引言:数据孤岛的技术根源与解决思路
在企业信息化建设过程中,业务系统往往随业务发展逐步建设,形成 CRM、ERP、WMS、OA 等多个异构系统并存的局面。这些系统通常由不同厂商开发,采用独立的数据存储架构、编码规范与接口标准,天然形成数据孤岛。技术层面表现为:多源异构数据难以统一查询、跨系统数据关联需要人工干预、数据时效性无法满足实时分析需求。

数据仓库(Data Warehouse)作为解决此类问题的经典技术方案,通过分层架构设计、统一数据建模与标准化 ETL 流程,实现企业级数据的集中存储与治理。本文基于企业级数据仓库建设的通用技术实践,阐述从数据源接入到应用层输出的完整技术架构。

一、总体架构设计:三层分层模型
企业级数据仓库采用经典的三层架构设计,确保数据流转的可控性与可追溯性:

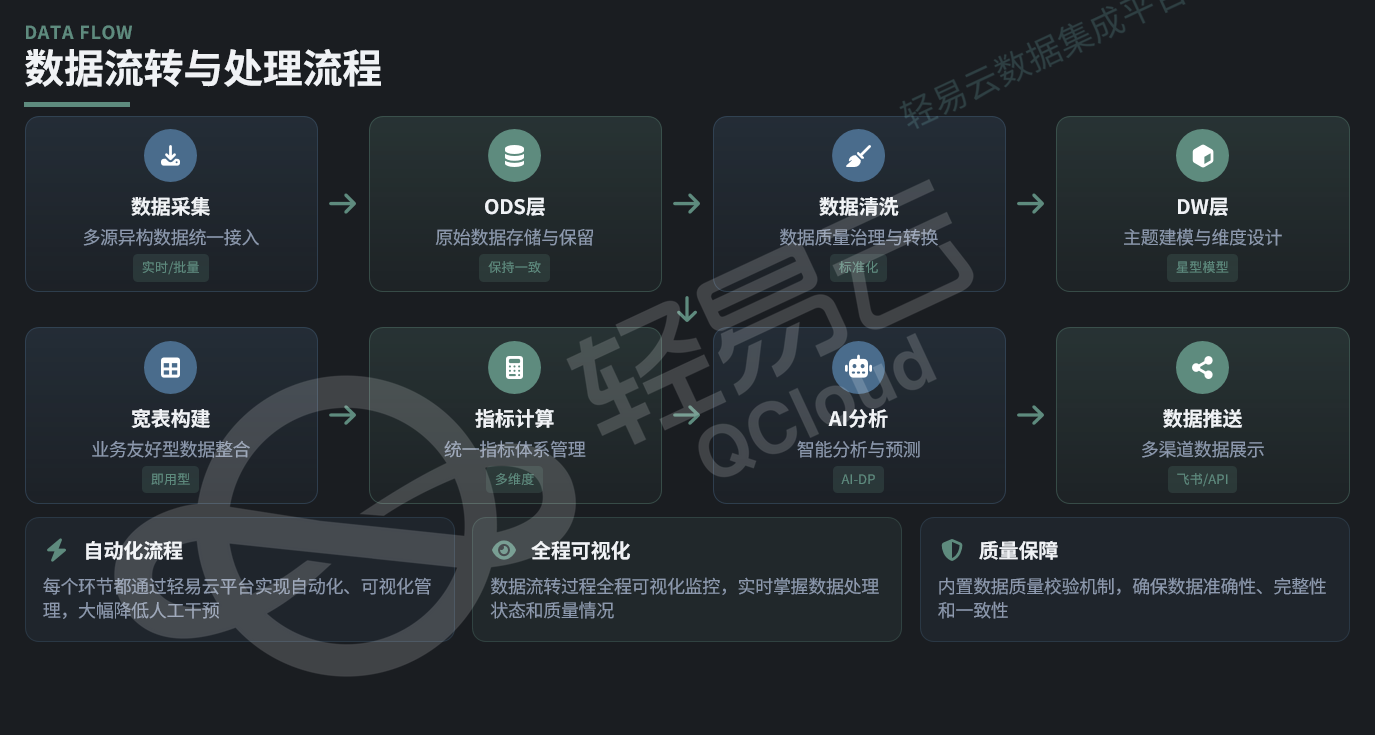
1.1 ODS 层(操作数据存储层)
ODS(Operational Data Store)作为数据入口层,承担原始数据的接收与保留职责。该层保持与源系统数据结构的一致性,不做复杂转换,主要功能包括:
- 原始数据镜像:完整保留源系统数据原貌,支持历史数据追溯
- 增量捕获:通过 CDC(Change Data Capture)或时间戳机制捕获增量数据
- 数据缓冲:作为后续处理的缓冲带,隔离源系统与数仓处理压力
1.2 DW 层(数据仓库层)
DW 层是数据仓库的核心,进行主题建模与维度设计:
- 主题域划分:通常包括客户、订单、库存、财务等核心业务主题
- 维度建模:采用星型模型或雪花模型,构建一致的维度表(如时间维、组织维、产品维)
- 数据标准化:统一编码规则(如统一客户编码、SKU 编码),解决跨系统数据对齐问题
- 数据清洗:处理缺失值、异常值、重复数据,建立主数据管理(MDM)基础
1.3 APP 层(数据应用层)
APP 层面向业务应用,提供即用的数据资产:
- 数据宽表构建:将分散在多个系统的相关数据预关联,形成扁平化的业务宽表,降低下游使用复杂度
- 指标统一管理:建立企业级指标库,统一口径(如"活跃客户"的统一定义与计算逻辑)
- 数据接口服务:封装为 API 或数据视图,供 BI 工具、业务系统或 AI 应用调用
二、多源异构数据接入的技术实现
2.1 数据源类型与接入模式
企业数据源通常包括:
| 数据源类型 | 典型系统 | 技术接入方式 |
|---|---|---|
| 关系型数据库 | MySQL、PostgreSQL、SQL Server、Oracle | JDBC/ODBC 连接、Binlog 监听 |
| NoSQL 数据库 | MongoDB | 驱动直连、Oplog 监听 |
| SaaS 应用 | CRM、ERP、WMS | REST API 对接、Webhook 推送 |
| 文件数据 | Excel、CSV、JSON | 文件上传、SFTP 同步、对象存储对接 |
| 消息队列 | Kafka、RabbitMQ | 消息订阅与消费 |
2.2 同步模式选择
根据业务场景的技术特性,选择不同的数据同步策略:
实时同步(Streaming)
- 技术方案:基于 CDC(如 MySQL Binlog、PostgreSQL WAL)或消息队列
- 适用场景:库存监控、实时风控、即时业务预警
- 技术特点:秒级延迟,对源系统性能影响需评估
批量抽取(Batch)
- 技术方案:定时调度(如基于 Cron 的 ETL 作业)
- 适用场景:财务报表、日报、历史数据分析
- 技术特点:通常在业务低峰期执行,资源占用可控
三、数据治理与质量控制
数据仓库的价值依赖于数据质量,技术层面需建立完整的治理体系:
3.1 数据质量校验
在 ETL 流程中嵌入质量检查节点:
- 完整性检查:非空字段校验、外键关联完整性
- 一致性检查:跨系统数据一致性比对(如 CRM 客户数与 ERP 客户数核对)
- 时效性监控:数据入仓延迟监控,设置 SLA 阈值告警
- 异常值检测:基于统计学方法或业务规则识别异常数据
3.2 数据血缘追溯
构建数据血缘(Data Lineage)图谱,记录数据从源系统到应用层的完整流转路径:
- 字段级血缘:追踪某个指标字段依赖的源表与转换逻辑
- 影响分析:当源系统结构变更时,快速定位受影响的下游报表与应用
- 血缘可视化:通过 DAG(有向无环图)展示数据流转关系
3.3 权限与安全管理
企业级数据权限需精细化控制:
- 行列级权限:基于角色的列级权限(如财务可见金额字段,销售不可见)与行级权限(如区域经理仅见本区域数据)
- 数据脱敏:敏感信息(如手机号、身份证)在查询层自动脱敏
- 操作审计:记录数据查询与导出日志,满足合规要求
四、数据应用与价值输出
数据仓库建设最终服务于业务分析,技术实现上需支持多样化的数据消费模式:
4.1 BI 与可视化
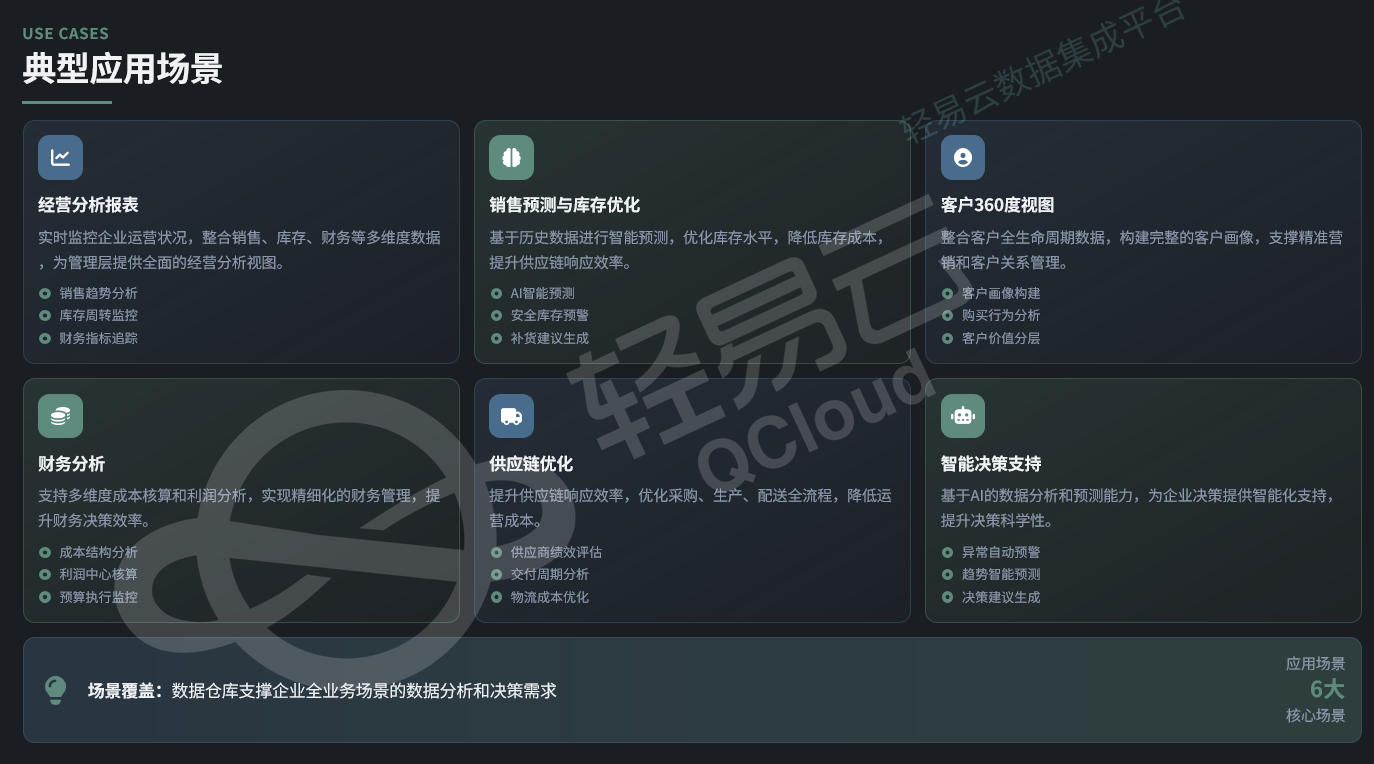
- 自助式分析:业务人员通过拖拽式界面构建报表,无需编写 SQL
- 固定报表:定时生成的标准化经营报表(如日报、周报)
- 数据下钻:支持从汇总数据逐层下钻至明细数据的多维分析(OLAP)
4.2 数据服务化(Data as a Service)
将数据能力封装为标准化 API:
- RESTful 接口:供业务系统实时查询客户 360 视图、库存状态等
- 消息推送:通过企业微信、钉钉、飞书等 IM 工具推送关键指标异常告警
- 数据订阅:允许第三方系统订阅特定数据主题的变更事件
4.3 AI 与高级分析支持
为机器学习与 AI 应用提供高质量数据基础:
- 特征工程支持:提供宽表与聚合指标,作为模型输入特征
- 样本数据提供:按时间窗口快速提取训练数据集
- 预测结果回写:将 AI 模型预测结果(如销量预测)回写至数仓,供业务系统调用
五、工程实施方法论
数据仓库项目需遵循标准化的工程实施流程,确保质量与可控性:
5.1 实施阶段划分
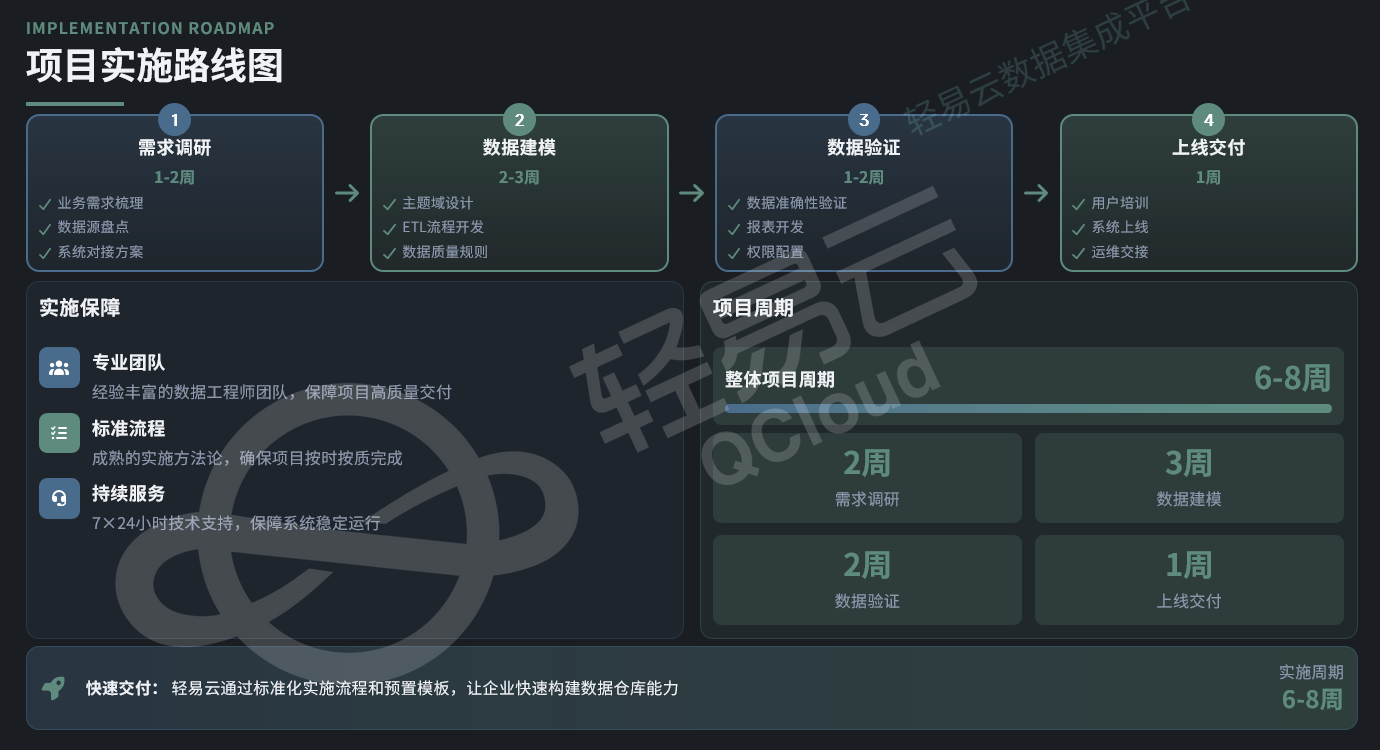
典型的数据仓库项目可分为四个阶段:
-
需求调研与数据源盘点(1-2 周)
- 业务需求收集与优先级排序
- 源系统数据字典梳理与质量评估
- 数据接入方案设计(接口方式、频率、容量评估)
-
数据建模与 ETL 开发(2-3 周)
- 主题域模型设计(维度表、事实表定义)
- ETL 流程开发与调度配置
- 数据质量规则配置
-
数据验证与报表开发(1-2 周)
- 数据准确性验证(与源系统交叉核对)
- 报表原型开发与业务确认
- 权限策略配置与测试
-
上线交付与运维交接(1 周)
- 生产环境部署与性能调优
- 用户培训与文档交付
- 运维监控体系建立(延迟告警、失败重试机制)
5.2 技术选型建议
- 存储引擎:根据数据规模选择,中小规模可采用 PostgreSQL/MySQL,大规模场景采用 ClickHouse、Apache Doris 等 OLAP 引擎
- 调度系统:Airflow、DolphinScheduler 或自研调度框架,支持依赖管理与失败重试
- 数据集成:基于开源框架(如 Apache SeaTunnel、Debezium)或自研连接器,确保多源适配能力
六、总结:数据仓库的技术价值与演进

数据仓库作为企业数据基础设施的核心组件,其技术价值体现在:
- 架构解耦:通过分层设计解耦源系统变更与下游应用,降低系统间耦合度
- 数据资产化:将分散的业务数据转化为可复用、可治理的数据资产
- 决策支持:提供一致、可信的数据视图,支撑数据驱动的业务决策
- AI 基础:为机器学习与智能化应用提供高质量、结构化的数据输入
随着实时计算技术的发展,现代数据仓库正从传统的 T+1 批处理架构向 Lambda 或 Kappa 架构演进,支持流批一体处理。企业在规划数据仓库时,应充分考虑业务增长带来的数据规模扩张,选择具备水平扩展能力的存储与计算架构,确保技术投资的长期有效性。