用动量提升对抗攻击
Yinpeng Dong 1^{1}1 , Fangzhou Liao 1^{1}1 , Tianyu Pang 1^{1}1 , Hang Su 1^{1}1 , Jun Zhu 1^{1}1 , Xiaolin Hu 1^{1}1 , Jianguo Li 2^{2}2
1^{1}1 计算机科学与技术系,清华大学脑与智能实验室
1^{1}1 北京信息科学与技术国家研究中心,BNRist 实验室
1^{1}1 清华大学,中国 100084
2^{2}2 英特尔中国实验室
{dyp17, liaofz13, pty17}@mails.tsinghua.edu.cn, {suhangss, dcszj,xlhu}@mail.tsinghua.edu.cn, jianguo.li@intel.com
摘要
深度神经网络易受对抗样本的影响,由于可能产生严重后果,这给这些算法带来了安全担忧。对抗攻击作为一种重要的替代方法,用于在部署深度学习模型之前评估其鲁棒性。然而,现有的大多数对抗攻击只能以较低的成功率欺骗黑盒模型。为了解决这个问题,我们提出了一类广泛的基于动量的迭代算法来提升对抗攻击。通过将动量项集成到攻击的迭代过程中,我们的方法可以稳定更新方向,并在迭代过程中逃离较差的局部极大值,从而生成更具可迁移性的对抗样本。为了进一步提高黑盒攻击的成功率,我们将动量迭代算法应用于模型集成,并表明具有强大防御能力的对抗训练模型也容易受到我们的黑盒攻击。我们希望所提出的方法将作为评估各种深度模型和防御方法鲁棒性的基准。凭借此方法,我们在 NIPS 2017 非针对性对抗攻击和针对性对抗攻击竞赛中均获得第一名。
1. 引言
深度神经网络 (DNN) 因其对对抗样本的脆弱性而受到挑战 23, 5,这些对抗样本是通过向合法样本添加人类难以察觉的小噪声而生成的,但会使模型输出攻击者期望的错误预测。生成对抗样本已引起越来越多的关注,因为它有助于在模型部署之前识别其脆弱性。此外,对抗样本还通过提供更多样化的训练数据来促进各种 DNN 算法评估鲁棒性 5, 10。

图 1. 我们展示了针对 Inception v3 22 模型,使用所提出的动量迭代快速梯度符号方法 (MI-FGSM) 生成的两个对抗样本。左列:原始图像。中列:应用 MI-FGSM 迭代 10 次生成的对抗噪声。右列:生成的对抗图像。我们还展示了 Inception v3 对这些图像的预测标签和概率。
在给定模型结构和参数的情况下,许多方法可以以白盒方式成功生成对抗样本,包括基于优化的方法(如带盒约束的 L-BFGS 23)、基于单步梯度的方法(如快速梯度符号 5)以及基于梯度的迭代变体 9。一般来说,对抗样本一个更严重的问题是它们具有良好的可迁移性 23, 12, 14,即为一个模型制作的对抗样本对其他模型仍然具有对抗性,从而使得黑盒攻击在实际应用中成为可能,并带来真正的安全问题。可迁移性现象是由于不同的机器学习模型在数据点附近学习到相似的决策边界,因此为一个模型制作的对抗样本对其他模型也有效。
然而,现有的攻击方法在攻击黑盒模型时效果不佳,尤其是对那些具有防御机制的模型。例如,集成对抗训练 24 显著提高了深度神经网络的鲁棒性,而大多数现有方法无法以黑盒方式成功攻击它们。这一事实很大程度上归因于攻击能力与可迁移性之间的权衡。特别地,基于优化和迭代方法生成的对抗样本可迁移性较差 10,从而使黑盒攻击效果不佳。另一方面,单步基于梯度的方法生成更具可迁移性的对抗样本,但它们对白盒模型的成功率通常较低 10,导致黑盒攻击无效。鉴于实际黑盒攻击的困难,Papernot 等人 16 使用自适应查询来训练一个替代模型,以完全刻画目标模型的行为,从而将黑盒攻击转化为白盒攻击。然而,这需要目标模型给出完整的预测置信度以及大量的查询,尤其是在 ImageNet 19 这样的大规模数据集上。这些要求在实际应用中是不现实的。因此,我们考虑如何在不知道目标模型架构和参数的情况下,甚至无需查询,有效地攻击黑盒模型。
在本文中,我们提出了一类广泛的动量迭代梯度方法,以提高生成对抗样本的成功率。在迭代梯度方法(通过每次迭代对输入添加梯度方向的扰动以最大化损失函数 5)的基础上,基于动量的方法在迭代过程中累积损失函数梯度方向的速度向量,以稳定更新方向并逃离较差的局部极大值。我们展示了由动量迭代方法生成的对抗样本在白盒和黑盒攻击中都具有更高的成功率。所提出的方法缓解了白盒攻击与可迁移性之间的权衡,并且比单步方法 5 和普通迭代方法 9 更强大。
为了进一步提高对抗样本的可迁移性,我们研究了攻击模型集成的几种方法,因为如果一个对抗样本能够欺骗多个模型,那么它更有可能对其他黑盒模型仍然具有对抗性 12。我们展示了由动量迭代方法为多个模型生成的对抗样本,能够以黑盒方式成功欺骗通过集成对抗训练 24 获得的鲁棒模型。本文的发现为开发更鲁棒的深度学习模型提出了新的安全问题,希望我们的攻击将被用作评估各种深度学习模型和防御方法鲁棒性的基准。总之,我们做出了以下贡献:
- 我们引入了一类称为动量迭代梯度方法的攻击算法,其中我们在每次迭代中累积损失函数的梯度,以稳定优化并逃离较差的局部极大值。
- 我们研究了同时攻击多个模型的几种集成方法,通过保持高攻击成功率展示了强大的可迁移能力。
- 我们首次表明,通过具有强大防御能力的集成对抗训练获得的模型也容易受到黑盒攻击。
2. 背景
在本节中,我们提供背景知识并回顾关于对抗攻击和防御方法的相关工作。给定一个分类器 f(x):x∈X→y∈Yf(\mathbf{x}):\mathbf{x}\in \mathcal{X}\rightarrow y\in \mathcal{Y}f(x):x∈X→y∈Y,输出标签 yyy 作为对输入 x\mathbf{x}x 的预测,对抗攻击的目标是寻找一个接近 x\mathbf{x}x 但被分类器错误分类的样本 x∗\mathbf{x}^{*}x∗。具体来说,有两类对抗样本:非针对性和针对性。对于一个被正确分类的输入 x\mathbf{x}x,其真实标签为 yyy 且 f(x)=yf(\mathbf{x}) = yf(x)=y,非针对性对抗样本 x∗\mathbf{x}^{*}x∗ 通过向 x\mathbf{x}x 添加微小噪声(不改变标签)而生成,但误导分类器使得 f(x∗)≠yf(\mathbf{x}^{*}) \neq yf(x∗)=y;而针对性对抗样本旨在欺骗分类器输出特定标签,即 f(x∗)=y∗f(\mathbf{x}^{*}) = y^{*}f(x∗)=y∗,其中 y∗y^{*}y∗ 是攻击者指定的目标标签,且 y∗≠yy^{*} \neq yy∗=y。在大多数情况下,对抗噪声的 LpL_{p}Lp 范数被要求小于一个允许值 \\epsilon,即 ∥x∗−x∥p≤ϵ\|\mathbf{x}^{*} - \mathbf{x}\|_{p} \leq \epsilon∥x∗−x∥p≤ϵ,其中 ppp 可以是 0,1,2, ∞\infty∞。
2.1. 攻击方法
现有生成对抗样本的方法可以分为三类。我们在此介绍它们的非针对性攻击版本,针对性版本可以简单推导。
单步梯度方法 ,例如快速梯度符号方法 (FGSM) 5,通过最大化损失函数 J(x∗,y)J(\mathbf{x}^{*},y)J(x∗,y) 来寻找对抗样本 x∗\mathbf{x}^{*}x∗,其中 JJJ 通常是交叉熵损失。FGSM 生成满足 L∞L_{\infty}L∞ 范数约束 ∥x∗−x∥∞≤ϵ\|\mathbf{x}^{*} - \mathbf{x}\|_{\infty} \leq \epsilon∥x∗−x∥∞≤ϵ 的对抗样本:
x∗=x+ϵ⋅sign(∇xJ(x,y)),(1)\mathbf{x}^{*} = \mathbf{x} + \epsilon \cdot \mathrm{sign}(\nabla_{\mathbf{x}}J(\mathbf{x},y)),\quad (1)x∗=x+ϵ⋅sign(∇xJ(x,y)),(1)$
其中 ∇xJ(x,y)\nabla_{\mathbf{x}}J(\mathbf{x},y)∇xJ(x,y) 是损失函数关于 x\mathbf{x}x 的梯度。快速梯度方法 (FGM) 是 FGSM 的推广,以满足 L2L_{2}L2 范数约束 ∥x∗−x∥2≤ϵ\|\mathbf{x}^{*} - \mathbf{x}\|_{2} \leq \epsilon∥x∗−x∥2≤ϵ:
x∗=x+ϵ⋅∇xJ(x,y)∥∇xJ(x,y)∥2.(2)\mathbf{x}^{*} = \mathbf{x} + \epsilon \cdot \frac{\nabla_{\mathbf{x}}J(\mathbf{x},y)}{\|\nabla_{\mathbf{x}}J(\mathbf{x},y)\|_{2}}. \quad (2)x∗=x+ϵ⋅∥∇xJ(x,y)∥2∇xJ(x,y).(2)
迭代方法 9 多次迭代应用快速梯度,步长 α\alphaα 较小。FGSM 的迭代版本 (I-FGSM) 可以表示为:
x0∗=x,xt+1∗=xt∗+α⋅sign(∇xJ(xt∗,y)).(3)\mathbf{x}{0}^{*} = \mathbf{x},\quad \mathbf{x}{t+1}^{*} = \mathbf{x}{t}^{*} + \alpha \cdot \mathrm{sign}(\nabla{\mathbf{x}}J(\mathbf{x}_{t}^{*},y)). \quad (3)x0∗=x,xt+1∗=xt∗+α⋅sign(∇xJ(xt∗,y)).(3)
为了使生成的对抗样本满足 L∞L_{\infty}L∞(或 L2L_{2}L2)约束,可以将 xt∗\mathbf{x}_{t}^{*}xt∗ 裁剪到 x\mathbf{x}x 的 ϵ\epsilonϵ 邻域内,或者简单地设置 α=ϵ/T\alpha = \epsilon / Tα=ϵ/T,其中 TTT 是迭代次数。已有研究表明,迭代方法比单步方法更强大的白盒攻击者,但代价是可迁移性更差 10, 24。
基于优化的方法 23 直接优化真实样本与对抗样本之间的距离,同时要求对抗样本被错误分类。可以使用带盒约束的 L-BFGS 来解决此类问题。一种更复杂的方法 1 是求解:
argminx∗ λ⋅∥x∗−x∥p−J(x∗,y).(4)\underset{\mathbf{x}^{*}}{\arg \min}\; \lambda \cdot \|\mathbf{x}^{*} - \mathbf{x}\|_{p} - J(\mathbf{x}^{*},y). \quad (4)x∗argminλ⋅∥x∗−x∥p−J(x∗,y).(4)
由于它直接优化对抗样本与对应真实样本之间的距离,因此无法保证 L∞L_{\infty}L∞(或 L2L_{2}L2)距离小于要求值。基于优化的方法也像迭代方法一样缺乏黑盒攻击的有效性。
2.2. 防御方法
在众多尝试 13, 3, 15, 10, 24, 17, 11 中,对抗训练是提高 DNN 鲁棒性最广泛研究的方法 5, 10, 24。通过将对抗样本注入训练过程,对抗训练的模型学会抵抗损失函数梯度方向的扰动。然而,由于对抗样本的生成与正在训练的参数之间存在耦合,它们并不能赋予对黑盒攻击的鲁棒性。集成对抗训练 24 不仅使用从正在训练的模型产生的对抗样本,还使用从其他保留模型产生的对抗样本来扩充训练数据。因此,集成对抗训练的模型对单步攻击和黑盒攻击具有鲁棒性。
3. 方法
在本文中,我们提出了一类广泛的动量迭代梯度方法来生成对抗样本,这些样本可以欺骗白盒模型以及黑盒模型。在本节中,我们详细阐述所提出的算法。我们首先说明如何将动量集成到迭代 FGSM 中,从而产生动量迭代快速梯度符号方法 (MI-FGSM),以非针对性攻击方式生成满足 L∞L_{\infty}L∞ 范数约束的对抗样本。然后,我们提出了几种高效攻击模型集成的方法。最后,我们将 MI-FGSM 扩展到 L2L_{2}L2 范数约束和针对性攻击,产生了一类广泛的攻击方法。
算法 1 MI-FGSM
输入 : 分类器 fff 及其损失函数 JJJ;真实样本 x\mathbf{x}x 和真实标签 yyy
输入 : 扰动大小 ϵ\epsilonϵ;迭代次数 TTT 和衰减因子 μ\muμ
输出 : 对抗样本 x∗\mathbf{x}^{*}x∗ 满足 ∥x∗−x∥∞≤ϵ\|\mathbf{x}^{*} - \mathbf{x}\|_{\infty} \leq \epsilon∥x∗−x∥∞≤ϵ
1: α=ϵ/T\alpha = \epsilon / Tα=ϵ/T
2: g0=0; x0∗=xg_{0} = 0;\; \mathbf{x}_{0}^{*} = \mathbf{x}g0=0;x0∗=x
3: for t=0t = 0t=0 to T−1T - 1T−1 do
4: 将 xt∗\mathbf{x}{t}^{*}xt∗ 输入 fff,得到梯度 ∇xJ(xt∗,y)\nabla{\mathbf{x}}J(\mathbf{x}_{t}^{*},y)∇xJ(xt∗,y)
5: 通过累积梯度方向的速度向量更新 gt+1g_{t+1}gt+1:
gt+1=μ⋅gt+∇xJ(xt∗,y)∥∇xJ(xt∗,y)∥1;(6)g_{t+1} = \mu \cdot g_{t} + \frac{\nabla_{\mathbf{x}}J(\mathbf{x}{t}^{*},y)}{\|\nabla{\mathbf{x}}J(\mathbf{x}{t}^{*},y)\|{1}}; \quad (6)gt+1=μ⋅gt+∥∇xJ(xt∗,y)∥1∇xJ(xt∗,y);(6)
6: 通过应用符号梯度更新 xt+1∗\mathbf{x}{t+1}^{*}xt+1∗:xt+1∗=xt∗+α⋅sign(gt+1);(7)\mathbf{x}{t+1}^{*} = \mathbf{x}{t}^{*} + \alpha \cdot \mathrm{sign}(g{t+1}); \quad (7)xt+1∗=xt∗+α⋅sign(gt+1);(7)
7: end for
8: return x∗=xT∗\mathbf{x}^{*} = \mathbf{x}_{T}^{*}x∗=xT∗
3.1. 动量迭代快速梯度符号方法
动量方法 18 是一种通过在迭代过程中累积损失函数梯度方向的速度向量来加速梯度下降算法的技术。对先前梯度的记忆有助于穿过狭窄的山谷、小丘和较差的局部极小值或极大值 4。动量方法在随机梯度下降中也显示出稳定更新的有效性 20。我们将动量的思想应用于生成对抗样本,并获得了巨大的收益。
为了从真实样本 x\mathbf{x}x 生成满足 L∞L_{\infty}L∞ 范数约束的非针对性对抗样本 x∗\mathbf{x}^{*}x∗,基于梯度的方法通过求解以下约束优化问题来寻找对抗样本:
argmaxx∗ J(x∗,y),s.t.∥x∗−x∥∞≤ϵ,(5)\underset{\mathbf{x}^{*}}{\arg \max}\; J(\mathbf{x}^{*},y),\quad \mathrm{s.t.}\quad \|\mathbf{x}^{*} - \mathbf{x}\|_{\infty} \leq \epsilon, \quad (5)x∗argmaxJ(x∗,y),s.t.∥x∗−x∥∞≤ϵ,(5)
其中 ϵ\epsilonϵ 是对抗扰动的大小。FGSM 通过假设数据点附近决策边界的线性性,仅一次应用梯度的符号(公式 (1))来生成对抗样本。然而在实践中,当失真较大时,线性假设可能不成立 12,这使得 FGSM 生成的对抗样本"欠拟合"模型,限制了其攻击能力。相比之下,迭代 FGSM 在每次迭代中贪婪地沿梯度符号方向移动对抗样本(公式 (3))。因此,对抗样本容易陷入较差的局部极大值并"过拟合"模型,从而不太可能跨模型迁移。
为了打破这种困境,我们将动量集成到迭代 FGSM 中,以稳定更新方向并逃离较差的局部极大值。因此,基于动量的方法在增加迭代次数的同时保持了对抗样本的可迁移性,并且像迭代 FGSM 一样成为白盒模型的强大攻击者。它缓解了攻击能力与可迁移性之间的权衡,展现了强大的黑盒攻击能力。
动量迭代快速梯度符号方法 (MI-FGSM) 如算法 1 所示。具体地,gtg_{t}gt 以衰减因子 μ\muμ 收集前 ttt 次迭代的梯度,如公式 (6) 所定义。然后,在第 ttt 次迭代时的对抗样本 xt∗\mathbf{x}{t}^{*}xt∗ 沿着 gtg{t}gt 的符号方向以步长 α\alphaα 进行扰动,如公式 (7)。如果 μ=0\mu = 0μ=0,MI-FGSM 退化为迭代 FGSM。在每次迭代中,当前梯度 ∇xJ(xt∗,y)\nabla_{\mathbf{x}}J(\mathbf{x}{t}^{*},y)∇xJ(xt∗,y) 以其自身的 L1L{1}L1 距离(任何距离度量都可行)进行归一化,因为我们注意到不同迭代中梯度的尺度大小变化很大。
3.2. 攻击模型集成
在本节中,我们研究如何高效地攻击模型集成。集成方法已被广泛用于研究和竞赛中,以提高性能和改进鲁棒性 6, 8, 2。集成的思想也可以应用于对抗攻击,因为如果一个样本对多个模型仍然具有对抗性,它可能捕捉到一个总是能欺骗这些模型的内在方向,并且同时更有可能迁移到其他模型 12,从而实现强大的黑盒攻击。
我们提出攻击多个模型,并将其 logit 激活融合在一起,我们将此方法称为 logits 集成。由于 logits 捕捉了概率预测之间的对数关系,通过 logits 融合的模型集成聚合了所有模型的精细输出,其脆弱性容易被发现。具体地,为了攻击 KKK 个模型的集成,我们将 logits 融合为:
l(x)=∑k=1Kwklk(x),(8)l(\mathbf{x}) = \sum_{k=1}^{K} w_{k} l_{k}(\mathbf{x}), \quad (8)l(x)=∑k=1Kwklk(x),(8)
其中 lk(x)l_{k}(\mathbf{x})lk(x) 是第 kkk 个模型的 logits,wkw_{k}wk 是集成权重,满足 wk≥0w_{k} \geq 0wk≥0 且 ∑k=1Kwk=1\sum_{k=1}^{K} w_{k} = 1∑k=1Kwk=1。给定真实标签 yyy 和 logits l(x)l(\mathbf{x})l(x),损失函数 J(x,y)J(\mathbf{x},y)J(x,y) 定义为 softmax 交叉熵损失:
J(x,y)=−1y⋅log(softmax(l(x))),(9)J(\mathbf{x},y) = -\mathbf{1}_{y} \cdot \log(\mathrm{softmax}(l(\mathbf{x}))), \quad (9)J(x,y)=−1y⋅log(softmax(l(x))),(9)
其中 1y\mathbf{1}_{y}1y 是 yyy 的独热编码。我们在算法 2 中总结了针对 logits 平均的多个模型进行攻击的 MI-FGSM 算法。
为了比较,我们还介绍了两种替代的集成方案,其中一种已被研究 12。具体地,KKK 个模型可以在预测上平均 12:p(x)=∑k=1Kwkpk(x)\mathbf{p}(\mathbf{x}) = \sum_{k=1}^{K} w_{k} \mathbf{p}{k}(\mathbf{x})p(x)=∑k=1Kwkpk(x),其中 pk(x)\mathbf{p}{k}(\mathbf{x})pk(x) 是第 kkk 个模型在输入 x\mathbf{x}x 下的预测概率。KKK 个模型也可以在损失上平均:J(x,y)=∑k=1KwkJk(x,y)J(\mathbf{x},y) = \sum_{k=1}^{K} w_{k} J_{k}(\mathbf{x},y)J(x,y)=∑k=1KwkJk(x,y)。在这三种方法中,唯一的区别是在哪里组合多个模型的输出,但它们导致不同的攻击能力。我们通过实验发现,在各种攻击方法和集成中的各种模型之间,logits 集成比预测集成和损失集成表现更好,这将在第 4.3.1 节中展示。
算法 2 用于模型集成的 MI-FGSM
输入 : KKK 个分类器的 logits l1,l2,...,lKl_{1}, l_{2}, \ldots, l_{K}l1,l2,...,lK;集成权重 w1,w2,...,wKw_{1}, w_{2}, \ldots, w_{K}w1,w2,...,wK;真实样本 x\mathbf{x}x 和真实标签 yyy
输入 : 扰动大小 ϵ\epsilonϵ;迭代次数 TTT 和衰减因子 μ\muμ
输出 : 对抗样本 x∗\mathbf{x}^{*}x∗ 满足 ∥x∗−x∥∞≤ϵ\|\mathbf{x}^{*} - \mathbf{x}\|_{\infty} \leq \epsilon∥x∗−x∥∞≤ϵ
1: α=ϵ/T\alpha = \epsilon / Tα=ϵ/T
2: g0=0; x0∗=xg_{0} = 0;\; \mathbf{x}_{0}^{*} = \mathbf{x}g0=0;x0∗=x
3: for t=0t = 0t=0 to T−1T - 1T−1 do
4: 输入 xt∗\mathbf{x}{t}^{*}xt∗,输出 lk(xt∗)l{k}(\mathbf{x}_{t}^{*})lk(xt∗) 对于 k=1,2,...,Kk = 1,2,\ldots,Kk=1,2,...,K
5: 融合 logits:l(xt∗)=∑k=1Kwklk(xt∗)l(\mathbf{x}{t}^{*}) = \sum{k=1}^{K} w_{k} l_{k}(\mathbf{x}_{t}^{*})l(xt∗)=∑k=1Kwklk(xt∗)
6: 基于 l(xt∗)l(\mathbf{x}{t}^{*})l(xt∗) 和公式 (9) 得到 softmax 交叉熵损失 J(xt∗,y)J(\mathbf{x}{t}^{*},y)J(xt∗,y)
7: 获得梯度 ∇xJ(xt∗,y)\nabla_{\mathbf{x}} J(\mathbf{x}_{t}^{*},y)∇xJ(xt∗,y)
8: 通过公式 (6) 更新 gt+1g_{t+1}gt+1
9: 通过公式 (7) 更新 xt+1∗\mathbf{x}_{t+1}^{*}xt+1∗
10: end for
11: return x∗=xT∗\mathbf{x}^{*} = \mathbf{x}_{T}^{*}x∗=xT∗
3.3. 扩展
动量迭代方法可以轻松推广到其他攻击设置。通过将当前梯度替换为所有先前步骤的累积梯度,任何迭代方法都可以扩展为其动量变体。这里我们介绍在 L2L_{2}L2 范数约束攻击和针对性攻击方面生成对抗样本的方法。
为了在 L2L_{2}L2 距离度量下找到满足 ∥x∗−x∥2≤ϵ\|\mathbf{x}^{*} - \mathbf{x}\|_{2} \leq \epsilon∥x∗−x∥2≤ϵ 的对抗样本,迭代快速梯度方法的动量变体 (MI-FGM) 可以写为:
xt+1∗=xt∗+α⋅gt+1∥gt+1∥2,(10)\mathbf{x}{t+1}^{*} = \mathbf{x}{t}^{*} + \alpha \cdot \frac{g_{t+1}}{\|g_{t+1}\|_{2}}, \quad (10)xt+1∗=xt∗+α⋅∥gt+1∥2gt+1,(10)
其中 gt+1g_{t+1}gt+1 由公式 (6) 定义,α=ϵ/T\alpha = \epsilon / Tα=ϵ/T,TTT 是总迭代次数。
对于针对性攻击,寻找被错误分类为目标类别 y∗y^{*}y∗ 的对抗样本的目标是最小化损失函数 J(x∗,y∗)J(\mathbf{x}^{*}, y^{*})J(x∗,y∗)。累积梯度推导为:
gt+1=μ⋅gt+∇xJ(xt∗,y∗)∥∇xJ(xt∗,y∗)∥1.(11)g_{t+1} = \mu \cdot g_{t} + \frac{\nabla_{\mathbf{x}} J(\mathbf{x}{t}^{*}, y^{*})}{\|\nabla{\mathbf{x}} J(\mathbf{x}{t}^{*}, y^{*})\|{1}}. \quad (11)gt+1=μ⋅gt+∥∇xJ(xt∗,y∗)∥1∇xJ(xt∗,y∗).(11)
具有 L∞L_{\infty}L∞ 范数约束的针对性 MI-FGSM 为:
xt+1∗=xt∗−α⋅sign(gt+1),(12)\mathbf{x}{t+1}^{*} = \mathbf{x}{t}^{*} - \alpha \cdot \mathrm{sign}(g_{t+1}), \quad (12)xt+1∗=xt∗−α⋅sign(gt+1),(12)
具有 L2L_{2}L2 范数约束的针对性 MI-FGM 为:
xt+1∗=xt∗−α⋅gt+1∥gt+1∥2.(13)\mathbf{x}{t+1}^{*} = \mathbf{x}{t}^{*} - \alpha \cdot \frac{g_{t+1}}{\|g_{t+1}\|_{2}}. \quad (13)xt+1∗=xt∗−α⋅∥gt+1∥2gt+1.(13)
因此,我们引入了一类广泛的用于各种攻击设置的动量迭代方法,其有效性将在第 4 节中展示。
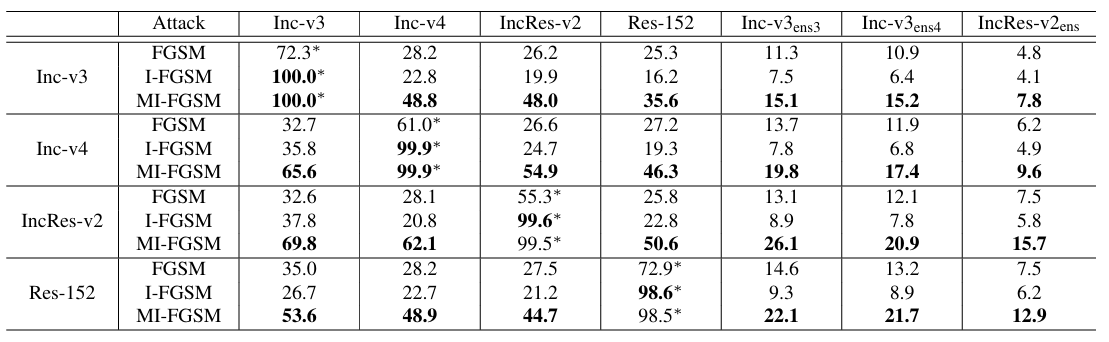
表 1 . 针对我们所研究的七个模型的非针对性对抗攻击成功率(%)。对抗样本分别针对 Inc-v3、Inc-v4、IncRes-v2 和 Res-152,使用 FGSM、I-FGSM 和 MI-FGSM 生成。∗ 表示白盒攻击。
4. 实验
在本节中,我们在 ImageNet 数据集 19 上进行大量实验,以验证所提出方法的有效性。我们首先在第 4.1 节中说明实验设置。然后我们在第 4.2 节中报告攻击单个模型的结果,在第 4.3 节中报告攻击模型集成的结果。我们的方法在第 4.4 节介绍的配置下,赢得了 NIPS 2017 非针对性对抗攻击和针对性对抗攻击竞赛的双料第一名。
4.1. 设置
我们研究了七个模型,其中四个是正常训练的模型------Inception v3 (Inc-v3) 22、Inception v4 (Inc-v4)、Inception Resnet v2 (IncRes-v2) 21、Resnet v2-152 (Res-152) 7;另外三个是通过集成对抗训练训练的------Inc-v3ens3、Inc-v3ens4、IncRes-v2ens 24。在不引起歧义的情况下,我们将后三个模型简称为"对抗训练模型"。
如果模型不能正确分类原始图像,研究攻击的成功率就没有意义。因此,我们从 ILSVRC 2012 验证集中随机选择了 1000 张图像,这些图像属于 1000 个类别,并且都被这些模型正确分类。
在我们的实验中,我们将我们的方法与单步梯度方法和迭代方法进行比较。由于基于优化的方法不能显式控制对抗样本与对应真实样本之间的距离,它们不能直接与我们的方法比较,但它们与迭代方法具有相似的属性,如第 2.1 节所述。为清晰起见,我们仅报告基于 L∞L_{\infty}L∞ 范数约束的非针对性攻击结果,并将基于 L2L_{2}L2 范数约束和针对性攻击的结果留在补充材料中。本文的发现对于不同的攻击设置是普遍的。
4.2. 攻击单个模型
我们在表 1 中报告了针对我们考虑的模型的攻击成功率。对抗样本分别针对 Inc-v3、Inc-v4、InvRes-v2 和 Res-152,使用 FGSM、迭代 FGSM (I-FGSM) 和 MI-FGSM 攻击方法生成。成功率是以对抗图像作为输入时相应模型的错误分类率。所有实验中最大扰动 ϵ\epsilonϵ 设为 16,像素值范围 0, 255。I-FGSM 和 MI-FGSM 的迭代次数为 10,衰减因子 μ=1.0\mu = 1.0μ=1.0,这将在第 4.2.1 节中研究。
从表中我们可以观察到,MI-FGSM 仍然是像 I-FGSM 一样强大的白盒攻击者,因为它能以接近 100%100\%100% 的成功率攻击白盒模型。另一方面,可以看出,对于黑盒攻击,I-FGSM 的成功率低于单步 FGSM。但是通过集成动量,我们的 MI-FGSM 在黑盒攻击中显著优于 FGSM 和 I-FGSM。在大多数黑盒攻击案例中,它获得的成功率是 I-FGSM 的两倍以上,证明了所提出算法的有效性。我们在图 1 中展示了两个为 Inc-v3 生成的对抗图像。
需要注意的是,尽管我们的方法大大提高了黑盒攻击的成功率,但以黑盒方式攻击对抗训练模型仍然无效(例如,对 IncRes-v2ens 的成功率低于 16%16\%16%)。稍后我们将在第 4.3 节中展示基于集成的方法大大改善了结果。接下来,我们研究 MI-FGSM 与普通迭代方法不同的几个方面,以进一步解释为什么它在实践中表现良好。
4.2.1 衰减因子 μ\muμ
衰减因子 μ\muμ 对于提高攻击成功率起着关键作用。如果 μ=0\mu = 0μ=0,基于动量的迭代方法退化为普通迭代方法。因此,我们研究衰减因子的适当值。我们使用 MI-FGSM 攻击 Inc-v3 模型,扰动 ϵ=16\epsilon = 16ϵ=16,迭代次数 10,衰减因子从 0.0 到 2.0 以 0.1 为粒度。我们展示了生成的对抗样本对 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 的成功率,如图 2 所示。针对黑盒模型的成功率曲线是单峰的,其最大值在 μ≈1.0\mu \approx 1.0μ≈1.0 附近取得。当 μ=1.0\mu = 1.0μ=1.0 时,公式 (6) 中定义的 gtg_{t}gt 的另一种解释是它简单地将所有先前的梯度相加来执行当前更新。
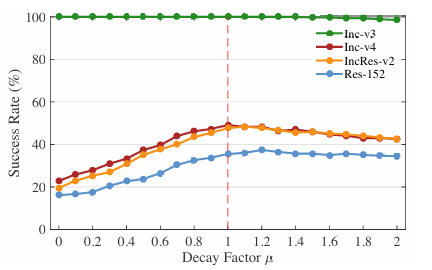
图 2 . 针对 Inc-v3 生成的对抗样本对 Inc-v3(白盒)、Inc-v4、IncRes-v2 和 Res-152(黑盒)的成功率 (%)(\%)(%),μ\muμ 的范围为 0.0 到 2.0。
4.2.2 迭代次数
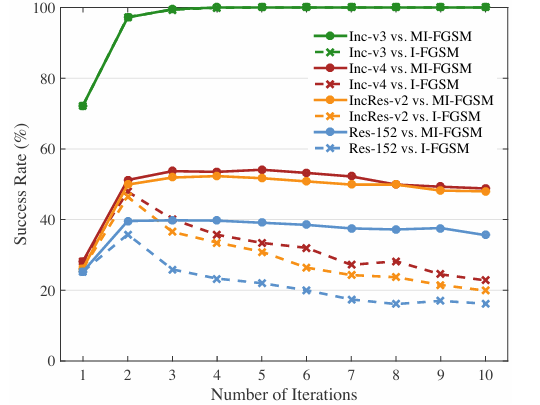
图 3 . 针对 Inc-v3 模型生成的对抗样本对 Inc-v3(白盒)、Inc-v4、IncRes-v2 和 Res-152(黑盒)的成功率 (%)(\%)(%)。我们比较了 I-FGSM 和 MI-FGSM 在不同迭代次数下的结果。请注意,Inc-v3 vs. MI-FGSM 和 Inc-v3 vs. I-FGSM 的曲线重叠在一起。
然后我们研究迭代次数对使用 I-FGSM 和 MI-FGSM 时成功率的影响。我们采用相同的超参数(即 ϵ=16\epsilon = 16ϵ=16,μ=1.0\mu = 1.0μ=1.0)攻击 Inc-v3 模型,迭代次数从 1 到 10,然后评估对抗样本对 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 模型的成功率,结果如图 3 所示。
可以观察到,当增加迭代次数时,I-FGSM 对黑盒模型的成功率逐渐降低,而 MI-FGSM 的成功率保持在高值。结果证明了我们的论点:迭代方法生成的对抗样本容易过拟合白盒模型,不太可能跨模型迁移。但基于动量的迭代方法有助于缓解白盒攻击与可迁移性之间的权衡,从而同时对白盒和黑盒模型展现出强大的攻击能力。
4.2.3 更新方向
为了解释为什么 MI-FGSM 表现出更好的可迁移性,我们进一步检查了 I-FGSM 和 MI-FGSM 在迭代过程中的更新方向。我们计算了两次连续扰动的余弦相似度,并在图 4 中展示了攻击 Inc-v3 时的结果。MI-FGSM 的更新方向比 I-FGSM 更稳定,因为 MI-FGSM 中的余弦相似度值更大。
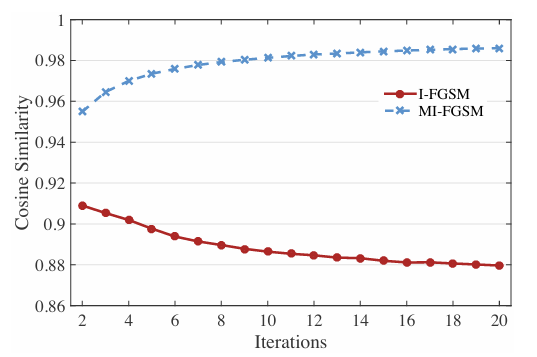
图 4. 攻击 Inc-v3 模型时,I-FGSM 和 MI-FGSM 中两次连续扰动的余弦相似度。结果在 1000 张图像上取平均。
回顾一下,可迁移性来自于模型在数据点附近学习到相似的决策边界 12。尽管决策边界相似,但由于 DNN 的高度非线性结构,它们不太可能完全相同。因此,在数据点附近可能存在一些模型特有的例外决策区域(如 12 中图 4 和 5 所示的"孔洞"),这些区域很难迁移到其他模型。这些区域对应于优化过程中的较差局部极大值,迭代方法容易陷入这些区域,导致可迁移性较差的对抗样本。另一方面,如图 4 观察到的,通过动量方法获得的稳定更新方向有助于逃离这些例外区域,从而为对抗攻击带来更好的可迁移性。另一种解释是,稳定的更新方向使得扰动的 L2L_{2}L2 范数更大,这可能有助于可迁移性。
4.2.4 扰动大小
我们最后研究对抗扰动大小对成功率的影响。我们使用 FGSM、I-FGSM 和 MI-FGSM 攻击 Inc-v3 模型,ϵ\epsilonϵ 范围从 1 到 40(图像强度 0,255),并评估在白盒模型 Inc-v3 和黑盒模型 Res-152 上的性能。在我们的实验中,我们将 I-FGSM 和 MI-FGSM 中的步长 α\alphaα 设为 1,因此迭代次数随扰动大小 ϵ\epsilonϵ 线性增长。结果如图 5 所示。
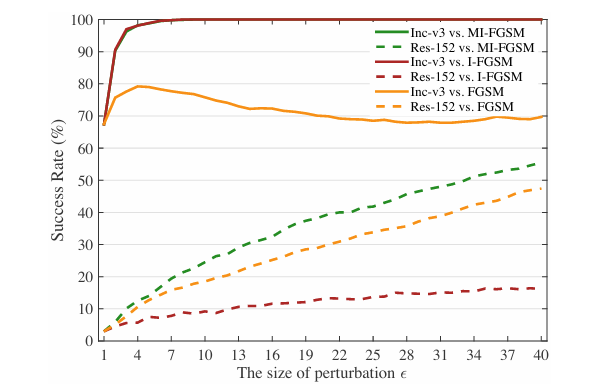
图 5 . 针对 Inc-v3 生成的对抗样本对 Inc-v3(白盒)和 Res-152(黑盒)的成功率 (%)(\%)(%)。我们比较了 FGSM、I-FGSM 和 MI-FGSM 在不同扰动大小下的结果。Inc-v3 vs. MI-FGSM 和 Inc-v3 vs. I-FGSM 的曲线重叠在一起。
对于白盒攻击,迭代方法很快达到 100%100\%100% 的成功率,但单步 FGSM 的成功率在扰动较大时下降。这种现象很大程度上归因于当扰动较大时决策边界线性性的不恰当假设 12。对于黑盒攻击,尽管这三种方法的成功率随扰动大小线性增长,但 MI-FGSM 的成功率增长更快。换句话说,为了以所需的成功率攻击黑盒模型,MI-FGSM 可以使用更小的扰动,这对人类来说更难以视觉区分。
4.3. 攻击模型集成
在本节中,我们展示攻击模型集成的实验结果。我们首先比较第 3.2 节中介绍的三种集成方法,然后证明对抗训练模型容易受到我们的黑盒攻击。
4.3.1 集成方法的比较
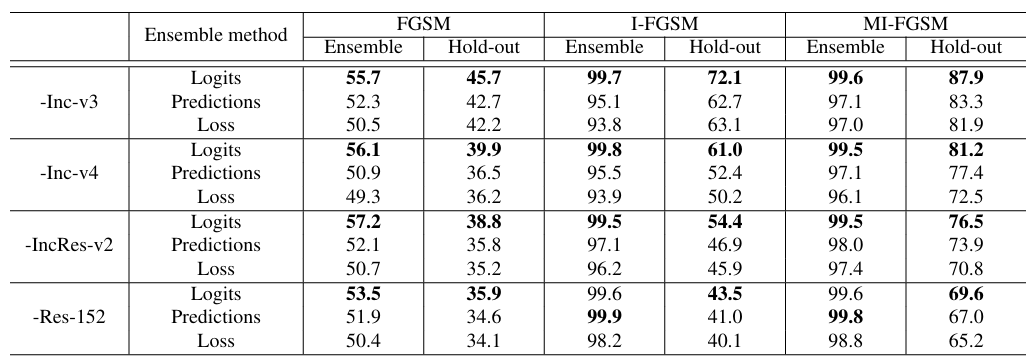
我们在此节比较用于攻击的集成方法。我们在研究中包括四个模型:Inc-v3、Inc-v4、IncRes-v2 和 Res-152。在我们的实验中,我们保留一个模型作为留出的黑盒模型,并分别使用 FGSM、I-FGSM 和 MI-FGSM 攻击其他三个模型的集成,以充分比较三种集成方法(即 logits 集成、预测集成和损失集成)的结果。我们设置 ϵ=16\epsilon = 16ϵ=16,I-FGSM 和 MI-FGSM 的迭代次数为 10,MI-FGSM 中的 μ=1.0\mu = 1.0μ=1.0,集成权重相等。结果如表 2 所示。
可以观察到,对于所有攻击方法和集成中的不同模型,无论是白盒还是黑盒攻击,logits 集成始终优于预测集成和损失集成。因此,logits 集成方案更适合对抗攻击。
从表 2 的另一个观察是,MI-FGSM 生成的对抗样本以高比率迁移,实现了强大的黑盒攻击。例如,通过攻击 Inc-v4、IncRes-v2 和 Res-152 的集成(在 logits 上融合,不包括 Inc-v3),生成的对抗样本可以以 87.9%87.9\%87.9% 的成功率欺骗 Inc-v3。正常训练的模型表现出对这种攻击的巨大脆弱性。
表 2 . 三种集成方法的非针对性对抗攻击成功率 (%)(\%)(%)。我们报告了白盒模型集成和留出的黑盒目标模型的结果。我们研究了四个模型:Inc-v3、Inc-v4、IncRes-v2 和 Res-152。在每一行中,"-"表示留出模型的名称,对抗样本是分别为其他三个模型的集成使用 FGSM、I-FGSM 和 MI-FGSM 生成的。Logits 集成始终优于其他方法。
4.3.2 攻击对抗训练模型
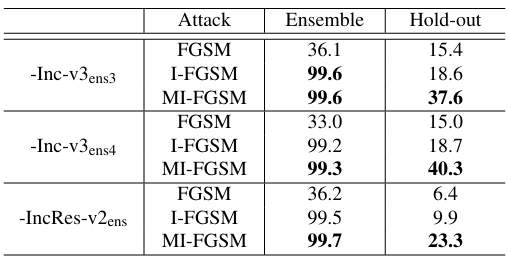
为了以黑盒方式攻击对抗训练模型,我们包括了第 4.1 节中介绍的所有七个模型。类似地,我们保留一个对抗训练模型作为留出的目标模型来评估黑盒方式的性能,并攻击其余六个模型的集成,其 logits 以相等的集成权重融合在一起。扰动 ϵ=16\epsilon = 16ϵ=16,衰减因子 μ=1.0\mu = 1.0μ=1.0。我们比较了 FGSM、I-FGSM 和 MI-FGSM 在 20 次迭代下的结果。结果如表 3 所示。
可以看出,对抗训练模型也无法有效防御我们的攻击,其中超过 40%40\%40% 的对抗样本可以欺骗 Inc-v3ens4。因此,通过集成对抗训练获得的模型(据我们所知,是在 ImageNet 上训练的最鲁棒的模型)容易受到我们的黑盒攻击,从而为开发鲁棒深度学习模型的算法带来了新的安全问题。
表 3 . 针对白盒模型集成和留出的黑盒目标模型的非针对性对抗攻击成功率 (%)(\%)(%)。我们包括七个模型:Inc-v3、Inc-v4、IncRes-v2、Res-152、Inc-v3ens3、Inc-v3ens4 和 IncRes-v2ens。在每一行中,"-"表示留出模型的名称,对抗样本是为其他六个模型的集成生成的。
4.4. 竞赛
NIPS 2017 对抗攻击与防御竞赛包含三个子竞赛:非针对性对抗攻击、针对性对抗攻击和对抗攻击防御。组织者提供了 5000 张与 ImageNet 兼容的图像,用于评估攻击和防御提交。对于每次攻击,为每张图像生成一个对抗样本,扰动大小范围为 4 到 16(由组织者指定),所有对抗样本通过所有防御提交以得到最终分数。我们凭借本文介绍的方法在非针对性攻击和针对性攻击中均获得第一名。我们将在下面说明提交中的配置。
对于非针对性攻击,我们实现了 MI-FGSM 来攻击一个集成,该集成包括 Inc-v3、Inc-v4、IncRes-v2、Res-152、Inc-v3ens3、Inc-v3ens4、IncRes-v2ens 和 Inc-v3adv 10。我们采用 logits 集成方案。前七个模型的集成权重均设为 1/7.251 / 7.251/7.25,Inc-v3adv 的权重设为 0.25/7.250.25 / 7.250.25/7.25。迭代次数为 10,衰减因子 μ=1.0\mu = 1.0μ=1.0。
对于针对性攻击,我们构建了两个攻击图。如果扰动大小小于 8,我们以 1/31/31/3 和 2/32/32/3 的集成权重攻击 Inc-v3 和 IncRes-v2ens;否则,我们攻击 Inc-v3、Inc-v3ens3、Inc-v3ens4、IncRes-v2ens 和 Inc-v3adv 的集成,集成权重分别为 4/11,1/11,1/11,4/114/11, 1/11, 1/11, 4/114/11,1/11,1/11,4/11 和 1/111/111/11。迭代次数分别为 40 和 20,衰减因子 μ=1.0\mu = 1.0μ=1.0。
5. 讨论
从不同的角度来看,我们认为寻找对抗样本类似于训练一个模型,而对抗样本的可迁移性也类似于模型的泛化能力。从元视角来看,我们实际上是在给定一组模型作为训练数据的情况下"训练"一个对抗样本。这样,通过动量和集成方法获得的改进的可迁移性是合理的,因为模型的泛化能力通常通过采用动量优化器或在更多数据上训练来提高。我们认为,其他用于增强模型泛化能力的技巧(例如 SGD)也可以被纳入对抗攻击中以获得更好的可迁移性。
6. 结论
在本文中,我们提出了一类广泛的基于动量的迭代方法来提升对抗攻击,这些方法可以有效地欺骗白盒模型以及黑盒模型。我们的方法在黑盒方式下始终优于单步梯度方法和普通迭代方法。我们进行了大量实验来验证所提出方法的有效性,并解释它们在实践中有效的原因。为了进一步提高生成对抗样本的可迁移性,我们提出攻击一个将 logits 融合在一起的模型集成。我们展示了通过集成对抗训练获得的模型容易受到我们的黑盒攻击,这为开发更鲁棒的深度学习模型提出了新的安全问题。
致谢
本工作得到国家自然科学基金(Nos. 61620106010, 61621136008, 61332007, 61571261, U1611461)、北京自然科学基金(No. L172037)、清华大学天津智能计算研究院、NVIDIA NVAIL 计划资助,并部分得到微软亚洲研究院和清华-英特尔联合研究机构的资助。
参考文献
1 N. Carlini and D. Wagner. Towards evaluating the robustness of neural networks. In IEEE Symposium on Security and Privacy , 2017.
2 R. Caruana, A. Niculescu-Mizil, G. Crew, and A. Ksikes. Ensemble selection from libraries of models. In ICML , 2004.
3 Y. Dong, H. Su, J. Zhu, and F. Bao. Towards interpretable deep neural networks by leveraging adversarial examples. arXiv preprint arXiv:1708.05493 , 2017.
4 W. Duch and J. Korczak. Optimization and global minimization methods suitable for neural networks. Neural computing surveys , 2:163--212, 1998.
5 I. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. In ICLR , 2015.
6 L. K. Hansen and P. Salamon. Neural network ensembles. IEEE transactions on pattern analysis and machine intelligence , 12(10):993--1001, 1990.
7 K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In ECCV , 2016.
8 A. Krogh and J. Vedelsby. Neural network ensembles, cross validation and active learning. In NIPS , 1994.
9 A. Kurakin, I. Goodfellow, and S. Bengio. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533 , 2016.
10 A. Kurakin, I. Goodfellow, and S. Bengio. Adversarial machine learning at scale. In ICLR , 2017.
11 Y. Li and Y. Gal. Dropout inference in bayesian neural networks with alpha-divergences. In ICML , 2017.
12 Y. Liu, X. Chen, C. Liu, and D. Song. Delving into transferable adversarial examples and black-box attacks. In ICLR , 2017.
13 J. H. Metzen, T. Genewein, V. Fischer, and B. Bischoff. On detecting adversarial perturbations. In ICLR , 2017.
14 S. M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard. Universal adversarial perturbations. In CVPR , 2017.
15 T. Pang, C. Du, and J. Zhu. Robust deep learning via reverse cross-entropy training and thresholding test. arXiv preprint arXiv:1706.00633 , 2017.
16 N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. B. Celik, and A. Swami. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security , 2017.
17 N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami. Distillation as a defense to adversarial perturbations against deep neural networks. In IEEE Symposium on Security and Privacy , 2016.
18 B. T. Polyak. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics , 4(5):1--17, 1964.
19 O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision , 115(3):211--252, 2015.
20 I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the importance of initialization and momentum in deep learning. In ICML , 2013.
21 C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In AAAI , 2017.
22 C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In CVPR , 2016.
23 C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks. In ICLR , 2014.
24 F. Tramèr, A. Kurakin, N. Papernot, D. Boneh, and P. McDaniel. Ensemble adversarial training: Attacks and defenses. In ICLR, 2018.