, %X\n", 9 ^ 5, -9 ^ 5, n ^ 0XFFFF0000);
return 0;
}
运行结果:
12, -14, F5F8002D取反运算(~)
取反运算符~为单目运算符,右结合性,作用是对参与运算的二进制位取反。例如~1为0,~0为1,这和逻辑运算中的!非常类似。
例如,~9可以转换为如下的运算:
~ 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
-----------------------------------------------------------------------------------
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0110 (-10 在内存中的存储)所以~9的结果为 -10。
例如,~-9可以转换为如下的运算:
~ 1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-----------------------------------------------------------------------------------
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1000 (8 在内存中的存储)所以~-9的结果为 8。
取反示例:
#include <stdio.h>
int main(){
printf("%d, %d\n", ~9, ~-9 );
return 0;
}
运行结果:
-10, 8左移运算(<<)
左移运算符<<用来把操作数的各个二进制位全部左移若干位,高位丢弃,低位补0。
例如,9<<3可以转换为如下的运算, 将数字9(在二进制中为 1001)向左移动3位:
<< 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
-----------------------------------------------------------------------------------
0000 0000 -- 0000 0000 -- 0000 0000 -- 0100 1000 (72 在内存中的存储)9 的二进制表示为 1001 ,左移3位后,得到 1001000。将这个二进制数转换回十进制 72, 所以9<<3的结果为 72。
又如,(-9)<<3可以转换为如下的运算:
<< 1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-----------------------------------------------------------------------------------
1111 1111 -- 1111 1111 -- 1111 1111 -- 1011 1000 (-72 在内存中的存储) 所以(-9)<<3的结果为 -72
左移示例:
#include <stdio.h>
int main(){
printf("%d, %d\n", 9<<3, (-9)<<3 );
return 0;
}
运行结果:
72, -72右移运算(>>)
右移运算符>>用来把操作数的各个二进制位全部右移若干位,低位丢弃,高位补 0 或 1。如果数据的最高位是 0,那么就补 0;如果最高位是 1,那么就补 1。
例如,9>>3可以转换为如下的运算:
>> 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
-----------------------------------------------------------------------------------
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0001 (1 在内存中的存储)所以9>>3的结果为 1。
又如,(-9)>>3可以转换为如下的运算:
>> 1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-----------------------------------------------------------------------------------
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 1110 (-2 在内存中的存储) 所以(-9)>>3的结果为 -2
右移示例:
int main(){
printf("%d, %d\n", 9>>3, (-9)>>3 );
return 0;
}
运行结果:
1, -2C语言typedef的用法
C语言允许为一个数据类型起一个新的别名,就像给人起"绰号"一样;起别名的目的不是为了提高程序运行效率,而是为了编码方便。
struct stu stu1;类型别名定义
需要强调的是,typedef 是赋予现有类型一个新的名字,而不是创建新的类型。为了"见名知意",请尽量使用含义明确的标识符,并且尽量大写。
使用关键字 typedef 可以为类型起一个新的别名。typedef 的用法一般为:
typedef oldName newName;oldName 是类型原来的名字,newName 是类型新的名字。例如:
typedef int INTEGER;
INTEGER a, b;
a = 1;
b = 2;INTEGER a, b;等效于int a, b;。
typedef 还可以给数组、指针、结构体等类型定义别名
typedef char ARRAY20[20];
它等价于:
char a1[20], a2[20], s1[20], s2[20];结构体类型定义别名:
typedef struct stu{
char name[20];
int age;
char sex;
} STU;STU 是 struct stu 的别名,可以用 STU 定义结构体变量:
STU body1,body2;指针类型定义别名:
typedef int (*PTR_TO_ARR)[4];
表示 PTR_TO_ARR 是类型int * [4]的别名指针定义别名:
#include <stdio.h>
typedef char (*PTR_TO_ARR)[30];
typedef int (*PTR_TO_FUNC)(int, int);
int max(int a, int b){
return a>b ? a : b;
}
char str[3][30] = {
"http://c.biancheng.net",
"C语言中文网",
"C-Language"
};
int main(){
PTR_TO_ARR parr = str;
PTR_TO_FUNC pfunc = max;
int i;
printf("max: %d\n", (*pfunc)(10, 20));
for(i=0; i<3; i++){
printf("str[%d]: %s\n", i, *(parr+i));
}
return 0;
}运行结果:
max: 20
str0: http://c.biancheng.net
str1: C语言中文网
str2: C-Language
typedef 和 #define 的区别
typedef 看成一种彻底的"封装"类型,声明之后不能再往里面增加别的东西。
#define INTERGE int
unsigned INTERGE n; //没问题
typedef int INTERGE;
unsigned INTERGE n; //错误,不能在 INTERGE 前面添加 unsignedC语言const的用法
有时候我们希望定义这样一种变量,它的值不能被改变,在整个作用域中都保持固定。
使用const关键字对变量加以限定:
const int MaxNum = 100; //班级的最大人数
MaxNum = 90; //错误,试图向 const 变量写入数据我们经常将 const 变量称为常量(Constant)。创建常量的格式通常为:
const type name = value;const 和 type 都是用来修饰变量的,它们的位置可以互换,也就是将 type 放在 const 前面:
type const name = value;但我们通常采用第一种方式,不采用第二种方式。另外建议将常量名的首字母大写,以提醒程序员这是个常量。
由于常量一旦被创建后其值就不能再改变,所以常量必须在定义的同时赋值(初始化),后面的任何赋值行为都将引发错误。一如既往,初始化常量可以使用任意形式的表达式,如下所示:
#include <stdio.h>
int getNum(){
return 100;
}
int main(){
int n = 90;
const int MaxNum1 = getNum(); //运行时初始化
const int MaxNum2 = n; //运行时初始化
const int MaxNum3 = 80; //编译时初始化
printf("%d, %d, %d\n", MaxNum1, MaxNum2, MaxNum3);
return 0;
}运行结果:
100, 90, 80
const 和指针
const 也可以和指针变量一起使用,这样可以限制指针变量本身,也可以限制指针指向的数据。const 和指针一起使用会有几种不同的顺序,如下所示:
const int *p1;
int const *p2;
int * const p3;在最后一种情况下,指针是只读的,也就是 p3 本身的值不能被修改;在前面两种情况下,指针所指向的数据是只读的,也就是 p1、p2 本身的值可以修改(指向不同的数据),但它们指向的数据不能被修改。
const 和函数形参
在C语言中,单独定义 const 变量没有明显的优势,完全可以使用#define命令代替。const 通常用在函数形参中,如果形参是一个指针,为了防止在函数内部修改指针指向的数据,就可以用 const 来限制。
在C语言标准库中,有很多函数的形参都被 const 限制了,下面是部分函数的原型:
size_t strlen ( const char * str );
int strcmp ( const char * str1, const char * str2 );
char * strcat ( char * destination, const char * source );
char * strcpy ( char * destination, const char * source );
int system (const char* command);
int puts ( const char * str );
int printf ( const char * format, ... );我们自己在定义函数时也可以使用 const 对形参加以限制,例如查找字符串中某个字符出现的次数:
#include <stdio.h>
size_t strnchr(const char *str, char ch){
int i, n = 0, len = strlen(str);
for(i=0; i<len; i++){
if(str[i] == ch){
n++;
}
}
return n;
}
int main(){
char *str = "http://c.biancheng.net";
char ch = 't';
int n = strnchr(str, ch);
printf("%d\n", n);
return 0;
}运行结果:
3
根据 strnchr() 的功能可以推断,函数内部要对字符串 str 进行遍历,不应该有修改的动作,用 const 加以限制,不但可以防止由于程序员误操作引起的字符串修改,还可以给用户一个提示,函数不会修改你提供的字符串,请你放心。
const 和非 const 类型转换
也就是说,const char *和char *是不同的类型,不能将const char *类型的数据赋值给char *类型的变量。但反过来是可以的,编译器允许将char *类型的数据赋值给const char *类型的变量。
#include <stdio.h>
void func(char *str){ }
int main(){
const char *str1 = "c.biancheng.net";
char *str2 = str1;
func(str1);
return 0;
}第5、6行代码分别通过赋值、传参(传参的本质也是赋值)将 const 类型的数据交给了非 const 类型的变量,编译器不会容忍这种行为,会给出警告,甚至直接报错。
C语言随机数生,rand和srand用法
在实际编程中,我们经常需要生成随机数,例如,贪吃蛇游戏中在随机的位置出现食物,扑克牌游戏中随机发牌。
们一般使用 <stdlib.h> 头文件中的 rand() 函数来生成随机数,它的用法为:
int rand (void);rand() 会随机生成一个位于 0 ~ RAND_MAX 之间的整数。
RAND_MAX 是 <stdlib.h> 头文件中的一个宏,它用来指明 rand() 所能返回的随机数的最大值。C语言标准并没有规定 RAND_MAX 的具体数值,只是规定它的值至少为 32767。在实际编程中,我们也不需要知道 RAND_MAX 的具体值,把它当做一个很大的数来对待即可。
随机数生成的实例:
#include <stdio.h>
#include <stdlib.h>
int main(){
int a = rand();
printf("%d\n",a);
return 0;
}运行结果举例:
41
多次运行上面的代码,你会发现每次产生的随机数都一样,这是怎么回事呢?为什么随机数并不随机呢?
注意,需要种子:
如果没有用 srand() 函数来设置随机数种子,rand() 会每次从相同的初始状态开始,因此每次产生的随机数序列也是相同的。
为了解决这个问题,你通常需要在程序开始时使用当前时间(或其他变化的值)作为种子来初始化随机数生成器。这可以通过调用 srand() 函数并传递 time(NULL) 作为参数来实现,time(NULL) 返回从1970年1月1日以来的秒数。
使用 <time.h> 头文件中的 time() 函数即可得到当前的时间(精确到秒),就像下面这样:
srand((unsigned)time(NULL));
#include <stdio.h>
#include <stdlib.h>
#include <time.h> // 引入time.h头文件来使用time函数
int main(){
int a;
// 使用当前时间作为随机数种子
srand((unsigned int)time(NULL));
a = rand();
printf("%d", a);
return 0;
}
多次运行程序,会发现每次生成的随机数都不一样了。
srand(...): 这是设置随机数种子的函数。通过调用srand并传入一个变化的种子值(如当前时间),我们可以确保每次运行程序时都得到不同的随机数序列。
time(NULL): 这是一个调用到time函数的表达式,它返回从1970年1月1日(称为Unix纪元)以来的秒数。当传入NULL作为参数时,time函数返回当前时间。这个时间通常是一个time_t类型的值,它在不同的系统和编译器上可能有不同的定义,但通常足以表示从Unix纪元开始的秒数。
(unsigned int): 这是一个类型转换,它将time_t类型的值转换为unsigned int类型。这是因为srand函数通常需要一个无符号整数作为参数。虽然在现代系统上time_t到unsigned int的转换通常是安全的,但在某些极端情况下(比如系统运行了非常长的时间,导致时间值超过了unsigned int能表示的范围),这可能会导致问题。生成一定范围内的随机数
在实际开发中,我们往往需要一定范围内的随机数,过大或者过小都不符合要求,那么,如何产生一定范围的随机数呢?我们可以利用取模的方法:
int a = rand() % 10; //产生0~9的随机数,注意10会被整除如果要规定上下限:
int a = rand() % 51 + 13; //产生13~63的随机数
51:用于定义取模运算的范围,即随机数的余数应该在0到50之间。(包括0但不包括51)
13:用于将取模后的结果范围上移,从0到50变为13到63。分析:取模即取余,rand()%51+13我们可以看成两部分:rand()%51是产生 0~50 的随机数,后面+13保证 a 最小只能是 13,最大就是 50+13=63。
最后给出产生 13~63 范围内随机数的完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(){
int a;
srand((unsigned)time(NULL));
a = rand() % 51 + 13;
printf("%d\n",a);
return 0;
}连续生成随机数
有时候我们需要一组随机数(多个随机数),该怎么生成呢?很容易想到的一种解决方案是使用循环,每次循环都重新播种,请看下面的代码:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
int a, i;
//使用for循环生成10个随机数
for (i = 0; i < 10; i++) {
srand((unsigned)time(NULL));
a = rand();
printf("%d ", a);
}
return 0;
}运行结果举例:
8 8 8 8 8 8 8 8 8 8
运行结果非常奇怪,每次循环我们都重新播种了呀,为什么生成的随机数都一样呢?
这是因为,for 循环运行速度非常快,在一秒之内就运行完成了,而 time() 函数得到的时间只能精确到秒,所以每次循环得到的时间都是一样的,这样一来,种子也就是一样的,随机数也就一样了。
要在一秒内生成连续的随机数,你需要将 srand 的调用移出循环,只在程序开始时设置一次种子。然后,你可以在循环内部多次调用 rand() 来生成随机数。以下是修改后的代码:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
int a, i;
// 只在程序开始时设置一次随机数种子
srand((unsigned)time(NULL));
// 使用for循环生成10个随机数
for (i = 0; i < 10; i++) {
a = rand(); // 在循环内部调用rand()生成随机数
printf("%d ", a);
}
printf("\n"); // 打印一个换行符,使输出更整洁
return 0;
}C语言中的文件
文件的概念:如常见的 Word 文档、txt 文件、源文件等。文件是数据源的一种,最主要的作用是保存数据。
在操作系统中,为了统一对各种硬件的操作,简化接口,不同的硬件设备也都被看成一个文件。对这些文件的操作,等同于对磁盘上普通文件的操作。例如:
- 通常把显示器称为标准输出文件,printf 就是向这个文件输出数据;
- 通常把键盘称为标准输入文件,scanf 就是从这个文件读取数据。
常见硬件设备所对应的文件
| 文件 | 硬件设备 |
|---|---|
| stdin | 标准输入文件,一般指键盘;scanf()、getchar() 等函数默认从 stdin 获取输入。 |
| stdout | 标准输出文件,一般指显示器;printf()、putchar() 等函数默认向 stdout 输出数据。 |
| stderr | 标准错误文件,一般指显示器;perror() 等函数默认向 stderr 输出数据(后续会讲到)。 |
| stdprn | 标准打印文件,一般指打印机。 |
操作文件的正确流程为:打开文件 --> 读写文件 --> 关闭文件。文件在进行读写操作之前要先打开,使用完毕要关闭。
在C语言中,文件有多种读写方式,可以一个字符一个字符地读取,也可以读取一整行,还可以读取若干个字节。文件的读写位置也非常灵活,可以从文件开头读取,也可以从中间位置读取。
数据从数据源到程序(内存)的过程叫做输入流(Input Stream),从程序(内存)到数据源的过程叫做输出流(Output Stream)。
输入输出(Input output,IO)是指程序(内存)与外部设备(键盘、显示器、磁盘、其他计算机等)进行交互的操作。
C语言fopen函数的用法
在C语言中,操作文件之前必须先打开文件;所谓"打开文件",就是让程序和文件建立连接的过程。
fopen() 会获取文件信息,包括文件名、文件状态、当前读写位置等,并将这些信息保存到一个 FILE 类型的结构体变量中,然后将该变量的地址返回。
使用 <stdio.h> 头文件中的 fopen() 函数即可打开文件,它的用法为:
FILE *fopen(char *filename, char *mode);filename为文件名(包括文件路径),mode为打开方式,它们都是字符串。
fopen() 函数的返回值
如果希望接收 fopen() 的返回值,就需要定义一个 FILE 类型的指针。例如:
FILE *fp = fopen("demo.txt", "r");表示以"只读"方式打开当前目录下的 demo.txt 文件,并使 fp 指向该文件,这样就可以通过 fp 来操作 demo.txt 了。fp 通常被称为文件指针。
再来看一个例子:
FILE *fp = fopen("D:\\demo.txt","rb+");表示以二进制方式打开 D 盘下的 demo.txt 文件,允许读和写。
判断文件是否打开成功
打开文件出错时,fopen() 将返回一个空指针,也就是 NULL,我们可以利用这一点来判断文件是否打开成功,请看下面的代码:
FILE *fp;
if( (fp=fopen("D:\\demo.txt","rb")) == NULL ){
printf("Fail to open file!\n");
exit(0); //退出程序(结束程序)
}我们通过判断 fopen() 的返回值是否和 NULL 相等来判断是否打开失败:如果 fopen() 的返回值为 NULL,那么 fp 的值也为 NULL,此时 if 的判断条件成立,表示文件打开失败。
fopen() 函数的打开方式
调用 fopen() 函数时,这些信息都必须提供,称为"文件打开方式"。最基本的文件打开方式有以下几种:
| 控制读写权限的字符串(必须指明) | |
|---|---|
| 打开方式 | 说明 |
| "r" | 以"只读"方式打开文件。只允许读取,不允许写入。文件必须存在,否则打开失败。 |
| "w" | 以"写入"方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。 |
| "a" | 以"追加"方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。 |
| "r+" | 以"读写"方式打开文件。既可以读取也可以写入,也就是随意更新文件。文件必须存在,否则打开失败。 |
| "w+" | 以"写入/更新"方式打开文件,相当于w和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。 |
| "a+" | 以"追加/更新"方式打开文件,相当于a和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。 |
| 控制读写方式的字符串(可以不写) | |
| 打开方式 | 说明 |
| "t" | 文本文件。如果不写,默认为"t"。 |
| "b" | 二进制文件。 |
读写权限和读写方式可以组合使用,但是必须将读写方式放在读写权限的中间或者尾部(换句话说,不能将读写方式放在读写权限的开头)。例如:
-
将读写方式放在读写权限的末尾:"rb"、"wt"、"ab"、"r+b"、"w+t"、"a+t"
-
将读写方式放在读写权限的中间:"rb+"、"wt+"、"ab+"
整体来说,文件打开方式由 r、w、a、t、b、+ 六个字符拼成,各字符的含义是:
- r(read):读
- w(write):写
- a(append):追加
- t(text):文本文件
- b(binary):二进制文件
- +:读和写
关闭文件
文件一旦使用完毕,应该用 fclose() 函数把文件关闭,以释放相关资源,避免数据丢失。fclose() 的用法为:
int fclose(FILE *fp);fp 为文件指针。例如:
fclose(fp);文件正常关闭时,fclose() 的返回值为0,如果返回非零值则表示有错误发生。
#include <stdio.h>
#include <stdlib.h>
#define N 100
int main() {
FILE *fp;
char str[N + 1];
//判断文件是否打开失败
if ( (fp = fopen("d:\\demo.txt", "rt")) == NULL ) {
puts("Fail to open file!");
exit(0);
}
//循环读取文件的每一行数据
while( fgets(str, N, fp) != NULL ) {
printf("%s", str);
}
//操作结束后关闭文件
fclose(fp);
return 0;
}fgets 是一个用于从指定的流中读取一行数据的函数。它的原型通常如下:
char *fgets(char *str, int n, FILE *stream);.
str:这是一个指向字符数组的指针,用于存储从流中读取的数据。
n:这是要读取的最大字符数(包括结尾的空字符)。
stream:这是要读取数据的文件流。C语言fgetc和fputc函数用法
向文件中写入一个字符。主要使用两个函数,分别是 fgetc() 和 fputc()。
字符读取函数 fgetc
fgetc 是 file get char 的缩写,意思是从指定的文件中读取一个字符。fgetc() 的用法为:
int fgetc (FILE *fp);fp 为文件指针。fgetc() 读取成功时返回读取到的字符,读取到文件末尾或读取失败时返回EOF。
fgetc() 的用法举例:
char ch;
FILE *fp = fopen("D:\\demo.txt", "r+");
ch = fgetc(fp);表示从D:\\demo.txt文件中读取一个字符,并保存到变量 ch 中。
注意:
这个文件内部的位置指针与C语言中的指针不是一回事。位置指针仅仅是一个标志,表示文件读写到的位置,也就是读写到第几个字节,它不表示地址。文件每读写一次,位置指针就会移动一次,它不需要你在程序中定义和赋值,而是由系统自动设置,对用户是隐藏的。
【示例】在屏幕上显示 D:\demo.txt 文件的内容。
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//如果文件不存在,给出提示并退出
if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//每次读取一个字节,直到读取完毕
while( (ch=fgetc(fp)) != EOF ){
putchar(ch);
}
putchar('\n'); //输出换行符
fclose(fp);
return 0;
}while 循环的条件为(ch=fgetc(fp)) != EOF。fget() 每次从位置指针所在的位置读取一个字符,并保存到变量 ch,位置指针向后移动一个字节。当文件指针移动到文件末尾时,fget() 就无法读取字符了,于是返回 EOF,表示文件读取结束了
对 EOF 的说明
EOF 本来表示文件末尾,意味着读取结束,但是很多函数在读取出错时也返回 EOF,那么当返回 EOF 时,到底是文件读取完毕了还是读取出错了?我们可以借助 stdio.h 中的两个函数来判断,分别是 feof() 和 ferror()。
feof() 函数用来判断文件内部指针是否指向了文件末尾,它的原型是:
int feof ( FILE * fp );
当指向文件末尾时返回非零值,否则返回零值。ferror() 函数用来判断文件操作是否出错,它的原型是:
int ferror ( FILE *fp );出错时返回非零值,否则返回零值。
需要说明的是,文件出错是非常少见的情况,上面的示例基本能够保证将文件内的数据读取完毕。如果追求完美,也可以加上判断并给出提示:
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//如果文件不存在,给出提示并退出
if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//每次读取一个字节,直到读取完毕
while( (ch=fgetc(fp)) != EOF ){
putchar(ch);
}
putchar('\n'); //输出换行符
if(ferror(fp)){
puts("读取出错");
}else{
puts("读取成功");
}
fclose(fp);
return 0;
}
这样,不管是出错还是正常读取,都能够做到心中有数。字符写入函数 fputc
fputc 是 file output char 的所以,意思是向指定的文件中写入一个字符。fputc() 的用法为:
int fputc ( int ch, FILE *fp );ch 为要写入的字符,fp 为文件指针。fputc() 写入成功时返回写入的字符,失败时返回 EOF,返回值类型为 int 也是为了容纳这个负数。例如:
fputc('a', fp);或者:
char ch = 'a';
fputc(ch, fp);表示把字符 'a' 写入fp所指向的文件中。
【示例】从键盘输入一行字符,写入文件。
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//判断文件是否成功打开
if( (fp=fopen("D:\\demo.txt","wt+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
printf("Input a string:\n");
//每次从键盘读取一个字符并写入文件
while ( (ch=getchar()) != '\n' ){
fputc(ch,fp);
}
fclose(fp);
return 0;
}getchar() 用于从标准输入(通常是键盘)读取一个字符。它定义在 <stdio.h> 头文件中。getchar() 函数没有参数,并返回一个 int 类型的值。返回的整数值是读取到的字符的ASCII码。