1.简介
在Java中分为HashMap和TreeMap,HashSet和TreeSet,C++是map和unordered_map,set和unordered_set
一般哈希表的效率更优秀一些,通过下面代码测性能确实如此
查找
1.暴力查找O(N)
2.二分,性能O(logN),要求:数据有序O(NlogN)+可随机访问,且在头部和中间位置插入代价O(N)
3.AVL,红黑树
unordered系列顾名思义遍历出来是无序的,没有rbegin迭代器,是单向迭代器
哈希,亦称散列,存储的值与位置建立一个映射关系,比如计数排序,建立大小为(max-min)的数组,每个num位置是num-min,存储的是count出现次数,问题是如果元素过于分散,空间极度浪费,这说的是哈希的直接定值法(一般用于范围小比如确认字符串中每个字符出现的次数,最多26个字母);
为了优化,提出除留余数法,N%m,m是数组大小,每个num的存储位置是num%m,问题是可能出现哈希碰撞,多个key映射同一个位置,一般采用拉链法,也称哈希桶来解决
2.效率测试
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
#include <unordered_set>
#include <set>
#include <ctime>
using namespace std;
int main() {
const int N = 1000000;
vector<int> v;
unordered_set<int> us;
set<int> s;
srand(time(0));
for (int i = 0; i < N; i++) {
v.push_back(rand());
//v.push_back(rand()+i);
//v.push_back(i);
}
size_t begin1 = clock();
for (const int& e:v)
us.insert(e);
size_t end1 = clock();
cout << "unordered_set insert: " << end1 - begin1 << endl;
size_t begin2 = clock();
for (const int& e : v)
s.insert(e);
size_t end2 = clock();
cout << "set insert: " << end2 - begin2 << endl;
cout << "unordered_set size: " << us.size() << endl;
cout << "set size: " << s.size() << endl;
size_t begin3 = clock();
for (const int& e : v)
us.find(e);
size_t end3 = clock();
cout << "unordered_set find: " << end3 - begin3 << endl;
size_t begin4 = clock();
for (const int& e : v)
s.find(e);
size_t end4 = clock();
cout << "set find: " << end4 - begin4 << endl;
size_t begin5 = clock();
for (const int& e : v)
us.erase(e);
size_t end5 = clock();
cout << "unordered_set erase: " << end5 - begin5 << endl;
size_t begin6 = clock();
for (const int& e : v)
s.erase(e);
size_t end6 = clock();
cout << "set erase: " << end6 - begin6 << endl;
return 0;
}3.简单实现
除留余数法hash表删除/插入/查找简单实现(基于线性探测)
负载因子越大,冲突概率越大,空间利用率越高;
负载因子越小,冲突概率越小,空间利用率越低,哈希表不能满了再扩容,一般负载因子(有效数据个数/总大小)在0.7~0.8之间,0.75最好就扩容
cpp
#pragma once
enum STATE {
EMPTY,
DELETE,
EXIST
};
namespace diy {
template<class K,class V>
struct HashData {
pair<K, V> _kv;
STATE _state = EMPTY;
};
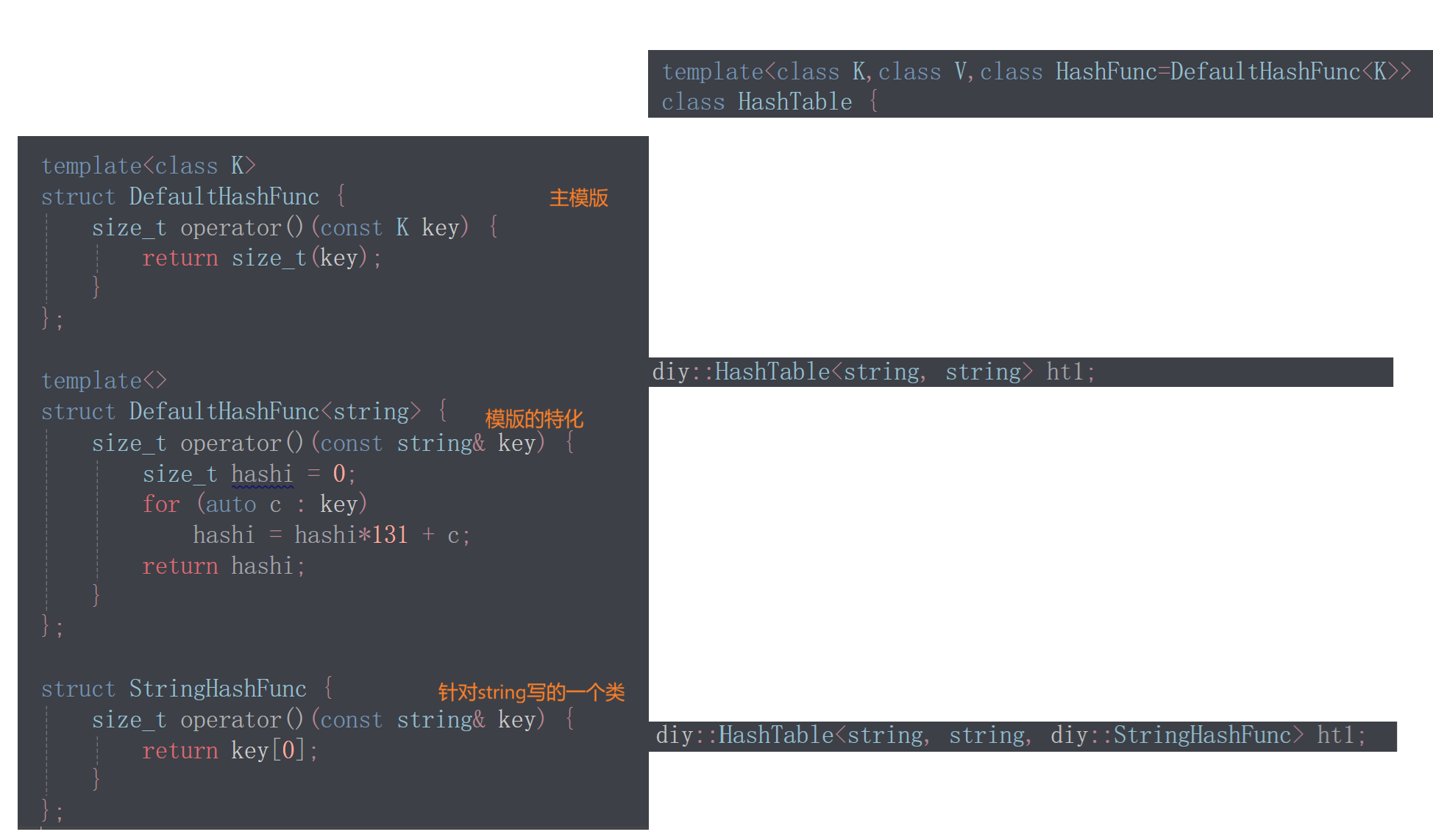
template<class K>
struct DefaultHashFunc {
size_t operator()(const K& key) {
return size_t(key);//负数的key也一并处理了
}
};
template<>
struct DefaultHashFunc<string> {//模板的特化
size_t operator()(const string& key) {
size_t hashi = 0;
for (const char& ch : key)
hashi = hashi*131 + ch;//字符串->整型比较常用,因此也有很多方法,不论哪种方法,其实不同字符串都有可能映射为相同的值,选择合适的方法尽可能降低这种概率
return hashi;
}
};
struct HashFunc {//需要在类实例化时显示传参
size_t operator()(const string& str) {
return str[0];
}
};
//仿函数(指定判断关系考虑使用仿函数):1.优先级队列用于比较 2.红黑树封装map用于获取key
//3.hash实现用来获取key,如果是string或自定义类型转为整数方便后续处理(相当于两层映射,string->整型->下标)
template<class K,class V,class HashFunc=DefaultHashFunc<K>>
class HashTable {
public:
bool Insert(const pair<K, V>& kv) {
//if ((double)_n / (double)_table.size() >= 0.7) {
if (_n * 10 / _table.size() >= 7) {//扩容
size_t newSize = _table.size() * 2;
HashTable<K, V,HashFunc> newHT;
newHT._table.resize(newSize);
for (int i = 0; i < _table.size(); i++) {//扩容后映射关系变了,重新映射(原来冲突,扩容后可能不冲突;原来不冲突,扩容后可能冲突)
if(_table[i]._state==EXIST)
newHT.Insert(_table[i]._kv);
}
_table.swap(newHT._table);
}
HashFunc hf;
size_t hashi = hf(kv.first) % _table.size();
while (_table[hashi]._state == EXIST) {
hashi++;
hashi %= _table.size();
}
_table[hashi]._kv = kv;
_table[hashi]._state = EXIST;
_n++;
return true;
}
HashData<const K, V>* Find(const K& key) {
HashFunc hf;
size_t hashi = hf(key) % _table.size();
while (_table[hashi]._state != EMPTY) {
if (_table[hashi]._state == EXIST && _table[hashi]._kv.first == key)
return (HashData<const K, V>*) & _table[hashi];
hashi++;
hashi %= _table.size();
}
return nullptr;
}
bool Erase(const K& key) {
HashData<const K, V>* ret = Find(key);
if (ret) {
ret->_state = DELETE;
_n--;
return true;
}
return false;
}
HashTable() {
_table.resize(10);
}
private:
vector<HashData<K, V>> _table;
size_t _n=0;
};
}