接到不少有关数据同步的需求,其中一个需求,需要将10多张 mysql 表每天定时导入到 starrocks,于是顺带写了一个小工具实现了快速批量同步表的功能,手敲指令的工作变少了。不过前期测试这个工具的时候,还是没少在命令行和 vscode 之间反复折腾
刚好公司最近采购了一些 cursor 账号,再加上了解到 cursor 有 cli 命令行模式之后,就想到这个需求,假如我不依赖其他代码和工具,能让 cursor 直接完成整个数据同步需求吗?
那么本文就是从这样,从一个简化版的需求入手,但尝试把过程做得完善的 cursor cli 使用方式探索
在正式开始任务之前,我们需要先简单了解一下什么是 ETL,以及 cursor cli 怎么安装
ETL
ETL 可能是很多人接触大数据,第一个了解到的概念。它的确是在大数据种类繁杂的任务中,执行时间放在第一位的。ETL 负责把业务的原始数据按照一定的过滤规则和约定格式进行清洗和转换,再通过工具和数据库接口,导入到大数据体系的数据仓库中
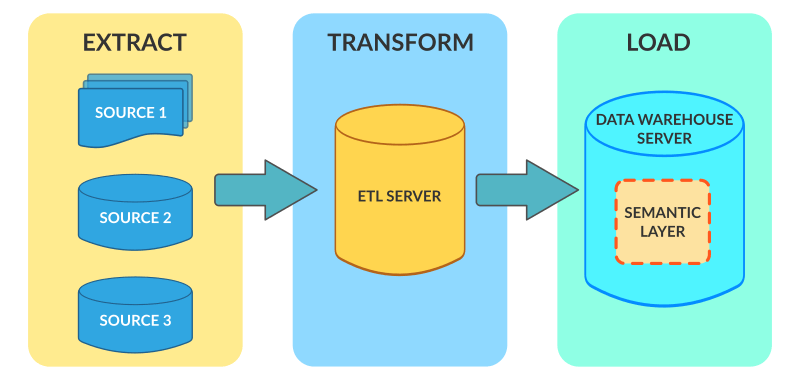
E: Extract , 从源表提取数据,在这里你可以做数据筛选
T: Translate , 数据在导入数仓之前,进行的数据内容和格式的转换,比如一个 json 格式的字符串字段,业务只需要其中的一个键值,就会在这个阶段进行提取
L: Load, 数据最终写入到数仓的过程
下图是 ETL 过程对应到现实中需要怎么做的4步曲
cursor cli
AI 时代最流行的就是 AI 辅助编程,如下图,在 cursor IDE 中直接提出需求让 AI 帮我们把基本的代码写好
当然 IDE 并不是这期的主角,而是 cursor cli ,它是 cursor 的命令行运行模式,可以直接在终端中给 cursor 发送指令,去生成代码、修改代码、与操作系统进行交互、使用 mcp 等,无需功能比较复杂的 IDE,保持最纯净的和 AI 之间对话的方式
这种模式非常适合执行有明确预期的任务。比如在 DevOps 流水线单测过程中修改 bug,在镜像制作过程中安装特定组件,以及接下来的数据完整同步的任务等
cursor cli 的安装非常简单,执行官方安装脚本即可
# 安装
curl https://cursor.com/install -fsS | bash
# 首次登录
# 注: 这个指令打印的链接不需要当前系统支持弹出浏览器,把链接复制到外部浏览器打开也可以
~/.local/bin/cursor-agent login
# 开启上一个会话
~/.local/bin/cursor-agent --resume=会话id,在退出时会显示
恢复上一次会话:

其他常用指令
# 查看登录状态
~/.local/bin/cursor-agent status
# 退出登录
~/.local/bin/cursor-agent logout
# 查看本地支持的 mcp 列表
~/.local/bin/cursor-agent mcp list
# 使用特定模型
# 目前支持模型: composer-1, auto, sonnet-4.5, sonnet-4.5-thinking, opus-4.5, opus-4.5-thinking, gemini-3-pro, gemini-3-flash, gpt-5.2, gpt-5.1, gpt-5.2-high, gpt-5.1-high, gpt-5.1-codex, gpt-5.1-codex-high, gpt-5.1-codex-max, gpt-5.1-codex-max-high, opus-4.1, grok
# --model: 设置模型名
# -p: print 输出结果之后结束会话
# --output-format: 设置输出格式: text / json
~/.local/bin/cursor-agent --model "gpt-5.2" -p "查找当前项目的问题并修复" --workspace /opt/coding/go_common --output-format text这里我没有切换模型,使用的是 cursor 默认的模型 composer-1,后续我测试了 gpt-5 ,效果和默认模型差不多
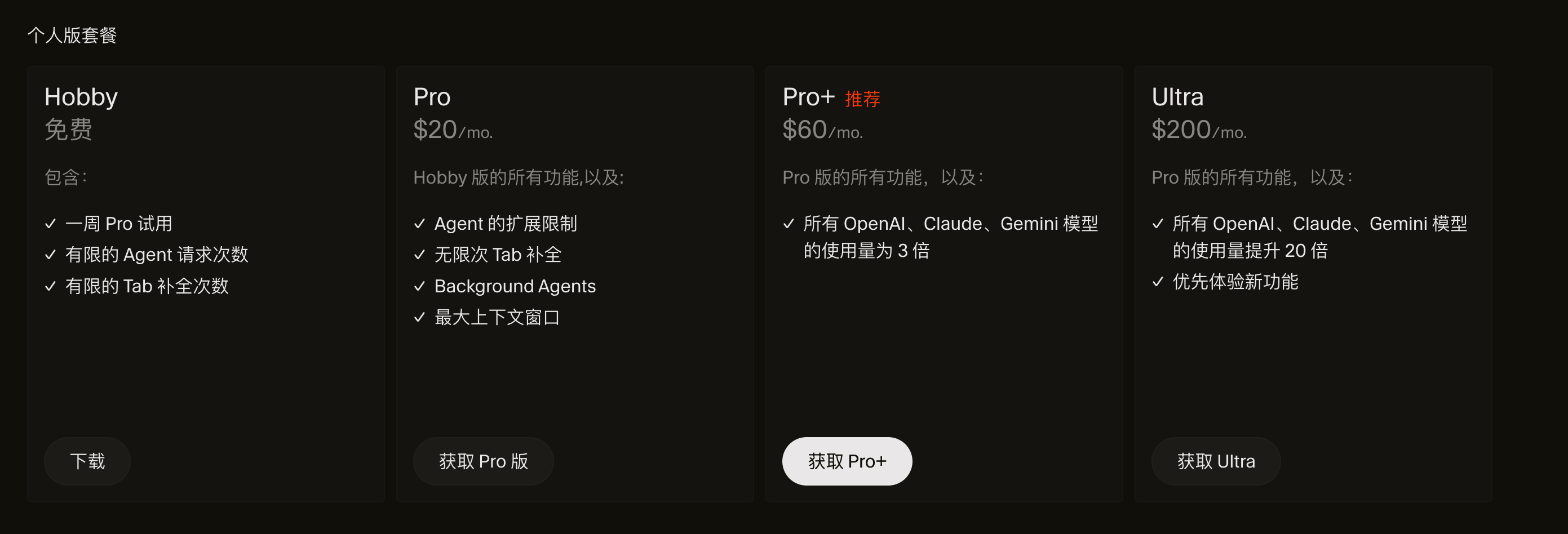
cursor 价格: 有14天的免费适用, 对普通用户来说 Pro 套餐足够了,一个月100多元
整体任务设计思路
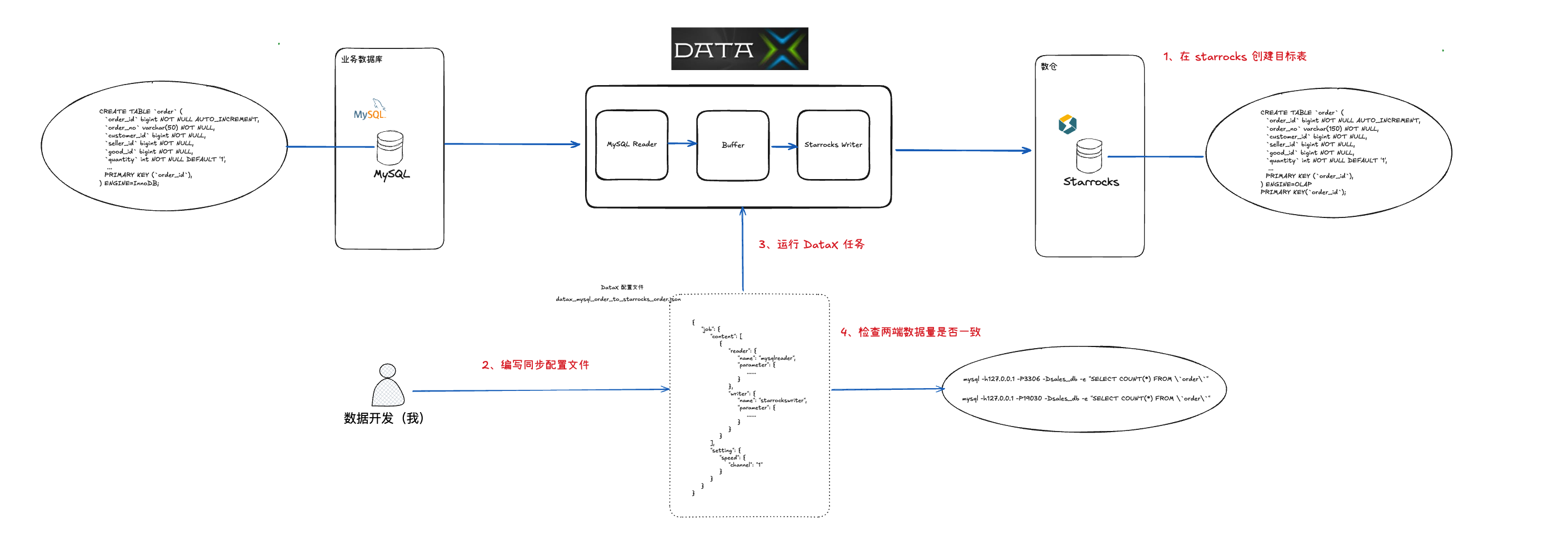
遵循着尽量让过程更完善的思路,我们希望让 cursor 做更多的事情,因此整体任务的设计包括 DataX 安装、数据库安装和 ETL 数据同步三个部分
一点点的准备工作也还是需要的,在自己电脑我们可以通过 docker 启动一个 centos8 或者 ubuntu24 的容器,或者公司有给你提供一个纯净的测试虚拟机也可以
- 注: 不能用 centos7 因为内核版本较低,不支持运行 cursor cli 中的一些 nodejs 库,至少需要 centos8
通过 cursor 辅助我们,任务流程变成了下图:
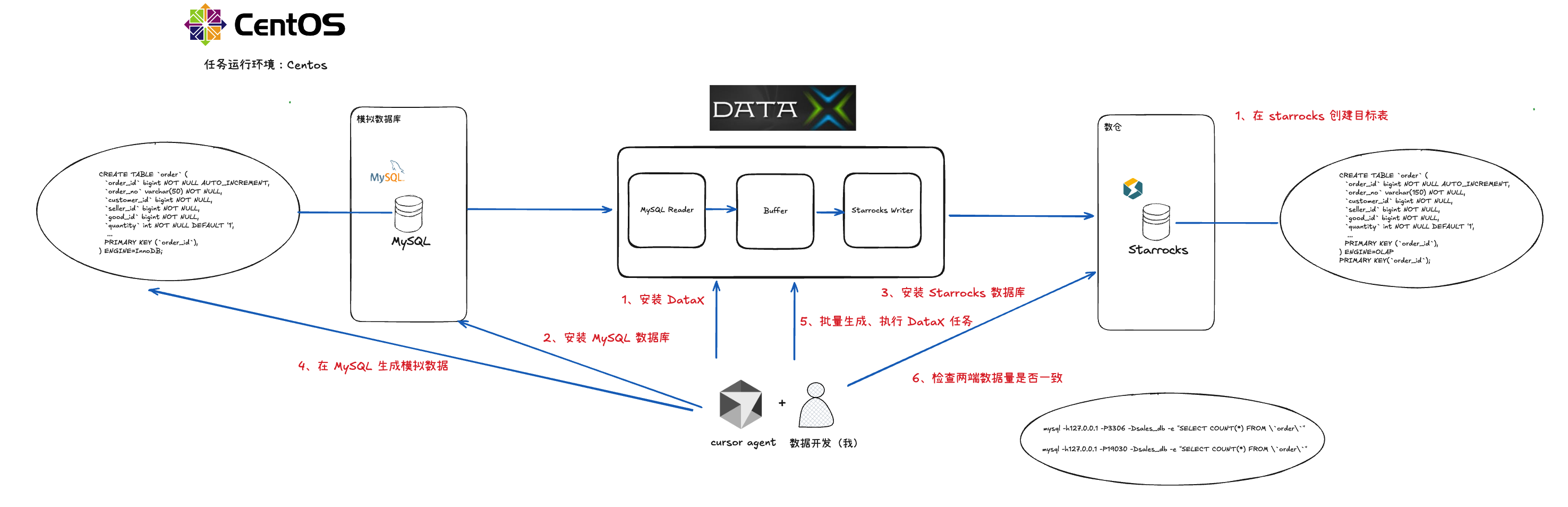
过程
step 1: 安装 DataX
DataX 是阿里开源的跨数据库批量数据同步工具,它不涉及服务端,所以它的安装过程是比较简单的,我们先把它安装好
help me install datax at /opt/modules, including basic environment一些关键日志:
# 分析安装 datax 详细步骤
⬢ To-do Working on 5 to-dos
☐ 创建 /opt/modules 目录
☐ 安装 Java 环境(JDK 1.8+)
☐ 下载 DataX 安装包
☐ 解压并配置 DataX
☐ 配置环境变量
# 安装目录、下载命令行工具检查
$ ls -la /opt/modules 2>/dev/null || echo "Directory does not exist" 77s
total 0
drwxr-xr-x 13 root root 173 Nov 21 23:50 .
... truncated (13 more lines) · ctrl+o to expand
$ which wget curl 2>/dev/null || echo "Need to check download tools" 77s
/usr/bin/wget
/usr/bin/curl
... truncated (1 more line) · ctrl+o to expand
# 检查 java 是否安装
Checking Java installation (required for datax), then downloading and installing datax.
$ java -version 2>&1 | head -1 12s
openjdk version "1.8.0_432"
# 下载 datax
$ cd /tmp && wget --no-check-certificate -O datax.tar.gz
"https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz" 2>&1 | tail -5 183s
1639950K .......... .......... .......... .......... .......... 99% 8.75M 0s
1640000K .......... .......... ... 100% 11.0M=2m38s
... truncated (4 more lines) · ctrl+o to expand
# 校验安装是否成功
$ ls -lh /opt/modules/datax/job/ 2>&1 | head -10 6.2s
total 4.0K
-rw-r--r-- 1 1001 1001 1.6K Aug 23 13:03 job.json
... truncated (1 more line) · ctrl+o to expand从日志可以看出 cursor 在安装组件任务上,步骤比较"严谨"的特点:
-
执行任务之前,它会详细列出具体每一步会做什么,包括完整的准备、安装和检查,很清晰和标准
-
在加上了需要安装基础环境的 prompt 说明之后,运行 DataX 需要的 python 和 JDK 它都会装好
也有一些小瑕疵:
-
在 DataX 已经安装的情况下,再次发送相同的 prompt,还是要30s左右跑完
因为它需要在系统执行
ls、python bin/datax.py等指令,先将指令的返回传给 cursor 的后台服务器,再等待服务端的判断结果,大部分耗时可能都在接口调用上了 -
DataX 的官方下载地址 datax-opensource.oss-cn-hangzhou.aliyuncs.com 提供的其实不是最新的版本,它的更新日期只到 202308,但官方仓库在那之后还是有少量更新,想用最新版本应该直接编译源码
安装 mysql
第二步是安装 mysql,这里我顺便尝试让 cursor 把 root 密码和数据存储路径也修改一下
help me install mysql at /opt/modules/mysql, start at 3306 port and set default root user password to Root@888 and set data dir to /opt/data/mysql一些关键日志:
# 分析详细步骤
⬢ To-do Working on 7 to-dos
☐ 检查系统环境和现有 MySQL
☐ 创建安装目录和数据目录
☐ 下载并安装 MySQL
☐ 配置 MySQL(端口、数据目录)
☐ 初始化 MySQL 数据库
☐ 设置 root 密码为 Root@888
☐ 启动 MySQL 服务并配置开机自启
# 下载 mysql 官方 linux 安装包
$ cd /opt/modules && wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-8.0.37-linux-glibc2.12-x86_64.tar.xz -O mysql.tar.xz
2>&1 | tail -15 35s
# 基本配置
etc/my.cnf +27
+ [mysqld]
+ # 基本配置
+ port = 3306
+ datadir = /opt/data/mysql
+ socket = /tmp/mysql.sock
+ pid-file = /opt/data/mysql/mysql.pid
+ # 字符集
+ character-set-server = utf8mb4
+ collation-server = utf8mb4_unicode_ci
+
# 解决依赖库缺少的问题
$ yum install -y libaio numactl-libs 2>&1 | tail -20 66s
(2/2): numactl-libs-2.0.12-13.el8.x86_64.rpm 161 kB/s | 36 kB 00:00
--------------------------------------------------------------------------------
... truncated (19 more lines) · ctrl+o to expand
# 初始化 mysql 并设置密码
$ /opt/modules/mysql/bin/mysqld --initialize-insecure --user=mysql --datadir=/opt/data/mysql --basedir=/opt/modules/mysql 2>&1 | tail -5 14s
$ su - mysql -s /bin/bash -c "/opt/modules/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf --user=mysql --datadir=/opt/data/mysql
--basedir=/opt/modules/mysql > /dev/null 2>&1 &" && sleep 5 16s
# 完成安装
mysql -u root -pRoot@888安装完成后查看进程:

安装 mysql 是所有阶段中做得最好的一步:
-
首先是版本,选择的 8.0.37 是去年5月的版本,对 mysql 而言还是比较新的
-
系统中诸如 libaio 、libnuma、ncurses 等依赖库缺少的问题,它都能解决
-
设置 root 密码需要先启动 mysql 初始化之后再设置,这个步骤也是完全正确
-
/etc/my.cnf 中还设置了和慢查询、字符集、最大连接数等在生产环境常用的优化配置
安装 starrocks
接着我们安装大数据体系中的实时数仓服务 starrocks。starrocks 的安装就明显比前面两个安装要复杂一些了,所以在 prompt 中我们也需要写得更详细
help me to install starrocks at /opt/modules/starrocks, following the steps
1. download starrocks version 3.3.20 from https://releases.starrocks.io/starrocks/StarRocks-3.3.20-centos-amd64.tar.gz
2. install to /opt/modules
3. set fe mysql port set to 19030
4. default root user password to Root@Star666
5. register be to fe, be ip use local ipv4 ip and port use 9050
6. start fe and be
# 注: 如果你是用 ubuntu 系统,需要把下载地址改成 https://releases.starrocks.io/starrocks/StarRocks-3.3.20-ubuntu-amd64.tar.gz一些关键日志:
# 分析安装步骤
⬢ To-do Working on 7 to-dos
☐ 下载 StarRocks 3.3.20 版本
☐ 解压并安装到 /opt/modules/starrocks
☐ 配置 FE (MySQL 端口 19030, root 密码 Root@Star666)
☐ 配置 BE (端口 9050)
☐ 启动 FE 并初始化
☐ 注册 BE 到 FE
☐ 启动 BE 并验证
# 设置 fe 的配置
│ opt/modules/starrocks/fe/conf/fe.conf +1 -1
│
│ http_port = 8030
│ rpc_port = 9020
│ - query_port = 9030
│ + query_port = 19030
│ edit_log_port = 9010
# 设置 root 密码并注册 be
$ mysql -h 127.0.0.1 -P 19030 -uroot -e "ALTER USER 'root'@'%' IDENTIFIED BY 'Root@Star666';" 2>&1 | grep -v Warning exit 1 • 7.4s
$ BE_IP=$(hostname -I | awk '{print $1}') && BE_PORT=9050 && echo "注册 BE: ${BE_IP}:${BE_PORT}" && mysql -h127.0.0.1 -P19030 -uroot
-pRoot@Star666 -e "ALTER SYSTEM ADD BACKEND '${BE_IP}:${BE_PORT}';" 2>&1 | grep -v Warning exit 1 • 5.6s
$ sleep 15 && mysql -h 127.0.0.1 -P 19030 -uroot -pRoot@Star666 -e "SHOW BACKENDS\G" 2>&1 | grep -E
"(Host|Port|Alive|SystemDecommissioned)" | head -8 21s
HeartbeatPort: 9060
BePort: -1
# 完成安装
mysql -h127.0.0.1 -P19030 -uroot -pRoot@Star666安装完成后的进程,以及查看 be 注册情况:
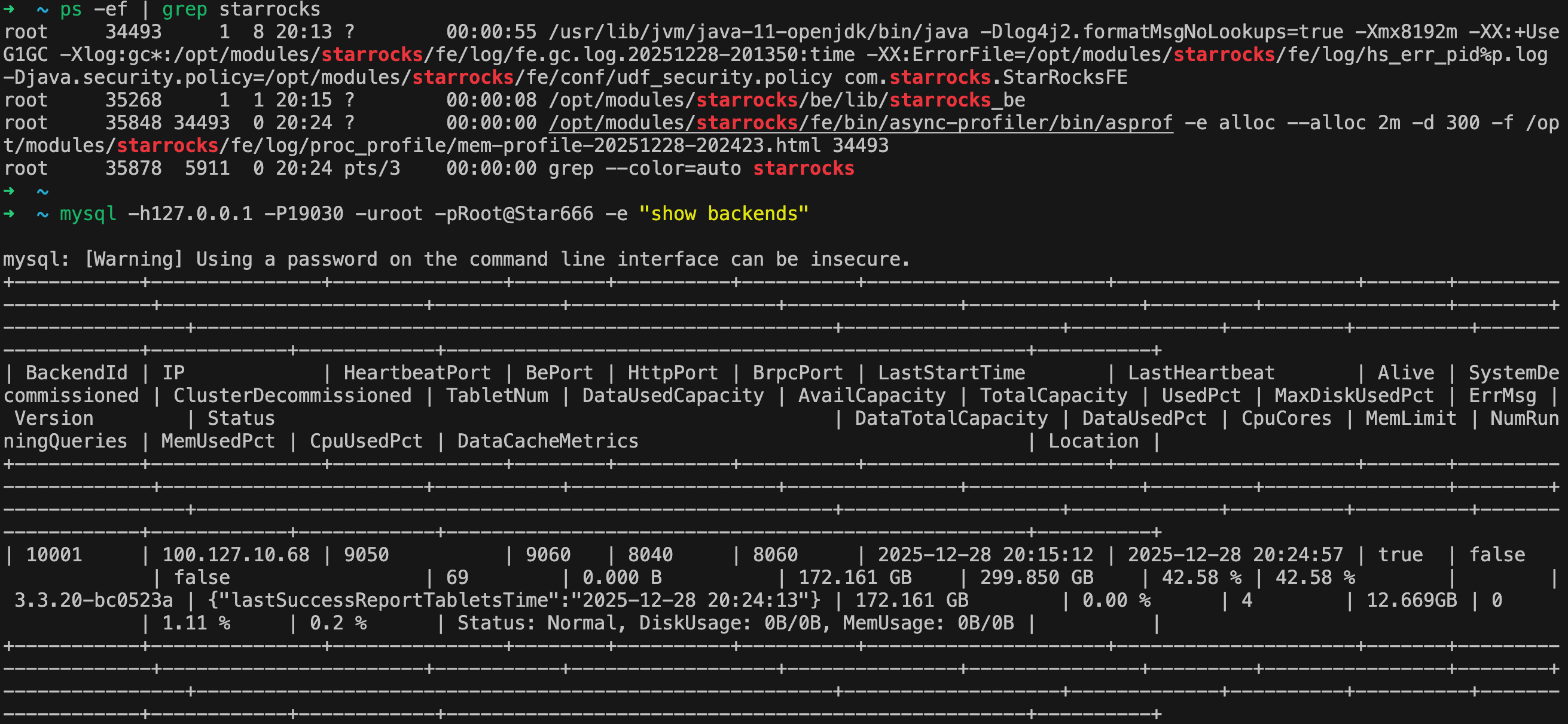
体会:
-
第一次安装时,我故意没有告诉它安装包下载地址,它先尝试从官方下载 3.1.8 的版本,但可能是这个版本比较早了,从官方下载返回文件不存在。然后它就继续尝试从 apache repo 去下载,但是这一步就明显错误了,starrocks 项目并不在 apache 组织下
所以这才有了上面的 prompt,我需要把确定能下载到安装包的版本号告诉它才行
-
starrocks 的主要服务包括负责处理查询请求的 fe 和 负责数据存储的 be ,完整安装也包括这两个组件的启动、注册和状态检查,因此 cursor 在安装时的过程比较复杂,时间也更长
-
be 注册时,fe 会检查注册指令传入的 be ip 和 be 上报的节点的 ipv4 ip 是否一致 ,若不一致会报
FE saved address not match backend address,所以在 be 的注册指令add backend必须用本机的 ipv4 ip 去注册。但关于这点 cursor 是不知道的,它会用 127.0.0.1 去注册,导致 be 无法激活和写入数据。因此这个细节也需要在 prompt 中说明 -
在 mysql 的配置文件
my.cnf可以看到一些生产级别的优化,但是 starrocks 的 fe 和 be 配置中就没有了
mysql 中插入模拟电商场景的数据
如果你想测试一个数据库支持的函数、查询性能等,先把数据制造出来,写到数据库中,往往是重要的第一步。常见的造数据方法有两个: 通过脚本或工具生成纯随机的文本、数字等,比如 flink 的 datagen 或者 seatunnel 的 FakeSource;第二种是直接使用一些网站提供的数据集,比如 kaggle 这里提供了比较真实的 csv 格式数据,你可以用脚本导入到数据库中再进行测试