公共字段自动填充


自定义注解AutoFill
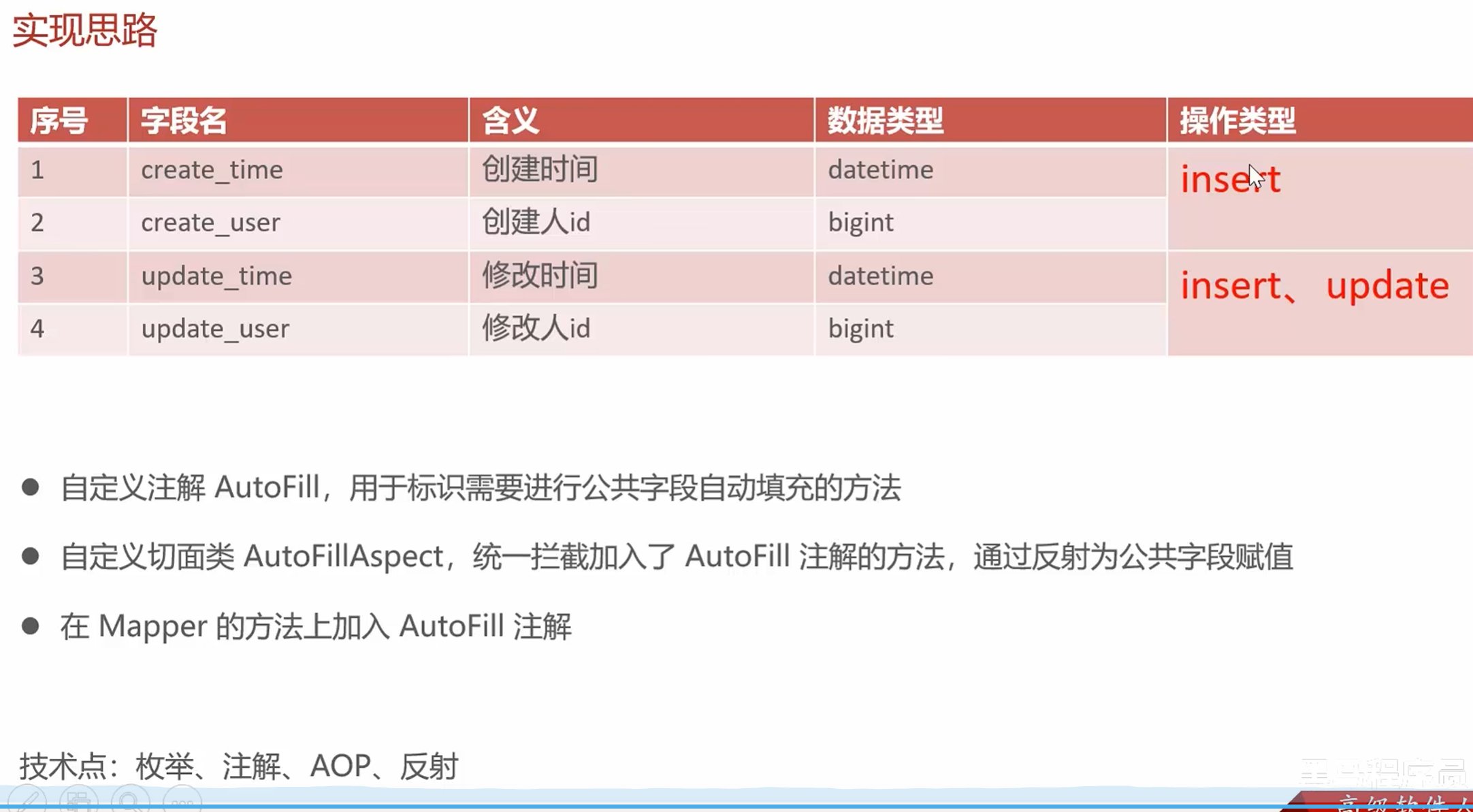
公共字段自动填充和反射有很大的关系
公共字段填充中自定义注解AutoFill ->反射在查找给某个方法进行公共字段填充的时候的标识

反射与注解
认识注解
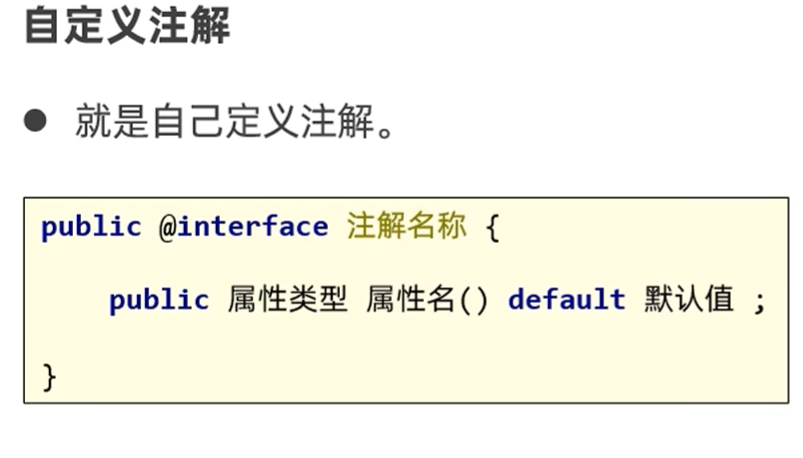
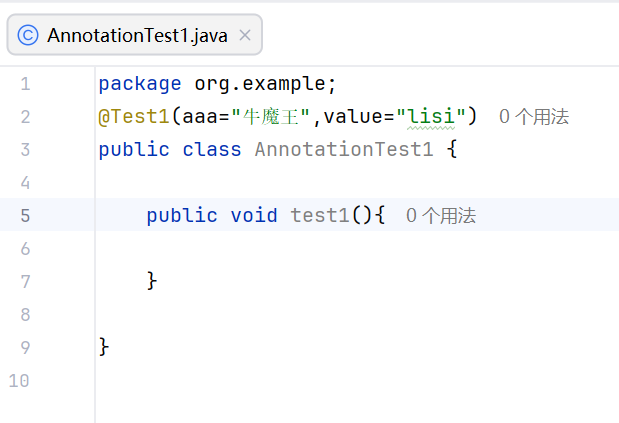
属性名后面要加()
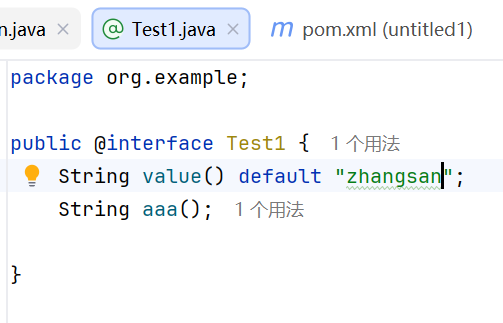
在使用的时候把注解写在方法上,括号内为属性名赋值
特殊情况
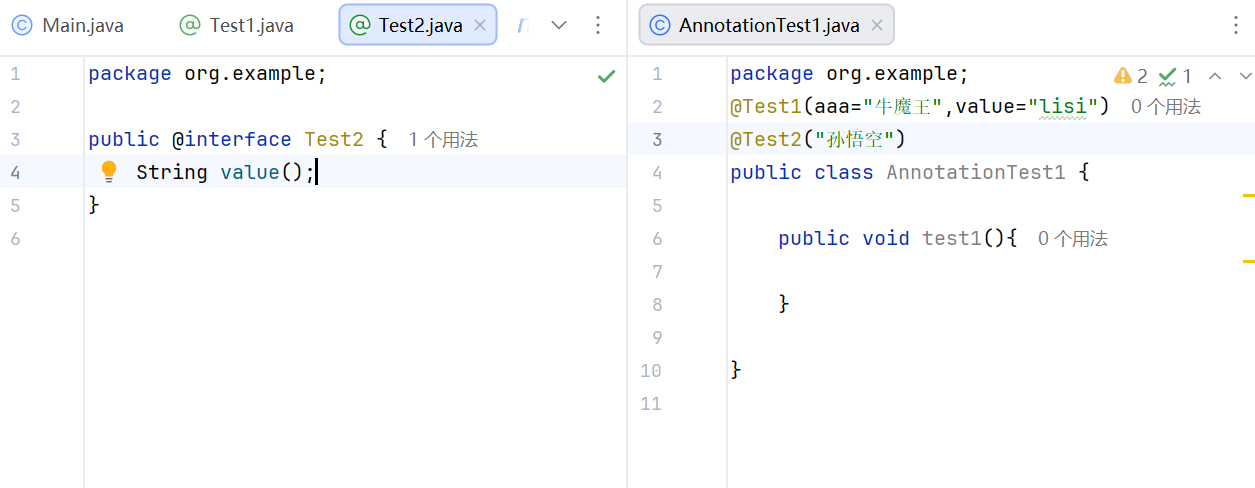
在注解只有一个属性value的时候,,在方法上面给value赋值的时候可以不写value=

注解的原理就是,注解本质上是一个接口,继承了Annotation方法,
在给注解中的属性赋值的时候实际上是在实现注解,给注解创造实现类对象(又因为继承的特殊性,实现了子类注解也就实现了Annotation注解)
元注解

Target注解,说明注解可以在哪里使用
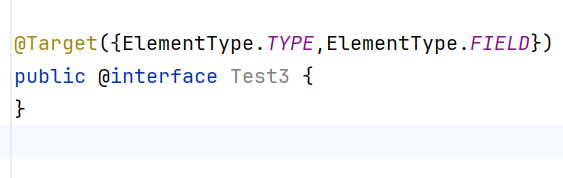
Retention注解,说明注解的保留周期

注解的解析


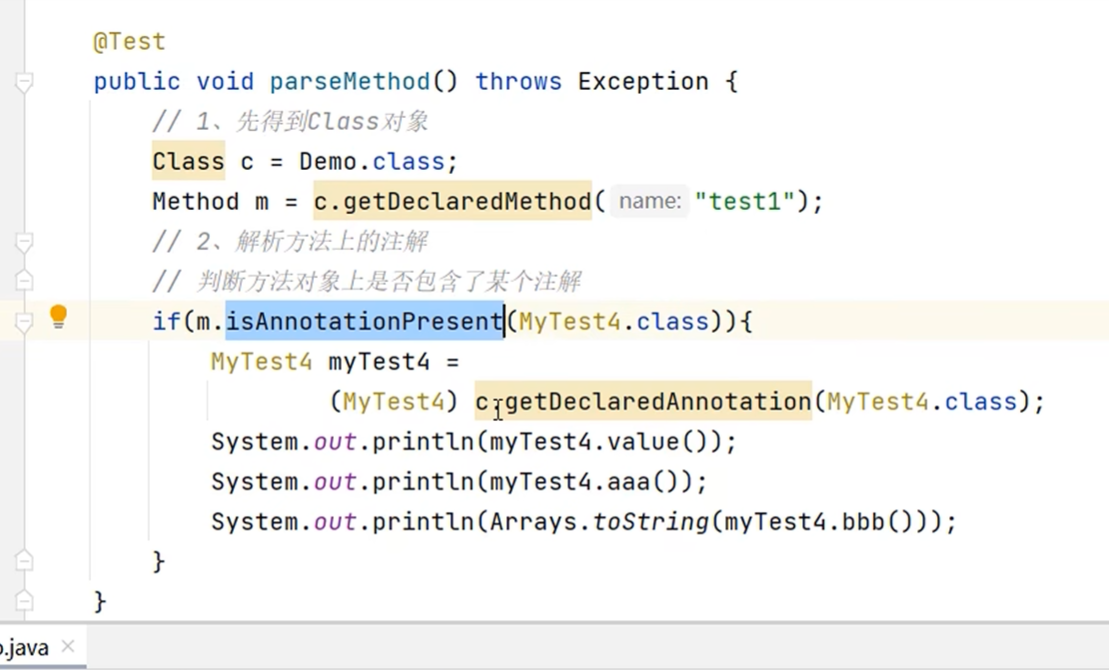
自定义切面
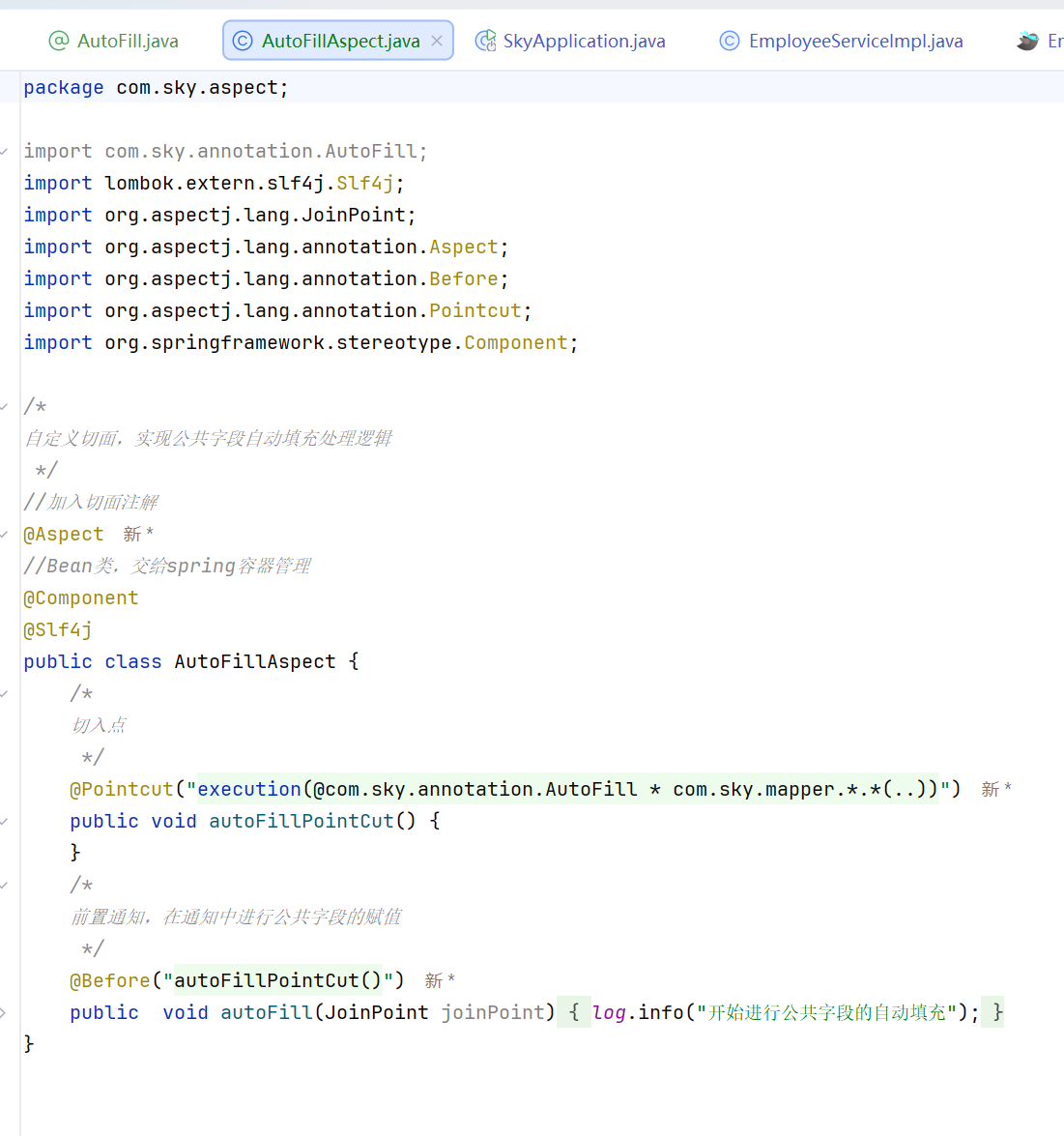
在执行update和insert方法的时候开启公共字段的自动填充

通过反射获取方法签名,从而获取签名中的对数据库的操作类型
通过反射获取方法:先获取类,再获取方法
通过反射获取的不同方法,对于不同的方法设置不同的数据
java
/*
自定义切面,实现公共字段自动填充处理逻辑
*/
//加入切面注解
@Aspect
//Bean类,交给spring容器管理
@Component
@Slf4j
public class AutoFillAspect {
/*
切入点
*/
@Pointcut("execution(@com.sky.annotation.AutoFill * com.sky.mapper.*.*(..))")
public void autoFillPointCut() {
}
/*
前置通知,在通知中进行公共字段的赋值
*/
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint) {
log.info("开始进行公共字段的自动填充");
//获取到当前被拦截的方法上的数据库的操作类型
//1.获取方法签名对象
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
//2.获取方法上的注解对象
AutoFill autoFill = signature.getMethod().getAnnotation(AutoFill.class);
//3.获取数据库的操作类型
OperationType operationType = autoFill.value();
//获取到当前被拦截的方法的参数--实体对象
//做出一个约定,把实体对象放在参数的第一个
Object[] args = joinPoint.getArgs();
if(args == null && args.length == 0){
return;
}
Object entity =args[0];
//准备赋值的数据
LocalDateTime now = LocalDateTime.now();
Long currentId = BaseContext.getCurrentId();
//根据当前不同的操作类型,为参数的不同属性通过反射赋值
if(operationType.equals(OperationType.INSERT)){
//为四个公共字段赋值
try {
Method setCreateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_TIME, LocalDateTime.class);
Method setCreateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_USER, Long.class);
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象属性赋值
setCreateTime.invoke(entity,now);
setCreateUser.invoke(entity,currentId);
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
} catch (Exception e) {
throw new RuntimeException(e);
}
}else if(operationType.equals(OperationType.UPDATE)){
try {
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象属性赋值
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}查询回显-一对多多表查询
---两张表分开查询
Service 层(核心:分开两次查询)
java
@Service
public class CategoryServiceImpl implements CategoryService {
@Autowired
private CategoryMapper categoryMapper;
@Autowired
private SetmealMapper setmealMapper; // 注入套餐Mapper
/**
* 分开查询:分类 + 套餐(一对多)
*/
@Override
public CategoryVO getCategoryWithSetmeal(Long categoryId) {
// 第一次查询:查 主表(一的一方)
Category category = categoryMapper.getById(categoryId);
// 第二次查询:查 从表(多的一方)
// 根据分类ID查所有套餐
List<Setmeal> setmealList = setmealMapper.getByCategoryId(categoryId);
// 手动封装成 VO
CategoryVO vo = new CategoryVO();
BeanUtils.copyProperties(category, vo);
vo.setSetmealList(setmealList);
return vo;
}
}---另一种方法
XML 核心:一对多查询(最关键)
XML
<resultMap id="CategoryWithSetmealMap" type="com.sky.vo.CategoryVO">
<!-- 一的一方:分类 -->
<id column="c_id" property="id"/>
<result column="c_name" property="name"/>
<!-- 多的一方:套餐(一对多核心) -->
<collection
property="setmealList"
ofType="com.sky.entity.Setmeal"
>
<id column="s_id" property="id"/>
<result column="s_name" property="name"/>
<result column="s_price" property="price"/>
</collection>
</resultMap>
<!-- 一对多关联查询 SQL -->
<select id="getCategoryWithSetmeal" resultMap="CategoryWithSetmealMap">
SELECT
c.id AS c_id,
c.name AS c_name,
s.id AS s_id,
s.name AS s_name,
s.price AS s_price
FROM category c
LEFT JOIN setmeal s ON c.id = s.category_id
WHERE c.id = #{categoryId}
</select>表套表--修改的复杂情况
口味可能被是被删掉了也可能是被修改了,不好说调用哪个接口,所以采用先删除后上传的方法
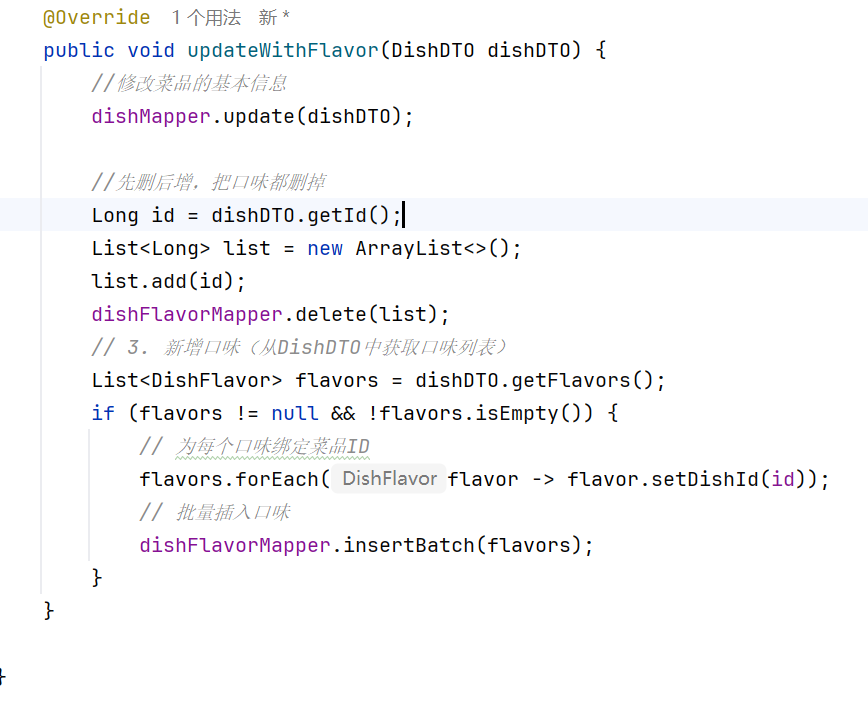
在新增菜品的时候,如果还要新增口味,就只能在菜品添加完毕并返回主键ID之后才能添加口味
XML
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into dish(name, category_id, price, image, description,
create_time, update_time, create_user, update_user, status)
values
(#{name},#{categoryId},#{price},#{image},#{description},
#{createTime},#{updateTime},#{createUser},#{updateUser},#{status})
</insert>
java
@Transactional
@Override
public void saveWithFlavor(DishDTO dishdto) {
Dish dish = new Dish();
BeanUtils.copyProperties(dishdto,dish);
//向菜品表插入1条数据
dishMapper.insert(dish);
//获取insert语句生成的主键值
Long dishId=dish.getId();
//向口味表插入n条数据,支持批量插入
List<DishFlavor> flavors = dishdto.getFlavors();
if(flavors!=null && !flavors.isEmpty()){
for(DishFlavor flavor:flavors){
flavor.setDishId(dishId);
}
dishFlavorMapper.insertBatch(flavors);
}
}接口参数规则解析
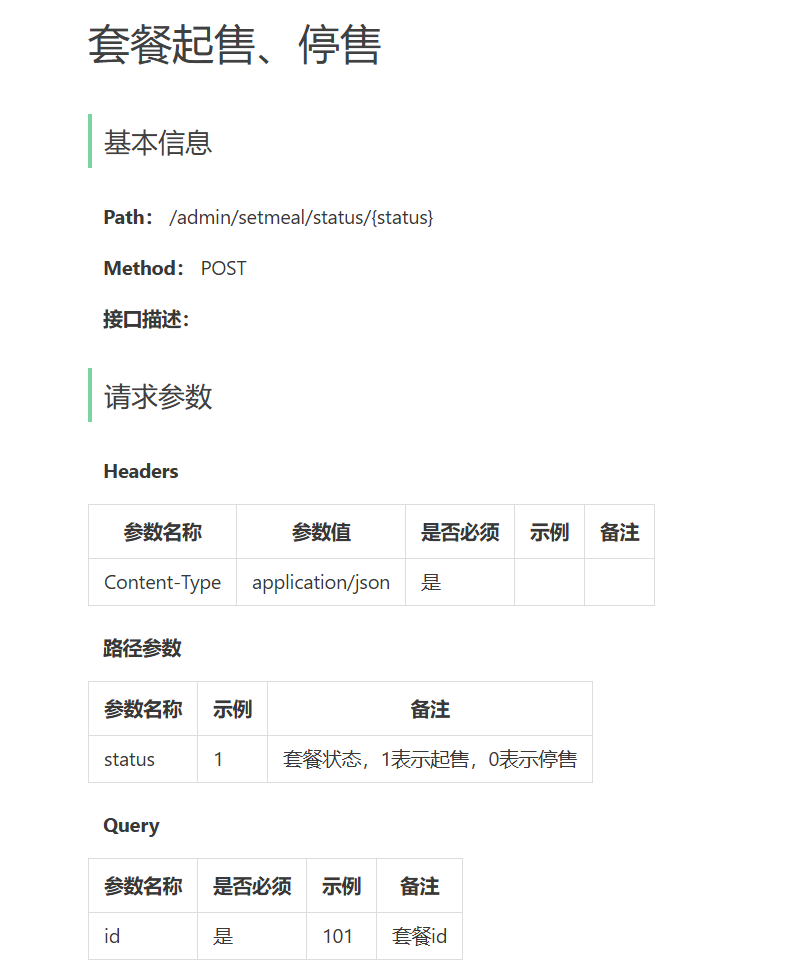
这张表是一个 **【修改套餐状态】** 的接口文档,我帮你把参数的含义、位置、以及前后端怎么对接彻底讲清楚。
一、接口核心信息
-
请求方式:PUT / POST(通常是修改状态)
-
请求格式 :JSON(Body 体)
-
路径参数 :
status(在 URL 路径中) -
Query 参数 :
id(在 URL 问号后)
二、参数位置与规则(3 个参数全覆盖)
- Header(请求头)
| 参数名 | 值 | 说明 |
|---|---|---|
| Content-Type | application/json | **必须填!**表示我发送的是 JSON 格式数据,缺了这个后端解析不到数据。 |
- 路径参数(Path Param)
| 参数名 | 示例 | 备注 |
|---|---|---|
| status | 1 | 套餐状态 1 = 起售(打开售卖)0 = 停售(禁止售卖)这个参数拼在 URL 路径里。 |
- Query 参数(Query Param)
| 参数名 | 是否必须 | 示例 | 备注 |
|---|---|---|---|
| id | 是 | 101 | 套餐 ID 要修改的那个套餐的 ID(比如 101 号套餐)这个参数拼在 URL ? 后面。 |
三、正确的请求 URL(拼接规则)
根据接口文档,请求的 URL 要这样写:
/api/setmeal/[status]?id=[套餐id]实际例子(修改 101 号套餐为起售)
PUT http://localhost:8080/api/setmeal/1?id=101-
/1:路径参数status=1(表示起售) -
?id=101:Query 参数id=101(表示修改 ID 为 101 的套餐)
四、后端代码怎么接?(Java 解析)
因为参数在 路径 和 Query 两个地方,后端 Controller 要分开接收。
-
Controller 写法(核心)
@PutMapping("/setmeal/{status}") // 这里捕获路径参数 status
@ApiOperation("修改套餐状态")
public ResultupdateStatus(
// 👇 接收路径参数
@PathVariable Integer status,// 👇 接收 Query 参数 @RequestParam Long id) {
log.info("修改套餐状态:id={}, status={}", id, status);// 调用 Service 处理逻辑 setmealService.updateStatus(id, status); return Result.success("修改成功");}
-
DTO / 实体类(不需要写 DTO)
因为参数很少,直接用 @RequestParam 和 @PathVariable 接,不用写 SetmealDTO(如果是复杂的新增 / 修改才用 DTO)。
五、前端请求代码(Vue 示例)
前端必须按照这个规则发送请求,URL 格式不能错。
// 1. 定义参数
const status = 1; // 起售
const id = 101; // 套餐ID
// 2. 发送请求
// 注意:URL 要拼接 /status?id=xxx
await axios.put(`/api/setmeal/${status}?id=${id}`);六、特别注意(避坑指南)
-
Content-Type必须是application/json-
虽然这个接口传的参数很少(只有 id),但因为是 PUT 请求,后端通常要求接收 JSON 体。
-
如果后端报错
Required request body is missing,说明你没加这个 Header,或者没传 JSON 体。
-
-
参数位置不要搞混
-
status:写在路径里/1 -
id:写在查询参数里?id=101 -
不要把
id写到路径里,严格按照文档来。
-
Path 参数 vs Query 参数
我用最通俗的方式,把本质区别、使用场景、前后端写法一次性讲透,帮你彻底分清。
一、本质区别(一句话总结)
| 维度 | Path 参数(路径参数) | Query 参数(查询参数) |
|---|---|---|
| 位置 | URL 路径中 (/xxx/{id}) |
URL ? 后面 (?id=xxx&name=xxx) |
| 作用 | 标识资源本身(比如「哪个套餐」「哪个用户」) | 对资源做筛选、分页、条件、附加操作 |
| 是否必须 | 通常是必填(缺了就找不到资源) | 通常是可选(不传用默认值) |
| 格式 | 直接嵌入路径,无key=,只有值 |
key=value 键值对,多参数用&分隔 |
| 缓存友好性 | 路径变了 = 资源变了,适合做缓存 | 同一资源不同参数,缓存需特殊处理 |
二、直观对比(用你刚才的套餐接口举例)
- 路径参数(Path Param)
URL 示例 :/admin/setmeal/1
-
含义:
1是路径参数,代表「状态 = 1(起售)」,直接嵌在 URL 路径里 -
特点:是 URL 的一部分,缺了这个路径就不存在(404)
-
适用场景:资源的状态、类型、分类 (比如
/setmeal/{status}、/user/{id})
- 查询参数(Query Param)
URL 示例 :/admin/setmeal/1?id=101
-
含义:
id=101是查询参数 ,在?后面,是对路径资源的附加条件 -
特点:不是 URL 的核心路径,不传也能访问(后端做默认值处理)
-
适用场景:分页、筛选、排序、附加参数 (比如
?page=1&pageSize=10、?status=1)
三、核心使用场景(怎么选?)
✅ 什么时候用 Path 参数?
-
标识唯一资源 :
/user/{userId}、/order/{orderId}(必须传,否则找不到资源) -
资源的分类 / 状态 :
/setmeal/{status}、/category/{type}(状态是资源的属性,嵌在路径里) -
RESTful 风格接口:符合「URL 代表资源,HTTP 方法代表操作」的设计规范
✅ 什么时候用 Query 参数?
-
分页查询 :
/setmeal/page?page=1&pageSize=10 -
条件筛选 :
/setmeal?categoryId=13&status=1 -
排序 / 搜索 :
/setmeal?name=套餐&sort=createTime -
可选附加参数:非必须,不传不影响核心资源访问
四、后端代码写法(SpringBoot 对比)
-
Path 参数(
@PathVariable)// 路径参数:{status} 嵌在URL里
@PutMapping("/setmeal/{status}")
public Result updateStatus(
@PathVariable Integer status, // 绑定路径中的{status}
@RequestParam Long id // 绑定?后面的id
) {
// 逻辑...
}
-
必须用
@PathVariable注解,参数名要和路径占位符{status}完全一致 -
路径参数是 URL 的一部分,缺了会 404
-
Query 参数(
@RequestParam/ 自动绑定)// Query参数:?id=xxx&name=xxx
@GetMapping("/setmeal/page")
public Result page(SetmealPageQueryDTO dto) {
// 自动绑定?后面的参数到DTO
}
// 或者单独接收
@GetMapping("/setmeal")
public Result list(
@RequestParam(required = false) String name,
@RequestParam(defaultValue = "1") Integer page
) {
// 逻辑...
}
-
用
@RequestParam(或直接用 DTO)接收,支持required=false(可选)、defaultValue(默认值) -
多参数用
&分隔,顺序不影响
五、前端请求写法(Axios 对比)
-
Path 参数
// 路径参数:直接拼在URL里
const status = 1;
const id = 101;
axios.put(/admin/setmeal/${status}?id=${id}); -
Query 参数
// Query参数:用params对象自动拼接
axios.get("/admin/setmeal/page", {
params: {
page: 1,
pageSize: 10,
categoryId: 13,
status: 1
}
});
// 自动生成URL:/admin/setmeal/page?page=1&pageSize=10&categoryId=13&status=1
六、关键避坑指南
- 不要搞混参数位置
-
路径参数是URL 的一部分 ,不能用
?包裹 -
Query 参数必须在
?后面,多参数用&分隔 -
错误示例:
/setmeal?status=1?id=101(?只能有一个,后面全是 Query 参数)
- Path 参数的 RESTful 规范
-
路径参数尽量用单数 :
/user/{userId},不要/users/{userId} -
不要把多个参数都塞路径里:
/setmeal/{id}/{status}不如/setmeal/{id}?status={status}清晰
- Query 参数的空值处理
-
Query 参数支持
required=false,不传时后端用默认值 -
路径参数通常是必填,不传会 404,适合做强校验
七、一句话总结(面试 / 工作都能用)
Path 参数是「资源的身份证」,用来定位唯一资源;Query 参数是「资源的筛选条件」,用来对资源做附加操作。 遵循 RESTful 风格:URL 定位资源,Query 描述操作。
pagehelper的细节
PageHelper 原理
一、PageHelper 到底是什么?
它是一个 MyBatis 拦截器(Interceptor) 作用:自动帮你拼接分页 SQL 不用你自己写 LIMIT ?,?
二、核心原理(一句话)
PageHelper 在执行你的查询 SQL 之前偷偷拦截, 自动帮你改成 分页 SQL,然后再执行。
三、它的工作流程(4 步走)
-
你写:
PageHelper.startPage(1, 10);
作用:把 page=1、pageSize=10 存到当前线程里(ThreadLocal)
-
你执行查询:
List
list = mapper.page(dto);
- PageHelper 拦截器工作:
-
拦截你的 SQL
-
从 ThreadLocal 取出
page=1, pageSize=10 -
*自动计算:offset = (1-1)10 = 0
-
把你的 SQL 改成分页 SQL:
SELECT * FROM table LIMIT 0,10
- 返回分页结果 Page/PageInfo
-
总条数
-
当前页数据
-
总页数
四、为什么你之前 page 不生效,只有 pageSize 生效?
因为你违反了 PageHelper 最核心的规则:
🚨 规则 1:
必须紧跟在查询方法前面!中间不能有任何代码!
java
运行
// 正确
PageHelper.startPage(1,10);
List list = mapper.select();
// 错误!!!分页失效
PageHelper.startPage(1,10);
其他代码();
List list = mapper.select();🚨 规则 2:
查询方法必须返回 List 类型!
你之前写:
xml
resultType="PageResult"→ 返回的不是 List→ PageHelper 无法拦截→ 只能拼出
sql
LIMIT 10→ page 失效
🚨 规则 3:
page 不能是 0 或 null
java
运行
PageHelper.startPage(0,10);→ 生成 SQL
sql
LIMIT 10→ 只有 pageSize 生效
五、PageHelper 最关键的 3 个知识点
-
基于 ThreadLocal 存储分页参数
-
基于 MyBatis 拦截器 改写 SQL
-
只对 紧跟的第一条查询 生效
六、你之前的错误总结
-
XML 返回类型错误(返回 PageResult 而不是 VO)
-
PageHelper 无法拦截
-
生成错误 SQL:LIMIT 10
-
page 不生效,只有 pageSize 生效
七、正确写法(最终版)
java
运行
// 1. 开启分页
PageHelper.startPage(pageNum, pageSize);
// 2. 立刻查询(必须紧跟)
List<SetmealVO> list = setmealMapper.page(dto);
// 3. 封装分页
PageInfo<SetmealVO> pageInfo = new PageInfo<>(list);
return new PageResult(pageInfo.getTotal(), pageInfo.getList());
<select id="page" resultType="SetmealVO">
...
</select>PageHelper = 自动帮你拼 LIMIT 的拦截器 必须紧跟查询、必须返回 List、page 不能为 0
PageHelper 原理(极简版)
-
PageHelper.startPage(page, pageSize)把分页参数存到当前线程的 ThreadLocal 里。 -
执行查询 紧接着的第一条
List<?>查询会被 PageHelper 的 MyBatis 拦截器 截获。 -
自动改 SQL 拦截器根据线程里的分页参数,自动计算
offset = (page-1)*pageSize,给你的 SQL 加上LIMIT offset, pageSize。 -
封装分页结果 查询完返回
Page/PageInfo,包含总条数、当前页数据。
核心记住这 3 条
-
只对紧跟的第一条查询生效
-
必须返回
List才能分页 -
基于 ThreadLocal + MyBatis 拦截器 实现
以后再出现 "只有 pageSize 生效",你就知道:要么 page 是 0 ,要么 没紧跟查询 ,要么 返回不是 List。