大家好,我是袋鼠帝。
之前我在B站看到一位AI视频创作者分享他的工作流。不可否认,那套流程做出来的视频确实很专业,画面精美,运镜流畅。但是,看完我只觉得头皮发麻。
原文档找不到了,我记得他先是用Gemini写剧本,接着用NanoBanana跑画面,然后再去另外的配音平台搞音频,中间穿插着使用ComfyUI来控制视频、图片生成。
ComfyUI这玩意儿我以前也折腾过几次,连线复杂就算了,每个节点的各种配置参数直接给我整懵逼了,我感觉比当初学敲代码还难,后面就再也没碰过了。
然后整个流程的最后一步,是用即梦的Seedance 2.0去生成最终的视频。
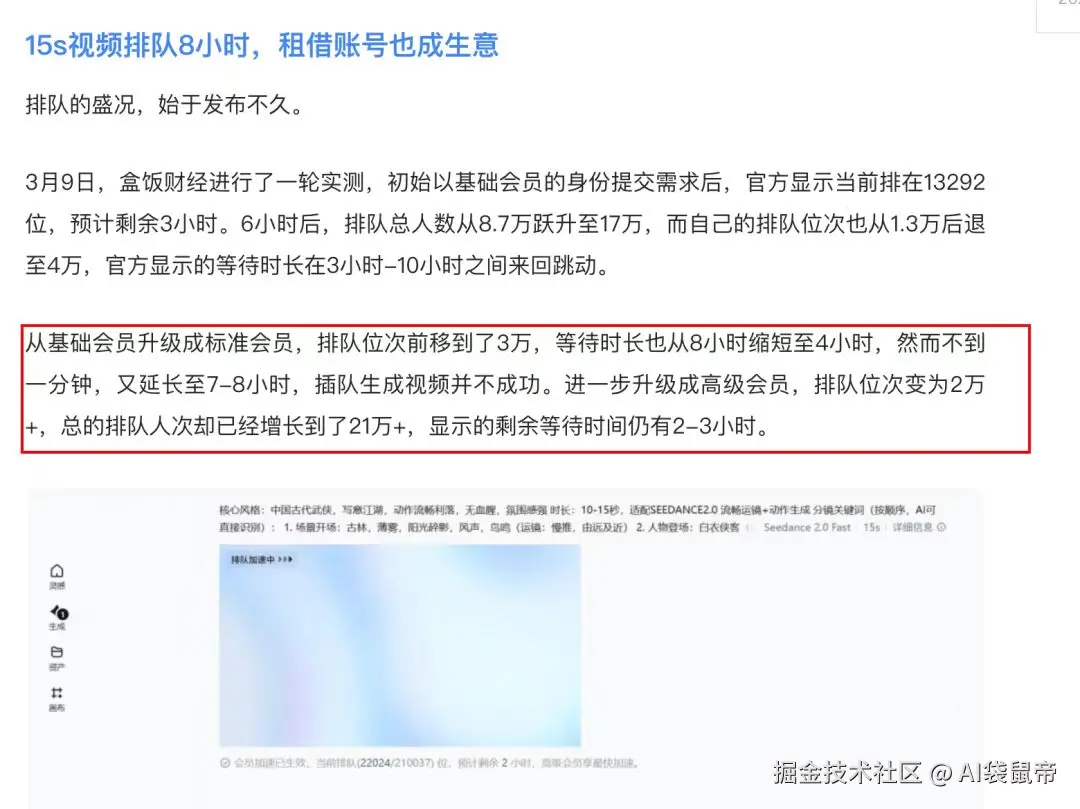
大家应该都知道,Seedance 2.0的效果虽然是公认的天花板,但即梦那边的生成速度,真的是能让人等到怀疑人生。
根据3月的资料显示,高峰期居然有几十万人排队,生成一个视频甚至一天就过去了😅。等视频出来了,当时创作的灵感和激情也就被消磨没了。
 而且上面所说的工作流存在一个让人非常难受的点:严重的孤岛效应。 你的剧本、人物设定、分镜、视频片段、音频素材,全部散落在不同的平台和软件里。它们就像一座座孤岛,没法形成一个连贯的、可复用的工作流。这就导致你这次做完一个视频,下次如果想做个同系列或者类似风格的,还得重新打开那些乱七八糟的软件,从头再搭一遍积木,负担重。
而且上面所说的工作流存在一个让人非常难受的点:严重的孤岛效应。 你的剧本、人物设定、分镜、视频片段、音频素材,全部散落在不同的平台和软件里。它们就像一座座孤岛,没法形成一个连贯的、可复用的工作流。这就导致你这次做完一个视频,下次如果想做个同系列或者类似风格的,还得重新打开那些乱七八糟的软件,从头再搭一遍积木,负担重。
发现群友也在吐槽,即梦Seedance2.0太慢了。
 不过,最近有个好用的破局工具。 LibTV°终于接入了万众瞩目的Seedance 2.0! www.liblib.tv/
不过,最近有个好用的破局工具。 LibTV°终于接入了万众瞩目的Seedance 2.0! www.liblib.tv/
 最关键的是,在LibTV里跑Seedance 2.0,速度非常快,几分钟就能出一条高质量的视频,彻底治好了我的排队焦虑。
最关键的是,在LibTV里跑Seedance 2.0,速度非常快,几分钟就能出一条高质量的视频,彻底治好了我的排队焦虑。
另外,LibTV是一个真正意义上的All in One创作平台。 它把剧本撰写、分镜设计、视频生成、语音配音,以及一块极其自由的无限画布,全部打包在了一起。你可以在这里一条龙搞定整个AI视频的创作流程。
它还有一个很大的好处: 你创作过程中产生的所有中间资产,都会被沉淀保存在画布⾥,流程也可复用。
 以下是用LibTV+Seedance2.0快速制作的一个完整短片。 主题是「打工人精神胜利法」,赛璐璐风格的动漫故事,讲述了被老板压迫的打工人在一次和老板开会时又被PUA开始幻想自己在拳台上打的老板鼻青脸肿。一起看完成片吧~
以下是用LibTV+Seedance2.0快速制作的一个完整短片。 主题是「打工人精神胜利法」,赛璐璐风格的动漫故事,讲述了被老板压迫的打工人在一次和老板开会时又被PUA开始幻想自己在拳台上打的老板鼻青脸肿。一起看完成片吧~
 做AI视频,最难的从来不是生成某一个惊艳的单镜头,而是如何把这些镜头拼凑成一个完整的故事,并且还能保持人物一致、镜头风格和剧情发展的连贯性。
做AI视频,最难的从来不是生成某一个惊艳的单镜头,而是如何把这些镜头拼凑成一个完整的故事,并且还能保持人物一致、镜头风格和剧情发展的连贯性。
LibTV在工程化这方面,做得很出色。 同时,也不得不再次感叹,Seedance 2.0的效果还是一贯的稳定且惊艳。视频里那些丝滑的打斗动作,极具张力的视觉冲击,以及人物生动的微表情和肢体细节,都处理得极其到位。
这里放几张过程中的效果图给大家感受一下:
 最让人叫绝的是这些视频是我同时同步输入生成的! 也就是说当你在libtv里使用sd2.0模型,不仅不用排长队,还可以同步生成多个视频。(上限我还没试过哈哈,不过同时布置6-8个任务完全没问题)
最让人叫绝的是这些视频是我同时同步输入生成的! 也就是说当你在libtv里使用sd2.0模型,不仅不用排长队,还可以同步生成多个视频。(上限我还没试过哈哈,不过同时布置6-8个任务完全没问题)
最近那部电影风格非常的火,想到了《流金谷》系列,我决定也跟风尝试8火的。 一只猫大侠一只蝙蝠反派以及一个潮湿的街道,他们在夜里发出了我的刀盾以及呐喊...我想试试面对这个离谱的脚本,AI的导演思维能力到底如何
我尝试着只用一些尽可能简单的提示词去让它生成:
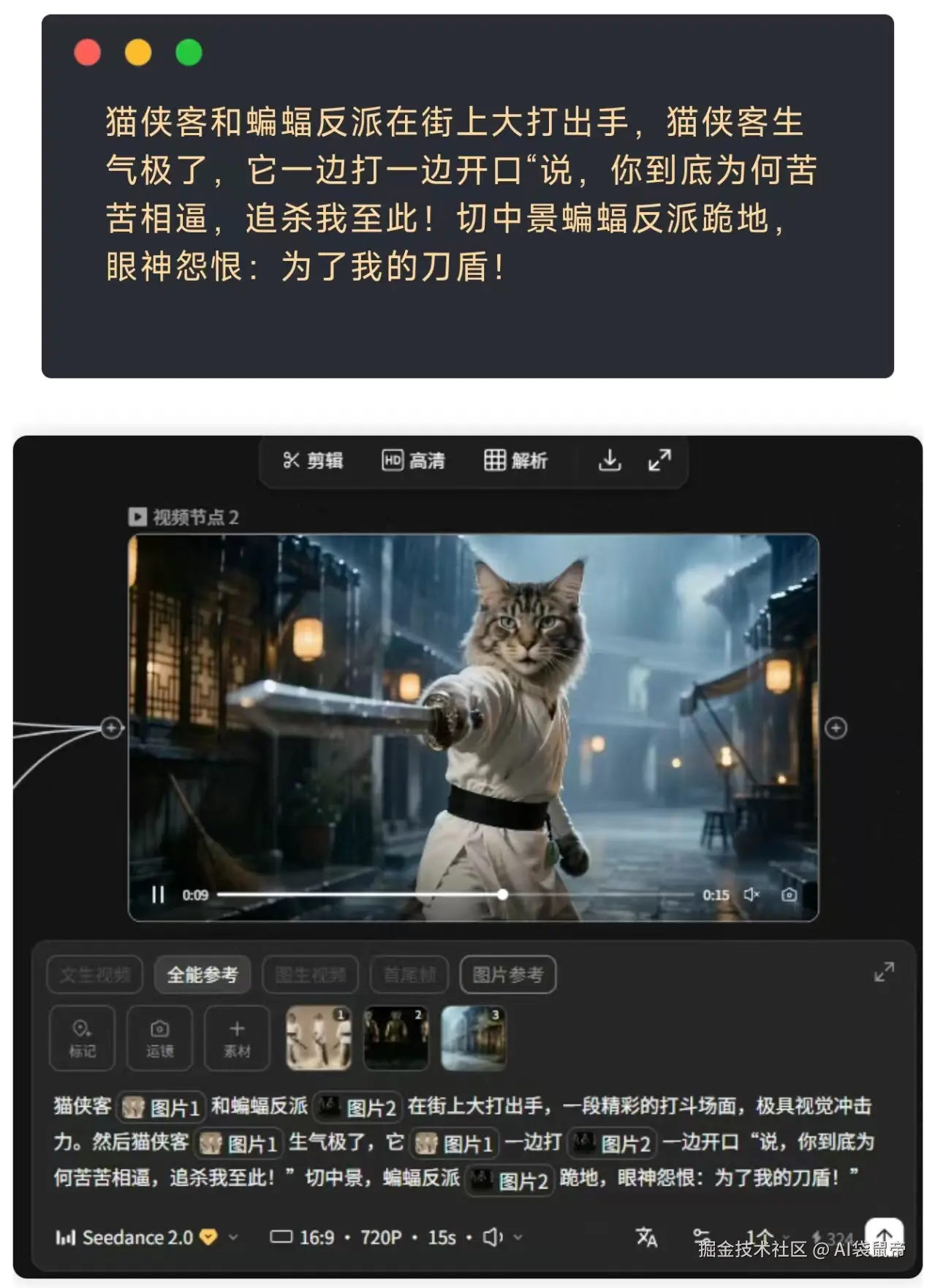 这是它根据这段简单提示词生成的视频效果:
这是它根据这段简单提示词生成的视频效果:
 确实不错。为了对比,我又写了一段更为详细、精确到动作细节和镜头切换的提示词,想看看它能不能严格遵循我的意图。
确实不错。为了对比,我又写了一段更为详细、精确到动作细节和镜头切换的提示词,想看看它能不能严格遵循我的意图。
新的提示词是这样的:
 这是详细提示词生成的视频效果:
这是详细提示词生成的视频效果:
 大家不妨在评论区说说看,你们更喜欢哪一条的效果?
大家不妨在评论区说说看,你们更喜欢哪一条的效果?
我个人的感觉是,简单的提示词生成的画面有着意想不到的创造力,简单的提示词就能完美复现你脑子里的分镜构想。这两条我都挺满意的。 既然讲故事和刻画打斗动作,它的表现都这么稳定,我决定再出一道难题考考它。 生成一段商业级的AI广告,一个关于葡萄汽水的短片广告。
老规矩,咱们先看效果。
 值得重点肯定的是,Seedance 2.0在多模态融合方面的能力真的很是强。 除了能在视频里看到的逼真的环境动作以及上面那段停不出来的葡萄汽水的广告的动作音效,这些都可以和画面同步输出之外。 只要我输入相应的提示词,它还能直接给我配上一个情绪非常饱满、极其贴合广告氛围的旁白音色。
值得重点肯定的是,Seedance 2.0在多模态融合方面的能力真的很是强。 除了能在视频里看到的逼真的环境动作以及上面那段停不出来的葡萄汽水的广告的动作音效,这些都可以和画面同步输出之外。 只要我输入相应的提示词,它还能直接给我配上一个情绪非常饱满、极其贴合广告氛围的旁白音色。
要知道,我以前每次制作视频,最头疼的就是配音环节。因为要在海量的素材库里寻找直接语气很搭针,质感完美契合画面的音色,简直就是大海捞针。 但如今,有了接入Seedance 2.0的LibTV,这一切都在一个画布⾥顺手解决了。 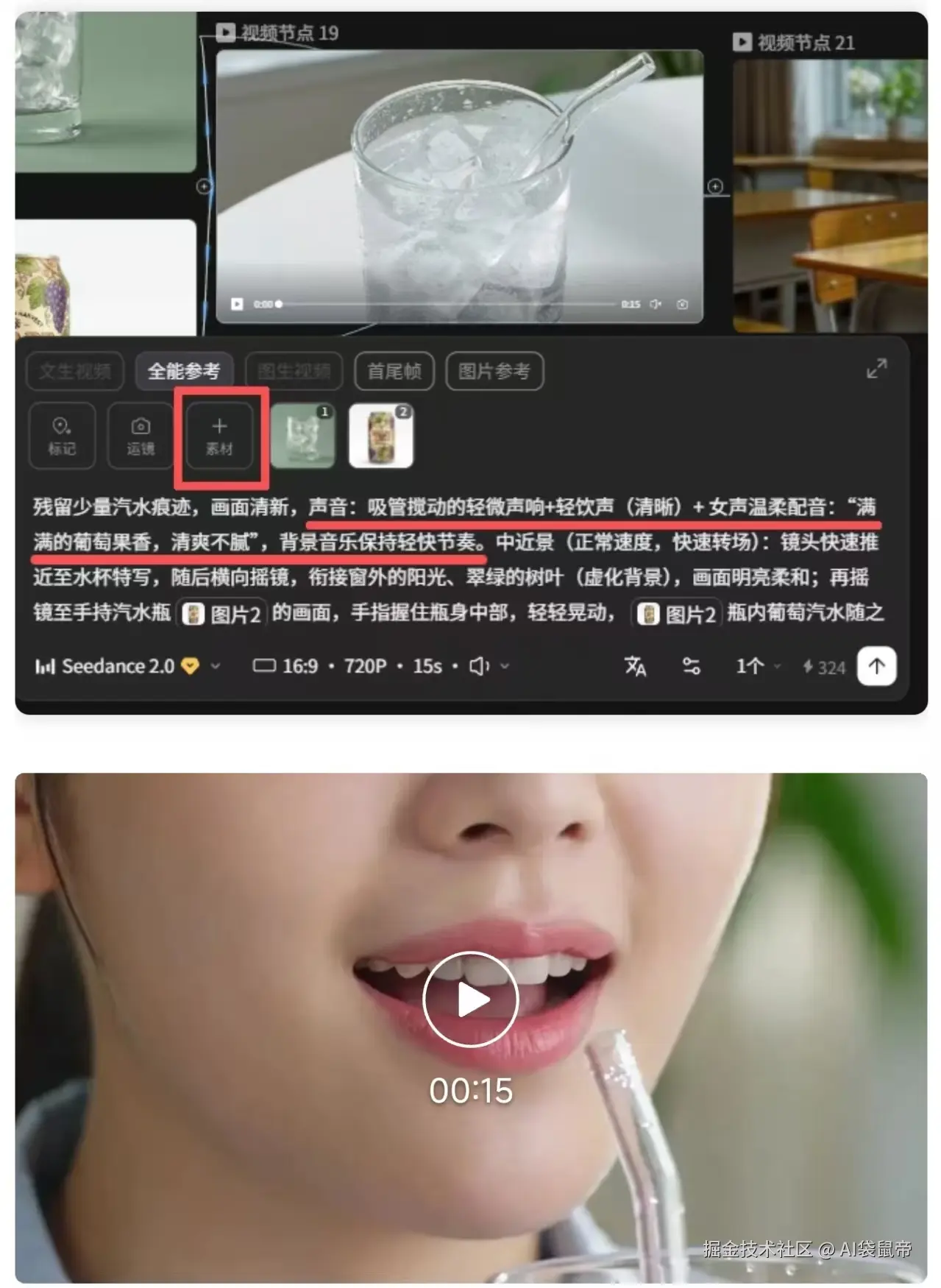 除了这些核心的生图生视频能力,LibTV还在工作流体验上做了很多极其贴心的细节功能。比如主体库智能补全三视图、旋转镜像、解析视频、音频处理等。
除了这些核心的生图生视频能力,LibTV还在工作流体验上做了很多极其贴心的细节功能。比如主体库智能补全三视图、旋转镜像、解析视频、音频处理等。
当你生成了一个满意的角色形象后,点击主体库的功能,它就能智能地帮你补全这个角色的其他视角图(比如侧面、背面)。 如果你自己之前已经做好了三视图,也可以直接上传作为标准资产。
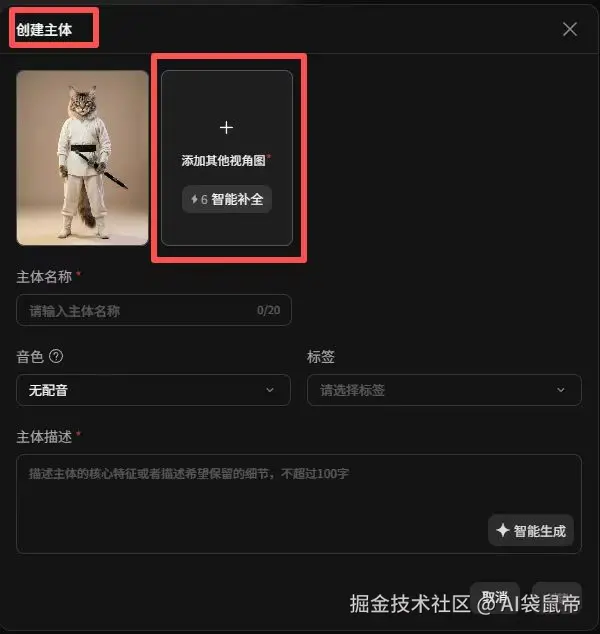 如果生成的画面构图不太理想,你可以点击旋转镜像功能。旋转的具体角度和镜像的方式,都可以由你自己精准控制。
如果生成的画面构图不太理想,你可以点击旋转镜像功能。旋转的具体角度和镜像的方式,都可以由你自己精准控制。
 还有一个对小白极度友好的功能:解析视频。
还有一个对小白极度友好的功能:解析视频。
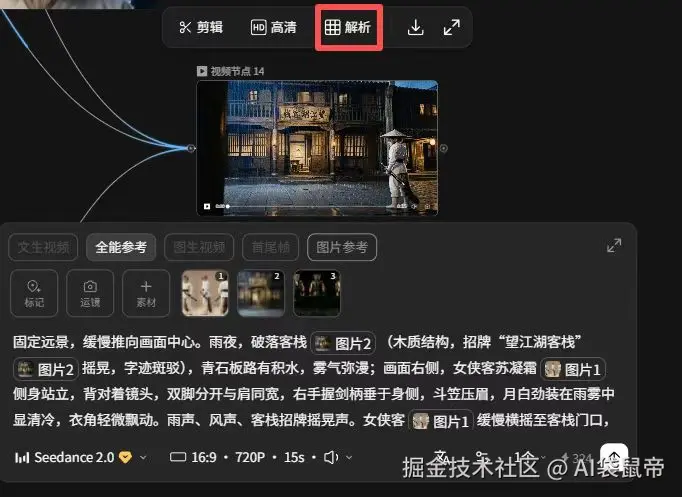
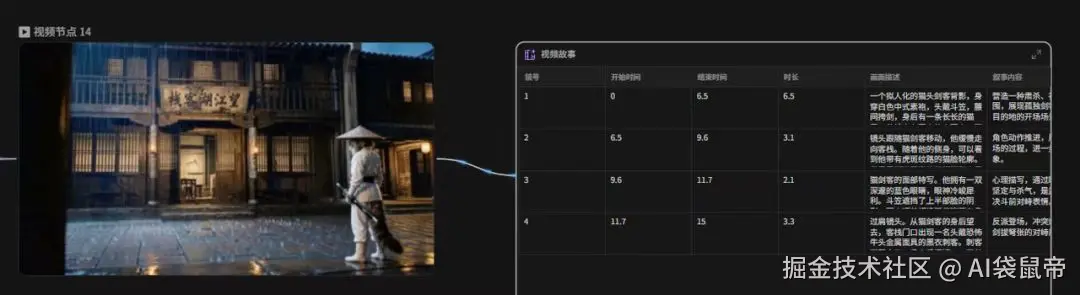
当你看到别人生成了一段非常牛的视频,你不知道他是怎么做到的。 你可以把视频扔进去解析,它就会反向推导出一个详细的分镜头脚本。 这就像是给了你一份参考答案,你可以顺藤摸瓜去学习别人的打光、运镜和提示词技巧。这在学习别人的优秀画布工作流时,简直是神器。
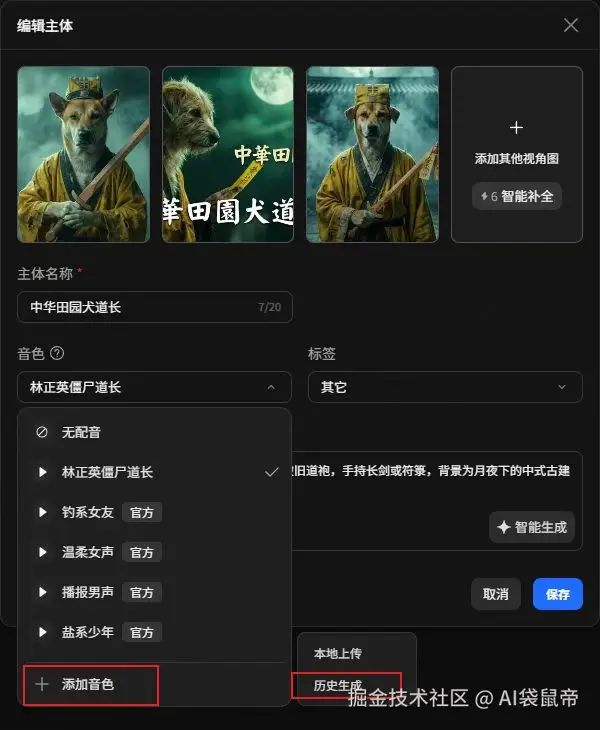
 在音频处理这块,LibTV也做了深度优化: 比如音色上传支持视频格式,素材导入更便捷 以前克隆音色,你还得专门去把视频转换成MP3格式。现在根本不需要这么麻烦,直接把包含目标声音的视频上传即可。 比如,前段时间抖音上那个林正英原声的橘猫道长特别火。我觉得那个正宗的九叔声音,是它视频能爆火的一个极其关键的原因。 于是我也想模仿那种90年代香港僵尸电影的风格。我把橘猫换成了中华田园犬,然后直接在网上找了一段林正英僵尸电影里的经典对白视频片段,直接上传了上去。
在音频处理这块,LibTV也做了深度优化: 比如音色上传支持视频格式,素材导入更便捷 以前克隆音色,你还得专门去把视频转换成MP3格式。现在根本不需要这么麻烦,直接把包含目标声音的视频上传即可。 比如,前段时间抖音上那个林正英原声的橘猫道长特别火。我觉得那个正宗的九叔声音,是它视频能爆火的一个极其关键的原因。 于是我也想模仿那种90年代香港僵尸电影的风格。我把橘猫换成了中华田园犬,然后直接在网上找了一段林正英僵尸电影里的经典对白视频片段,直接上传了上去。
这里提醒一下,上传提取音色的片段长度最好控制在5到30秒之间,太长是不行的。上传后系统会进行一个快速审核,审核通过后,你就能拥有一个属于你自己的九叔音色库了。 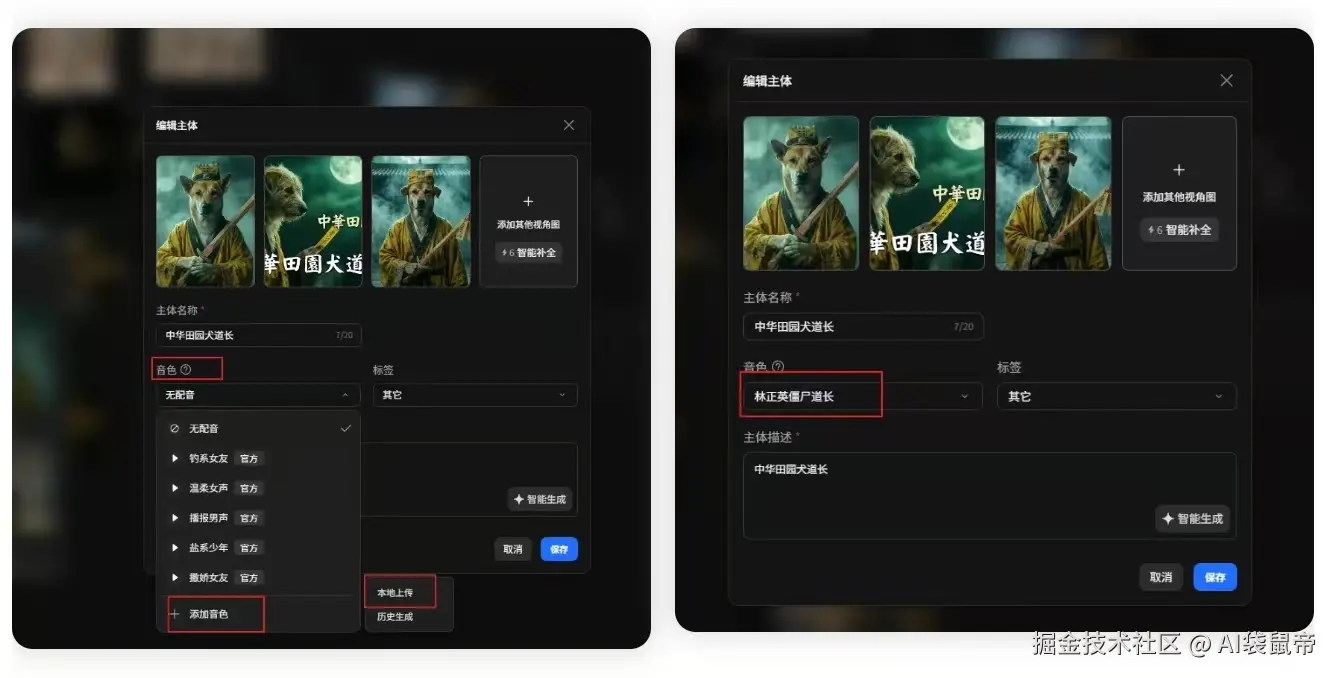 还可以从历史资产直接选用音色,复用更高效 如果你之前生成某个视频时,偶尔得到了一个极度满意的音色。你不需要重新去提取,系统允许你直接从历史满意的视频资产中,一键提取并复用那个音色。
还可以从历史资产直接选用音色,复用更高效 如果你之前生成某个视频时,偶尔得到了一个极度满意的音色。你不需要重新去提取,系统允许你直接从历史满意的视频资产中,一键提取并复用那个音色。
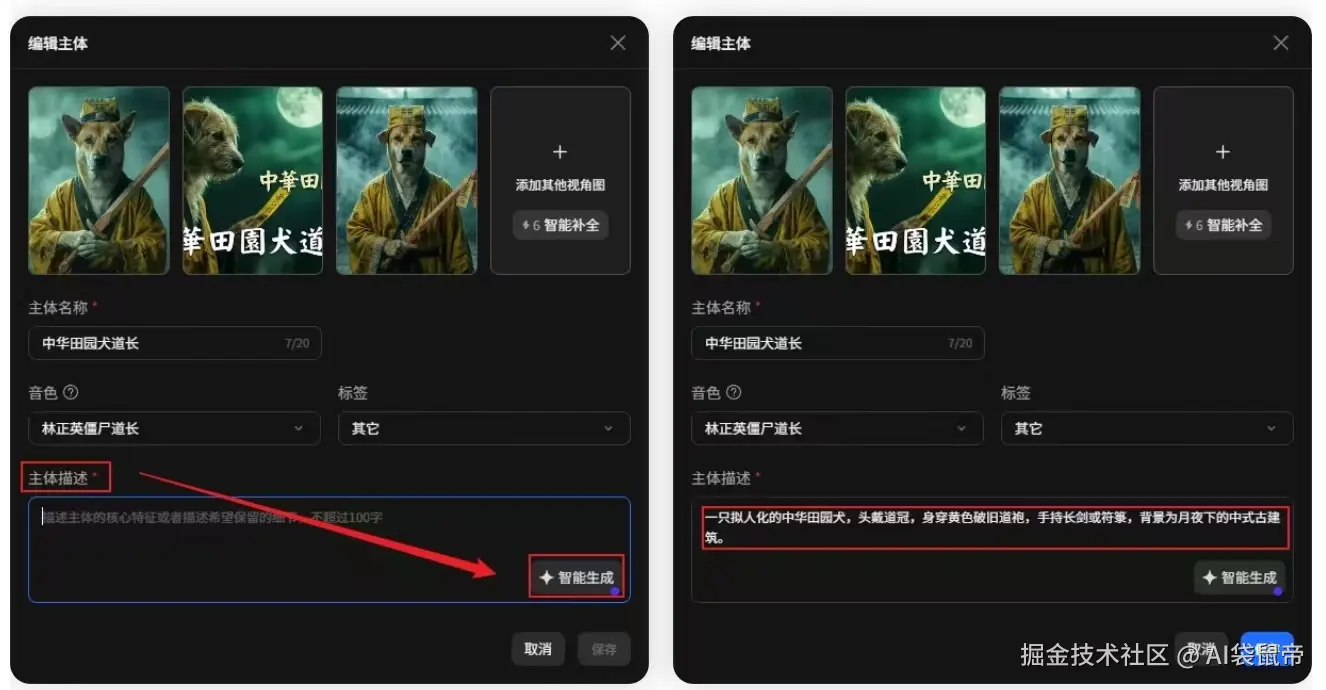
 主体描述支持AI自动生成,可以省去手动编辑 有时候我们捏出了一个好看的角色,但要用文字去极其精准地描述它的五官、穿着、气质,是一件很费脑子的事。现在,你可以直接使用AI一键生成主体描述。 你看这是AI帮我生成的描述,它捕捉到的细节,甚至比我自己写的还要精准。
主体描述支持AI自动生成,可以省去手动编辑 有时候我们捏出了一个好看的角色,但要用文字去极其精准地描述它的五官、穿着、气质,是一件很费脑子的事。现在,你可以直接使用AI一键生成主体描述。 你看这是AI帮我生成的描述,它捕捉到的细节,甚至比我自己写的还要精准。
 另外,必须提一句,LibTV不仅仅是一个供人类操作的图形化创作平台。它同样也能给(Agent)使用。 LibTV提供了专属的Skill: clawhub.ai/haofanwang/...
另外,必须提一句,LibTV不仅仅是一个供人类操作的图形化创作平台。它同样也能给(Agent)使用。 LibTV提供了专属的Skill: clawhub.ai/haofanwang/...
这意味着,你可以把它提供给你的龙虾(OpenClaw)、Claude Code、Codexα等自动化工具调用。
目前在LibTV里使用顶级的Seedance 2.0模型,还是有一定的门槛限制的。你需要是团队会员才能畅是这个功能。
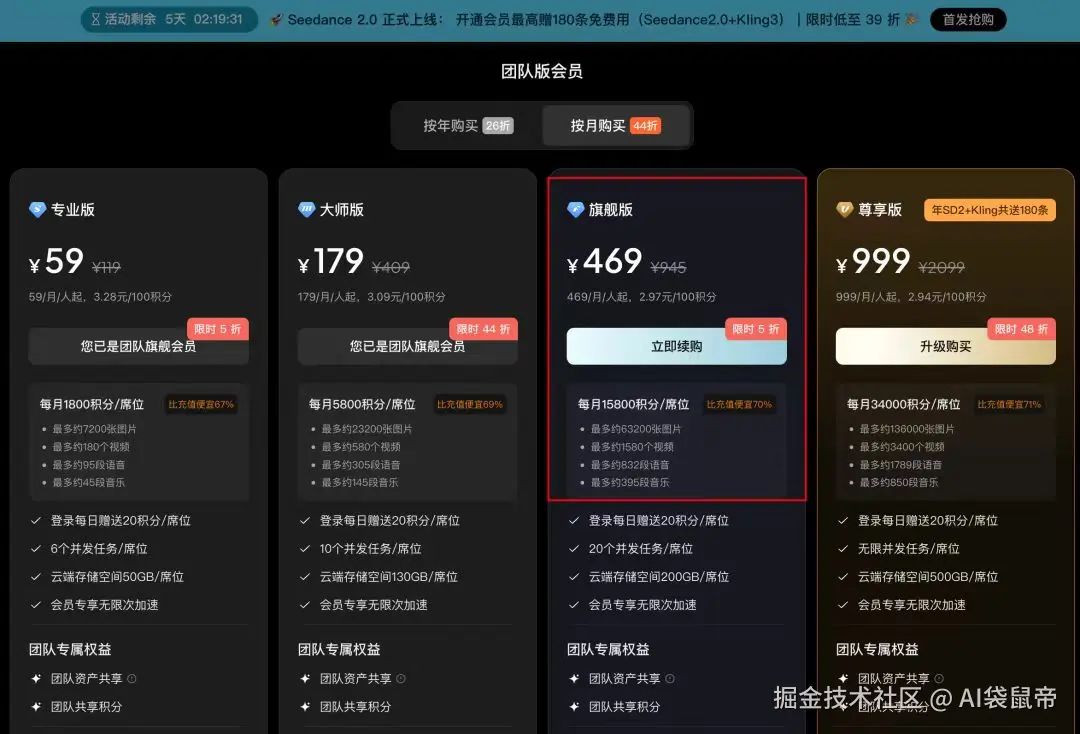 不过最近LibTV正在搞一些福利活动,相对来说非常划算。要知道,Seedance 2.0目前在市面上虽然效果公认最好,但调用成本也是出了名的高。 我看了一下,LibTV现在会员是免费赠送Seedance 2.0和可灵的生成条数,最高可以到240条。 同时,LibTV超值的积分商店也上线了。对于重度视频创作者来说多买多送。
不过最近LibTV正在搞一些福利活动,相对来说非常划算。要知道,Seedance 2.0目前在市面上虽然效果公认最好,但调用成本也是出了名的高。 我看了一下,LibTV现在会员是免费赠送Seedance 2.0和可灵的生成条数,最高可以到240条。 同时,LibTV超值的积分商店也上线了。对于重度视频创作者来说多买多送。
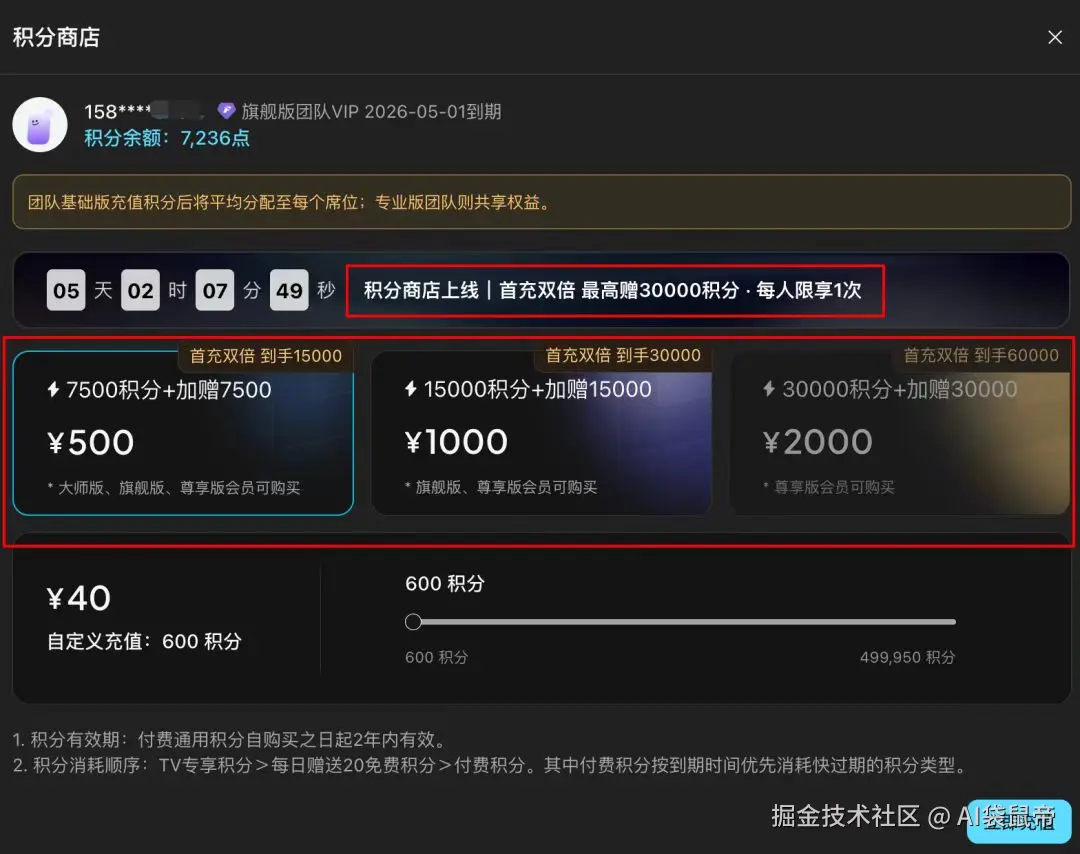 首购积分包,还可以限时获得双倍积分,最高免费送5万积分,这些积分是支持用来跑Seedance2.0的。
首购积分包,还可以限时获得双倍积分,最高免费送5万积分,这些积分是支持用来跑Seedance2.0的。
「最后」
折腾完这一整套流程,我还是忍不住感叹AI发展的速度实在太快了。 虽然这两个月视频大模型能力没有更大突破。但模型配套的工程化工具飞速迭代。 优秀的工程化平台,加上顶级的视频模型,当这个飞轮真正转起来之后,AI内容创作的效率和质量提升,是呈指数级爆发的。 而在这个过程中,人类需要亲手去做的机械性苦力活越来越少。 创意、审美和想象力,在创作中的价值占比变得越来越大。
如果你脑子里有故事,想搞AI漫剧,做高质量的AI短视频,不妨执行起来,去LibTV的无限画布⾥试试。
我是袋鼠帝,一个致力于帮你把AI变成生产力的博主。我们下期见✨