Redis 渐进式 rehash:为什么要分批搬迁哈希表
Redis 的 KV 组织底层依赖字典结构,字典本质上是"数组 + 链表"的哈希表结构,key 经过 hash 函数得到一个 64 位整数,再通过 hash & sizemask 映射到数组槽位,如果多个 key 映射到同一个槽位,就会通过链表解决冲突
在 Redis 中,不只是全局 key 空间会用到字典,hash 类型在元素数量较多或字符串较长时也会从压缩结构转换为字典结构,因此字典的扩容、缩容和 rehash 是 Redis 存储模型里非常核心的一部分
一、Redis 字典的基本结构
1. dictEntry 保存一个键值对
Redis 字典中的每个节点是一个 dictEntry,它保存 key、value 以及 next 指针,next 指针用于把哈希冲突的多个节点串成链表
c
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;可以把 dictEntry 理解成哈希桶链表上的一个节点,key 用来做查找,value 保存真正的数据,next 解决哈希冲突
2. dictht 表示一张哈希表
一张哈希表由数组、数组长度、掩码、已使用节点数构成
c
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;table 是哈希桶数组,size 是数组长度,sizemask 等于 size - 1,当 size 是 2 的幂时,hash % size 可以优化为 hash & sizemask,used 表示当前哈希表中已经存放了多少个节点
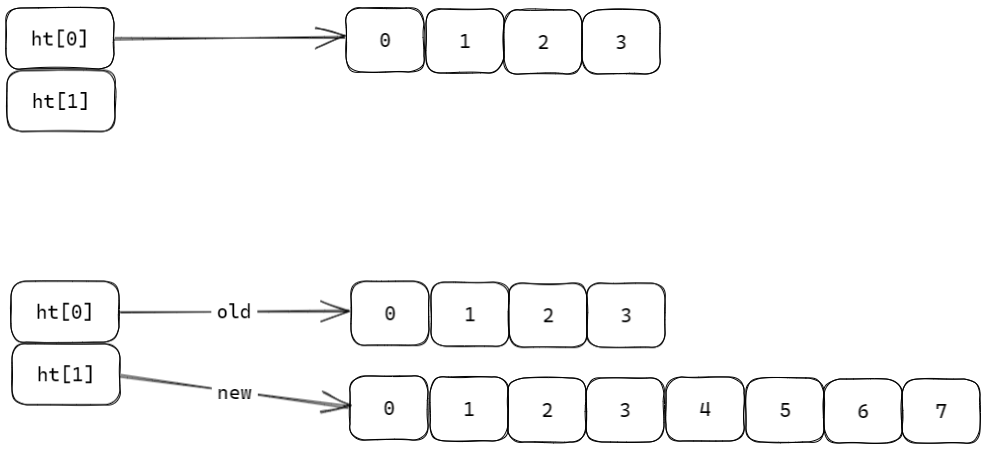
3. dict 同时维护 ht0 和 ht1
Redis 的字典并不是只维护一张哈希表,而是维护两张哈希表 ht[0] 和 ht[1]
c
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
int16_t pauserehash;
} dict;正常情况下只使用 ht[0],ht[1] 为空,当需要扩容或缩容时,Redis 会给 ht[1] 分配新数组,然后逐步把 ht[0] 中的数据迁移到 ht[1],rehashidx 用来记录当前迁移到哪个数组槽位,如果 rehashidx == -1,表示当前没有进行 rehash
二、为什么 Redis 需要 rehash
1. 哈希冲突会影响查询效率
Redis 通过哈希函数把 key 映射到数组槽位,但哈希空间远大于数组长度,所以不同 key 映射到同一个槽位是必然存在的,冲突越多,链表越长,查找、插入、删除时需要遍历的节点就越多
这就是负载因子的意义,负载因子可以理解为 used / size,其中 used 是元素数量,size 是数组长度,负载因子越大,冲突概率越高,哈希表性能越容易退化
2. 扩容与缩容都会触发 rehash
Redis 会根据负载因子决定是否扩容或缩容
- 扩容场景
当负载因子大于 1 时,说明元素数量已经超过数组长度,冲突可能越来越多,Redis 会考虑扩容,扩容通常会让新表容量变大,比如从 4 扩到 8
如果 Redis 正在执行 RDB、AOF 重写或 RDB-AOF 混用相关的 fork 操作,普通扩容会被尽量推迟,因为 fork 后父子进程共享内存页,扩容会带来大量写操作,容易触发写时复制,导致额外内存开销
但是如果负载因子已经大于 5,说明哈希冲突非常严重,继续拖延会导致访问效率明显下降,此时 Redis 仍然会强制扩容
- 缩容场景
当负载因子小于 0.1 时,说明数组太大但元素很少,空间浪费比较明显,Redis 会考虑缩容,缩容后的容量会选择一个能容纳 used 的 2 的幂,例如 used 为 9 时,新容量至少是 16
3. rehash 的本质是重新映射
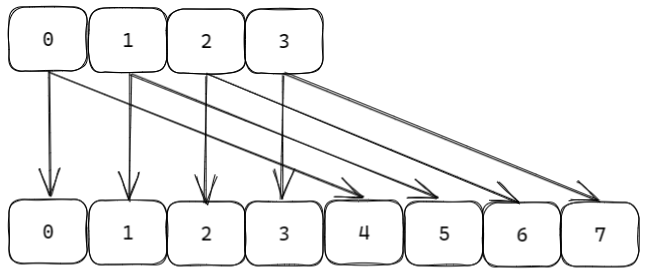
扩容或缩容后,数组长度发生变化,同一个 key 的槽位计算结果也可能发生变化,因此不能简单把旧数组复制到新数组,而是要重新计算每个 key 的位置
例如旧表大小为 4,新表大小为 8,原来通过 hash & 3 得到槽位,扩容后要通过 hash & 7 得到槽位,很多 key 会被映射到新的桶中,这个过程就是 rehash
三、为什么不能一次性完成 rehash
1. Redis 主线程不能长期被占用
Redis 的命令执行主要在主线程中完成,如果哈希表中有几十万甚至几百万个 key,一次性把所有节点从 ht[0] 搬到 ht[1],主线程会长时间停在 rehash 逻辑里
这段时间内其他客户端命令得不到响应,表现出来就是 Redis 卡顿,延迟尖刺,甚至业务超时
所以 Redis 没有采用一次性 rehash,而是采用渐进式 rehash,把一个大任务拆成很多小任务,分散到后续操作中慢慢完成
2. 渐进式 rehash 是典型的分治思想
渐进式 rehash 的核心思想是:先创建新表 ht[1],然后不急着一次性迁移所有数据,而是每次只迁移一小部分桶

假设 ht[0] 有 4 个槽位,ht[1] 有 8 个槽位,Redis 会从 rehashidx = 0 开始迁移,每次找到 ht[0] 中对应槽位的链表,把链表上的所有节点重新计算 hash 后放入 ht[1],然后把 rehashidx 往后推进
迁移过程可以理解为下面这样
- 给
ht[1]分配新数组 - 设置
rehashidx = 0,表示开始渐进式 rehash - 迁移
ht[0][rehashidx]这个桶上的所有节点到ht[1] - 清空旧桶,
rehashidx++ - 重复迁移,直到
ht[0].used == 0 - 释放旧的
ht[0],让ht[1]成为新的ht[0] - 清空
ht[1],设置rehashidx = -1
四、渐进式 rehash 期间如何处理命令
1. 查询需要同时查两张表
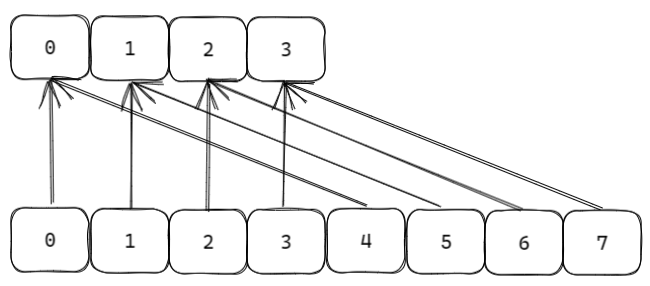
在 rehash 过程中,数据可能一部分在 ht[0],一部分在 ht[1],所以查找一个 key 时,Redis 不能只查一张表
查询流程可以概括为:先查 ht[0],如果没有找到,再查 ht[1]
这样可以保证迁移过程中不会因为数据分散在两张表里而查不到 key
2. 新增数据直接写入 ht1
如果 rehash 期间还有新的 key 插入,Redis 会直接把新 key 写入 ht[1],而不是继续写入 ht[0]
这样做的目的很明确:让 ht[0] 中的数据只减不增,保证渐进式 rehash 最终一定能结束
3. 修改和删除要兼容两张表
修改、删除和查询类似,也需要考虑 key 可能存在于 ht[0] 或 ht[1]
如果 key 还没有被迁移,就在 ht[0] 中修改或删除,如果已经被迁移,就在 ht[1] 中修改或删除
4. 每次命令顺便推进一点 rehash
Redis 会把迁移动作分摊到后续的增删改查命令中,每执行一次相关命令,就顺便迁移一部分桶
这就是"渐进式"的含义,用户命令本身仍然执行,只是在执行前后顺带做一点搬迁工作,避免一次性搬迁带来的长时间阻塞
五、Redis 还会在定时任务中推进 rehash
1. 命令触发不是唯一推进方式
如果 Redis 长时间没有收到命令,仅依靠命令触发就可能导致 rehash 停在那里,因此 Redis 还会在周期性任务中主动推进 rehash
资料中提到,Redis 会在定时器中最多执行 1 毫秒 rehash,每次步长可以按 100 个数组槽位推进
这样即使命令请求不密集,rehash 也能继续向前走,不会永远停留在中间状态
2. 时间限制是为了控制延迟
定时任务中不能无限制地 rehash,因为 Redis 还要处理客户端请求、过期 key、AOF、复制等其他任务
所以 Redis 给定时 rehash 设置时间上限,例如最多执行 1 毫秒,这种设计本质上是在吞吐和延迟之间做平衡
六、渐进式 rehash 阶段的几个面试重点
1. 渐进式 rehash 时还会继续扩容或缩容吗
不会
当字典已经处于 rehash 阶段时,Redis 不会在这个过程中再次触发新的扩容或缩容,因为此时已经有两张表在迁移,如果继续改变目标表大小,会让迁移状态变得复杂,也会增加实现成本
2. 渐进式 rehash 会不会影响查询性能
会有一点影响,但这是可接受的
正常情况下查询只需要查 ht[0],rehash 期间可能需要先查 ht[0] 再查 ht[1],多了一次哈希表查询,但相比一次性 rehash 造成长时间阻塞,这个代价更小
3. 渐进式 rehash 为什么能降低卡顿
因为它把一次性的大迁移拆成很多次小迁移
一次性 rehash 是"一个命令承担全部迁移成本",渐进式 rehash 是"很多命令共同承担迁移成本",单次命令增加的耗时很小,整体延迟更加平滑
4. 渐进式 rehash 和大 key 有什么关系
大 key 也可能导致卡顿,例如一个特别大的 hash 或 zset,在扩容时可能申请更大的内存块,在删除时也可能一次性释放大量内存
渐进式 rehash 可以缓解字典整体搬迁造成的阻塞,但它不能完全解决所有大 key 问题,如果单个 key 内部结构本身非常大,操作这个 key 仍然可能造成明显延迟
七、用一个例子理解完整过程
假设 Redis 当前字典的 ht[0] 长度为 4,已经存放了 5 个元素,此时负载因子 used / size = 5 / 4 = 1.25,超过扩容阈值,需要扩容到长度为 8 的 ht[1]
- Redis 创建
ht[1],长度为 8 - 设置
rehashidx = 0 - 下一次执行命令时,顺便迁移
ht[0][0]桶中的所有节点 - 再下一次执行命令时,继续迁移
ht[0][1] - 如果某个桶为空,直接跳过并继续推进
- 查询 key 时,两张表都要查
- 新增 key 时,只写入
ht[1] - 当
ht[0]所有元素都迁移完成后,释放旧表 - 把
ht[1]变成新的ht[0],rehash 结束
这个过程的关键不在于"是否重新计算 hash",而在于"重新计算 hash 的成本被拆散了",Redis 用更长的总时间换来了更低的单次阻塞时间
八、总结
Redis 渐进式 rehash 解决的是哈希表扩容、缩容时一次性搬迁成本过高的问题
Redis 字典通过 ht[0] 和 ht[1] 两张表配合 rehashidx 实现迁移状态管理,正常情况下只使用 ht[0],扩容或缩容时创建 ht[1],然后分批把旧表数据搬到新表
在 rehash 期间,查询、修改、删除需要兼容两张表,新增数据直接写入新表,保证旧表元素只减不增,迁移过程会分摊到后续命令和定时任务中执行
从工程角度看,渐进式 rehash 的本质是把不可接受的一次性阻塞拆成很多可接受的小开销,这是 Redis 保持低延迟的重要设计之一