论文链接:Elucidating the Design Space of Diffusion-Based Generative Models(22'6)
扩散模型有很坚实的理论基础,但是模型、采样策略、训练策略、噪声参数化方法等等之间强耦合,且五花八门。作者的贡献在于
-
提出了一套对去噪分数匹配模型的统一框架EDM;
-
找到采样时最优性能的时间步离散方法,应用高阶Runge-Kutta方法,评估不同采样器;
-
为提升训练效果,对模型的输入、输出、损失函数进行预处理,调整训练期间的噪声水平分布,应用non-leaking数据增强。
首先在常见框架下表述一下diffusion model:
假设数据分布为,其标准差为
。通过往数据x中添加独立同分布的标准差为
的高斯噪声,获得分布族
,对于巨大的
,
几乎与纯高斯噪声无异。初始随机采样
,顺序去噪成
,这个过程中样本的噪声水平满足
,终点
便落在了数据分布中。
ODE公式
基于漂移系数f(t)和扩散系数g(t) 的原始叙事
Song et al.将扩散模型的前向随机微分方程定义为,
和
分别表示漂移和扩散系数,在方差保持VP和方差爆炸VE中设计存在差异,一般是
,前向SDE可写成
。
布朗运动在事件反向时会改变统计结构,反向SDE并不是将时间反向那么简单,为,其中分数函数
是一个指示当前噪声水平下数据概率密度更高的方向的矢量(概率密度对数的梯度)。
前向扰动核的一般形式为,其中信号缩放系数
,噪声强度
,对应边缘分布
,将能求解出相同p_t(x)的常微分方程称作概率流ODE:
,在前向和反向过程中就只有时间反向的差异了。在每轮迭代中,可以通过一个随机求解器去噪加噪,也可以用一个ODE求解器去噪,整个流程中唯一的随机来源于采样
。
基于信号缩放s(t)和噪声水平\sigma(t)的EMD叙事
这样的表述过程有个问题,PF ODE公式建立在本身没有多少实际意义的fg上,而对于训练模型、引导采样、理解ODE在实践中的具体意义至关重要的边缘分布却只能由这些公式间接推导。EDM换了一种表述,既然PF ODE是为了匹配特定集合的边缘分布,为什么不直接将边缘分布作为目标,基于和s(t)定义ODE?拆解边缘分布
表示两个概率密度函数之间的卷积操作,定义分布
,有边缘分布
,同样用
表示PF ODE
用和s(t)对f(t)和g(t)进行重写:
,
,点表示导数。回代可得
。PF ODE的不同实现都是对同一个正则ODE的重新参数化,噪声强度
和信号缩放系数s(t)分别对t和x进行转换。
分数匹配
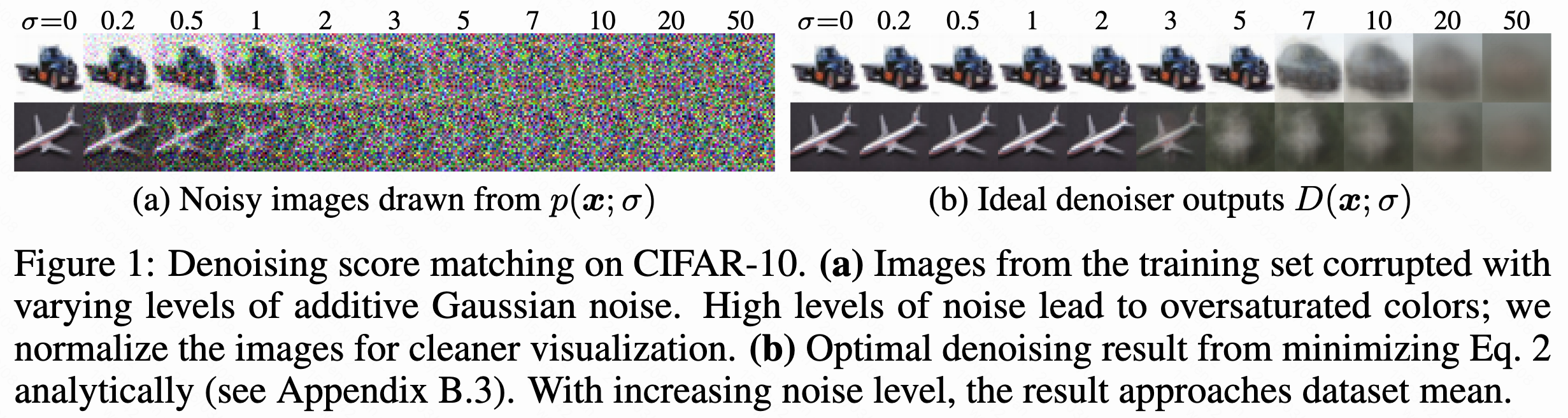
下图a是在不同噪声水平的分布中采样,即往干净数据中添加不同强度高斯噪声后得到的图片。高噪声可能导致过饱和,所以
假设训练集包含有限个样本,即
,于是
理想的去噪器,对原始样本y的最佳预测,能最小化在任何
下的L_2去噪期望误差
,把期望展开,改写成含噪声样本x的积分
说明可以通过独立最小化每个x的来最小化
,求解
是一个凸优化问题,根据导数为0得到
,对于小数据集,例如CIFAR-10,这个值是可计算的。下列图a对图片添加不同水平的高斯噪声,得到
(高噪声下算出的像素值范围广,多数会被裁剪到0或255,导致过饱和的颜色,为了可视化需归一化每张图像的像素范围),图b是计算出的最优去噪器输出,可以看到噪声越来越大时,最优去噪器从"恢复原图"会逐渐退化为"输出数据集平均图像"
考虑分数函数,其中高斯的导数
,于是
,
独立于,是一个不错的预测目标。实践中去噪器是一个根据"优化目标"训练出的神经网络
,其中
,代入PF ODE
ODE求解器
为了更多地优化细节,推理时对噪声水平采用幂律调度,取,代入边界条件
和
,得到
,以及
,其中N表示ODE求解器的迭代步数,
用来调节步长分布,为1时就是普通的线性插值,步长均匀,
越大,越多的
靠近
,实验选择
,
,
。对应地参数化时间步
。
之前的方案一般采用一阶Euler数值求解ODE,而EDM改为二阶Heun方法,能在局部误差和NFE(模型调用次数)之间取得更好的权衡,针对初值问题、
,每轮迭代:1. 计算当前点的斜率
;2. 用欧拉法预测下一点的临时值
;3. 用临时值计算下一点的斜率
;4. 两斜率取平均,算最终值
。假设步长h,一阶欧拉求解器引入的局部误差为
,Heun二阶方法多引入一次模型调用,将误差变成
。

EMD选择s(t)=1,\sigma(t)=t
ODE求解轨迹由和s(t)定义,为了减少截断误差(与曲率成比例),EDM选择
、s(t)=1,此时
和t等价,ODE方程可简化成
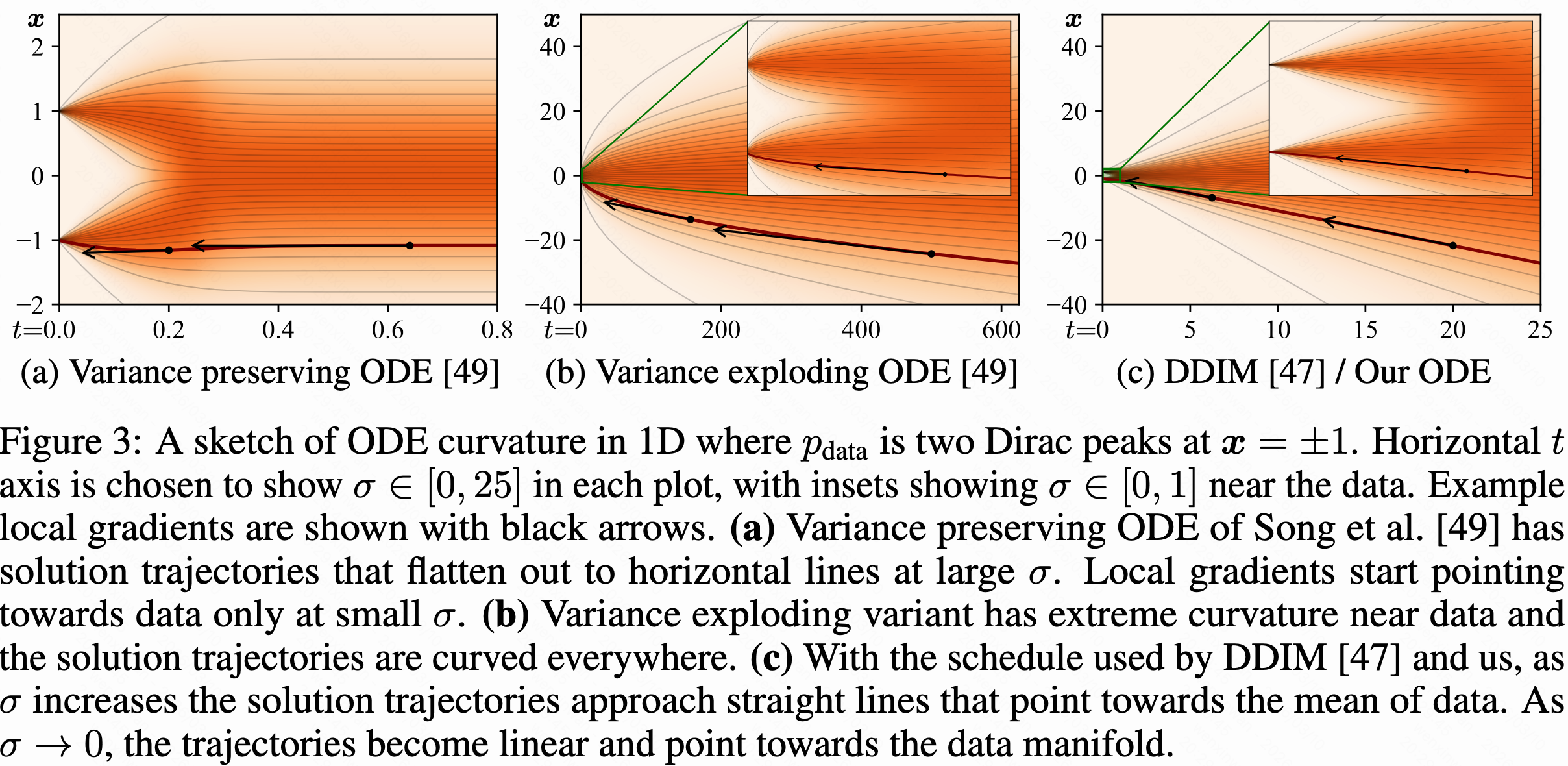
。这样的ODE更容易数值求解?下图中构造了一个一维的toy数据集
,数据只有两个点
,给数据加高斯噪声
,随着
增大,两个峰会逐渐变成一个高斯分布,表示为在同一t下橙色的深浅显示,橙色线表示生成过程中的流场,黑色箭头表示局部梯度。VP在大噪声区域轨迹几乎水平,在小噪声区域轨迹突然完全并指向
,因为分数
在小
才明显;VE的轨迹一直都很弯;而DDIM或者EDM在大
区域近似直线且指向数据均值(0),中
区域稍微弯曲,变小后又直了,指向数据(±1)。
引入随机性
相较于确定性采样,引入随机性会更好吗?结合Huen二阶确定性求解器、显式的Langevin式"扰动",每步去噪含两步:1. 按因子往样本中加噪,噪声强度升至
;2. 从
变到
,只需添加一个
,然后就是按Huen ODE求解器求解

加入随机性可以缓解前面引入的误差,但也可能导致细节丢失或者颜色过饱和,可能因为实践中去噪器存在误差,需要启发式方案进行修复,比如只在噪声水平区间加入随机项,定义
,由
控制整体随机性,同时通过裁剪保证不要高于原本的噪声水平。针对细节丢失问题,主要因为模型倾向于去掉稍稍偏多的噪声,输出靠近数据均值,这也是L2损失常导致的"均值回归"的现象,可通过设置略高于1的
缓解。消融实验:
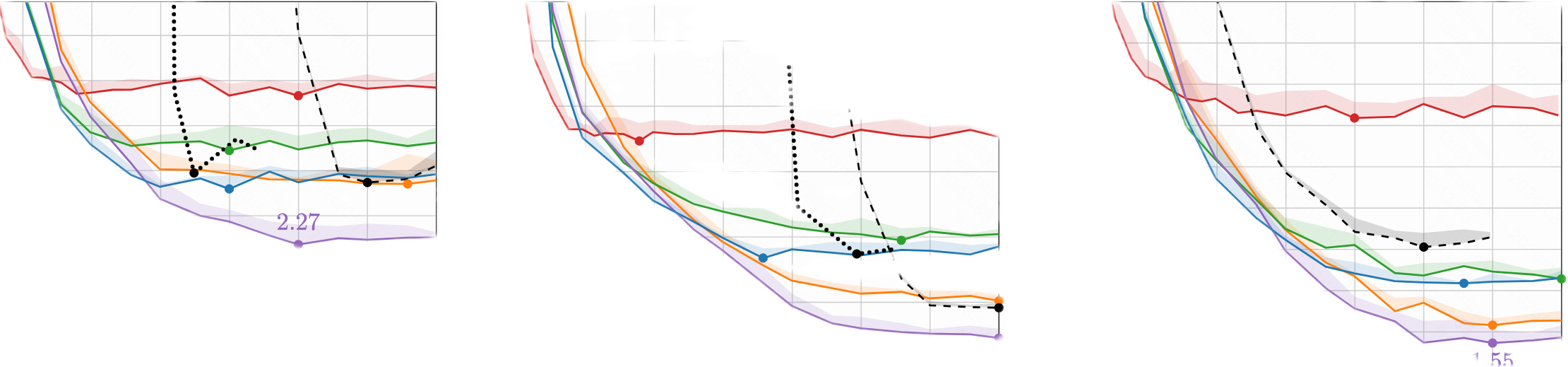
启发式设置的值最好根据模型定制,启用网格搜索逐个查找最优配置,能看出来,启用随机采样改进模型调用次数时可能会影响到模型架构和训练策略的选择。所以作者声明"We stress that this is not a general-purpose SDE solver, but a sampling procedure tailored for the specific problem."。
预条件化
通过监督训练网络时,最好把输入输出固定在相同方差,各式模型的性能差异可以归结于对输入输出不同的scaling,而原始样本的方差会随着
剧烈变化,之前的工作对输入除
,训练模型预测方差一致的噪声n,重建信号
,问题是模型的输出误差会被放大
倍,高噪声时直接预测信号
似乎更容易。EDM将去噪器统一成
,其中
直接保留输入,
表示网络预测残差,涵盖了模型预测n、y,或者介于两者之间的东西的所有情况。根据噪声水平调整总体损失
,其中
、
、
,替换回原始模型输出的表示:
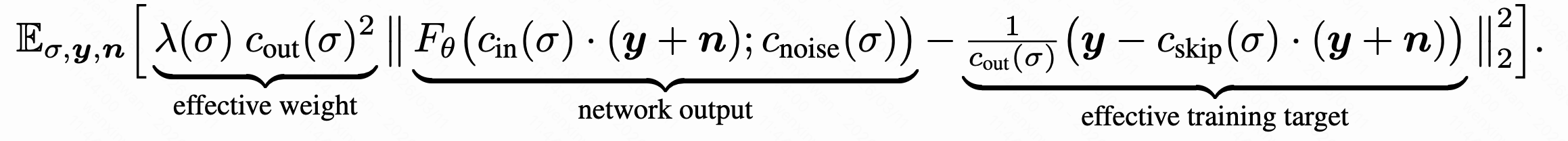
这样的格式便于探索对网络的有效训练:希望模型输入的方差保持,设置,得到
;同样,对于模型的目标输出
,于是
,为了减少对模型输出误差的放大作用,需要尽可能选择较小的
(恒非负),成优化问题
,求导数零解,即
,得到
,代入可得
;为了让不同噪声强度下梯度尺寸接近,有
。遵循之前的工作,设置输出层权重为0,初始时
,可以看到在任意
损失的期望都是1,固定
,有
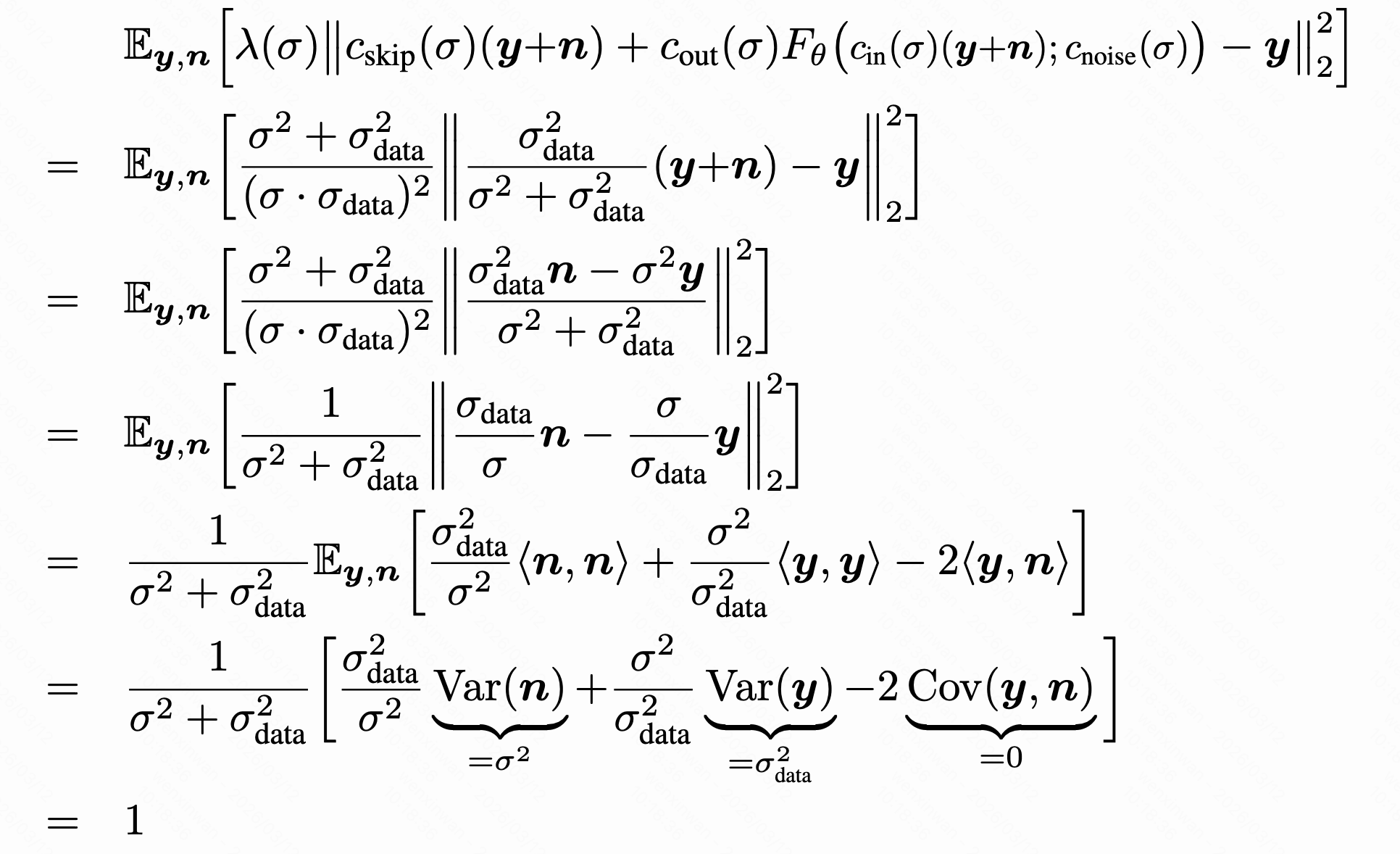
"输入网络的噪声条件变量"设置为,也是避免数值范围太大,经验选择log-scale。这些设置下训练更稳定,可以放心地关注损失的设计。实验中
。
训练时噪声分布
怎么选择,设计训练时的噪声水平?
看下面子图a,画了不同任务下loss随噪声强度的变化曲线,绿色表示训练开始时的loss,蓝色和橙色为训练完成时的,如果在某个下,训练前后loss下降很多,就说明模型学到很多,loss几乎不变则说明这个噪声水平很难学或者没价值,阴影区域表示随机采样1万个训练样本的标准差。EMD训练时采样
的概率分布为红色虚线,采用log-normal采样分布,让训练样本集中在中间区域,即
,设置
、
。
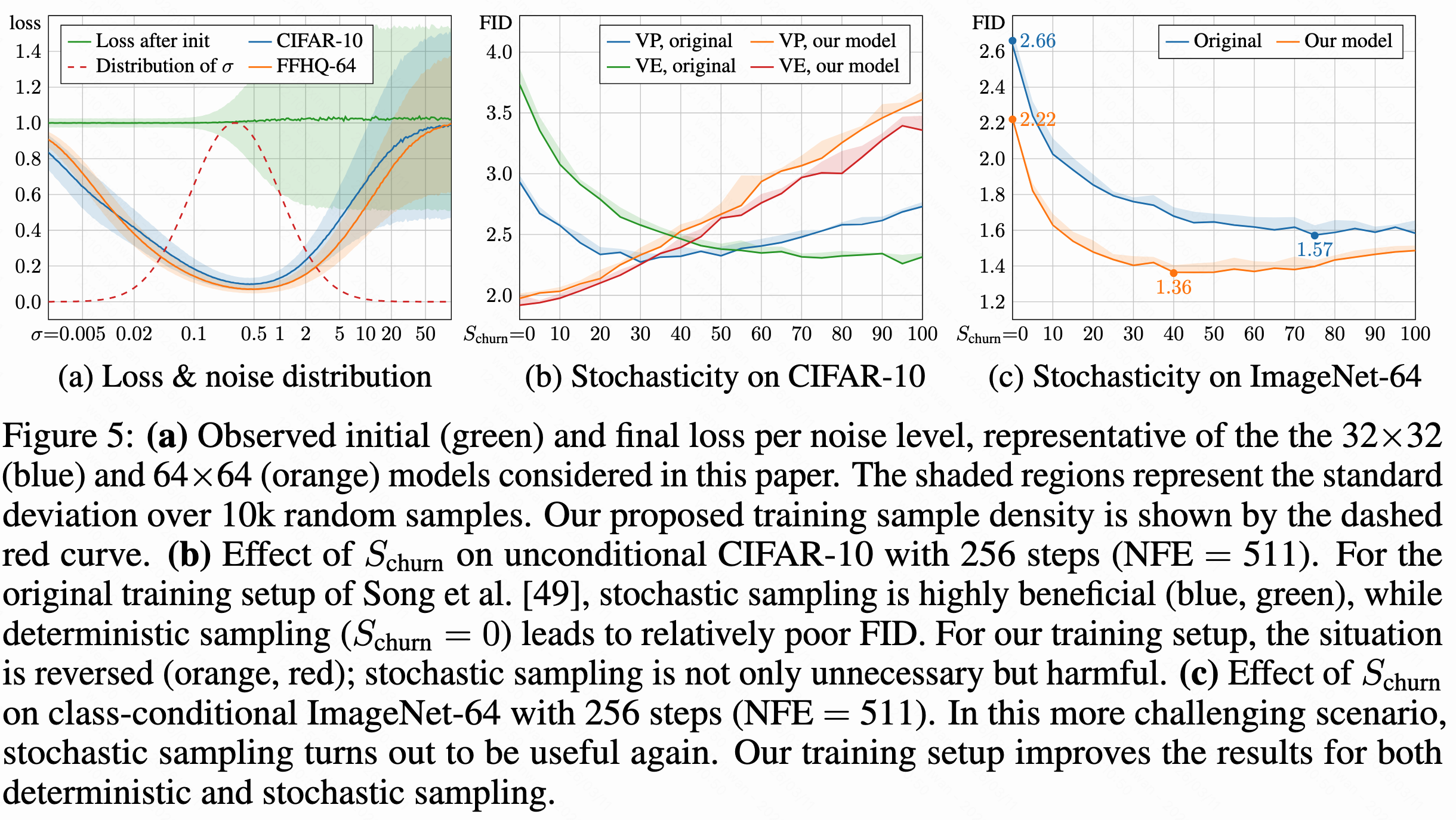
为了避免扩散模型在小数据集上发生过拟合,可以在训练时引入GAN系列论文中的数据增强技术,其中对训练集中的原始图片做了各式几何转换,同时为了避免增强泄露给模型,将增强系数作为条件输入,推理时设置为0不做增强,结果是数据增强能提升FID。随着模型改进,随机采样的相关性似乎在减弱,参考上图中的b(无条件CIFAR-10任务)、c(类条件ImageNet-64任务)子图。
统一框架下的不同参数化结果
先前工作的原始实现之间的差异可以总结为模型输入输出、图片数据的动态范围、对x的缩放、对的插值,在EMD架构下可以归纳为下列表格,
表示模型输出,图片数据用-1,1中的连续值表示,x和
始终满足
N表示在近似求解微分方程时的离散时间步数,但原始的模型权重可能不是在任意时间网格都训练过,假设训练时的时间步为

在Song et al.定义的VP版本中
在原始叙事中,设置、
,其中\
控制着噪声的增长速度,原始设置中被定义为一个线性调度
,还采用线性时间调度
。令
,定义积分
,可以推导出表格中的调度函数
,
,有
。
通过噪声网络近似分数函数,其中M=1000,
对应扰动核
的标准差
,替换成用原始样本
表示的形式
,代入s(t),用去噪器表示左边,有
,转换一下
,
,得到
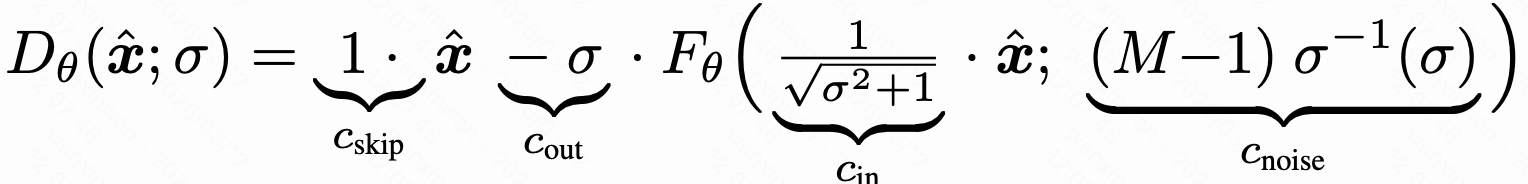
损失函数为,即
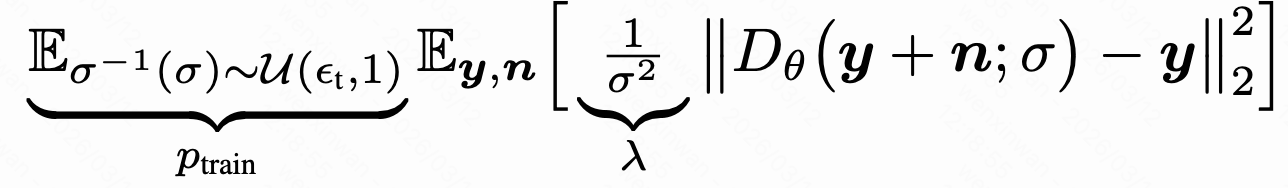
实验时采用CIFAR-10对应的"DDPM++ cont. (VP)"权重,含62M可训练参数,噪声强度范围,远宽于EDM偏好的范围0.002, 80,直接将该模型应用到算法1、2中。
原始实现中存在些疏忽。在欧拉求解器中dx/dt乘的是-1/N而非,最后一步从
到
,当
时
,这意味着比如当N=128时,生成的图片中会包含大量噪声,作者修复了这些错误,每步步长都从时间序列统一推导出来,且明确终点
。
在Song et al.定义的VE版本中
在原始叙事中,设置f(t)=0,,其中
,根据对应的SDE推导出与扰动核相匹配的
,
。
但实践时希望的是指数增长噪声,噪声水平呈log-uniform分布
,采用离散的噪声序列
,
,通过
近似求解PF ODE。稍微解释一下这个迭代式,在s(t)=1的情况下,
,再代入
,得
,欧拉离散化可得。
这和在EMD框架下,设置、s(t)=1、
,替换
时得到的ODE的Euler迭代公式一致(参考算法1):
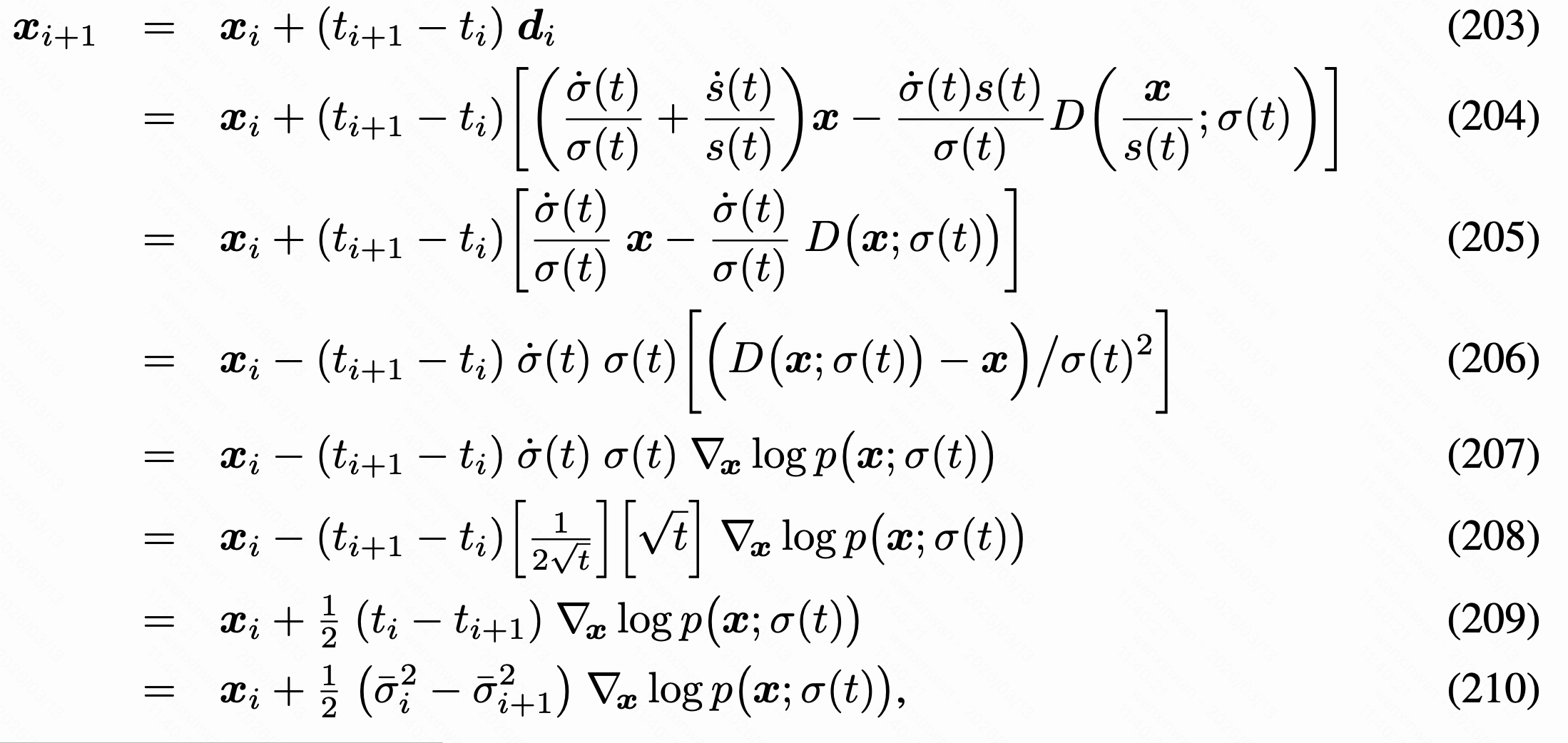
原始针对CIFAR-10的设置中、
,图片范围
,现在要调整成-1,1,这两就也得乘2。
原始通过下式近似分数函数,分数网络
已包含预处理和后处理步骤,由负噪声网络
得到,即
,其中2x-1取值范围在-1,1,
对跨越数量级的噪声水平取对数,都是更稳定的网络输入。
为了统一到EDM框架,希望用表示预/后处理过程,而不是直接集成到网络本身,考虑到图片表示范围的差异,需对
进行替换:
,
,
,得到
再用去噪器表示左边,得到,化解为

损失函数和VP一样为,代入指数增长噪声,有
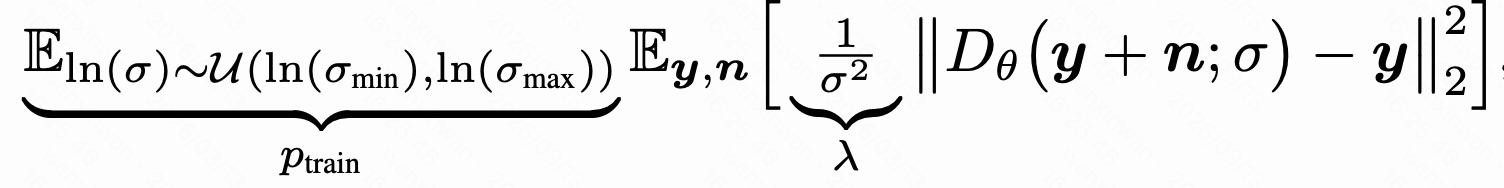
实验时采用CIFAR-10对应的"NCSN++ cont. (VE)"权重,含63M可训练参数,噪声强度范围,而EDM偏好的范围是0.002, 80,在重新实现时直接调整
的话,模型会遇到没见过的噪声强度,但EDM在重新设计了训练分布,将log-uniform的
改为log-normal,并调整了损失权重,还做了数据增强后,模型可以支持更小的\sigma了。再改用统一的条件处理框架,这样就能直接将该模型应用到算法1、2中了。另外将样本的精度从单精度调整成双精度,减少了高步数采样误差。
改进版DDPM和DDIM
Song et al.观察到确定性的DDIM采样器可以表示成的欧拉迭代过程,其中噪声网络的输入输出都是缩放过程的,也就是说对于x(t)=y(t)+n(t)而言,有
,代入预测原始数据的去噪器
,可以得到
。对于最理想的
和
,有
,同时设置
,上列ODE便可简化成
,和在EDM框架下设置s(t)=1、
得到的ODE一致。
原始DDPM的前向过程是一个逐步往数据中添加高斯噪声的马尔可夫链,根据离散的方差调度(如一个线性调度),有
,得到从
到
的转移概率为
,其中
;也可以先定义
(比如一个余弦调度),再推导
。
在改进版iDDPM中便定义,其中
,s=0.008,不过Nichol et al.在实现时省去了"除以f(0)"这点。同时为了避免靠近t=T 时出现奇异点(发生除零操作),原始实现中会对
做裁剪,改用
,对应地
现在,在EDM框架下重新介绍一遍推理。定义iDDPM的采样步为,
按噪声水平
降序排列,得对之前的式子替换
,
,设置常量
,
,有
,
,
。
为了能够匹配"扰动核",即,展开后为
。先替换
、
、
,得到
,通过定义
可以匹配两个分布的均值,即
,
然后是匹配方差,解得
,对等式左边进行替换,有
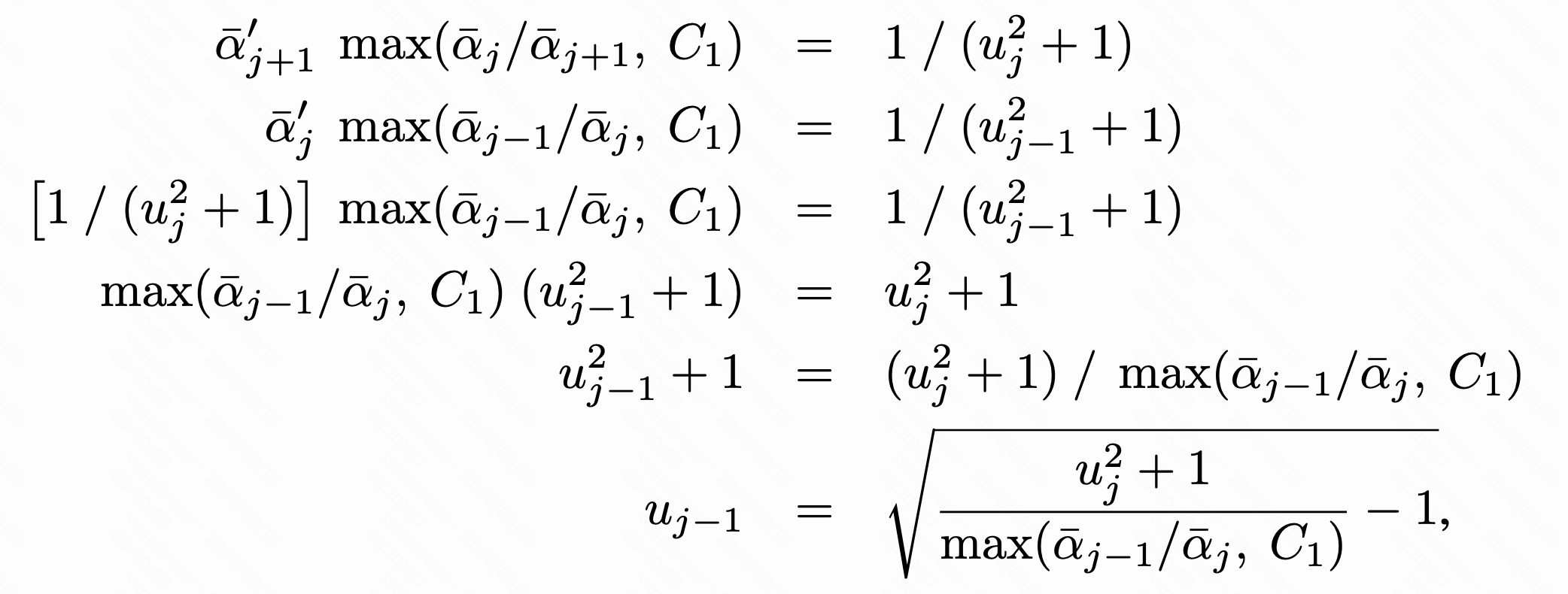
上式给出了的递推公式,边界满足
,这就是采样时"时间步"的设计。
之前说过,网络预测的是缩放后的噪声,在设置时有
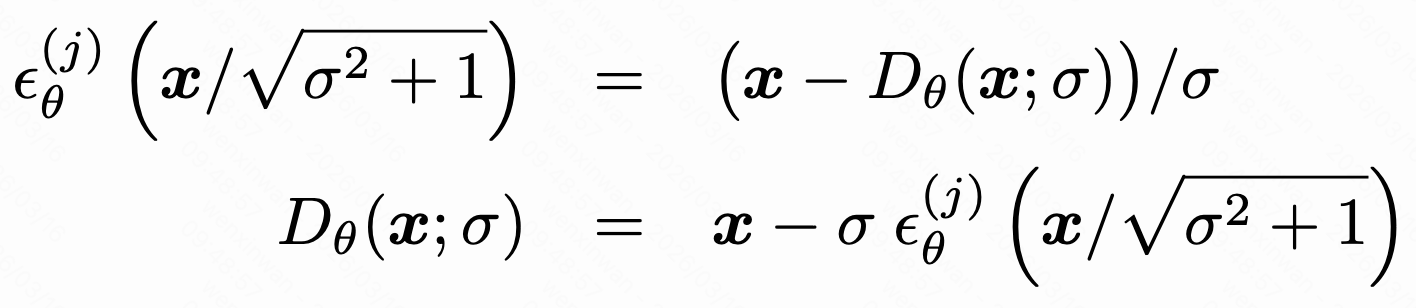
找到最靠近当前噪声水平的
,下标j作为输入网络的噪声条件,即

这和VP的预条件公式是一样的。
训练时,采用和VP同样的方案定义主损失(iDDPM中还有第二个损失项
)和噪声分布,从
中均匀抽取
,即
,
,设置
。
实验时采用ImageNet-64对应的"ADM (dropout)"权重,296M可训练参数,支持M=1000个离散噪声水平,所以在接入(假设训练时\sigma连续的)EDM统一采样框架时就存在一些问题:
-
EDM的采样算法通常使用N个时间步进行采样,实际上
,需要重新选择时间步。可以采用线性映射,同时前8个
-
EDM采样离散时间步时,需要将
-
随机采样(算法2)产生的中间时间步
于是便可以直接将原网络应用到算法1、2,请忽略网络预测的方差。
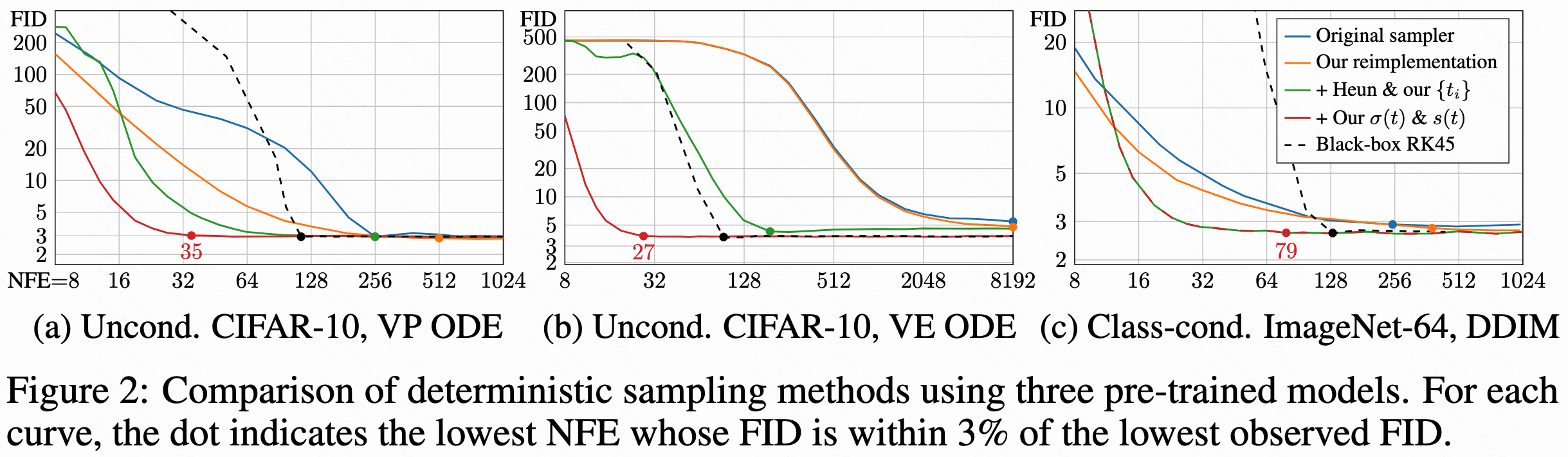
消融实验
下图中,蓝线表示采用原始配套的采样器,橙色表示作者处理了原始实现中一些疏忽后的结果。绿色是采用Heun求解器和EDM时间步,在所有样例中,能比欧拉方法在达到相同FID的情况下调用更少次模型。红色线表示使用EDM设定的和s(t)。还有黑色的虚线,在ODE的调度设计上用了很复杂的ODE求解器,得不偿失。