-
进程之间不能直接访问对方内存
-
所以必须用 Socket + 共享内存 通信
-
每个进程独立运行
-
每个进程自己负责自己的连接
-
网卡模拟器进程:监听 PCIe 连接
-
QEMU 进程:主动连接 PCIe
-
它们通过 Socket 建立连接,交换自我介绍
-
然后用共享内存高速通信
底层状态

初始化
- BaseIfInit = 给接口填参数、做检查
- BaseIfListen = 创建 Socket、绑定、监听、从共享内存里划分队列空间
- BaseIfEstablish = 等待连接 + 握手(真正把链路打通)
- in_num_entries /out_num_entries 是固定常数!不是动态变化的!
因为这是 "环形队列(Ring Buffer)"!长度固定!
你必须理解:
SimBricks 用的是 预分配固定长度环形队列,不是动态链表!
-
in_num_entries = 队列最大能存多少条消息
-
out_num_entries = 队列最大长度
-
创建时就定死,永远不变!
就像:
-
快递柜一共有 50 个格子
-
这个数量 永远不变
-
格子只会在 "空 / 满" 之间变化
-
最大容量永远是 50
所以:
- in_num_entries = 固定常数
- out_num_entries = 固定常数
- 创建时就确定,不会变!
SimbricksBaseIfInit
作用:初始化接口结构体、做参数检查
只干 3 件事:
- 检查 延迟 ≥ 同步间隔(必须满足,否则同步出错)
- 把接口内存清零
- 把参数复制到接口里
它不创建 Socket、不分配内存、不监听!只是 "填表"!
blocking_conn = 是否使用阻塞连接
-
blocking_conn = true→ 阻塞模式→ 等待连接时,程序会卡住不动,直到有人连接 -
blocking_conn = false→ 非阻塞模式(我们要设置的) → 等待连接时,程序不会卡住,可以去做别的事

判断 fcntl 获取属性是否失败
Linux 系统函数调用失败时会返回 -1。这里就是检查:**"我刚才读取文件状态成功了吗?"**失败就直接报错退出。
SimbricksBaseIfListen
作用:创建 Socket + 绑定 + 监听 + 从共享内存划分队列空间
干 6 件大事:
- 创建 Unix Socket
- 设置非阻塞(可选)
- bind 绑定路径
- listen 开始等待连接
- 从共享内存池里划出一段空间作为 入队列 (in_queue)
- 再划出一段空间作为 出队列 (out_queue)
这个函数执行完 → 接口开始等待别人来连接!
- 创建 Socket(相当于装个电话)
- 绑定地址(相当于装个电话号码)
- 开始监听(相当于等着别人打电话)
- 划分共享内存队列(切出收件箱、发件箱)






pool->base:共享内存起始地址pool->pos:当前分配到的位置- 计算结果:从共享内存里切出一段作为收件箱

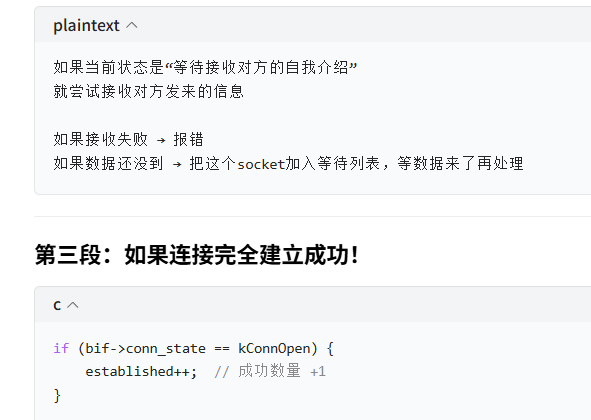
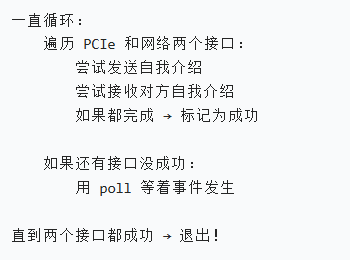
SimBricksBaseIfEstablish
作用:等待所有接口连接成功 + 握手交换信息
就是你启动时看到的:
plaintext
waiting for pcie connection...
waiting for net connection...干 3 件事:
- 循环检查所有接口(PCIe + ETH)是否连上
- 连上后发送 / 接收握手信息(intro)
- 所有接口全部就绪才返回
它是 "等待全部接通" 的函数!
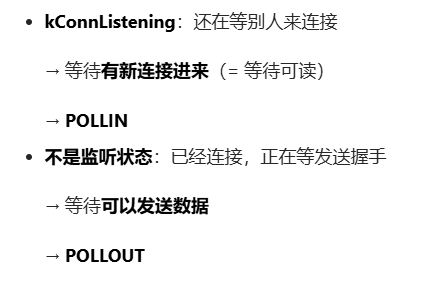
调用 SimbricksBaseIfConnected 检查当前接口连好了吗。
它会返回 3 种值:
- ret < 0:连接失败(出错)
- ret = 0:已经连接好
- ret > 0 :还没好,需要继续等待

- 发送握手消息(告诉对方我是谁)
- 接收握手消息(读取对方是谁)
- 用 poll 等着事件发生(不浪费 CPU)
直到 PCIe 和网络都握手成功,函数才结束!
-
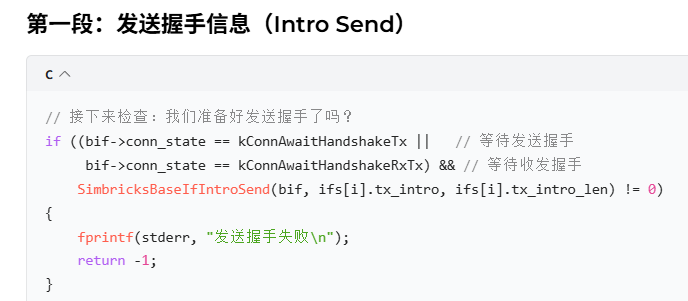
Handshake = 握手
-
Tx = Send 发送
-
Intro = 自我介绍(我是网卡、我的设备 ID...)
如果当前状态是"等待发送自我介绍"
那就调用函数把自我介绍发出去!
如果发送失败 → 报错退出!




NicIf
队列大小 = 条目数量 × 单个条目大小
ests 2 = 存放 "要建立的连接信息" 的数组
最多同时建立 2 个连接:PCIe + 网络
所以数组大小是 2。
n_bifs = 实际要建立的接口数量
有网络 → n_bifs++
有 PCIe → n_bifs++
建立接口信息
if (netParams) {
SimbricksBaseIfInit(netif, netParams); // 初始化网络接口
SimbricksBaseIfListen(netif, pool); // 等待交换机连接
// 把这个接口加入"待建立列表"
ests[n_bifs].base_if = netif;
ests[n_bifs].tx_intro = &net_intro; // 我发给对方的信息
ests[n_bifs].rx_intro = &net_intro; // 对方发给我的信息
n_bifs++;
}Socket
sockaddr_un= Unix 域套接字地址结构体_un= Unix 的缩写(表示本地进程间通信)saun=sockaddr_un的简写sun_= sockaddr_un 前缀(为了统一命名)sun_family是宏展开出来的,不是手动写的socket()= 买了一部手机(得到手机号 / FD)bind()= 去营业厅把手机号和你本人绑定








结构体地址问题
nicif_ 不是指针!它是一个实实在在的结构体变量!
结构体变量一旦创建,它的内部所有成员就已经存在内存里了!
不需要提前初始化,也不需要赋值,就能取地址!

 即使里面的值是随机的、脏的,变量本身是存在的!
即使里面的值是随机的、脏的,变量本身是存在的!
struct SimbricksBaseIf *netif = &nicif->net.base;
struct SimbricksBaseIf *pcieif = &nicif->pcie.base;
为什么这两行没问题?
因为:
-
nicif是一个有效指针 (你传的是&nicif_) -
nicif->net已经存在(结构体成员) -
nicif->net.base也已经存在 -
所以
&nicif->net.base是合法地址
这里仅仅是取地址!没有读里面的值!

CXL




CXLCache



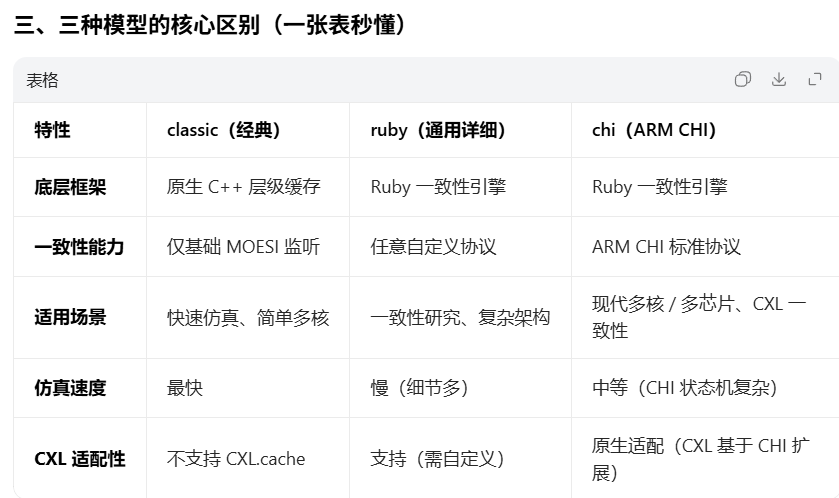
CXL Type3
4.1 Type 3(内存扩展器)Classic 模式完整链条
用户运行:
gem5.opt x86-cxl-type3-with-classic.py
│
▼
[Python 初始化阶段]
1. 创建 SimpleBoard / X86Board
2. 配置 PrivateL1PrivateL2SharedL3CacheHierarchy
(L1 32K/32K + L2 512K + L3 96M, MESI)
3. 创建 DIMM_DDR5_4400 × 2
- memory[0]: 3GB 主机内存 @ 0x00000000
- memory[1]: 8GB CXL 内存 @ 0xC0000000 (CXL 地址空间)
4. 注入 CXLBridge(位于 L3 缓存与 CXL DRAM 控制器之间)
5. set_kernel_disk_workload(vmlinux, disk_img, cmd)
6. simulator.run()
│
▼
[gem5 事件驱动模拟启动]
7. KVM CPU 快速启动 Linux 内核(跳过 Boot 细节)
8. Linux 内核通过 ACPI/SRAT 发现 CXL NUMA 节点
9. m5 exit 事件触发 → 切换到 TIMING/O3 CPU
│
▼
[基准测试执行阶段]
10. 用户程序发起内存访问(例如 numactl --membind=1 ./test)
│
▼
[CPU 访问 CXL 内存的周期级模拟路径]
CPU 核心(O3/TIMING)
→ L1D Cache(MESI 查找)
→ L2 Cache(MESI 查找)
→ L3 Cache(共享,MESI 查找)
→ Cache Miss → 发送 MemReq 包到内存总线
│
▼
CoherentXBar(一致性总线)
→ 地址解码:命中 CXL 地址范围?
→ Yes → 路由到 CXLBridge
│
▼
CXLBridge::BridgeResponsePort::recvTimingReq()
→ 检查地址是否在 cxl_range 内
→ 计算 total_delay = bridge_lat + proto_proc_lat
→ 设置 pkt->cxl_cmd = M2SReq(读)/ M2SRwD(写)
→ 将包推入 reqQueue,调度 schedTimingReq 事件
│
[等待 total_delay 周期]
│
▼
CXLBridge::BridgeRequestPort 发送请求
→ CXL 设备侧 MemCtrl::recvTimingReq()
→ DRAM Interface 计算 DRAM 时序(tCL, tRCD, tRP...)
→ 生成响应包,pkt->cxl_cmd = S2MDRS(含数据)
│
[等待 DRAM 访问延迟]
│
▼
CXLBridge::BridgeResponsePort 接收响应
→ 推入 respQueue
→ 调度 schedTimingResp 事件
│
[等待 bridge_lat 返回延迟]
│
▼
CoherentXBar → L3 Cache 填充
→ L2 Cache 填充
→ L1D Cache 填充
→ CPU 寄存器文件获得数据
│
▼
[周期计数更新,统计延迟/带宽指标]CXLBridge
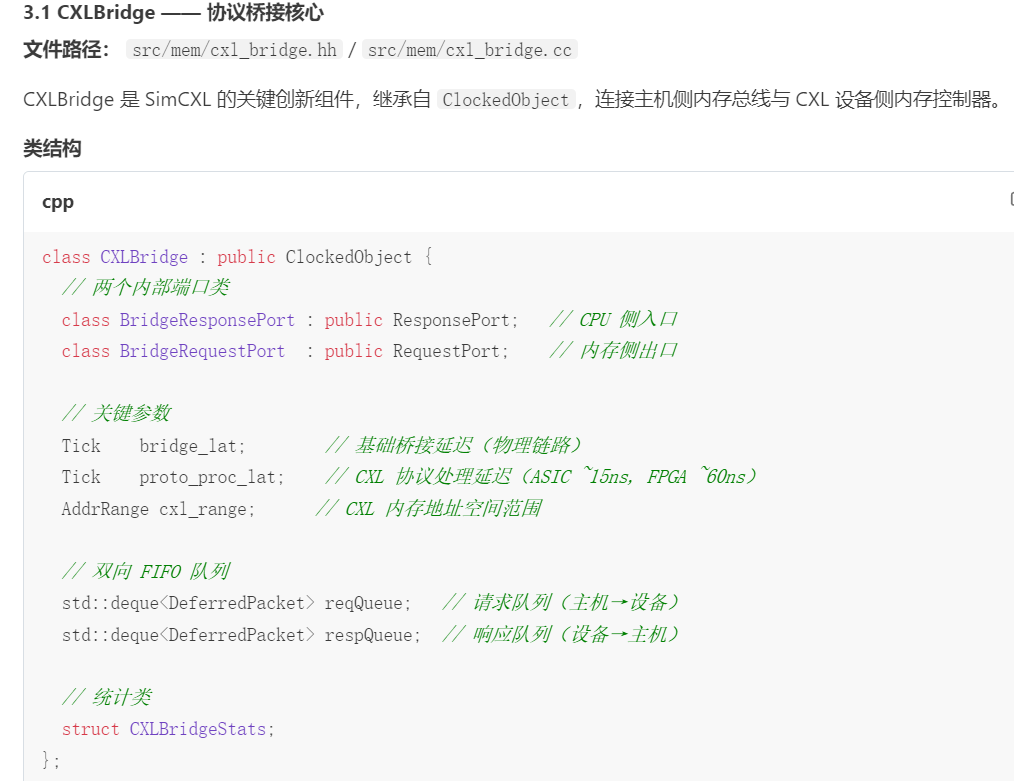

m5
m5 是 gem5 模拟器的核心 Python 模块,是用户与 gem5 底层 C++ 仿真引擎交互的入口,也是 SimCXL(基于 gem5 扩展)中控制仿真全生命周期的核心接口。
核心定位:
m5 模块由 gem5 构建系统通过 pybind11 自动生成(绑定 C++ 代码)+ 手动编写的 Python 封装组成,是 Python 层与 C++ 层的 "桥梁"。
所有仿真操作(实例化系统、启动仿真、读取统计信息、控制仿真流程)都通过 m5 模块完成,比如:
m5.instantiate():将 Python 定义的系统配置转化为 C++ 仿真对象;
m5.simulate():启动事件驱动的仿真循环;
m5.stats.dump():导出仿真统计数据;
m5.exit():终止仿真。
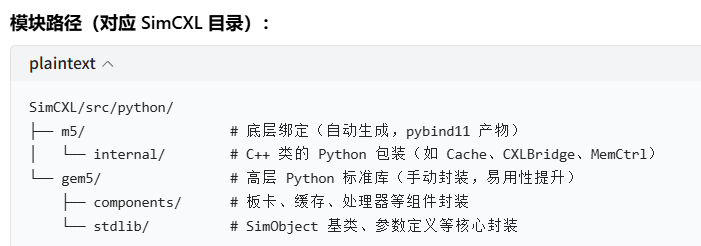
这是 SimCXL/gem5 中从高层易用的 Python 组件封装,到底层 C++ 绑定的调用链路,核心是 "把用户写的简洁 Python 配置,转化为底层 C++ 仿真对象",
C语言
socket()
创建一个通信端点(电话)
bind()
给 Socket 绑定一个路径地址(装电话号码)
listen()
开始等待别人连接(等电话)
fcntl()
修改文件描述符属性(设置非阻塞)
close()
关闭 Socket,释放资源(挂电话)
strlen(字符串)
- 作用:计算字符串长度
- 这里检查:Socket 路径太长会超出系统限制,无法绑定
listen 监听函数
- 作用:开始等待别人来连接
- 参数
5:等待连接的队列长度(最多等 5 个)
socket(地址族, 类型, 协议)
- AF_UNIX:本地进程间通信(机器内)
- SOCK_STREAM:可靠字节流(TCP 模式)
- 返回值
listen_fd- 文件描述符(相当于电话的 ID)
- 后面所有操作都靠它
bind 绑定函数(非常重要)
- 作用:把 Socket 和文件路径绑定在一起
- 相当于:给电话装上号码
- 别人通过这个路径就能找到你
strncpy 字符串拷贝
- 安全复制字符串,防止超长溢出
代理
-
DNS 解析失败 --- Clash 配置了使用 Cloudflare 的 DoH(DNS over HTTPS)
dns.cloudflare.com/dns-query,但这个 DNS 服务器本身就被墙了,所以连 DNS 都查不了。 -
模式是"直连" --- 当前是
DIRECT直连模式,没有走代理,所以即使 DNS 解析出来,GitHub 的连接也大概率超时。
去左侧点「代理 」,把模式从「直连」改成「规则 」或「全局」:
- 规则模式 --- 按规则分流,推荐
- 全局模式 --- 所有流量走代理,用于测试
宏
宏 = 代码替换工具(文本替换)
- 宏就是给一段代码 / 内容起个别名
- 编译之前,编译器会把别名自动替换成真实内容
- 纯文本替换,不理解语法,只是无脑替换!



