
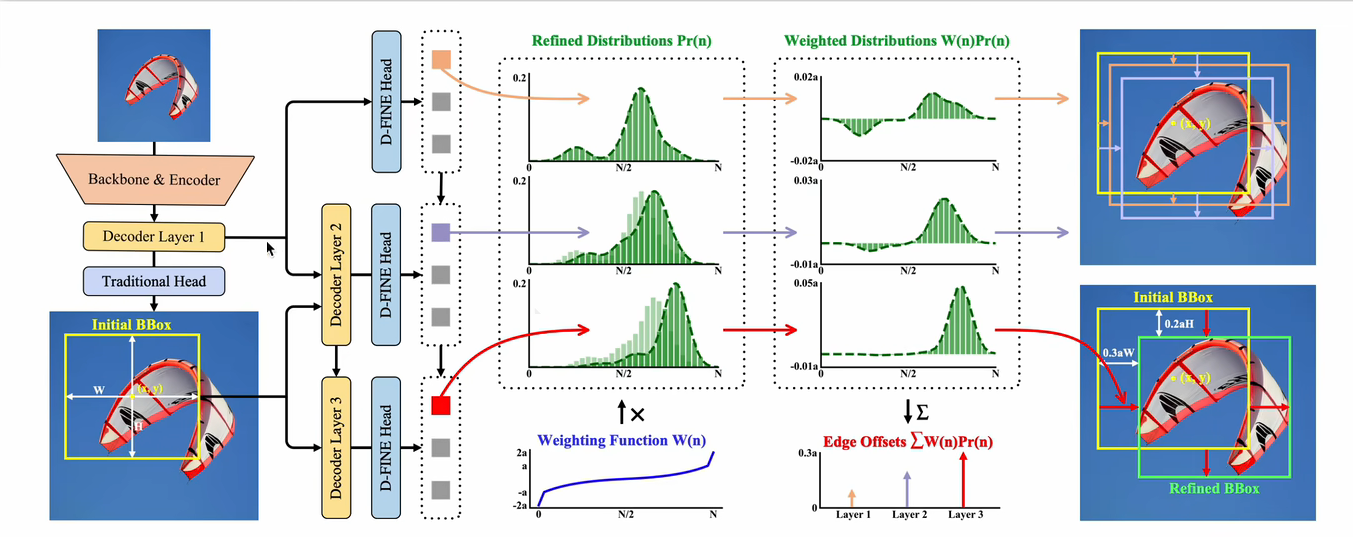
FDR细粒度分布优化
define实在RT-DETR的基础上进行改进
先回顾RT-DETR部分的计算: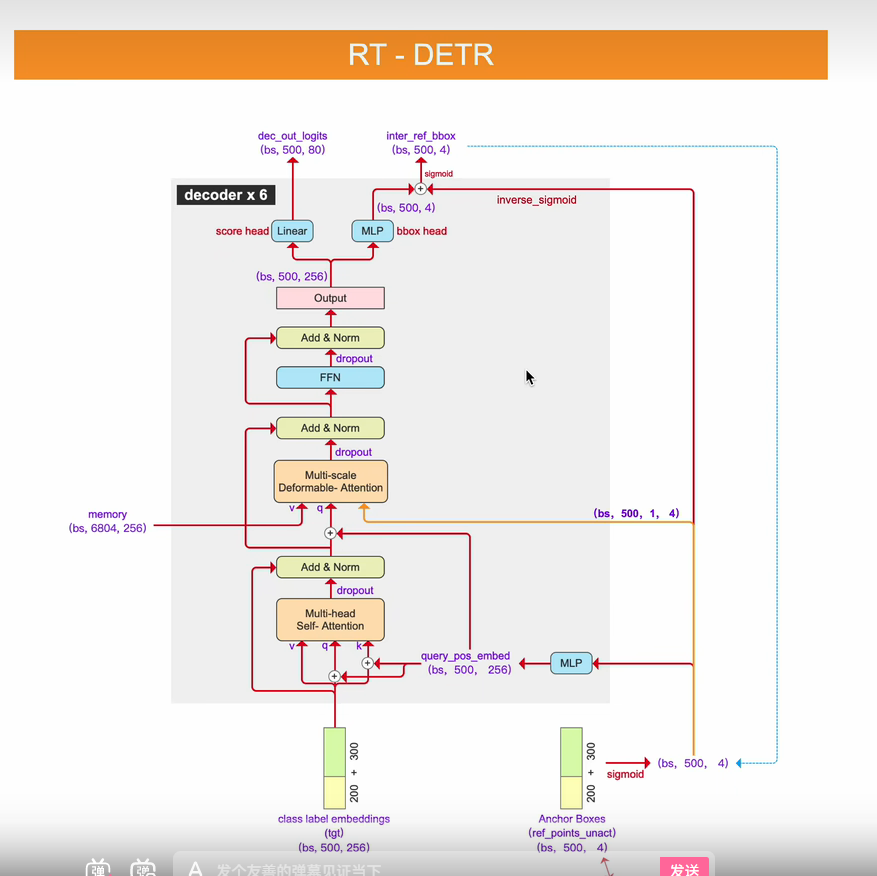
让decoder部分的输出分别经过两个检测头,一个是类别检测头,一个是定位检测头,从定位检头得到的输出,它相较于基准坐标的预测偏移量,我们会让这个基准坐标先经过sigmoid的反函数,把坐标先映射为左sigmoid之前的原始值,加上预测出来的坐标偏移量,想加后就是修正过的,预测出来的bound box,这里要再做一个sigmoid,进行归一化,然后再拿回去,作为下一个decoder列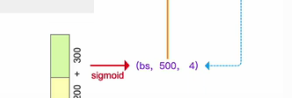 的输入,下一个decoder列会在这个坐标的基础上继续预测偏移量,等六个decoder列都预测完,最终得到预测出来的bound box的坐标就是在最初的reference-points-unact坐标的基础上,++修正六次之后得到的bounding box 的坐标。++这就是对RT-DETR这部分运算的回顾。
的输入,下一个decoder列会在这个坐标的基础上继续预测偏移量,等六个decoder列都预测完,最终得到预测出来的bound box的坐标就是在最初的reference-points-unact坐标的基础上,++修正六次之后得到的bounding box 的坐标。++这就是对RT-DETR这部分运算的回顾。
D-Fine
和RT-DETR也是一样,逐层的对定位坐标进行修正。
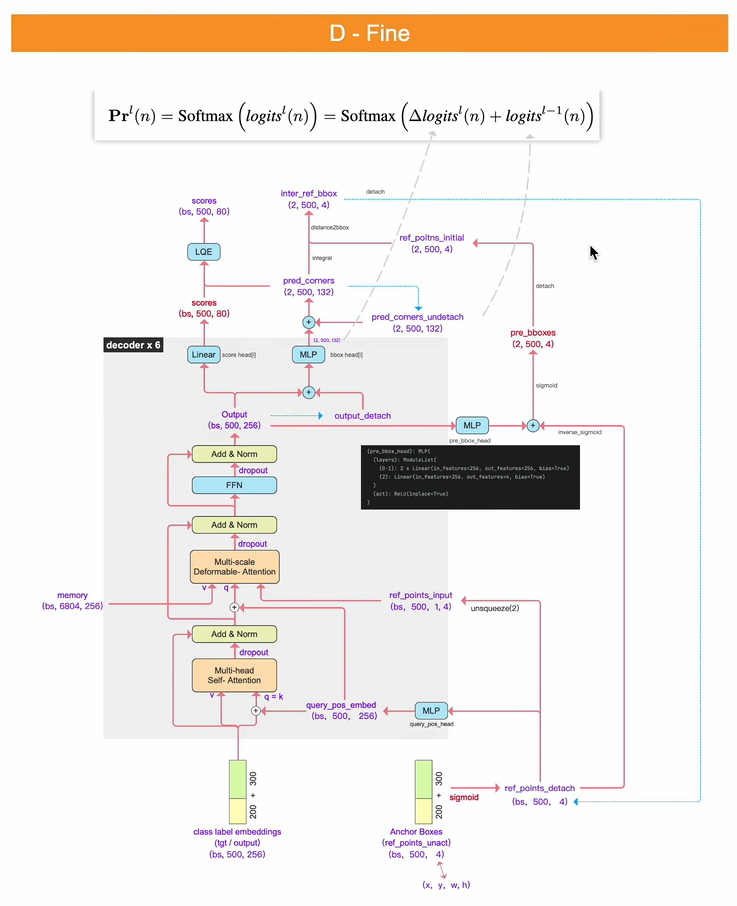
经过六层的decoder列,会修正六次坐标,像论文中的示意图这样:
第一个decoder列会分别经过两个检测头,一个是traditional head,D-fine head;traditional head 她的作用是预测出来一个初始的bounding box坐标,这边每层decoder列的输出,分别经过define head 去预测出一个坐标偏移量,这些坐标偏移量会进行累加,逐层在bounding box的位置上进行修正 。
第一个decoder经过第一个define head
第二个decoder经过第二个define head 输出出来的结果也是预测的坐标偏移量,这次预测出的坐标偏移量会累加在上一个坐标偏移量之上...后面依次类推。
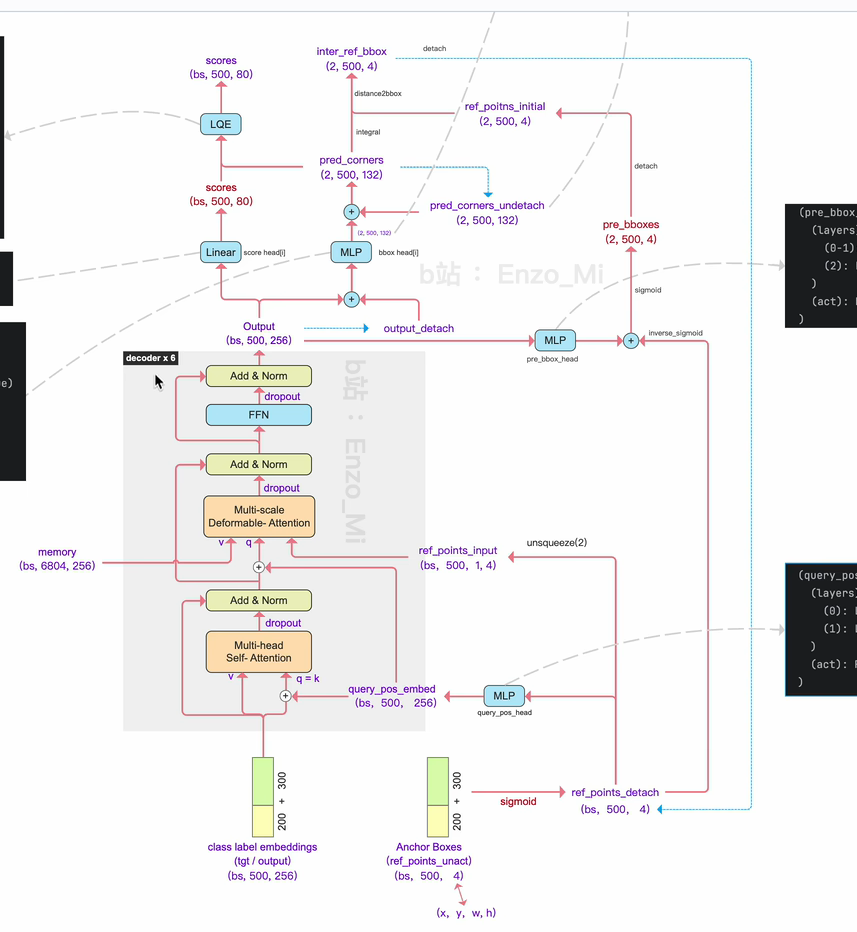
我们从decoder列1 得到的输出,是(bs 500 256),这个500表示的是有500个bounding box,
这五百个bounding box是咋得到的?
500个 bounding box 不是从图像提取出来的,而是网络自己想象出来的可学习的参数。
具体来两,这500是object queries(对象查询)
伪代码示意
self.num_queries = 500 # 超参数,人为设定
self.hidden_dim = 256 # 特征维度这 500 个查询是可学习的 Embedding,就像卷积核权重一样
self.tgt_embed = nn.Embedding(num_queries, hidden_dim) # (500, 256)
- 形状:(bs,500,256)中的500表示"我假设这张图最多有500个坐标"
- 本质:这500个向量是随机初始化的,通过端到端的惗,他们逐渐学会:
- 有的query专门差"左上角的猫"
- 有的query专门查"右下角的人"
- 有的query学会查"小目标"
- 有的query学会查"大目标"
(200+300机制)
是混合查询选择机制的结果,
1.encoder输出特征图,图像经过backbone和encoder之后,得到特征图
2.选出top-200 (来自图像内容)
1.预测分数,在encoder输出的每个空间位置预测类别无关的objectness分数
2.选出top-200,选出得分最高的200个位置索引
3.提取特征作为query content,这200个位置对应的特征向量被提取出来,作为200个 content
4.生成reference points(参考点)这两百个位置对应的原图坐标经过归一化(加上预测 的小偏移)生成两百个参考点
3。除了图像选出200,增加300个纯可学习的query(类似原始DETR)
4.直接拼接成500个box query
image-aware 200 encoder选出的真实特征**精确定位:**确保query锚定在有可能有物体的实际位置,加速收敛
learnable 300 网络随机初始化学习 **覆盖纰漏:**学习数据集中的统计分布,防止encoder漏检小目标