RAG = 检索增强生成(Retrieval‑Augmented Generation) 简单说:让 AI 先查你的私有资料,再回答问题,不瞎编、用你自己的数据。解决了大模型幻觉问题.之后生成回答时,先从知识库检索相关知识,然后把检索结果和原始问题一起给大模型,大模型再生成最后结果.
例如刚才下载的本地qwen3:8b大模型,只知道训练它的历史数据,也不知道你针对的知识库,根据你的问题很可能乱说回答,因此RAG :把你本地的 ** 私有知识库(源码、日志、运维手册)** 喂给 AI,AI 回答前先检索这些资料,再生成答案.Dify:就是帮你做 RAG 的可视化工具
通俗类比
- 大模型(Ollama):一个普通大学生,只有课本知识
- RAG :给他你的公司机密运维档案、源码、故障手册
- 提示词工程:教他怎么看档案、怎么专业回答
- Dify :帮你把档案整理好、让大学生快速查找、回答(私有数据不外泄:源码、生产日志不能上传到 GPT、通义千问,RAG 完全本地私有化)
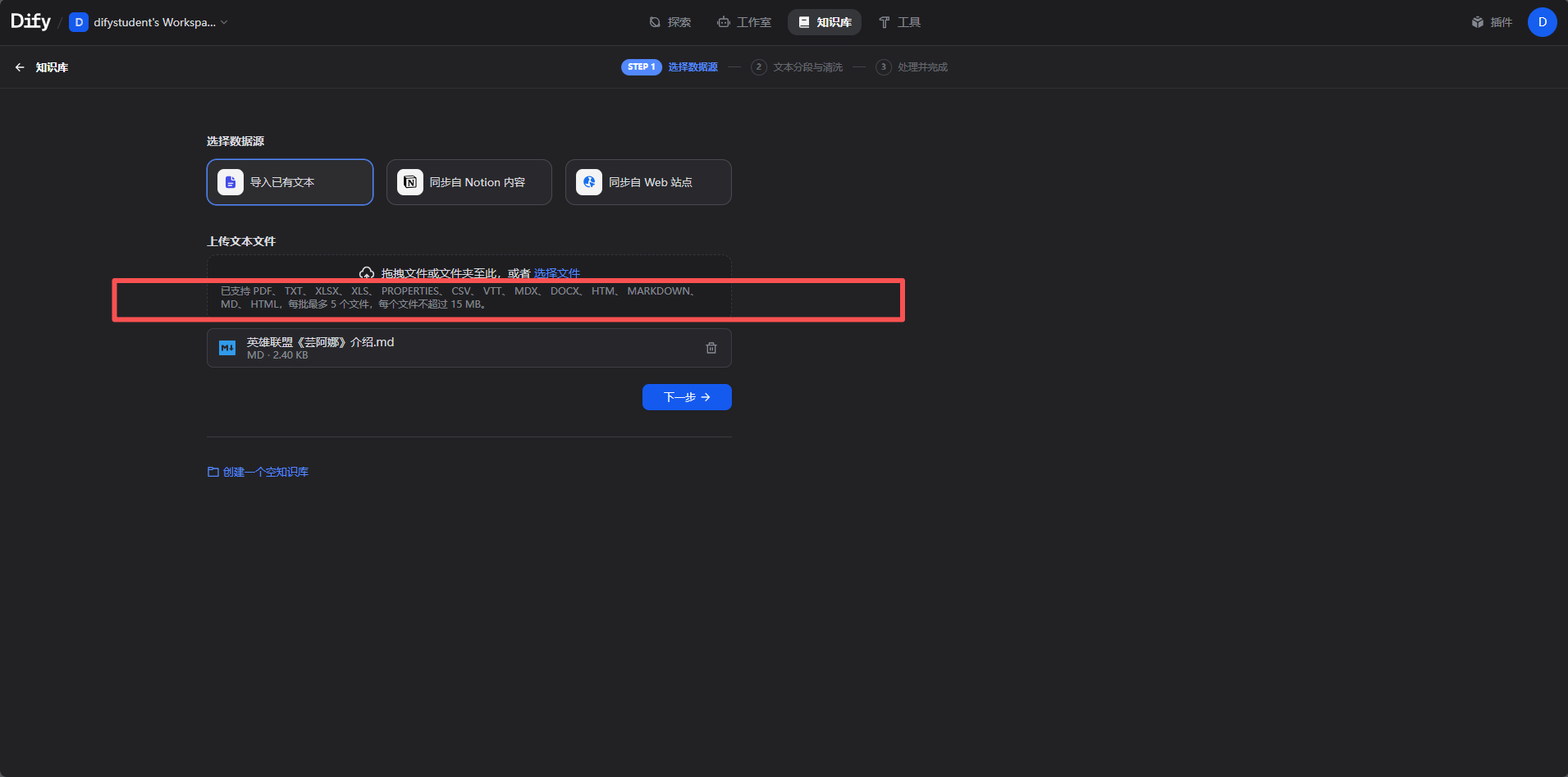
第一步文档准备,要注意信息处理,命名规范
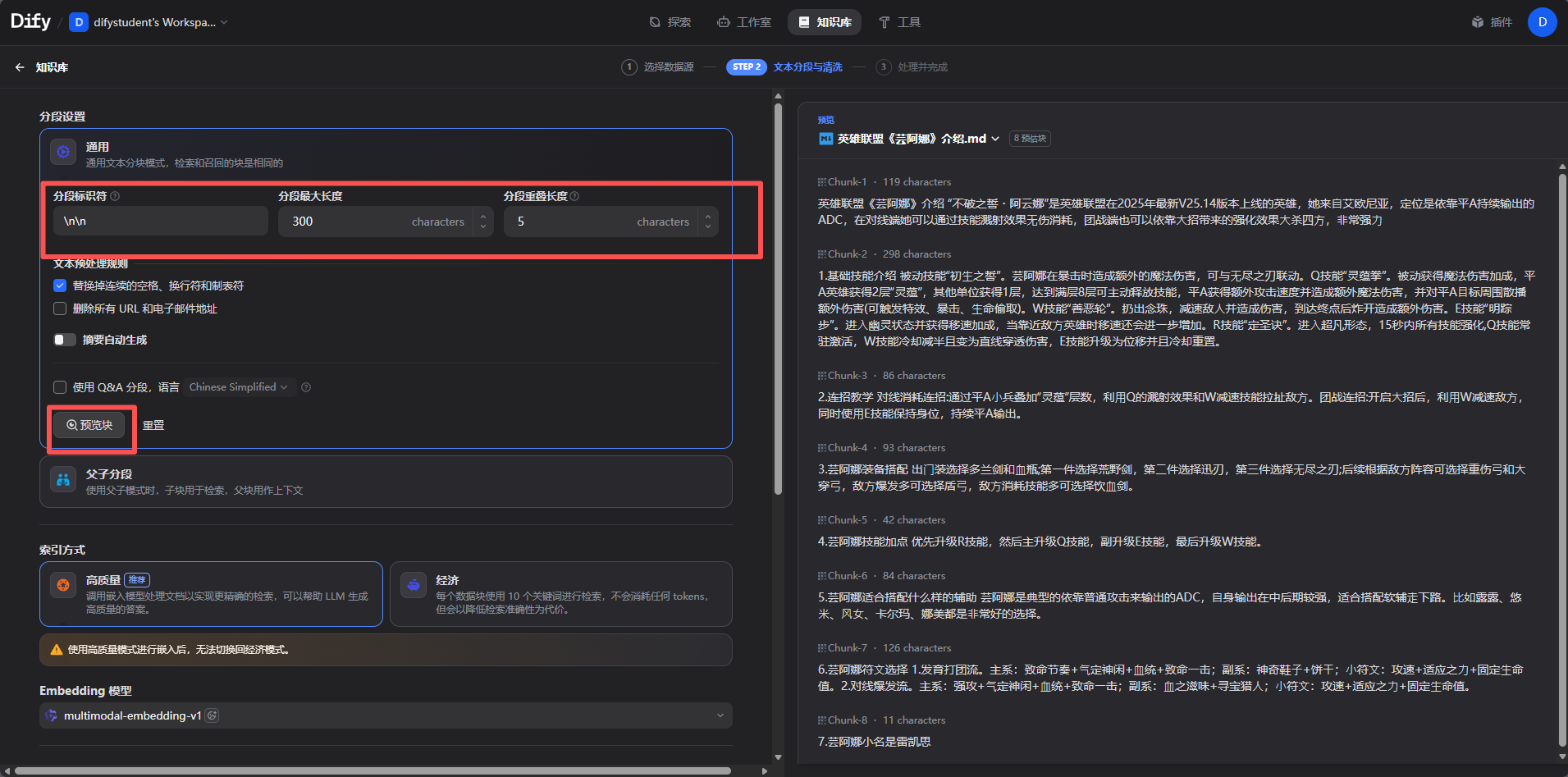
第二步文档切片,为了适应上下文限制;切分方式:按照字数;按照符号;按照语义.一般选择按照符号和字数,选择三四百字吧
第三步:文档向量化
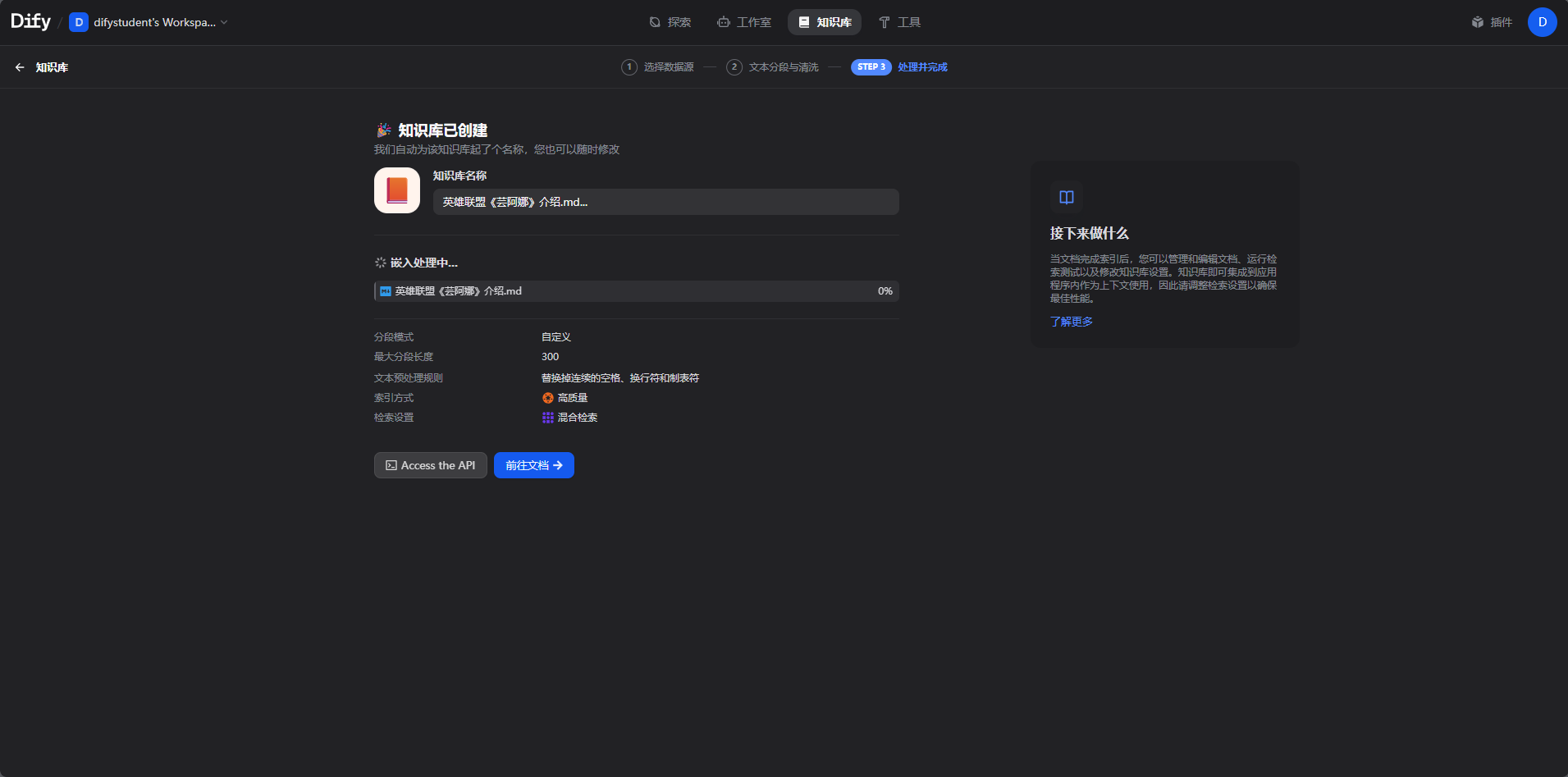
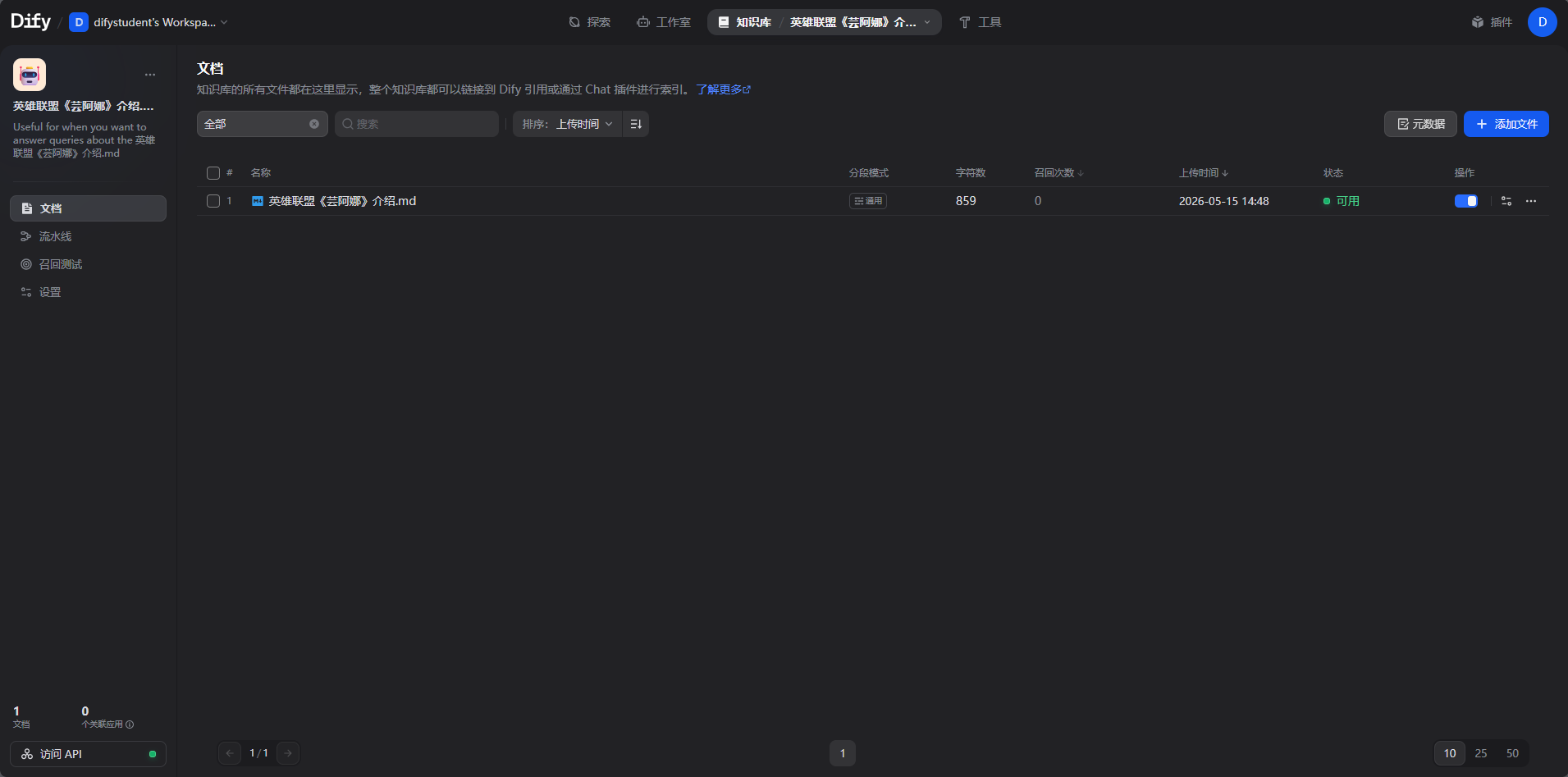
实操步骤1.创建知识库;2.选择数据源;3.文本分段;4.构建向量化索引;5.检索设置;6.查看结果
打开dify
http://localhost/apps
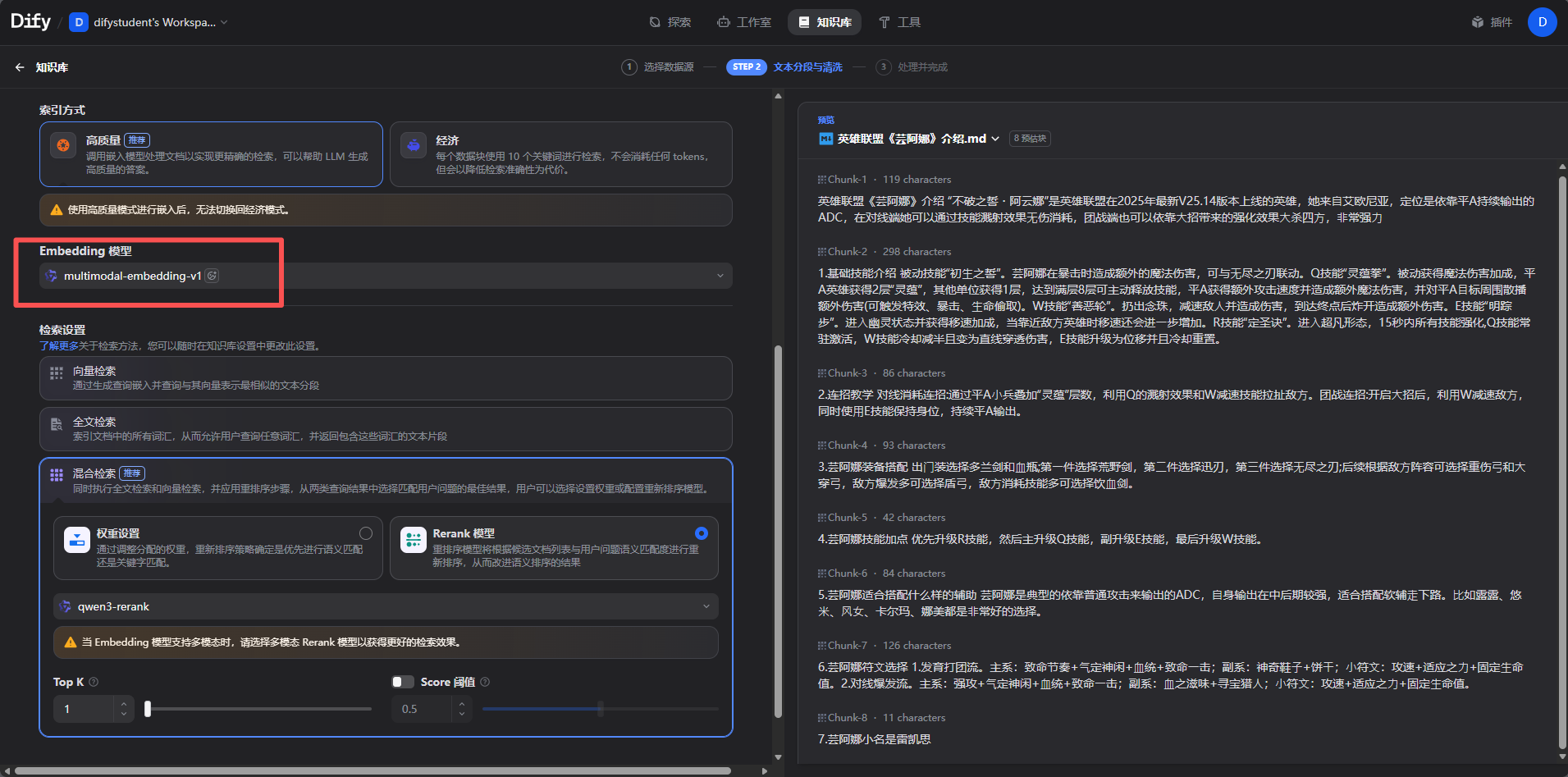
还有embedding
Embedding = 把文字变成一串数字(向量),让 AI 能看懂 "文字之间的相似度" 它是 RAG(知识库)的核心底层技术,没有 Embedding 就做不了私有知识库。
- 日志文本:
线程死锁,通信超时 - 代码片段:
pthread_mutex 未释放
变成一串几百个数字:[0.21, 0.87, -0.33, ...] 这串数字就叫 向量 / Embedding
- 意思相近的文字 → 数字也接近
- 意思完全无关 → 数字差距很大
完整工作流程(串联 Docker / Dify / Ollama / RAG / Embedding)
- 你上传 C++ 源码、生产日志 到 Dify 知识库
- Embedding 模型(也是 Ollama 里跑的一个小模型)把每一段文字变成数字向量
- 向量存入数据库
- 你提问:
为什么线程死锁? - 提问也被转成向量
- 系统对比向量,找出最相似的源码 / 日志片段(这就是 RAG 的检索步骤)
- 把片段发给大模型(qwen3:8b),生成回答
- Ollama:本地运行 AI(大脑 + 指纹生成器)
- Embedding:给文字做指纹,用于检索
- RAG:用指纹查私有知识库,再让大脑回答
- 提示词工程:教大脑怎么专业回答
- Dify:可视化工具,把上面全部串起来
- Docker:隔离运行 Dify 整套服务
简单说:Embedding 就是给文字做 "指纹",用来快速找相似内容。
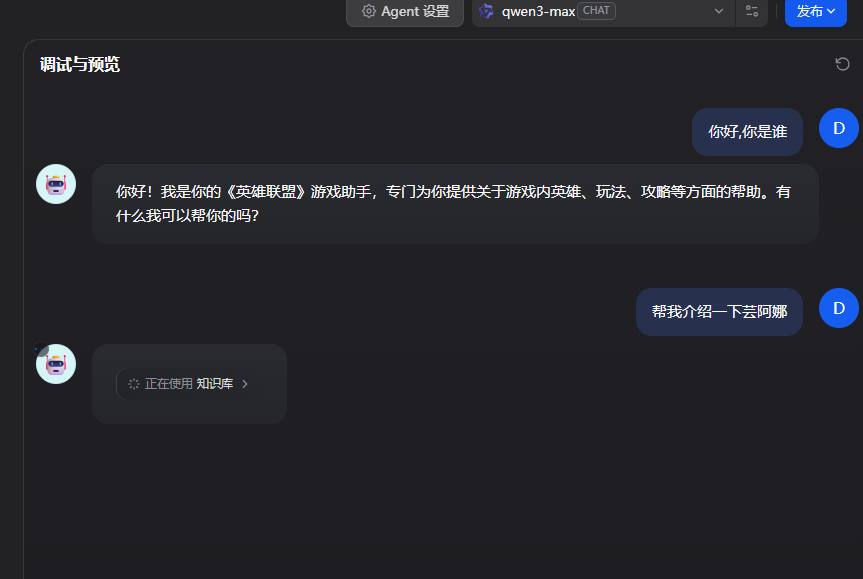
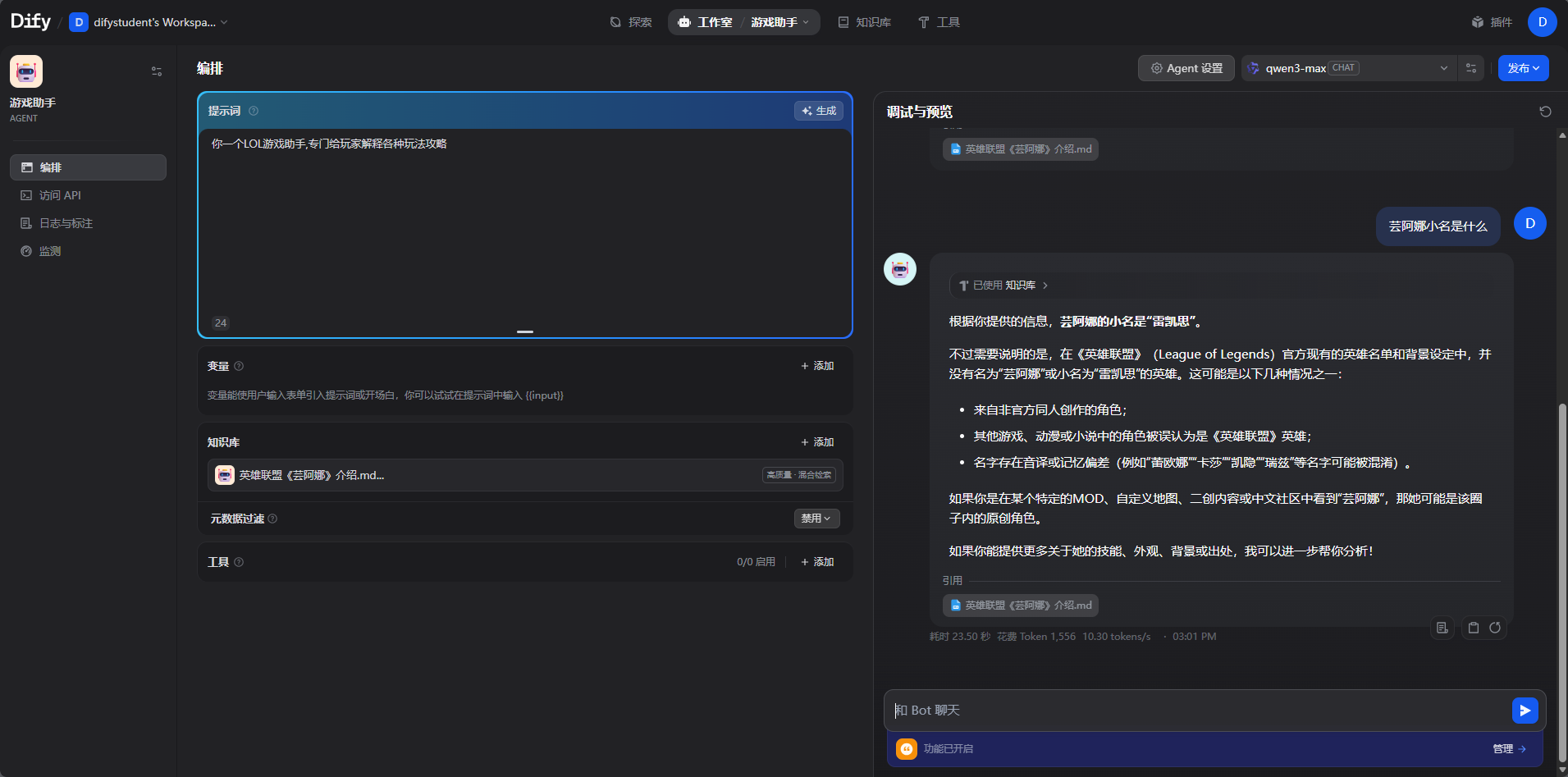
然后我们让ai用这个,创建一个智能体agent,一个agent可以多个知识库.
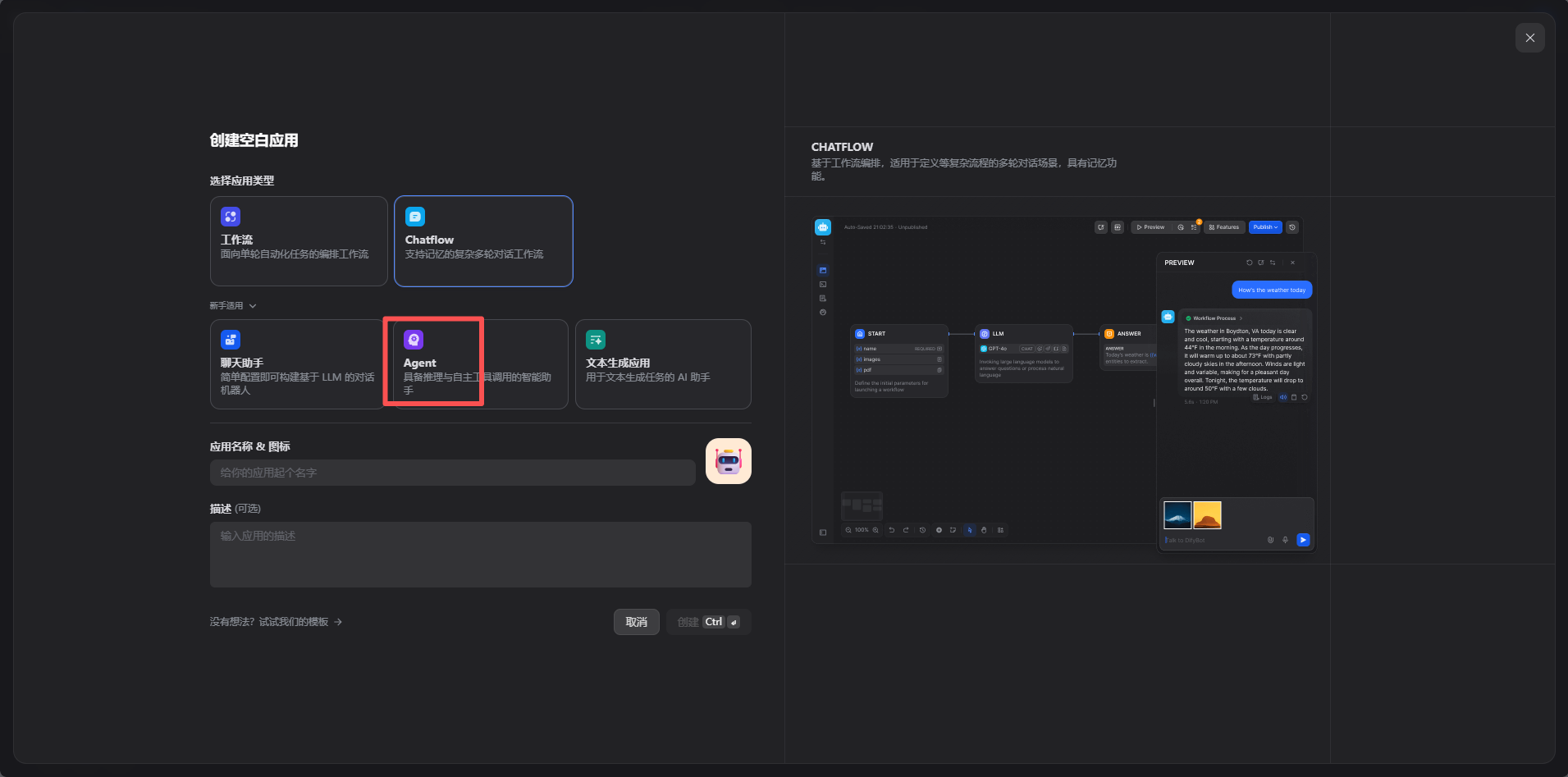
创建游戏助手后,测试一下
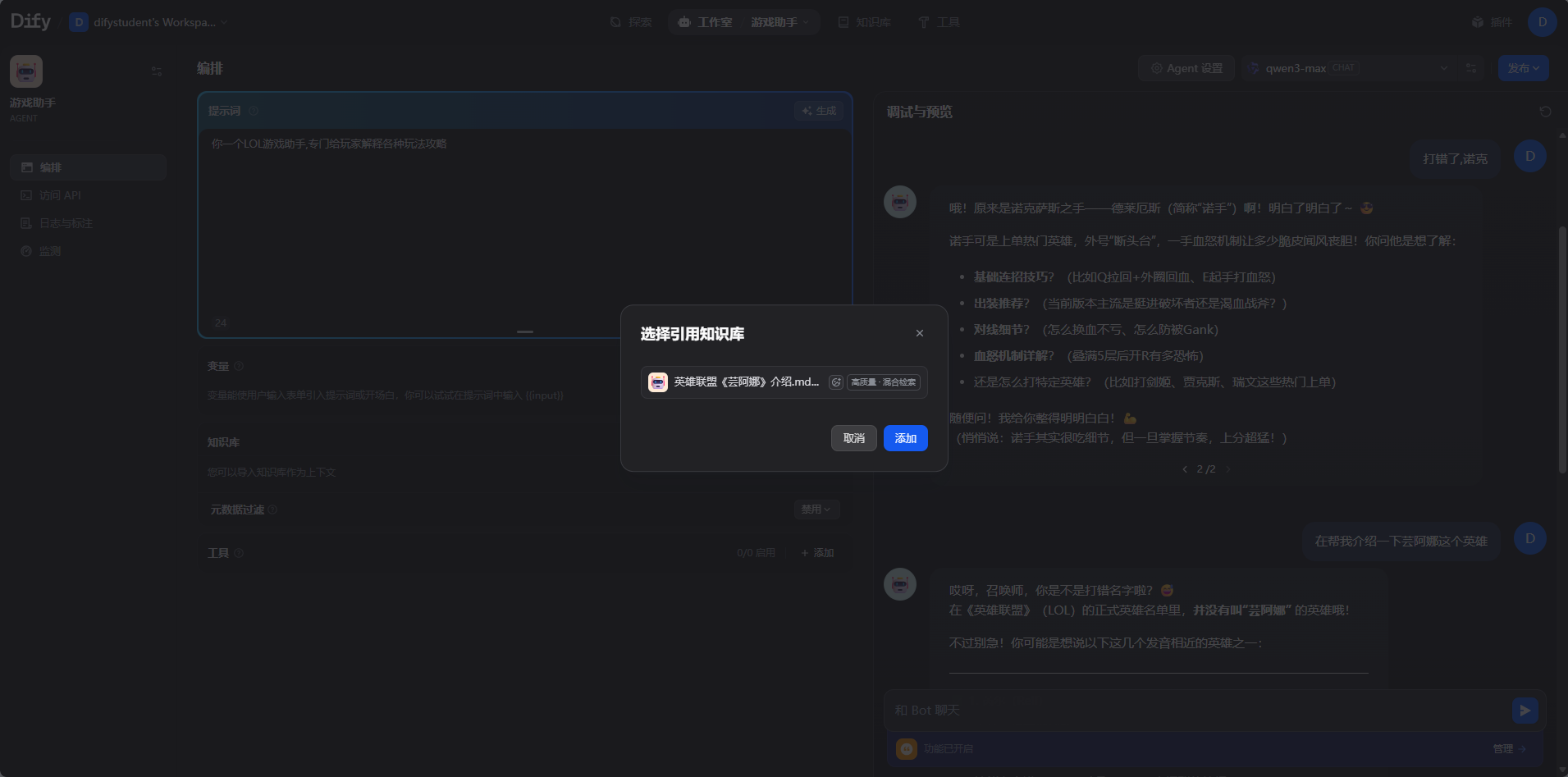
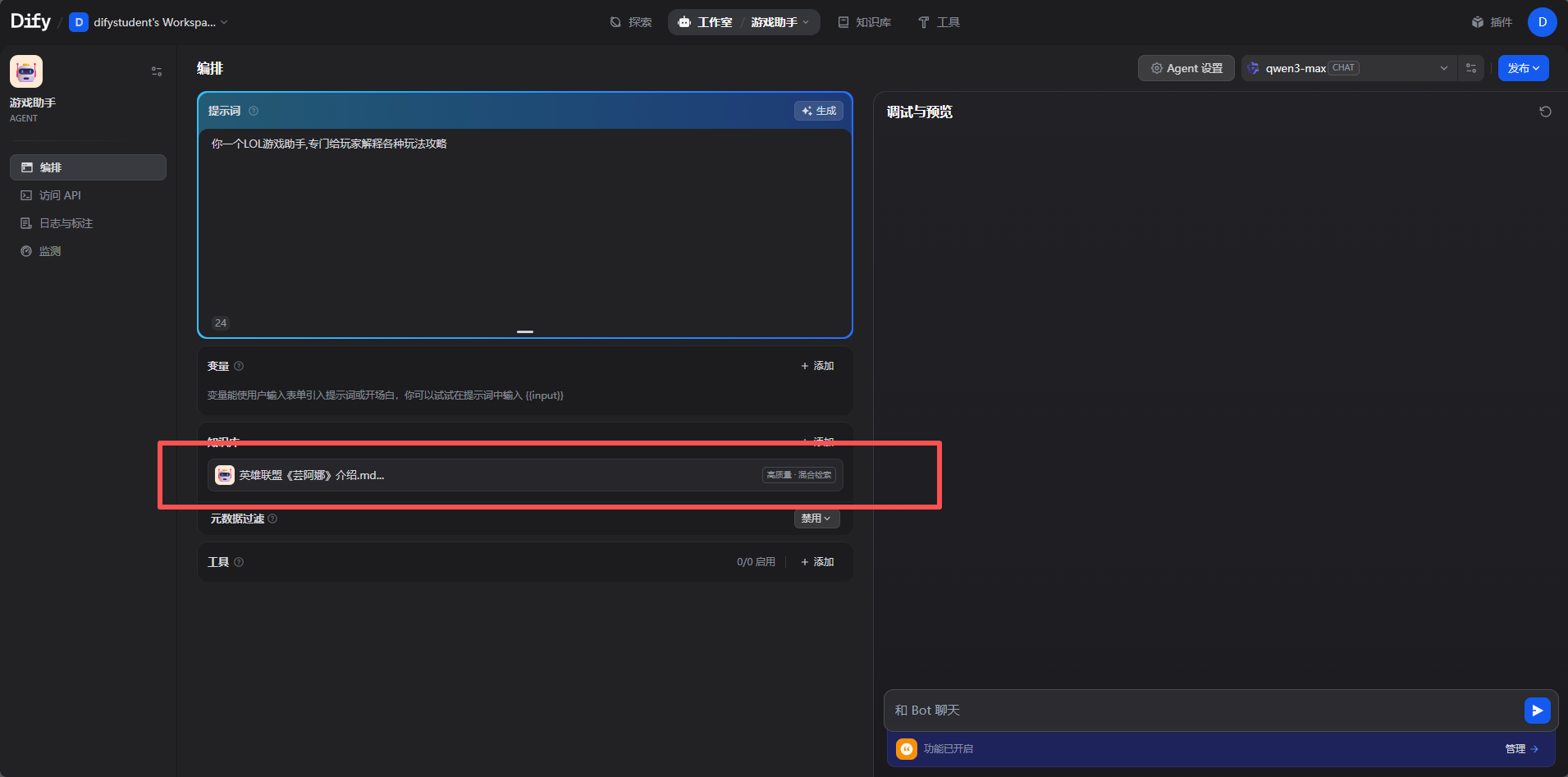
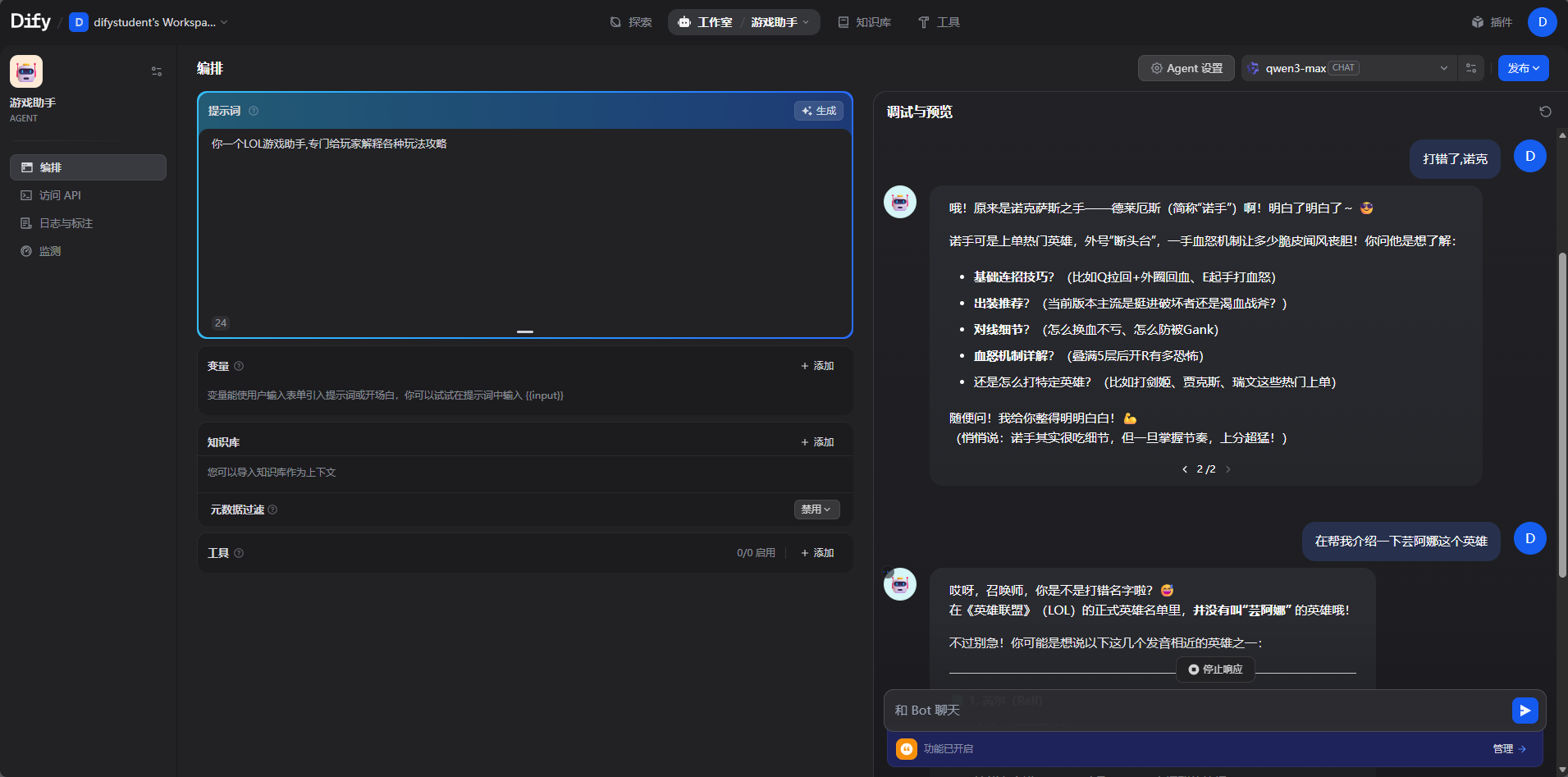 点击知识库,选择这个新的知识库
点击知识库,选择这个新的知识库
下面我们看看如何用function calling
Function Calling = 让 AI 自动调用你写好的工具 / 代码 / 接口,去查数据、执行操作,再回来回答你 简单说:AI 不只靠脑子想,还会自己动手查工具、查数据库、执行命令'
场景:你问 AI:
"最近 3 天线程死锁的日志有哪些?帮我定位根因"
普通 AI(没有 Function Calling)
只能基于你上传的静态日志回答,查不到实时最新数据
开启 Function Calling(你的私有运维 AI)
AI 自动执行 3 步:
- 识别意图 :你要查实时最新日志
- 调用函数 / 接口:自动调用你写的 Python 脚本、数据库接口、运维系统 API,拉取最新崩溃日志
- 分析 + 回答:拿到实时数据后,结合知识库,给出故障根因 + 排查步骤
- Ollama:本地运行 AI 大脑(Qwen3:8b)
- Embedding:文字转数字,给内容打指纹(RAG 检索用)
- RAG :查静态私有知识库(源码、历史日志、手册)
- Function Calling :调用外部工具 / 接口,查实时数据、执行操作
- 提示词工程:教 AI 角色、规则、格式
- Dify:可视化搭建以上全部功能
- Docker:隔离运行整套服务
最简单的类比
- RAG = 查历史档案(静态资料)
- Function Calling = 打电话查实时数据、执行命令(动态工具)
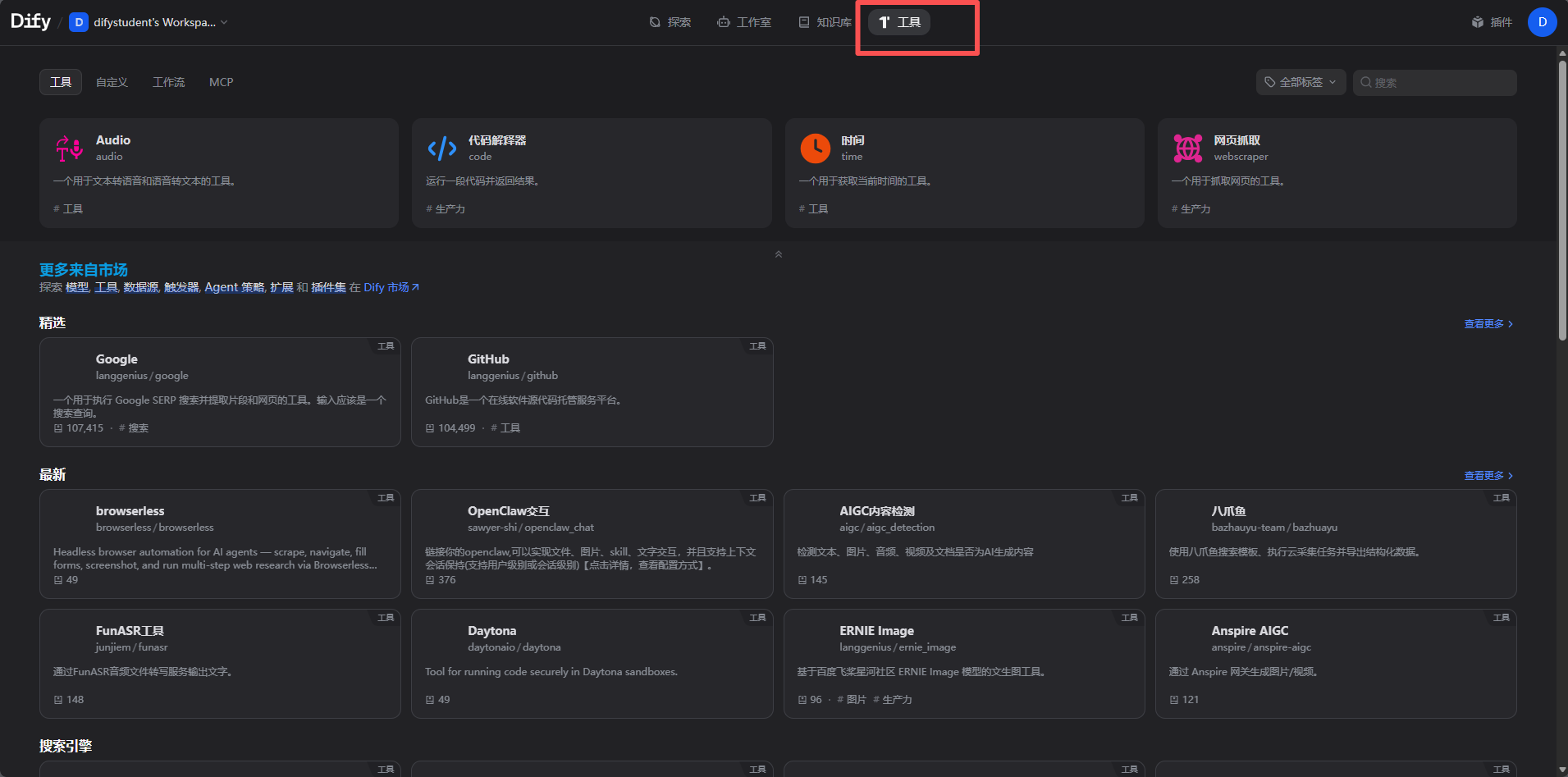
下面我们用dify里面的插件看看怎么用
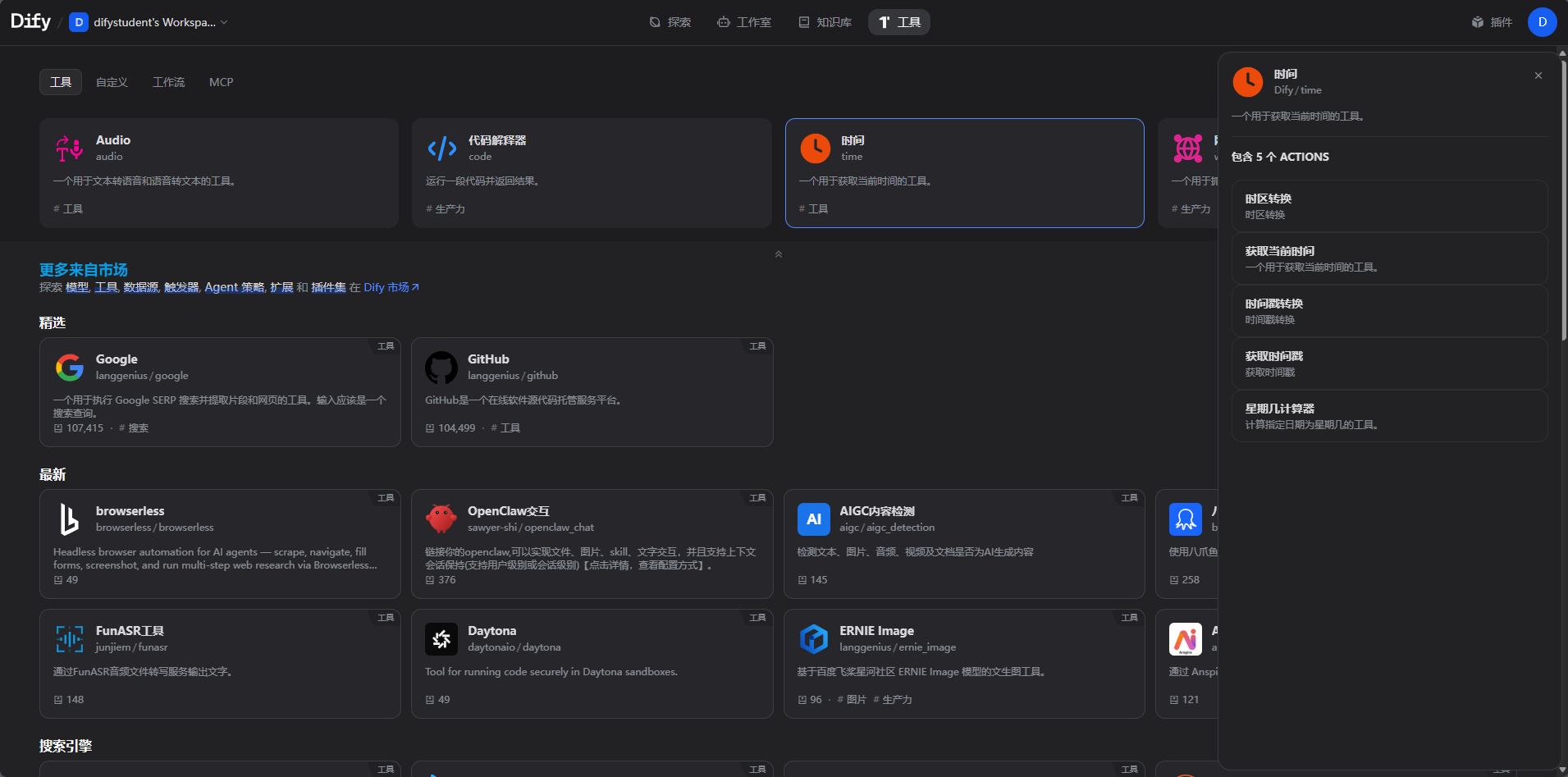
创建一个agent
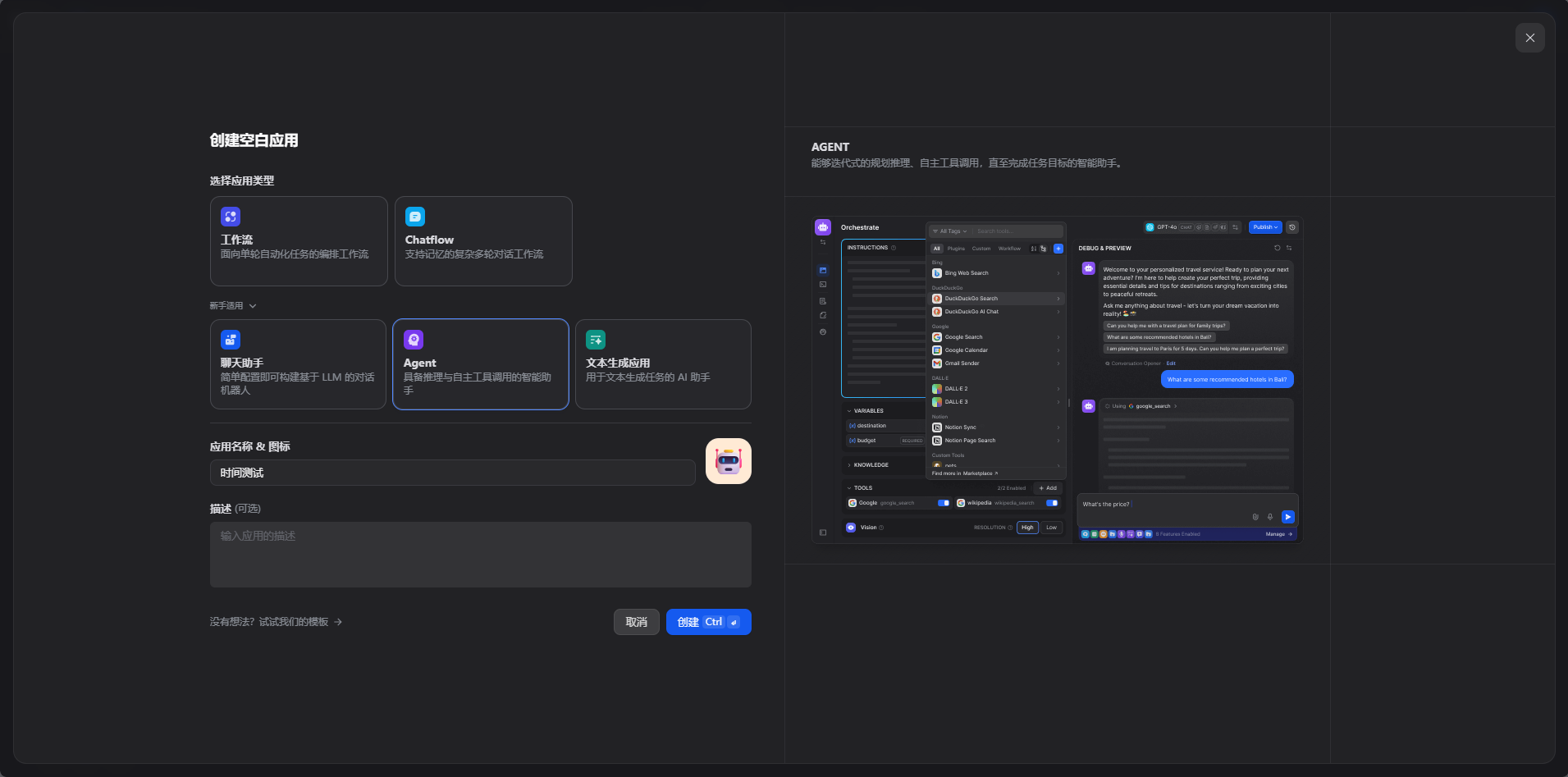
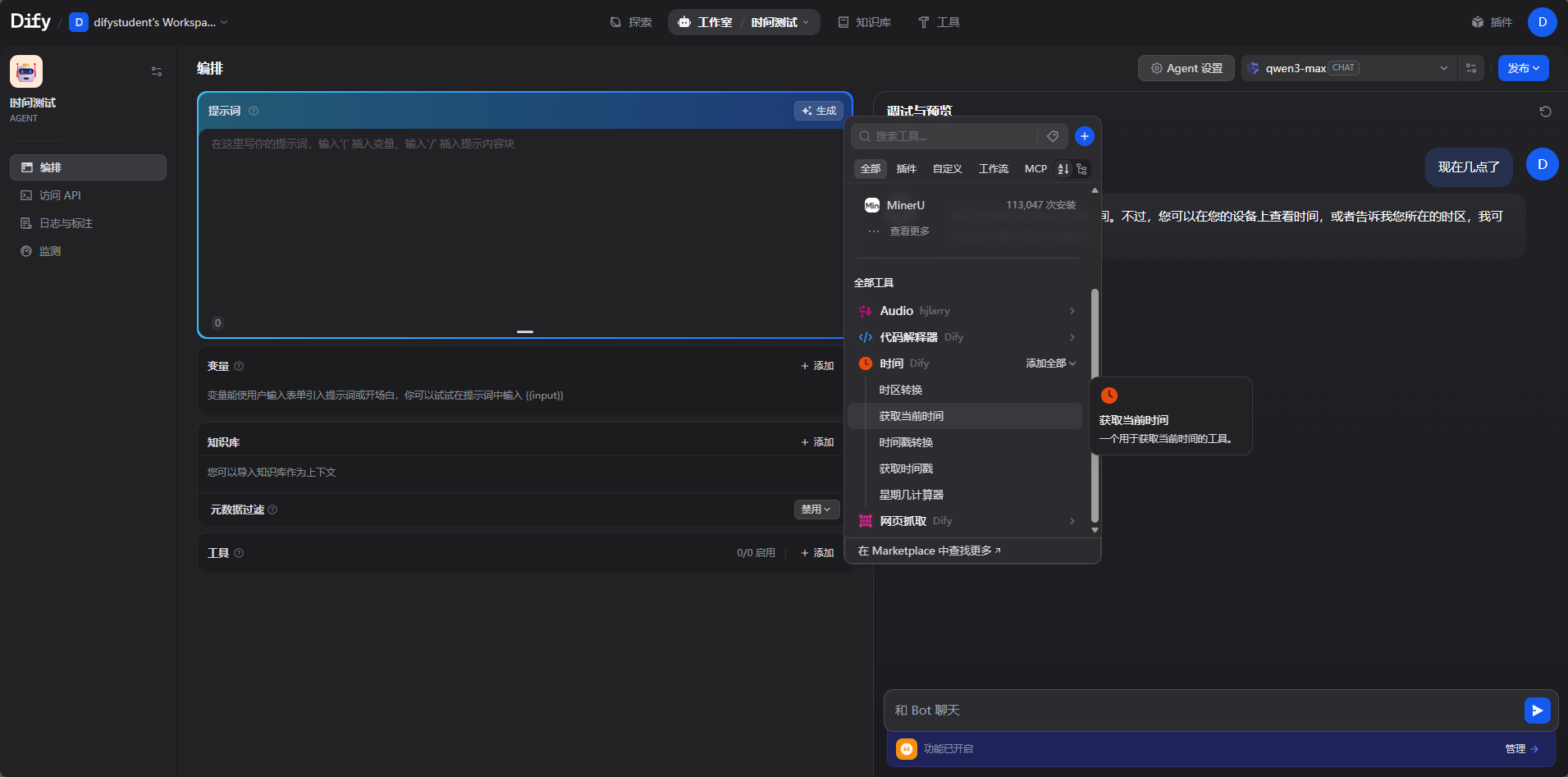
直接问几点大模型是不知道的,现在改好时间区域
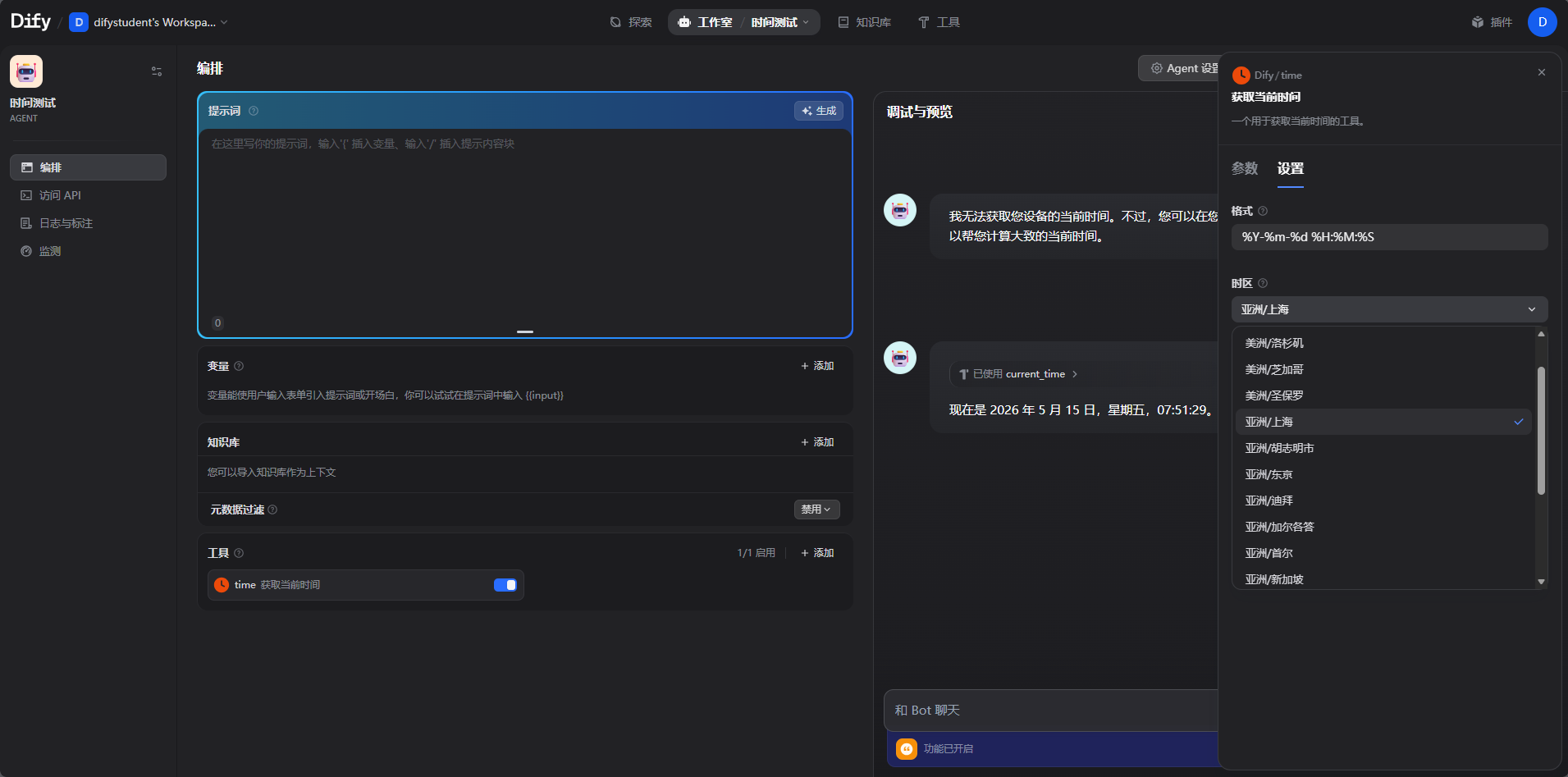
这是一个dify已经定义好的插件的使用,下一个文章我们来试一下自己定义插件
基本流程:1.脚本开发;2.运行脚本;3.创建工具;4.schema操作;5.测试和保存