关注它,不迷路。
- 本文章中所有内容仅供学习交流,不可用于任何商业用途和非法用途,否则后果自负,如有侵权,请联系作者立即删除!
一.题目地址
python
https://match.yuanrenxue.cn/match/7二.抓包分析
打开控制台后,抓包分析,看看所要的数据在哪里:
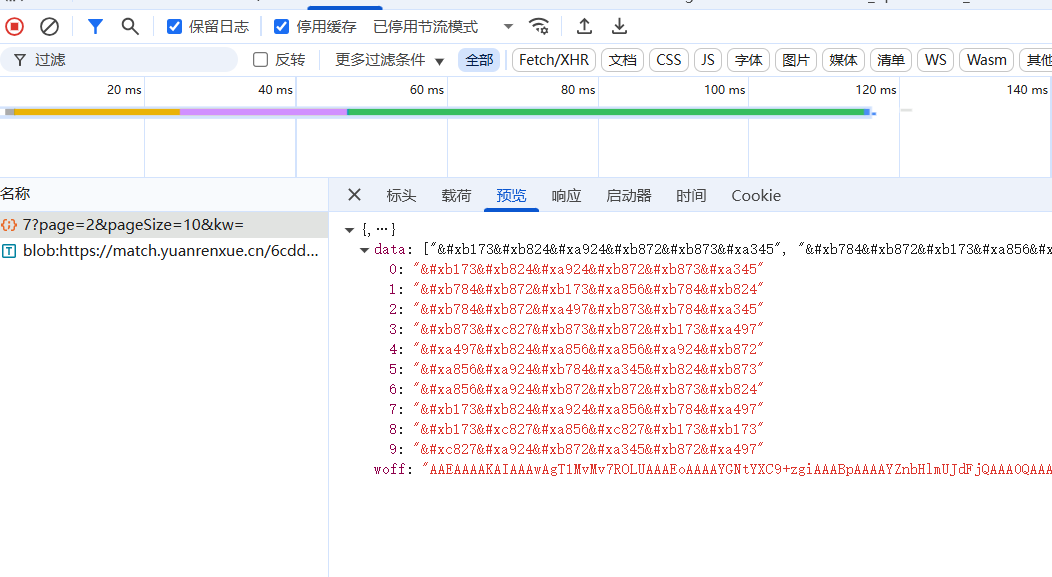
返回了一些data和woff数据,并且同时请求了 blob:https://match.yuanrenxue.cn/ 这个接口。返回的是:
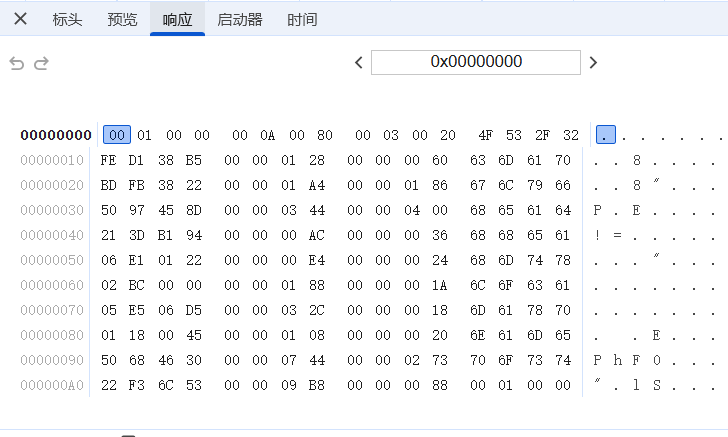
这种和js逆向相关的我就不深究了。具体思路可以参考下面这篇文章:
三.AI工具
我这里使用codeX的cli工具 + Gpt-5.4 xhigh 的AI模型。
使用的MCP则是 JSReverser-MCP
提示词:
makefile
使用:JSReverse MCP方式:插桩采集完整的输入输出及中间态数据,与本地算法进行逻辑一致性和结果正确性对比分析。URL: 【https://match.yuanrenxue.cn/match/7】目标:【目标接口,https://match.yuanrenxue.cn/api/question/7?page=2&pageSize=10&kw=,这个接口会返回data数据和woff文件,请你根据woff文件识别这些data数据】 触发方式: 【翻面】 约束:不使用playwright等浏览器自动化工具,不能联网搜索公开案例 cookie:将{"sessionid":"XXXXXX"}加入到请求代码中,表示当前登录UA设置:yuanrenxue交付:可运行的python脚本,运行后打印1-5页的响应数据,并计算总和四.AI提供的源码
python
import base64import reimport tempfilefrom functools import lru_cachefrom pathlib import Path
import numpy as npimport requestsfrom PIL import Image, ImageDraw, ImageFont, ImageOps
BASE_URL = "https://match.yuanrenxue.cn"API_URL = f"{BASE_URL}/api/question/7"USER_AGENT = "yuanrenxue"SESSION_ID = "XXXXXXX"PAGE_SIZE = 10TOTAL_PAGES = 5TEMPLATE_SIZE = 32RENDER_SIZE = 180CACHE_DIR = Path(__file__).resolve().parent / ".cache"TEMPLATE_CACHE = CACHE_DIR / "digit_templates_v1.npz"WINDOWS_FONT_DIR = Path(r"C:\Windows\Fonts")
def normalize_image(img: Image.Image) -> np.ndarray | None: arr = np.array(img) points = np.argwhere(arr < 240) if points.size == 0: return None
y0, x0 = points.min(axis=0) y1, x1 = points.max(axis=0) + 1 crop = Image.fromarray(arr[y0:y1, x0:x1]) fitted = ImageOps.contain(crop, (TEMPLATE_SIZE, TEMPLATE_SIZE)) canvas = Image.new("L", (TEMPLATE_SIZE, TEMPLATE_SIZE), 255) canvas.paste( fitted, ((TEMPLATE_SIZE - fitted.width) // 2, (TEMPLATE_SIZE - fitted.height) // 2), ) return np.array(canvas, dtype=np.float32) / 255.0
def render_char(font_source: str | Path, text: str, size: int = RENDER_SIZE) -> np.ndarray | None: try: font = ImageFont.truetype(str(font_source), size) except Exception: return None
canvas_size = 256 img = Image.new("L", (canvas_size, canvas_size), 255) draw = ImageDraw.Draw(img) bbox = draw.textbbox((0, 0), text, font=font) if not bbox: return None
width = bbox[2] - bbox[0] height = bbox[3] - bbox[1] x = (canvas_size - width) // 2 - bbox[0] y = (canvas_size - height) // 2 - bbox[1] draw.text((x, y), text, font=font, fill=0) return normalize_image(img)
def list_system_fonts() -> list[Path]: fonts: list[Path] = [] for pattern in ("*.ttf", "*.otf", "*.ttc"): fonts.extend(sorted(WINDOWS_FONT_DIR.glob(pattern))) return fonts
def build_templates() -> tuple[np.ndarray, np.ndarray]: CACHE_DIR.mkdir(exist_ok=True) if TEMPLATE_CACHE.exists(): cached = np.load(TEMPLATE_CACHE) return cached["templates"], cached["labels"]
templates: list[np.ndarray] = [] labels: list[int] = [] for font_path in list_system_fonts(): rendered: list[np.ndarray] = [] for digit in "0123456789": image = render_char(font_path, digit) if image is None: rendered = [] break rendered.append(image) if not rendered: continue templates.extend(rendered) labels.extend(range(10))
if not templates: raise RuntimeError("未能从系统字体构建数字模板。")
template_array = np.stack(templates) label_array = np.array(labels, dtype=np.int16) np.savez_compressed(TEMPLATE_CACHE, templates=template_array, labels=label_array) return template_array, label_array
@lru_cache(maxsize=1)def get_template_groups() -> dict[int, np.ndarray]: templates, labels = build_templates() return {digit: templates[labels == digit] for digit in range(10)}
def extract_codepoints(encoded_items: list[str]) -> list[int]: seen: list[int] = [] for item in encoded_items: for hex_value in re.findall(r"&#x([0-9a-fA-F]+)", item): codepoint = int(hex_value, 16) if codepoint not in seen: seen.append(codepoint) return seen
def build_cost_matrix(font_path: Path, codepoints: list[int]) -> np.ndarray: groups = get_template_groups() costs = np.zeros((len(codepoints), 10), dtype=np.float32) for row, codepoint in enumerate(codepoints): glyph = render_char(font_path, chr(codepoint)) if glyph is None: raise RuntimeError(f"无法渲染码位 {hex(codepoint)}。") for digit in range(10): refs = groups[digit] costs[row, digit] = np.min(((refs - glyph) ** 2).mean(axis=(1, 2))) return costs
def assign_digits(costs: np.ndarray) -> list[int]: n = costs.shape[0] full_mask = (1 << n) - 1 dp = [float("inf")] * (1 << n) prev: list[tuple[int, int] | None] = [None] * (1 << n) dp[0] = 0.0
for mask in range(1 << n): row = mask.bit_count() if row >= n or dp[mask] == float("inf"): continue for digit in range(10): if mask & (1 << digit): continue next_mask = mask | (1 << digit) score = dp[mask] + float(costs[row, digit]) if score < dp[next_mask]: dp[next_mask] = score prev[next_mask] = (mask, digit)
if dp[full_mask] == float("inf"): raise RuntimeError("未能完成 glyph 到数字的唯一匹配。")
assignment = [0] * n mask = full_mask for row in range(n - 1, -1, -1): parent = prev[mask] if parent is None: raise RuntimeError("匹配回溯失败。") old_mask, digit = parent assignment[row] = digit mask = old_mask return assignment
def decode_items(encoded_items: list[str], codepoint_to_digit: dict[int, str]) -> list[int]: decoded: list[int] = [] for item in encoded_items: digits = [] for hex_value in re.findall(r"&#x([0-9a-fA-F]+)", item): digits.append(codepoint_to_digit[int(hex_value, 16)]) decoded.append(int("".join(digits))) return decoded
def make_session() -> requests.Session: session = requests.Session() session.headers.update({"User-Agent": USER_AGENT}) session.cookies.set("sessionid", SESSION_ID, domain="match.yuanrenxue.cn", path="/") return session
def fetch_page(session: requests.Session, page: int) -> dict: response = session.get( API_URL, params={"page": page, "pageSize": PAGE_SIZE, "kw": ""}, timeout=15, ) response.raise_for_status() return response.json()
def decode_page(page: int, payload: dict) -> list[int]: font_path = Path(tempfile.gettempdir()) / f"yrx7_page_{page}.woff" font_path.write_bytes(base64.b64decode(payload["woff"])) codepoints = extract_codepoints(payload["data"]) costs = build_cost_matrix(font_path, codepoints) digits = assign_digits(costs) mapping = {codepoint: str(digit) for codepoint, digit in zip(codepoints, digits)} return decode_items(payload["data"], mapping)
def main() -> None: session = make_session() total = 0 for page in range(1, TOTAL_PAGES + 1): payload = fetch_page(session, page) values = decode_page(page, payload) total += sum(values) print(f"page {page}: {values}") print(f"sum: {total}")
if __name__ == "__main__": main()今天的分享就到这里,感谢阅读。
欢迎加入知识星球,学习更多AST和爬虫技巧。
