在VMware上使用ubuntu-24.04.3-live-server-amd64搭建的虚拟机集群
|--------|----------------|
| 名称 | IP |
| ceph-1 | 192.168.31.145 |
| ceph-2 | 192.168.31.146 |
| ceph-3 | 192.168.31.148 |
后续步骤请先完成集群的ssh免密登录与时间同步
时间同步:(每个节点,)
1、# 安装 chrony
apt install chrony -y
2、# 配置 NTP 服务器指向控制节点
主机点指向openstack controller节点
echo "server controller iburst" >> /etc/chrony/chrony.conf
我们这里指向ceph-1 节点,生产环境建议都指向openstack controller节点;
echo "server ceph-1 iburst" >> /etc/chrony/chrony.conf
其他节点同步主节点
chronyc sources ceph-1
3、# 重启服务
systemctl restart chrony
4、# 验证
chronyc activity -v
systemctl status chrony.service
ssh免密登录:
在ceph-1端机器上
1、# 生成公钥私钥对
ssh-keygen -t rsa
一路默认回车,系统在/root/.ssh下生成 id_rsa、id_rsa.pub
2、# 把id_rsa.pub发送到服务端机器上
ssh-copy-id -i /root/.ssh/id_rsa.pub ceph-2 #或者server ip
ssh-copy-id -i /root/.ssh/id_rsa.pub ceph-3 #或者server ip
3、# 重复上述所有步骤
例如我有17个节点,依次将每个节点的root分别进行上述步骤,循环一次即可全部ssh通
4、# 验证
ssh root@ceph-2 #或者server ip
ssh root@ceph-3 #或者server ip
说明:应该是不需要密码即可进入相关节点
下载 ceph 安装
对集群每一台虚拟机均执行如下命令( ceph集群的每个主机都安装ceph )
#安转ceph
apt -y install ceph
#查看版本
ceph -v

ceph-1的配置
给集群生成一个唯一 ID
给集群生成一个唯一 ID,
uuidgen
28b79990-450c-4280-a140-936fb7b32ab1
创建配置文件
创建配置文件
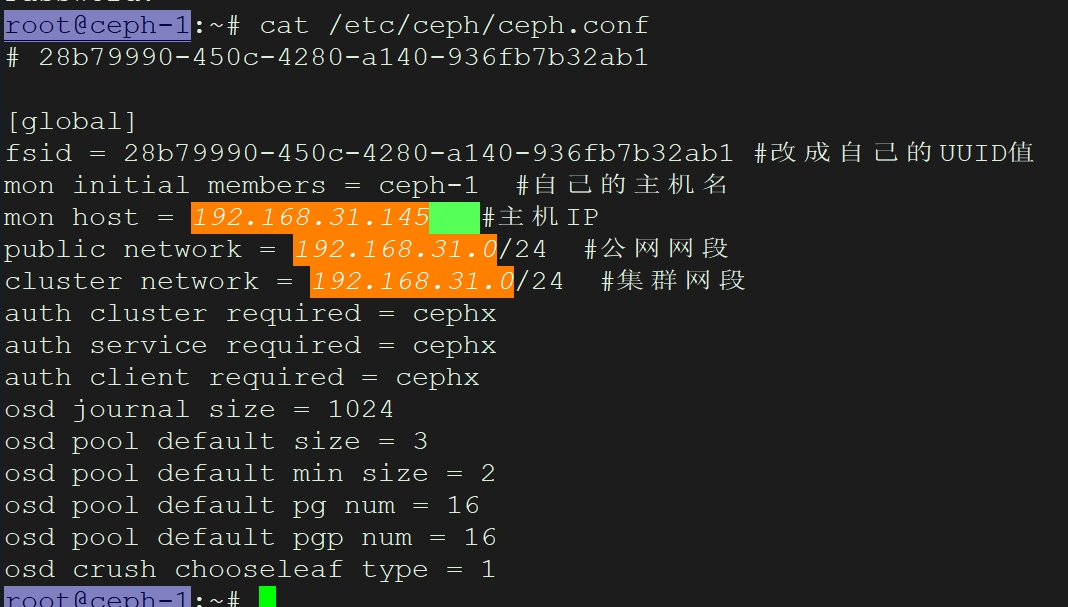
vim /etc/ceph/ceph.conf
fsid为刚才生成的ID,mon host为当前主机IP,public network为服务网络,cluster network为集群网络。
fsid = c9bb7e3d-5e4e-4a3a-9c49-e68a54ccc5e3
mon initial members = ceph-1
mon host = 192.168.88.147
public network = 192.168.88.0/24
cluster network = 192.168.88.0/24
文件添加的内容
global
fsid = c9bb7e3d-5e4e-4a3a-9c49-e68a54ccc5e3
mon initial members = ceph-1#需要更改
mon host = 192.168.88.147#需要更改
public network = 192.168.88.0/24#需要更改
cluster network = 192.168.88.0/24#需要更改
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd journal size = 1024
osd pool default size = 3
osd pool default min size = 2
osd pool default pg num = 16
osd pool default pgp num = 16
osd crush chooseleaf type = 1
为集群生成一个 mon 密钥环
sudo ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
生成管理密钥环
sudo ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow *' --cap mgr 'allow *'
生成 bootstrap-osd 密钥环
sudo ceph-authtool --create-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring --gen-key -n client.bootstrap-osd --cap mon 'profile bootstrap-osd' --cap mgr 'allow r'

将生成的密钥环导入
sudo ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
sudo ceph-authtool /tmp/ceph.mon.keyring --import-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring

全部命令执行

修改权限
sudo chown ceph:ceph /tmp/ceph.mon.keyring
生成监视图
!!!注意更改主机名、ip和fsid!!!
monmaptool --create --add ceph-1 192.168.88.147 --fsid c9bb7e3d-5e4e-4a3a-9c49-e68a54ccc5e3 /tmp/monmap
本次测试执行(修改主机名/ip/fsid)
monmaptool --create --add ceph-1 192.168.31.145 --fsid 28b79990-450c-4280-a140-936fb7b32ab1 /tmp/monmap
monmaptool: monmap file /tmp/monmap
setting min_mon_release = quincy
monmaptool: set fsid to 28b79990-450c-4280-a140-936fb7b32ab1
monmaptool: writing epoch 0 to /tmp/monmap (1 monitors)
创建节点 mon 目录,默认命名格式为ceph-hostname
sudo -u ceph mkdir /var/lib/ceph/mon/ceph-ceph-1
################命令解释####################
命令分解:
sudo:以超级用户权限执行命令。管理Ceph的目录通常需要root权限。
-u ceph:sudo命令的选项,指定以哪个用户的身份执行后续命令。这里是指定以ceph用户(Ceph服务默认的运行用户)的身份来执行mkdir操作,以确保创建的目录具有正确的所有权。
mkdir:创建目录的命令。
/var/lib/ceph/mon/ceph-ceph-1:要创建的目录的完整路径。
路径参数详解:
这个路径是Ceph监控器实例的标准数据存储位置,其结构遵循特定约定:
/var/lib/ceph/:Ceph守护进程存储其运行时数据和状态信息的默认根目录。
mon/ :表明此目录用于存放监控器(Monitor) 守护进程的数据。Ceph集群中有不同的守护进程类型(如osd/用于OSD,mgr/用于管理器等)。
ceph-<monitor-hostname>:这是目录名的核心部分,用于唯一标识一个监控器实例。其命名格式通常为:
ceph-:固定的集群名前缀。默认集群名是ceph。如果你的集群有自定义名称(例如mycluster),则前缀应为mycluster-。
<monitor-hostname> :监控器所在主机的名称。在这个例子中是ceph-1,表明这个监控器计划部署在主机名为ceph-1的服务器上。
总结与完整目的:
执行这个命令的完整目的是:在主机上,以ceph用户的身份,为计划部署在ceph-1这台主机上的、属于默认集群(ceph)的监控器,创建其专用的数据目录。
##############命令解释结束####################
初始化
sudo -u ceph ceph-mon --mkfs -i ceph-1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring

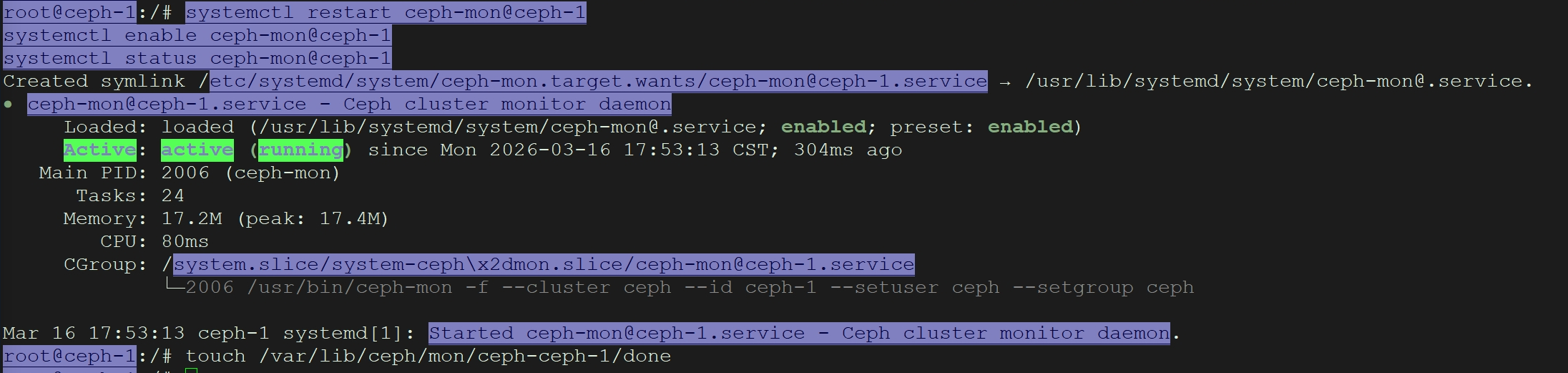
启动服务并查看状态
systemctl restart ceph-mon@ceph-1
systemctl enable ceph-mon@ceph-1
systemctl status ceph-mon@ceph-1
为防止重新安装创建一个空的 done 文件
touch /var/lib/ceph/mon/ceph-ceph-1/done
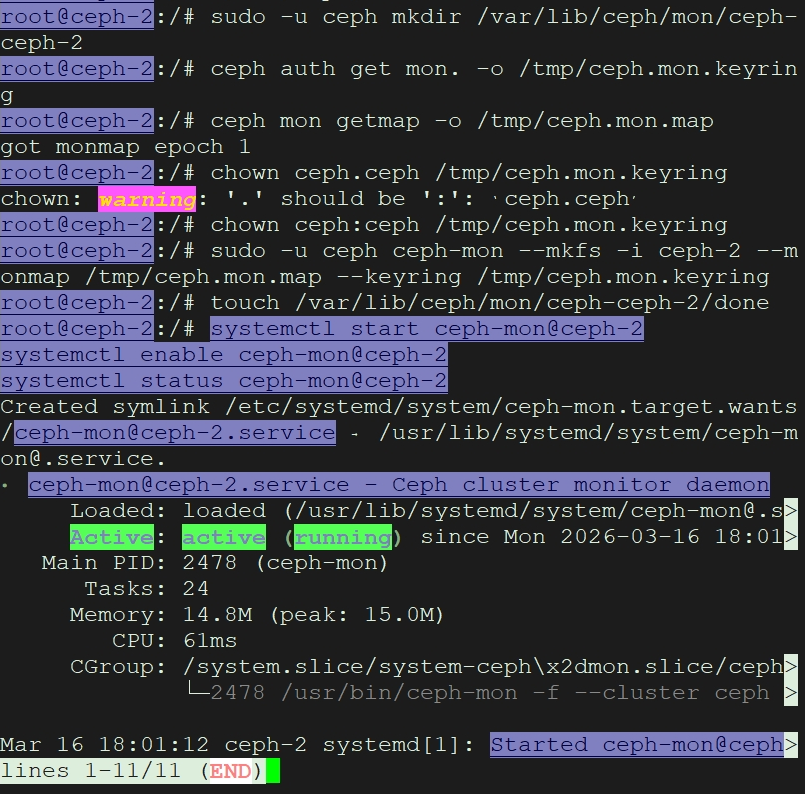
ceph-2的配置
在ceph-1内将配置文件拷贝
scp -r /etc/ceph/ ceph-2:/etc/
#在ceph-2内
sudo -u ceph mkdir /var/lib/ceph/mon/ceph-ceph-2
在临时目录获取监视器密钥环
ceph auth get mon. -o /tmp/ceph.mon.keyring
获取监视器运行图
ceph mon getmap -o /tmp/ceph.mon.map
修改 ceph.mon.keyring 属主和属组为 ceph
chown ceph:ceph /tmp/ceph.mon.keyring
初始化 mon
sudo -u ceph ceph-mon --mkfs -i ceph-2 --monmap /tmp/ceph.mon.map --keyring /tmp/ceph.mon.keyring
为了防止重新被安装创建一个空的 done 文件
touch /var/lib/ceph/mon/ceph-ceph-2/done
启动服务,它会自动加入集群
systemctl start ceph-mon@ceph-2
systemctl enable ceph-mon@ceph-2
systemctl status ceph-mon@ceph-2
ceph-3的配置
在ceph-1内将配置文件拷贝
scp -r /etc/ceph/ ceph-3:/etc/
#在ceph-3内
sudo -u ceph mkdir /var/lib/ceph/mon/ceph-ceph-3
在临时目录获取监视器密钥环
ceph auth get mon. -o /tmp/ceph.mon.keyring
获取监视器运行图
ceph mon getmap -o /tmp/ceph.mon.map
修改 ceph.mon.keyring 属主和属组为 ceph
chown ceph:ceph /tmp/ceph.mon.keyring
初始化 mon
sudo -u ceph ceph-mon --mkfs -i ceph-3 --monmap /tmp/ceph.mon.map --keyring /tmp/ceph.mon.keyring
为了防止重新被安装创建一个空的 done 文件
touch /var/lib/ceph/mon/ceph-ceph-3/done
启动服务,它会自动加入集群
systemctl start ceph-mon@ceph-3
systemctl enable ceph-mon@ceph-3
systemctl status ceph-mon@ceph-3
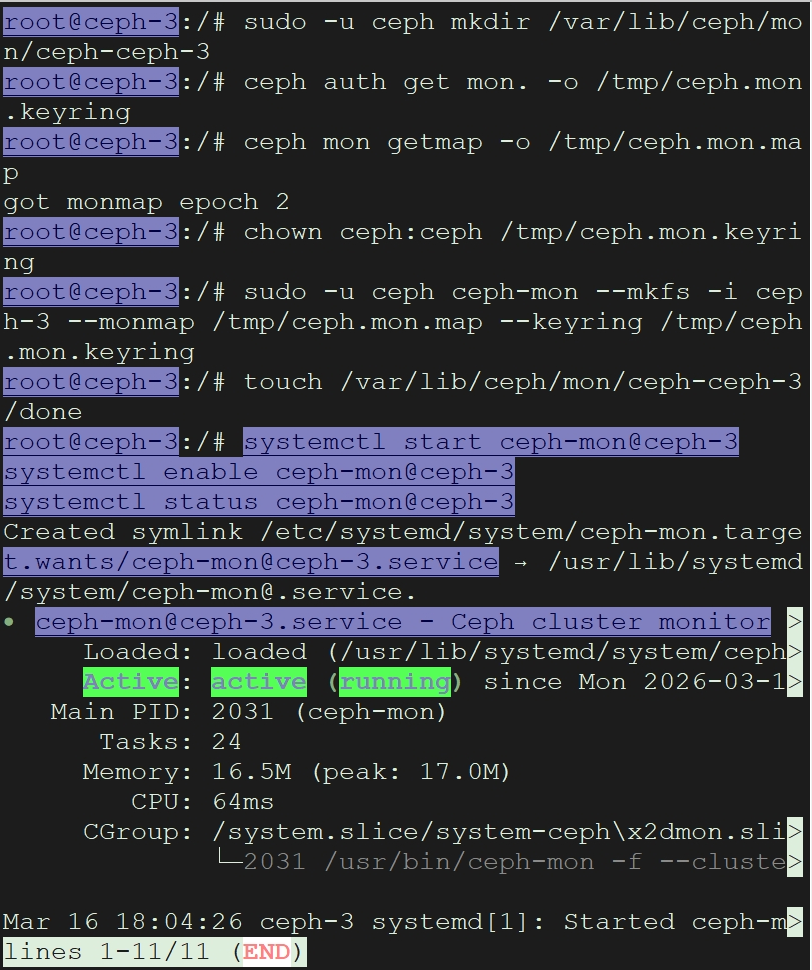
查看集群
ceph -s
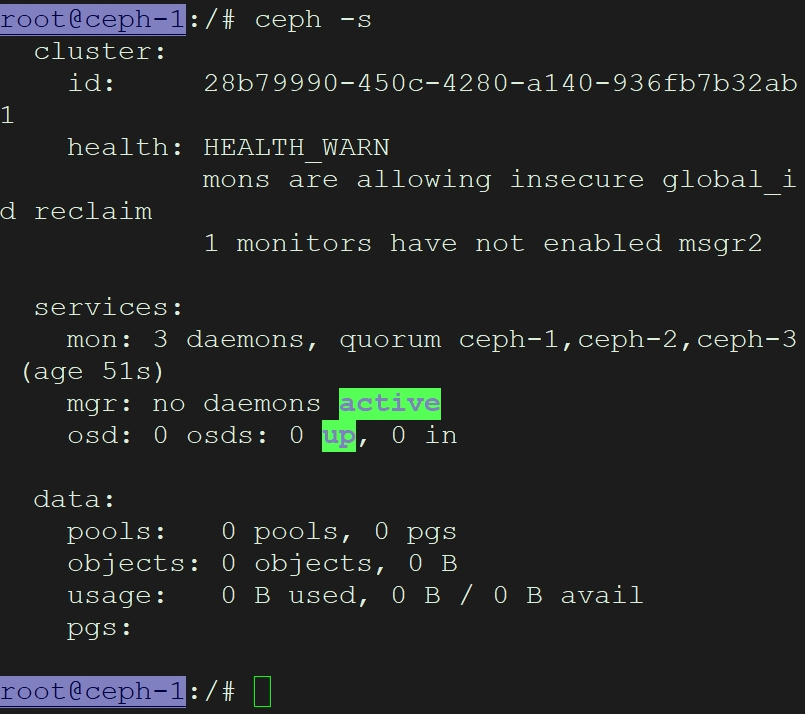
如果出现错误
#以ceph-1为例先停止再删除文件,然后重新开始
sudo systemctl stop ceph-mon@ceph-1
sudo rm -rf /var/lib/ceph/mon/ceph-ceph-1
部署 OSD 存储节点
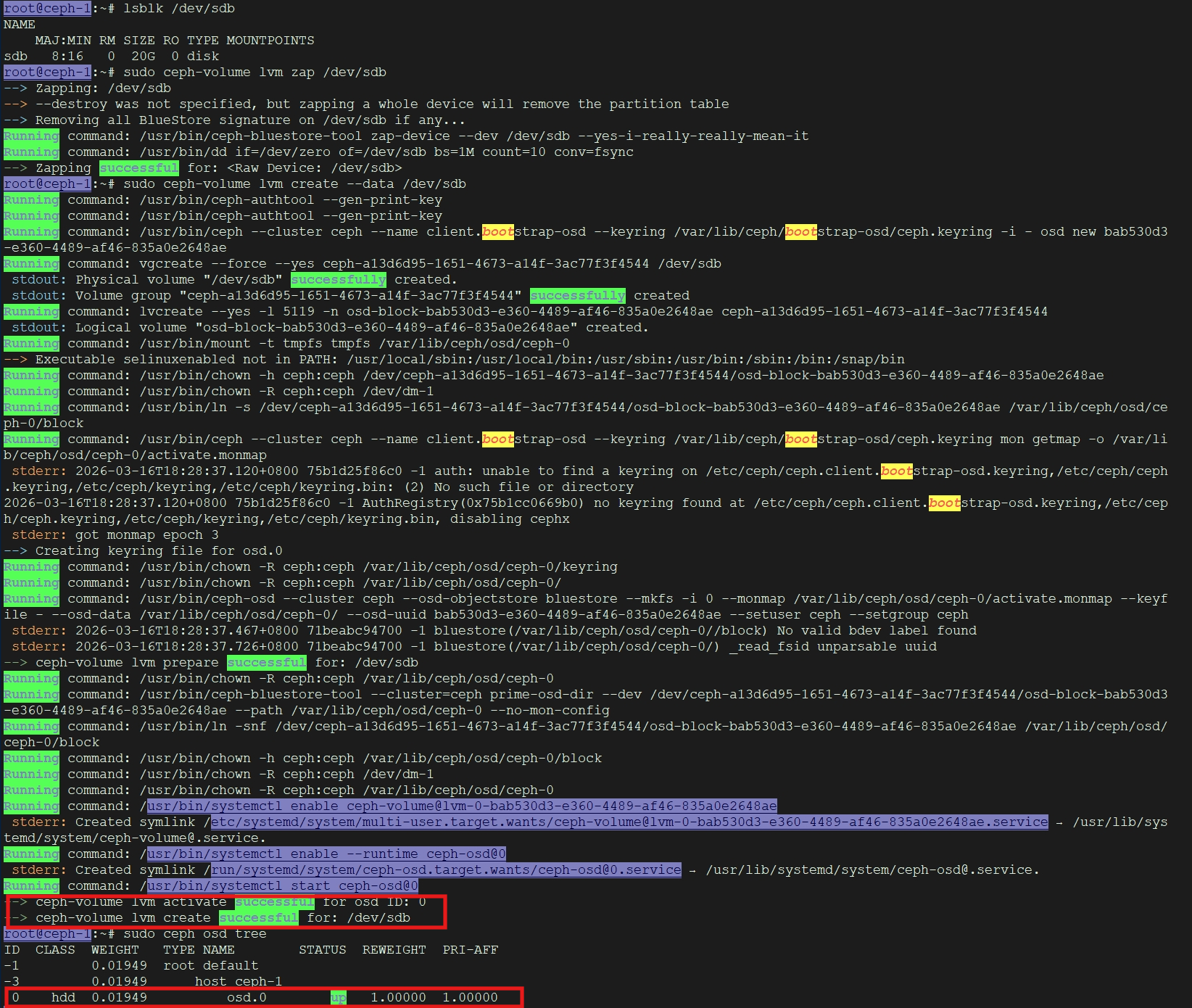
1. 准备磁盘(Preparing the Disk)
这一步的目标是擦除磁盘上的旧数据,并将其初始化为 Ceph 可用的状态。
* 查看磁盘信息:首先确认 /dev/sdb确实是你要使用的磁盘,且没有重要数据。
lsblk /dev/sdb
* 擦除磁盘(Zap):使用 ceph-volume工具彻底清除磁盘上的分区表和文件系统签名,确保磁盘是"干净"的。
sudo ceph-volume lvm zap /dev/sdb
* 参数说明:zap命令会销毁磁盘上的所有数据,请务必确认磁盘路径无误。
2. 创建 OSD(Creating the OSD)
这是核心步骤,Ceph 会自动在磁盘上创建逻辑卷(LVM)并启动 OSD 守护进程。
* 执行创建命令:
sudo ceph-volume lvm create --data /dev/sdb
* 参数说明:
* lvm create:指示使用 LVM 后端来创建 OSD。
* --data /dev/sdb:指定用于存储 OSD 数据的物理磁盘设备。Ceph 会在此磁盘上自动创建加密的 LVM 卷。
* 命令输出解读:命令执行成功后,你会看到类似以下的输出,其中包含新 OSD 的 ID(如 0)和用于激活的密钥(osd key):
复制
--> ceph-volume lvm create successful for: /dev/sdb
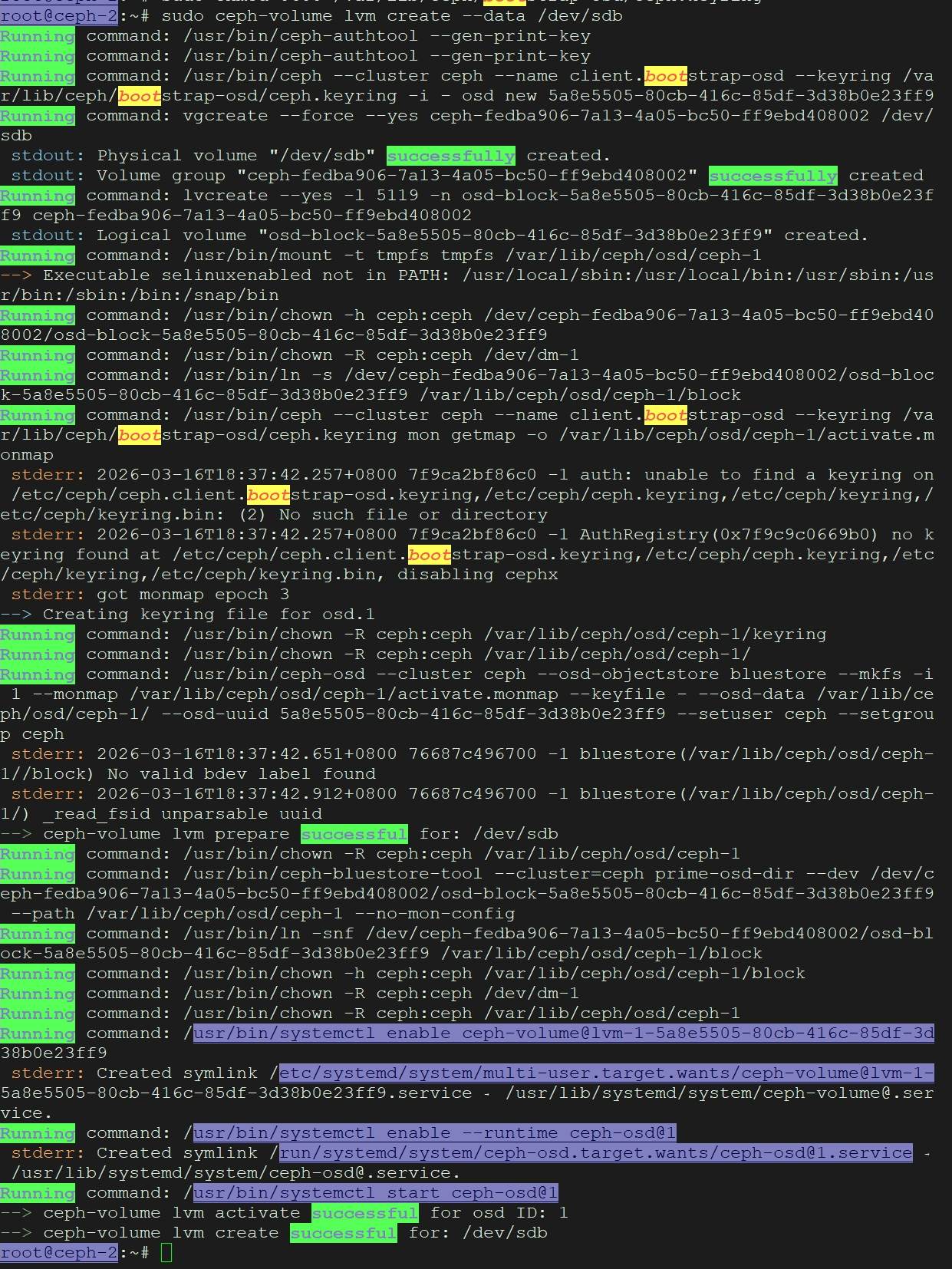
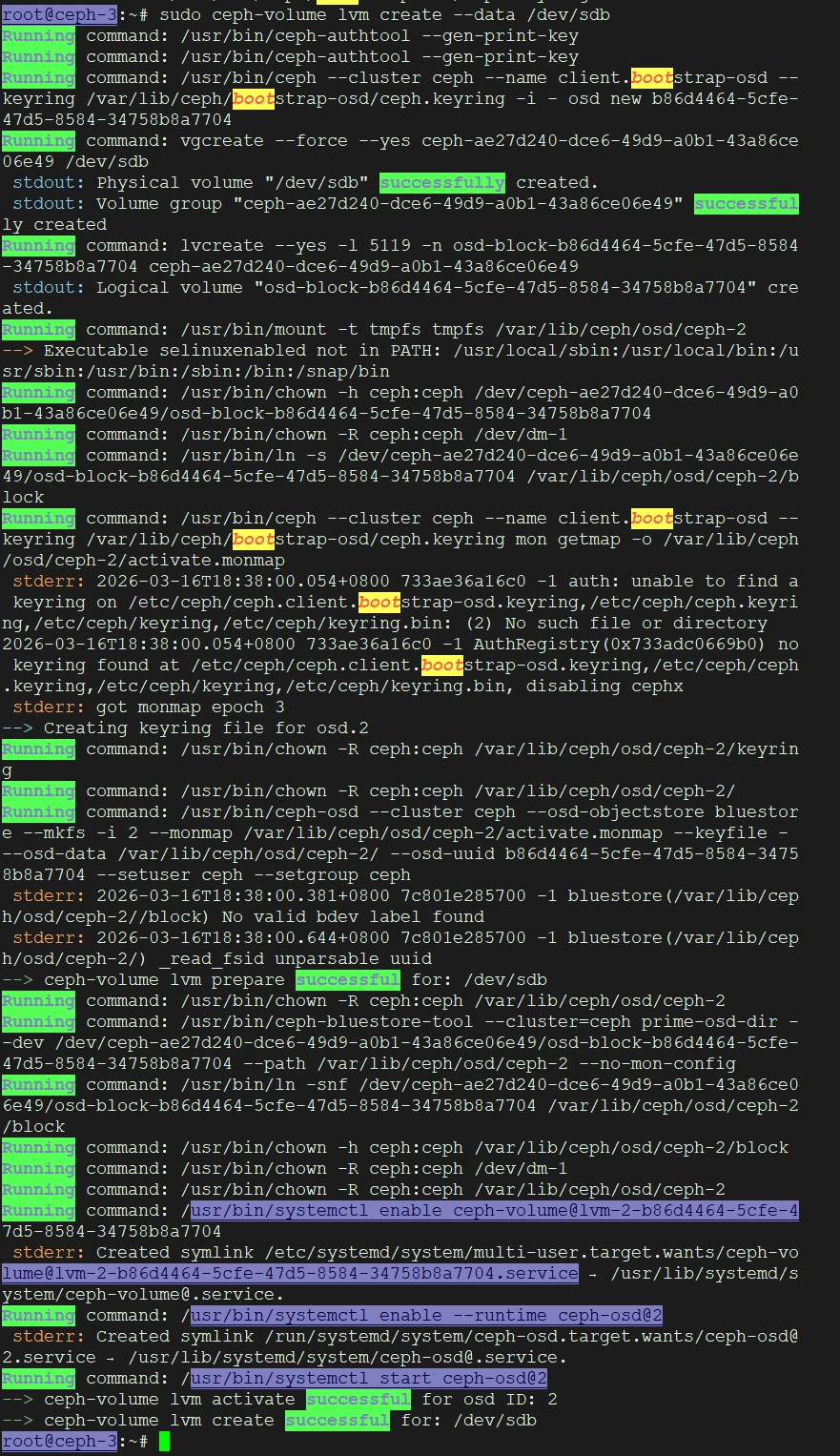
# 其他节点创建报错如下图:
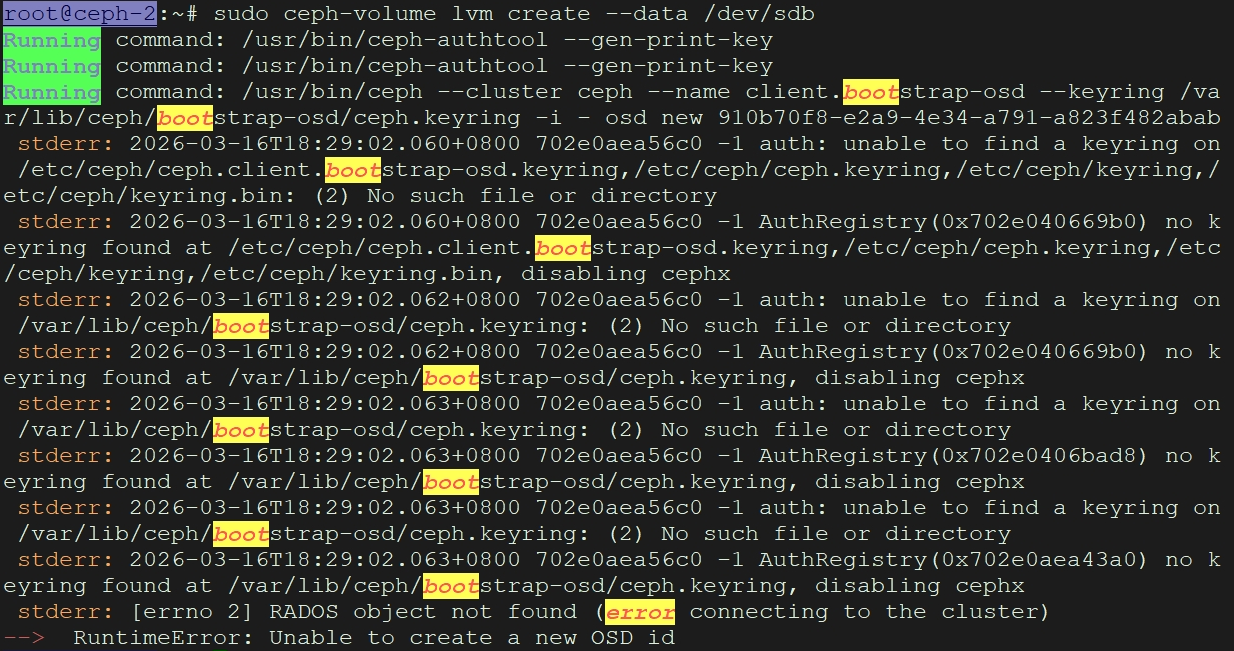
解决办法:
这个错误表明你的 ceph-2 节点上缺少必要的 引导密钥环 (bootstrap-osdkeyring)。这是一个常见的部署问题,发生在非管理节点或未正确同步配置的节点上。
核心原因:
ceph-volume命令需要与 Ceph 集群的 Monitor 通信来注册一个新的 OSD ID,为此需要使用具有 bootstrap-osd权限的密钥环 /var/lib/ceph/bootstrap-osd/ceph.keyring。这个文件在你的管理节点上,但未同步到 ceph-2。
解决方案:
你需要 从管理节点(通常是第一个安装 Ceph Monitor 的节点,比如 ceph-1)将这个关键文件复制到 ceph-2 节点。
详细修复步骤:
第一步:在管理节点(ceph-1)上操作
确认文件存在 :
在 ceph-1 上检查文件是否存在。
ls -la /var/lib/ceph/bootstrap-osd/ceph.keyring
复制文件到 ceph-2:
使用 scp命令将该文件复制到 ceph-2 节点的相同路径下。你需要有 ceph-2 的 root 权限或通过 sudo 执行。
scp /var/lib/ceph/bootstrap-osd/ceph.keyring root@ceph-2:/var/lib/ceph/bootstrap-osd/
- 如果遇到权限问题,可以先复制到 ceph-2 的 /tmp/目录,然后登录 ceph-2 移动过去。
第二步:在 ceph-2 节点上操作
- (如果需要)设置正确的所有权和权限:
登录 ceph-2 节点,并确保该密钥环文件的属主是 ceph用户。
如果上一步直接复制到了目标路径
sudo chown ceph:ceph /var/lib/ceph/bootstrap-osd/ceph.keyring
sudo chmod 0600 /var/lib/ceph/bootstrap-osd/ceph.keyring
如果你是先复制到 /tmp/ 的sudo mkdir -p /var/lib/ceph/bootstrap-osd/
sudo cp /tmp/ceph.keyring /var/lib/ceph/bootstrap-osd/
sudo chown ceph:ceph /var/lib/ceph/bootstrap-osd/ceph.keyring
sudo chmod 0600 /var/lib/ceph/bootstrap-osd/ceph.keyring
- 确认网络和 Monitor 连接:
确保 ceph-2 节点能够访问集群的 Monitor 节点。你可以用管理节点上的 ceph.conf文件来帮助 ceph-2 找到 Monitor。最简单的方法是将管理节点的 /etc/ceph/ceph.conf文件也复制到 ceph-2 节点。
在 ceph-1 上执行
scp /etc/ceph/ceph.conf root@ceph-2:/etc/ceph/
2. 重新执行创建 OSD 的命令:
sudo ceph-volume lvm create --data /dev/sdb
第三步:为 ceph-3 节点做同样准备
在创建 ceph-3 节点的 OSD 之前,你需要 重复第一步和第二步,将 bootstrap-osd密钥环文件和 ceph.conf配置文件从管理节点复制到 ceph-3。
总结与最佳实践
问题根源 :bootstrap-osd密钥环是新节点加入集群的"准入凭证",必须从 已存在于集群的管理节点 分发到 新加入的存储节点。
自动化工具:如果你使用 ceph-deploy等自动化部署工具,这个复制过程通常是自动完成的。手动部署时最容易遗漏此步骤。
后续操作:解决此问题后,你应该先在 ceph-2 上成功创建 OSD,然后在 ceph-3 上重复这个过程(先复制文件,再创建 OSD)。
关键点 :Ceph 集群的部署不仅仅是安装软件, 配置文件和密钥环的同步是确保各节点能够与 Monitors 正确通信的基础。
其他节点配置OSD成功
3. 验证状态(Verification)
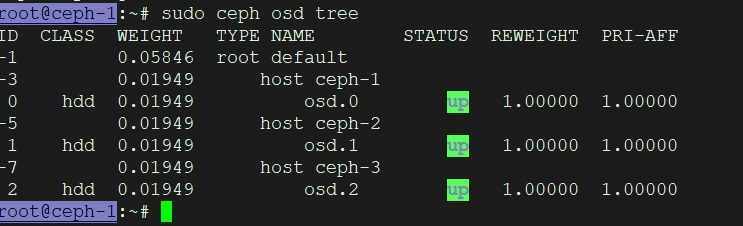
创建完成后,需要检查 OSD 是否已成功加入集群并处于正常运行状态。
* 查看 OSD 树:在任意 Ceph 管理节点执行以下命令,查看 OSD 的分布和状态。
sudo ceph osd tree
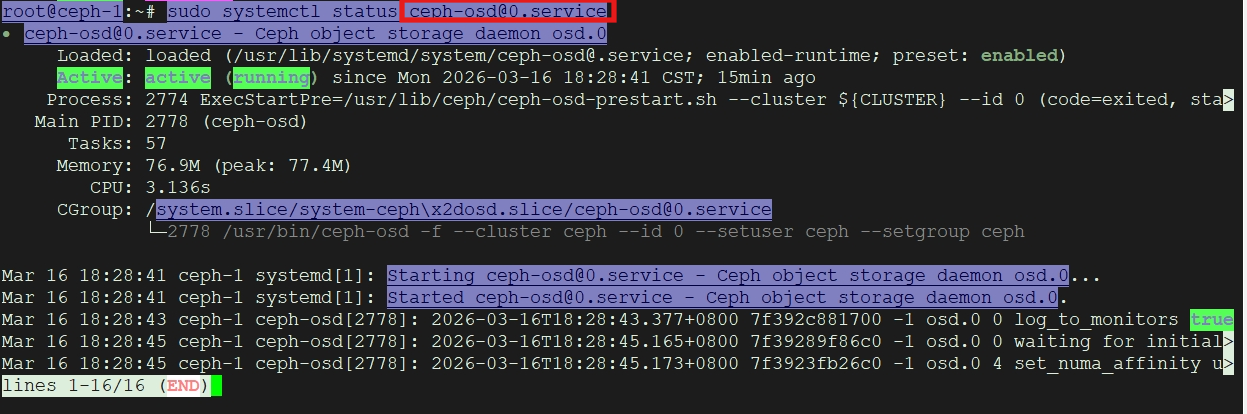
* 检查 OSD 服务:在创建 OSD 的节点上,检查 ceph-osd服务是否正在运行。
sudo systemctl status ceph-osd@<osd_id>.service
例如,如果 OSD ID 是 0,则执行:
sudo systemctl status ceph-osd@0.service
补充说明
* 权限要求:以上所有 ceph-volume命令通常需要 sudo权限,因为涉及磁盘设备操作。
* 自动化部署:如果你使用的是 cephadm或 ceph-ansible等自动化部署工具,创建 OSD 的流程可能会略有不同(通常通过 ceph orch命令),但手动部署场景下,上述 ceph-volume流程是最标准的方式。
扩展配置:-将ceph存储池加入openstack集群
一、安装ceph软件包:
现环境存在controller、computer、及cinder节点各一个,需在这三个节点安装ceph软件包:
ubuntu 系统:
根据你的操作系统(Ubuntu 或 CentOS),需要安装以下核心包:
节点类型 核心软件包 说明
Controller ceph-common 包含 ceph命令行工具、rbd工具,用于管理 Ceph 集群。
Cinder ceph-common 同上,Cinder 存储节点需要 rbd工具来操作块设备。
Compute ceph-common 计算节点需要挂载 Ceph 卷,必须安装客户端工具。
注意:在 Ubuntu 系统中,ceph-common包通常包含了所有必要的客户端工具。在 CentOS 中,有时可能需要额外安装 ceph包(包含 Python 绑定)。
1、安装软件包
在 Controller、Cinder 和 Compute 节点上分别执行:
Ubuntu:
sudo apt update
sudo apt install -y ceph-common
2、验证安装
安装完成后,验证命令是否可用:
ceph --version
rbd --version
如果显示版本号,说明安装成功。
二、从 Ceph-1 节点复制 ceph.conf 和 ceph.client.admin.keyring 文件
详细的步骤说明,用于从 Ceph-1 节点复制 ceph.conf和 ceph.client.admin.keyring文件到 Controller 和 Cinder 存储节点:
前提条件
- 确保 Ceph-1 节点上的 Ceph 集群已部署完成,并已生成管理员密钥环。
- 确保您拥有 Ceph-1 节点的 SSH 访问权限,并且已设置免密登录到目标节点(或准备好密码)。
- 确认目标节点(Controller 和 Cinder 存储节点)上已存在 /etc/ceph/目录(如果没有,请先创建)。
步骤 1:在 Ceph-1 节点上定位文件
首先,登录到 Ceph-1 节点,确认文件存在并记录其路径:
登录到 Ceph-1
ssh username@ceph-1-ip
检查文件是否存在
ls -l /etc/ceph/ceph.conf
ls -l /etc/ceph/ceph.client.admin.keyring
通常,这两个文件的默认路径就是 /etc/ceph/。
步骤 2:复制文件到 Controller 节点
从 Ceph-1 节点将文件复制到 Controller 节点。您可以使用 scp命令:
从 Ceph-1 节点执行(假设您当前在 Ceph-1 上)
scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring <controller-username>@<controller-ip>:/etc/ceph/
示例(如果 Controller IP 是 192.168.31.151,用户是 root):
scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring root@192.168.31.151:/etc/ceph/
注意:如果目标节点的 /etc/ceph/目录不存在,scp会失败。您可以在复制前先在目标节点创建目录:
在 Controller 节点上创建目录(如果不存在)
ssh root@192.168.31.151 "mkdir -p /etc/ceph"
步骤 3:复制文件到 Cinder 存储节点
同样,从 Ceph-1 节点将文件复制到 Cinder 存储节点:
从 Ceph-1 节点执行
scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring <cinder-username>@<cinder-ip>:/etc/ceph/
示例(如果 Cinder 存储节点 IP 是 192.168.31.141,用户是 root):
scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring root@192.168.31.141:/etc/ceph/
同样,如果目录不存在,先创建:
ssh root@192.168.31.141 "mkdir -p /etc/ceph"
# 复制到controller、computer、cinder节点上
root@ceph-1:~# scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring root@192.168.31.151:/etc/ceph/
root@192.168.31.151's password:
ceph.conf 100% 560 596.7KB/s 00:00
ceph.client.admin.keyring 100% 151 84.6KB/s 00:00
root@ceph-1:~# scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring root@192.168.31.161:/etc/ceph/
root@192.168.31.161's password:
ceph.conf 100% 560 703.1KB/s 00:00
ceph.client.admin.keyring 100% 151 191.8KB/s 00:00
root@ceph-1:~# scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring root@192.168.31.141:/etc/ceph/
The authenticity of host '192.168.31.141 (192.168.31.141)' can't be established.
ED25519 key fingerprint is SHA256:puuLMf6sR1gz89nBFe2ycPV4Cs0I5xbEMM0WOAaK6ng.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/fingerprint)? yes
Warning: Permanently added '192.168.31.141' (ED25519) to the list of known hosts.
root@192.168.31.141's password:
ceph.conf 100% 560 751.7KB/s 00:00
ceph.client.admin.keyring 100% 151 235.8KB/s 00:00
步骤 4:验证复制结果
分别在 Controller 和 Cinder 存储节点上验证文件是否复制成功,并检查权限:
在 Controller 节点上验证
ssh root@192.168.31.151 "ls -l /etc/ceph/"
在 Cinder 存储节点上验证
ssh root@192.168.31.141 "ls -l /etc/ceph/"
预期输出应显示两个文件,并且 ceph.client.admin.keyring的权限应为 600(仅所有者可读)。
如果权限不正确,在目标节点上修正:
chmod 600 /etc/ceph/ceph.client.admin.keyring
chmod 644 /etc/ceph/ceph.conf
步骤 5:测试 Ceph 连接
在 Controller 和 Cinder 存储节点上,测试是否能正常访问 Ceph 集群:
执行以下命令,应能成功返回 Ceph 集群状态
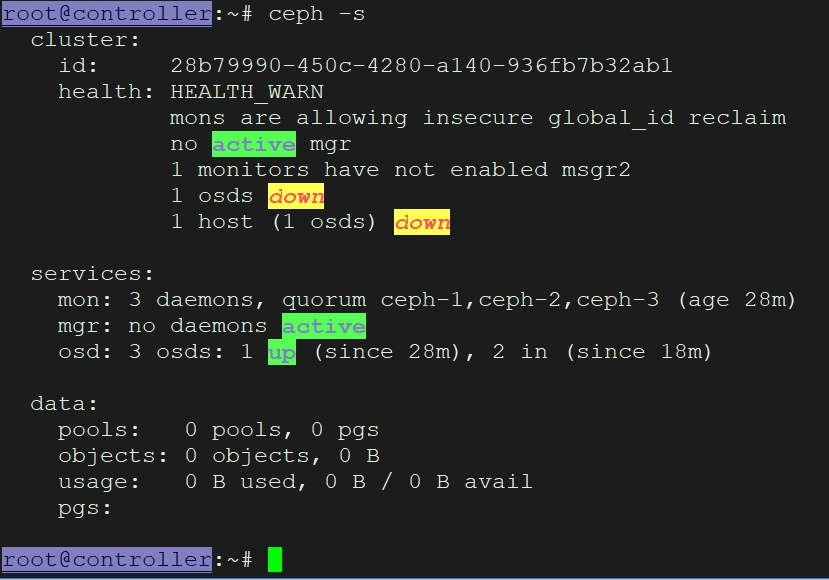
ceph -s
如果出现"permission denied"错误,请检查密钥环文件的权限和路径。如果出现"connect error",请检查网络连通性和防火墙设置。
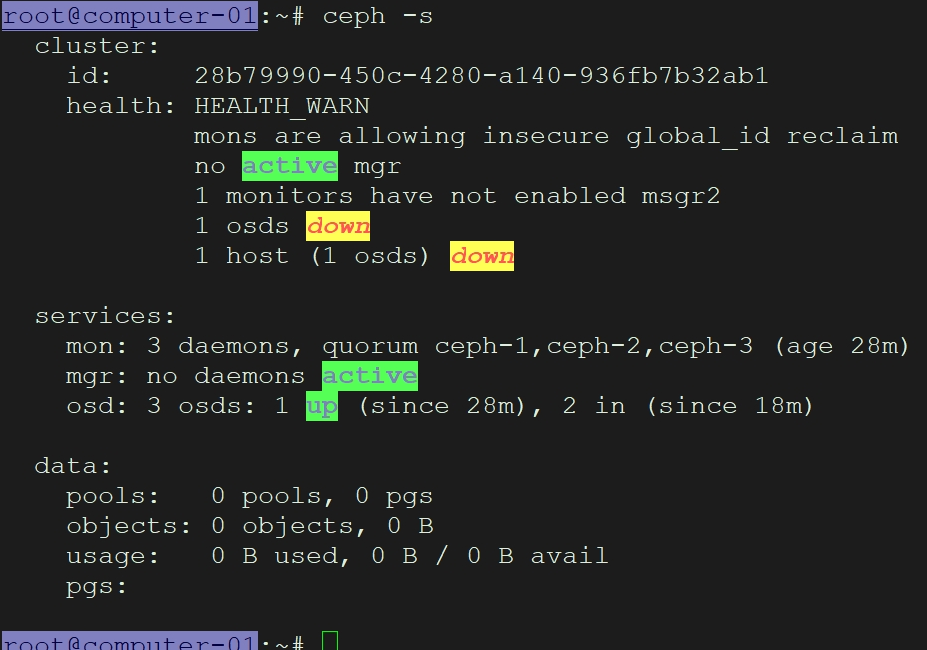
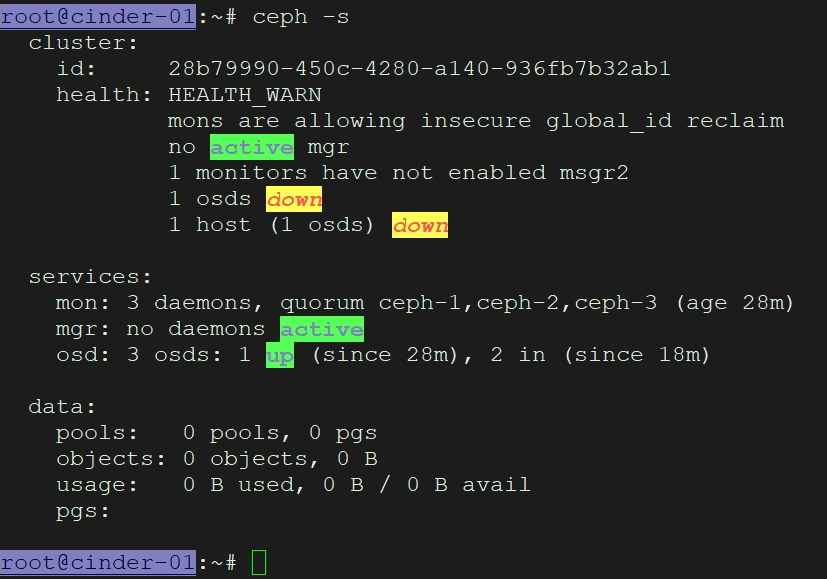
获取配置文件:
在 Ceph 管理节点(如 ceph-1)上,将 /etc/ceph/ceph.conf和 /etc/ceph/ceph.client.admin.keyring复制到所有 OpenStack 节点(如 Controller、Compute 节点)
这一步,controller节点作为cinder的控制节点,还有一个cinder存储节点,需要怎么配置
针对你这种Controller(控制节点)与Cinder存储节点分离的架构,配置思路是:所有节点都需要基础配置,但存储节点需要额外权限。
以下是详细的配置步骤:
1. 基础配置(所有节点都需要)
无论是 Controller 还是 Cinder 存储节点,都需要 Ceph 的配置文件来"认识"集群。
* 复制文件:将 ceph.conf和 ceph.client.admin.keyring从 Ceph-1 复制到 Controller 节点和 Cinder 存储节点的 /etc/ceph/目录下。
* 安装客户端:在 Cinder 存储节点上,必须安装 ceph-common包(Controller 节点通常也需要)。
sudo apt install ceph-common
2. 权限配置(关键区别)
这是核心区别。Controller 节点只需要"读"权限来查询状态,
而 Cinder 存储节点需要"写"权限来创建和删除块设备。
* Controller 节点:
* 保持 ceph.client.admin.keyring的默认权限即可(root:root),因为 cinder-api和 cinder-scheduler服务通常以 root 身份运行,只需要读取集群状态。
* Cinder 存储节点:
* 必须修改属主:cinder-volume服务通常以 cinder用户身份运行,因此需要将密钥环文件的属主改为 cinder。
在 Cinder 存储节点上执行
sudo chown cinder:cinder /etc/ceph/ceph.client.admin.keyring
sudo chmod 600 /etc/ceph/ceph.client.admin.keyring
3. 验证配置
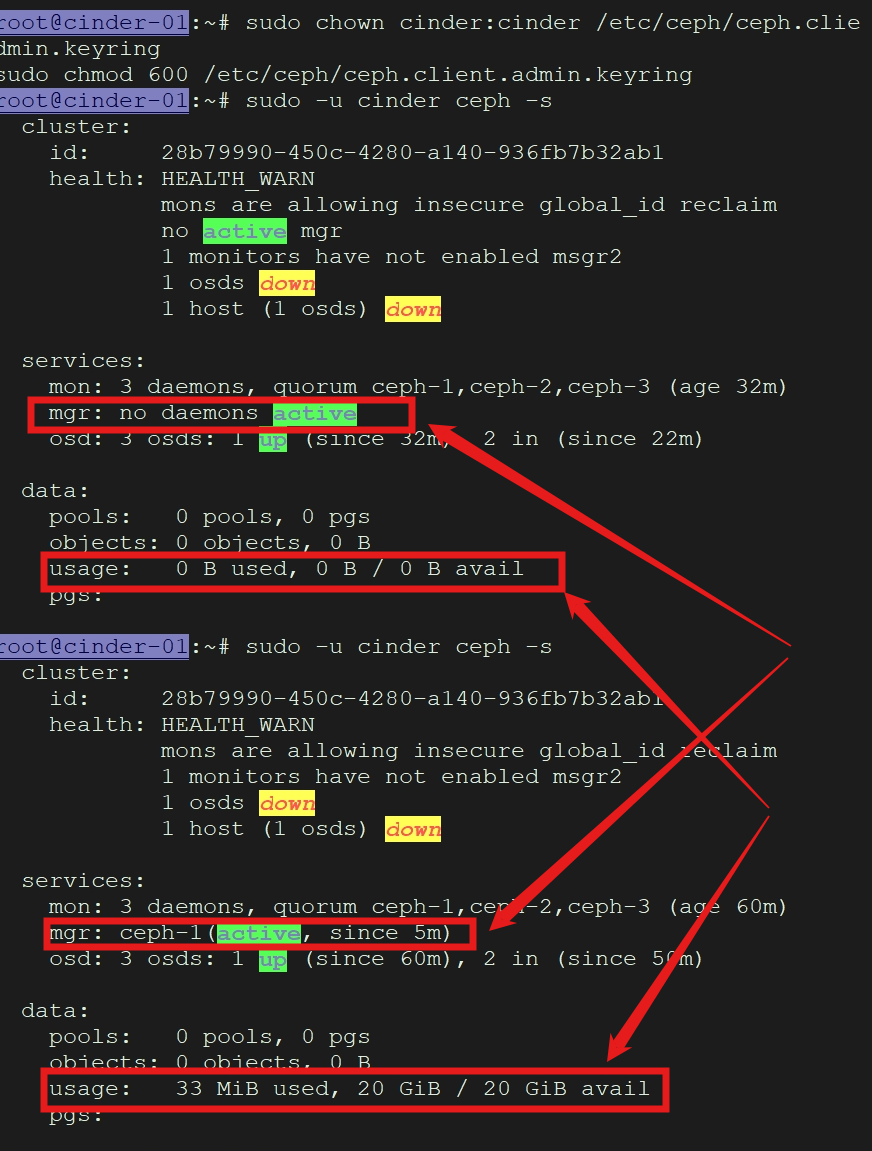
在 Cinder 存储节点上,切换到 cinder用户测试权限:
sudo -u cinder ceph -s
如果返回 HEALTH_OK,说明配置正确。如果报错"权限不足",请检查密钥环文件的属主和权限。 验证配置
在 Cinder 存储节点上,切换到 cinder用户测试权限:
基于你现有的 Ceph 集群(ceph-1/ceph-2/ceph-3),对接 OpenStack 主要涉及 配置 Ceph 客户端 、 创建存储池 、 配置 OpenStack 服务 以及 验证对接四个核心步骤。
以下是详细的对接流程:
1. 准备 Ceph 客户端配置
OpenStack 节点需要作为 Ceph 客户端访问集群,因此需要将 Ceph 管理节点的配置文件复制到所有 OpenStack 节点。
操作步骤:
- 获取配置文件:在 Ceph 管理节点(如 ceph-1)上,将 /etc/ceph/ceph.conf和 /etc/ceph/ceph.client.admin.keyring复制到所有 OpenStack 节点(如 Controller、Compute 节点)。
2. 设置权限:在 OpenStack 节点上,确保配置文件权限正确,通常需要 root或 nova用户可读。在 OpenStack 节点上执行
sudo chown root:root /etc/ceph/ceph.conf
sudo chown root:root /etc/ceph/ceph.client.admin.keyring
sudo chmod 644 /etc/ceph/ceph.conf
sudo chmod 600 /etc/ceph/ceph.client.admin.keyring
2. 创建 OpenStack 专用存储池
Ceph 使用存储池(Pool)来管理数据。你需要为 OpenStack 的不同服务创建专用的存储池。
操作步骤:
创建镜像池
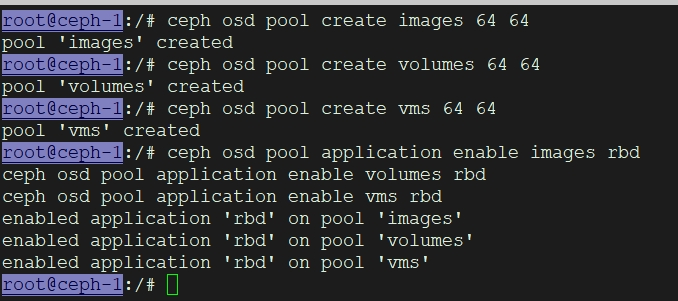
创建存储池 :在 Ceph 管理节点上,创建用于虚拟机镜像(Glance)、虚拟机磁盘(Cinder)和虚拟机临时磁盘(Nova)的存储池。
ceph osd pool create images 64 64
创建卷池
ceph osd pool create volumes 64 64
创建虚拟机池
ceph osd pool create vms 64 64
注: 64 是 PG(Placement Group)数量,具体数值需根据集群规模调整。
初始化池:为每个池启用 RBD(RADOS Block Device)功能。
ceph osd pool application enable images rbd
ceph osd pool application enable volumes rbd
ceph osd pool application enable vms rbd
在ceph管理节点创建(这里是ceph-1节点)
3. 配置 OpenStack 服务
接下来需要修改 OpenStack 各服务的配置文件,使其指向 Ceph 集群。
3.1 配置 Glance(镜像服务)
Glance 负责存储虚拟机镜像。配置它使用 Ceph 作为后端存储。
配置文件:/etc/glance/glance-api.conf
DEFAULTshow_image_direct_url = True
glance_storestores = rbd
default_store = rbd
rbd_store_pool = images
rbd_store_user = openstack
rbd_store_ceph_conf = /etc/ceph/ceph.conf
3.2 配置 Cinder(块存储服务)
Cinder 负责管理卷(Volume)。配置它使用 Ceph 作为后端驱动。
配置文件:/etc/cinder/cinder.conf
DEFAULTenabled_backends = ceph
glance_api_version = 2
cephvolume_driver = cinder.volume.drivers.rbd.RBDDriver
rbd_pool = volumes
rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_flatten_volume_from_snapshot = falserbd_max_clone_depth = 5rbd_store_chunk_size = 4rados_connect_timeout = -1
3.3 配置 Nova(计算服务)
Nova 负责运行虚拟机。配置它使用 Ceph 来存储虚拟机的临时磁盘(Ephemeral Disk)。
配置文件:/etc/nova/nova.conf
libvirtimages_type = rbd
images_rbd_pool = vms
images_rbd_ceph_conf = /etc/ceph/ceph.conf
disk_cachemodes = "network=writeback"rbd_user = openstack
guestfsdebug = True
###########补充详细说明#####################
修改需要 在不同的 OpenStack 服务节点上进行操作。以下是详细的操作节点说明:
📋 操作节点分布
|-----------------------------|----------------|-------------------------------------|--------------------------------------------------------------------------------------------------------|
| 配置文件 | 服务 | 操作节点 | 节点说明 |
| /etc/glance/glance-api.conf | Glance (镜像服务) | Controller 节点 | Glance API 服务通常部署在控制节点上。 |
| /etc/cinder/cinder.conf | Cinder (块存储服务) | Cinder 存储节点 和 Controller 节点 | 1. Cinder 存储节点:修改 ceph后端配置。 2. Controller 节点:如果运行了 cinder-scheduler或 cinder-api,也需要确保配置一致。 |
| /etc/nova/nova.conf | Nova (计算服务) | 所有 Compute 节点 | 每个运行虚拟机的计算节点都需要配置,以使用 Ceph RBD 作为镜像后端。 |
🔧 详细操作步骤
第一步:在 Controller 节点上配置 Glance
- 登录 Controller 节点 (ssh root@controller-ip)。
2. 备份原始配置:
sudo cp /etc/glance/glance-api.conf /etc/glance/glance-api.conf.bak
3. 编辑配置文件:
sudo nano /etc/glance/glance-api.conf
4. 添加或修改以下部分(使用你提供的配置):
DEFAULTshow_image_direct_url = True
glance_storestores = rbd
default_store = rbd
rbd_store_pool = images
rbd_store_user = openstack
rbd_store_ceph_conf = /etc/ceph/ceph.conf
5. 重启 Glance 服务:
sudo systemctl restart glance-api
第二步:在 Cinder 存储节点上配置 Cinder
- 登录 Cinder 存储节点 (ssh root@cinder-storage-ip)。
2. 备份原始配置:
sudo cp /etc/cinder/cinder.conf /etc/cinder/cinder.conf.bak
3. 编辑配置文件:
sudo nano /etc/cinder/cinder.conf
4. 在 DEFAULT 部分确保有:
DEFAULTenabled_backends = ceph
glance_api_version = 2
5. 添加 ceph 后端配置:
cephvolume_driver = cinder.volume.drivers.rbd.RBDDriver
rbd_pool = volumes
rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_flatten_volume_from_snapshot = falserbd_max_clone_depth = 5rbd_store_chunk_size = 4rados_connect_timeout = -1
6. 重启 Cinder Volume 服务:
sudo systemctl restart cinder-volume
第三步:在所有 Compute 节点上配置 Nova
- 登录每个 Compute 节点 (ssh root@compute-X-ip)。
2. 备份原始配置:
sudo cp /etc/nova/nova.conf /etc/nova/nova.conf.bak
3. 编辑配置文件:
sudo nano /etc/nova/nova.conf
4. 在 libvirt 部分添加:
libvirtimages_type = rbd
images_rbd_pool = vms
images_rbd_ceph_conf = /etc/ceph/ceph.conf
disk_cachemodes = "network=writeback"rbd_user = openstack
5. 在 guestfs 部分添加(可选,用于调试):
guestfsdebug = True
6. 重启 Nova Compute 和 Libvirt 服务:
sudo systemctl restart nova-compute
sudo systemctl restart libvirtd
⚠️ 重要前提条件
在执行上述配置 之前,请确保已完成以下步骤:
- Ceph 客户端安装:所有需要连接 Ceph 的节点(Controller, Cinder, Compute)都已安装 ceph-common软件包。
- Ceph 配置文件复制:/etc/ceph/ceph.conf和 /etc/ceph/ceph.client.openstack.keyring文件已从 Ceph 集群复制到所有上述节点。
3. Ceph 存储池创建:在 Ceph 集群中已创建对应的存储池:
ceph osd pool create images 128
ceph osd pool create volumes 128
ceph osd pool create vms 128
ceph osd pool application enable images rbd
ceph osd pool application enable volumes rbd
ceph osd pool application enable vms rbd
4. Ceph 客户端用户:确保已创建 openstack用户并授权访问上述池:
ceph auth get-or-create client.openstack mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=images, allow rwx pool=volumes, allow rwx pool=vms'
✅ 验证配置
配置完成后,建议进行验证:
- Glance:上传一个镜像,检查是否在 Ceph 的 images池中创建了对应对象。
- Cinder:创建一个卷,检查是否在 volumes池中生成。
- Nova:启动一个实例,检查其磁盘是否在 vms池中。
总结 :你需要分别在 Controller、Cinder 存储节点和所有 Compute 节点 上操作对应的配置文件。务必按顺序并确保前提条件满足。
#########################################
4. 创建 Ceph 客户端用户
OpenStack 服务需要通过 Ceph 用户进行身份验证。你需要为 OpenStack 创建一个专用的客户端用户。
操作步骤:
创建用户:在 Ceph 管理节点上,创建名为 client.openstack的用户,并授予其对三个存储池的读写权限。
ceph auth get-or-create client.openstack mon 'profile rbd' osd 'allow rwx pool=images, allow rwx pool=volumes, allow rwx pool=vms'
导出密钥:将生成的密钥导出到文件,并分发到所有 OpenStack 节点。
ceph auth get-key client.openstack | sudo tee /etc/ceph/ceph.client.openstack.keyring
设置权限:在 OpenStack 节点上,确保 nova和 cinder用户能读取该密钥。
sudo chown nova:nova /etc/ceph/ceph.client.openstack.keyring
sudo chown cinder:cinder /etc/ceph/ceph.client.openstack.keyring
5. 重启服务与验证
完成配置后,重启 OpenStack 相关服务并验证对接是否成功。
重启服务:
sudo systemctl restart glance-api
sudo systemctl restart cinder-volume
sudo systemctl restart nova-compute
验证对接:
- 创建测试卷:在 OpenStack 中创建一个卷,检查 Ceph 集群的 volumes池中是否出现对应的 RBD 镜像。
- 查看集群状态:在 Ceph 管理节点执行 ceph -s,确认集群状态为 HEALTH_OK,且 OSD 使用率正常。
注意事项
- 网络连通性:确保 OpenStack 节点与 Ceph 集群之间的网络(通常是存储网络)通畅,且防火墙规则允许 Ceph 客户端端口(通常为 6789 等)的通信。
- 性能调优:在生产环境中,可能需要对 Ceph 的 CRUSH Map 进行调优,或者为 OpenStack 服务配置专用的 Ceph 缓存层(Cache Tiering)以提升性能。