vector 在OJ中的使用
OJ 1.只出现一次的数字i
复习一下异或(^)
异或运算的基本性质
恒等律:任何数与0异或的结果是其本身,即 X ⊕ 0 = X。
归零律:任何数与自身异或的结果是0,即 X ⊕ X = 0。
交换律:异或运算满足交换律,即 A ⊕ B = B ⊕ A。
结合律:异或运算满足结合律,即 (A ⊕ B) ⊕ C = A ⊕ (B ⊕ C)。
cpp
class Solution
{
public:
int singleNumber(vector<int>& nums)
{
int value = 0;
for(auto e : nums)
{
value ^= e;
}
return value;
}
}; OJ 2.杨辉三角OJ
cpp
// 涉及resize / operator[]
// 核心思想:找出杨辉三角的规律,发现每一行头尾都是1,中间第[j]个数等于上一行[j-1]+ [j]
class Solution
{
public:
vector<vector<int>> generate(int numRows)
{
vector<vector<int>> vv;
//创建numRows个元素,每个元素的内容是空的vector<int>对象
//vector<int>()是匿名对象
vv.resize(numRows,vector<int>());
//第i行创建i+1个数据,并赋值为1
for(size_t i = 0; i < numRows; ++i)
{
vv[i].resize(i+1, 1);
}
for(size_t i = 2; i < vv.size(); ++i)
{
for(int j = 1; j < vv[i].size()-1; ++j)
{
vv[i][j] = vv[i-1][j] + vv[i-1][j-1];
}
}
return vv;
}
};在generate函数中,vv 是一个vector<vector< int>>,通过 vv.resize(numRows, vector()) 将其大小(行数)设置为 numRows。之后的所有操作(包括两个 for 循环)都只修改了各行 vector 的内容或长度,并没有改变 vv 本身的大小。因此,在整个函数执行期间,vv.size() 始终等于 numRows。
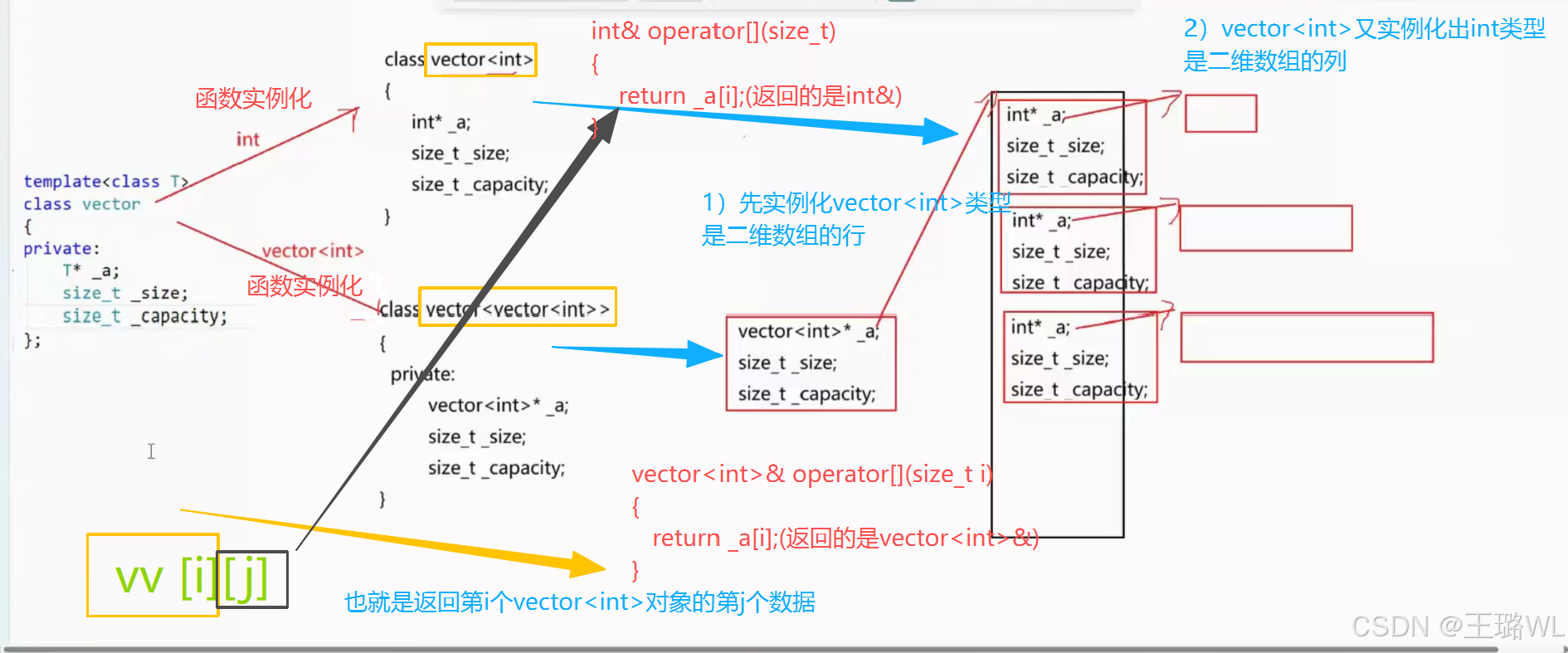
总结:通过上面的练习我们发现vector常用的接口更多是插入和遍历。遍历更喜欢用数组operatori的形式访问,因为这样便捷。
OJ 3.删除排序数组中的重复项
cpp
class Solution {
public:
int removeDuplicates(vector<int>& nums)
{
int n = nums.size();
if (n == 0)
return 0;
//slow表示下一次要插入的位置,fast遍历
int fast = 1, slow = 1;
while (fast < n)
{
if (nums[fast] != nums[fast - 1])
{
nums[slow] = nums[fast];
slow++;
}
++fast;
}
//此时slow刚好是个数
return slow;
}
};OJ 4.只出现一次的数ii
为什么可以按位统计?
整数在计算机中用二进制表示(比如 32 位)。对于每个二进制位(第 0 位、第 1 位......第 31 位),我们可以独立地统计所有数字在该位上为 1 的总次数。
因为出现三次的数字,在同一个位上,要么是 0(贡献 0),要么是 1(贡献 3 次 1),所以它们在该位上的总计数一定是 0 或 3(即 3 的倍数)。而只出现一次的数字,在该位上要么是 0(贡献 0),要么是 1(贡献 1)。因此,所有数字在该位上的 1 的个数,除以 3 的余数,就是目标数字在该位上的值。
举例说明(以 4 位二进制简化为例)
假设数字只有 4 位(实际是 32 位,道理相同)。
数组:2, 2, 2, 3
二进制表示(4 位):
2 = 0010
3 = 0011
第 0 位(最右边)
2:第 0 位是 0
2:0
2:0
3:第 0 位是 1
总共有 1 个 1。
1 % 3 = 1 → 目标数字的第 0 位是 1。
第 1 位
2:第 1 位是 1
2:1
2:1
3:第 1 位是 1
总共有 4 个 1。
4 % 3 = 1 → 目标数字的第 1 位是 1。
第 2 位
2:第 2 位是 0
2:0
2:0
3:第 2 位是 0
总共有 0 个 1。
0 % 3 = 0 → 目标数字的第 2 位是 0。
第 3 位(最高位)
所有数字第 3 位都是 0,总数为 0,余数 0 → 目标数字第 3 位是 0。
所以目标数字的二进制是 0011,即 3。
cpp
class Solution
{
public:
int singleNumber(vector<int>& nums)
{
int ans = 0;
for (int i = 0; i < 32; i++)
{
int total = 0;
for(int num:nums)
{
total += ((num >> i) & 1);
}
if (total % 3)
ans |= (1 << i);
}
return ans;
}
};(1 << i) 生成了一个只在第 i 位为 1、其余位为 0 的掩码。
ans |= mask 将 ans 的第 i 位设置为 1(因为按位或运算:只要有一位为 1,结果就为 1)。
因此,1 << i 用来构造一个只有第 i 位为 1 的整数,便于将结果 ans 的对应位置 1。
OJ 5. 只出现一次的数iii
第一步:全部异或
cpp
int xorsum = 0;
for (int num: nums) {
xorsum ^= num;
}异或(^)的性质:
a ^ a = 0(相同数字抵消)
a ^ 0 = a
所以把整个数组异或一遍,所有成对出现的数字都会抵消为0,剩下的就是两个只出现一次的数字的异或结果:
cpp
xorsum = a ^ b其中 a 和 b 就是我们要找的两个数。
2.第二步:找到 a 和 b 不同的某一位
因为 a != b,所以 a ^ b 的二进制中至少有一位是 1。这一位在 a 中是 0,在 b 中是 1(或者反过来)。
我们只要随便找出这样的一位,就可以把 a 和 b 区分开。
如何找出这一位?
常用技巧:++xorsum & (-xorsum) 可以取出 xorsum 最低位的 1(即从右往左第一个为 1 的位)。++
例如 xorsum = 6(二进制 110),
-6 在计算机中是补码:先取反得 ...111001,再加1得 ...111010。
6 & (-6) = 110 & 010 = 010(二进制),即数字 2,代表第1位(从0开始)是1。
代码中特殊处理了 xorsum == INT_MIN 的情况,++这是为了避免整数溢出(INT_MIN 的负值等于自身,直接取 xorsum 即可)<u>。++
3.第三步:根据这一位分组
现在我们有了一个掩码 lsb,它只有一位是 1(比如 2,即二进制 010)。
我们将数组中所有数字按照 该位是否为 1 分成两组:
第1组:num & lsb == 0(该位为0)
第2组:num & lsb != 0(该位为1)
为什么这样分组有效?
因为 a 和 b 在这一位上不同,所以它们一定会被分到不同的组。
而所有其他数字都出现了两次,并且它们在这一位上的值相同(因为它们是相同的数字),所以成对地落在同一个组里。
于是,每个组内,成对出现的数字异或后抵消,剩下的就是本组里那个单独的数字(即 a 或 b)。
4.第四步:分别异或各组
cpp
int type1 = 0, type2 = 0;
for (int num: nums) {
if (num & lsb) {
type1 ^= num;
} else {
type2 ^= num;
}
}type1 会得到该位为 1 的那一组中只出现一次的数字(假设是 a)。
type2 会得到另一组的只出现一次的数字(即 b)。
最终返回 {type1, type2}。
5.用例子走一遍
数组 1,2,1,3,2,5
全部异或:1^ 2^ 1 ^ 3^ 2 ^ 5 = 6(二进制 110)。
最低位1:6 & (-6) = 2(二进制 010,代表第1位)。
分组:
第1组(该位为0):数字 1(001)、1(001)、5(101) → 异或:1 ^ 1 ^ 5 = 5
第2组(该位为1):数字 2(010)、3(011)、2(010) → 异或:2 ^ 3 ^ 2 = 3
结果:5,3
6.为什么要特殊处理 INT_MIN?
INT_MIN 是 -2147483648,二进制是 1000...000(32位中最高位为1,其余全0)。
它的负值 -INT_MIN 在补码中也是 1000...000,所以 INT_MIN & (-INT_MIN) 会得到 INT_MIN 自身,这没有问题,但为了避免某些编译器的未定义行为(比如溢出),官方题解加了一个判断,如果 xorsum 就是 INT_MIN,直接用它作为 lsb,否则用 xorsum & (-xorsum)。
cpp
class Solution {
public:
vector<int> singleNumber(vector<int>& nums) {
int xorsum = 0;
for (int num: nums) {
xorsum ^= num;
}
// 防止溢出
int lsb = (xorsum == INT_MIN ? xorsum : xorsum & (-xorsum));
int type1 = 0, type2 = 0;
for (int num: nums)
{
//lsb只有一位为1
//此时num在这位为1
if (num & lsb)
{
//得到这个值
type1 ^= num;
}
else
{
type2 ^= num;
}
}
return {type1, type2};
}
};原理:
观察 x 和 -x 的二进制关系:
设 x 的最低位的 1 在第 k 位(从 0 开始计数),那么 x 的第 0 到 k-1 位都是 0。
在 -x 中,第 0 到 k-1 位也是 0(因为取反加 1 的过程会使低位变为 0),第 k 位为 1,而更高位与 x 的对应位相反。
因此 x & (-x) 只会保留第 k 位的 1,更高位因为互补而相与为 0,更低位也都是 0。
OJ 6. 数组中出现次数超过一半的数字
数组中一定存在一个数字出现的次数超过数组长度的一半
cpp
class Solution
{
public:
int MoreThanHalfNum_Solution(vector<int>& numbers) {
sort(numbers.begin(), numbers.end());
int count = 0;
int n = numbers.size() ;
for (size_t i=0;i<n;i++)
{
if(numbers[i]==numbers[n/2])
{
count++;
}
}
if (count > n / 2)
return numbers[n / 2];
return 0;
}
}多数元素的定义是:出现次数严格大于数组长度的一半(即 count > n/2)。当数组排序后,相同的元素会连续排列。由于该元素的个数超过了一半,无论它从哪个位置开始连续,其连续区间必然覆盖数组的中间位置(下标 n/2)。因此,排序后下标 n/2 处的元素一定是多数元素。
OJ 7. 电话号码字母组合
cpp
class Solution {
public:
void func(vector<string> &res, string str, string &digits, unordered_map<char, string> &m, int k)
{
if(str.size() == digits.size())
{
res.push_back(str);
return;
}
string tmp = m[digits[k]];
for(char w : tmp)
{
str += w;
func(res, str, digits, m, k+1);
str.pop_back();
}
return ;
}
vector<string> letterCombinations(string digits) {
unordered_map<char, string> table
{
{'0', " "}, {'1',"*"}, {'2', "abc"},
{'3',"def"}, {'4',"ghi"}, {'5',"jkl"},
{'6',"mno"}, {'7',"pqrs"},{'8',"tuv"},
{'9',"wxyz"}};
vector<string> res;
if(digits == "")
return res;
func(res, "", digits, table, 0);
return res;
}
};