【CVPR2025】DefMamba突破固定扫描的枷锁的可变形视觉状态空间模型
1 . 研究背景:视觉 Mamba"刻舟求剑" 的困境
近年来,以 Mamba 为代表的状态空间模型(SSM)因其线性计算复杂度和强大的长程建模能力,成为挑战 Transformer 地位的有力竞争者 。然而,将一维的 SSM 应用于二维图像时,研究者们面临一个核心难题:如何将 2D 像素展平为 1D 序列?
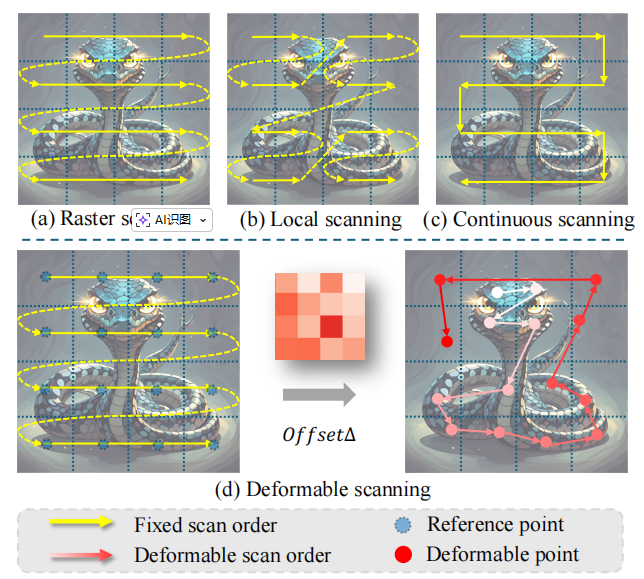
目前主流的方法,如光栅扫描(Raster scanning)、局部扫描(Local scanning)或连续扫描(Continuous scanning),本质上都是预定义且固定 的路径 。这种做法就像是"刻舟求剑":无论图像内容是什么,模型都按死板的路线走。这导致空间上相邻的像素在展平后可能相距甚远,从而丢失了图像原有的几何结构信息 。为了解决这一痛点,论文提出DefMamba 。它不再被动地接受网格数据,而是通过可变形扫描(Deformable Scanning),让模型学会了"主动寻找信息" 。
论文中图1就展示了集中扫描方式的区别:
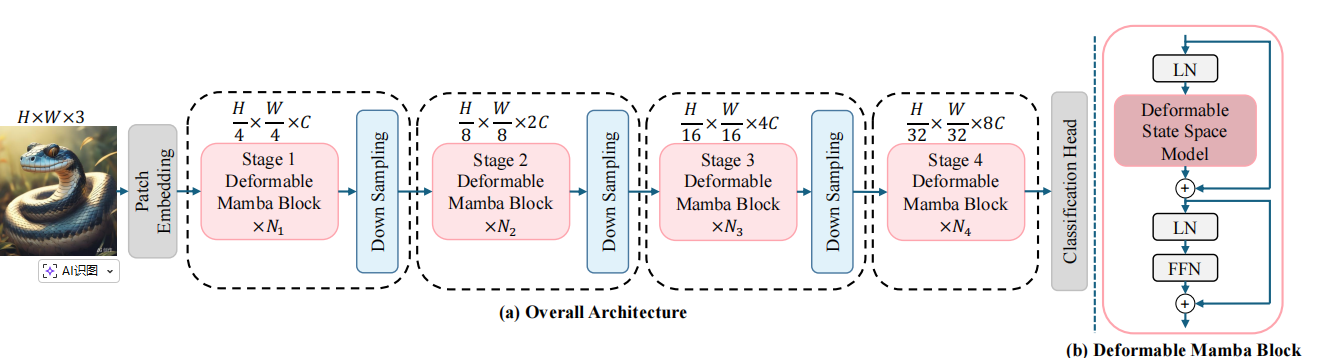
模型采用Swin-Transformer的四阶段结构:
2、为什么要让采样点"动起来"?
在传统的视觉 Mamba 中,序列中的每个 Token 严格对应一个像素格点,例如坐标 (3,5)(3, 5)(3,5)。这种方式在处理具有复杂轮廓的物体(如蜿蜒的蛇或侧身的猫)时,效率极低 。
DefMamba 的突破在于: 模型不再局限于 (3,5)(3, 5)(3,5) 这种整数点,而是通过预测一个偏移量 Δp\Delta pΔp,让采样点"移动"到 (3.2,5.8)(3.2, 5.8)(3.2,5.8) 这种小数位置 。想象你正在黑暗中用手电筒观察一只躲在草丛里的猫。固定扫描就像是你机械地从左往右晃动手电筒;而"可变形采样"则是你发现猫影后,主动将光束集中在猫的耳朵、眼睛和脊背轮廓上。通过让采样点从背景区域移动到物体核心区域,模型在有限的序列长度内,填充了更多"高质量"的特征,从而实现了对物体结构的精准感知 。
(1) 突破网格盲区:现实物体的边缘往往不落在整数像素上。通过移动,模型能精准定位到物体的几何轮廓,提取最纯粹的结构特征 。
(2) 资源重分配(采样逻辑) :虽然 Mamba 仍然处理 H×WH \times WH×W 个 Token,但这些 Token 的内容不再是均匀分布的。原本在单调背景区域的采样点,会受到"吸引"移动到物体核心区 。这意味着序列中的"含金量"大幅提升,而非物体的背景噪音被有效抑制。
扫描和采样的区别:
| 特性 | 传统 Mamba 扫描 | DefMamba 可变形采样 |
|---|---|---|
| 坐标来源 | 固定的整数网格点 | 动态计算的小数坐标点 |
| 内容分配 | 均匀分配(每个像素看一次) | 按需分配(重要区域看多次) |
| 空间感 | 被动的序列化 | 主动的结构感知(Sampling + Sort) |

我制作了一个动图来方便读者理解。动图刚开始是传统光栅扫描(死板的网格)。你会看到一条扫描线像老式电视机刷新一样,按部就班地从左到右、从上到下扫过所有像素。此时,物体如果呈现对角线形状,就会被这种扫描方式无情切断。 DefMamba是后续的方式:
**点偏移发生(寻找高价值目标):**画面中会出现代表图像核心特征的"高价值区域"。您会看到原本整齐排列的网格点,像被磁铁吸引一样,纷纷偏离原位,向这些高价值区域靠拢。
索引重排与动态扫描(结构优先):这是最精彩的一步。扫描线不再按先前的 Z 字形走,而是根据刚刚点移动的距离重新排队。距离核心特征越近的点,越先被连上。你会看到一条蜿蜒曲折、完全贴合物体轮廓的扫描轨迹被动态绘制出来。
3、结构解读
Figure 3(b) 展示了如何将这种"移动"转化为计算机能理解的数学语言。它分为两条并行的流水线:
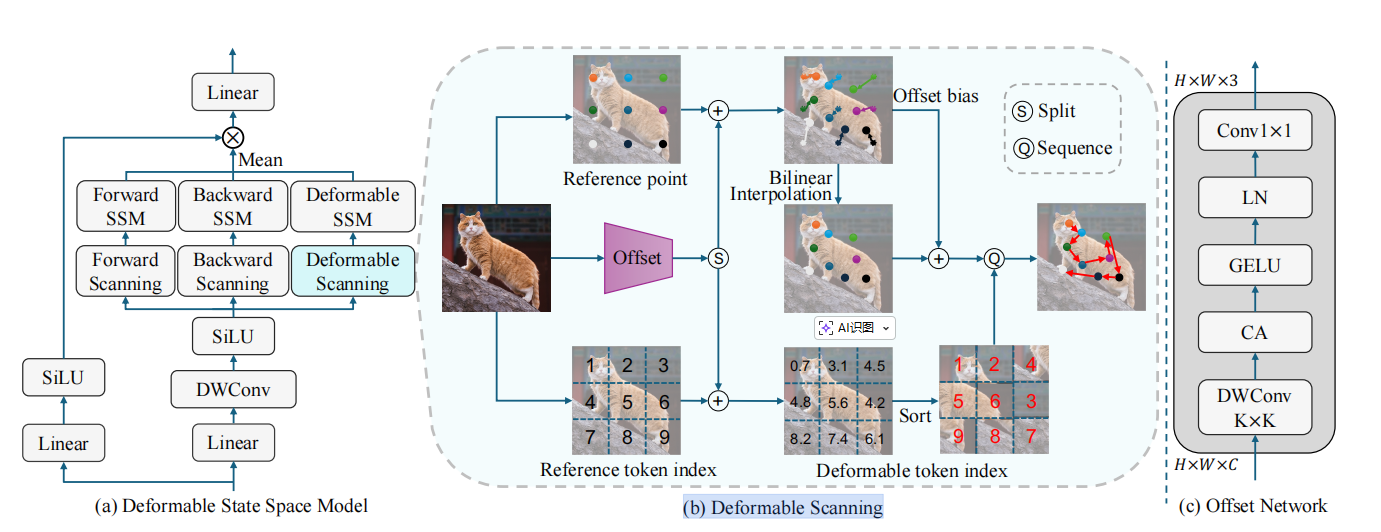 点偏移(上半部分)改变的是"你看到的内容" (通过插值采样),而索引重排(下半部分)改变的是"你阅读内容的顺序" 。这两者是并行的。
点偏移(上半部分)改变的是"你看到的内容" (通过插值采样),而索引重排(下半部分)改变的是"你阅读内容的顺序" 。这两者是并行的。
上路:点偏移与坐标补偿(Point Offset)
这一路解决了"在哪看"的问题。
x^=ϕ(x,p^)+ϕ(R,p^)\hat{x} = \phi(x, \hat{p}) + \phi(R, \hat{p})x^=ϕ(x,p^)+ϕ(R,p^)
双线性插值 ϕ(x,p^)\phi(x, \hat{p})ϕ(x,p^) :由于移动后的位置 p^\hat{p}p^ 是小数,模型通过双线性插值,综合周围四个像素的值,估算出该位置的特征 。
偏移偏置补偿 ϕ(R,p^)\phi(R, \hat{p})ϕ(R,p^) :这是确保模型不产生"空间错觉"的关键 。由于特征移动了,它原有的"绝对位置编码"会失效。这就像你带着手机在繁华的大街上走,但你的 手机 GPS 导航系统坏了(或者更新太慢) 。你实际已经走到了"十字路口"(新位置 p^\hat{p}p^)。但导航地图上的那个小蓝点(位置编码 ppp)还卡在 50 米外的"小胡同"里。如果你完全听导航的,它会告诉你:"现在请靠左走进入胡同"。但你实际上在宽阔的大街上,按照"胡同"的逻辑去处理"大街"的信息,这显然会导致模型识别出错。偏移偏置 RRR 的作用,就是根据你偏离的这 50 米,给导航系统打一个实时补丁。它告诉模型:"别看蓝点在胡同,其实他在大街,请按大街的坐标系来处理这个特征"。
下路:序列重排(Index Offset)
这一路解决了"按什么顺序读"的问题。
模型为每个 Token 预测一个序号偏移 Δt\Delta tΔt,得到新序号 td=tr+Δtt_d = t_r + \Delta ttd=tr+Δt 。
排序(Sort)操作:模型根据新序号的大小重新排列 Token 顺序。这使得原本在空间上不相邻但逻辑相关的特征(如属于同一个物体的不同部位),在送入 Mamba 模块前被"邻近化" 。
就像一场运动会入场,原本大家按学号 1、2、3... 死板地排队。现在裁判(网络)根据每个人的表现,给学号加上了一个偏移量。有人变成了 1.5 号,有人变成了 0.8 号。重新从小到大排队后,0.8 号站在了第一位。 图中下半部分的折线因此变得蜿蜒曲折,沿着猫的身体轮廓连接,形成了一种**"结构优先"**的扫描路径 。
为了便于读者理解和原始扫描方式的不同,这里我做了两个动图,第一个是常规Mamba的固定扫描
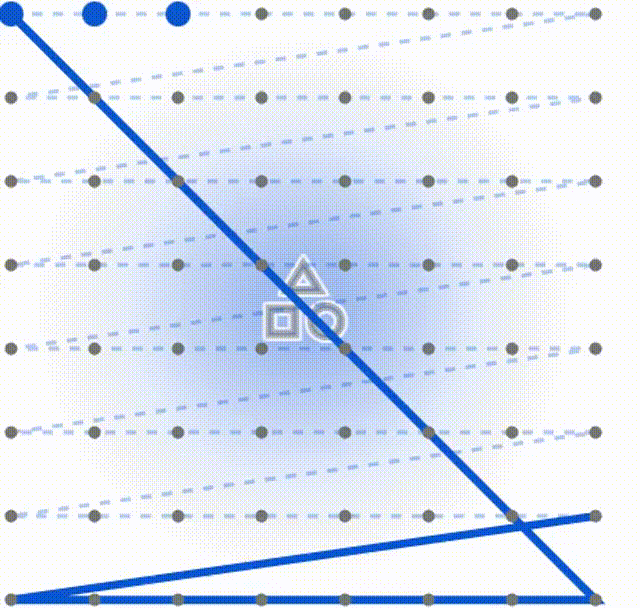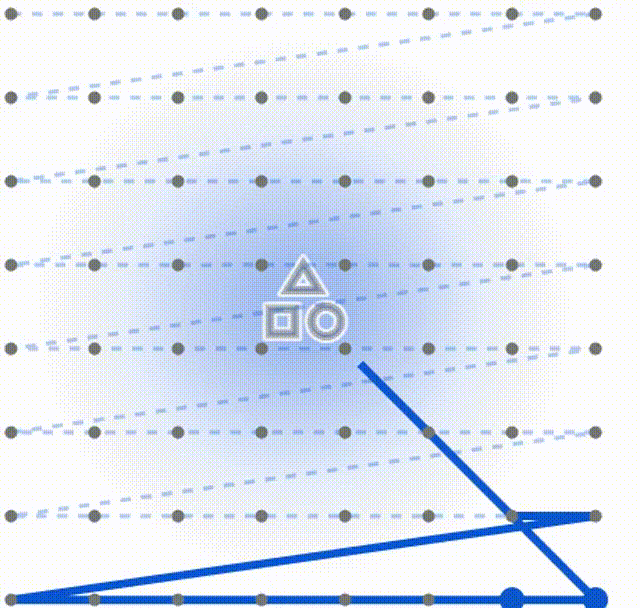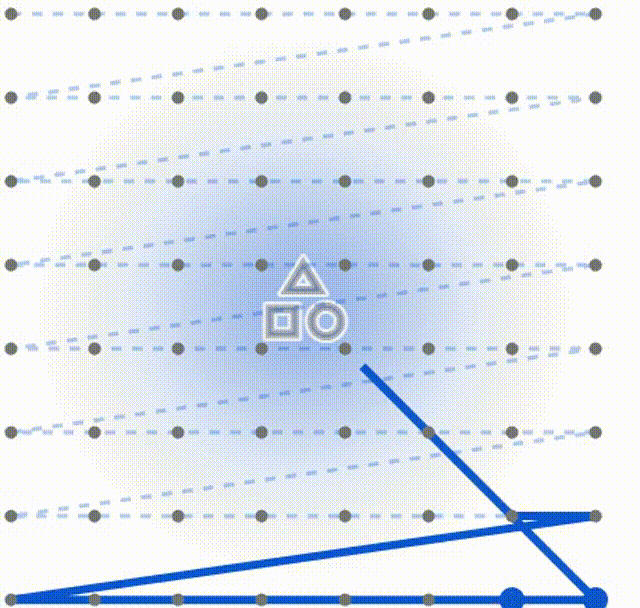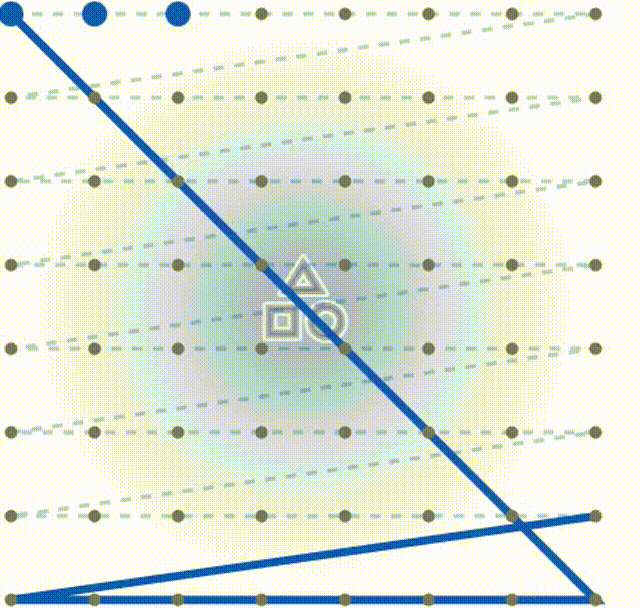
下面这个是DefMamba的方式,可以看到扫描的总的点数相同,但是侧重点发生了改变,通过训练关注到了重点上。
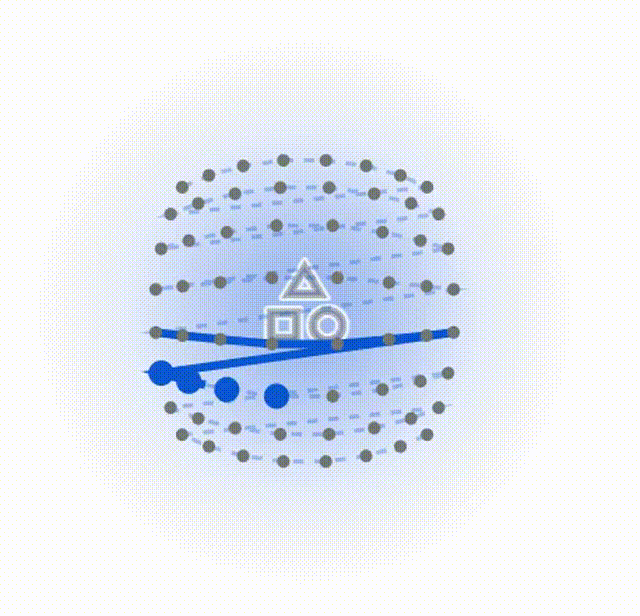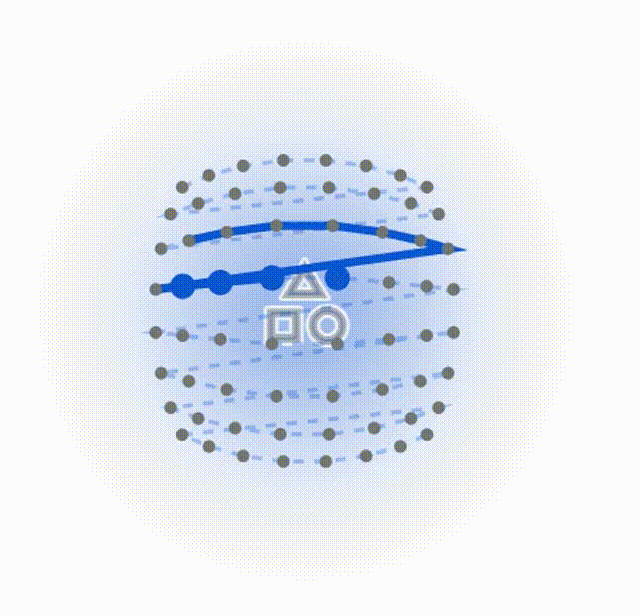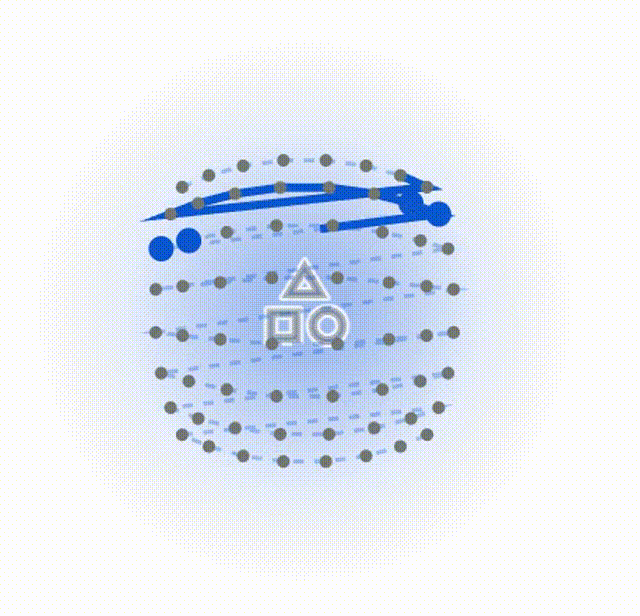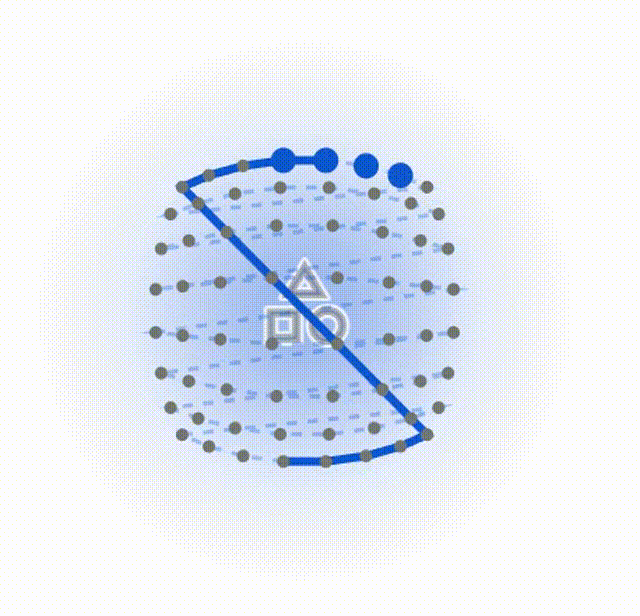
4、攻克不可微难题:梯度复制近似法
在实现"序列重排"时,作者遇到了神经网络的死穴------排序(Sort)操作是不可导的 。排序是一个**"跳跃式"的过程。比如有两个数 [0.8, 0.9],排序是 (1, 2)。如果第一个数增加一点点变成 0.91,顺序瞬间变成了 (2, 1)。 在数学上,这种瞬间的地位反转是 不连续的。就像你爬台阶,上一秒在 1 楼,下一秒就在 2 楼,中间没有平滑的过渡,所以算不出"变化率(梯度)"。既然算不出精确的"谁该负多少责",作者就采用了一种"集体责任制"**。
什么是"梯度复制"?
由于无法通过排序算法直接反向传播梯度,负责预测偏移量的网络就像断了线的风筝,不知道该如何改进。作者采用了一种工程智慧:
(1) 测量最终生成的图像序列上的总误差(梯度)。
(2) 将这些梯度在维度上进行平均(Averaged) 。
(3) 将这个"平均误差"直接复制给 Δt\Delta tΔt。
为什么要用平均值?
因为排序是"集体行为",我们无法精准判定是哪个点的偏移导致了排序错误。想象一支足球队(一组 Token)比赛输了(产生了误差/梯度)。教练(模型)知道是球员们的站位(排序顺序)有问题,但他没法精准地指出:是因为前锋跑慢了 0.1 秒,还是后卫退后了 2 厘米导致输球的。如果不平均,教练可能因为某一瞬间的愤怒,把所有火气都撒在守门员一个人头上,这显然不公平,也解决不了进攻问题。采用平均,教练把全队集合起来,给全队下达了一个统一的指令:"大家整体往对方禁区再压上 5 米!"(这就是梯度平均)。虽然这个指令对每个人来说不一定是最完美的,但它给出了一个大致正确的大方向 。在神经网络成千上万次的训练中,这种"大方向正确"的平均推力,足以让负责预测偏移量 Δt\Delta tΔt 的网络慢慢摸索出规律,最终学会如何排出一支最有杀伤力的阵型。
5. 改进方向探讨
我非常欣赏作者在论文结尾(Limitation 章节)坦诚地剖析了 DefMamba 的局限性。当前方法在以下两种极端场景下表现不佳:
(1) 不完整的物体结构(Incomplete objects):当图像中只出现物体的局部(例如只有半个棒球)时,可变形机制无法捕捉到完整的结构信息 。这会导致预测出的偏移量(Offsets)变得非常小,最终退化回普通的固定扫描路线 。
(2) 规则排列的物体(Regularly spaced objects):当画面中是高度规律排列的物体(如密集的瓦片、酒桶)时,相邻 Token 之间的信息差异极小 。这会让模型在学习偏移量时变得"懒惰(indolent)",找不到明确的形变方向 。
针对作者指出的自身不足,我斗胆的探讨一下可能的改进:
1、可以考虑在偏移网络(Offset Network)中引入更长程的上下文先验(Long-range context prior)。既然局部信息不足以支撑变形(例如只有半个棒球),模型如果能结合全局的语义理解(比如识别出这是在体育场),或许能给出更有底气的偏移预测
2、对于规则纹理导致的"学习懒惰",引入某种形式的对比学习损失(Contrastive Loss)来强制拉开相似特征的表征距离,或许是一个值得尝试的思路。
小结
这篇工作逻辑清晰,切入点非常准确。它没有为了用 Mamba 而用 Mamba,而是敏锐地抓住了 2D 到 1D 映射中的空间损失痛点,给出的动态扫描解法优雅且有效。希望我的解析对你理解这篇前沿论文有所帮助!