1 单选题(每题 2 分,共 30 分)
第1题 下列关于 C++ 中类的描述,正确的是( )。
A. 如果类没有用户声明的构造函数,那么编译器会隐式声明一个默认构造函数
B. 类的析构函数可以被重载,一个类可以有多个析构函数
C. 类中的所有成员都必须声明为 public
D. 类和结构体在 C++ 中没有区别,包括默认访问权限也相同
解析:答案A。在C++中,如果用户未声明任何构造函数(包括默认构造函数、拷贝构造函数等),编译器会自动隐式声明一个默认构造函数(无参构造函数)。该构造函数用于初始化对象,但不会初始化内置类型成员(如 int、float 等),仅处理类类型成员的默认构造,所以选项A正确。在C++中,析构函数不能被重载,一个类只能有一个析构函数,所以选项B错误。在C++中,类成员可以声明为 public、protected 或 private,且默认访问权限是 private(即未显式指定时,成员默认为私有),所以选项C错误。类和结构体在C++中的关键区别是默认访问权限:类(class)成员默认为 private,而结构体(struct)成员默认为 public。此外,结构体在C++中虽支持构造函数、继承等特性,但通常用于纯数据聚合,而类更强调封装和行为绑定,所以选项D错误。故选A。
第2题 下列代码中, s1->draw(); 和 s2->draw(); 输出不同结果的主要原因是( )。
cpp
class Shape {
public:
virtual void draw() {
cout << "绘制图形" << endl;
}
virtual ~Shape() {}
};
class Circle : public Shape {
public:
void draw() override {
cout << "绘制圆形" << endl;
}
};
class Rectangle : public Shape {
public:
void draw() override {
cout << "绘制矩形" << endl;
}
};
int main() {
Shape* s1 = new Circle();
Shape* s2 = new Rectangle();
s1->draw();
s2->draw();
delete s1;
delete s2;
return 0;
}A. draw() 是普通成员函数
B. Shape 中的 draw() 被声明为虚函数
C. Circle 和 Rectangle 中使用了 public 继承
D. 指针变量名不同
解析:答案B。虚函数是实现多态的核心机制,它确保通过基类指针调用函数时,根据实际对象类型动态分派到正确的派生类实现。在代码中,s1->draw() 和 s2->draw() 分别输出"绘制圆形"和"绘制矩形",而非基类Shape的"绘制图形",这源于C++的多态性机制。draw() 是虚函数,不是普通成员函数,所以选项A错误。Shape中的draw()被声明为虚函数,虚函数是实现多态的核心机制,所以选项B正确。Circle和Rectangle中使用了public继承,public继承是派生类重写基类函数的必要条件,若无虚函数声明,public 继承本身无法实现多态,所以选项C错误。指针变量名(s1和s2)仅影响标识符,与函数调用行为无关,所以选项D错误。故选B。
第3题 下面的代码在 main() 中有一行会导致编译错误,请找出来。
cpp
class Pet {
public:
Pet(string n, int a) : name(n), age(a) {}
string getName() { return name; }
void birthday() { age++; }
private:
string name;
int age;
};
int main() {
Pet cat("奶茶", 2);
cout << cat.getName(); // ①
cat.birthday(); // ②
cat.name = "大橘"; // ③
cout << cat.getName(); // ④
}A. 第①行
B. 第②行
C. 第③行
D. 第④行
解析:答案C。调用公有方法getName()访问name,合法,所以选项A正确。调用公有方法birthday()修改age,合法,所以选项B正确。直接访问私有成员name,违反封装规则,编译器报错(类似error: 'name' is private within this context),所以选项C会导致编译错误。调用公有方法getName()访问name,合法,所以选项D正确。故选C。
第4题 游乐园的过山车每次限坐 4 人,用循环队列管理排队(容量 MAX=5 ,空一格判满)。下面代码执行后,循环队列是否已满? rear 的值是多少?
cpp
const int MAX = 5;
int queue[MAX];
int front = 0, rear = 0;
// 入队
void enqueue(int x) {
queue[rear] = x;
rear = (rear + 1) % MAX;
}
// 出队
void dequeue() {
front = (front + 1) % MAX;
}
int main() {
enqueue(1); enqueue(2); enqueue(3); enqueue(4);
dequeue(); dequeue();
enqueue(5); enqueue(6);
}A. 已满, rear = 1
B. 未满, rear = 1
C. 已满, rear = 2
D. 未满, rear = 4
解析:答案A。根据题目描述的循环队列操作过程逐步分析:
初始状态:front = 0, rear = 0,队列为空。
容量为MAX=5,但为了区分队满和队空,牺牲一个位置,因此实际可容纳4个元素。
入队操作:enqueue(1) → rear = 1
继续入队:enqueue(2) → rear = 2
继续入队:enqueue(3) → rear = 3
继续入队:enqueue(4) → rear = 4
此时队列中已有 4 个元素,再入队前需判断是否已满。此时 rear = 4,下一个位置是 (rear + 1) % MAX = 0,而 front = 0,所以 (rear + 1) % MAX == front,表示队列已满。
然后执行两次出队:dequeue() → front = 1;再执行一次 dequeue() → front = 2
此时队列中还剩 2 个元素,front = 2, rear = 4
再次入队:enqueue(5) → rear = 0
再次入队:enqueue(6) → rear = 1
此时队列中已有4个元素(从位置2到1),front = 2, rear = 1,再次判断是否满:(rear + 1) % MAX = 2,front = 2,所以 (rear + 1) % MAX == front,队列已满。
最终状态:队列已满,rear = 1,选项A正确。
第5题 在以下计算机系统应用场景中,最适合使用循环队列的是( )。
A. 函数调用过程中,保存局部变量和返回地址
B. 表达式求值中的运算符优先级处理
C. 操作系统中的进程优先级调度(高优先级先执行)
D. 生产者和消费者问题中的共享缓冲区
解析:答案D。循环队列是一种基于数组实现的先进先出(FIFO)结构,其核心优势在于可以循环利用存储空间,避免普通队列中的"假溢出"问题。在实际应用中,特别适用于需要高效地进行数据入队和出队操作,并且对内存使用效率有要求的场景。
选项A. 函数调用过程中,保存局部变量和返回地址,这是栈的作用,不是队列,所以错误。选项B. 表达式求值中的运算符优先级处理,通常使用栈来处理,比如中缀转后缀表达式,所以不正确。选项C. 操作系统中的进程优先级调度(高优先级先执行),这属于优先队列或调度算法的范畴,不是普通循环队列,所以也不正确。选项D. 生产者和消费者问题中的共享缓冲区,这正是循环队列的典型应用场景。生产者不断向缓冲区写入数据,消费者从缓冲区取出数据。循环队列能高效地复用缓冲区空间,非常适合这种场景,所以正确。故选D。
第6题 在二叉搜索树(BST)中,若中序遍历的序列为{1, 2, 3, 4, 5},且先序遍历的第一个序列元素为3,则下列说法正确的是( )。
A. 该树一定是一棵完全二叉树。
B. 元素4和5不可能是兄弟节点。
C. 元素1所在节点的深度可能大于3(根节点深度为1)。
D. 元素2一定是元素1的父节点。
解析:答案B。在二叉搜索树(BST)中,中序遍历结果为 {1, 2, 3, 4, 5},说明这是一棵严格递增的有序树,即节点值按升序排列。而先序遍历的第一个元素是3,意味着3是根节点。
中序遍历:左子树 → 根 → 右子树 → {1, 2, 3, 4, 5}
先序遍历:根 → 左子树 → 右子树 → 第一个元素是3 → 所以根=3
因此:左子树中序:{1, 2}; 右子树中序:{4, 5}
再根据先序遍历,根之后的元素是左子树的根。
先序序列以3开头,接下来一定是左子树的根(因为左子树非空),然后是右子树。
所以左子树的先序是 {1, 2},右子树的先序是 {4, 5}。 → 左子树:根=1,中序={1,2} → 说明2是1的右孩子 → 右子树:根=4,中序={4,5} → 说明 5 是 4 的右孩子。也可能左子树:根=2,中序={1,2} → 说明1是2的左孩子 → 右子树:根=5,中序={4,5} → 说明4是5的左孩子。因此,可能的树结构有四种(如图1所示):

图1 可能的四种树结构
注意:由于是BST,每个节点的左子树所有值 < 节点值,右子树所有值 > 节点值。
无论是哪个结构均不能构成完全二叉树(完全二叉树要求:除最后一层外,其他层全满,且最后一层节点从左到右连续排列),选项A错误。兄弟节点意味着同一父节点的两个子节点,根据BST性质和遍历序列,存在四种结构,4和5都父子关系,不是兄弟节点,所以选项B正确。如元素1是左子树的根,其父节点是3,深度=2;如元素2是1的右孩子,深度=3,不超过3,所以选项C错误。元素2可能是元素1的父节点,也可能是元素1的右孩子节点,所以选项D错误。故选B。
第7题 某二叉树共有10个结点,记为A~J,已知它的先序遍历序列为:A B D H I E C F J G,中序遍历序列为:H D I B E A F J C G,则该二叉树的后序遍历序列是( )。
A. H I D E B J F G C A B. H I D B E J F G C A
C. I H D E B J F G C A D. H I D E B F J G C A
解析:答案A。
先序遍历:根 → 左子树 → 右子树 → 第一个元素是A → 所以根=A
中序遍历:左子树 → 根 → 右子树 → H D I B E【A】F J C G
先序遍历:左子树 → B D H I E →根=B,中序遍历:左子树→ H D I【B】E,右子树→ E
先序遍历:左左子树 → D H I → 根=D,中序遍历:左左子树→ H【D】I
所以左树如图2(1)所示。
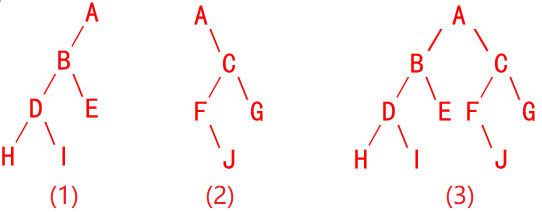
图2 按先序遍历、中序遍历构建的子树和树
先序遍历:右子树 → C F J G → 根=C,中序遍历:右子树→F J【C】G,右右子树→ G
先序遍历:右左子树 → F J → 根=F,中序遍历:右左子树→【F】J,右左右子树→ J
所以右树如图2(2)所示。合并后的树如图2(3)所示。
后序遍历次序为:左子树 → 右子树 → 根。由图2(3)得后序遍历为HIDEBJFGCA,与选项A一致。故选A。
第8题 下列关于树的遍历的说法中,正确的一项是( )。
A. 对任意一棵树进行深度优先遍历,所得序列一定唯一。
B. 已知一棵二叉树的先序遍历和后序遍历序列,可以唯一确定这棵二叉树。
C. 已知一棵二叉树的先序遍历和中序遍历序列,可以唯一确定这棵二叉树。
D. 已知一棵二叉树的先序遍历序列,可以唯一确定这棵二叉树。
解析:答案C。树的深度优先遍历序列取决于子节点访问顺序(如前序遍历、中序遍历等),故不唯一,选项A错误。当存在度为1的节点(仅一个子节点)时,无法区分该子节点是左孩子还是右孩子(如先序A B、后序B A对应两种结构)选项B错误。先序遍历(根→左→右)的首元素为根节点,中序遍历(左→根→右)通过根节点划分左右子树。递归应用此逻辑,可唯一确定二叉树结构,选项B正确。先序序列仅能确定根节点,无法划分左右子树边界(如先序A B可对应A的左孩子为B,或A的右孩子为B),选项D错误。故选C。
第9题 有 6 个字符,它们出现的次数分别为: {2, 3, 3, 4, 6, 8} ,现在用哈夫曼编码为这些字符编码,最小加权路径长度WPL(每个字符的出现次数×它的编码长度,再把每个字符结果加起来)的值为( )。
A. 58 B. 60 C. 62 D. 64
解析:答案D。设这六个字符为A, B, C, D, E, F,其出现频率为2, 3, 3, 4, 6, 8。先合并低频。A、B合并为5(新节点5)>4,C、D合并为7(新节点7)>6>5,5、E合并为11(新节点11)>8>7,7、F合并为15(新节点15)>11,11、15合并为26(新节点26),构成如图3所示哈夫曼树。
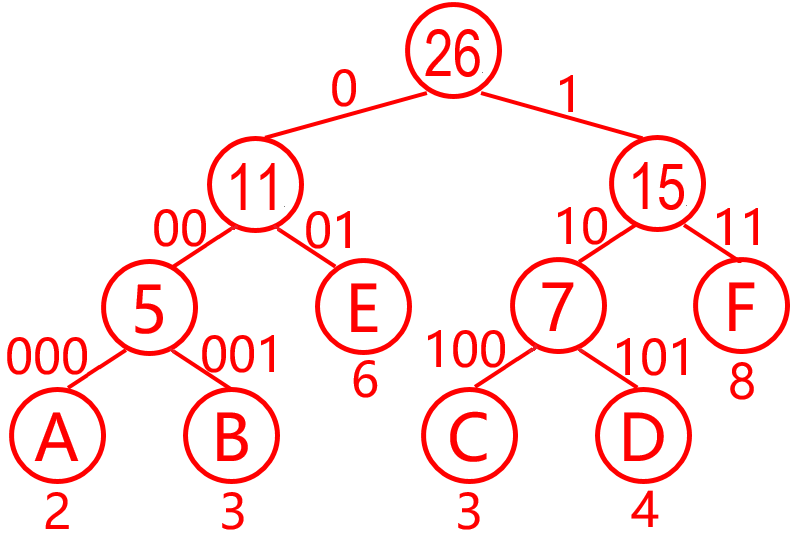
图3 按第9题数据构建哈夫曼树
WPL=2*3+3*3+3*3+3*4+6*2+8*2=64,所以选D。
第10题 对𝑛个不同符号的符号进行哈夫曼编码。若生成的共有115个结点,则𝑛的值是( )。
A. 60 B. 58 C. 57 D. 56
解析:答案B。根据哈夫曼树的性质,对于n个互不相同的符号(对应哈夫曼树的叶子结点),生成的哈夫曼树满足:总结点数=2n−1。题目给定总结点数为115,代入公式:
2n−1=115
解得:
2n=116 → n=58
所以选项B正确。故选B。
第11题 关于格雷编码(Gray Code),下列说法正确的是( )。
A. 格雷编码中,编码位数越多,相邻编码之间变化的位数也越多
B. 格雷编码中,相邻两个编码的二进制位恰好有一位不同
C. 格雷编码就是把普通二进制编码按位取反后得到的结果
D. 格雷编码不能用于数字电路和状态转换的设计中
解析:答案B。格雷编码(Gray Code)是一种二进制编码方式,其核心特点是:任意两个相邻的代码仅有一位二进制数不同。这种特性使其在数字系统中具有高可靠性,广泛应用于模拟-数字转换、位置检测、通信系统等领域。符合的只有选项B。故选B。
第12题 给定一棵二叉树,采用广度优先搜索 (BFS) 算法,返回右视图所有节点的值。其中右视图定义为:二叉树的右视图是从树的右侧看过去时可见的节点集合,即右视图中的每个节点都是某一层中最右侧的节点。
cpp
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x): val(x), left(nullptr), right(nullptr) {}
};
vector<int> rightSideView(TreeNode* root) {
unordered_map<int, int> rightmostValueAtDepth;
int max_depth = -1;
queue<TreeNode*> nodeQueue;
queue<int> depthQueue;
nodeQueue.push(root);
depthQueue.push(0);
while (!nodeQueue.empty()) {
TreeNode* node = nodeQueue.front(); nodeQueue.pop();
int depth = depthQueue.front(); depthQueue.pop();
if (node != NULL) {
max_depth = max(max_depth, depth);
rightmostValueAtDepth[depth] = node->val;
nodeQueue.push(node->left);
nodeQueue.push(node->right);
depthQueue.push(________);
depthQueue.push(________);
}
}
vector<int> rightView;
for (int depth = 0; ________; ++depth) {
rightView.push_back(rightmostValueAtDepth[depth]);
}
return rightView;
};A.
cpp
depth
depth
depth < max_depthB.
cpp
depth + 1
depth + 1
depth <= max_depthC.
cpp
depth + 1
depth + 1
depth < max_depthD.
cpp
depth
depth
depth <= max_depth解析:答案B。根据给定的BFS算法实现二叉树的右视图,代码中需要填充三个空白部分。
子节点深度入队(前两个空白),在BFS遍历中,当前节点node的深度为depth,其子节点(左孩子或右孩子)位于下一层,深度应为depth+1。当将子节点加入nodeQueue时,其对应的深度必须为depth+1入队到depthQueue。如果填入depth(如选项A或选项D),则子节点深度与父节点相同,导致层级错误,遍历逻辑混乱。for 循环条件(第三个空白):max_depth记录了树的最大深度(从 0 开始,根节点深度为 0)。结果向量rightView需要包含从深度0到max_depth(包含max_depth)的所有最右侧节点值。
条件depth<=max_depth确保深度范围覆盖完整(例如,当max_depth=0时,depth<=0会执行depth=0;而depth<max_depth会跳过深度0)。如果填入depth<max_depth(如选项C),则当max_depth为有效深度时,最后一层节点会被遗漏。故选B。
第13题 下列关于树的深度优先搜索(DFS)的说法中,正确的是( )。
A. 对树进行 DFS 时,一定是按层从上到下依次访问结点
B. 对任意一棵树进行 DFS,得到的遍历序列唯一
C. 对一棵树进行 DFS 时,常借助递归或栈实现
D. DFS 只能用于二叉树,不能用于普通树
解析:答案C。按层遍历是广度优先搜索(BFS)的特性,二叉树的DFS可能先访问根节点→左子树深节点→回溯后访问右子树,而非从上到下逐层访问,所以选项A错误。DFS遍历序列序列取决于遍历方式(先序、中序、后序)、子节点访问顺序(如多叉树中子节点顺序未指定)及实现细节,所以选项B错误。DFS的核心逻辑是尽可能深地探索分支(沿一条路径向下访问至叶子节点,再回溯),递归利用函数调用栈隐式管理节点访问顺序,而显式栈(如stack数据结构)则手动模拟这一过程,确保后进先出(LIFO)的遍历特性,所以选项C正确。DFS是通用算法,适用于二叉树、多叉树(普通树)及图结构,所以选项D错误。故选C。
第14题 小朋友们去邻里拜年,每个家里有不同数量的糖果。规则是:不能连续进入两个相邻的房子(即不能同时取相邻两家的糖果)。目标是拿到最多糖果。以下是代码实现,请补全横线。
cpp
int visit(vector<int>& nums) {
if (nums.empty()) {
return 0;
}
int size = nums.size();
if (size == 1) {
return nums[0];
}
vector<int> dp = vector<int>(size, 0);
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < size; i++) {
dp[i] = ______; // 在此处填写代码
}
return dp[size - 1];
}A. dpi = dpi - 1 + numsi;
B. dpi = max(dpi - 1, dpi - 2 * numsi);
C. dpi = max(dpi - 1, dpi - 2 + numsi);
D. dpi = dpi - 2 + numsi;
解析:答案C。选项A,未考虑相邻限制(若取numsi,不能同时取numsi-1,但这里强制添加了numsi,可能导致违反规则),故错误。选项B,问题要求求和而非乘积,乘法不符合逻辑,故错误。选项C,不取numsi:则最大和为dpi-1(继承前一个状态)。取numsi:则不能取numsi-1(因相邻禁止),因此最大和为dpi-2+numsi(跳过前一个元素);因此,dpi应取这两种情况的最大值:max(dpi-1,dpi-2+numsi);完整覆盖两种选择,确保状态转移合理,所以正确。选项D,未考虑不取numsi的情况(dpi - 1可能更大),所以错误。故选 C。
第15题 元宵节晚上,小朋友沿着一条发光石板路前进,每次可向前走 1 块或 2 块石板。动态规划定义如下:
dpi = dpi - 1 + dpi - 2 ,下面关于 dpi 的含义最合适的是( )。
A. 走到第i 块石板的不同走法数量
B. 走到第i 块石板时,已经走过的石板总数
C. 从第i 块石板走回起点的最少步数
D. 从第i 块石板走回起点的最大步数
解析:答案A。对于题目中动态规划定义dpi=dpi−1+dpi−2,在小朋友走石板路的场景下,dpi的含义是走到第i块石板的不同走法数量(可以在前1个块石板跨1块石板走到i块石板,或在前2个块石板跨2块石板走到i块石板,这两种走法的数量和),选项A正确。dpi是一个固定数值(表示方法数),而非累计石板数,实际走过的石板数取决于具体路径,无法由简单递推得出,选项B错误。方程描述的是从起点正向移动到第i块石板的过程,而非反向返回起点,所以选项C、D错误。故选A。
2 判断题(每题 2 分,共 20 分)
第1题 下面定义了一个表示二维坐标点的类 Point , 并提供了一个带参数的构造函数,但第②行 Point b; 会调用编译器自动生成的默认构造函数,将 b.x 和 b.y 被初始化为 0.0,程序可以正常编译运行。
cpp
class Point {
public:
double x, y;
Point(double px, double py) : x(px), y(py) {}
void print() {
cout << "(" << x << ", " << y << ")";
}
};
int main() {
Point a(3.0, 4.0); // ①
Point b; // ②
a.print();
}解析:答案错误(╳)。在C++中,当类中显式定义了任何构造函数(如有参构造函数)时,编译器不再自动生成默认的无参构造函数。在提供的代码中,Point类定义了一个带参数的构造函数Point(double px, double py),因此编译器不会生成默认的无参构造函数。第②行 Point b; 试图调用默认无参构造函数,但由于该类没有可用的默认构造函数,此代码会导致编译错误(错误信息通常为"没有合适的默认构造函数可用"或类似提示)。此外,即使默认构造函数被调用,内置类型成员变量(如 double x, y;)不会被自动初始化为0.0;其值将是未定义的(持有随机值)。程序无法正常编译运行,故错误。
第2题 C++ 中的继承支持单继承和多继承,但子类无法直接访问父类的私有成员。
解析:答案正确(√)。C++ 中的继承机制允许单继承(一个子类继承一个父类)和多继承(一个子类继承多个父类)。然而,无论继承方式如何(公有继承、保护继承或私有继承),子类均无法直接访问父类的私有成员(private members)。这是因为私有成员被严格封装在父类内部,只能通过父类自身的成员函数访问,以保障数据安全性和封装性。故正确。
第3题 对如下结构的树,执行 travel 函数,输出结果是 1 2 3 4 5 。
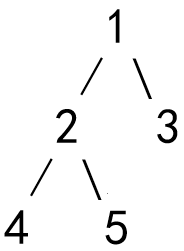
cpp
struct Node {
int val;
Node *left, *right;
Node(int v) : val(v), left(nullptr), right(nullptr) {}
};
void travel(Node* root) {
if (!root) return;
stack<Node*> s;
s.push(root);
while (!s.empty()) {
Node* cur = s.top(); s.pop();
cout << cur->val << " ";
if (cur->right) s.push(cur->right);
if (cur->left) s.push(cur->left);
}
}解析:答案错误(╳)。题目提供的 travel 函数使用栈(stack) 实现深度优先搜索(DFS),但其访问顺序是先右后左 的先序遍历 (根-右-左),而非一般"从左到右"的前序遍历(根-左-右),实际输出为1 3 2 5 4,故错误。
第4题 若所有字符出现频率相同,则哈夫曼编码一定会得到完全二叉树。
解析:答案错误(╳)。若所有字符出现频率相同,哈夫曼编码不一定得到完全二叉树,它得到的是一棵最优二叉树,但不保证是"完全二叉树"。哈夫曼编码是一种贪心算法,其目标是构建一棵带权路径长度最短的二叉树(即最优二叉树),使得高频字符编码短、低频字符编码长,从而实现无损压缩。当所有字符频率完全相同时,任意两个节点合并的代价都相等,因此合并顺序不唯一,最终生成的树结构可能有多种。故错误。
第5题 哈夫曼编码是一种变长的前缀编码,在解码时不需要额外的分隔符就能唯一还原,这是因为在哈夫曼树中,任何一个字符的叶子结点都不会成为另一个字符结点的祖先。
解析:答案正确(√)。哈夫曼编码通过构建一棵最优二叉树(带权路径长度最小),将每个字符映射为从根到叶子的路径(左0右1),最终得到一组变长二进制编码。关键在于:所有字符都位于叶子节点;每个叶子节点代表一个唯一字符;内部节点不对应任何字符;因此,没有任何一个字符的编码路径是另一个字符编码路径的延伸------换句话说,没有哪个叶子是另一个叶子的祖先。所以正确。
第6题 在 C++ 中使用一维数组 vector<int> tree 存储按层序遍历的完全二叉树时,若根节点存储在tree0 ,则对于任意非空节点 treei ,其右孩子(如果存在)必然位于 tree2 \* i + 2 。
解析:答案正确(√)。在完全二叉树的层序遍历存储中,使用一维数组vector<int>时,若根节点位于索引0(tree),则节点间的父子关系由索引算术规则确定:左孩子索引:2*i+1;右孩子索引:2*i+2;这一规则基于完全二叉树的数学特性:层序连续性:完全二叉树的节点按层级顺序连续存储,无空洞,因此索引计算直接有效。索引推导:根节点(i=0)的右孩子位于2*0+2=2(即tree),节点i=1的右孩子位于2*1+2=4(即tree),通用公式2*i+2覆盖所有非根节点。故正确。
第7题 在 C++ 中使用栈来非递归地实现二叉树的前序遍历时,为了保证遍历顺序正确,在处理完当前结点后,应该先将该结点的左孩子压入栈中,然后再将右孩子压入栈中。
解析:答案错误(╳)。在非递归前序遍历中,遍历顺序必须遵循 根节点 → 左子树 → 右子树 的原则。栈作为后进先出(LIFO)的数据结构,要求压栈顺序与期望的访问顺序相反:正确顺序是先将右孩子压入栈中,再将左孩子压入栈中。如:弹出当前结点后,先压右孩子、再压左孩子,以保证左孩子先被处理。若先将左孩子压栈,再将右孩子压栈:右孩子后压入栈,位于栈顶,会先于左孩子被弹出访问导致访问顺序变为:根节点 → 右子树 → 左子树,违反前序遍历要求。故错误。
第8题 设二叉树共有𝑛个结点,函数 preorderTraversal 以下代码的时间复杂度为𝑂(𝑛),空间复杂度为𝑂(𝑛)。
cpp
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x): val(x), left(nullptr), right(nullptr) {}
};
void preorder(TreeNode *root, vector<int> &res) {
if (root == nullptr) {
return;
}
res.push_back(root->val);
preorder(root->left, res);
preorder(root->right, res);
}
vector<int> preorderTraversal(TreeNode *root) {
vector<int> res;
preorder(root, res);
return res;
};解析:答案正确(√)。函数 preorderTraversal 执行二叉树的先序遍历,每个节点被访问且仅被访问一次。具体操作(如 res.push_back(root->val) 和递归调用)均为常数时间𝑂(1)。
对于𝑛个节点的二叉树,总操作次数为𝑛次,因此时间复杂度为𝑂(𝑛)。递归栈空间:递归调用时系统隐式维护调用栈,最坏情况下(二叉树退化为链状,如所有节点只有左子树或右子树),栈深度为𝑛,占用𝑂(𝑛)空间。平均情况下(树平衡),栈深度为𝑂(log 𝑛),但大𝑂记法以最坏情况为准,因此为𝑂(𝑛)。输出存储空间:结果向量res存储所有𝑛个节点的值,占用𝑂(𝑛)空间。
总空间复杂度为递归栈与输出空间之和,即𝑂(𝑛)+ 𝑂(𝑛)= 𝑂(𝑛)。
第9题 下列代码实现了一个0-1背包的一维动态规划代码,内层循环是经典的逆序写法。若将内层循环改成正序遍历(即 for (int j = wi; j <= W; j++) ),仍能得到正确答案。
cpp
int main() {
int W = 5;
int w[] = {2, 3, 4};
int v[] = {10, 1, 1};
int n = 3;
int dp[6] = {0};
for (int i = 0; i < n; i++) {
for (int j = W; j >= w[i]; j--) { // ← 逆序!
dp[j] = max(dp[j], dp[j - w[i]] + v[i]);
}
}
cout << dp[W];
}解析:答案错误(╳)。在于0-1背包问题的一维动态规划实现中,内层循环必须逆序遍历背包容量(从大到小),以确保每个物品只被选择一次。若改为正序遍历(从小到大),会导致物品被重复选择,从而错误地将问题转化为完全背包问题(物品可无限次使用),计算结果必然偏离正确值。故错误。
第10题 在动态规划问题中,状态空间相同且没有重复计算的情况下,"状态转移方程+递推"与"递归+记忆化搜索"的时间复杂度通常相同。
解析:答案正确(√)。正确。在状态空间相同且无重复计算的前提下,"状态转移方程+递推"与"递归+记忆化搜索"的时间复杂度通常完全相同,均为𝑂(状态数×单状态转移时间)。递推(迭代):从基础状态出发,按顺序计算所有状态,每个状态仅被访问一次。递归+记忆化:通过递归调用按需计算状态,首次遇到某状态时计算并缓存,后续直接查表,避免重复。二者本质都是状态空间的遍历+缓存复用,只是执行顺序不同:递推是"自底向上"地填表;记忆化是"自顶向下"地按需填表。故正确。
3 编程题(每题 25 分,共 50 分)
3.1 编程题 1
- 试题名称:选数
- 时间限制:1.0 s
- 内存限制:512.0 MB
3.1.1题目描述
给定两个包含𝑛个整数的数组𝑎=𝑎₁, ⋯, 𝑎ₙ与𝑏=𝑏₁, ⋯, 𝑏ₙ。你需要指定若干下标𝑝₁<⋯<𝑝ₖ(1≤𝑘≤𝑛)使得以下条件成立:
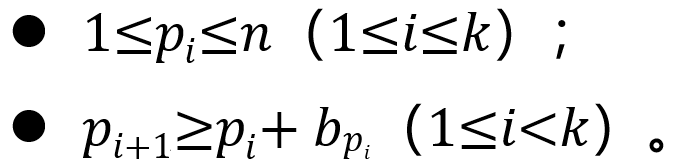
你需要在满足以上条件的前提下最大化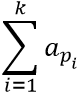 ,也即最大化数组 对应下标的整数之和。
,也即最大化数组 对应下标的整数之和。
3.1.2 输入格式
第一行,一个正整数𝑛,表示数组长度。
第二行,𝑛个正整数𝑎₁, 𝑎₂, ⋯, 𝑎ₙ,表示数组𝑎。
第三行,𝑛个正整数𝑏₁, 𝑏₂, ⋯, 𝑏ₙ,表示数组𝑏。
3.1.3 输出格式
一行,一个整数,表示在满足下标条件的前提下,数组𝑎对应下标的整数之和的最大值。
3.1.4 样例
3.1.4.1 输入样例 1
cpp
4
1 2 3 4
3 3 1 13.1.4.2 输出样例 1
cpp
73.1.4.3 输入样例 2
cpp
6
1 1 4 5 1 4
1 2 3 2 1 03.1.4.4 输出样例 2
cpp
113.1.5 数据范围
对于40%的测试点,保证2≤𝑛≤10³。
对于所有测试点,保证2≤𝑛≤10⁵,0≤𝑎ᵢ≤10⁹,0≤𝑏ᵢ≤𝑛。
3.1.6 编写程序
解析:本题要求在数组a和b中选取递增下标序列p₁<p₂<···<pₖ,且满足相邻下标间的跳跃约束pᵢ₊₁≥pᵢ+bpᵢ,目标是最大化所选下标的a值之和。
这是一个典型的动态规划问题,也是一道典型的动态规划 + 跳跃约束优化问题。
这道题的核心在于:从左到右遍历数组,对每个位置i,决定是否选择它作为序列中的一个点。若选择aᵢ,则下一个可选位置必须满足j≥i+bᵢ。不能随意跳过,必须确保前驱状态已计算完毕。
思路:动态规划+延迟更新
定义:dpi以位置i为最后一个选中元素时,所能获得的最大和。
状态转移:对于每个i,我们可以从所有满足j+bj<i的j转移而来,即:

也就是说,所有能"跳到"i的前驱j,取dpj最大值。
若没有合法前驱,则dpi=ai(仅选自己)。
但直接枚举所有j,因时间复杂度为𝑂(𝑛²),对𝑛≤10⁵ ,会超时,必须优化。
优化关键:用线段树或树状数组维护区间最大值
对每个位置i,关心的是:所有满足j+bj≤i的j中,dpj的最大值。
可以按i从1到n顺序计算dpi,同时维护一个数据结构,支持:
插入:当计算完dpj后,将它插入到位置j+bj(表示从j出发,可以影响到所有 ≥ j+bj 的位置)
查询:查询区间1, i 中所有已插入的dp值的最大值
这正是树状数组(Fenwick Tree) 或 线段树 的经典应用场景!
具体步骤:
初始化 dp0..n = 0
用一个树状数组维护"最大值",下标为"可被影响的起始位置"(即j+bj)
对于i从1到n:查询1, i区间内所有已激活的dpj的最大值(即所有j+bj≤i的j)
dpi=ai+query(i)
将dpi插入到树状数组的下标pos=i+bi处(如果i+bi>n,则插入到n+1)
最终答案 = max(dp1..n)
最终解决方案:线段树优化DP
使用线段树维护区间最大值,支持单点更新和区间查询。时空复杂度:
- 时间复杂度:𝑂(𝑛log𝑛)
- 空间复杂度:𝑂(𝑛)。
完整参考代码(洛谷AC)如下:
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int MAXN = 100010; // n≤10⁵
int n, a[MAXN], b[MAXN];
long long tree[MAXN], dp[MAXN], cnt = 0; // tree为树状数组,维护前缀最大值
void update(int idx, long long val) {
for (int i = idx; i <= n; i += i & -i)
tree[i] = max(tree[i], val);
}
long long query(int idx) { // 树状数组单点更新(取max)
long long res = 0;
for (int i = idx; i; i -= i & -i)
res = max(res, tree[i]);
return res;
}
int main() {
ios::sync_with_stdio(false); // 提高cin/cout效率
cin.tie(nullptr);
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i];
for (int i = 1; i <= n; i++) cin >> b[i];
for (int i = 1; i <= n; i++) {
long long prev_max = query(i); // 查询所有j+b[j]<=i的dp[j]的最大值
dp[i] = a[i] + prev_max;
cnt = max(cnt, dp[i]);
int next_pos = i + b[i]; // 将当前dp[i]插入到位置i+b[i],
if (next_pos > n) next_pos = n + 1; // 若超出n则插入n+1
update(next_pos, dp[i]);
}
cout << cnt << endl;
return 0;
}方法二
简化运算:当i从1到n,如dpi+1 = max(dpi+1, dpi); 此时dpi+1已是1. . .n+1中最大,也即dpi已是1. . .n中最大,则
dpi=ai+query(i)可改写为dpi=ai+dpi
若i+bi≤n则dpi+b\[i]=max(dpi+b\[i], dpi+ai); 否则不予处理(线段树指向n+1>n,也不处理)。
完整参考代码(洛谷AC)如下:
cpp
#include <iostream>
using namespace std;
const int N = 100010; // n≤10⁵
int n, a[N], b[N];
long long dp[N], cnt;
int main() {
ios::sync_with_stdio(false); // 提高输入输出效率
cin.tie(0);
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i]; // 输入数组A
for (int i = 1; i <= n; i++) cin >> b[i]; // 输入数组B
for (int i = 1; i <= n; i++) { // i相当于pᵢ
cnt = max(cnt, dp[i] + a[i]); // 先+自己(求和)。cnt为最大和
if (i + b[i] <= n) // 若pᵢ+b[pᵢ]为有效下标
dp[i + b[i]] = max(dp[i + b[i]], dp[i] + a[i]); // 取大者
dp[i + 1] = max(dp[i + 1], dp[i]); // 更新下一dp为到i最大者
}
cout << cnt << endl;
return 0;
}3.2 编程题 2
- 试题名称:完全二叉树
- 时间限制:1.0 s
- 内存限制:512.0 MB
3.2.1题目描述
给定一棵包含𝑛个结点的有根二叉树,结点依次以1, 2, ⋯, 𝑛编号,根结点编号为1。
对于结点𝑖,其左儿子的编号记为lᵢ,右儿子编号记为rᵢ。特别地,如果左儿子不存在则lᵢ=0,如果右儿子不存在则rᵢ=0。
树中每个结点都对应一棵以其为根的子树。请你求出给定有根树的所有𝑛棵子树中,有多少棵子树是完全二叉树。
3.2.2 输入格式
第一行,一个正整数𝑛,表示有根二叉树结点数量。
接下来𝑛行,每行两个正整数lᵢ, rᵢ,表示结点𝑖的左儿子编号和右儿子编号。
3.2.3 输出格式
输出一行,一个整数,表示所有子树中完全二叉树的数量。
3.2.4 样例
3.2.4.1 输入样例 1
cpp
4
2 3
4 0
0 0
0 03.2.4.2 输出样例 1
cpp
43.2.4.3 输入样例 2
cpp
4
2 3
0 0
4 0
0 03.2.4.4 输出样例 2
cpp
33.2.5 数据范围
对于40%的测试点,保证1≤𝑛≤500。
对于所有测试点,保证1≤𝑛≤10⁵。
3.2.6 编写程序
解析:判断一棵子树是否为完全二叉树,要明确两个重要概念:
(1)满二叉树:所有层的结点都被完全填满,即左右子树都是满二叉树且树的高度相同。
(2)完全二叉树:除最后一层外,所有层都被完全填满;最后一层的结点必须从左到右连续排列,不允许中间有空缺。
由于满二叉树的结构完全符合完全二叉树的定义,因此它是完全二叉树的一种特殊形式。
核心算法深度优先(dfs)采用后序遍历(先处理左右子树,再处理当前结点)
方法一:
思路:定义一个结点结构体保存结点信息。
cpp
struct TreeInfo {
int height; // 子树高度
bool isFull; // 是否为满二叉树
bool isComplete; // 是否为完全二叉树
};对每个结点,递归获取其左右子树是否满二叉树、是否完全二叉树,高度(从叶子到当前结点的层数)、是否为满二叉树(所有层完全填满)。然后根据表1规则判断当前子树是否为完全二叉树。

边界情况:空子树(高度为0)视为满二叉树和完全二叉树。如果当前子树是满二叉树或完全二叉树,则该子树判定为完全二叉树。
时间复杂度:每个结点仅访问一次 → 𝑂(𝑛)。适用于𝑛≤10⁵。
完整参考代码(洛谷AC)如下:
cpp
#include <iostream>
using namespace std;
const int MAXN = 100010; // n≤10⁵
// 定义返回结构:{高度, 是否为满二叉树, 是否为完全二叉树}
struct TreeInfo {
int height; // 子树高度
bool isFull; // 是否为满二叉树
bool isComplete; // 是否为完全二叉树
TreeInfo(int h = 0, bool f = true, bool c = true)
: height(h), isFull(f), isComplete(c) {}
};
int leftChild[MAXN], rightChild[MAXN]; // 存储每个节点的左右儿子
int cnt = 0; // 完全二叉树子树数(含满二叉树)
TreeInfo dfs(int node) { // 后序遍历递归函数:返回当前子树的信息
if (node == 0) { // 空节点
return TreeInfo(0, true, true);
}
TreeInfo left = dfs(leftChild[node]); // 递归获取左右子树信息
TreeInfo right = dfs(rightChild[node]);
int h_left = left.height, h_right = right.height;
bool left_full = left.isFull, right_full = right.isFull;
bool left_comp = left.isComplete, right_comp = right.isComplete;
bool isComplete = false, isFull = false; // 当前子树是否为完全/满二叉树
if (left_full && right_full) { // 情况1:左右子树都是满二叉树
if (h_left == h_right) { // 左右子树高度相等
isFull = true; // 是满二叉树
} else if (h_left == h_right + 1) { // 左子树高度=右子树高度+1
isComplete = true; // 是完全二叉树
}
} else if (left_full && right_comp && h_left == h_right) { // 情况2:左右子树等高 → 左子树满,右子树完全
isComplete = true; // 是完全二叉树
} else if (left_comp && right_full && h_left == h_right + 1) { // 情况3:左子树比右子树高1 → 左子树完全,右子树满
isComplete = true; // 是完全二叉树
} // 其他情况都不是完全二叉树
if (isComplete || isFull) cnt++; // 更新计数(某子树中完全二叉树或满二叉树)
return TreeInfo( // 返回当前节点的子树信息
max(h_left, h_right) + 1, // 高度 = 子树最大高度 + 1
isFull, // 是否为满二叉树
isComplete // 是否为完全二叉树
);
}
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i++) // 读取每个节点的左右儿子
cin >> leftChild[i] >> rightChild[i];
dfs(1); // 从根节点(编号1)开始后序遍历
cout << cnt << endl; // 输出完全二叉树子树总数
return 0;
}方案二:
思路:不用结构体,直接用变量简化。算法、判断条件同方法一。时间复杂度:每个结点仅访问一次 → 𝑂(𝑛)。适用于𝑛≤10⁵。
完整参考代码(洛谷AC)如下:
cpp
#include <iostream>
using namespace std;
const int MAXN = 100010; // n≤10⁵
int leftChild[MAXN], rightChild[MAXN]; // 存储每个节点的左右儿子
bool isComp[MAXN], isFull[MAXN]; // 标记以x为根的地叉树是否为完全/满二叉树
int h[MAXN], cnt = 0; // h为子树高度,cnt为结果(满+完全二叉树数)
void dfs(int node) { // 后序遍历递归函数dfs
if (node == 0) // 空节点(递归终止条件)
return;
int left = leftChild[node], right = rightChild[node];
dfs(left); // 递归获取左子树信息
dfs(right); // 递归获取右子树信息
h[node] = h[left] + 1; // 计算当前子树高度(左子树高度+1)
if (isFull[left] && isFull[right]) { // 情况1:左右子树都是满二叉树
if (h[left] == h[right]) { // 左右子树高度相等
isFull[node] = true; // 是满二叉树
} else if (h[left] == h[right] + 1) { // 左子树高度=右子树高度+1
isComp[node] = true; // 是完全二叉树
}
} else if (isFull[left] && isComp[right] && h[left] == h[right]) { // 情况2:左右子树等高 → 左子树满,右子树完全
isComp[node] = true; // 是完全二叉树
} else if (isComp[left] && isFull[right] && h[left] == h[right] + 1) { // 情况3:左子树比右子树高1 → 左子树完全,右子树满
isComp[node] = true; // 是完全二叉树
} // 其他情况都不是完全二叉树
if (isComp[node] || isFull[node]) cnt++;// 更新计数(某子树中完全二叉树或满二叉树)
}
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i++) // 读取每个节点的左右儿子
cin >> leftChild[i] >> rightChild[i];
h[0] = 0; isFull[0] = true; isComp[0] = true; // 空节点高度为0,为满/完全二叉树
dfs(1); // 从根节点(编号1)开始后序遍历
cout << cnt << endl; // 输出完全二叉树子树总数
return 0;
}