🎬 胖咕噜的稞达鸭 :个人主页
🔥 个人专栏 : 《数据结构》《C++初阶高阶》
《Linux系统学习》
《算法日记》
⛺️技术的杠杆,撬动整个世界!
3.26 实习产品支持工程师
1. TCP 和 UDP 的区别
-
连接方式
TCP 面向连接(三次握手);UDP 无连接。
-
可靠性
TCP 可靠传输(确认应答机制、重传机制、按序到达);
UDP 不保证可靠性(可能丢包、乱序)。
-
传输方式
TCP 面向字节流(没有边界,可能产生粘包问题);
UDP 面向数据报(有边界,一个包一个包发送)。
-
控制机制
TCP:
- 拥塞控制(慢启动、拥塞避免)
- 流量控制(滑动窗口)
UDP:
- 没有任何控制机制
-
头部开销
TCP:20 ~ 60 字节,可变;
UDP:8 字节,固定。
UDP 更轻量,性能更高。
-
使用场景不同
TCP 适用场景
- HTTP / HTTPS
- 文件传输(FTP)
- 数据库通信(MySQL)
- 邮件(SMTP)
特点:
数据不能错、不能丢。
UDP 适用场景(要求"实时性")
- DNS(一次请求一次响应)
- 视频直播 / 音频通话(如 WebRTC)
- 游戏(实时性优先)
- 广播 / 多播
特点:
可以丢一点,但是必须快。
2. TCP 慢启动机制用了什么算法?
拥塞控制有哪些算法
主要是四个算法:
- 慢启动算法
- 拥塞避免
- 拥塞发生
- 快速恢复
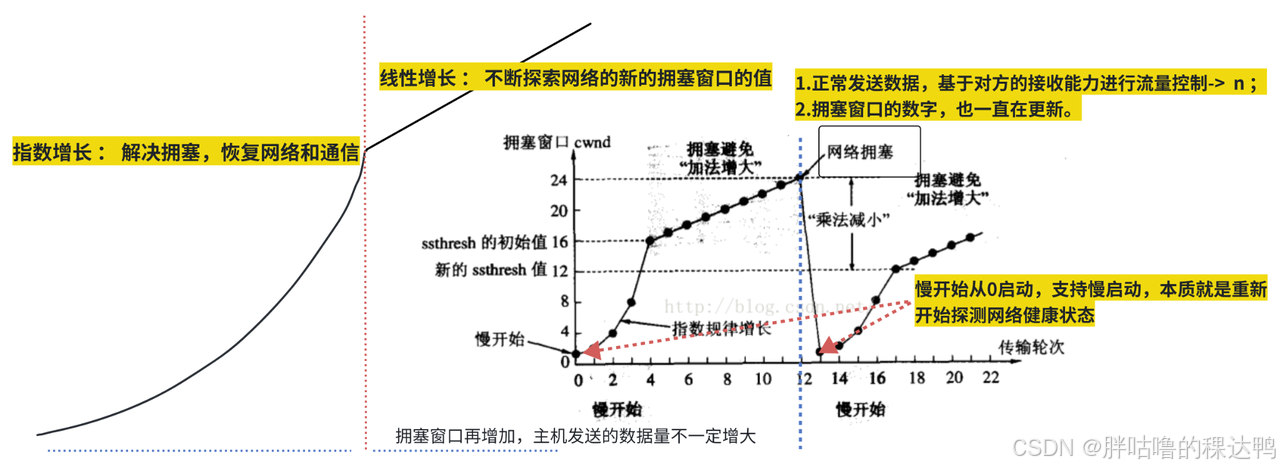
TCP 通过慢启动快速探测带宽,通过拥塞避免平稳增长,通过丢包反馈动态调整发送速率,从而在保证高吞吐的同时避免网络拥塞。
TCP 为了解决在未知网络状态下直接发送大量数据可能导致拥塞的问题,引入了拥塞控制机制,其中核心就是 拥塞窗口 cwnd。
cwnd:发送方根据自己"网络是否拥塞"控制的窗口,本质上是"我最多敢发送多少数据"rwnd:接收窗口,本质上是"我最多还能接收多少数据"- 滑动窗口 = min(接收窗口 rwnd, 拥塞窗口 cwnd)
在连接建立后,TCP 不会一开始就发送大量数据,而是进入慢启动阶段:
- 初始时
cwnd很小(通常为 1 ~ 10 个 MSS) - MSS:最大报文段长度,也即一次 TCP 真正发送的数据块大小
- 每经过一个 RTT(一个数据包发出去 + 收到确认 ACK 的时间),
cwnd指数增长(翻倍) - 这是为了快速探测网络的可用带宽
TCP 用 RTT 来判断网络快慢,cwnd 的增长是按照 RTT 来算的。
当 cwnd 增长到慢启动阈值 ssthresh 后:
- 进入拥塞避免阶段
cwnd由指数增长变为线性增长(每个 RTT + 1 MSS)- 目的是避免网络突然拥塞
当发生丢包时:
丢包分两种情况:
① 超时(严重拥塞)
ssthresh = cwnd / 2cwnd重置为 1- 重新进入慢启动
② 三次重复 ACK(轻微拥塞)
ssthresh = cwnd / 2cwnd ≈ ssthresh- 进入快恢复阶段,不再从 1 开始
总结口诀:
先指数,后线性;丢包减半,超时归一。
3. 拥塞控制说一下
为什么要有拥塞控制
网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包延时、丢包等情况。TCP 触发丢包重传后,会加重网络传输负担,导致更大的延迟以及更多的丢包。
拥塞控制的目的,就是为了避免发送方的数据填满整个网络。
什么是拥塞窗口
cwnd:发送方根据自己"网络是否拥塞"控制的窗口,本质上是"我最多敢发送多少数据"rwnd:接收窗口,本质上是"我最多还能接收多少数据"- 滑动窗口 = min(接收窗口 rwnd, 拥塞窗口 cwnd)
我怎么知道网络中是不是发生了拥塞
发送方没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就认为网络出现了拥塞。
4. Linux 查看磁盘、查看内存的指令是什么?
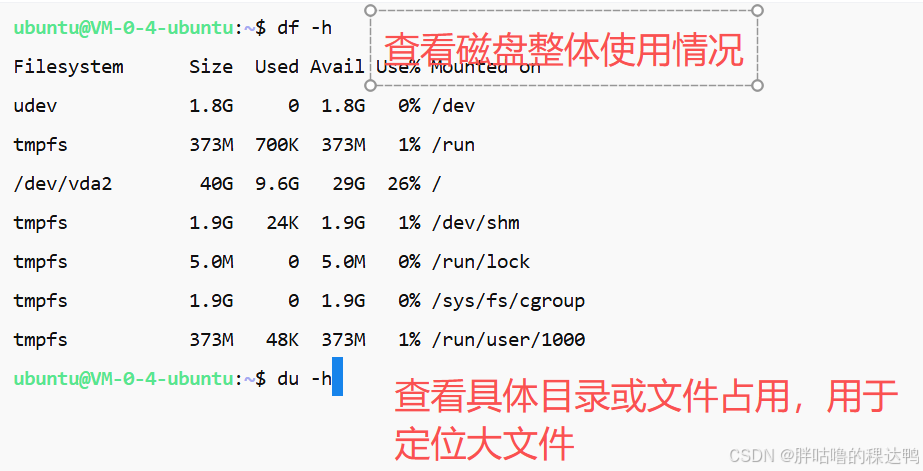
查看磁盘使用情况
我一般使用:
df -h:查看磁盘整体使用情况du -h:查看具体目录或文件占用,用于定位大文件
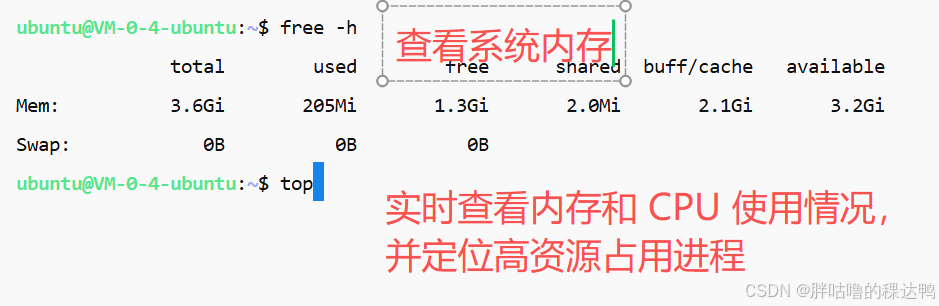
查看内存使用情况
free -h:查看系统内存,其中available表示实际可用内存top:实时查看内存和 CPU 使用情况,并定位高资源占用进程
5. Get、Post 的区别
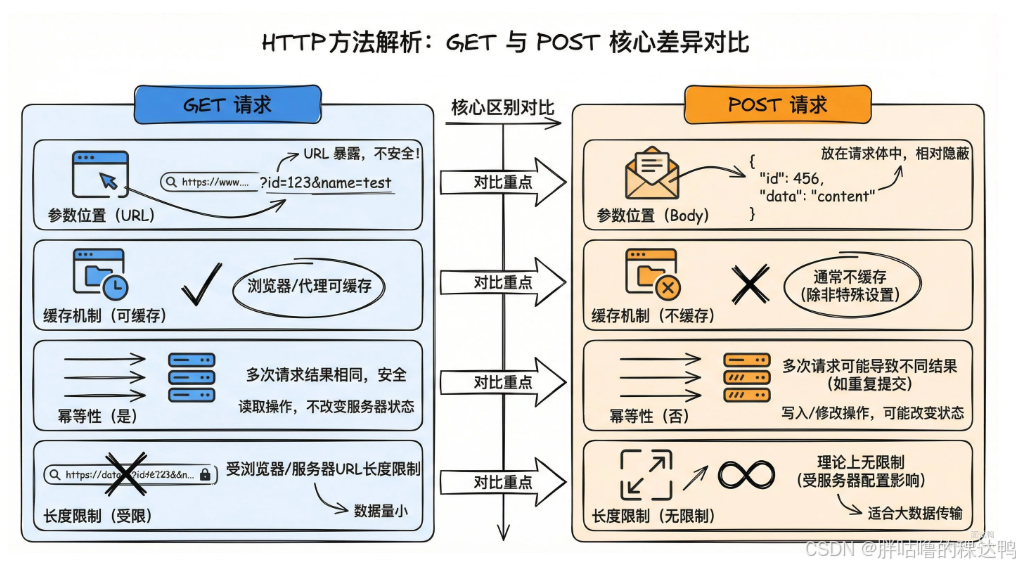
Get 和 Post 的区别(直接记)
从 HTTP 语义上来说:
- GET 用于获取资源,不应该修改服务器状态
- POST 用于提交数据,通常会产生副作用,比如创建或更新资源
实际开发中的主要区别有四点:
第一,参数位置不同
- GET 参数通常放在 URL 中,长度有限
- POST 参数放在请求体中,适合传输大数据
第二,安全性
- GET 参数会暴露在 URL 中,容易被记录(浏览器历史记录看得见,不适合传密码这类隐私信息)
- POST 放在请求体中相对隐蔽,但本质上都不安全,需要依赖 HTTPS
(都是 HTTP,明文传输,随便一个抓包工具都抓取得到)
第三,幂等性
- GET 是幂等的,多次请求结果一致
- POST 一般是非幂等的,多次请求可能产生多次副作用
第四,缓存机制
- GET 可以被浏览器和 CDN 缓存
- POST 默认不缓存
6. HTTP 抓包工具(Wireshark、Fiddler)
常见 HTTP 抓包工具有:
- Wireshark
- Fiddler
- Charles
- tcpdump
Wireshark 主要用于底层协议分析,Fiddler 和 Charles 用于 HTTP 调试,tcpdump 常用于 Linux 服务器抓包。
实际中我会根据场景选择工具,比如用 Charles 抓接口请求,用 tcpdump 排查线上网络问题。
如果是 HTTPS,还需要配置证书进行解密。
7. DNS 的理解
首先客户端会发送一个 DNS 请求,比如问 www.server.com 的 IP 地址在哪里,并且询问本地 DNS 服务器。
本地 DNS 服务器收到客户端请求后:
- 如果缓存中的表格可以找到
www.server.com,就直接返回 IP 地址 - 如果没有,就进行以下操作
DNS 查询流程
-
本地 DNS 询问根域名服务器
根服务器(
.)收到本地 DNS 请求,返回.com顶级域名服务器地址 -
本地 DNS 询问
.com顶级域名服务器
.com顶级域名服务器收到本地 DNS 请求,返回负责www.server.com区域的权威 DNS 服务器地址 -
本地 DNS 询问权威 DNS 服务器
权威 DNS 服务器查询后,将对应的 IP 地址告诉本地 DNS
-
本地 DNS 将 IP 地址返回给客户端
客户端和目标建立连接
8. HTTP 和 HTTPS 的理解
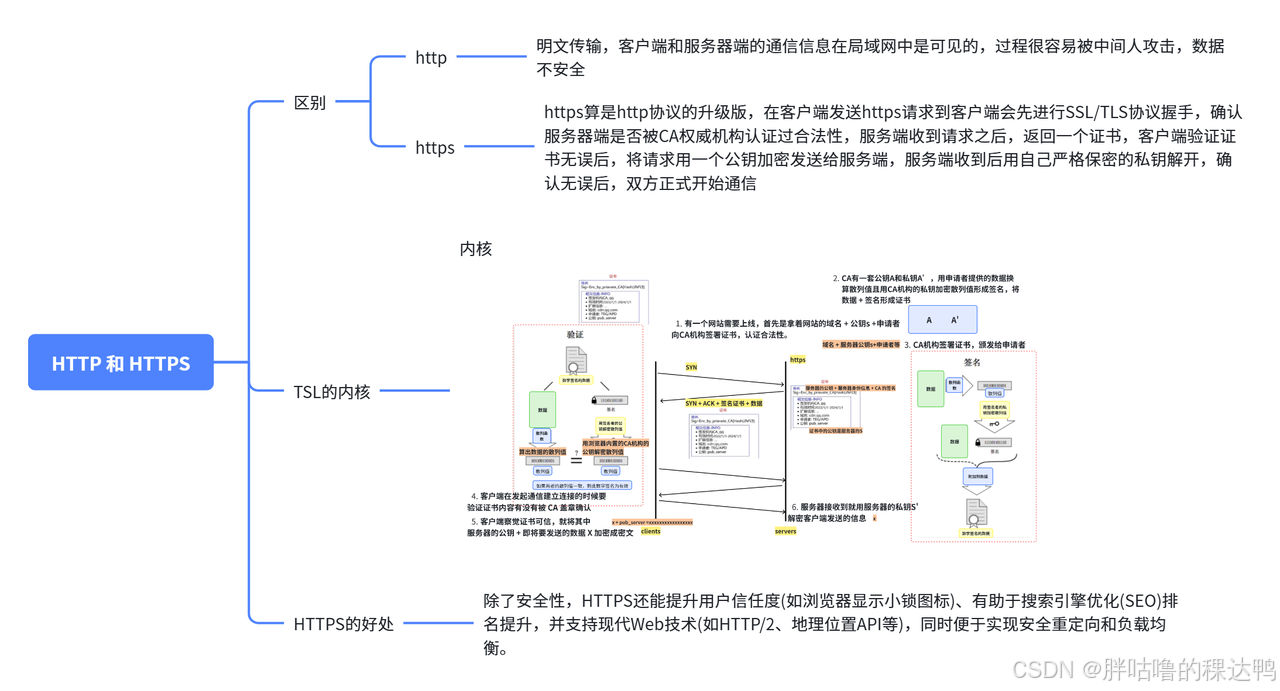
TLS 握手流程
-
客户端发送
ClientHello包含客户端支持的 TLS 版本 + 加密套件 + 随机数 A
-
服务器端发送
ServerHello包含确认客户端支持的 TLS 版本 + 加密套件 + 随机数 B + 证书
(证书包含服务器公钥 + CA 机构签名的数字证书)
-
客户端收到之后,确认证书合法性
生成一个
pre_master_secret,用服务器公钥加密这个pre_master_secret,发送给服务器 -
服务器用服务器私钥解密
得到
pre_master_secret -
双方根据随机数 A、随机数 B、
pre_master_secret生成对称加密密钥 -
双方发送
Finished消息,验证握手成功 -
后续通信使用对称加密
3.27 IT 技术支持实习生(运维)
1. 做项目的时候用的 Linux 哪个系统,你了解哪一些?
主要使用 Ubuntu,也了解过 CentOS。
Ubuntu 和 CentOS 区别
简答:
- Ubuntu 偏向开发环境,软件更新快
- CentOS 更稳定,常用于服务器环境
2. 了解网络中的哪些协议?
我主要了解 TCP/IP 协议体系,包括:
- 传输层的 TCP 和 UDP
- 网络层的 IP
- 应用层的 HTTP、HTTPS 和 DNS 协议
在项目中主要使用 TCP 和 HTTP。
3. Linux 用过哪些指令?
我在 Linux 中常用的命令主要包括:
文件操作类
lscdcprm
日志查看
tail -fless
进程管理
pstopkill
网络排查
netstatsscurl
文本处理命令
grepawk
在实际开发中,我会结合这些命令进行日志分析和问题排查,比如用 tail -f + grep 定位错误日志。
4. 服务器崩掉了用 Linux 指令怎么排查?
我一般会按"由外到内"的思路排查:
- 先用
ps或top查看进程是否存在 - 如果不存在,查看日志(
tail -f)定位崩溃原因 - 如果存在但无法访问,使用
netstat或ss查看端口是否监听
(ss比netstat更高效) - 使用
curl或telnet测试服务是否正常响应 - 如果 CPU 或内存异常,用
top或free进一步分析
5. CPU 100% 的情况怎么排查问题,一般是什么原因?
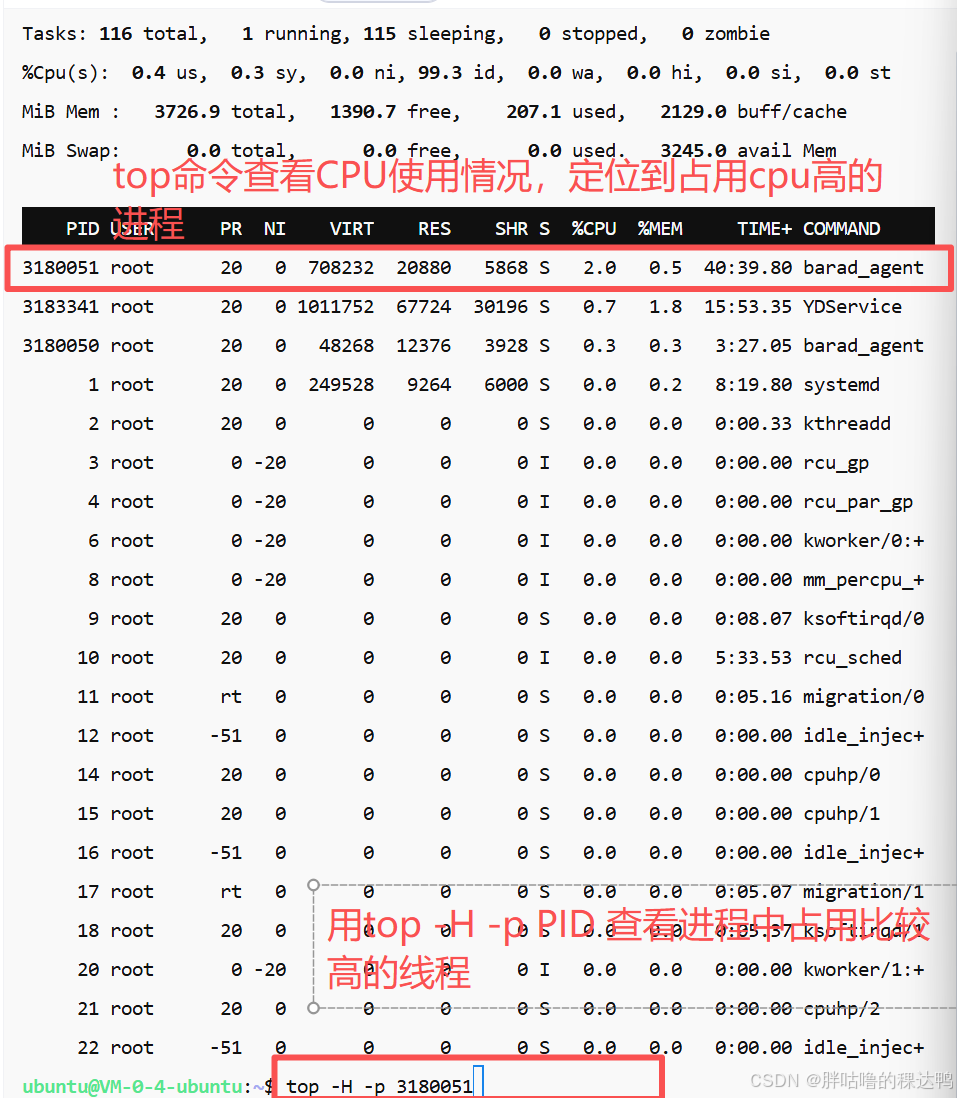
排查问题
- 用
top命令,定位到占用 CPU 最高的进程 - 通过
top -H -p pid或ps -T -p pid找到进程中高 CPU 的线程 - 通过
jstack命令查看该线程的堆栈信息 - 根据输出的信息,去项目中定位代码,判断是不是发生了死循环导致 CPU 跑到 100%
原因
- 死循环
- 多次 IO
- 锁竞争
6. HTTP 和 HTTPS 的区别
刚我们已经说过了,运维,技术支持必考!
7. TCP 和 UDP 区别,如果要保证传输可靠性的话用哪个,TCP 和 UDP 使用的场景
-
连接方式
TCP 面向连接(三次握手);UDP 无连接
-
可靠性
TCP 可靠传输(确认应答机制、重传机制、按序到达);
UDP 不保证可靠性(可能丢包、乱序)
-
传输方式
TCP 面向字节流(没有边界,产生粘包问题);
UDP 面向数据报(有边界,一个包一个包发送)
-
控制机制
TCP:
- 拥塞控制(慢启动、拥塞避免)
- 流量控制(滑动窗口)
UDP:
- 没有任何控制机制
-
头部开销
TCP(20 ~ 60 字节,可变);
UDP(8 字节,固定),UDP 更轻量,性能更高
-
使用场景不同
TCP 适用场景
- HTTP / HTTPS
- 文件传输(FTP)
- 数据库通信(MySQL)
- 邮件(SMTP)
特点:
数据不能错、不能丢。
UDP 适用场景(要求"实时性")
- DNS(一次请求一次响应)
- 视频直播 / 音频通话(如 WebRTC)
- 游戏(实时性优先)
- 广播 / 多播
特点:
可以丢一点,但是必须快。
8. 线程和进程的区别
- 进程是操作系统资源分配的基本单位,每个进程有独立的地址空间
- 线程是 CPU 调度的基本单位,是进程中的执行单元,多个线程共享同一进程的资源