轻量级超分的双频域协同:深入源码解析 DMNet 架构设计

在边缘计算设备(如手机、无人机)上部署图像超分辨率(SR)模型时,算法工程师常常面临一个权衡:如何在极其有限的计算资源(低参数量、低 FLOPs)下,尽可能恢复出高保真的图像细节?
现有的轻量级超分网络大多局限于空间域(Spatial Domain)进行操作,这天然限制了模型的感受野,导致难以捕捉全局结构。为了打破这一限制,研究者开始引入频域(如傅里叶域或小波域)信息。
由北京邮电大学等机构发表在IEEE TRANSACTIONS ON MULTIMEDIA的论文《Dual-domain Modulation Network for Lightweight Image Super-Resolution》(DMNet)提出了一种极具工程启发性的方案:在小波域中进行局部特征重构,在傅里叶域中进行全局结构监督。
本文将结合论文作者开源的源码,深入拆解 DMNet 的底层逻辑,并提供核心模块的可插拔代码与详细注释,探讨其在工业界落地的潜力与局限。
一、 核心动机:为什么必须是"双频域"协同?
许多读者在阅读频域相关的论文时,常有一个疑问:既然小波变换和傅里叶变换都能把图像转到频域,为什么 DMNet 非要两个一起用?只用一个不行吗?
这里我们可以用一个**"画肖像"的生活比喻**来解释:
傅里叶变换(Fourier)就像是画家退后三步,眯着眼睛看整幅画的"宏观比例"(比如五官位置对不对)。它提取的是全局频率分布。如果只用傅里叶域做特征提取,模型能很好地把握整体结构,但当你凑近看时,会发现睫毛、毛孔等高频细节是模糊的。
小波变换(Wavelet)就像是画家拿着放大镜,专门刻画某一个局部的"边缘细节"。它能将图像无损分解为一个低频(大体轮廓)和三个高频(水平、垂直、对角线纹理)。但如果只在小波域里疯狂优化高频细节,不同方向的高频特征在梯度下降时容易产生冲突,导致最终合成的图像虽然清晰,但整体结构可能发生扭曲。
DMNet 的思路: 既然小波擅长"抓细节",傅里叶擅长"控大局",DMNet 将两者分工:
- 模型内部的特征提取交给小波域(利用其保留空间位置信息的特性,锐化纹理)。
- 模型外部的损失约束交给傅里叶域(利用全局频率分布,稳住整体结构,防止小波域优化跑偏)。
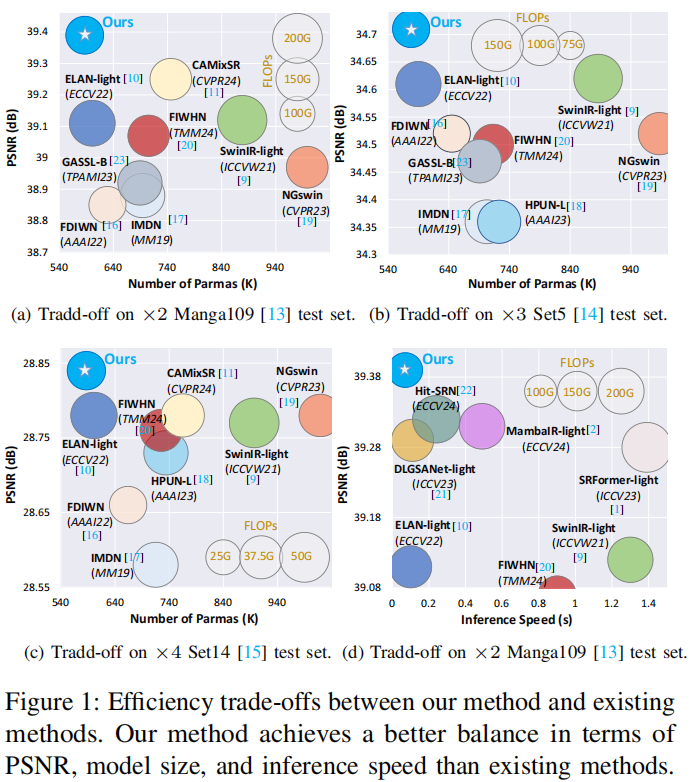
上图展示了本文模型在精度与效率的 Trade-off。DMNet 在保证极高 PSNR 的同时,大幅削减了 FLOPs。相比于基于 Mamba 架构的 MambaIR,DMNet 节省了超过 50% 的计算量,推理速度提升了数倍。这证明了找对物理特征域比单纯堆叠复杂算子更高效。
二、 核心架构与源码深度剖析
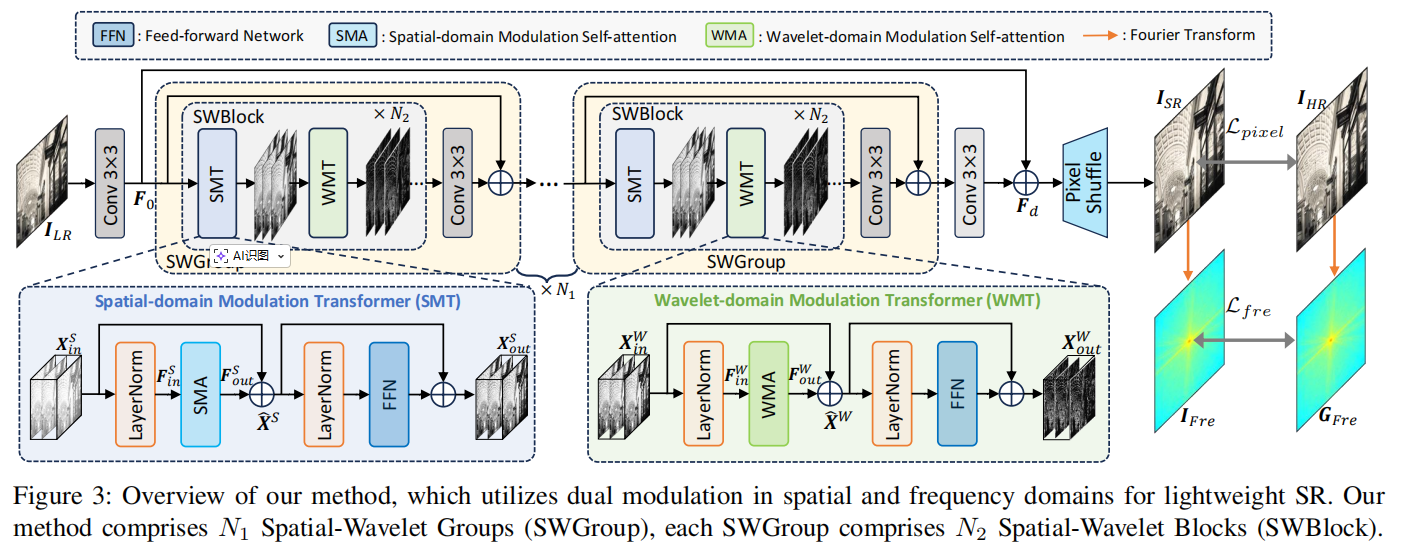
DMNet 的整体网络结构(对应源码 dmnet_arch.py)非常清晰。它由一个浅层特征提取卷积、若干个 SWGroup(空间-小波组),以及一个上采样重建模块组成。
每个 SWGroup 内部,交替使用了两种核心的 Transformer 变体:SMA(空间域调制自注意力) 和 WMA(小波域调制自注意力)。
下面我把源码进行可插拔封装,方便大家结合论文图片深入理解这两个核心模块。
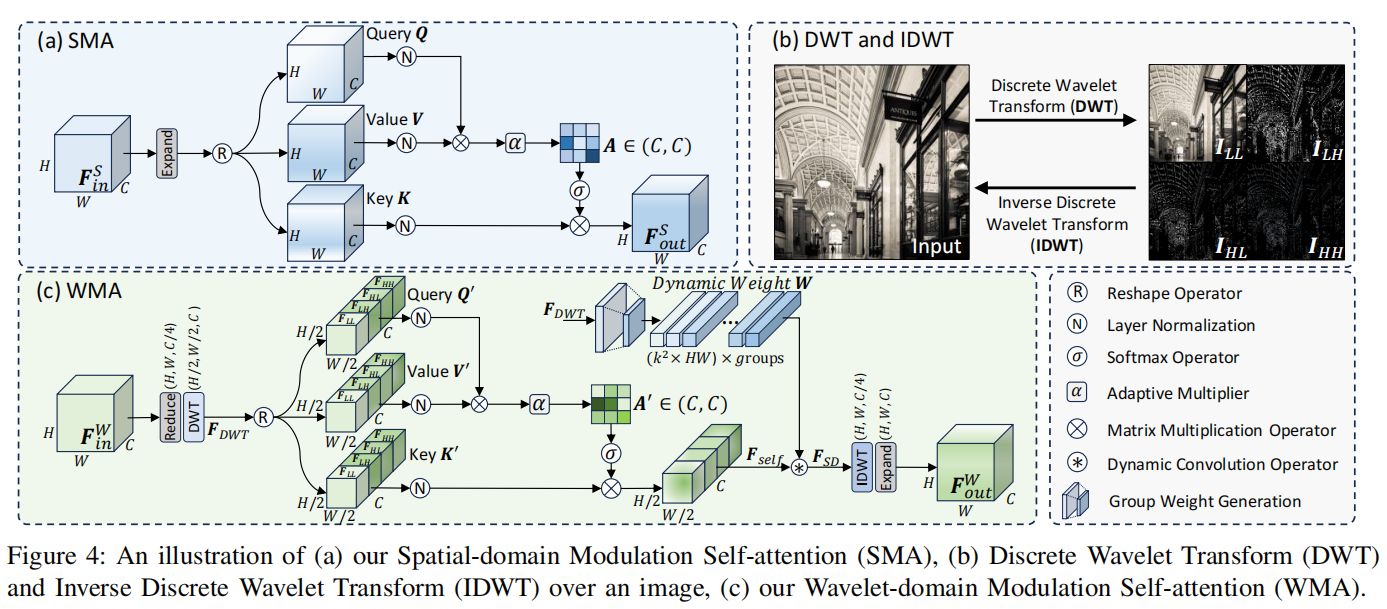
1. SMA (Spatial-domain Modulation Attention):轻量化空间交互
在轻量级网络中,如果在空间维度计算自注意力(复杂度为 O(H2W2)O(H^2 W^2)O(H2W2)),显存会直接溢出。SMA 的做法是:利用 1×11 \times 11×1 卷积聚合跨通道上下文,利用 3×33 \times 33×3 深度可分离卷积(DWConv)聚合局部空间上下文,并在通道维度上计算注意力。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SMA(nn.Module):
"""
空间域调制自注意力 (Spatial-domain Modulation Attention)
核心逻辑:在通道维度进行 Attention 计算,复杂度降为 O(C^2 * HW)
"""
def __init__(self, dim):
super(SMA, self).__init__()
# 生成 Q, K, V
# 1x1 卷积处理通道交互,3x3 DWConv 处理局部空间交互
self.qkv = nn.Sequential(
nn.Conv2d(dim, dim * 3, kernel_size=1, bias=False),
nn.Conv2d(dim * 3, dim * 3, kernel_size=3, padding=1, groups=dim * 3, bias=False)
)
self.proj = nn.Conv2d(dim, dim, kernel_size=1, bias=False)
# 可学习的温度系数,用于调节 Softmax 分布
self.temperature = nn.Parameter(torch.ones(1, 1, 1))
def forward(self, x):
B, C, H, W = x.shape
# 获取Q, K, V
qkv = self.qkv(x)
q, k, v = qkv.chunk(3, dim=1) # [B, C, H, W]
# 展平空间维度:[B, C, H, W] -> [B, C, H*W]
q = q.view(B, C, -1)
k = k.view(B, C, -1)
v = v.view(B, C, -1)
# L2 归一化,使得内积等于余弦相似度
q = F.normalize(q, dim=-1)
k = F.normalize(k, dim=-1)
# 在通道维度计算注意力矩阵:[B, C, C]
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
# 将注意力权重施加到 V 上
out = (attn @ v).view(B, C, H, W)
return self.proj(out)2. WMA (Wavelet-domain Modulation Attention):频域解耦与动态增强
WMA 是本文最大的创新点。它的核心流程是:通过离散小波变换(DWT)将特征图拆分为低频和高频子带 →\rightarrow→ 在频带特征间计算注意力 →\rightarrow→ 通过动态卷积(Dynamic Conv)进行局部特征增强 →\rightarrow→ 逆小波变换(IDWT)还原。
注:为了让代码完全脱离第三方库依赖(如 pytorch_wavelets),这里提供基于 Haar 小波的纯 PyTorch 原生实现。
可插拔模块源码:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# pip install pytorch_wavelets
from pytorch_wavelets import DWTForward, DWTInverse
class WMA_Optimized(nn.Module):
"""
小波域调制自注意力 (Wavelet-domain Modulation Attention)
"""
def __init__(self, dim):
super(WMA_Optimized, self).__init__()
# 1. 前置降维:保证 DWT 后四个频带拼接起来的通道数恰好等于 dim
self.reduce = nn.Conv2d(dim, dim // 4, kernel_size=1, bias=False)
# 2. 实例化小波算子 (J=1: 单级分解, mode='zero': 零填充边界, wave='haar': Haar小波基)
self.dwt = DWTForward(J=1, mode='zero', wave='haar')
self.idwt = DWTInverse(mode='zero', wave='haar')
# 3. 频域内的 Q, K, V 投影网络
self.qkv = nn.Sequential(
nn.Conv2d(dim, dim * 3, kernel_size=1, bias=False),
nn.Conv2d(dim * 3, dim * 3, kernel_size=3, padding=1, groups=dim * 3, bias=False)
)
# 4. 动态调制权重生成分支
self.dynamic_weight = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(dim, dim, kernel_size=1, bias=False),
nn.Sigmoid()
)
# 5. 后置升维:恢复特征尺寸
self.expand = nn.Conv2d(dim // 4, dim, kernel_size=1, bias=False)
self.temperature = nn.Parameter(torch.ones(1, 1, 1))
def forward(self, x):
B, C, H, W = x.shape
# --- 第一阶段:小波频域解耦 ---
x_red = self.reduce(x) # [B, C/4, H, W]
# DWT 输出解析:
# yl: 低频分量 (LL), 形状为 [B, C/4, H/2, W/2]
# yh: 高频分量列表,单级分解(J=1)时 yh[0] 形状为 [B, C/4, 3, H/2, W/2]
# 其中的 3 代表 LH(水平), HL(垂直), HH(对角线) 三个高频方向
yl, yh = self.dwt(x_red)
# 拆包提取高频,并在通道维度上与低频拼接,重组为计算 Attention 所需的统一张量
high_freqs = yh[0]
x_dwt = torch.cat([
yl, # LL: [B, C/4, H/2, W/2]
high_freqs[:, :, 0, :, :], # LH: [B, C/4, H/2, W/2]
high_freqs[:, :, 1, :, :], # HL: [B, C/4, H/2, W/2]
high_freqs[:, :, 2, :, :] # HH: [B, C/4, H/2, W/2]
], dim=1) # 拼接后总形状: [B, C, H/2, W/2]
# --- 第二阶段:跨频带自注意力计算 ---
qkv = self.qkv(x_dwt)
q, k, v = qkv.chunk(3, dim=1) # 各自形状: [B, C, H/2, W/2]
# 展平空间维度并进行 L2 归一化 (通道 Attention 范式)
q = F.normalize(q.view(B, C, -1), dim=-1)
k = F.normalize(k.view(B, C, -1), dim=-1)
v = v.view(B, C, -1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out_attn = (attn @ v).view(B, C, H//2, W//2)
# --- 第三阶段:动态调制 (Dynamic Modulation) ---
weight = self.dynamic_weight(x_dwt) # 获取自适应通道权重 [B, C, 1, 1]
out_dyn = out_attn * weight # 逐通道调制频域特征 [B, C, H/2, W/2]
# --- 第四阶段:逆小波变换还原 ---
# 关键工程细节:需要将 [B, C, H/2, W/2] 的张量重新"打包"回 IDWT 能够识别的元组格式
sub_c = C // 4
# 1. 剥离出低频 yl
yl_out = out_dyn[:, :sub_c, :, :]
# 2. 剥离出三个高频,利用 unsqueeze 恢复维度索引,再 cat 拼装成 yh[0] 格式
yh_out_LH = out_dyn[:, sub_c : 2*sub_c, :, :].unsqueeze(2)
yh_out_HL = out_dyn[:, 2*sub_c : 3*sub_c, :, :].unsqueeze(2)
yh_out_HH = out_dyn[:, 3*sub_c :, :, :].unsqueeze(2)
yh_out = [torch.cat([yh_out_LH, yh_out_HL, yh_out_HH], dim=2)] # [B, C/4, 3, H/2, W/2]
# 执行 IDWT 还原至空间域
out_idwt = self.idwt((yl_out, yh_out)) # 形状恢复为: [B, C/4, H, W]
# 扩张通道数并输出
return self.expand(out_idwt)3. 全局频域监管:傅里叶损失 (Fourier Loss)
在网络输出端,DMNet 并没有改变推理架构,而是在训练阶段引入了快速傅里叶变换(FFT)损失。模型对超分输出图像和高斯清晰图像分别进行 2D-FFT,获取各自的振幅(Amplitude)和相位(Phase) ,并计算两者之间的 L1 距离。这一步就像是一个"无形的手",在不增加任何推理计算量的前提下,强迫网络学习正确的全局结构,防止小波域"用力过猛"导致的局部失真。以下是完全还原论文公式 Lfre=∣∣ASR,PSR−AHR,PHR∣∣1\mathcal{L}_{fre} = ||A_{SR}, P_{SR} - A_{HR}, P_{HR}||_1Lfre=∣∣ASR,PSR−AHR,PHR∣∣1 的实现:
python
import torch
import torch.nn as nn
class FourierLoss(nn.Module):
"""
DMNet中的全局频域监管:傅里叶损失函数 (Fourier Loss)
在频域中分离振幅与相位,使用L1距离约束网络学习正确的全局结构分布。
"""
def __init__(self, loss_weight=0.1):
super(FourierLoss, self).__init__()
# 频域损失通常作为辅助损失,权重设为 0.1 左右(需结合实际任务调参)
self.loss_weight = loss_weight
self.criterion = nn.L1Loss()
def forward(self, sr, hr):
"""
sr: 网络输出的超分图像 (Super-Resolved), Shape: [B, C, H, W]
hr: 真实的高清图像 (High-Resolution Ground Truth), Shape: [B, C, H, W]
"""
# 1. 执行二维快速傅里叶变换 (2D FFT)
# norm='ortho' 表示使用正交归一化,防止变换前后能量发生剧烈缩放,有利于梯度稳定
fft_sr = torch.fft.fft2(sr, norm='ortho')
fft_hr = torch.fft.fft2(hr, norm='ortho')
# fft2 输出的是复数张量 (Complex Tensor: real + imag * j)
# 2. 提取振幅 (Amplitude)
# torch.abs 用于计算复数的模。
# 物理意义:振幅代表了图像中各个频率成分的"强度"(宏观的明暗对比和整体分布)。
amp_sr = torch.abs(fft_sr)
amp_hr = torch.abs(fft_hr)
# 3. 提取相位 (Phase)
# torch.angle 用于计算复数的幅角。
# 物理意义:相位决定了图像中不同正弦波的"位置",包含了图像最关键的轮廓、边缘和结构信息。
phase_sr = torch.angle(fft_sr)
phase_hr = torch.angle(fft_hr)
# 4. 特征拼接 (Concatenation)
# 将振幅和相位在通道维度 (dim=1) 拼接起来,形成混合频域特征
# 拼接后 Shape: [B, 2*C, H, W]
freq_sr = torch.cat([amp_sr, phase_sr], dim=1)
freq_hr = torch.cat([amp_hr, phase_hr], dim=1)
# 5. 计算频域的 L1 距离
loss = self.criterion(freq_sr, freq_hr)
return loss * self.loss_weight三、 评判性分析与优化建议
在轻量级 SR 赛道中,DMNet 的"小波提特征 + 傅里叶算损失"策略提供了一个优秀的范本。通过其论文中提供的**局部归因图(LAM)**可以看出,DMNet 激活的像素范围(红点分布)显著广于常规的轻量级网络,证明其有效感受野得到了极大扩展。

LAM 展示了模型在重建某一块局部区域时,利用了原图中多大范围的信息。DMNet 拥有更广的红点分布,说明双频域设计成功打破了纯空间卷积的局部性限制。
然而,从算法落地和架构演进的角度来看,DMNet 仍有以下可值得思考的地方:
1. 串行结构的效率
在当前的 SWGroup 中,空间模块(SMA)和频域模块(WMA)是严格串行执行的。虽然这有利于特征的深度提纯,但在硬件底层,空间和频域的计算原本是可以解耦并行的。如果"双分支并行计算 + 后期特征融合门控(Gating)"的结构是否可行?这样不仅能缩短前向传播的计算图长度,还能进一步降低推理延迟(Latency)。
2. 应对真实世界退化的鲁棒性
DMNet 的实验主要建立在理想的双三次插值降采样(Bicubic)数据集上。在真实的工业或医疗场景中,图像往往伴随复杂的传感器散斑噪声和运动模糊。小波变换对高频噪声非常敏感,容易将噪声误认为"边缘纹理"进行放大。如果在 WMA 模块前引入一个轻量级的"退化模式估计器",或者在小波的高频子带(HL, LH, HH)处理中加入自适应的软阈值去噪(Soft-thresholding)是否有用?
3. 极端低分辨率下的特征坍塌
由于 DWT 操作会在物理上将特征图的宽和高减半,如果输入的低分辨率图像已经非常小(例如 16×1616 \times 1616×16),经过 DWT 后特征图将变为 8×88 \times 88×8。在如此小的分辨率下,空间语义极度压缩,WMA 的频域自注意力可能无法捕捉到有效的纹理差异。如果对于极低分辨率任务,将离散小波变换替换为不改变空间分辨率的频域滤波器,或结合近期大热的可变形状态空间模型(Deformable Mamba)进行全尺寸的序列扫描是否可行?
小结
在算力受限的场景下,巧妙利用传统的数学工具(小波与傅里叶变换)对深度特征进行物理域的解耦,远比盲目堆叠 Transformer 层更加高效且优雅。DMNet为未来的边缘视觉模型设计提供了宝贵的参考。