一、MySQL 查询执行的六大核心阶段
1. 连接建立与认证(Connection & Authentication)
- 客户端通过 TCP/IP 或 Unix Socket 发起连接。
- MySQL Server 的 Connection Manager 接收请求,分配线程(或从线程池复用)。
- 执行用户身份验证(校验用户名、密码、主机白名单),加载权限信息。
- 若启用了 SSL/TLS,则在此阶段完成加密握手。
注意:自 MySQL 8.0 起,Query Cache 已被彻底移除,因此不再参与后续流程。
2. 查询解析(Parsing)
- SQL 文本被送入 Parser(语法分析器)。
- 使用 LALR(1) 语法分析器(基于 yacc/bison)进行词法与语法分析。
- 输出一棵 解析树(Parse Tree),表示 SQL 的结构化形式。
- 此阶段会检查基本语法错误(如关键字拼写、括号不匹配等)。
示例:
sql
SELECT id, name FROM users WHERE age > 25;→ 被解析为包含 SELECT_LIST、FROM_CLAUSE、WHERE_CLAUSE 的抽象语法树。
3. 预处理(Preprocessing / Resolution)
- Resolver 模块介入,对解析树进行语义分析:
- 验证表、列是否存在;
- 检查用户是否有对应对象的访问权限;
- 解析视图(若涉及)并展开;
- 确定字段所属的数据库/表(处理歧义);
- 类型推导与隐式转换判断。
- 此阶段生成 Resolved Parse Tree,为优化器提供准确元数据。
4. 查询优化(Optimization)
这是整个流程中最复杂的环节,由 Query Optimizer 主导:
关键子步骤包括:
- 常量传播与折叠 :如
WHERE id = 1 + 2→WHERE id = 3 - 谓词下推:将过滤条件下推至存储引擎层
- 索引选择:基于统计信息(cardinality、直方图等)评估可用索引
- 连接顺序重排:对多表 JOIN 使用动态规划或贪心算法确定最优顺序
- 访问路径选择:决定使用 index scan、range scan、full table scan 等
- 成本模型计算:基于 I/O、CPU、内存等估算执行成本(单位:"cost units")
最终输出 执行计划(Execution Plan) ,以 Query Plan Tree 形式表示。
MySQL 8.0 引入了 直方图(Histograms) 和 不可见索引(Invisible Indexes),显著提升了优化器决策精度。
5. 执行引擎处理(Execution)
- Executor 模块根据执行计划调用 Handler API 与存储引擎交互。
- 对于 InnoDB(默认引擎):
- 通过 Buffer Pool 缓存数据页;
- 执行 B+ 树查找、范围扫描或全表扫描;
- 应用 MVCC 机制读取符合事务隔离级别的可见版本;
- 若存在排序(ORDER BY)或分组(GROUP BY),可能触发 临时表(Temp Table) 或 文件排序(Filesort)。
- 结果集逐行构建,流式返回(非一次性加载全部数据)。
6. 结果返回(Result Sending)
- Executor 将结果通过网络协议(MySQL Protocol)封装;
- 由连接线程发送回客户端;
- 客户端驱动(如 JDBC、mysql-connector-python)解析二进制/文本协议,还原为应用可读格式。
二、执行流程图
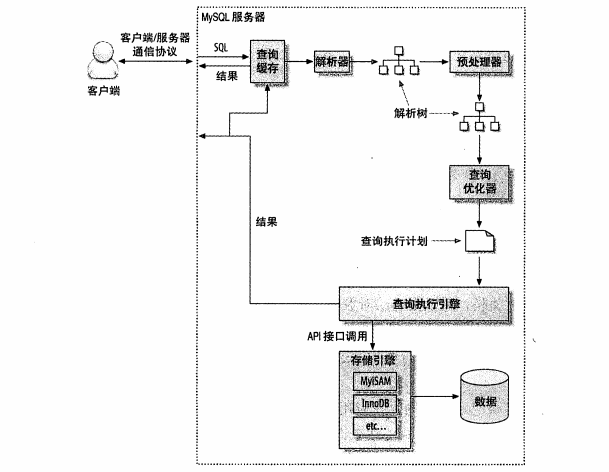
注意:自 MySQL 8.0 起,Query Cache 已被彻底移除,所以在MySQL8.0没有这个流程。
[客户端]
↓(通过 TCP 或 Unix Socket 建立连接)
[连接管理器] → [用户身份认证]
↓
[接收 SQL 查询语句]
↓
[解析器] →(语法检查)→ [生成解析树]
↓
[预处理器] →(解析表名、列名及权限校验)→ [生成已解析树]
↓
[查询优化器] →(基于成本的优化)→ [生成执行计划]
↓
[执行器] ↔ [Handler 接口] ↔ [存储引擎(例如 InnoDB)]
↓
[构建结果集]
↓
[网络协议层] → [将结果返回给客户端]各阶段简要说明:
- 连接管理器:负责建立连接、分配线程、验证用户凭证。
- 解析器:检查 SQL 语法是否合法,构建抽象语法树。
- 预处理器:进行语义分析,确认对象存在性与访问权限。
- 查询优化器:决定最优执行路径(如索引选择、JOIN 顺序)。
- 执行器 + 存储引擎:实际读取数据、应用过滤、聚合等操作。
- 网络协议层:将最终结果按 MySQL 协议封装并发送回客户端。
三、各阶段关键组件对比表
| 阶段 | 核心组件 | 输入 | 输出 | 涉及模块 |
|---|---|---|---|---|
| 连接建立 | Connection Manager | 网络连接请求 | 认证后的会话线程 | auth, thread pool |
| 解析 | Parser | SQL 字符串 | Parse Tree | sql/parser_yystype.h |
| 预处理 | Resolver | Parse Tree | Resolved Tree | sql/item.cc, sql/table.cc |
| 优化 | Optimizer | Resolved Tree | Execution Plan | sql/optimize.cc, sql/sql_planner.cc |
| 执行 | Executor + Handler | Execution Plan | 行数据流 | sql/executor/, storage/innodb/ |
| 返回 | Protocol Layer | 行数据 | 网络数据包 | sql/protocol_classic.cc |
注:Query Cache 在 MySQL 8.0 中已移除。
非常好的建议!在技术博客中加入对 SQL 逻辑执行顺序(Logical Query Processing Order)的解析,能极大提升读者对查询语句本质的理解------尤其当他们混淆"书写顺序"与"实际执行顺序"时。下面我将为你补充这一关键内容,并无缝整合进原博客结构。
四、SQL 逻辑执行顺序 vs. 书写顺序
尽管我们在编写 SQL 时通常按以下语法顺序书写:
sql
SELECT
column_list
FROM table_name
WHERE condition
GROUP BY group_expression
HAVING having_condition
ORDER BY sort_expression
LIMIT row_count;但 MySQL(以及所有符合 SQL 标准的数据库)在逻辑上并非按此顺序执行。
MySQL 中 SELECT 查询的逻辑执行顺序如下:
| 步骤 | 子句 | 说明 |
|---|---|---|
| 1 | FROM |
确定数据源(表、视图、JOIN 结果),生成初始虚拟表 VT1 |
| 2 | WHERE |
对 VT1 应用行级过滤,生成 VT2 |
| 3 | GROUP BY |
将 VT2 按分组表达式聚合,生成 VT3(每组一行) |
| 4 | HAVING |
对 VT3 的分组结果进行过滤,生成 VT4 |
| 5 | SELECT |
计算选择列表(包括表达式、别名、聚合函数),生成 VT5 |
| 6 | ORDER BY |
对 VT5 排序,生成有序结果 VT6 |
| 7 | LIMIT / OFFSET |
截取指定行数,生成最终结果 |
注意:这是逻辑顺序 ,不代表物理执行路径。优化器可能重排操作以提升性能(如谓词下推),但必须保证结果等价性。
示例分析
考虑以下完整查询:
sql
SELECT
department,
COUNT(*) AS employee_count,
AVG(salary) AS avg_salary
FROM employees
WHERE hire_date > '2020-01-01'
GROUP BY department
HAVING AVG(salary) > 80000
ORDER BY employee_count DESC
LIMIT 5;执行逻辑分解:
-
FROM employees
→ 读取
employees表(可能通过索引或全表扫描)。 -
WHERE hire_date > '2020-01-01'
→ 过滤出 2020 年后入职的员工(可在存储引擎层完成,若
hire_date有索引)。 -
GROUP BY department
→ 按部门分组,为每组计算中间聚合值(count、sum 等)。
-
HAVING AVG(salary) > 80000
→ 仅在此阶段才能使用聚合函数;过滤掉平均薪资 ≤8 万的部门。
-
SELECT ... AS ...
→ 构造输出列(注意:此时
employee_count和avg_salary才被定义,因此WHERE或GROUP BY中不能引用这些别名)。 -
ORDER BY employee_count DESC
→ 按聚合后的计数降序排列(可能触发 filesort)。
-
LIMIT 5
→ 返回前 5 行。
五、面试题
问题一:
MySQL 8.0 中,一条 SELECT 语句是否还会经过 Query Cache?
答 :不会。MySQL 自 8.0.3 版本起完全移除了 Query Cache 功能。官方认为其在高并发场景下反而成为性能瓶颈,且维护一致性开销大。因此,所有查询均直接进入解析阶段。
问题二:
优化器如何决定是否使用索引?你能举例说明吗?
答 :优化器基于成本模型(Cost Model) 决策,主要考虑:
- 索引的选择性(高选择性更优);
- 数据分布(通过直方图或索引统计);
- 是否覆盖查询(Covering Index 可避免回表);
- 排序/分组是否可利用索引有序性。
示例:
sql
SELECT name FROM users WHERE age > 30;若 (age, name) 是联合索引,则可走 Index Only Scan (无需回表),成本远低于全表扫描。但若 age > 30 匹配 90% 的行,优化器可能判定全表扫描更高效(因顺序 I/O 比随机 I/O 快)。
**问题三:
为什么不能在 WHERE 子句中使用聚合函数(如 COUNT、SUM),但可以在 HAVING 中使用?这和查询执行流程有什么关系?**
答 :这是因为 SQL 的逻辑执行顺序 决定的。WHERE 在 GROUP BY 之前执行,此时数据尚未分组,也未计算聚合值,因此无法引用聚合函数。而 HAVING 在 GROUP BY 之后执行,作用于已形成的分组结果集,此时聚合值已经生成,故可进行过滤。
从 MySQL 执行流程看:
WHERE条件由 Executor 在访问存储引擎前 应用(可能下推至 InnoDB);- 聚合计算(如
COUNT)发生在 Executor 的聚合阶段 ,位于GROUP BY处理之后; - 因此,优化器在解析阶段就会拒绝
WHERE COUNT(*) > 1这类语句,报错 "Invalid use of group function"。