文章目录
- LangChain
-
- LangChain组件
-
- StrOutputParser解析器
- Runnable接口
- JsonOutputParser&多模型执行链
- RunnableLambda&函数加入链
- [Memory 临时会话记忆](#Memory 临时会话记忆)
- [Memory 长期会话记忆](#Memory 长期会话记忆)
- [Document loaders: 文档加载器](#Document loaders: 文档加载器)
- TextLoader和文档分割器
- [Vector stores 向量存储](#Vector stores 向量存储)
- 检索向量并构建提示词
- RunnablePassthrough的使用
视频链接: 黑马程序员大模型RAG与Agent智能体项目实战教程,基于主流的LangChain技术从大模型提示词到实战项目
LangChain
LangChain组件
StrOutputParser解析器
StrOutputParser是LangChain内置的简单字符串解析器
- 可以将AIMessage解析为简单的字符串,符合了模型invoke方法要求(可传入字符串,不接收AIMessage类型)
- 是Runnable接口的子类(可以加入链)
python
parser = StrOutputParser()
chain = prompt | model | parser | model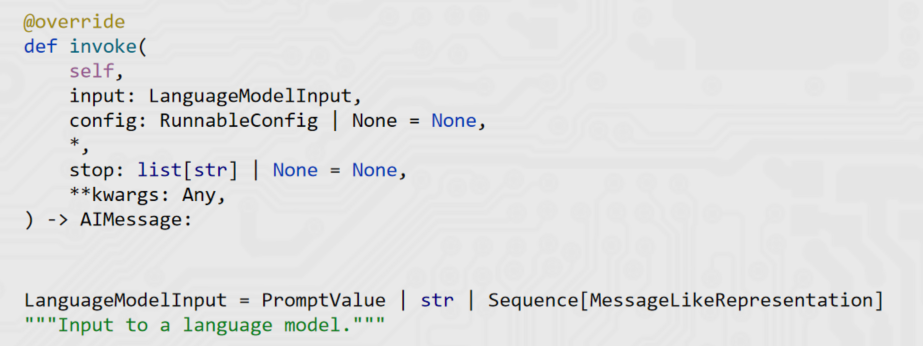
有如下代码
python
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.messages import AIMessage
model = ChatOpenAI(
api_key='sk-xxx7',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen3.5-plus"
)
prompt = PromptTemplate.from_template(
"我的邻居姓:{lastname},刚生了{gender},你帮我起个名字,简单回答"
)
parser = StrOutputParser()
chain = prompt | model | parser | model | parser
# res: AIMessage = chain.invoke({"lastname":"张", "gender":"女儿"})
res = chain.invoke({"lastname":"张", "gender":"女儿"})
print(res)Runnable接口
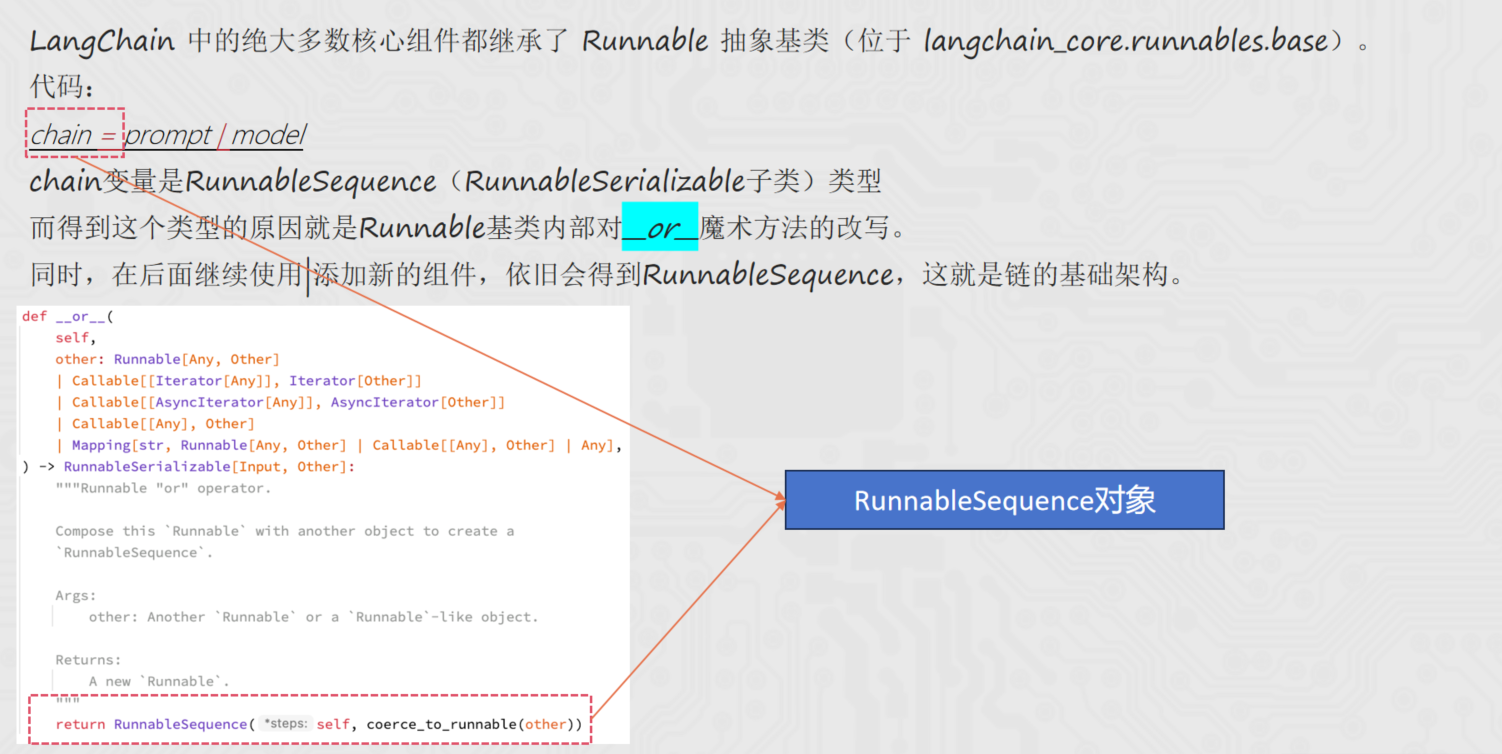
LangChain 中的绝大多数核心组件都继承了 Runnable 抽象基类(位于 langchain_core.runnables.base)。
代码:
chain = prompt | model
chain变量是RunnableSequence(RunnableSerializable子类)类型
而得到这个类型的原因就是Runnable基类内部对__or__魔术方法的改写。
同时,在后面继续使用|添加新的组件,依旧会得到RunnableSequence,这就是链的基础架构。
JsonOutputParser&多模型执行链
python
chain = prompt | model | parser | model | parser在前面我们完成了这样的需求去构建多模型链,不过这种做法并不标准,因为:
上一个模型的输出,没有被处理就输入下一个模型。
正常情况下我们应该有如下处理逻辑:
python
invoke|stream 初始输入 > 提示词模板 > 模型 > 数据处理 > 提示词模板 > 模型 > 解析器 > 结果即:
- 上一个模型的输出结果,应该作为提示词模版的输入,构建下一个提示词,用来二次调用模型。
根据输出和输入的要求:
python
invoke|stream 初始输入 > 提示词模板 > 模型 > 数据处理 > 提示词模板 > 模型 > 解析器 > 结果- 模型的输出为:AIMessage类对象
- 提示词模板要求输入如右侧代码:
所以,我们需要完成:
将模型输出的AIMessage > 转为字典 > 注入第二个提示词模板中,形成新的提示词(PromptValue对象)
python
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
#创建所需的解析器
str_parser = StrOutputParser()
json_parser = JsonOutputParser()
#创建模型
model = ChatOpenAI(
api_key='sk-xxx',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen3.5-plus"
)
#第一个提示词
first_prompt = PromptTemplate.from_template(
"我的邻居姓:{lastname},刚生了{gender},你帮我起个名字,以json格式返回,要求key是name,value是你起的名字,请严格遵守格式要求"
)
#第二个提示词
second_prompt = PromptTemplate.from_template(
"姓名:{name}, 请帮我解析含义"
)
#构建链
chain = first_prompt | model | json_parser | second_prompt | model | str_parser
res = chain.stream({"lastname":"张", "gender":"女儿"})
#res = chain.invoke({"lastname":"张", "gender":"女儿"})
for chunk in res:
print(chunk, end="", flush=True)RunnableLambda&函数加入链
python
chain = first_prompt | model | json_parser | second_prompt | model | str_parser前文我们根据JsonOutputParser完成了多模型执行链条的构建。
- 除了JsonOutputParser这类固定功能的解析器之外
- 我们也可以自己编写Lambda匿名函数来完成自定义逻辑的数据转换,想怎么转换就怎么转换,更自由。
想要完成这个功能,可以基于RunnableLambda类实现。
RunnableLambda类是LangChain内置的,将普通函数等转换为Runnable接口实例,方便自定义函数加入chain。
语法:
- RunnableLambda(函数对象或lambda匿名函数)
python
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
#创建所需的解析器
str_parser = StrOutputParser()
json_parser = JsonOutputParser()
#创建模型
model = ChatOpenAI(
api_key='sk-xxx',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen3.5-plus"
)
#第一个提示词
first_prompt = PromptTemplate.from_template(
"我的邻居姓:{lastname},刚生了{gender},你帮我起个名字,仅告知我名字,不需要额外信息"
)
my_func = RunnableLambda(lambda ai_msg: {"name": ai_msg.content})
#第二个提示词
second_prompt = PromptTemplate.from_template(
"姓名:{name}, 请帮我解析含义"
)
#构建链
chain = first_prompt | model | my_func | second_prompt | model | str_parser
res = chain.stream({"lastname":"张", "gender":"女儿"})
#res = chain.invoke({"lastname":"张", "gender":"女儿"})
for chunk in res:
print(chunk, end="", flush=True)
python
chain = first_prompt | model | (lambda ai_msg: {"name": ai_msg.content}) | second_prompt | model | str_parser跳过RunnableLambda类,直接让函数加入链也是可以的。
因为Runnable接口类在实现__or__的时候,支持Callable接口的实例。
函数就是Callable接口的实例

如上代码示例,|符号(底层是调用__or__)组链,是支持函数加入的。
其本质是将函数自动转换为RunnableLambda
Memory 临时会话记忆
如果想要封装历史记录,除了自行维护历史消息外,也可以借助LangChain内置的历史记录附加功能。
LangChain提供了History功能,帮助模型在有历史记忆的情况下回答。
- 基于RunnableWithMessageHistory在原有链的基础上创建带有历史记录功能的新链(新Runnable实例)
- 基于InMemoryChatMessageHistory为历史记录提供内存存储(临时用)
python
from langchain_classic.chains.summarize.refine_prompts import prompt_template
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_core.chat_history import InMemoryChatMessageHistory
#创建模型
model = ChatOpenAI(
api_key='sk-xxx',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen3.5-plus"
)
# prompt_template = PromptTemplate.from_template(
# "你需要根据历史回应用户问题,对话历史:{chat_history},用户问题:{input},请回答。"
# )
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system","你需要根据会话历史回应用户问题,对话历史:"),
MessagesPlaceholder("chat_history"),
("user","请回答如下问题:{input}")
]
)
str_parser = StrOutputParser()
def print_prompt(prompt):
print(prompt)
print("="*20)
return prompt
store = {} #key:session_id value:InMemoryChatMessageHistory对象
def get_history(session_id):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
base_chain = chat_prompt_template | print_prompt | model | str_parser
conversation_chain = RunnableWithMessageHistory(
base_chain, #被增强的原有的chain
get_history, #通过会话id获取InMemory
input_messages_key="input", #表示用户输入在模板中的占位符
history_messages_key="chat_history" #表示历史消息在模板中的占位符
)
if __name__ == '__main__':
#固定格式,添加langChain配置,为当前程序配置一个session_id
session_config = {
"configurable":{
"session_id":"user_001"
}
}
res = conversation_chain.invoke({"input":"小明有2个猫"}, session_config)
print("第1次执行:", res)
res = conversation_chain.invoke({"input":"小刚有1只狗"}, session_config)
print("第2次执行:", res)
res = conversation_chain.invoke({"input":"总共有几只宠物"}, session_config)
print("第3次执行:", res)总结
RunnableWithMessageHistory是LangChain内Runnable接口的实现,主要用于:
- 创建一个带有历史记忆功能的Runnable实例(链)
它在创建的时候需要提供一个BaseChatMessageHistory的具体实现(用来存储历史消息)
- InMemoryChatMessageHistory可以实现在内存中存储历史
额外的,如果想要在invoke或stream执行链的同时,将提示词print出来,可以在链中加入自定义函数实现。
- 注意:函数的输入应原封不动返回出去,避免破坏原有业务,仅在return之前,print所需信息即可。
Memory 长期会话记忆
使用InMemoryChatMessageHistory仅可以在内存中临时存储会话记忆,一旦程序退出,则记忆丢失。
InMemoryChatMessageHistory 类继承自 BaseChatMessageHistory

在官方注释中给出了相关实现的指南,并给出了基于文件的历史消息存储示例代码。
我们可以自行实现一个基于Json格式和本地文件的会话数据保存。
FileChatMessageHistory类实现,核心思路:
- 基于文件存储会话记录,以session_id为文件名,不同session_id有不同文件存储消息
继承BaseChatMessageHistory实现如下3个方法:
- add_messages:同步模式,添加消息
- messages:同步模式,获取消息
- clear:同步模式,清除消息
如下方代码,官方在BaseChatMessageHistory类的注释中提供了一个基于文件存储的示例代码。

代码实现:
python
import os,json
from typing import Sequence
from langchain_core.messages import message_to_dict, messages_from_dict, BaseMessage
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
# message_to_dict 单个消息对象,(BaseMessage类实例) -> dict
# messages_from_dict [字典,字典] -> [消息,消息]
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.session_id = session_id # 会话id
self.storage_path = storage_path # 不同会话id的存储文件,所在文件夹路径
#完整的文件路径
self.file_path = os.path.join(self.storage_path, self.session_id)
#确保文件夹存在
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, messages: Sequence[BaseMessage]):
#已有的消息
all_messages = list(self.messages)
all_messages.extend(messages)
#将数据同步写入到本地文件中
#类对象写入文件 -> 一堆二进制
#为了方便,将BaseMessage消息转为字典
# new_messages = []
# for message in all_messages:
# d = message_to_dict(message)
# new_messages.append(d)
new_messages = [message_to_dict(message) for message in all_messages]
#写入文件
with open(self.file_path, 'w', encoding="utf-8") as f:
json.dump(new_messages, f)
@property #此装饰器将messages方法变成成员属性使用
def messages(self) -> list[BaseMessage]:
# 当前文件 list[字典]
try:
with open(self.file_path, 'r', encoding="utf-8") as f:
json_messages = json.load(f)
return messages_from_dict(json_messages)
except FileNotFoundError:
return []
def clear(self):
with open(self.file_path, 'w', encoding="utf-8") as f:
json.dump([], f)
#创建模型
model = ChatOpenAI(
api_key='sk-xxx',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen3.5-plus"
)
# prompt_template = PromptTemplate.from_template(
# "你需要根据历史回应用户问题,对话历史:{chat_history},用户问题:{input},请回答。"
# )
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system","你需要根据会话历史回应用户问题,对话历史:"),
MessagesPlaceholder("chat_history"),
("user","请回答如下问题:{input}")
]
)
str_parser = StrOutputParser()
def print_prompt(prompt):
print(prompt)
print("="*20)
return prompt
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
base_chain = chat_prompt_template | print_prompt | model | str_parser
conversation_chain = RunnableWithMessageHistory(
base_chain, #被增强的原有的chain
get_history, #通过会话id获取InMemory
input_messages_key="input", #表示用户输入在模板中的占位符
history_messages_key="chat_history" #表示历史消息在模板中的占位符
)
if __name__ == '__main__':
#固定格式,添加langChain配置,为当前程序配置一个session_id
session_config = {
"configurable":{
"session_id":"user_001"
}
}
res = conversation_chain.invoke({"input":"小明有2个猫"}, session_config)
print("第1次执行:", res)
res = conversation_chain.invoke({"input":"小刚有1只狗"}, session_config)
print("第2次执行:", res)
res = conversation_chain.invoke({"input":"总共有几只宠物"}, session_config)
print("第3次执行:", res)Document loaders: 文档加载器
文档加载器提供了一套标准接口,用于将不同来源(如 CSV、PDF 或 JSON等)的数据读取为 LangChain 的文档格式。这确保了无论数据来源如何,都能对其进行一致性处理。
文档加载器(内置或自行实现)需实现BaseLoader接口。
Class Document,是LangChain内文档的统一载体,所有文档加载器最终返回此类的实例。
一个基础的Document类实例,基于如下代码创建:
python
from langchain_core.documents import Document
document = Document(
page_content="Hello, world!", metadata={"source": "https://example.com"}
)可以看到,Document类其核心记录了:
- page_content:文档内容
- metadata:文档元数据(字典)
不同的文档加载器可能定义了不同的参数,但是其都实现了统一的接口(方法)。
- load():一次性加载全部文档
- lazy_load():延迟流式传输文档,对大型数据集很有用,避免内存溢出。
LangChain内置了许多文档加载器,详细参见官方文档:https://docs.langchain.com/oss/python/integrations/document_loaders
我们简单的学习如下几个常用的文档加载器:
- CSVLoader
- JSONLoader
- PDFLoader
CSVLoader
python
"""
name,age,gender,hobby
王梓涵,25,男,"吃饭,rap"
刘若曦,22,女,"睡觉,rap"
陈俊宇,20,男,"吃饭,rap"
赵思瑶,28,女,"睡觉,rap"
黄浩然,15,男,"吃饭,rap"
林雨桐,20,女,"唱跳,rap"
周博文,20,男,"吃饭,rap"
吴诗琪,24,女,"吃饭,rap"
马子轩,22,男,"睡觉,rap"
孙悦然,27,女,"吃饭,rap
"""
from langchain_community.document_loaders import CSVLoader
loder = CSVLoader(
file_path="./data/stu.csv",
encoding="utf-8",
csv_args={
"delimiter": ",", # 指定分隔符
"quotechar": '"', # 如果数据中有此分隔符,使用这个符号将其包起来,变成一个整体
"fieldnames":['a','b','c','d'] #添加指定表头,不指定默认使用第一行作为表头
}
)
#批量加载
# documents = loder.load()
#
# for document in documents:
# print(type(document))
# print(document)
# 懒加载 .laze_load() 迭代器[Document]
for document in loder.lazy_load():
print(document)JSONLoader
JSONLoader用于将JSON数据加载为Document类型对象。
使用JSONLoader需要额外安装: pip install jq
jq是一个跨平台的json解析工具,LangChain底层对JSON的解析就是基于jq工具实现的。
将JSON数据的信息抽取出来,封装为Document对象,抽取的时候依赖jq_schema语法。

python
"""
{"name": "周杰轮", "age": 11, "gender": "男"}
{"name": "蔡依临", "age": 12, "gender": "女"}
{"name": "王力鸿", "age": 11, "gender": "男"}
"""
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="./data/stu_json_lines.json",
#jq_schema=".[].name",
jq_schema=".name",
#text_content=False # 告知json loader 抽取的内容不是字符串
json_lines=True # 告知json loader 这是一个json lines 文件,每一行都是一个json
)
document = loader.load()
print(document)PDFLoader
LangChain内支持许多PDF的加载器,我们选择其中的PyPDFLoader使用。
PyPDFLoader加载器,依赖PyPDF库,所以,需要安装它:
pip install pypdf
PyPDFLoader使用还是比较简单的,如下代码即可快速加载PDF中的文字内容了:
python
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="./data/pdf2.pdf",
mode="single", #默认是page模式,每个页面形成一个document, single不管有多少页,只形成一个document
password="itheima"
)
for doc in loader.lazy_load():
print(doc)TextLoader和文档分割器
除了前文学习的三个Loader以外,还有一个基本的加载器:TextLoader
作用:读取文本文件(如.txt),将全部内容放入一个Document对象中。
RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter递归字符文本分割器,是LangChain官方推荐的默认分割器。
基于文本的自然段落分割大文档为小文档
可以指定小文档的最大字符数、重叠字符数
可以手动指定段落划分的依据(符号)以及字符数量统计函数
python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader(
"./data/Python基础语法.txt",
encoding="utf-8",
)
document = loader.load()
print(document)
spliter = RecursiveCharacterTextSplitter(
chunk_size=500, # 分段的最大字符数
chunk_overlap=50, # 分段之间允许重复的字符数
separators=["\n\n", "\n", "。", "?", "?", "!", "!", " ", ""],
length_function=len,
)
split_documents = spliter.split_documents(document)
print("------"*20)
print(len(split_documents))
for split_document in split_documents:
print("="*20)
print(split_document)Vector stores 向量存储
基于LangChain的向量存储,存储嵌入数据,并执行相似性搜索。
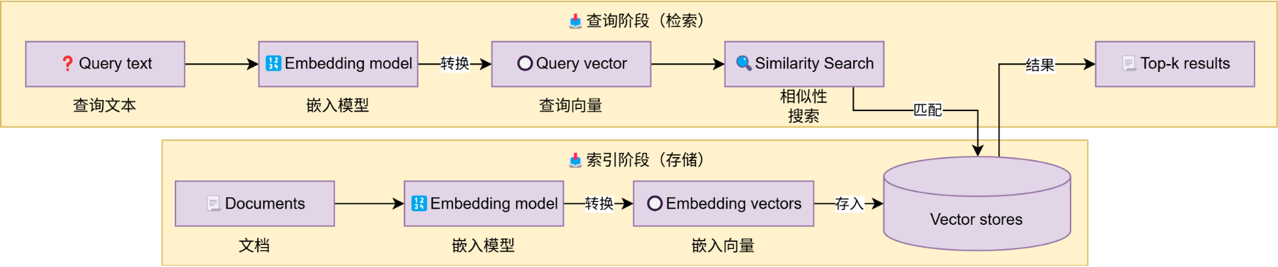
如图,这是一个典型的向量存储应用,也即是典型的RAG流程。
这部分开发主要涉及到:
如何文本转向量(前文已经学习)
创建向量存储,基于向量存储完成:

LangChain内提供向量存储功能,可以基于:
- InMemoryVectorStore,完成内存向量存储
python
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(
file_path="./data/info.csv",
encoding="utf-8",
source_column="source",
)
vector_store = InMemoryVectorStore(
embedding=DashScopeEmbeddings(
dashscope_api_key='sk-xxx'
),
)
documents = loader.load()
vector_store.add_documents(
documents=documents, #被添加的文档 list[Document]
ids=[ ('id' + str(i)) for i in range(1, len(documents) + 1)], #被添加文档的id list[str]
)
vector_store.delete("id1")
result = vector_store.similarity_search(
query="python 是不是简单易学?",
k=2
)
print(result)- Chroma,外部数据库向量存储
python
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
from langchain_chroma import Chroma
#Chroma
loader = CSVLoader(
file_path="./data/info.csv",
encoding="utf-8",
source_column="source",
)
vector_store = Chroma(
collection_name='test', #当前向量存储的名字
embedding_function=DashScopeEmbeddings( #嵌入模型
dashscope_api_key='sk-xxx'
),
persist_directory='./chroma_db' #指定数据存放的文件夹
)
documents = loader.load()
vector_store.add_documents(
documents=documents, #被添加的文档 list[Document]
ids=[ ('id' + str(i)) for i in range(1, len(documents) + 1)], #被添加文档的id list[str]
)
vector_store.delete("id1")
result = vector_store.similarity_search(
query="python 是不是简单易学?",
k=2,
filter={"source": "黑马程序员"},
)
print(result)向量存储类均提供3个通用API接口:
- add_document,添加文档到向量存储
- delete,从向量存储中删除文档
- similarity_search:相似度搜索
检索向量并构建提示词
向量存储的实例,通过add_texts(liststr)方法可以快速添加到向量存储中。
流程:
- 先通过向量存储检索匹配信息
- 将用户提问和匹配信息一同封装到提示词模板中提问模型
python
"""
提示词:用户的提示词 + 向量库中检索的参考资料
"""
from langchain_openai import ChatOpenAI
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
#创建模型
model = ChatOpenAI(
api_key='sk-xxx',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen3.5-plus"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,简介和专业的回答用户问题。参考资料:{context}"),
("user","用户题为:{input}"),
]
)
vector_store = InMemoryVectorStore(
embedding=DashScopeEmbeddings(
dashscope_api_key='sk-xxx',
model="text-embedding-v4"
)
)
#准备参考资料
#add_texts 传入一个列表 list[str]
vector_store.add_texts(["减肥就要多吃多练","在减肥期间吃东西很重要,清淡少油控制卡路里摄入并运动起来","跑步是很好的运动哦"])
input_text = "怎么减肥"
result = vector_store.similarity_search(input_text, k=2)
reference_text = "["
for doc in result:
reference_text += doc.page_content
reference_text += "]"
def print_prompt(prompt):
print(prompt.to_string())
print("---"*20)
return prompt
chain = prompt | print_prompt | model | StrOutputParser()
res = chain.invoke({"context": reference_text, "input": input_text})
print(res)RunnablePassthrough的使用
python
"""
提示词:用户的提示词 + 向量库中检索的参考资料
"""
from langchain_core.documents import Document
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
#创建模型
model = ChatOpenAI(
api_key='sk-xxx',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen3.5-plus"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,简介和专业的回答用户问题。参考资料:{context}"),
("user","用户题为:{input}"),
]
)
vector_store = InMemoryVectorStore(
embedding=DashScopeEmbeddings(
dashscope_api_key='sk-xx',
model="text-embedding-v4"
)
)
#准备参考资料
#add_texts 传入一个列表 list[str]
vector_store.add_texts(["减肥就要多吃多练","在减肥期间吃东西很重要,清淡少油控制卡路里摄入并运动起来","跑步是很好的运动哦"])
input_text = "怎么减肥"
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
#chain = retriever | prompt | model | StrOutputParser()
"""
retriever
输入:用户的提问作为输入 str
输出:向量库的检索结果 list[Document]
prompt
输入:用户提问 + 向量的检索结果 dict
输出:完整的提示词 PromptValue
"""
def format_func(documents: list[Document]):
if not documents:
return "无相关参考资料"
reference_text = "["
for doc in documents:
reference_text += doc.page_content
reference_text += "]"
return reference_text
#RunnablePassthrough 拿到整个链条的输入
chain = (
{"input": RunnablePassthrough(), "context": retriever | format_func } | prompt | model | StrOutputParser()
)
res = chain.invoke(input_text)
print(res)