表的设计
OOA 面向对象分析 -- > OOD 面向对象设计 --> OOP 面向对象编程
1.从需求中获得类,类对应到数据库中的实体,实体在数据库中就表现为一张一张表,类中对应者表中的字段(列)
2.确定类与类之间的关系(一对一关系,一对多关系,多对多关系,没有关系)
针对一对一关系,设计表时,有两种方式
(1)把两个实体所有的信息全部都放在一张表里
(2)创建两张表,分别记录用户信息与账户信息,并把这两张表做关联
一对多关系
分别为不同的实体创建表,创建表之后建立表与表之间的关联关系
多对多关系
(1)分别创建实体表
(2)创建关系表,在关系表中为实体表之间创建关联关系
练习:创建班级表,学生表,课程表与成绩表
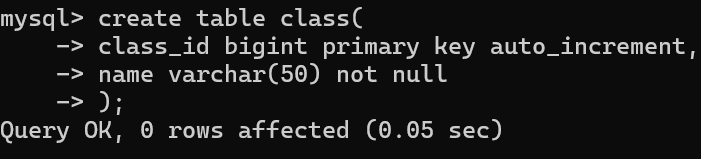
1.班级表(班级编号,班级名)
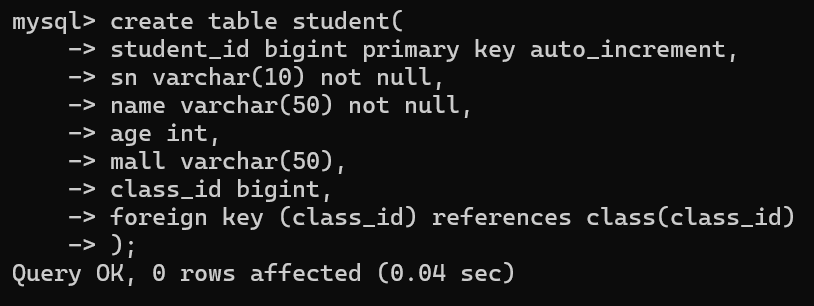
2.学生表(学生编号,学号,姓名,年龄,邮件,班级编号)
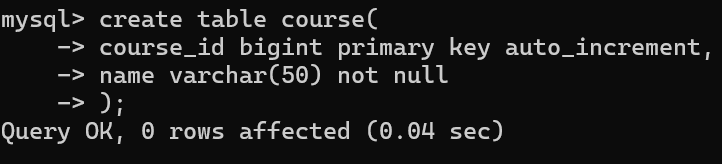
3.课程表(课程编号,课程名)
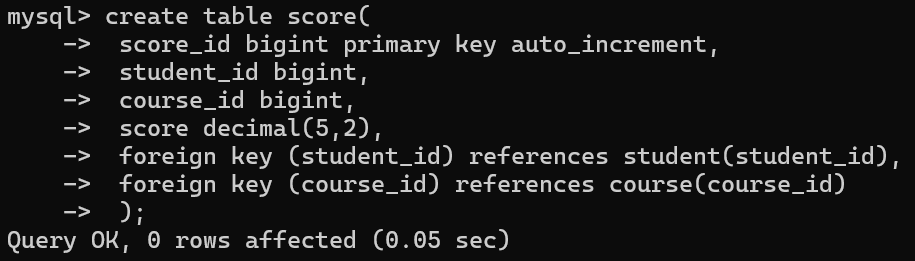
4.成绩表(编号,学生编号,课程编号)
班级表与学生表之间是一对多的关系
学生表与课程表之间是多对多的关系,通过一个关系表进行关联
3.使用SQL去创建具体的表
设计表的时候会遵守一些规则,一般我们把这些规则称为三大范式
什么是范式
范式描述的是数据关系的模型,一对一关系,一对多关系,多对多关系
分类:第一范式:1NF,第二范式:2NF,第三范式:3NF
其余范式:BC范式,BCNF
第一范式1NF
关系型数据库的一个基本的要求,不满足第一范式就不可以称为关系型数据库
表里的字段不可再进行拆分
可以继续拆分在关系型数据库中绝对不允许的
在定义表的时候,对照数据中的数据类型每一个字段都可以用一个数据类型表示,那么当前这个表就天然满足第一范式
第二范式2NF
在满足第一范式的基础上,不存在非关键字段对任意候选键的部分函数依赖(存在于复合主键的情况下)
非关键字段:可以理解为非关键字段
候选键:可以理解为主键,外键,没有主键时的唯一值
复合主键:一个表中不能存在两个主键,但是一个主键可以包含多个列(primary key (列名,列名))
对于由两个或多个关键字段决定一条记录的情况
如果一些数据中有些字段只与关键字端中的一个有关系,那么这种就说它只存在部分函数依赖
如果有这样的情况就说明这个表达式不满足第二范式
如果想避免这种情况,可以将表进行拆分,这样设计,每张表都有非关键字段,都强依赖于主键,满足了第二表达式
另外,一个表中没有复合主键(主键只有一列)那么这种的表天然满足第二范式
不满足第二范式可能出现的问题
1.数据冗余
2.更新异常
3.插入异常
4.删除异常
第三范式3NF
在第二范式的基础上,不存在非关键字段,对任一候选键的传递依赖
一张表可以通过外键与另一张表建立关系
第三范式可以解决数据冗余,更新异常,插入异常,删除异常的问题
第一范式将数据不可再分
第二范式消除部分函数依赖
第三范式消除传递依赖
新增
新建一张表,把旧表中的指定列的数据导入到新表中
语法:insert into table_name (column \[, column ....)] select ....
select:要从旧表中查询出来的列
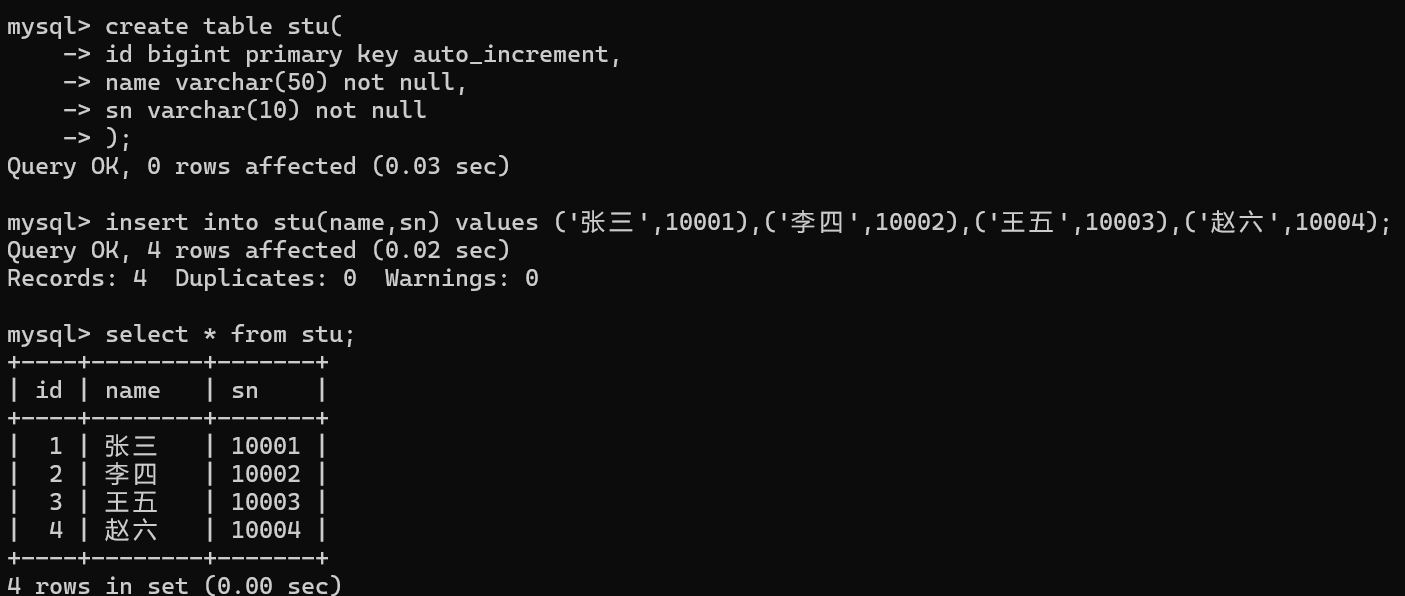
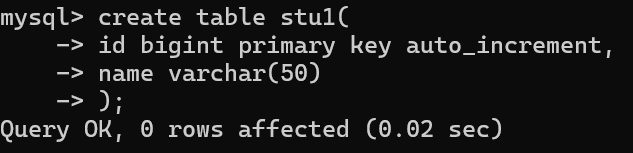
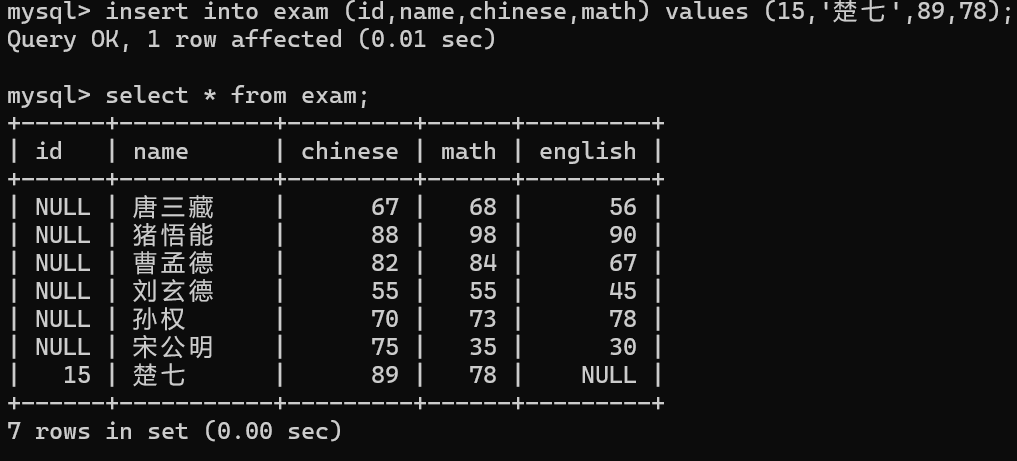
需要把stu中的数据复制到stu1中去
1.一条一条的重新插入一遍
2.把原来的数据导出来,再把表名改一下,再改入到目标表中
3.可以使用insert into select 语句

stu1是目标表
(id,name)表示要插入的列,必须要与要插入的列匹配
stu是原始表
聚合查询
MYSQL中内置的一些函数
COUNT----返回数量
SUM----返回总和
AVG----返回平均值
MAX---返回最大值
MIN---返回最小值
以上操作都是针对某一列进行运算的,之前学的表达式查询,是对一行记录中的列和列之间进行运算,比如:数学成绩+语文成绩+英语成绩
聚合查询是本质是针对数据表中的行和行进行运算
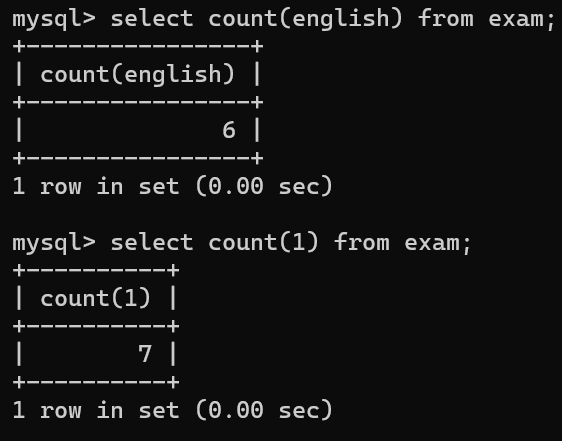
1.COUNT():统计所有的行
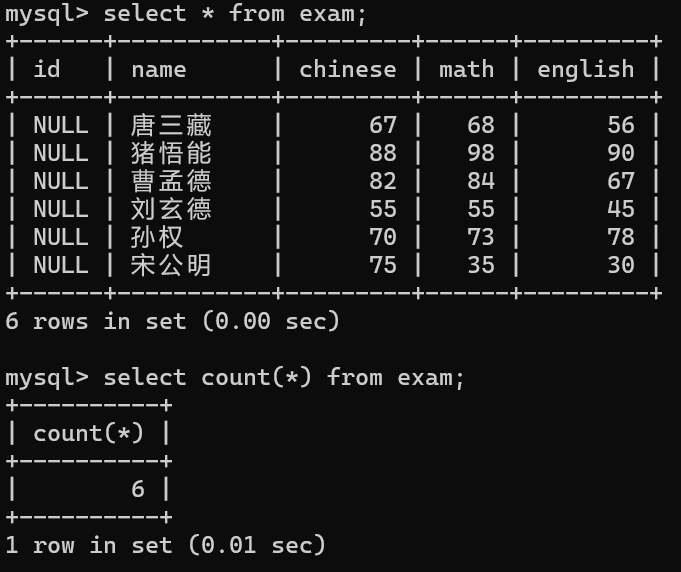
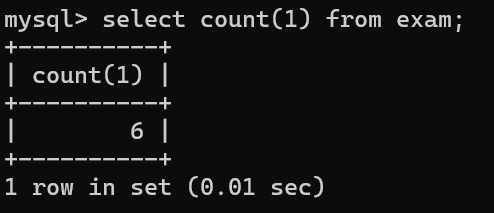
*是统计表中的行数,使用常量也可以进行统计,但推荐使用count(*)
count(列名),如果说列表中有null,则不会被统计在内
2.SUM(列名) 求和
示例:计算所有学生的语文成绩的总分
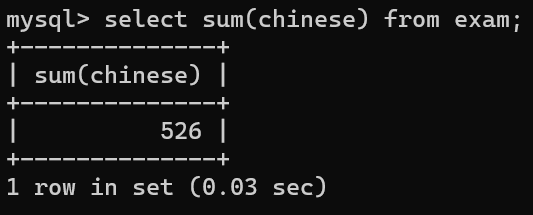
结果在一个临时表中,结果不受表中的字段长度约束
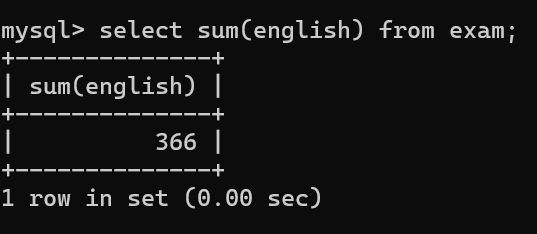
在SUM()求和时,NULL值不参与运算
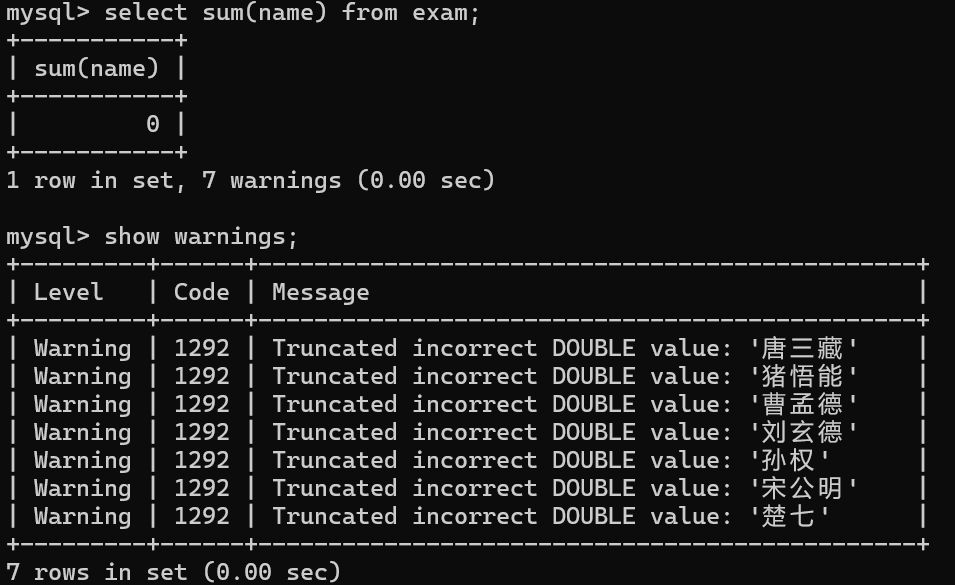
如果对非数值类型的列进行运算,会得到一些警告信息
3.AVG()
对所有行的指定列进行求平均值运算
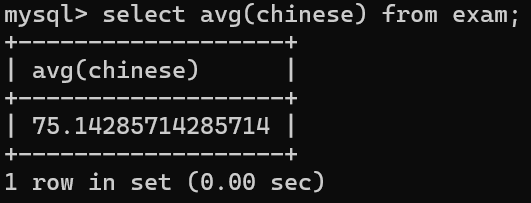
1.对所有同学的语文成绩求平均值
2.求语文,数学,英语三门课的总分的平均值
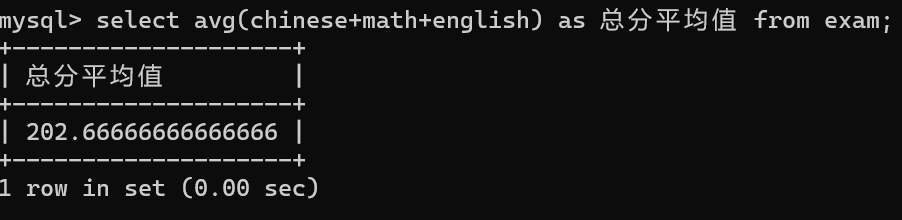
参数可以是表达式,也可以是别名
4.MAX(),MIN()
求所有行中指定的最大值,与最小值
1.找出语文成绩的最高分和英语成绩的最低分
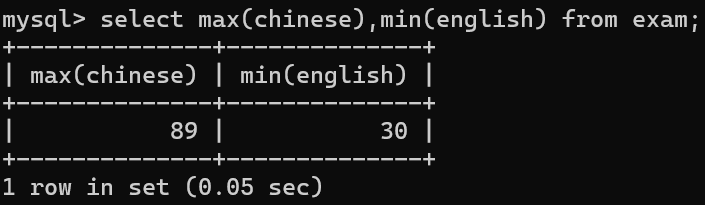
多个聚合函数可以同时使用
2.查找出语文成绩的最高分和最低分
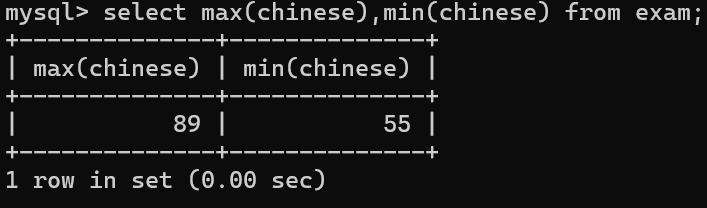
同一列可以使用不同的聚合函数
在使用关于运算的聚合函数时,不拔用在非数值上,比如说sum(),avg(),max(),min()
GROUP BY字句---分组查询
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查 询时,SELECT 指定的字段必须是"分组依据字段",其他字段若想出现在SELECT 中则必须包含在聚合函数中
没有指定的字段,呈现时要通过聚合函数,比如,求和,平均
分组依据字段:要对哪个列进行分组
语法:select column1,sum(column),...from table group by column1,column3;
column1:分组的列名
sum(column2):没有被分组的列(需要运算的列),但是要显示结果,那么就需要用到聚合函数
group by column1,column3:要分组的列
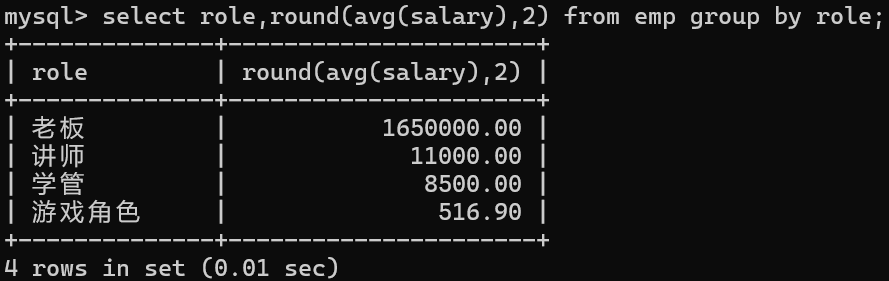
1.计算不同人的平均工资
要分组的列时role列
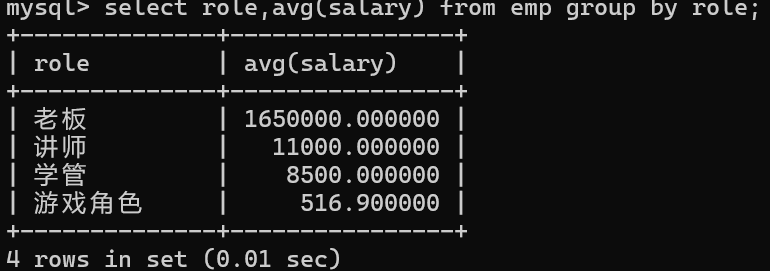
注意:ROUND(数值,小数点位数)
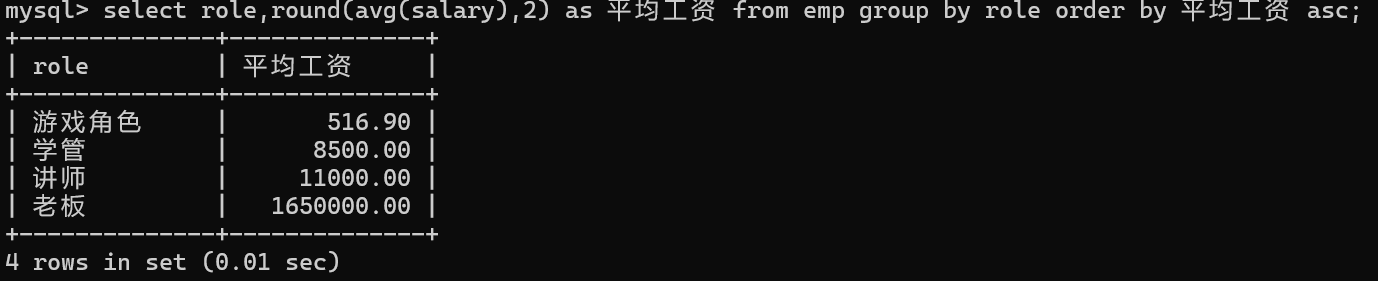
groby之后可以跟order by子句
HAVING
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用 HAVING
找到对分组之后的结果进行过滤,比如说,找出平均工资大于1万,小于10万的角色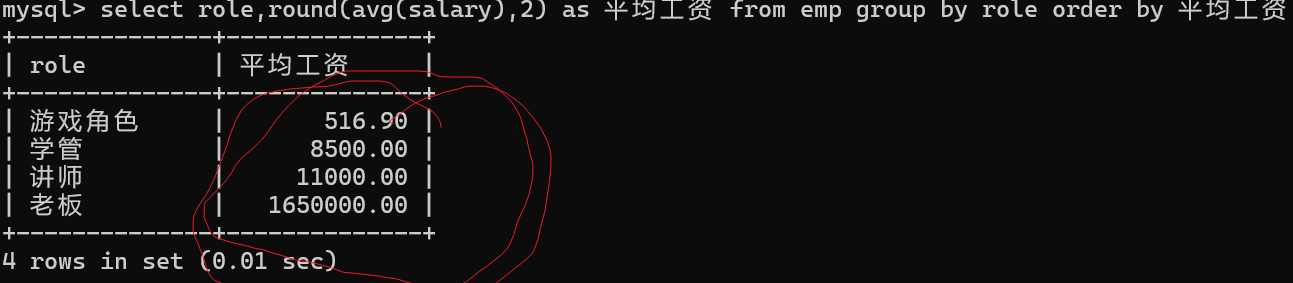
having可以把这个结果集中的数据进行过滤操作,平均工资并不是表中真正数据,而是通过聚合函数计算得出来的

having跟在group by字句之后,对分组结果进行过滤
where是对标中表中每一行的真实数据进行过滤的,having是对group by之后,计算出来的结果进行过滤
如果需求要对真实数据进行过滤,同时需要对分组结果进行过滤,那么在合适的位置写where和having即可
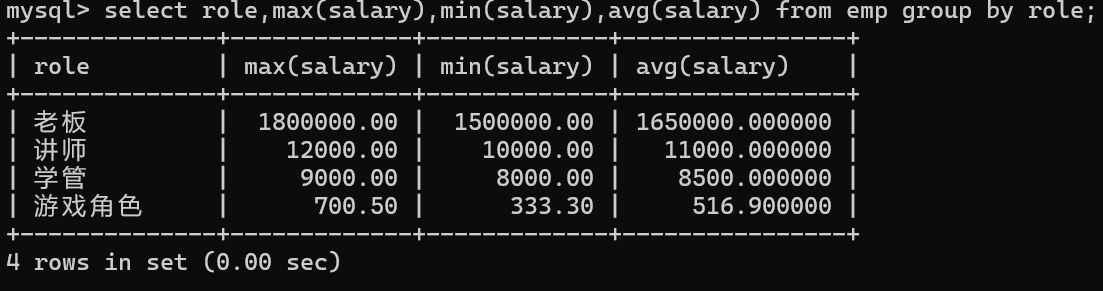
查询每个角色的最高工资,最低工资和平均工资
1.按角色分组
2.使用相应的聚合函数
联合查询
联合多个表进行查询
设计数据时把表进行拆分,为了消除表中的字段的依赖关系,比如部分函数依赖,传递依赖,这时会导致一条SQL语句查出来的数据时不完整的,我们就可以使用联合查询把关系中的数据全部查出来
联合查询时MYSQL是如何执行的
1.去多张表的笛卡尔机
对多张表进行笛卡尔积的过程,
- 先从第一张表中取一条记录,然后再与第二张表中的第一条记录进行组合,生成一条新的记录
- 先从第一张表中取一条记录,然后再与第二张表中的第二条记录进行组合,生成一条新的记录
。。。。
最后得到的结果就是一个全排列结果集
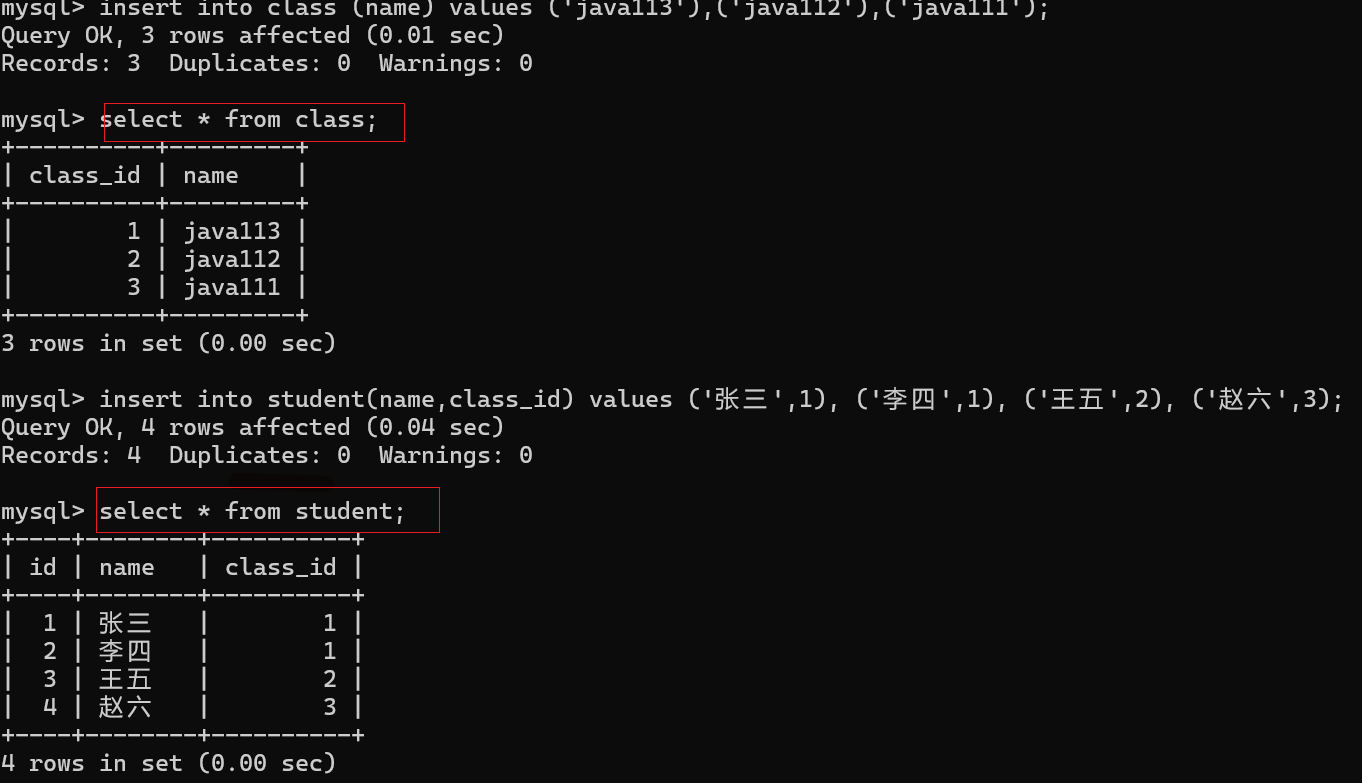
语法:select * from 表名,表名;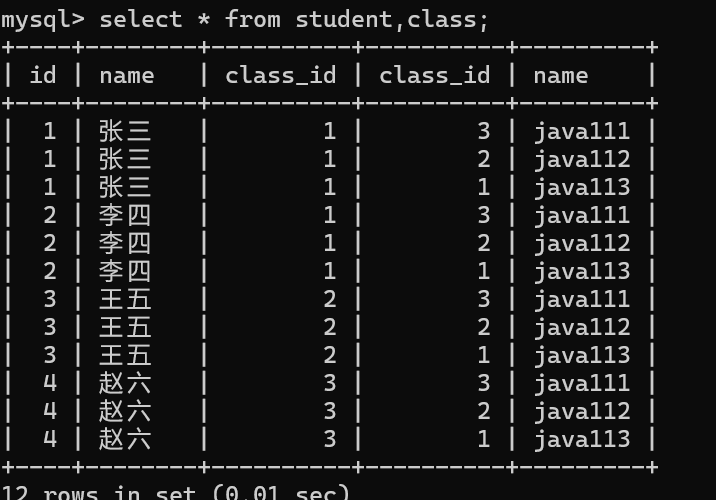
通过观察,两张表取笛卡尔积之后,有些数据是无效数据
如何过滤这些无效数据?
2.通过连接条件过滤掉无效条件
两个表之间是有主外键关系,只需要判断两个表中的主外键字段是否相等即可

class_id在两张表中都存在,MYSQL分不清当前语句中的class_id应取自哪张表
可以通过表名.列名的方式来解决这个问题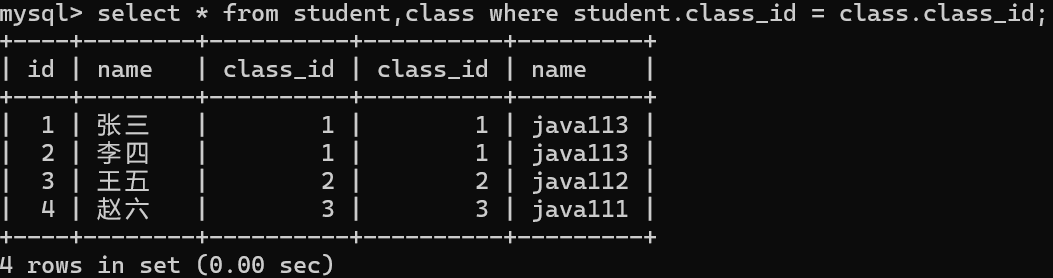
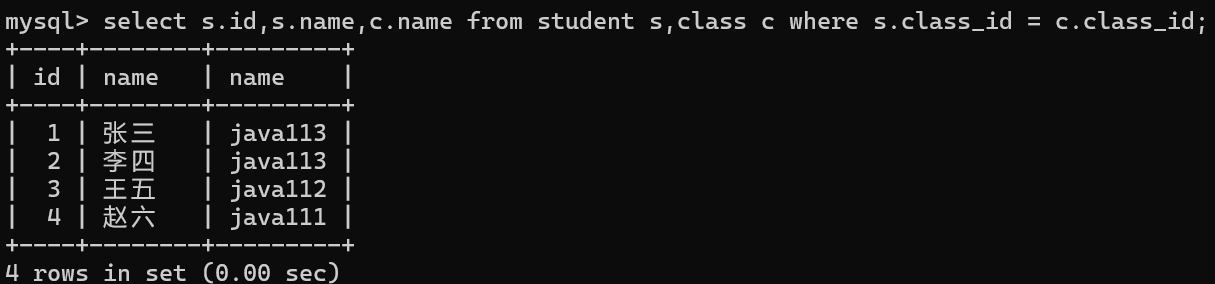
3.能通过指定列查询,来精减结果集
查询列表中通过表名.列名的方式指定要查询的字段
通过给表名起别名的方式来简化SQL语句
联合查询也叫表连接查询
1.首先确定哪几张表要参与查询
2.根据表与表之间的主外键关系,确定过滤关系
3.精减查询字段,得到想要的结果
内连接
select 字段 from 表1 别名1 inner join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1, 表2 别名2 where 连接条件 and 其他条件;
(1)查询'许仙'同学的成绩
1.首先确定哪几张表要参与查询
成绩表和学生表
取两张表的笛卡尔积
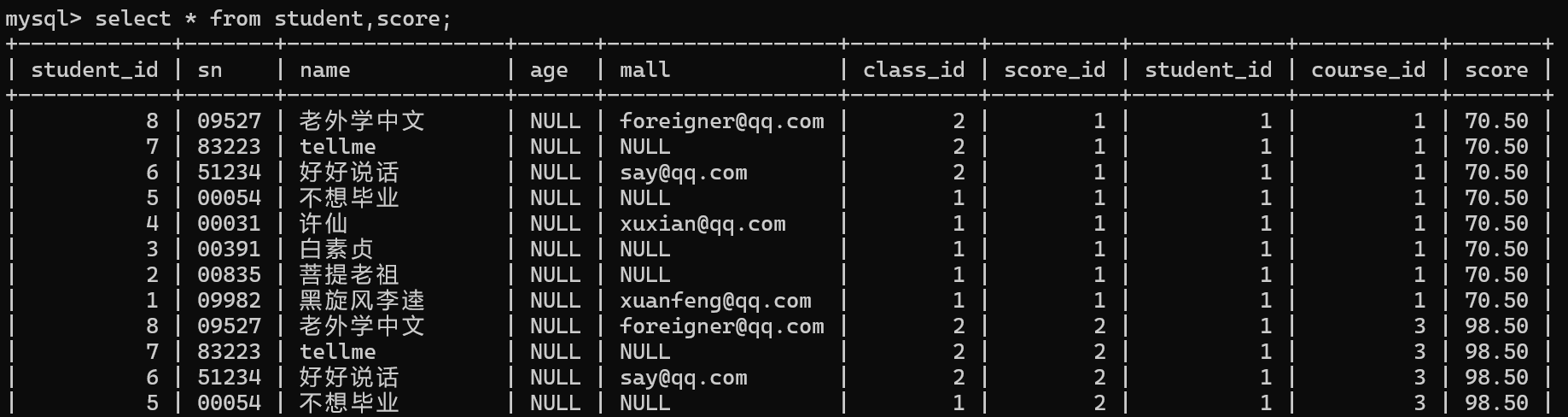
2.根据表与表之间的主外键关系,确定过滤条件
两张表中通过student_id作为主外键关联字段

确定结果集中的过滤条件
在where条件中,增加student.name='许仙'的过滤条件

3.精减查询类表中的字段
学生名,分数
(2)查询所有同学的总成绩及个人信息
需要使用聚合函数
1.确定要查询的表是学生表和成绩表
总成绩要用分组查询group by
对行与行之间进行运算,使用SUM()进行求和
2.取两张表的笛卡尔积
3.确定两张表之间的关联关系
所有同学成绩的结果集
4.按学生的id进行分组,并在查询列表中,使用聚合函数sum(分数),计算总分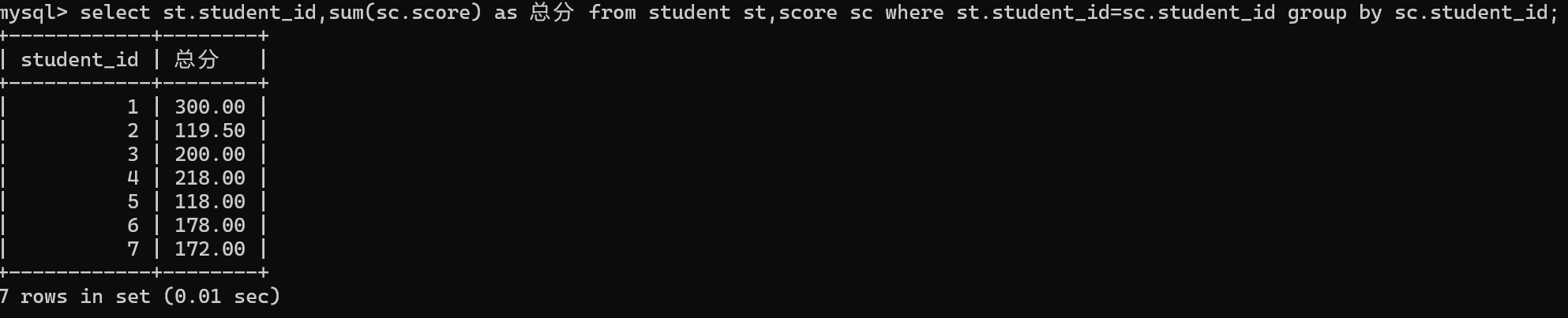
5.在查询列表中精减和确定要查询的列
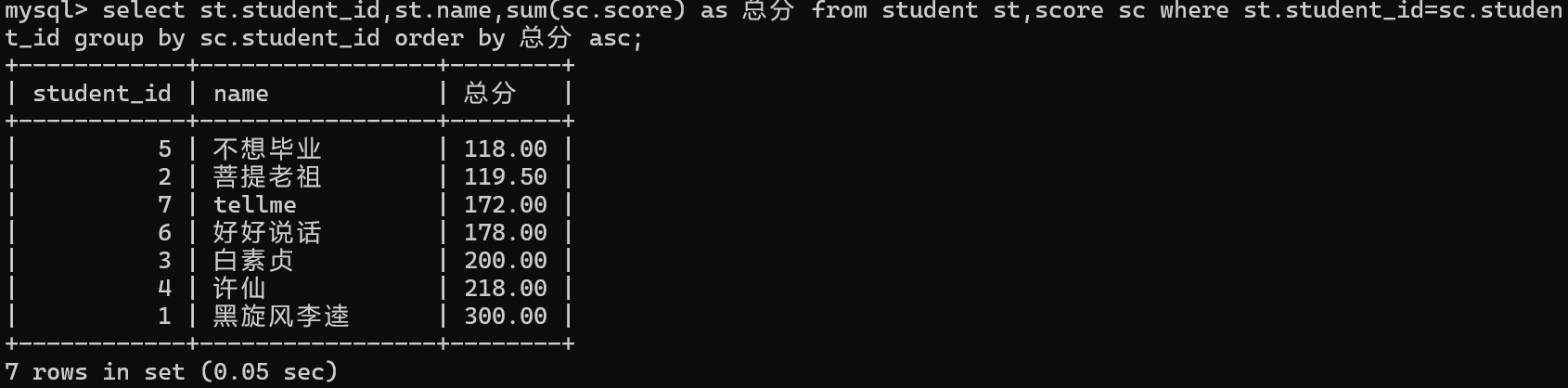
询步骤细化之后
1.确定查询中涉及到哪些表
2.对目标取笛卡尔积
3.确定连接条件
4.确定对整个结果集的过滤条件
5.精减查询字段