当 LLM 的上下文窗口成为瓶颈,Anthropic 选择用系统工程思维而非简单扩窗来解决问题。
-
- [引言:上下文窗口------LLM 的"金鱼记忆"困境](#引言:上下文窗口——LLM 的"金鱼记忆"困境)
- 7层架构全景图
- 逐层深度解析
-
- 第1层:工具结果存储------"第一道防线"
- 第2层:微压缩------"日常保洁"
- 第3层:会话记忆------"最聪明的一层"
- 第4层:全压缩------"紧急刹车"
- 第5层:自动记忆提取------"长期知识库"
- 第6层:做梦机制------"记忆巩固"
- [第7层:跨代理通信------"多 Agent 协作基础"](#第7层:跨代理通信——"多 Agent 协作基础")
- [横向对比:Claude Code vs Cursor vs GitHub Copilot](#横向对比:Claude Code vs Cursor vs GitHub Copilot)
- 批判性分析:7层设计是否过度工程化?
- [对普通开发者构建 Agent 的启示](#对普通开发者构建 Agent 的启示)
-
- [1. 上下文管理是 Agent 的核心竞争力](#1. 上下文管理是 Agent 的核心竞争力)
- [2. 从简单方案开始,逐步演进](#2. 从简单方案开始,逐步演进)
- [3. 避免过度设计](#3. 避免过度设计)
- [4. 关键设计原则](#4. 关键设计原则)
- 结论:优雅但可能过度设计的工程杰作
- 参考与延伸阅读
引言:上下文窗口------LLM 的"金鱼记忆"困境
大型语言模型(LLM)有一个基本约束:固定的上下文窗口 。Claude Code 默认提供 200K token 的窗口(使用 [1m] 后缀可扩展至 1M),但在真实的编程场景中,这个限制很快就会被触及:
- 读取几个大型源文件(50K+ tokens)
- 执行全仓库的
grep搜索(100K+ tokens) - 多轮对话的累积历史
一次典型的开发会话轻松就能超出窗口限制。
传统的解决思路是"扩窗"------不断追求更大的上下文窗口。但 Anthropic 在 Claude Code 中展示了一种更具工程智慧的方案:7层渐进式记忆管理系统。这套架构像人类大脑一样分层管理记忆,从毫秒级的轻量清理到跨会话的长期记忆巩固,层层递进。
本文将深入解析这套架构的设计原理,并对其进行批判性分析------它真的如宣传中那样完美吗?与 Cursor、GitHub Copilot 的方案相比如何?对于普通开发者构建 Agent 有什么启示?
7层架构全景图
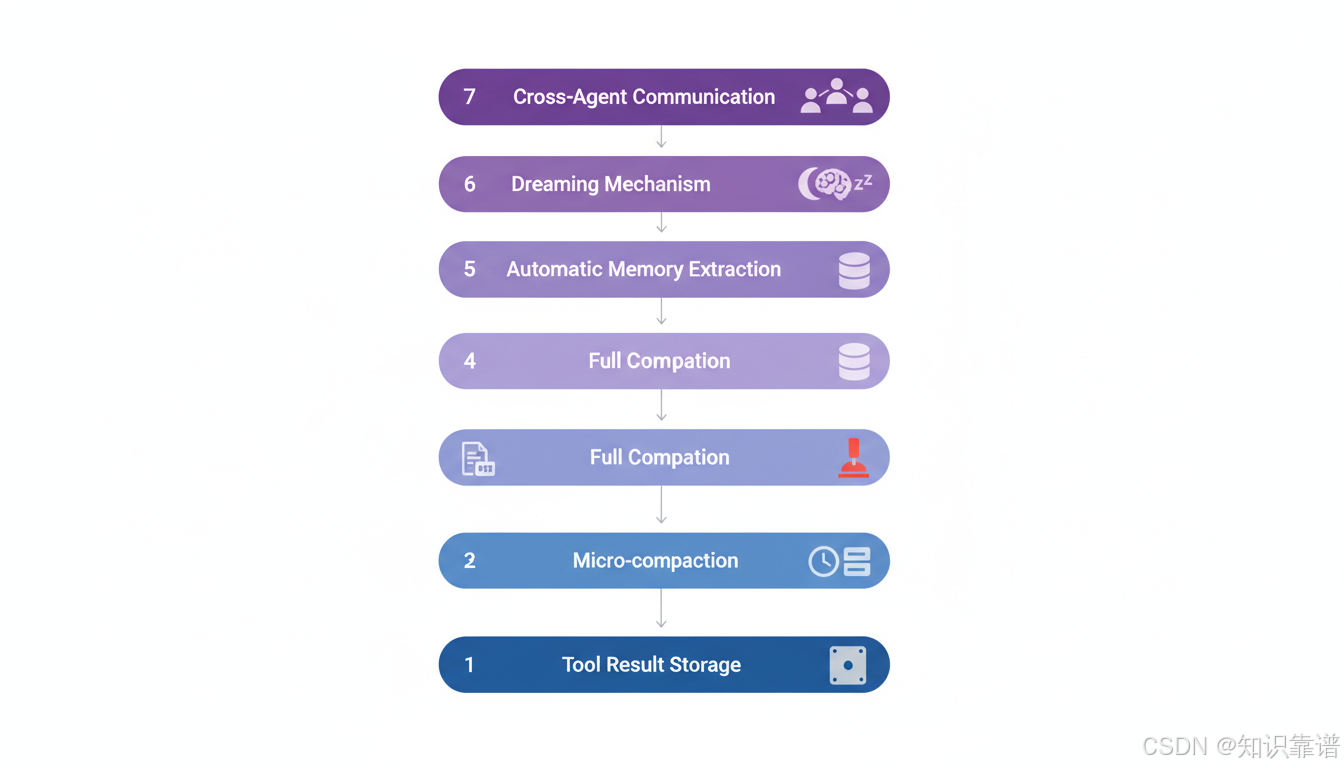
Claude Code 的7层渐进式记忆管理架构
这7层架构遵循一个核心设计原则:成本递增、能力递增,层层防护,避免下一层触发。每一层都设计为尽可能防止更昂贵的 N+1 层被激活。
| 层级 | 名称 | 触发时机 | 成本 | 核心能力 |
|---|---|---|---|---|
| L1 | 工具结果存储 | 每次工具调用 | 极低 | 大输出写入磁盘,上下文只保留预览 |
| L2 | 微压缩 | 每轮 API 调用前 | 极低 | 基于时间/缓存的轻量级清理 |
| L3 | 会话记忆 | Token 增长达阈值 | 低 | 实时维护结构化笔记 |
| L4 | 全压缩 | 上下文快满时 | 中 | 9段结构化摘要 |
| L5 | 自动记忆提取 | 任务结束时 | 中 | 构建跨会话长期知识库 |
| L6 | 做梦机制 | 积累足够会话后 | 高 | 跨会话记忆巩固 |
| L7 | 跨代理通信 | 多 Agent 协作时 | 可变 | 多 Agent 协作基础 |
逐层深度解析
第1层:工具结果存储------"第一道防线"
问题场景 :单次 grep 可能返回 100KB+ 文本,cat 大文件可能 50KB+。这些内容直接塞进上下文,既浪费 Token 又很快过时。
解决方案:
- 每个工具结果进入上下文前经过"预算系统"
- 超过阈值时,完整结果写入磁盘(
tool-results/<sessionId>/<toolUseId>.txt) - 上下文只保留前 ~2KB 预览,用
<persistent_output>标签包裹 - 模型如需完整内容,可用
Read工具后续读取
关键工程细节:
- 内容替换状态冻结:一旦决定用预览,该决定被"冻结",后续所有 API 调用使用同样的预览,确保 Prompt 前缀字节完全一致,最大化缓存命中率
- 状态持久化:支持会话恢复(resume)
- 远程调参 :通过
tengu_satin_quoll功能标志远程调节阈值,无需代码部署
第2层:微压缩------"日常保洁"
这是最轻量级的上下文清理,几乎零 API 成本,每轮 API 调用前执行。微压缩不做总结,只是清除不太可能用到的旧工具结果。
三种机制:
a) 基于时间的清理
- 距离上次助手消息超过 60 分钟(Prompt Cache TTL 约 1 小时)
- 缓存已过期,可安全清理旧工具结果
- 替换为
[Old tool result content cleared],保留最近 N 条
b) 缓存微压缩(技术最精妙)
- 使用
cache_edits在服务器端删除旧工具结果 - 本地消息不变,避免破坏缓存前缀
- 工具结果注册到全局
CachedMCState,超过阈值选最旧的删 - 关键点:只运行主线,分支子代理修改全局状态会破坏主线程缓存
c) API 级上下文管理
- 使用
context_managementAPI 参数直接让 API 处理部分清理
第3层:会话记忆------"最聪明的一层"
核心思想 :不是等上下文满了再慌张总结,而是实时维护结构化笔记。
每个会话获得一个 Markdown 文件:
~/.claude/projects/<slug>/.claude/session-memory/<sessionId>.md包含结构化模板:
- Current Status:当前任务状态
- Key Decisions:关键决策记录
- Open Questions:待解决问题
- Next Steps:下一步行动
触发条件:Token 增长达阈值 +(工具调用次数达标 或 上轮无工具调用)
压缩时的优势:
- 检查会话内存是否有实际内容(而非空模板)
- 使用会话内存标记作为压缩摘要------无需调用 API
- 计算保留哪些最近消息
- 直接注入现成总结------零额外 API 调用,成本极低
第4层:全压缩------"紧急刹车"
当 tokenCountWithEstimation() 超过自动压缩阈值(有效窗口 - 13K)且会话内存不可用时触发。
严谨的压缩流程:
-
预处理 :执行用户
PreCompacthook,去除图片、技能附件等 -
生成摘要 :向摘要代理分支,要求提供 9 个部分的结构化摘要:
- 任务目标与范围
- 已完成的代码变更
- 关键决策及其理由
- 遇到的问题与解决方案
- 待办事项
- 相关文件列表
- 测试状态
- 性能考虑
- 后续建议
先写
<analysis>草稿思考,再输出<summary>正文(草稿被剥离,不占最终 Token) -
压缩后修复:重新注入最近读的文件、技能内容、计划附件等关键上下文
-
插入标记 :
SystemCompactBoundaryMessage标记压缩点
恢复机制:
- 只压缩部分消息
- 提示本身过长时,分组丢弃最旧消息,重试 3 次
第5层:自动记忆提取------"长期知识库"
每任务结束时,提取跨会话的持久知识,存到 ~/.claude/projects/.../memory/ 目录。
四种记忆类型:
| 类型 | 格式 | 用途 |
|---|---|---|
.claude-memory.md |
Markdown | 通用项目知识 |
.claude-patterns.md |
Markdown | 代码模式与约定 |
.claude-decisions.md |
Markdown | 架构决策记录 |
.claude-bugs.md |
Markdown | 已知问题与修复 |
MEMORY.md 索引文件:
- 最多 200 行或 25KB,超出自动截断
- 每个条目应为一行,低于 ~150 字符
- 作为记忆文件的"目录",加速检索
第6层:做梦机制------"记忆巩固"
这可能是整篇文章里最具争议也最具想象力 的部分。当积累足够会话后触发,模拟人脑睡眠时巩固记忆的过程:回顾过去会话日志,组织、整合、清理长期记忆。
门控序列设计(从便宜到昂贵):
- 检查是否有足够新会话需要巩固
- 检查磁盘空间是否充足
- 检查是否有冲突的巩固任务
- 执行实际巩固
四个阶段:
| 阶段 | 任务 | 说明 |
|---|---|---|
| 标定位置 | 扫描 memory 目录,读 MEMORY.md | 避免重复处理 |
| 收集 | grep 怀疑重要的片段 | 检查矛盾记忆 |
| 合并 | 合并新信号到现有文件 | 删除矛盾事实,相对日期转绝对日期 |
| 整理与索引 | 更新 MEMORY.md | 删除过时条目,解决文件间矛盾 |
安全机制:
- 锁文件(
.consolidate-lock)实现互斥,包含 PID 和时间戳 - Dream Agent 工具受严格限制:Bash 只读,Edit/Write 只限 memory 目录
- UI 显示为后台任务,用户可终止,锁会回滚方便下次重试
记忆从分散到组织的巩固过程
第7层:跨代理通信------"多 Agent 协作基础"
几乎所有后台操作(Session Memory、Dreaming 等)都基于分支代理模式。
状态隔离与共享的平衡:
- 分叉代理获得克隆的可变状态(LRU 缓存、abortController 等),防止交叉污染
- 但通过
CacheSafeParams和相同前缀共享 Prompt Cache,防止成本爆炸
Agent 工具支持多种模式:
SendMessageTool 实现 Agent 间实时通信(支持广播、跨会话等)- Agent Summary:每 30 秒用最便宜的 Haiku 模型生成 3-5 词进度快照,用于协调
横向对比:Claude Code vs Cursor vs GitHub Copilot
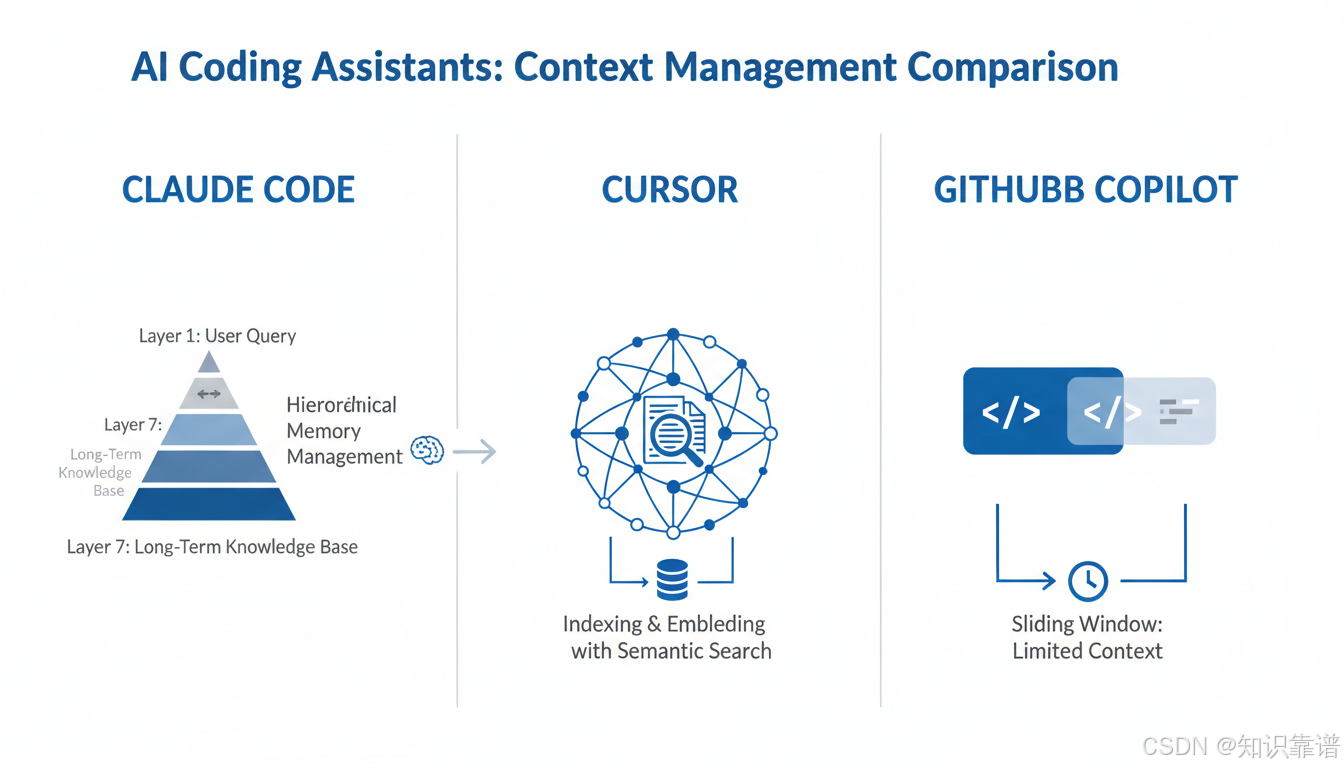
三大 AI 编程助手的上下文管理机制对比
架构哲学差异
| 维度 | Claude Code | Cursor | GitHub Copilot |
|---|---|---|---|
| 核心策略 | 7层渐进式记忆管理 | 索引+嵌入的语义搜索 | 滑动窗口+检索增强 |
| 上下文窗口 | 200K-1M tokens | ~200K(检索增强后等效更大) | 64K-192K tokens |
| 持久记忆 | 文件系统(memory/ 目录) | 索引+记忆系统 | 有限(主要依赖会话) |
| 跨会话记忆 | 完整支持(做梦机制) | 部分支持 | 基本不支持 |
Cursor 的记忆机制
Cursor 采用索引+嵌入的方案:
- 代码库索引:打开项目时,Cursor 将整个代码库转为 embeddings,创建语义地图
- 语义搜索:当你询问代码功能时,它通过语义相似度而非关键词匹配找到相关代码
- 记忆系统 :Cursor 使用双系统------Memories(AI 从对话中提取的模式)和 Rules(用户显式编写的指令)
- 记忆审批:Cursor 会建议记忆,但需要用户审批后才保存,保持用户控制
优势:
- 搜索速度快,基于向量相似度
- 用户可控的记忆审批机制
- 与 IDE 深度集成,体验流畅
劣势:
- 索引大型项目可能很慢
- 缺乏真正的跨会话长期记忆巩固
- 无法像 Claude Code 那样在会话间自动整理和优化记忆
GitHub Copilot 的记忆机制
Copilot 的方案相对简单直接:
- 滑动窗口:在活跃缓冲区上维护滑动窗口,保留最近上下文
- RAG 检索:对于大文档,使用检索增强生成,只加载最相关的片段
- 保留输出缓冲:预留约 30% 的上下文窗口(~60K tokens)作为输出缓冲,确保 AI 有足够空间生成响应
优势:
- 简单可靠,工程复杂度低
- 与 GitHub 生态深度集成
- 价格最低($10/月起步)
劣势:
- 缺乏持久记忆,会话间完全重置
- 容易丢失长对话中的早期上下文
- 对大型代码库的理解能力有限
性能对比总结
| 场景 | Claude Code | Cursor | Copilot |
|---|---|---|---|
| 大型代码库理解 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 跨会话记忆 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 响应速度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 多文件重构 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 成本效率 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 易用性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
批判性分析:7层设计是否过度工程化?
优势:一套精密的系统工程
1. 分层防御的成本控制
这套架构最出色的地方在于成本意识。每一层都设计为防止更昂贵的下一层触发:
- L1-L2 几乎零成本,处理 90% 的场景
- L3 低成本,处理 8% 的场景
- L4-L7 逐步升级,只处理真正复杂的 2%
这种"金字塔"设计确保了绝大多数情况下系统保持轻量。
2. Prompt Cache 的极致优化
几乎每一个设计决策都考虑了缓存命中率:
- 内容替换状态冻结
- 缓存微压缩的
cache_edits技巧 - 共享 Prompt Cache 前缀的分支代理模式
3. 工程成熟度极高
- 远程功能开关:通过 GrowthBook 控制,关键功能随时可回滚
- 到处都是阻断:3 次失败自动阻断、锁文件 PID 检测、互斥检查
- 状态隔离与共享的平衡:分叉代理既防止交叉污染,又共享缓存
劣势与质疑
1. 7层设计是否过度复杂?
这是一个值得深思的问题。让我们对比 Cursor 的方案:
| 指标 | Claude Code (7层) | Cursor (索引+嵌入) |
|---|---|---|
| 工程复杂度 | 极高 | 中等 |
| 维护成本 | 高 | 中 |
| 实际效果 | 优秀 | 良好 |
| 边际收益 | ? | - |
关键问题:从 5 层到 7 层的边际收益是否值得额外的复杂度?
- L1-L4 解决的是"当前会话内"的上下文管理问题
- L5-L7 解决的是"跨会话"的长期记忆问题
但这里有一个工程权衡:如果 90% 的用户会话都在 1-2 小时内结束,L5-L7 的价值是否被高估?
2. "做梦机制"的真实效果如何?
做梦机制是最具想象力的设计,但也面临最多质疑:
理论上的价值:
- 模拟人脑记忆巩固过程
- 自动整理和优化长期记忆
- 发现矛盾记忆并解决
实际使用中的问题:
- 触发频率低:需要积累"足够会话"才触发,对于轻度用户可能数周才运行一次
- 效果难以量化:如何衡量记忆巩固的效果?
- 用户感知弱:这是一个后台任务,用户可能完全感知不到其价值
- 资源消耗高:回顾和整理大量历史会话需要显著的计算资源
一个更激进的观点:做梦机制可能更多是一个"营销亮点"而非真正的工程必需。L5 的自动记忆提取已经能解决 80% 的跨会话记忆需求,L6 的额外收益是否值得其复杂度?
3. 与简单方案的对比
让我们做一个思想实验:如果用 Cursor 的索引方案替代 Claude Code 的 L5-L7,会损失什么?
| 能力 | Claude Code 方案 | Cursor 方案 | 差距 |
|---|---|---|---|
| 跨会话记忆 | 结构化文件+自动整理 | 索引+用户审批 | Claude Code 更自动化 |
| 记忆优化 | 做梦机制主动整理 | 无 | Claude Code 有优势 |
| 用户控制 | 较低(全自动) | 较高(需审批) | Cursor 更可控 |
| 工程复杂度 | 极高 | 中等 | Cursor 更易维护 |
结论:Claude Code 的方案在理论上更优雅,但在实际使用中,用户是否能感知到显著差异?这是一个开放问题。
简化建议
如果我要重新设计这套系统,可能会考虑以下简化:
方案 A:5层简化版
- 保留 L1-L4(当前会话管理)
- 将 L5-L7 合并为"长期记忆层":使用向量数据库 + 定期整理任务
- 移除"做梦机制"的生物学隐喻,改为更直接的"记忆整理任务"
方案 B:混合方案
- L1-L4 保持不变
- L5 采用 Cursor 式的索引方案
- 保留 L7 的多 Agent 通信(这是 Agent 协作的基础)
对普通开发者构建 Agent 的启示
1. 上下文管理是 Agent 的核心竞争力
Claude Code 的架构告诉我们:在 LLM 能力相近的情况下,上下文管理能力是区分 Agent 质量的关键。
对于构建 Agent 的开发者:
- 不要只关注模型能力,上下文管理同样重要
- 分层设计是控制成本的有效策略
- 缓存优化能显著降低运营成本
2. 从简单方案开始,逐步演进
Claude Code 的 7 层架构是长期演进的结果。对于新入场的开发者:
MVP 阶段:
- 实现基本的滑动窗口(Copilot 模式)
- 添加简单的会话记忆文件
进阶阶段:
- 添加工具结果的外部存储
- 实现基于时间的轻量清理
成熟阶段:
- 考虑语义搜索/向量数据库
- 根据实际使用数据决定是否需要更复杂的机制
3. 避免过度设计
Claude Code 的架构虽然精妙,但可能过度设计。对于资源有限的团队:
- 优先考虑 Cursor 式的索引方案:工程复杂度更低,效果足够好
- 谨慎引入"创新机制":如做梦机制,确保有明确的用户价值
- 关注可维护性:复杂的系统需要更高的维护成本
4. 关键设计原则
从 Claude Code 的架构中,我们可以提炼出以下可复用的原则:
原则 1:成本分层
廉价层处理 90% 的场景
↓
昂贵层处理 10% 的场景
↓
极昂贵层处理 1% 的场景原则 2:缓存优先
- 每一个设计决策都考虑缓存命中率
- 状态变化时确保前缀一致性
原则 3:防御性设计
- 失败重试机制
- 锁和互斥防止竞态条件
- 功能开关支持快速回滚
原则 4:渐进式增强
- 基础功能必须可靠
- 高级功能可以实验性添加
- 根据使用数据调整层级触发阈值
结论:优雅但可能过度设计的工程杰作
Claude Code 的 7 层记忆管理系统是一套精密的系统工程,展示了 Anthropic 在 Agent 架构设计上的深度思考。它的优势在于:
- 极致的成本控制:分层防御确保昂贵操作只在必要时触发
- 缓存优化:几乎每个细节都考虑了 Prompt Cache 效率
- 长期记忆:跨会话的记忆巩固是业界领先的功能
但它也面临过度设计的质疑:
- 7层复杂度:L5-L7 的边际收益是否值得其复杂度?
- 做梦机制的实际价值:用户是否能感知到其效果?
- 与简单方案的差距:Cursor 的索引方案是否已经"足够好"?
最终评价:
这套架构是当前 Agentic AI 的教科书级设计 ,值得每一个构建 Agent 的开发者学习。但对于资源有限的团队,建议从更简单的方案开始,根据实际使用数据逐步演进。不要为了优雅而优雅,用户的实际体验才是最终评判标准。
参考与延伸阅读
本文基于 Claude Code 源码分析和公开资料整理,部分架构细节可能随版本更新而变化。