- 开放标准
- 一次构建,多处部署
- 渐进式披露:技能的名称和描述始终存在于智能体的上下文窗口中,但只有当用户请求与技能描述匹配时,才会加载其余指令。
其中,我觉得最重要的特点是渐进式披露,AI的调用一个需要关注的点就是Token的消耗,而渐进式披露相比一次性加载的方式可以帮助用户一定程度上节约Token的消耗。
何时使用Skills
当你有一个反复 要求智能体实现的工作流 时,与其每次都解释相同的工作流,不如将其打包成一个技能,让智能体自动 知道该做什么。
重点在于重复性、自动化、工作流
针对大模型的不可预测性,通过Skill规范了输入与输出、执行步骤和执行脚本,保证的同一类的输入,大模型可以给出同一类的输出。
Skill的目录结构
skill名/ ├── SKILL.md # skill的"大脑" ├── references/ # skill的"知识库" │ └── style-guide.md ├── scripts/ # skill的"手脚" │ └── analyze_excel.py └── assets/ # skill的"装备" └── header.png
各部分的核心作用
SKILL.md - 指挥中心
- 这是技能的主配置文件,定义了技能的功能、工作流程和执行规范
- 告诉我技能的适用场景、触发条件和执行步骤
- 是加载技能时首先读取的核心文档
references/ - 知识沉淀
- 存放参考文档、模板、规范说明等静态资源
- 比如 style-guide.md 可能包含格式规范、写作标准等
- 这些是技能执行过程中需要查阅的"说明书"
scripts/ - 执行工具
- 包含可执行的脚本代码(Python、Bash等)
- 比如 analyze_excel.py 就是具体的数据分析实现逻辑
- 当 SKILL.md 中引用某个脚本时,会在这里找到并执行
assets/ - 资源支持
存放图片、样式文件等辅助资源
header.png 可能是生成报告时使用的标题图片
为技能的视觉输出提供素材支持
设计哲学
这种结构体现了模块化和职责分离的思想:
- 配置与代码分离
- 知识与执行分离
- 逻辑与资源分离
Excel Skills 的实践分析
本文选用Coze平台作为Skills实践平台。Coze中会有技能商店,里面的技能属于黑盒。接下来我们自己创建属于自己的Skills。Coze平台提供给我们的是帮助我们编写Skills的Skill。

如图中这句话,在skill的界面输入,Coze就会自己自动生成skill的目录结构、主目录的Markdown文档、可执行脚本和领域专业知识的Markdown文档。
目录结构:
excel-data-analyzer/ ├── SKILL.md # 入口文档与操作指南 ├── scripts/ │ └── analyze_excel.py # Excel分析主脚本 └── references/ └── excel-data-guide.md # 数据分析方法论参考
SKILL.md文件内容如下:
点击查看代码
Excel 数据分析器 ├── 前言区 (YAML) │ ├── name: Skill名称 │ ├── description: Skill功能描述 │ └── dependency:脚本执行依赖 │ ├── 任务目标 │ ├── 作用介绍 │ ├── 能力包含 │ └── 触发条件 │ ├── 前置准备 │ └── 依赖说明 │ ├── 操作步骤 │ ├── 标准流程 │ │ ├── 1. 获取Excel文件路径 │ │ ├── 2. 调用分析脚本 │ │ ├── 3. 解读分析结果 │ │ └── 4. 生成洞察报告 │ └── 可选分支 │ ├── 特定列分析场景 │ ├── 数据质量问题场景 │ └── 深度探索场景 │ ├── 资源索引 │ ├── 必要脚本 (scripts/analyze_excel.py) │ └── 领域参考 (references/excel-data-guide.md) │ ├── 注意事项 │ └── 使用示例 ├── 示例1: 基础数据分析 ├── 示例2: 数据质量检查 └── 示例3: 业务洞察生成
该文档结构符合 Skill 规范,包含完整的前言区、正文指导和资源索引,便于智能体快速理解和使用。
Skill实践优化
- 在SKILL.md的前言区中指定输入(inputs)和输出(outputs)的格式规范,比如输入是excel文件,输出的是excel文件等。
- 明确 Skill 的输入输出标准,示例文件放在 references 目录
- 所有脚本应有异常处理与错误报告能力,便于 Agent 自动修复
- 复杂逻辑建议分模块实现,主流程在 SKILL.md 中清晰描述
- Excel 公式相关操作建议分离脚本处理,避免直接在 openpyxl 中计算
- 尽量输出中间结果与最终数据,便于人工或 Agent 二次校验
附录
Coze平台自建Skill流程
-
在Coze平台的技能下输入你想构建Skill的功能(该页面就是封装了编写Skill的Skill,降低使用门槛)
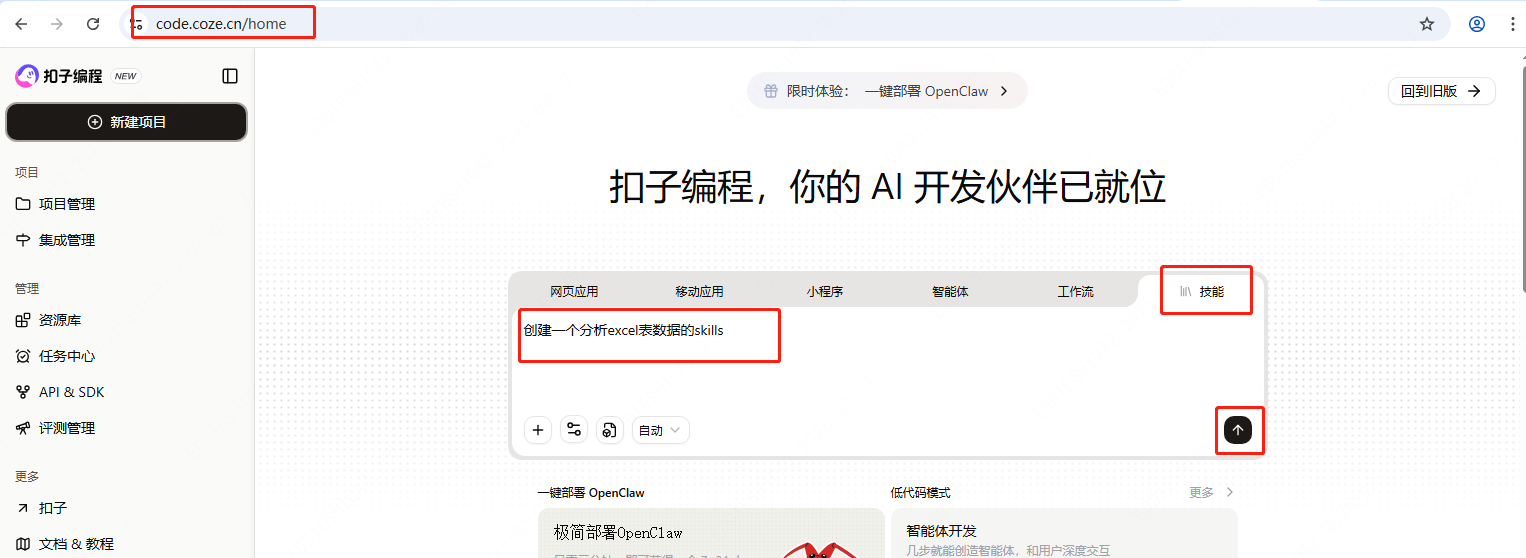
-
等待自动生成目录结构和文档,点击切换到目录结构(生成了满足Skill规范的结构与文档)
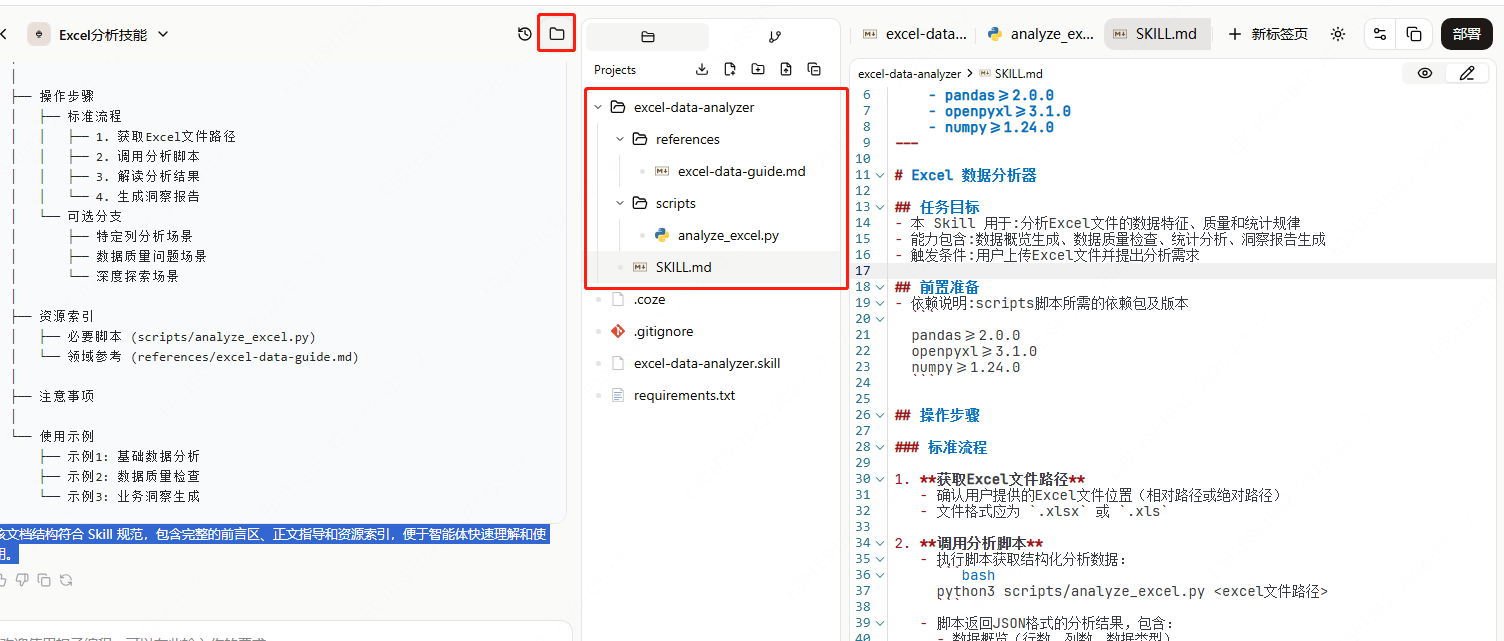
-
根据自己的需求直接修改文档,或者跟AI进行交互,进一步描述自己的述求,让AI进行修改
-
测试该Skill是否满足预期,根据测试结果,返回第三步进行修改
-
点击页面右上角的部署按钮,即可打包部署成功,就可以在自己的技能商店中看到自己创建的Skill了
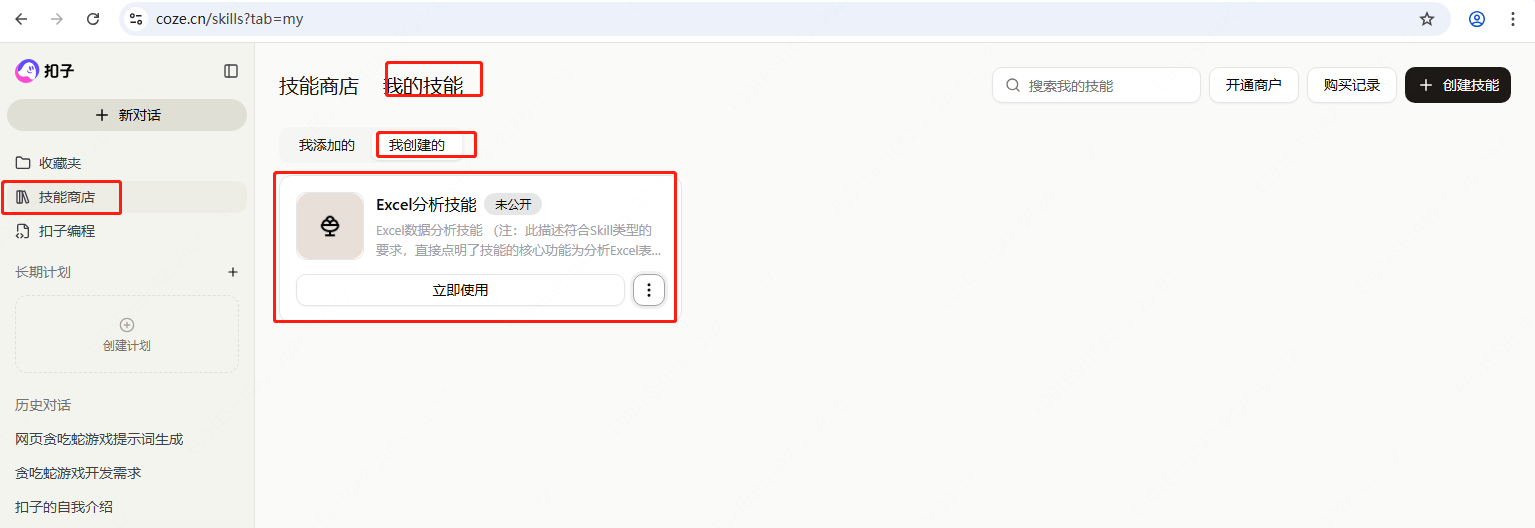
-
Skill的使用,后续直接上传文件进行分析时,会自动调用,当然也可以显示指定该Skill进行分析


