作者 :Blessing Agyei Kyem, Joshua Kofi Asamoah, Anthony Dontoh, Andrews Danyo, Eugene Denteh, Armstrong Aboah*
所属机构 :北达科他州立大学土木、建筑与环境工程系(除Anthony Dontoh来自孟菲斯大学)
通讯作者:Armstrong Aboah
摘要
自动化路面缺陷检测往往难以在多样化的真实世界条件下实现泛化,主要原因在于缺乏标准化的数据集。现有数据集在标注风格、病害类型定义和数据格式上存在差异,限制了它们用于统一模型训练。为弥补这一空白,本文引入了一个综合性基准数据集,该数据集整合了多个公开可用数据源,形成包含来自7个国家的52,747张图像、135,277个边界框标注、涵盖13种不同病害类型的标准化集合。该数据集捕获了图像质量、分辨率、拍摄视角和天气条件方面的广泛真实世界变化,为一致的训练和评估提供了独特资源。我们通过在先进目标检测模型(YOLOv8--YOLOv12、Faster R-CNN和DETR)上进行基准测试,验证了其有效性,这些模型在多样化场景下均取得了具有竞争力的性能。通过标准化类别定义和标注格式,该数据集提供了首个具有全球代表性的路面缺陷检测基准,实现了模型的公平比较,并支持向新环境的零样本迁移。
关键词------路面病害,深度学习,道路监测,基准测试,数据集,检测
一、引言
大数据与道路状况监测的融合为基础设施管理开辟了新途径1,2。尽管取得了这些进展,道路病害检测领域仍面临数据集碎片化的问题,这些数据集在传感器类型、地理区域、标注方案和环境条件方面存在显著差异3--6。这种碎片化限制了深度学习模型的开发与评估,导致模型往往仅在狭窄的特定领域设置中表现优异7,8。
为应对这些挑战,学界引入了Pavementscapes9、UAV-PDD202310和PID11等多个基准数据集,以提高模型的泛化能力并促进标准化评估。然而,这些数据集通常聚焦于特定视角或有限的路况条件,限制了它们在多样化真实场景中的适用性。
在解决数据集碎片化问题的基础上,本研究提出了PaveSync,这是一个大规模、多视角的数据集,通过整合现有路面基准数据源来增强数据多样性。通过融合来自多个国家的航拍、无人机和车载图像,该数据集捕捉了不同的环境条件、路面类型和病害类别。为保持跨不同来源的一致性,我们采用了标准化的标注框架,最终构建了一个包含52,854张标注图像、涵盖13种不同路面状况的数据集。
这种标准化方法为在多样化条件下评估模型性能提供了可靠基础。在此之上,我们使用先进目标检测模型对PaveSync进行评估,分析其在各类路面病害上的表现以验证其有效性。结果突显了不同路面病害类别间的性能差异,为比较不同架构提供了公平依据。该评估进一步证明了数据集的多样性与一致性如何帮助克服早期数据集的局限性。
除基准测试外,PaveSync旨在成为道路状况监测领域研究人员和从业者的实用资源。其公开可用性、预处理标注和详细文档确保了可访问性与可重复性。通过提供高质量、多样化的数据,本工作支持开发更鲁棒的监测解决方案,最终助力道路安全提升、维护成本降低和可持续城市发展。
本文的主要贡献如下:
- 我们引入了PaveSync,这是一个用于路况评估的大规模多视角数据集,通过整合多样化来源以提升模型泛化能力。
- 我们建立了一套标准化标注框架,确保跨数据集的一致性,为深度学习模型的可靠基准测试提供保障。
- 我们在PaveSync上对多种先进目标检测模型进行了基准测试,揭示了模型在不同路面病害类别上的性能差异。
- 我们公开了该数据集及其预处理标注和文档,以支持可重复性与未来研究。数据集可通过以下链接获取:https://drive.google.com/drive/folders/1asUZbdy-3RhSVoJMLlzMOnt643ncWy6Q?usp=sharing
本文其余部分组织如下:第二节回顾路面缺陷检测的相关研究;第三节描述所使用的数据集;第四节讨论用于基准测试PaveSync的各类模型;第五节展示目标检测模型的结果并探讨数据集的潜在应用场景;第六节总结全文。
二、相关研究
在自动化路面病害检测领域,已有大量数据集被开发用于训练和评估深度学习模型。Eisenbach等人提出的GAPs数据集12是首个大规模免费数据集,包含1,969张德国联邦公路的灰度图像,但气候多样性有限。后续数据集通过多视角图像和更广泛的环境条件弥补了这些局限。Majidifard等人引入了PID11,包含7,237张手动标注图像,涵盖7种病害类型;ISTD-PDS7数据集13提供了9种场景下的18,527张图像。然而,两者均缺乏对极端天气条件的覆盖。Liu等人开发了PaveDistress14,提供不同光照条件下的高分辨率图像与细粒度标签,但仅限于单一高速公路系统。UAV-PDD2023数据集10利用无人机捕获了11,150多张图像,涵盖多样化的天气与传感器条件,但基于无人机的方法面临遮挡与形变挑战。针对分割任务,Pavementscapes9提供了4,000张高分辨率图像,涵盖15种路面类型与8,680个标注损伤实例。地理多样化的RDD202215数据集跨越多个国家,而DSPS16则为算法开发竞赛提供了基准数据。
尽管取得了这些进展,显著局限依然存在:数据集通常聚焦于单一传感器类型,缺乏极端环境变化,且标注不一致阻碍了有效的基准测试。PaveSync通过提供多样化、大规模、多视角图像、标准化标注和全面环境条件的数据集,弥补了这些空白,从而增强模型泛化能力,并实现跨深度学习架构的公平基准测试。
三、数据集
A. 数据来源与构成
本研究引入了一个新编译的路面病害图像数据集,该数据集聚合自多个公开可用来源5,9,14--19。数据源自多样化的地理区域,包括伊朗、中国、美国和加纳,如图1所示。
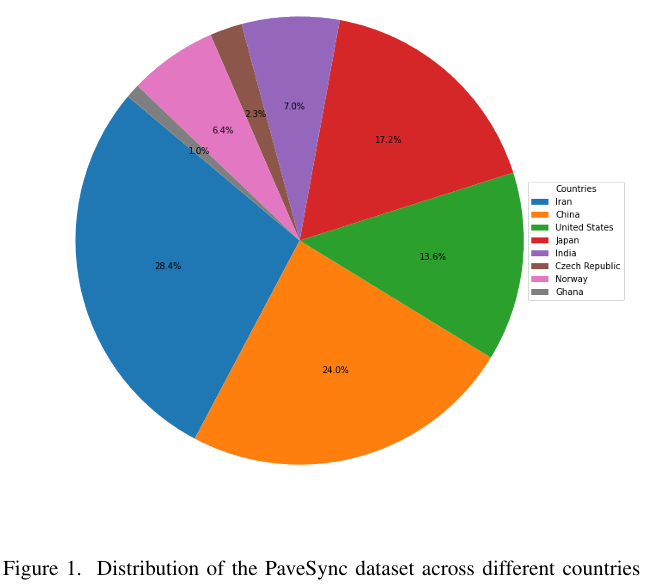
除地理多样性外,PaveSync还整合了多种朝向与视角,确保在不同成像条件下全面覆盖各类路面病害。如图2所示,数据集包含地面级、路面级、空中(无人机)和垂直俯视图,每种视角均为病害检测提供独特优势。这些变化确保数据集不偏向特定成像条件,使其更适应真实世界路面监测场景并具备更强泛化能力。

除多样视角外,数据集还捕获了不同天气与环境条件下的图像。包含白天、雪天和雨天收集的图像,代表了路面病害检测系统必须可靠运行的真实场景,如图3所示。纳入多样化天气条件增强了数据集处理路面监测中真实世界变异的能力。

B. 数据标准化
本研究使用的数据集具有不同的标注格式,如Pascal VOC(XML)、COCO(JSON)和YOLO(TXT),每种格式在表示边界框和对象元数据方面结构各异。虽然某些格式提供详细标注(包括分割掩码和层级标签),但其他格式侧重于面向实时应用的最小化高效表示。
为创建统一数据集,我们对标注格式、病害类别名称和类别ID进行了标准化,以确保跨不同来源的一致性与兼容性。我们没有将数据集限制为单一标注风格,而是保留了多种格式(XML、JSON和TXT),使研究人员能够使用其偏好的结构。该方法在保持跨格式标准化类别映射的同时确保了灵活性。
此外,不同数据集间的病害类别名称存在差异,导致标注不一致。例如,某数据集中的"Alligator"在另一数据集中显示为"Alligator Cracking"。为解决此问题,我们分配了标准化病害名称,移除重复项,并消除模糊标签与不需要的病害类型。另一挑战是类别ID分配不一致,不同数据集对同一病害类型使用不同ID。我们对这些标识符进行了标准化,确保每种病害类型在最终数据集中拥有唯一且一致的类别ID。此外,我们移除了样本数量不足的病害类别,以缓解数据集不平衡并提高训练稳定性。
在合并与标准化所有数据集后,最终病害类别如表I所示,确保了结构化且一致的数据集,同时保持对各类研究应用和标注偏好的适应性。
表I 数据集在国家与病害类型上的分布(训练集与验证集划分)
| 国家 | 训练集 | 验证集 | 总计 |
|---|---|---|---|
| 伊朗 | 13,485 | 1,498 | 14,983 |
| 中国 | 11,394 | 1,266 | 12,660 |
| 美国 | 6,457 | 717 | 7,174 |
| 日本 | 8,164 | 907 | 9,071 |
| 印度 | 3,323 | 369 | 3,692 |
| 捷克 | 1,092 | 121 | 1,213 |
| 挪威 | 3,038 | 338 | 3,376 |
| 加纳 | 520 | 58 | 578 |
| 类别ID | 病害类型 | 训练集 | 验证集 | 总计 |
|---|---|---|---|---|
| 0 | 泛油 (Bleeding) | 1,690 | 195 | 1,885 |
| 1 | 隆起与沉陷 (Bumps and Sags) | 784 | 73 | 857 |
| 2 | 井盖 (Manhole) | 721 | 75 | 796 |
| 3 | 修补 (Patching) | 4,629 | 492 | 5,121 |
| 4 | 坑槽 (Pothole) | 25,874 | 2,764 | 28,638 |
| 5 | 车辙 (Rutting) | 15,456 | 1,943 | 17,399 |
| 6 | 推移 (Shoving) | 1,394 | 162 | 1,556 |
| 7 | 龟裂 (Alligator Cracking) | 18,635 | 2,042 | 20,677 |
| 8 | 纵向裂缝 (Longitudinal Cracking) | 29,969 | 3,384 | 33,353 |
| 9 | 横向裂缝 (Transverse Cracking) | 17,520 | 1,931 | 19,451 |
| 10 | 块状裂缝 (Block Cracking) | 402 | 44 | 446 |
| 11 | 修复痕迹 (Repair) | 2,995 | 705 | 3,700 |
| 12 | 边缘裂缝 (Edge Cracking) | 1,523 | 191 | 1,714 |
| 总计图像 | 47,473 | 5,274 | 52,747 | |
| 边界框总数 | -- | -- | 135,277 |
C. 标注验证
由于标准化图像数量庞大,对所有标注进行全面人工审查不切实际。为保持准确性与一致性,我们实施了基于分层抽样的验证策略。该方法涉及选择代表性图像子集,确保覆盖各类病害类型、环境条件和地理位置。验证过程包括将标准化标注与原始标注叠加到对应图像上,以评估其对齐程度。识别出的任何差异均被修正并重新评估,该过程迭代进行,直至所有标注准确反映实际路面状况。这一结构化方法确保了整合至基准中的所有数据集具备高质量的真值标注。
D. 最终数据集构成
最终合并数据集包含52,747张路面图像,涵盖13个病害类别(见表I),总计135,277个边界框标注。数据集按90%训练集和10%验证集进行划分,确保每个病害类别在两个集合中保持相同分布。这种分层划分防止了训练与评估期间的类别不平衡。为增强泛化能力,我们确保了来自不同地理区域的图像混合均衡。
四、方法
本节描述用于预处理、基准测试和评估PaveSync的方法论。该过程包括数据预处理、训练与评估设置、评估指标以及多架构基准测试。
A. 数据预处理与增强
为确保一致性并提升模型性能,我们对PaveSync数据集应用了多项预处理步骤。所有图像均调整为标准尺寸640×640640 \times 640640×640像素,同时保持宽高比以确保与不同深度学习模型兼容。此外,实施了多种数据增强技术,包括随机裁剪、旋转、翻转、亮度调整和高斯噪声,以提升模型在多样化真实世界条件下的泛化能力。最后,由于某些病害类型出现频率更高,我们在训练期间应用了加权采样以解决类别不平衡问题,确保模型有效学习。具体预处理与增强技术见表II。
表II PaveSync预处理与增强设置
| 技术 | 参数值 |
|---|---|
| 随机裁剪 | 0.8 |
| 旋转角度 | 15° |
| 水平翻转 | 0.5 |
| 亮度调整 | 1.1 |
| 对比度调整 | 1.2 |
| 高斯噪声标准差 | 0.01 |
| 归一化(像素缩放) | 0,10, 10,1 |
B. 实验设置
数据集被划分为两个子集以确保稳健的模型训练与评估:90%用于训练,10%用于验证。该划分确保充足的训练数据,同时保留独立测试集用于最终评估。所有实验均在配备24GB显存的NVIDIA A100 GPU上进行,使用PyTorch 2.0作为深度学习框架。模型训练1000个epoch,批次大小为16,使用Adam优化器,初始学习率为0.0010.0010.001,并采用余弦退火调度进行衰减。
C. 用于基准测试的深度学习模型
为全面评估PaveSync数据集,我们使用7种先进模型进行基准测试,每种模型均旨在平衡准确性、计算效率和实际适用性。这些模型已广泛应用于路面病害检测、路面分析和通用目标检测任务。
-
YOLO系列:YOLO系列检测器(v8--v12)20--23因其在实时目标检测中速度与准确性的平衡而被选为基准。它们均采用适用于密集路面图像的无锚框架构,但各自引入了针对路面病害检测的针对性改进。YOLOv820作为基线,集成了无锚框检测头、动态标签分配和带解耦头的CSPDarkNet骨干网络,提供强大的基线准确性与效率。YOLOv924通过可编程梯度反向传播和GELAN改进特征提取,增强细粒度裂缝检测。YOLOv1025通过无NMS设计和双重分配消除冗余后处理,提升实时道路监测系统的一致性与效率。YOLOv1122通过C3k2块、SPPF和空间注意力模块强化多尺度特征聚合,提升对不同尺度缺陷(如坑槽与块状裂缝)的鲁棒性。YOLOv1223引入以注意力为中心的模块、可分离卷积和FlashAttention,改善在多国家路面数据集中常见的多样化图像质量与条件下的泛化能力。这些渐进式改进直接应对了缺陷在尺度、纹理和捕获环境中的变异挑战。
-
Faster R-CNN:Faster R-CNN26是一种两阶段目标检测模型,以其高检测精度著称,尤其适用于小型或密集对象27。它由区域提议网络(RPN)及分类与回归网络组成,使其能够迭代细化边界框预测。该模型使用ResNet-50作为特征提取器,使其在检测微裂缝和纹理不一致等细粒度路面缺陷方面非常有效。
-
DETR(Detection Transformer):DETR28采用自注意力机制进行目标检测。该架构消除了对非极大值抑制(NMS)的需求,并支持直接集合预测,使其在复杂路面纹理和重叠路面缺陷检测中表现优异。
D. 评估指标
为确保深度学习模型在路面病害检测中公平且标准化的比较,我们采用一组广泛使用的评估指标。
-
精确率(Precision, PPP) :精确率衡量在所有检测到的实例中正确预测的路面病害实例的比例。定义为:
P=TPTP+FPP = \frac{TP}{TP + FP}P=TP+FPTP (1)其中TPTPTP(真阳性)表示正确识别的病害实例,FPFPFP(假阳性)表示错误检测的实例。较高的精确率意味着误报更少,这对于需要高检测可靠性的应用至关重要。
-
召回率(Recall, RRR) :召回率评估模型检测数据集中实际路面病害实例的能力。计算方式为:
R=TPTP+FNR = \frac{TP}{TP + FN}R=TP+FNTP (2)其中FNFNFN(假阴性)表示漏检的病害实例。高召回率确保大多数路面缺陷被正确识别,这对基础设施评估应用至关重要。
-
F1分数(F1-Score) :F1分数在精确率和召回率之间取得平衡,确保假阳性与假阴性均不主导评估。计算方式为:
F1=2×P×RP+RF1 = 2 \times \frac{P \times R}{P + R}F1=2×P+RP×R (3)高F1分数表明模型在正确检测缺陷和最小化错误检测方面均表现良好。
-
平均精度均值(Mean Average Precision, mAP):mAP通过在多个交并比(IoU)阈值下平均精确率值来评估目标检测准确性。
- mAP@50mAP@50mAP@50:在固定IoU阈值为50%时的平均精度。
- mAP@50--95mAP@50--95mAP@50--95:在IoU阈值从50%到95%以5%为增量计算的平均精度,确保更严格的评估。
定义为:
mAP=1N∑i=1NAPimAP = \frac{1}{N} \sum_{i=1}^{N} AP_imAP=N1∑i=1NAPi (4)
其中NNN为IoU阈值数量,APiAP_iAPi为每个阈值下的平均精度。较高的mAP值表示模型性能更优。
五、结果与应用场景
A. 结果
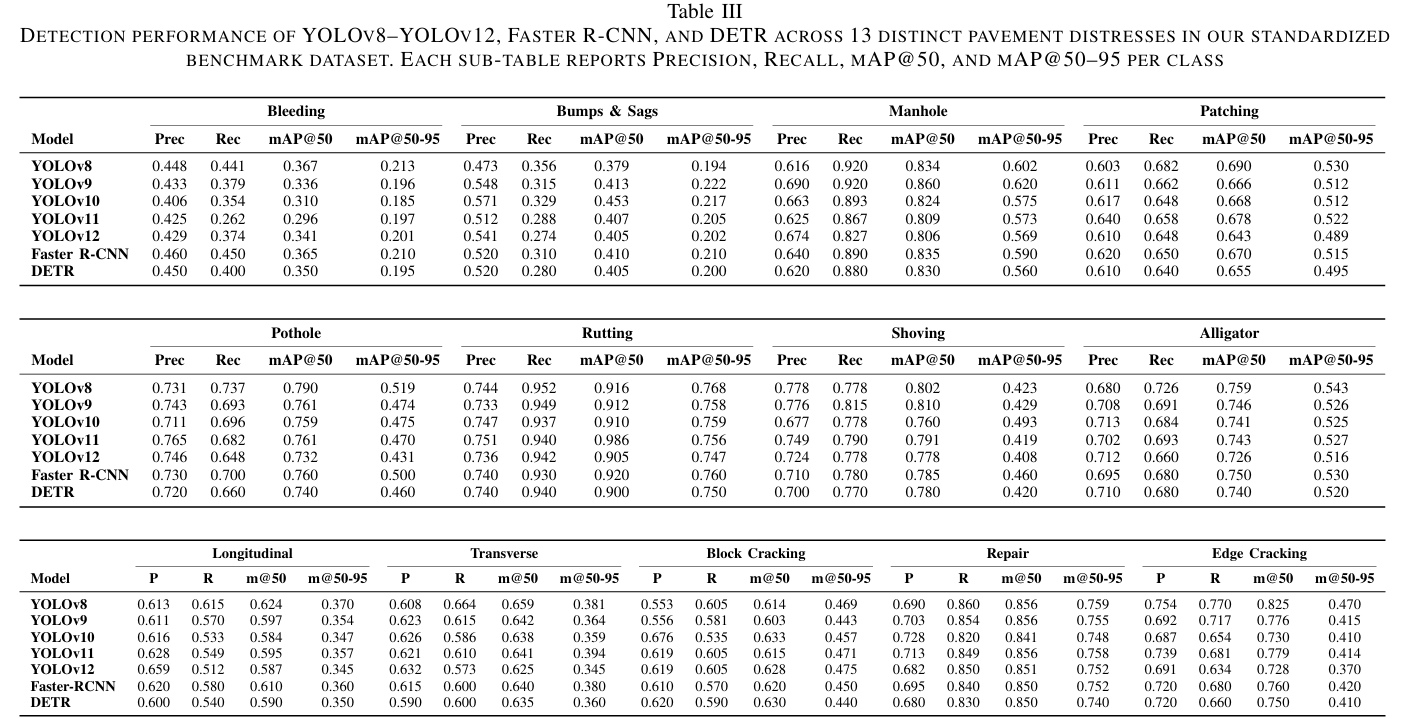
表III的结果显示,每个YOLO变体在特定病害类别上表现优异,而在其他类别上表现一致性稍弱。YOLOv8在车辙和推移方面表现强劲,表明其特征提取针对大型易识别形变进行了良好调优。YOLOv9在井盖和车辙上召回率更高,表明其在异常不明显时仍具备强大的捕捉能力。YOLOv10在大多数类别间平衡了精确率与召回率,表明其架构改进提升了检测一致性。YOLOv11在龟裂等复杂类别中实现了特别高的精确率,这可能归功于其对局部精细特征的关注。YOLOv12在许多缺陷上保持稳健的整体性能,但在不规则类别上召回率较低,暗示其在学习细微模式时存在困难。
除YOLO系列外,Faster R-CNN和DETR在井盖和车辙检测中展现出竞争性结果,反映了这些模型对上下文建模的能力。Faster R-CNN基于区域的方法在各种缺陷间提供均衡性能,而DETR的注意力驱动架构在具有明显形状特征的类别上实现高召回率,但在隆起与沉陷等细微问题上精确率略低。这些发现强调了各模型设计如何影响其对不同路面病害类型的敏感度与特异性,为未来工作优化更精准检测提供了方向。
B. 数据集的应用场景
该数据集在研究与实际运营环境中均发挥关键作用,推动路面监测、基础设施维护和智能交通系统的发展。首先,其庞大且多样化的图像库促进了深度学习模型的训练、验证与基准测试,帮助研究人员和从业者在多样化病害类型与环境条件下提升准确性。同时,交通管理部门可将这些模型集成至实时监测流水线中,以检测坑槽或严重裂缝等关键缺陷,并在恶化前优先安排维修。由于数据集涵盖多个地理位置和不同天气条件下的图像,它支持域适应与迁移学习研究。这使其在将目标检测系统扩展至新区域或传感器模态时极具价值。此外,城市规划者和维护承包商可利用标准化格式与全面标注开发预测性维护计划,简化资源分配并优化长期基础设施投资。在教育环境中,该数据集为实践项目提供了严格的测试平台,使学生能够学习先进目标检测技术并获得道路资产管理的实际洞察。
六、结论
总之,PaveSync将来自多视角、多气候和多传感器类型的路面图像整合为单一标准化资源,解决了现有数据集碎片化的问题。通过统一标注格式与类别定义,该数据集实现了在多样化真实世界条件下的公平一致基准测试。与不同架构的基线比较凸显了PaveSync揭示各模型优势与短板的能力,证明了其作为全面评估工具的价值。凭借全球覆盖与一致标注,该数据集为自动化路况评估的新研究奠定了基础,支持开发融合深度学习算法与多样化数据输入的底层模型,以提升预测准确性与运营效率。以此方式,PaveSync不仅连接了分散的数据源,还启发了未来更智能、更可靠的道路维护新策略。
七、致谢
本研究得到北达科他经济多元化研究基金(EDRF)的支持。作者对资助方提供的资金与支持表示感谢,这些支持使本工作得以顺利完成。
参考文献
1 Q. Shi and M. Abdel-Aty, "Big data applications in real-time traffic operation and safety monitoring and improvement on urban expressways," Transp. Res. Part C Emerg. Technol., vol. 58, pp. 380--394, Sep. 2015.
2 N. J. Owor, Y. Adu-Gyamfi, and M. Amo-Boateng, "Image2PCI: Vision transformer with multi-task learning for automated pavement condition index estimation," IEEE Access, vol. 11, pp. 121 894--121909, 2023.
3 K. P. Ayodele, W. O. Ikezogwo, M. A. Komolafe, and P. Ogunbona, "Supervised domain generalization for integration of disparate scalp EEG datasets for automatic epileptic seizure detection," Comput. Biol. Med., vol. 120, p. 103757, Mar. 2020.
4 Y. Ganin et al., "Domain-adversarial training of neural networks," J. Mach. Learn. Res., vol. 17, no. 59, pp. 1--35, 2016.
5 B. A. Kyem et al., "Pavecap: The first multimodal framework for comprehensive pavement condition assessment with dense captioning and PCI estimation," arXiv preprint arXiv:2408.04110, 2024.
6 B. A. Kyem, J. K. Asamoah, Y. Huang, and A. Aboah, "Weather-adaptive synthetic data generation for enhanced power line inspection using StarGAN," IEEE Access, vol. 12, pp. 193882--193901, 2024, doi: 10.1109/ACCESS.2024.3520120.
7 B. A. Kyem, J. K. Asamoah, and A. Aboah, "Context-CrackNet: A context-aware framework for precise segmentation of tiny cracks in pavement images," Construction and Building Materials, vol. 484, p. 141583, 2025, doi: 10.1016/j.conbuildmat.2025.141583.
8 B. Agyei Kyem et al., "Self-supervised multi-scale transformer with Attention-Guided Fusion for efficient crack detection," Autom. Constr., vol. 181, p. 106591, 2026.
9 Z. Tong, T. Ma, J. Huyan, and W. Zhang, "Pavementscapes: A large-scale hierarchical image dataset for asphalt pavement damage segmentation," arXiv preprint arXiv:2208.00775, 2022.
10 K. Yan et al., "UAV-PDD2023: A high-resolution UAV pavement distress detection dataset," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, 2023, pp. 1--9.
11 H. Majidifard, M. J. Buttlar, and H. Alavi, "Pavement image dataset (PID): A new benchmark dataset for pavement distress detection," Data Brief, vol. 31, p. 105961, Aug. 2020.
12 M. Eisenbach et al., "How to get pavement distress detection ready for deep learning? A systematic approach," in Proc. Int. Joint Conf. Neural Netw.(IJCNN), 2017, pp. 2039--2047.
13 Y. Song et al., "ISTD-PDS7: An image dataset for pavement distress segmentation in seven scenarios," Data Brief, vol. 48, p. 109 032, Jun. 2023.
14 Z. Liu et al., "PaveDistress: A high-resolution pavement distress dataset with fine-grained annotations," Road Mater. Pavement Des., pp. 1--19, 2024.
15 D. Arya, H. Maeda, S. K. Ghosh, D. Toshniwal, and Y. Sekimoto, "RDD2022: A multi-national image dataset for automatic road damage detection," arXiv preprint arXiv:2209.08538, 2022.
16 Y. Adu-Gyamfi, B. Buttlar, E. Dave, D. Mensching, and H. Majidifard, "DSPS: Data science for pavements challenge," Online. Available: https://dsps-1e998.web.app/data, accessed Feb. 9, 2025.
17 J. Zhu et al., "Pavement distress detection using convolutional neural networks with images captured via UAV," Autom. Constr., vol. 133, p. 103991, Mar. 2022.
18 N. J. Owor, Y. Adu-Gyamfi, A. Aboah, and M. Amo-Boateng, "PaveSAM---Segment anything for pavement distress," Road Mater. Pavement Des., pp. 1--25, 2024.
19 B. A. Kyem et al., "Advancing pavement distress detection in developing countries: A novel deep learning approach with locally-collected datasets," arXiv preprint arXiv:2408.05649, 2024.
20 A. Aboah and N. J. Owor, "Real-time pavement distress detection using deep learning," in Proc. IEEE Int. Conf. Big Data, 2023, pp. 1--7.
21 Danyo, A., Dontoh, A.,& Aboah, A.(2025). An improved ResNet50 model for predicting pavement condition index(PCI) directly from pavement images. Road Materials and Pavement Design, 1--18.
22 Ultralytics, "YOLOv11,"Online. Available: https://github.com/ultralytics/ultralytics, accessed Feb. 9, 2025.
23 S. Tian et al., "YOLOv12: Attention-centric real-time object detector," arXiv preprint arXiv:2501.01563, 2025.
24 C. Y. Wang et al., "YOLOv9: Learning what you want to learn using programmable gradient information," arXiv preprint arXiv:2402.13616, 2024.
25 C. Y. Wang et al., "YOLOv10: Real-time end-to-end object detection," arXiv preprint arXiv:2405.14458, 2024.
26 S. Ren, K. He, R. Girshick, and J. Sun, "Faster R-CNN: Towards real-time object detection with region proposal networks," IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137--1149, Jun. 2017.
27 A. Dontoh et al., "Visual dominance and emerging multimodal approaches in distracted driving detection: A review of machine learning techniques," arXiv preprint arXiv:2505.01973, 2025.
28 N. Carion et al., "End-to-end object detection with transformers," in Proc. Eur. Conf. Comput. Vis.(ECCV), 2020, pp. 213--229.