目录
[1. 为什么必须进行 RVA → FOA 转换?(核心矛盾)](#1. 为什么必须进行 RVA → FOA 转换?(核心矛盾))
[2. 磁盘布局 vs 内存布局(对比详解)](#2. 磁盘布局 vs 内存布局(对比详解))
[3. RVA、VA、FOA 精确定义与关系](#3. RVA、VA、FOA 精确定义与关系)
[4. RvaToFoa 函数完整技术详解(核心算法)](#4. RvaToFoa 函数完整技术详解(核心算法))
[5. 实战案例:导入表(Import Directory)为什么特别需要转换?](#5. 实战案例:导入表(Import Directory)为什么特别需要转换?)
[6. 记忆口诀 + 可视化图示](#6. 记忆口诀 + 可视化图示)
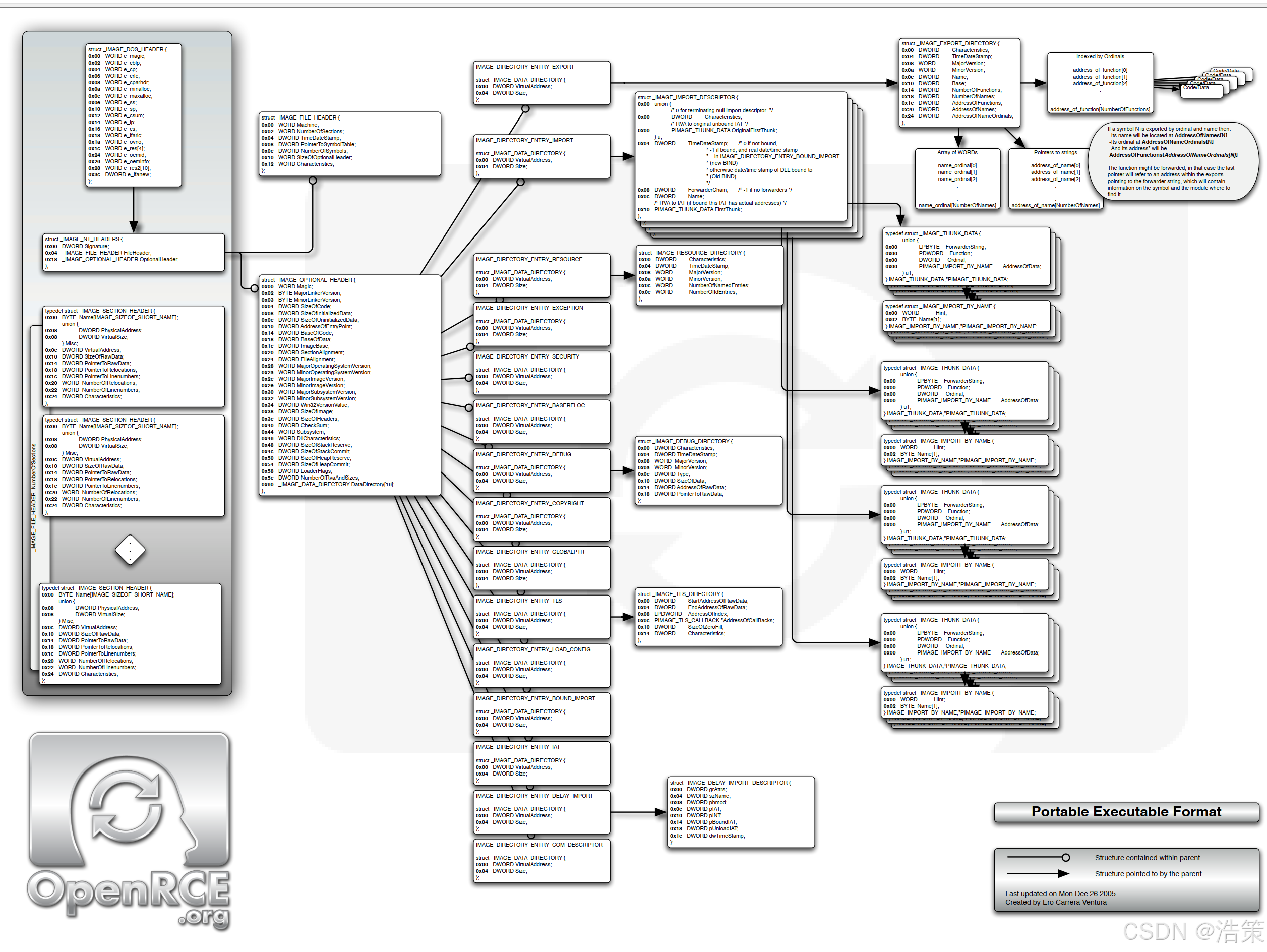
1. 为什么必须进行 RVA → FOA 转换?(核心矛盾)
当你编写 PE 文件解析工具 、逆向分析器、加壳/脱壳程序、恶意代码分析器,或任何直接操作 .exe / .dll 文件内容的代码时,你会立刻遇到一个无法回避的核心矛盾:
-
PE 文件头(Optional Header 的 Data Directory) 中记录的所有关键表格地址(如导入表、导出表、资源表、重定位表、TLS 表等)全部使用 RVA(Relative Virtual Address,相对虚拟地址)。
-
但你实际操作的是磁盘上的原始文件数据 (通过
fopen/fread读取到的字节缓冲区),数据的定位方式只能是 FOA(File Offset Address,文件偏移地址,也称为 Raw Offset 或 Pointer to Raw Data)。 -
不进行转换,你将无法正确读取任何数据结构。
-
直接把 RVA 当作缓冲区下标使用,会导致读取完全错误的位置、程序崩溃、或解析出垃圾数据。
-
根本原因 :PE 文件在磁盘(文件布局) 和 内存(加载后布局) 中的组织方式完全不同。
2. 磁盘布局 vs 内存布局(对比详解)
磁盘上的 PE 文件布局(线性、紧凑、节省磁盘空间):
-
文件从头开始依次为:DOS Header(MZ)→ DOS Stub → PE Signature(PE\0\0)→ File Header → Optional Header → Section Table(节表) → 各个 Section 的原始数据。
-
头部(直到 Section Table 结束)在磁盘和内存中大小基本一致(对齐后差异极小)。
-
每个 Section 的数据按 FileAlignment 对齐 (通常
0x200= 512 字节),可能存在填充(padding),但整体是连续的线性字节流。 -
使用
fseek(fp, FOA)或buffer + FOA即可直接定位。
内存中的 PE 镜像布局(由 Windows Loader 映射,虚拟化、对齐、保护):
-
Loader 以 ImageBase (Optional Header 中定义,通常
0x400000或0x10000000)为起点,将整个文件映射到虚拟地址空间。 -
按照 Section Table 的指示,把每个 Section 独立映射到对应的 RVA 位置。
-
每个 Section 在内存中按 SectionAlignment 对齐 (通常
0x1000= 4KB 页对齐),以便设置不同的内存保护属性(.text可执行、.data可读写、.rdata只读等)。 -
可能出现 VirtualSize > SizeOfRawData (未初始化数据如
.bss在内存中分配空间,但文件中不占字节)或空洞(未映射区域)。
简单总结:
|------|--------------------------|--------------------------|
| 维度 | 磁盘布局(FOA) | 内存布局(RVA) |
| 组织方式 | 线性连续字节流 | 按节独立映射 + 页对齐 |
| 对齐方式 | FileAlignment(通常 512 字节) | SectionAlignment(通常 4KB) |
| 空间目标 | 节省磁盘空间 | 便于内存保护与分页 |
| 头部大小 | 与内存基本一致 | 与磁盘基本一致 |
| 典型差异 | 可能有填充、紧凑存放 | 可能有空洞、VirtualSize 更大 |
PE 设计者的智慧 :程序运行时只关心"加载到内存后我在哪里",因此所有内部结构地址都使用 RVA(相对于 ImageBase 的偏移)。
这就产生了经典口诀:"手在读文件,脑得想内存,RvaToFoa 就是那座桥。"
3. RVA、VA、FOA 精确定义与关系
- VA (Virtual Address) :程序加载到内存后的绝对虚拟地址。
示例:ImageBase = 0x400000,RVA = 0x2000 → VA = 0x400000 + 0x2000 = 0x402000。
- RVA (Relative Virtual Address):相对于 ImageBase 的偏移量。
PE 头中几乎所有 Data Directory(如导入表地址)记录的都是 RVA。它描述的是"加载后离 ImageBase 多远"。
- FOA (File Offset Address):磁盘文件中实际的字节偏移。
buffer[FOA] 即可直接读取对应数据。
RVA ≠ FOA 的根源:
-
FileAlignment 与 SectionAlignment 的差异。
-
VirtualSize 可能大于 SizeOfRawData。
-
节在内存中独立映射导致的"错位"。
4. RvaToFoa 函数完整技术详解(核心算法)
RvaToFoa 的本质是通过 Section Table 建立 RVA → FOA 的映射桥梁。
每个 IMAGE_SECTION_HEADER(40 字节)包含的关键字段:
-
Name[8]:节名称(如.text、.data、.rdata) -
VirtualSize:内存中实际大小(可能大于文件大小) -
VirtualAddress:该节在内存中的起始 RVA -
SizeOfRawData:文件中实际占用字节(按 FileAlignment 对齐) -
PointerToRawData:该节在文件中的起始偏移(FOA) -
Characteristics:节属性(可执行、可写等)
完整转换算法步骤:
-
遍历 Section Table (共
NumberOfSections个节,从 NT Headers 后开始)。 -
判断 RVA 是否落入当前节 (推荐使用
VirtualSize):if (dwRva >= Section.VirtualAddress && dwRva < Section.VirtualAddress + Section.VirtualSize) -
计算 FOA:
FOA = (dwRva - Section.VirtualAddress) + Section.PointerToRawData; -
边界与特殊情况处理:
-
RVA 落在头部(<
SizeOfHeaders):直接返回 RVA(头部布局几乎一致)。 -
RVA 不在任何节内:返回 0 或报错。
-
VirtualSize > SizeOfRawData:内存有额外零填充,但文件读取只关心 Raw 数据。 -
特殊目录(如 Certificate Table):VirtualAddress 可能直接是文件偏移,需按 PE 规范区分处理。
-
生产级伪代码
DWORD RvaToFoa(PIMAGE_NT_HEADERS pNt, DWORD dwRva)
{
if (dwRva == 0) return 0;
PIMAGE_SECTION_HEADER pSection = IMAGE_FIRST_SECTION(pNt);
for (WORD i = 0; i < pNt->FileHeader.NumberOfSections; i++)
{
DWORD secStart = pSection->VirtualAddress;
// 使用 max 更安全,兼容 VirtualSize > SizeOfRawData 的情况
DWORD secEnd = secStart + max(pSection->VirtualSize, pSection->SizeOfRawData);
if (dwRva >= secStart && dwRva < secEnd)
{
return (dwRva - secStart) + pSection->PointerToRawData;
}
pSection++;
}
// 落在 PE 头部
if (dwRva < pNt->OptionalHeader.SizeOfHeaders)
return dwRva;
return 0; // 无效 RVA
}5. 实战案例:导入表(Import Directory)为什么特别需要转换?
BYTE* buffer = ...; // fread 读取的整个文件
PIMAGE_NT_HEADERS pNt = ...;
// 错误写法(直接用 RVA)
PIMAGE_IMPORT_DESCRIPTOR pImport = (PIMAGE_IMPORT_DESCRIPTOR)(buffer + importRVA);
// 正确写法
DWORD foa = RvaToFoa(pNt, importRVA);
PIMAGE_IMPORT_DESCRIPTOR pImport = (PIMAGE_IMPORT_DESCRIPTOR)(buffer + foa);后续的 DLL 名称、Import Lookup Table (ILT)、Import Address Table (IAT) 等字段也都是 RVA,必须反复调用 RvaToFoa 才能正确读取。
所有 PE 结构(导出表、资源、异常表、重定位等)都遵循同一原则。
6. 记忆口诀 + 可视化图示
终极口诀:
"RVA 是内存视角,FOA 是文件视角;手在读文件,脑得想内存,RvaToFoa 就是桥。"
可视化对比图示:
磁盘布局(线性紧凑) 内存布局(按页对齐)
┌────────────────────┐ ┌─────────────────────────────┐
│ PE Headers │ │ ImageBase │
├────────────────────┤ Loader映射 │ + RVA .text (0x1000) │
│ .text raw │ ───────────► │ ... 代码 ... │
│ (FOA 0x400) │ ├─────────────────────────────┤
├────────────────────┤ │ + RVA .data (0x2000) │
│ .data raw │ │ ... 数据 ... │
│ (FOA 0x0A00) │ └─────────────────────────────┘
└────────────────────┘
示例计算:
RVA = 0x2100(落在 .data 节)
FOA = (0x2100 - 0x2000) + 0x0A00 = 0x0B00好了到此为止:PE结构的基础部分更新就OK了 后面是与安全以及对抗相关PE结构的实战技术点了。