
一、这一周,国产AI圈炸了
如果你最近一周没刷技术圈,你可能错过了两件大事。
3月27日,智谱悄悄上线GLM-5.1,没有发布会,没有预告,直接开放给Coding Plan全量用户------然后订阅候补名单瞬间爆了。
4月2日,阿里Qwen3.6-Plus正式发布,1M上下文窗口,官方直接放话:编程能力接近全球最强的Claude系列。
两家公司,一周之内,接连出手。
国产大模型的编程赛道,从来没有像现在这么热闹过。
但问题来了:这次,国产模型是真的追上了,还是又在"接近"?
我们把三款模型放在一起,用数据说话。
二、先认识一下今天的三位选手
🇨🇳 GLM-5.1 | 智谱出品
智谱在短短六周内,连发了GLM-5、GLM-5-Turbo、GLM-5.1三个重要版本。这个迭代速度,说是"卷王"一点都不夸张。
GLM-5.1是GLM-5系列的迭代优化版本,核心定位延续"Agentic Engineering(智能体工程)"方向,针对性优化了编程能力、长序列执行、推理稳定性和部署效率,主打"低人工干预、全流程自主完成复杂任务"。
简单来说:它不只是帮你写代码,而是帮你把整个工程从头做到尾。
🇨🇳 Qwen3.6-Plus | 阿里出品
Qwen3.6-Plus主打Agentic Coding和复杂推理,支持1M超长上下文窗口。
自Qwen3.5发布后,千问已全面将主力模型转向原生多模态,团队希望模型逐步演进为一个能在真实环境中持续感知、推理和行动的原生多模态智能体。
一句话版本:千问这次不只是升级了大脑,还给它装上了眼睛。
Claude Opus 4.6 | Anthropic出品
江湖地位不用多说------两家国产厂商发布新模型,官方benchmark都拿它做对标。
能被当作靶子,本身就是一种认可。
三、核心数据:编程能力谁更强?
废话不多说,直接上数据。
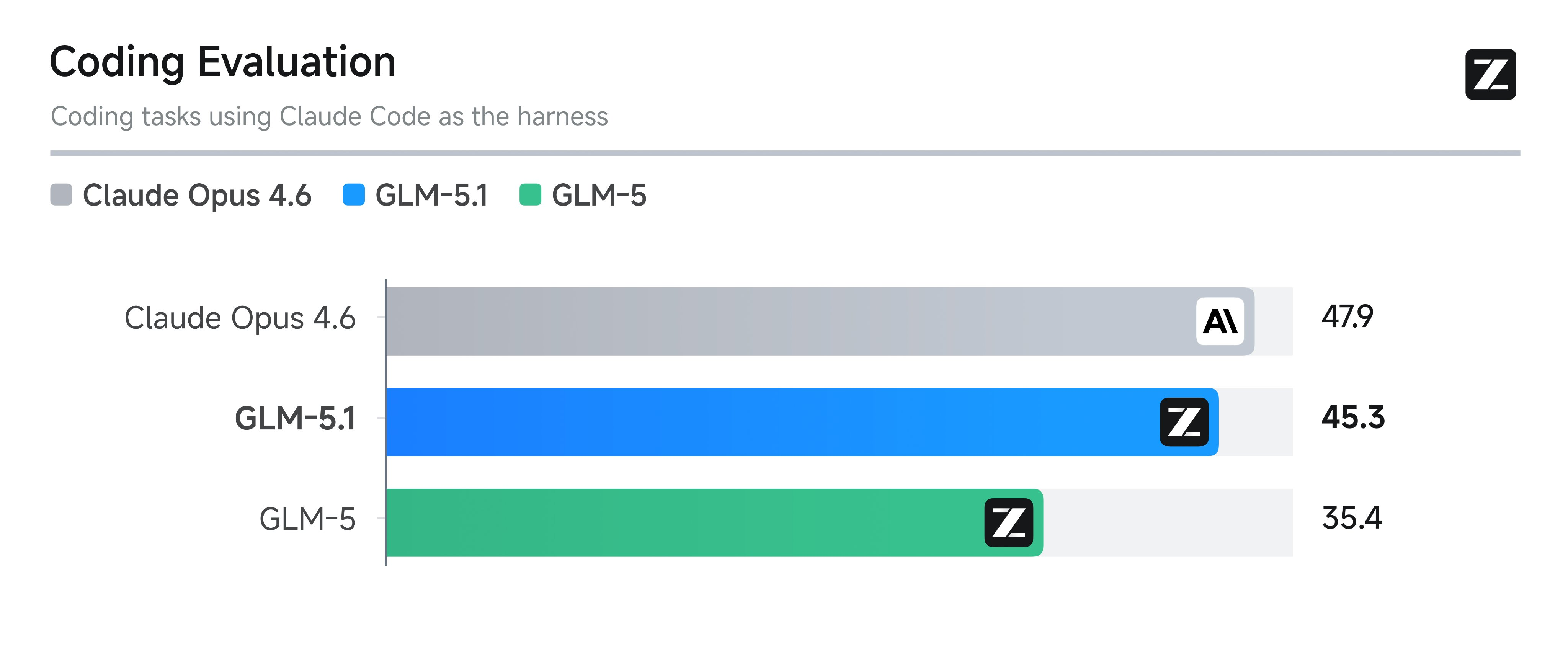
编程得分(Z.ai Coding Eval):
GLM-5.1在Z.ai编程评估中得分45.3,GLM-5基线得分为35.4,单次版本迭代提升了28%。作为参考,Claude Opus 4.6在同一基准测试中的得分为47.9。
换算一下:GLM-5.1和Claude Opus 4.6之间,只差2.6分。
一个月前这个差距还是双位数,现在已经快追平了。
SWE-bench / Terminal-Bench2 / NL2Repo(真实编程任务):
在SWE-bench Verified、Terminal-Bench 2、NL2Repo等编程基准测试中,Qwen3.6-Plus取得了超过GLM-5、Kimi-K2.5的成绩,在部分基准测试中的得分仍低于Claude Opus 4.5。
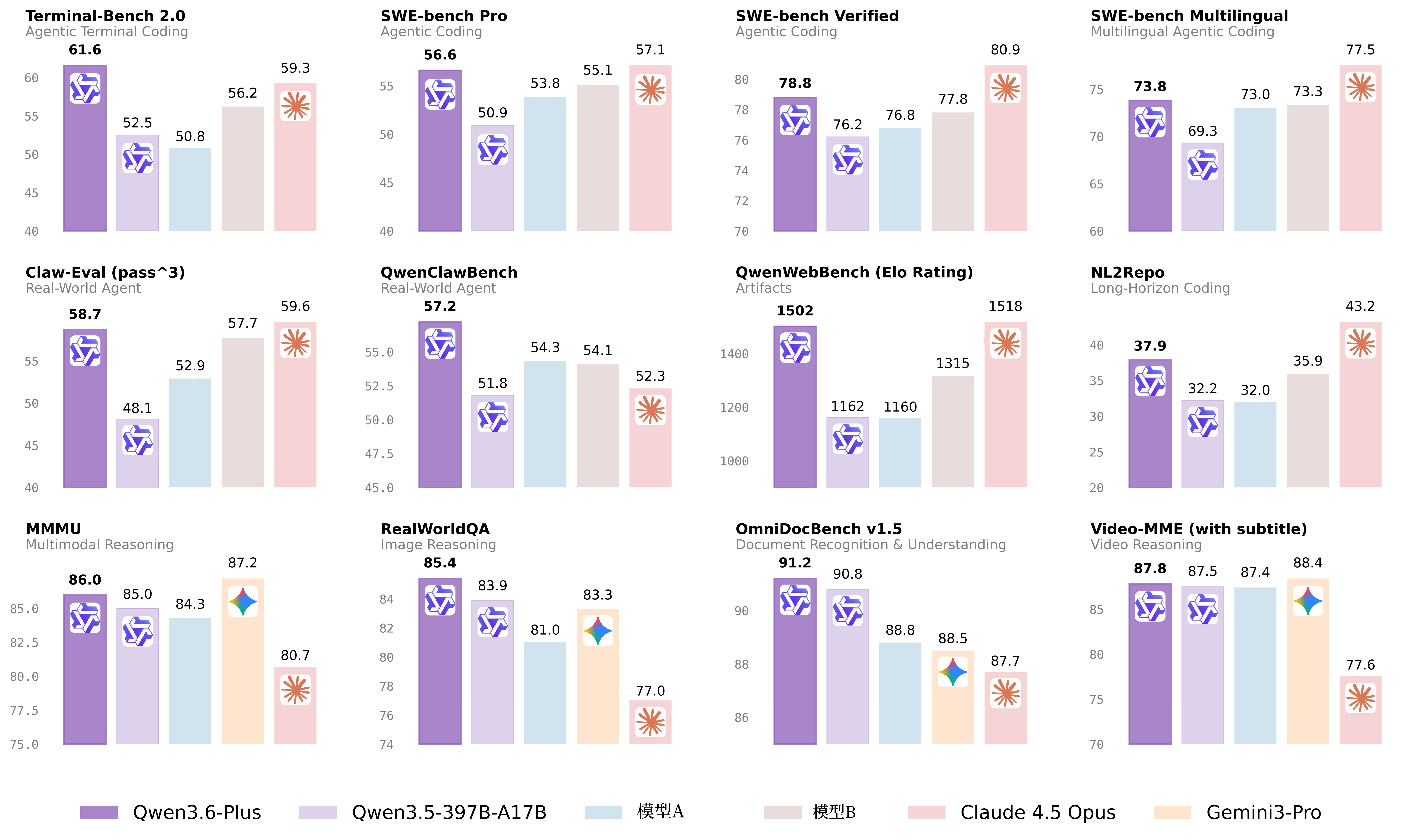
真实世界Agent能力(Claw-Eval / QwenClawBench):
在智能体编程SWE-bench系列评测、真实世界智能体任务Claw-Eval等权威评测中,千问3.6编程表现超越2倍乃至3倍参数量的GLM-5、Kimi-K2.5等模型,接近全球最强编程模型Claude系列。
用更直白的方式说:Qwen3.6-Plus用更小的身体,打赢了比自己重两到三倍的对手。
| 对比维度 | GLM-5.1 | Qwen3.6-Plus | Claude Opus 4.6 |
|---|---|---|---|
| 编程评分(Z.ai) | 45.3 | 暂无统一数据 | 47.9 |
| 上下文窗口 | 200K | 1M | 1M |
| SWE-bench表现 | 低于Qwen3.6 | 国产最强 | 全球顶尖 |
| Agent能力 | 强 | 国产第一梯队 | 全球标杆 |
| API价格(输入/百万token) | 待确认 | 最低2元(折后) | 显著更高 |
四、价格这件事,国产模型赢麻了
性能接近,但价格?差距大到有点好笑。
Qwen3.6-Plus已上架阿里云百炼,每百万Tokens输入最低2元,目前还有限时5折优惠。
折后算下来,相当于花一杯奶茶的钱,就能处理几百万字的代码。
Claude Opus 4.6的API定价则高出数倍------对于个人开发者、中小团队来说,这个差距才是真正影响选型决策的因素。
如果你只是想把活干完,Qwen3.6-Plus的性价比,目前国内找不到对手。
五、所以,国产模型追上了吗?
编程这件事:几乎追上了。
GLM-5.1和Claude Opus 4.6的编程评分差距已经缩小到2.6分,Qwen3.6-Plus在真实Agent任务上与Claude系列处于同一梯队。这放在一年前,是不敢想象的事情。
但有一件事,还差得远。
纯粹的代码能力可以用benchmark量化,但模型的"综合素质"------创意理解、复杂推理、中文细腻表达、边界场景的稳定性------目前还没有一个统一的公开数据能说明国产模型已经全面追平。
不过,真正让人在意的,不是今天的差距,而是迭代的速度。
GLM-5.1距离上一代GLM-5的发布,仅仅隔了一个多月。
一个多月,28%的编程能力提升,2.6分的差距。
如果这个节奏维持下去,下一次写这篇文章的时候,可能就不是"接近Claude",而是"Claude在追赶国产模型"了。
各位现在日常开发用的是哪款模型?