文章目录
- 引言
- 设计说明
- 原理方案
- 源码解析
-
- 实体类
- [敏感词 CRUD 接口](#敏感词 CRUD 接口)
- 分类管理接口
- 在对话链路中的前置拦截
- [RAG 接口中的同样拦截](#RAG 接口中的同样拦截)
- 验证结果
- 优化方向
- 小结
- 引言
- 设计说明
- 原理方案
- 代码解析
-
- 实体类
- [敏感词 CRUD 接口](#敏感词 CRUD 接口)
- 分类管理接口
- 在对话链路中的前置拦截
- [RAG 接口中的同样拦截](#RAG 接口中的同样拦截)
- 验证结果
- 优化方向
- 小结
引言
把大模型接入生产业务,"内容安全"是一道绕不过去的关卡。无论是用户输入的违规词汇,还是大模型生成的不合规内容,都可能给业务带来合规风险。
敏感词过滤是最基础也是最有效的第一道防线。本篇将解析项目中敏感词过滤的设计思路、CRUD 实现、以及如何在对话链路中前置拦截。
设计说明
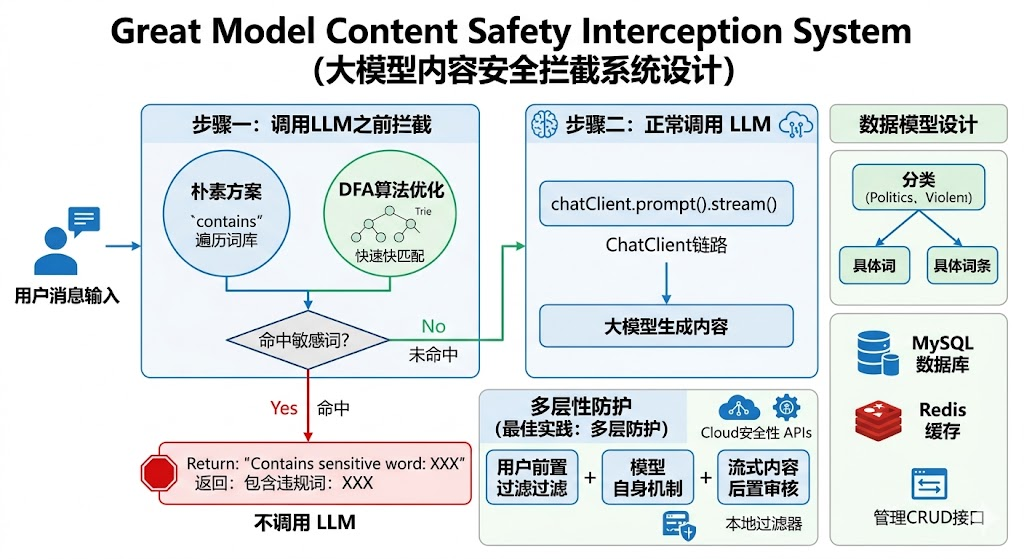
为什么要在前置环节拦截?
敏感词过滤可以放在三个位置:
| 位置 | 优势 | 劣势 |
|---|---|---|
| 调用 LLM 之前 | 节省 LLM 调用成本,响应快 | 需要维护词库,规则较死板 |
| LLM 输出过程中 | 可拦截大模型生成的违规内容 | 流式拦截复杂,已部分输出 |
| LLM 完成之后 | 实现简单,全文扫描 | 浪费 LLM 调用 |
最佳实践是多层防护:前置过滤用户输入 + 模型自身的内容安全机制 + 后置审核。本项目实现了第一道防线。
数据模型设计
敏感词系统采用经典的"分类 + 词条"两级结构:
Java
SensitiveCategory(分类)
├── 政治类
├── 暴力类
├── 涉黄类
└── 自定义类
│
├── SensitiveWord(具体词条)
├── SensitiveWord
└── SensitiveWord这种设计的好处:
- 分类便于管理和审计
- 可以按类别批量启用/禁用
- 不同类别可以走不同的处理策略(拦截 / 仅警告 / 替换)
原理方案
表结构
sql
-- 敏感词表
CREATE TABLE `sensitive_word` (
`id` INT NOT NULL AUTO_INCREMENT,
`word` VARCHAR(255) COMMENT '敏感词内容',
`category` VARCHAR(255) COMMENT '敏感词类别',
`status` VARCHAR(50) COMMENT '敏感词状态',
`created_at` VARCHAR(50),
`updated_at` VARCHAR(50),
PRIMARY KEY (`id`)
);
-- 敏感词分类表
CREATE TABLE `sensitive_category` (
`id` INT NOT NULL AUTO_INCREMENT,
`category_name` VARCHAR(255) COMMENT '分类名',
`created_time` DATE,
`update_time` DATE,
`status` VARCHAR(50),
PRIMARY KEY (`id`)
);拦截流程
Java
用户消息
↓
查询所有敏感词(List<SensitiveWord>)
↓
遍历词库逐个 contains 检查
↓
命中 → 直接返回 Flux.just("包含敏感词:xxx")
↓
未命中 → 继续走 ChatClient 链路这种朴素的实现方式适合中小规模词库(千级以内)。如果词库膨胀到万级以上,就需要考虑性能优化。
源码解析
实体类
java
@TableName(value = "sensitive_word")
@Data
public class SensitiveWord {
@TableId
private Integer id;
private String word; // 敏感词内容
private String category; // 类别
private String status; // 状态
private String createdAt;
private String updatedAt;
}
java
@TableName(value = "sensitive_category")
@Data
public class SensitiveCategory {
@TableId
private Integer id;
private String categoryName;
private LocalDate createdTime;
private LocalDate updateTime;
private String status;
}敏感词 CRUD 接口
java
@Tag(name = "SensitiveWordController", description = "敏感词控制器")
@Slf4j
@RestController
@RequestMapping(ApplicationConstant.API_VERSION + "/sensitive")
public class SensitiveWordController {
@Autowired
private SensitiveWordService sensitiveWordService;
@Operation(summary = "新增敏感词")
@PostMapping("/add")
public BaseResponse addSensitiveWord(@RequestBody SensitiveWord sensitiveWord) {
sensitiveWord.setStatus("1");
sensitiveWord.setCreatedAt(LocalDate.now().toString());
sensitiveWord.setUpdatedAt(LocalDate.now().toString());
boolean save = sensitiveWordService.save(sensitiveWord);
return save ? ResultUtils.success(true) : ResultUtils.error("新增失败");
}
@Operation(summary = "删除敏感词")
@DeleteMapping("/{id}")
public boolean deleteSensitiveWord(@PathVariable Integer id) {
return sensitiveWordService.removeById(id);
}
@Operation(summary = "批量删除敏感词")
@PostMapping("/batch")
public BaseResponse deleteSensitiveWords(@RequestBody List<Integer> ids) {
boolean b = sensitiveWordService.removeByIds(ids);
return b ? ResultUtils.success("删除成功") : ResultUtils.error("删除失败");
}
@Operation(summary = "更新敏感词")
@PutMapping
public boolean updateSensitiveWord(@RequestBody SensitiveWord sensitiveWord) {
return sensitiveWordService.updateById(sensitiveWord);
}
@Operation(summary = "分页查询敏感词")
@GetMapping("/page")
public BaseResponse<IPage<SensitiveWord>> getSensitiveWordPage(
@RequestParam int page, @RequestParam int size) {
Page<SensitiveWord> pageParam = new Page<>(page, size);
Page<SensitiveWord> page1 = sensitiveWordService.page(pageParam);
page1.setTotal(page1.getRecords().size());
return ResultUtils.success(page1);
}
@Operation(summary = "查询所有敏感词")
@GetMapping
public List<SensitiveWord> getAllSensitiveWords() {
return sensitiveWordService.list();
}
}基于 MyBatis-Plus 的 IService,CRUD 都是一行代码搞定。
分类管理接口
java
@Tag(name = "SensitiveCategoryController", description = "敏感词分类控制器")
@RestController
@RequestMapping(ApplicationConstant.API_VERSION + "/category")
public class SensitiveCategoryController {
@Autowired
private SensitiveCategoryService sensitiveCategoryService;
@Operation(summary = "新增敏感词分类")
@PostMapping("/add")
public BaseResponse<Boolean> create(@RequestBody SensitiveCategory entity) {
entity.setCreatedTime(LocalDate.now());
entity.setUpdateTime(LocalDate.now());
entity.setStatus("1");
return ResultUtils.success(sensitiveCategoryService.save(entity));
}
// 批量删除、修改、分页查询、列表查询...
}在对话链路中的前置拦截
这是核心拦截逻辑,出现在多个 Controller 中:
java
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamRagChat(@RequestParam String message, @RequestParam String prompt) {
// 敏感词前置拦截
List<SensitiveWord> list = sensitiveWordService.list();
for (SensitiveWord sensitiveWord : list) {
if (message.contains(sensitiveWord.getWord())) {
return Flux.just("包含敏感词:" + sensitiveWord.getWord());
}
}
// 通过敏感词检查后,正常调用 LLM
Long userId = BaseContext.getCurrentId();
return chatClient.prompt()
.system(prompt)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId))
.user(message)
.stream()
.content();
}关键点:
- 直接返回 Flux :命中敏感词时,用
Flux.just(...)构造一个只发送一条消息就完成的 Flux,前端依然能正常解析 SSE - 不调用 LLM:完全避开了昂贵的大模型调用,节省成本和响应时间
- 明确反馈:返回内容包含具体命中的敏感词,便于用户知晓原因
RAG 接口中的同样拦截
java
@PostMapping(value = "/rag")
@Loggable
public Flux<String> generatePost(
@RequestParam(value = "sources", required = false) List<String> sources,
@RequestParam String message) throws IOException {
// 敏感词过滤
List<SensitiveWord> list = sensitiveWordService.list();
for (SensitiveWord sensitiveWord : list) {
if (message.contains(sensitiveWord.getWord())) {
return Flux.just("包含敏感词:" + sensitiveWord.getWord());
}
}
return processNormalRagQuery(sources, message);
}每个对话入口都需要重复这段拦截代码。如果有多个入口,可以抽取成切面或公共方法。
验证结果
新增敏感词
请求:
POST /api/v1/sensitive/add
Content-Type: application/json
{
"word": "测试敏感词",
"category": "测试类"
}响应:
json
{ "code": 0, "data": true }命中拦截测试
请求:
GET /api/v1/chat/stream?message=这是一段包含测试敏感词的内容响应:
data: 包含敏感词:测试敏感词请求未到达 LLM,响应延迟在毫秒级。
未命中正常对话
请求:
GET /api/v1/chat/stream?message=你好响应:
data: 你好
data: !很高兴
data: 为您
data: 服务...优化方向
性能优化:DFA 算法
每次对话都遍历整个词库做 contains 检查,时间复杂度是 O(N×M)(N 是词库大小,M 是消息长度)。词库膨胀后会成为瓶颈。
业界标准方案是 DFA(Deterministic Finite Automaton)算法:
java
// 启动时构建 DFA 树
Map<Object, Object> sensitiveWordTree = buildDFATree(sensitiveWords);
// 检查时只遍历一次输入字符串,时间复杂度 O(M)
public boolean contains(String text) {
for (int i = 0; i < text.length(); i++) {
if (matchAtPosition(text, i)) return true;
}
return false;
}或者使用成熟的开源库,比如 ToolGood.Words 的 Java 移植版、sensitive-word(开源词库)等。
缓存优化
每次查询都从数据库 list 出全部敏感词,没有必要。可以加 Redis 缓存:
java
@Cacheable(value = "sensitiveWords", unless = "#result == null")
public List<SensitiveWord> listAll() {
return sensitiveWordService.list();
}
// CRUD 时清除缓存
@CacheEvict(value = "sensitiveWords", allEntries = true)
public boolean save(SensitiveWord word) {
return sensitiveWordService.save(word);
}状态字段的应用
实体里有 status 字段,目前没有用上。可以扩展为:
java
List<SensitiveWord> list = sensitiveWordService.list(
new LambdaQueryWrapper<SensitiveWord>().eq(SensitiveWord::getStatus, "1")
);只查询启用状态的词,便于运维灰度上下线。
命中策略多样化
目前命中后直接拦截。可以根据 category 走不同策略:
java
switch (category) {
case "禁止":
return Flux.just("包含敏感词,已拦截");
case "替换":
message = message.replace(word.getWord(), "***");
break;
case "警告":
log.warn("用户 {} 输入了敏感词 {}", userId, word.getWord());
// 继续放行
break;
}输出端过滤
前置过滤无法拦截大模型自身生成的违规内容。可以在 Flux 流上加一层过滤:
java
return chatClient.prompt()
.user(message)
.stream()
.content()
.map(chunk -> sensitiveWordFilter.replace(chunk)); // 流式替换或者使用阿里云、腾讯云的内容安全服务做 API 兜底审核。
切面化重构
把"敏感词过滤 + 拦截"逻辑抽到 AOP 切面,避免每个 Controller 重复:
java
@Aspect
@Component
public class SensitiveWordAspect {
@Around("@annotation(SensitiveCheck)")
public Object check(ProceedingJoinPoint pjp) {
// 提取参数中的 message
// 检查敏感词
// 命中则返回 Flux.just(...)
}
}小结
本篇梳理了敏感词过滤的设计与实现:
- 数据模型采用"分类+词条"两级结构,便于管理
- 在对话入口前置拦截,节省 LLM 成本
- CRUD 接口基于 MyBatis-Plus,开发成本极低
- 进阶优化:DFA 算法、缓存、多策略、流式过滤
引言
把大模型接入生产业务,"内容安全"是一道绕不过去的关卡。无论是用户输入的违规词汇,还是大模型生成的不合规内容,都可能给业务带来合规风险。
敏感词过滤是最基础也是最有效的第一道防线。本篇将解析项目中敏感词过滤的设计思路、CRUD 实现、以及如何在对话链路中前置拦截。
设计说明
为什么要在前置环节拦截?
敏感词过滤可以放在三个位置:
| 位置 | 优势 | 劣势 |
|---|---|---|
| 调用 LLM 之前 | 节省 LLM 调用成本,响应快 | 需要维护词库,规则较死板 |
| LLM 输出过程中 | 可拦截大模型生成的违规内容 | 流式拦截复杂,已部分输出 |
| LLM 完成之后 | 实现简单,全文扫描 | 浪费 LLM 调用 |
最佳实践是多层防护:前置过滤用户输入 + 模型自身的内容安全机制 + 后置审核。本项目实现了第一道防线。
数据模型设计
敏感词系统采用经典的"分类 + 词条"两级结构:
java
SensitiveCategory(分类)
├── 政治类
├── 暴力类
├── 涉黄类
└── 自定义类
│
├── SensitiveWord(具体词条)
├── SensitiveWord
└── SensitiveWord这种设计的好处:
- 分类便于管理和审计
- 可以按类别批量启用/禁用
- 不同类别可以走不同的处理策略(拦截 / 仅警告 / 替换)
原理方案
表结构
sql
-- 敏感词表
CREATE TABLE `sensitive_word` (
`id` INT NOT NULL AUTO_INCREMENT,
`word` VARCHAR(255) COMMENT '敏感词内容',
`category` VARCHAR(255) COMMENT '敏感词类别',
`status` VARCHAR(50) COMMENT '敏感词状态',
`created_at` VARCHAR(50),
`updated_at` VARCHAR(50),
PRIMARY KEY (`id`)
);
-- 敏感词分类表
CREATE TABLE `sensitive_category` (
`id` INT NOT NULL AUTO_INCREMENT,
`category_name` VARCHAR(255) COMMENT '分类名',
`created_time` DATE,
`update_time` DATE,
`status` VARCHAR(50),
PRIMARY KEY (`id`)
);拦截流程
java
用户消息
↓
查询所有敏感词(List<SensitiveWord>)
↓
遍历词库逐个 contains 检查
↓
命中 → 直接返回 Flux.just("包含敏感词:xxx")
↓
未命中 → 继续走 ChatClient 链路这种朴素的实现方式适合中小规模词库(千级以内)。如果词库膨胀到万级以上,就需要考虑性能优化。
代码解析
实体类
java
@TableName(value = "sensitive_word")
@Data
public class SensitiveWord {
@TableId
private Integer id;
private String word; // 敏感词内容
private String category; // 类别
private String status; // 状态
private String createdAt;
private String updatedAt;
}
java
@TableName(value = "sensitive_category")
@Data
public class SensitiveCategory {
@TableId
private Integer id;
private String categoryName;
private LocalDate createdTime;
private LocalDate updateTime;
private String status;
}敏感词 CRUD 接口
java
@Tag(name = "SensitiveWordController", description = "敏感词控制器")
@Slf4j
@RestController
@RequestMapping(ApplicationConstant.API_VERSION + "/sensitive")
public class SensitiveWordController {
@Autowired
private SensitiveWordService sensitiveWordService;
@Operation(summary = "新增敏感词")
@PostMapping("/add")
public BaseResponse addSensitiveWord(@RequestBody SensitiveWord sensitiveWord) {
sensitiveWord.setStatus("1");
sensitiveWord.setCreatedAt(LocalDate.now().toString());
sensitiveWord.setUpdatedAt(LocalDate.now().toString());
boolean save = sensitiveWordService.save(sensitiveWord);
return save ? ResultUtils.success(true) : ResultUtils.error("新增失败");
}
@Operation(summary = "删除敏感词")
@DeleteMapping("/{id}")
public boolean deleteSensitiveWord(@PathVariable Integer id) {
return sensitiveWordService.removeById(id);
}
@Operation(summary = "批量删除敏感词")
@PostMapping("/batch")
public BaseResponse deleteSensitiveWords(@RequestBody List<Integer> ids) {
boolean b = sensitiveWordService.removeByIds(ids);
return b ? ResultUtils.success("删除成功") : ResultUtils.error("删除失败");
}
@Operation(summary = "更新敏感词")
@PutMapping
public boolean updateSensitiveWord(@RequestBody SensitiveWord sensitiveWord) {
return sensitiveWordService.updateById(sensitiveWord);
}
@Operation(summary = "分页查询敏感词")
@GetMapping("/page")
public BaseResponse<IPage<SensitiveWord>> getSensitiveWordPage(
@RequestParam int page, @RequestParam int size) {
Page<SensitiveWord> pageParam = new Page<>(page, size);
Page<SensitiveWord> page1 = sensitiveWordService.page(pageParam);
page1.setTotal(page1.getRecords().size());
return ResultUtils.success(page1);
}
@Operation(summary = "查询所有敏感词")
@GetMapping
public List<SensitiveWord> getAllSensitiveWords() {
return sensitiveWordService.list();
}
}基于 MyBatis-Plus 的 IService,CRUD 都是一行代码搞定。
分类管理接口
java
@Tag(name = "SensitiveCategoryController", description = "敏感词分类控制器")
@RestController
@RequestMapping(ApplicationConstant.API_VERSION + "/category")
public class SensitiveCategoryController {
@Autowired
private SensitiveCategoryService sensitiveCategoryService;
@Operation(summary = "新增敏感词分类")
@PostMapping("/add")
public BaseResponse<Boolean> create(@RequestBody SensitiveCategory entity) {
entity.setCreatedTime(LocalDate.now());
entity.setUpdateTime(LocalDate.now());
entity.setStatus("1");
return ResultUtils.success(sensitiveCategoryService.save(entity));
}
// 批量删除、修改、分页查询、列表查询...
}在对话链路中的前置拦截
这是核心拦截逻辑,出现在多个 Controller 中:
java
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamRagChat(@RequestParam String message, @RequestParam String prompt) {
// 敏感词前置拦截
List<SensitiveWord> list = sensitiveWordService.list();
for (SensitiveWord sensitiveWord : list) {
if (message.contains(sensitiveWord.getWord())) {
return Flux.just("包含敏感词:" + sensitiveWord.getWord());
}
}
// 通过敏感词检查后,正常调用 LLM
Long userId = BaseContext.getCurrentId();
return chatClient.prompt()
.system(prompt)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId))
.user(message)
.stream()
.content();
}关键点:
- 直接返回 Flux :命中敏感词时,用
Flux.just(...)构造一个只发送一条消息就完成的 Flux,前端依然能正常解析 SSE - 不调用 LLM:完全避开了昂贵的大模型调用,节省成本和响应时间
- 明确反馈:返回内容包含具体命中的敏感词,便于用户知晓原因
RAG 接口中的同样拦截
java
@PostMapping(value = "/rag")
@Loggable
public Flux<String> generatePost(
@RequestParam(value = "sources", required = false) List<String> sources,
@RequestParam String message) throws IOException {
// 敏感词过滤
List<SensitiveWord> list = sensitiveWordService.list();
for (SensitiveWord sensitiveWord : list) {
if (message.contains(sensitiveWord.getWord())) {
return Flux.just("包含敏感词:" + sensitiveWord.getWord());
}
}
return processNormalRagQuery(sources, message);
}每个对话入口都需要重复这段拦截代码。如果有多个入口,可以抽取成切面或公共方法。
验证结果
新增敏感词
请求:
java
POST /api/v1/sensitive/add
Content-Type: application/json
{
"word": "测试敏感词",
"category": "测试类"
}响应:
json
{ "code": 0, "data": true }命中拦截测试
请求:
java
GET /api/v1/chat/stream?message=这是一段包含测试敏感词的内容响应:
Java
data: 包含敏感词:测试敏感词请求未到达 LLM,响应延迟在毫秒级。
未命中正常对话
请求:
Java
GET /api/v1/chat/stream?message=你好响应:
java
data: 你好
data: !很高兴
data: 为您
data: 服务...优化方向
性能优化:DFA 算法
每次对话都遍历整个词库做 contains 检查,时间复杂度是 O(N×M)(N 是词库大小,M 是消息长度)。词库膨胀后会成为瓶颈。
业界标准方案是 DFA(Deterministic Finite Automaton)算法:
java
// 启动时构建 DFA 树
Map<Object, Object> sensitiveWordTree = buildDFATree(sensitiveWords);
// 检查时只遍历一次输入字符串,时间复杂度 O(M)
public boolean contains(String text) {
for (int i = 0; i < text.length(); i++) {
if (matchAtPosition(text, i)) return true;
}
return false;
}或者使用成熟的开源库,比如 ToolGood.Words 的 Java 移植版、sensitive-word(开源词库)等。
缓存优化
每次查询都从数据库 list 出全部敏感词,没有必要。可以加 Redis 缓存:
java
@Cacheable(value = "sensitiveWords", unless = "#result == null")
public List<SensitiveWord> listAll() {
return sensitiveWordService.list();
}
// CRUD 时清除缓存
@CacheEvict(value = "sensitiveWords", allEntries = true)
public boolean save(SensitiveWord word) {
return sensitiveWordService.save(word);
}状态字段的应用
实体里有 status 字段,目前没有用上。可以扩展为:
java
List<SensitiveWord> list = sensitiveWordService.list(
new LambdaQueryWrapper<SensitiveWord>().eq(SensitiveWord::getStatus, "1")
);只查询启用状态的词,便于运维灰度上下线。
命中策略多样化
目前命中后直接拦截。可以根据 category 走不同策略:
java
switch (category) {
case "禁止":
return Flux.just("包含敏感词,已拦截");
case "替换":
message = message.replace(word.getWord(), "***");
break;
case "警告":
log.warn("用户 {} 输入了敏感词 {}", userId, word.getWord());
// 继续放行
break;
}输出端过滤
前置过滤无法拦截大模型自身生成的违规内容。可以在 Flux 流上加一层过滤:
java
return chatClient.prompt()
.user(message)
.stream()
.content()
.map(chunk -> sensitiveWordFilter.replace(chunk)); // 流式替换或者使用阿里云、腾讯云的内容安全服务做 API 兜底审核。
切面化重构
把"敏感词过滤 + 拦截"逻辑抽到 AOP 切面,避免每个 Controller 重复:
java
@Aspect
@Component
public class SensitiveWordAspect {
@Around("@annotation(SensitiveCheck)")
public Object check(ProceedingJoinPoint pjp) {
// 提取参数中的 message
// 检查敏感词
// 命中则返回 Flux.just(...)
}
}小结
本篇梳理了敏感词过滤的设计与实现:
- 数据模型采用"分类+词条"两级结构,便于管理
- 在对话入口前置拦截,节省 LLM 成本
- CRUD 接口基于 MyBatis-Plus,开发成本极低
- 进阶优化:DFA 算法、缓存、多策略、流式过滤
下一篇将解析 AOP 日志记录与基于日志的热词统计------一个有趣的副产品功能。
