你有没有遇到过这种场景:代码写完了,测试也跑过了,但上线时要手动登录服务器、拉代码、重启服务......每次都捏一把汗,生怕哪一步出错。有时候上线成功只是运气,而不是流程可靠。
一、背景:为什么手动部署是个危险游戏
在我还是算法工程师的时候,【上线】这件事一直很抽象。模型训练完,交给别人部署就结束了。直到开始接触工程项目,我第一次看到团队的上线流程。当时我的真实反应是上线原来要这么小心翼翼,这些命令到底在干嘛?
1.1 手动部署流程
想象一个五人小团队,每周发两次版本。每次上线流程是这样的:

-
在团队群里说一句:「我要上线了」
这一步看似随意,其实是在通知团队进入上线窗口。因为生产服务器通常只有一套环境,如果此时有人继续合并代码、修改配置,可能导致部署过程中版本被覆盖,甚至直接把线上服务弄挂。
-
SSH 登录服务器
bashssh user@server-ip 这一步非常关键,此时你操作的已经不是自己的电脑,而是一台远程的 Linux 服务器,也就是用户真正访问的网站所在的机器。
从这一刻开始,你的每一个命令都会直接影响线上环境。
-
拉取最新代码并构建项目
bashgit pull npm install npm run build这三条命令实际上是在让服务器一步步"变成新版本"。
-
git pull更新源码从代码仓库下载最新代码,覆盖服务器上的旧代码。
这时候只是代码变了,线上网站仍然在运行旧版本。
-
npm install安装运行依赖根据
package.json下载项目依赖,生成node_modules目录。这一步相当于在新机器上执行:
pip install -r requirements.txt。如果依赖版本变化,哪怕代码没变,运行结果也可能不同。 -
npm run build生成生产版本将前端源码编译为浏览器可以直接访问的静态文件,例如:
dist/ ├── index.html ├── app.js └── style.css真正上线的其实是这些 build 后的文件,而不是开发源码。
-
重启 Nginx 服务
bashsystemctl restart nginx用户访问网站时,请求路径其实是:
bash浏览器 → Nginx → 网站文件(dist)重启(或 reload)Nginx 后,Web 服务重新加载最新构建出的文件,新版本才正式对外生效。
-
手动验证网站是否正常
上线完成后,通常需要人工检查:
- 页面是否能正常打开
- API 请求是否成功
- 是否出现 404 或白屏
- 浏览器 Console 是否报错
-
只有确认这些都正常,才算一次部署真正完成。虽然看起来只是几条简单命令,但问题在于每一步都依赖人工判断,而线上环境往往没有"撤销按钮"。
1.2 每一步都暗藏风险
上述过程听起来不复杂,但每个步骤都是人工操作,就有出错的可能。更麻烦的是:你怎么知道这次部署的代码,真的通过了所有测试?也许同事昨天刚合并了一个没测试的 hotfix......
这就是 CI/CD 要解决的核心问题:让代码从提交到上线的整个过程可重复、可追溯、自动化。
二、什么是部署
很多新人(包括曾经的我)以为:部署就是把代码上传到服务器,其实完全不是。
2.1 部署的步骤
真正的部署是:
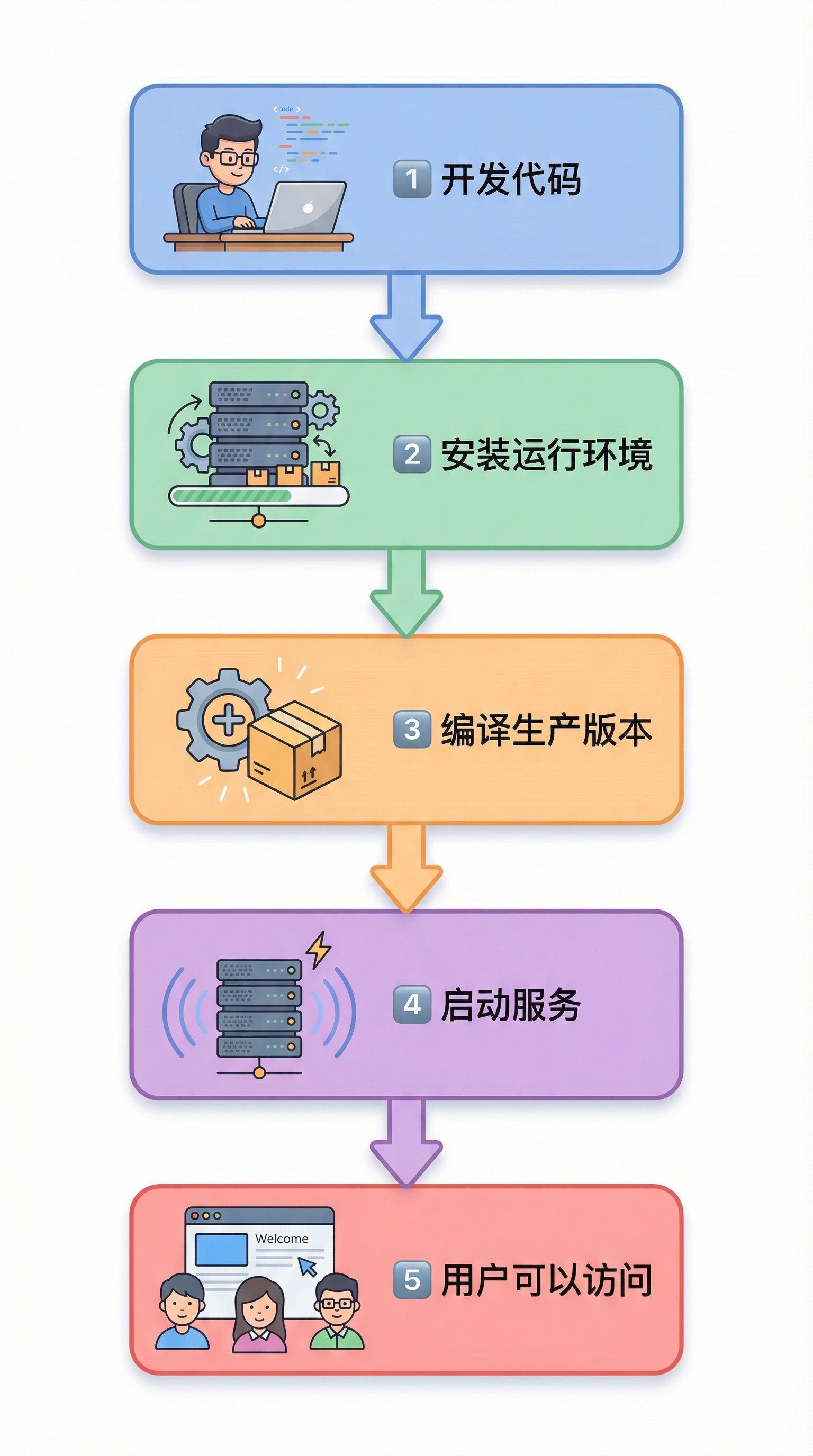
也就是说源码 ≠ 可以运行的程序,这点和算法领域其实完全一样。
部署的真正目标,从来不是"上传代码",而是"生成一个可稳定运行的系统状态"。
2.2 类比 ML 流程
| Web 世界 | 机器学习 |
|---|---|
| 前端源码 | 训练代码 |
| npm install | 安装 Python 依赖 |
| npm build | 导出模型 |
| Nginx | 推理服务入口 |
你不会把训练脚本直接上线,前端也一样。
三、手动部署时服务器到底发生了什么
3.1 第 1 步:git pull 获取最新代码
登录服务器后第一步:
bash
git pull 服务器做的事情非常简单:
远程仓库 → 下载最新代码 → 覆盖本地代码 此时服务器上只是不能运行的源码。
- 注意:**服务器和你电脑一样,只是一台远程 Linux,**它并不会自动更新代码。
3.2 第 2 步:npm install 构建运行环境
(1) 为什么要 install?
服务器是一台"干净机器",它没有React、Vue、axios和各种 JS 工具库,项目依赖写在package.json,类似requirements.txt。
(2) 执行后发生什么?
bash
npm install 服务器开始:
npm registry 下载依赖
↓
解析依赖树
↓
生成 node_modules/ 目录会变成:
project/
├── node_modules/ ← 几百 MB 的依赖
├── package.json
└── package-lock.json 你可以理解为conda create -n xxx_env,只是换成 JS 世界。
(3) 为什么这一步危险?
因为依赖版本可能变化、网络可能失败、不同机器结果可能不同,这就是后来为什么 CI 要锁版本。
3.3 第 3 步:npm run build 真正的"生产化"
这一阶段是认知分水岭。很多人以为部署失败是"服务器问题",实际上大多数问题都发生在 build 阶段。
(1) 你写的代码浏览器其实跑不了
开发时我们一般会写:
js
import React from "react" 但是浏览器并不理解这些模块系统,浏览器只认识:
HTML
CSS
原生 JS 所以必须进行一次:编译(Build)
(2) build 实际在干嘛?
执行npm run build服务器会运行打包工具(Vite/Webpack):
源码
↓
编译
↓
优化
↓
生成静态文件 输出:
dist/
├── index.html
├── app.8sd7a.js
└── style.a21.css 注意线上运行的是 dist,不是源码。
(3) 类比 ML
train.py
↓
export_model.py
↓
model.pt build 就是 export。
3.4 第 4 步:为什么要重启 Nginx?
现在服务器已经有:
/var/www/app/dist 但用户还访问不到,因为需要一个程序对外提供 HTTP 服务,这个角色就是 Nginx。
(1) Nginx 在干嘛?
用户访问:
https://example.com 真实路径:
浏览器
↓
Nginx
↓
dist/index.html Nginx 就像一个门卫。
(2) 为什么要 restart?
因为新版本文件替换了、可能改了配置、worker 需要重新加载
执行systemct1 restart nginx等价于「切换线上版本」。
四、部署时间线
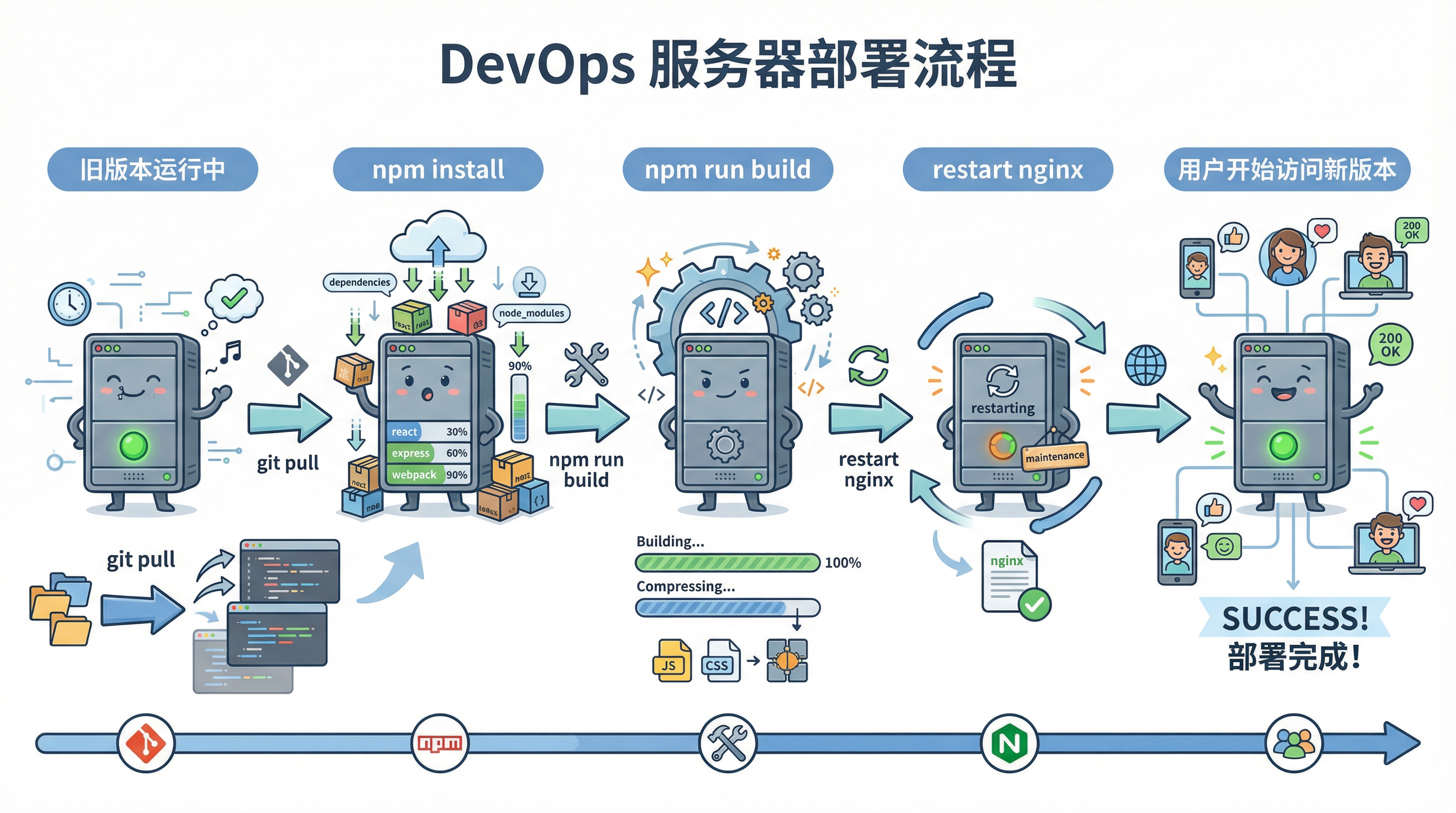
从服务器的视角来看,一次部署并不是执行几条命令那么简单,而是经历了一次完整的"状态切换"过程:
- 旧版本仍在运行
- 新代码被拉取到服务器
- 运行环境被重新准备
- 新版本被构建生成
- Web 服务重新加载内容
- 用户流量开始进入新版本
也就是说,部署本质上是让服务器逐步从旧状态过渡到新状态。而在手动部署中,这个过程完全依赖人工操作,任何一步出错,都可能导致线上服务异常。换句话说,部署不是执行命令,而是在小心翼翼地改变线上系统的状态。
五、总结:部署的本质不是"上线",而是"控制风险"
很多人以为部署只是把代码传到服务器,但实际上,一次上线意味着:
- 环境被重新构建
- 应用被重新生成
- 服务被重新切换
- 用户流量被重新接管
也就是说**部署不是上传代码,而是在生产环境进行一次系统变更。**手动部署之所以危险,不是因为步骤多,而是因为:
- 过程不可重复
- 状态不可验证
- 问题不可追溯
这正是 CI/CD 要解决的问题让上线从"人工操作",变成"标准流程"。因为手动部署解决的是"这次上线",而 CI/CD 解决的是"以后每一次上线"。