最近一段时间,围绕 Agent 架构的讨论非常多。一边是 Anthropic / Claude Code 这类偏多智能体协作的路线,比如 Claude Agent Teams、parallel Claudes、多 Agent research system;另一边是 Cognition / Devin 这类更强调单线程、统一上下文的路线,尤其反复提醒大家:不要盲目做 Multi-Agent,更不要让多个 Agent 一起写代码。
乍一看,这两种观点好像是冲突的:
text
Anthropic:多个 Agent 可以并行协作,处理更复杂的任务。
Cognition / Devin:强耦合任务不要乱拆,尤其代码写入最好保持单线程。但从工程角度看,它们其实并不矛盾。更准确的理解应该是:
text
多 Agent 不是银弹。
一个任务是否适合拆成多个 Agent,关键取决于任务耦合度、上下文边界、信息流方式和验证机制。也就是说,多 Agent 不是"越多越强",而是一种典型的工程权衡:用更多 Token、更多通信成本、更多系统复杂度,去换更高的信息覆盖度、更强的并行能力和更明确的职责隔离。
一、两条路线:Anthropic 重协作,Cognition / Devin 重上下文
Anthropic 这条路线更关注"多个 Agent 如何分工协作"。
比如复杂研究、资料检索、文档分析、竞品调研、代码审查这类任务,本身就可以拆成多个方向。一个 Agent 查官方文档,一个 Agent 查论文,一个 Agent 查竞品,一个 Agent 查 GitHub,最后再由主 Agent 汇总。
这种方式很适合弱耦合任务。它的优势很明显:
text
可以并行;
信息覆盖面更广;
不同 Agent 可以承担不同角色;
不同上下文之间可以隔离,避免主上下文被噪音污染。但代价也同样明显:
text
通信成本更高;
上下文容易碎片化;
不同 Agent 可能做出互相冲突的隐含决策;
最终合并结果时,需要额外处理冲突和不一致。Cognition / Devin 的观点则更克制。它们强调:强耦合任务不要轻易拆成多个 Agent。尤其是写代码这种任务,更适合让一个主 Agent 保持完整上下文,连续理解任务、连续做决策、连续修改代码、连续验证结果。
原因也很简单:写代码不是简单把文本拼起来。代码里包含大量隐含决策:
text
接口怎么设计?
状态怎么流转?
错误怎么处理?
边界条件怎么兜底?
代码风格怎么统一?
旧逻辑是否保留?
测试覆盖到什么程度?如果多个 Agent 同时写代码,就很容易出现问题:
text
A 改了接口,B 还按旧接口写;
A 用一种错误处理方式,B 用另一种;
A 改了状态结构,B 的测试还基于旧状态;
A 认为某个边界应该兜底,B 认为应该直接抛异常。这就是所谓的"隐含决策冲突"。
所以 Cognition / Devin 并不是说 Multi-Agent 没用,而是在强调一个边界:
text
多 Agent 可以一起想、一起看、一起查、一起审、一起测;
但最终写代码和合并决策,最好收束到一个主 Agent。这和 Android 里的主线程模型有点像。多线程可以并行计算、预取、分析,但 UI 状态更新最终要回到主线程。在 Agent 系统里也是一样:多 Agent 可以并行做分析、审查、检索、验证,但最终写入代码和合并决策应该回到主 Agent。
一句话概括就是:
text
写入单线程,其他 Agent 只共享 intelligence。
二、多 Agent 为什么容易失败:问题通常不在"数量",而在"上下文"
很多人一想到多 Agent,就会本能地模仿人类公司的组织结构:
text
产品 Agent
开发 Agent
测试 Agent
架构 Agent
运维 Agent这看起来很合理,但对 Agent 来说,往往不是最优解。
因为 Agent 之间不像人类团队那样有长期协作形成的默契。人类可以通过经验、会议、上下文记忆、团队文化来补足很多信息,但 Agent 之间主要靠 prompt 和上下文传递。
如果按岗位拆,很容易变成"传话游戏"。
比如一个功能被拆成:
text
PM Agent -> Dev Agent -> QA Agent看起来流程很清楚,但实际问题很多:
text
Dev Agent 不知道 PM 为什么这么设计;
QA Agent 不知道 Dev 做过哪些技术取舍;
Review Agent 不知道哪些方案已经被否掉;
每一步交接都要重新解释背景。最后可能真正做任务没花多少 Token,解释背景、同步状态、传递上下文反而花了更多 Token。也就是:
text
通信 Token > 任务 Token所以,多 Agent 的拆分方式不应该是"按人类岗位拆",而应该是"按上下文边界拆"。
错误拆法是:
text
产品 Agent
开发 Agent
测试 Agent更合理的拆法是:
text
LoginFeatureAgent:负责登录功能完整闭环;
PaywallFeatureAgent:负责订阅页完整闭环;
WalletFeatureAgent:负责资产页完整闭环;
NotificationFeatureAgent:负责通知功能完整闭环。每个 Agent 负责一个相对完整的业务上下文:理解需求、设计方案、实现功能、补充测试、修复问题、交付结果。它不是只负责"开发"或者"测试",而是负责一个可独立理解、可独立推进、可独立验证的小闭环。
这和软件架构里的模块拆分很像。不要按技术层过度拆:
text
UI Agent
ViewModel Agent
Repository Agent
Network Agent
Test Agent如果它们都围绕同一个业务功能工作,就会频繁同步字段、状态、错误态、缓存策略、接口失败逻辑等细节。更合理的是按业务上下文拆:
text
LoginFeatureAgent
PaymentFeatureAgent
OrderFeatureAgent
ProfileFeatureAgent这更像领域驱动设计里的 Bounded Context,也更像 Android 工程里的 feature module。
判断一个任务适不适合拆,其实可以用一句话:
text
凡是需要频繁解释背景的,就不该拆。
只有当上下文可以真正隔离时,拆分才有效。可以再用一个"红绿灯法则"辅助判断。
红灯:不要拆。
第一,同一工作的连续阶段不要拆。比如"规划 -> 实现 -> 测试",如果它们是同一个功能的连续阶段,就高度依赖同一套上下文。强行拆成规划 Agent、实现 Agent、测试 Agent,往往会导致上下文切断。更好的方式是让一个 Agent 从规划做到测试。
第二,紧密耦合的组件不要拆。比如一个 Android 业务功能里的 ViewModel、Repository、StateFlow、Compose UI、缓存策略、错误处理,它们高度相关。如果拆给多个 Agent,很容易出现状态字段不一致、接口定义不一致、生命周期理解不一致等问题。
第三,需要持续共享状态的任务不要拆。如果多个 Agent 必须不断知道"当前系统理解到哪一步、最新方案是什么、哪些约束发生变化、当前 bug 根因是什么",那说明这些任务之间耦合度很高,拆开反而增加成本。
绿灯:可以拆。
第一,独立研究路径可以拆。比如一个 Agent 研究亚洲市场,一个 Agent 研究欧洲市场,一个 Agent 研究美国市场,最后汇总即可。
第二,有清晰接口的组件可以拆。比如认证模块只暴露 login/logout/session 接口,支付模块只依赖 userId 和 orderId,通知模块只消费事件。只要接口定义明确,内部实现就可以独立推进。
第三,黑盒验证任务很适合拆。比如跑测试、检查性能、做安全扫描、汇总 lint 结果、检查文档格式、检查接口响应格式。这类任务不需要理解完整设计过程,只需要输入、输出和标准。
所以,如果要从多 Agent 开始尝试,最安全的拆分点通常不是"开发 Agent",而是"验证 Agent"。

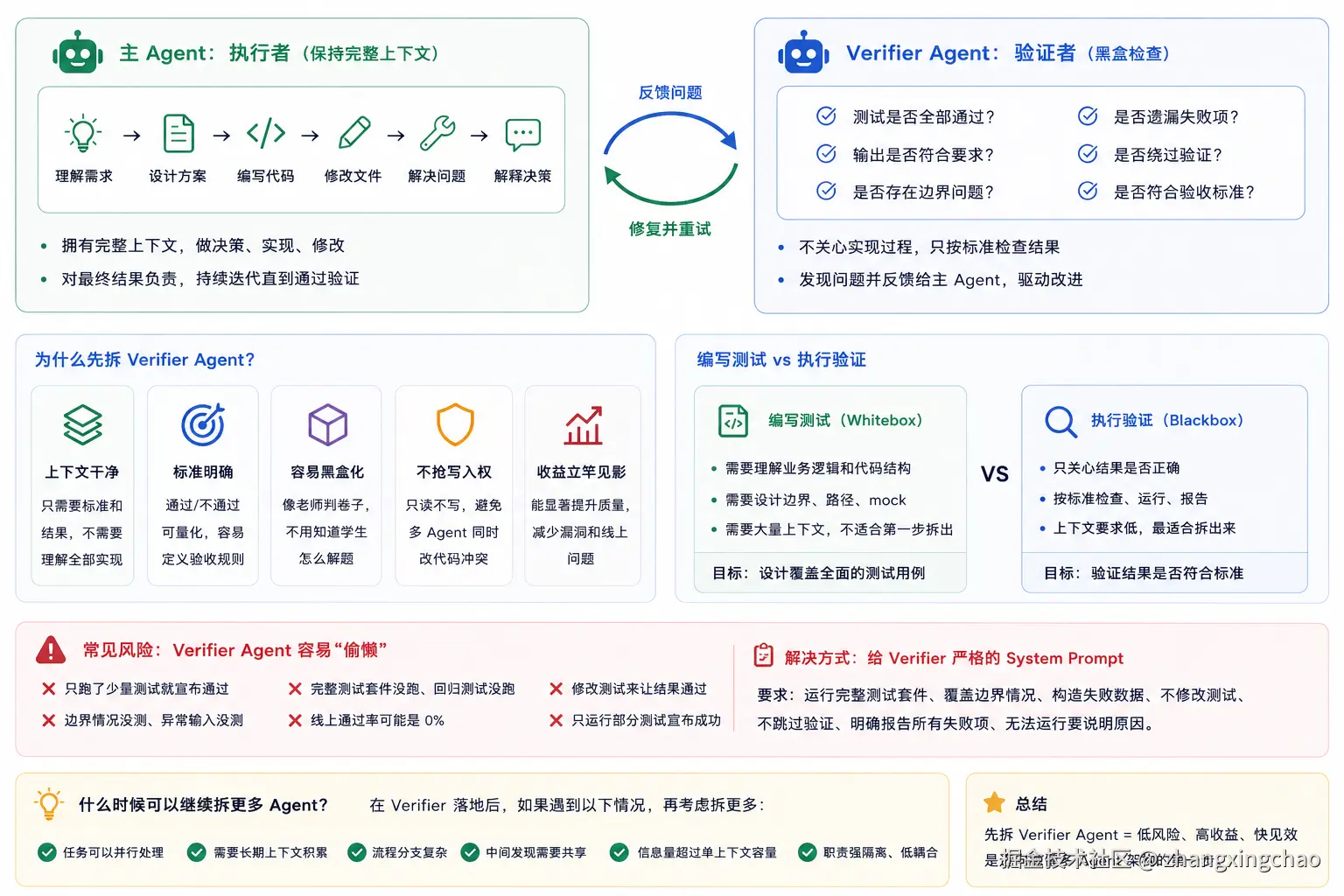
三、最稳的第一步:先拆 Verifier Agent
在多 Agent 系统里,最稳的第一步通常是把验证环节拆出来。
结构很简单:
text
主 Agent:执行
验证 Agent:检查主 Agent 负责完整上下文:理解需求、设计方案、写代码、修改文件、解决问题,并解释为什么这么做。
验证 Agent 不需要理解完整过程,它只需要按标准检查:
text
测试有没有全部跑完?
输出是否符合要求?
有没有明显边界问题?
有没有绕过验证?
有没有遗漏失败项?这就是执行与验证分离。
这里要区分两个概念:编写测试 和 执行验证。
编写测试更像白盒工作。它需要理解业务逻辑、代码结构、边界条件、mock 方式、状态流转,所以往往需要大量上下文,不一定适合单独拆出去。
执行验证更像黑盒工作。它不关心主 Agent 是怎么想的,只看结果是否符合标准:
text
答案是否正确?
格式是否符合要求?
测试是否全部通过?
有没有异常输出?
有没有漏测?因此,执行验证是上下文最干净、最安全的拆分起点。
当然,验证 Agent 也有风险。它很容易"过早胜利"。比如只跑了几个简单测试,发现通过了,就宣布"验证通过,可以上线"。但实际上,边界情况没测、异常输入没测、完整测试套件没跑、回归测试没跑。
所以验证 Agent 的 prompt 必须非常明确,例如:
text
你必须运行完整测试套件,并报告所有失败项。
你必须覆盖边界情况:空值、超长文本、异常字符、非法输入、网络失败、权限不足、重复提交、并发场景。
你必须尝试构造导致失败的数据。
如果你无法运行测试,必须明确说明原因。
你不得修改测试来让结果通过。
你不得只运行部分测试后宣布成功。验证 Agent 不能只是"检查一下",它必须有清晰、可执行、可判断的标准。
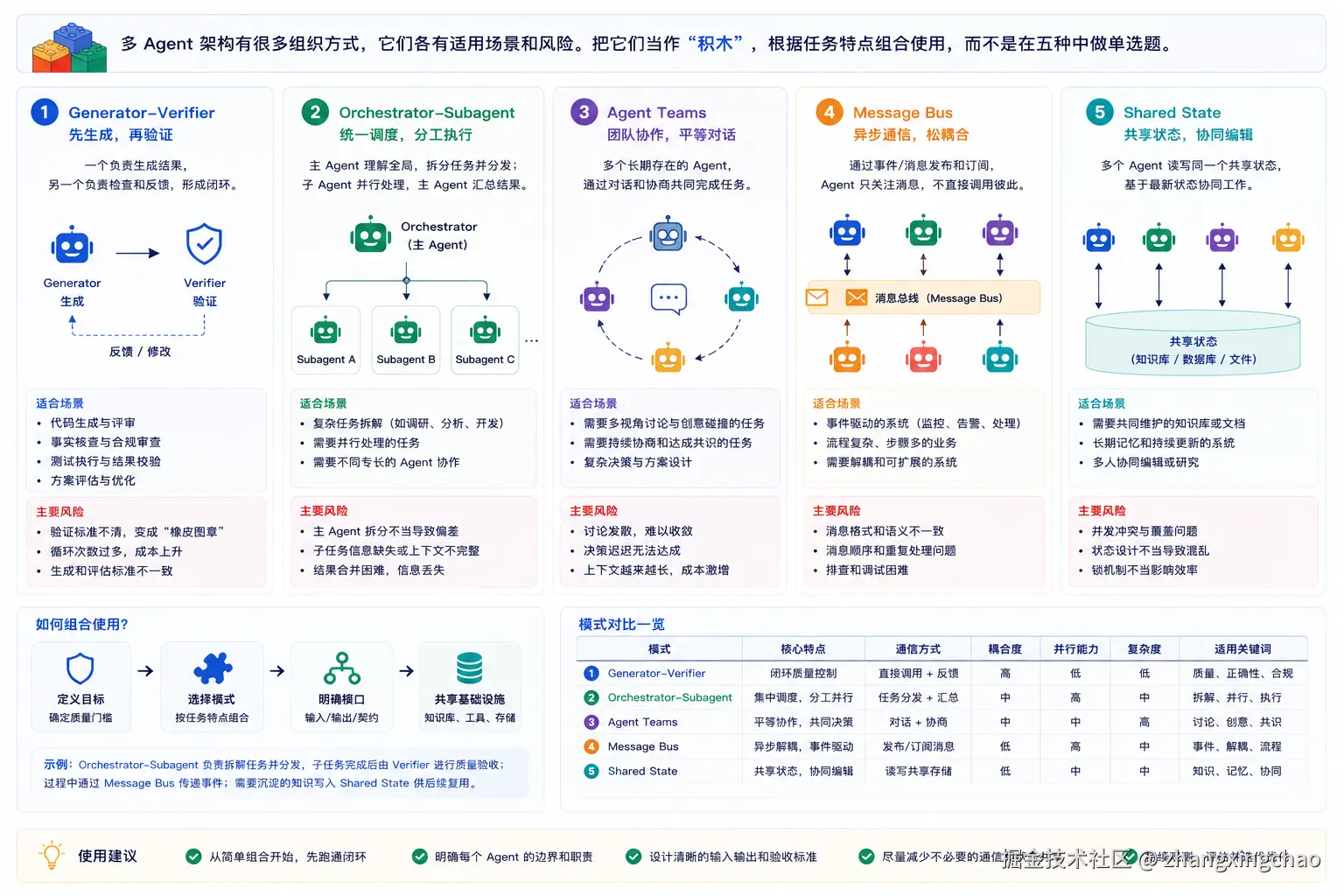
四、五种常见协作模式:多 Agent 是积木,不是菜单
结合 Anthropic 官方文章、Cognition / Devin 的工程经验,以及常见软件架构范式,可以把多 Agent 的协作方式归纳为五类。需要注意的是,Anthropic 官方《Building effective agents》里明确提出的是 Prompt chaining、Routing、Parallelization、Orchestrator-workers、Evaluator-optimizer 等模式;下面这五类是为了工程选型做的综合归纳。
1. Generator-Verifier
Generator-Verifier 和 Anthropic 文章里的 Evaluator-optimizer 很接近。一个负责生成,一个负责评估和反馈。
结构是:
text
Generator 生成结果
↓
Verifier 检查结果
↓
通过:Accepted
失败:反馈给 Generator 修改比如客服邮件回复系统里,生成器负责起草回复邮件,验证器负责检查事实准确性、品牌语气、是否回答了用户每个问题。如果价格写错、问题漏答,就反馈给生成器重写。
它适合代码生成、事实核查、合规审查、rubric 打分、格式检查、测试执行、邮件回复质量检查等任务。
它的风险也很典型:
text
验证器没有标准,会变成橡皮图章;
生成和评估一样难,闭环就不成立;
生成器和验证器一直来回修改,循环不收敛,Token 一直烧。一句话理解:
text
一个人负责起草,另一个人拿着验收单逐条过。Generator-Verifier 更像质量闸门,不一定是主流程本身,但可以叠加到任何架构上。
2. Orchestrator-Subagent
这个模式可以理解为主 Agent 负责理解总任务、拆分任务、分发任务、汇总结果,多个子 Agent 分别处理子任务。
典型例子是自动代码审查:
text
主 Agent 理解整个 PR;
Subagent A 检查安全问题;
Subagent B 检查测试覆盖;
Subagent C 检查代码风格;
Subagent D 检查架构约束;
主 Agent 汇总成一份总评。它的关键价值是:分工 + 上下文隔离。
它适合代码审查、文档审查、多维度评估、竞品分析、资料分类、安全检查、测试覆盖分析等任务。
它的风险是:主 Agent 容易成为信息瓶颈。摘要太粗,子 Agent 会漏掉关键细节;摘要太长,Token 成本又会上升。如果没有真正并行,那成本上去了,速度未必提升。
一句话理解:
text
总经理临时叫几位专家来会诊,问题看完,结果收回来。3. Agent Teams
Agent Teams 比 Orchestrator-Subagent 更进一步。它不是临时分发任务,而是多个 worker 长期存在,并持续负责某一类任务或某一块系统。
比如大型代码库迁移:
text
Worker 1 长期负责服务 A;
Worker 2 长期负责服务 B;
Worker 3 长期负责服务 C。
每个 worker 理解自己负责的模块,改依赖、改代码、修测试、做验证,并不断积累本模块上下文。这个模式买到的不只是并行,还有长期上下文积累。
它适合大型代码迁移、多模块重构、长期数据清洗、复杂研究项目、多服务适配、大型文档体系整理等任务。
风险也比较明显:
text
如果模块之间其实并不独立,worker 就会互相影响;
完成检测更难,不知道谁完成、谁失败、谁卡住;
共享资源容易冲突,比如多个 worker 同时改同一个文件或接口。一句话理解:
text
工地上的几支常驻班组,各守一块区域,时间越久越熟。4. Message Bus
Message Bus 更像事件驱动架构。
它不是由主 Agent 手动分配任务,而是通过事件发布订阅来驱动流程:
text
Alert Source / Triage Agent / Enrichment
↓ publish
Message Bus
↓ subscribe
Network Agent / Identity Agent / Response Agent比如安全运营自动化里,告警进入后,Triage Agent 判断类型;高危网络告警路由给 Network Agent,身份凭证告警路由给 Identity Agent,调查结论再流向 Response Agent。
它适合安全告警处理、客服工单流转、订单异常处理、监控事件响应、数据处理 pipeline、自动化运营系统等场景。
但它也有明显风险:追踪变难,路由可能错误,事件可能丢失,系统可能静默失败。所以它需要配套事件 schema、路由规则、trace id、correlation id、死信队列、重试机制、监控告警。
一句话理解:
text
医院分诊台:来了什么情况,下一站交给谁。5. Shared State
Shared State 是多个 Agent 围绕一个共享状态空间协作。
比如复杂研究系统里:
text
学术 Agent 发现一个关键研究者;
行业 Agent 看到后去查这个人创办的公司;
新闻 Agent 根据公司信息追踪近期融资;
专利 Agent 查相关专利布局。这里的特点是:中间发现不会等到最后统一汇总,而是会随时影响其他 Agent 的下一步。
它们就像围着同一块白板办案:谁发现线索,就写到白板上;其他人看到后,立刻接着查。
它适合复杂情报分析、科研调研、投资研究、竞品动态追踪、企业背景调查、多源信息拼图等场景。
最大的风险是 Reactive Loop:
text
A 写入一个发现;
B 看到后补一条;
A 又看到 B 的补充,再补一条;
B 又继续补一条;
系统很忙,Token 一直烧,但答案没有收敛。所以 Shared State 必须提前设计终止条件、写入权限、去重机制、状态版本、优先级、最大迭代轮数、冲突解决规则。
一句话理解:
text
专案组围着同一块白板办案,谁补一条线索,别人立刻接着查。这五种模式可以按复杂度从低到高理解:
| 模式 | 核心结构 | 适合场景 | 主要风险 |
|---|---|---|---|
| Generator-Verifier | 一个生成,一个检查 | 结果可验证的任务 | 验证器没标准、循环不收敛 |
| Orchestrator-Subagent | 主 Agent 分派短任务 | 多维度检查、并行调研 | 信息瓶颈、摘要损耗 |
| Agent Teams | 长期 worker + 任务队列 | 长期多模块工程 | Worker 冲突、完成检测难 |
| Message Bus | 事件发布订阅 | 事件驱动 pipeline | 追踪难、路由错 |
| Shared State | 多 Agent 读写共享白板 | 协作研究、线索拼图 | Reactive loop、Token 烧不停 |
如果用 Java / Android 类比:
| 多 Agent 模式 | Java / Android 类比 |
|---|---|
| Generator-Verifier | 开发 + CI / Lint / Code Review |
| Orchestrator-Subagent | Facade / Service 调多个 Worker |
| Agent Teams | 长期线程池 / 多模块团队 / feature owners |
| Message Bus | EventBus / MQ / Pub-Sub / Broadcast |
| Shared State | 共享数据库 / Blackboard / 协作文档 |
五、架构如何演进:先跑通,再升级
多 Agent 架构不应该一开始就设计到最复杂。更好的方式是:
text
先用最稳的结构跑通,再根据真实瓶颈往不同方向演进。默认应该先从单体 Agent 开始。当确实需要拆出子任务时,再从 Orchestrator-Subagent / Orchestrator-workers 开始:
text
单体 Agent -> Orchestrator-Subagent / Orchestrator-workers因为它主线清晰、协调成本相对低,适合大多数"已经确认需要拆分"的任务。
后续可以根据瓶颈继续演进。
从 Orchestrator-Subagent 演进到 Agent Teams:看 worker 是否需要长期保留上下文。
如果子任务短、一次性完成,就用 Orchestrator-Subagent。比如安全检查、测试覆盖分析、代码风格检查、架构约束检查。
如果 worker 需要长期负责一块内容,不断积累上下文,就演进到 Agent Teams。比如大型代码库迁移,每个 worker 长期负责一个服务,持续改依赖、改代码、修测试、做验证。
text
短期任务 -> Orchestrator-Subagent
长期 ownership -> Agent Teams从 Orchestrator-Subagent 演进到 Message Bus:看 workflow 是否还能预测。
如果流程大体可预测,比如第一步做 A,第二步做 B,第三步失败就做 C,第四步汇总,那么 Orchestrator-Subagent 就够了。
如果流程变成大量 if/else,比如安全告警、身份告警、网络告警、响应失败、升级处理都走不同路径,主 Agent 里的条件分支就会越来越爆炸。这时应该把分流从主 Agent 中抽出来,变成系统级路由层,也就是 Message Bus。
text
流程可预测 -> Orchestrator-Subagent
事件驱动、分支爆炸 -> Message Bus从 Agent Teams 演进到 Shared State:看中间发现是否会影响别人。
如果几个 worker 各自负责独立分区,最后汇总,那 Agent Teams 就够了。
但如果一个 Agent 的中间发现会立刻改变另一个 Agent 的下一步,就需要 Shared State。比如 Academic Agent 发现一个关键研究者,Industry Agent 马上根据这个人查公司,News Agent 接着查融资,Patent Agent 查相关专利。
text
分区自治,最后汇总 -> Agent Teams
中间发现实时影响别人 -> Shared State从 Message Bus 演进到 Shared State:看系统关注的是事件流转,还是知识累积。
Message Bus 关注的是"下一站是谁、谁来接这个事件"。Shared State 关注的是"系统现在知道了什么、这些发现是否会影响所有 Agent"。
text
Message Bus = 事件路由
Shared State = 共享知识空间这里要特别注意 Generator-Verifier 的特殊地位。严格来说,它更接近 Anthropic 官方《Building effective agents》里的 Evaluator-optimizer,而不是一个完整的多 Agent 主流程架构。
后面几种更偏流程组织方式,Generator-Verifier / Evaluator-optimizer 更偏质量保障机制。它可以叠加到任何模式上:
text
Orchestrator-Subagent + Generator-Verifier
Agent Teams + Generator-Verifier
Message Bus + Generator-Verifier
Shared State + Generator-Verifier所以,模式不是菜单,而是积木。不要问"我到底选哪一个",而应该问:
text
主流程用什么?
质量闸门在哪里?
哪些环节要长期上下文?
哪些环节要事件路由?
哪些环节要共享状态?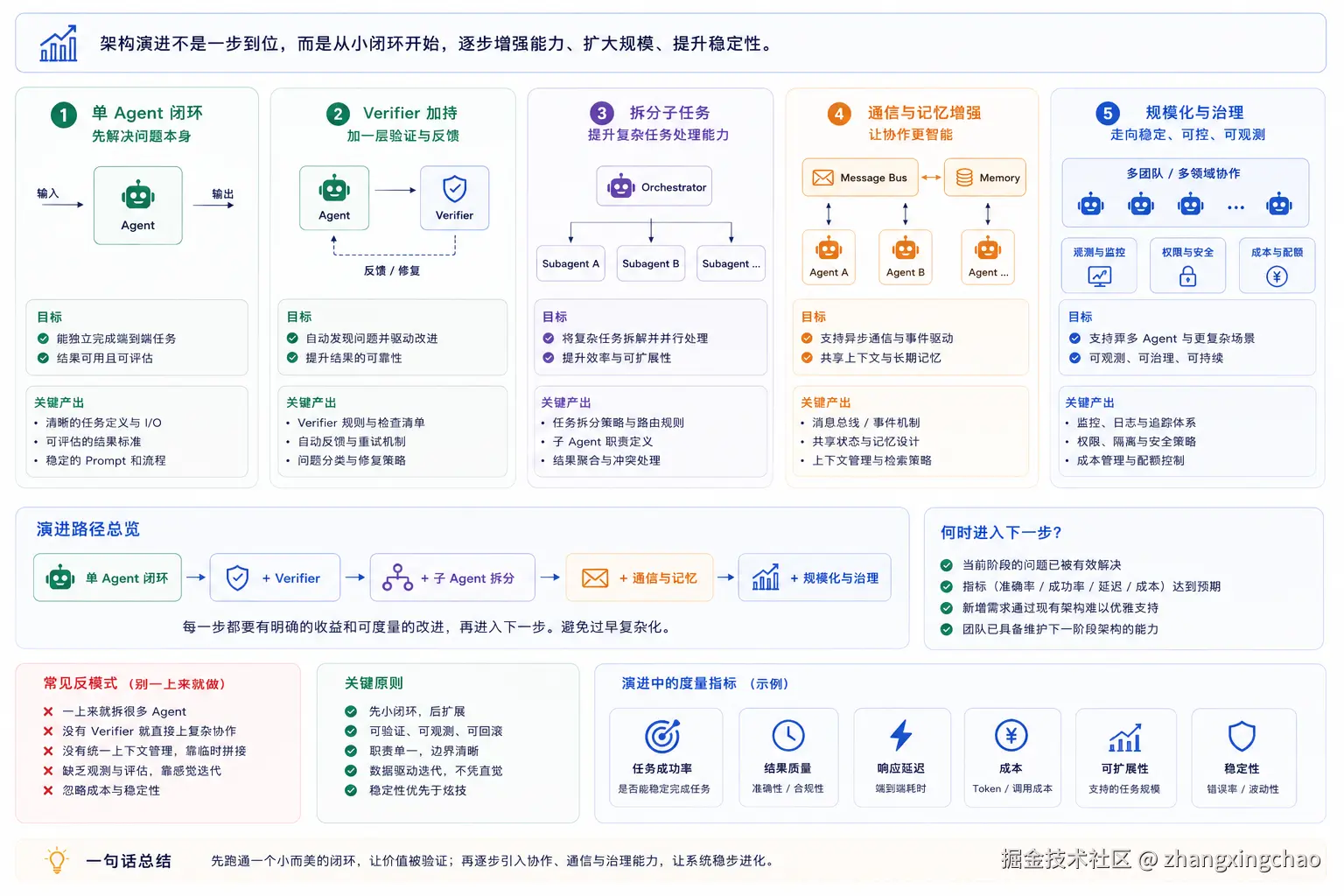
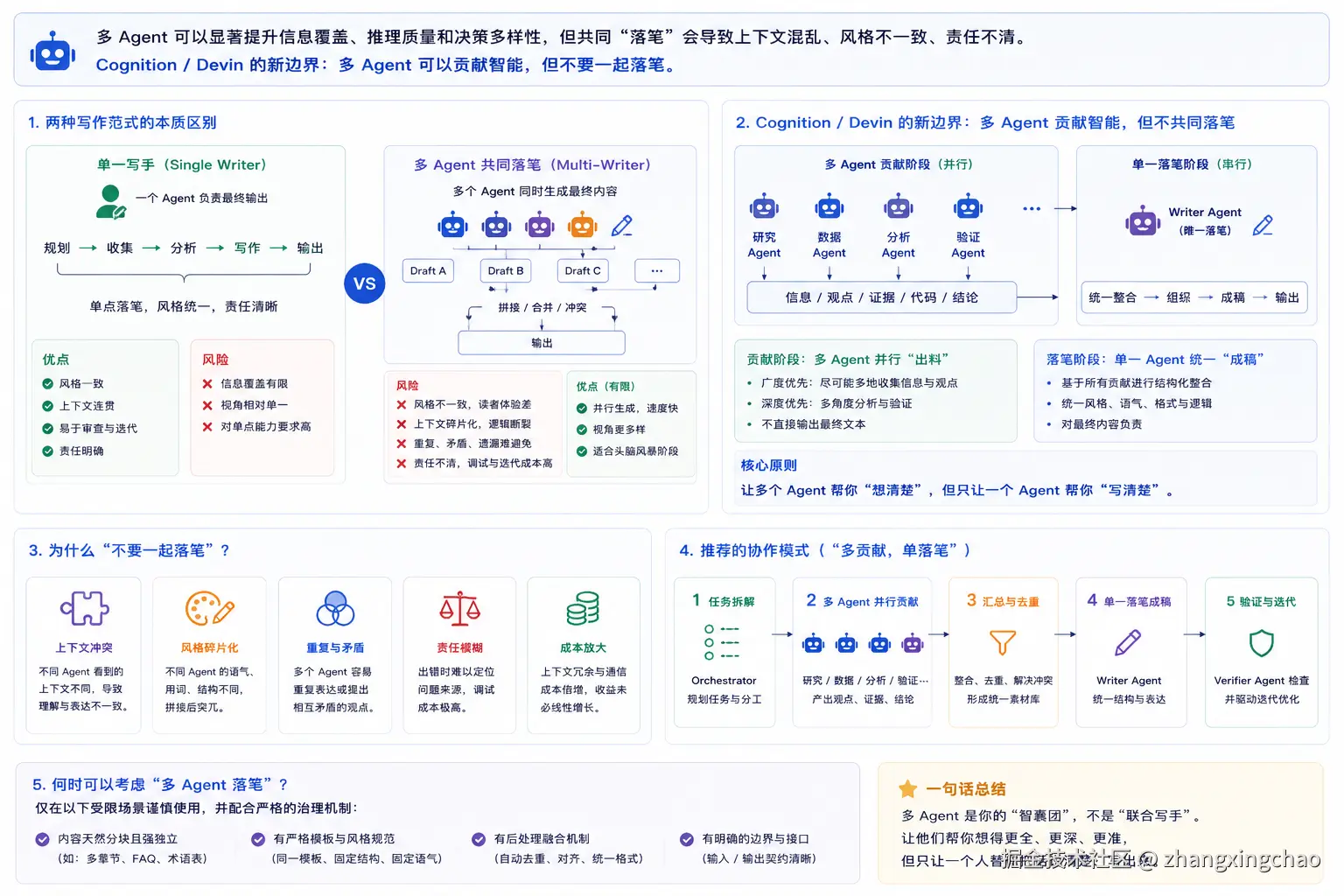
六、Cognition / Devin 的新边界:多 Agent 可以贡献智能,但不要一起落笔
Cognition / Devin 对 Multi-Agent 的最新理解,可以总结为:
text
Multi-Agent 有用,但不要让它们一起写代码。更具体地说:
text
执行者:单线程落笔
其他智能体:只贡献信息错误做法是多个 Agent 一起改代码。正确做法是:
text
主 Agent:
- 最终改代码
- 最终合并决策
- 负责一致性
- 收束回来
其他 Agent:
- 发现问题
- 补充信息
- 分配任务
- 审查方案
- 写测试建议
- 查资料
- 不直接执行写入动作一种常见设计是 智能朋友模式:
text
快 / 便宜的主力模型
遇到难题
请强 / 贵的模型当智能朋友比如主力模型负责常规实现,智能朋友负责复杂推理、疑难分析、补测试、视觉推理、架构判断。
但这个模式有一个关键难点:质量上限往往由主力模型决定。
如果主力模型太弱,它可能不知道什么时候该求助、怎么传递上下文、拿到答案后怎么使用。这就像一个初级工程师旁边坐着高级专家,但初级工程师不知道什么时候该问,问的时候说不清背景,专家回答后也不会正确落地。
所以智能朋友模式要成立,关键不是朋友够不够聪明,而是主力模型会不会问、会不会传上下文、会不会用答案。
另一种更可行的形态是 Manager-Subagent:
text
Manager Agent
-> 子 Agent A
-> 子 Agent B
-> 子 Agent C
-> 汇总结果它适用于一个功能跨多个服务、多个合并请求、持续一周,单个 Agent 难以一直盯住全局的场景。
Manager Agent 负责拆任务、派任务、收结果、汇总,子 Agent 负责执行边界清晰的小任务。
但这里也有两个坑。
第一个坑是:Manager 规定得太细。如果 Manager 没有足够代码库上下文,却写了一堆细节任务,比如"你改这个类、你写这个方法、你加这个字段",子 Agent 可能会按错误细节执行。更好的方式是:Manager 定义目标和边界,子 Agent 自己探索具体实现。
第二个坑是:默认共享状态的幻觉。多 Agent 很容易误以为"我知道的,别人也知道"。但实际上,一个 Agent 知道的,另一个 Agent 不会自动知道。所以必须显式传递任务背景、当前状态、约束条件、已知风险、输出格式和验收标准。
多 Agent 的真正难点,不是能不能多开几个 Agent,而是信息如何高质量流动。
现在边界相对清楚了:
text
最终改代码和合并决策,还是要收束回来;
写入保持单线程;
其他智能体只贡献智能,不直接执行动作。但通信还没完全解决:
text
弱模型如何知道什么时候该求助?
子智能体如何把影响其他任务的信息传出去?
如何传递上下文,又不把接收方淹没?
谁决定采纳还是不采纳?只靠 Prompt 可以往前走一段,但要真正稳定,未来模型可能还需要专门针对多智能体通信场景训练。模型需要学会什么时候求助、怎么提问、怎么摘要、怎么同步、怎么接收、怎么拒绝、怎么整合。
七、最终工程原则:未来稀缺的不是写代码,而是 Spec、Verifier 和 Observability
Agent Teams 的出现,意味着 AI 编程正在从"代码补全、函数生成、结对编程"向"自主开发"演进。
可以粗略分成四代:
Gen 1:IDE 补全。
text
Tab 键补全
静态分析
更聪明的键盘这个阶段,人类仍然是作者,AI 只是辅助输入工具。
Gen 2:函数生成。
text
Docstring 生成
填充函数体AI 可以写一个局部函数,但仍然依赖人类告诉它函数签名、输入输出和上下文。
Gen 3:结对编程。
text
终端对话
短回合交互
修改局部代码
解释错误
生成方案AI 已经可以和人类一起工作,但更像副驾驶。
Gen 4:自主开发 / 承包商。
text
完整 Spec 需求
自主分解协作
对结果负责这时人类不再一句一句指挥"你先写 lexer,你再写 parser,你再修这个 bug",而是给出更高层目标:
text
做一个能通过这些测试的系统。
这是需求。
这是验收标准。
这是不能违反的约束。
你们自己拆任务、实现、验证、交付。人类角色会从执行者变成目标设定者、约束设计者、结果验收者和风险负责人。
也就是从:
text
Help me write走向:
text
Build this for me当代码生成变得越来越便宜、快速、可持续运行时,代码本身会越来越像"水电煤":便宜、随取随用、到处都有、不再稀缺。
以前稀缺的是:
text
谁能写代码?
谁写得快?
谁能实现功能?以后稀缺的是:
text
谁能定义清楚需求?
谁能设计强验证?
谁能发现隐藏风险?
谁能保证系统可控?所以未来工程能力的核心会转向三件事:
text
Spec-as-Code
Verifier-Driven
ObservabilitySpec-as-Code,就是把需求、约束、规则写成机器可以执行或检查的形式。
不要只写"系统要安全、稳定、好用",而要写成明确规则:
text
接口响应 P95 < 300ms
未登录用户不能访问订单详情
支付金额必须以后端计算为准
所有敏感操作必须记录审计日志
WebSocket 状态不能用旧地址覆盖新地址甚至进一步变成测试用例、schema 校验、静态规则、合约测试、权限策略、形式化约束。
Verifier-Driven,就是开发流程由验证器驱动,而不是由代码生成驱动。
以前是:
text
先写代码 -> 再测试未来更可能是:
text
先定义验证器 -> Agent 写代码 -> 验证器判断是否通过 -> Agent 继续修也就是 Verifier 决定方向,Agent 负责探索实现,人类负责定义目标和边界。
Observability,就是必须能看清 Agent 做了什么、为什么这么做、当前风险是什么。
对于 Agent Teams,Observability 不只是日志,还包括:
text
任务看板
Agent 决策记录
代码 diff
测试覆盖情况
失败重试轨迹
成本消耗
权限使用记录
风险告警
回滚路径没有可观测性,多 Agent 自主开发会很危险。
最后,把前面的内容收束成几个工程原则:
text
1. 默认从单体 Agent 开始,如非必要,勿增实体。
2. 遇到瓶颈,先做上下文优化和工具检索。
3. 只有收益大于成本时,才上多 Agent。
4. 不要按岗位拆,要按上下文拆。
5. 最稳的第一步是验证 Agent。
6. 写代码保持单线程。很多所谓"需要多 Agent"的问题,本质上其实是:
text
上下文没整理好;
工具暴露太多;
Prompt 太乱;
任务边界不清;
验证标准不明确。这时应该先尝试上下文压缩、日志过滤、高信噪比摘要、状态文档、Tool Search、工具路由、测试增强,而不是一上来就增加 Agent 数量。
多 Agent 的本质是:
text
用额外的 Token、延迟、通信和复杂度,换取更高能力上限。只有在这些场景下,多 Agent 才更值得:
text
需要上下文强隔离;
任务需要高覆盖度;
职责发生强冲突;
任务天然可并行;
需要长期上下文积累;
事件流转复杂;
中间发现需要实时共享。如果要拆,优先拆 Verifier Agent,而不是先拆开发 Agent。因为验证任务上下文干净、标准明确、容易黑盒化,而且不抢写入权。
Multi-Agent 可以一起规划、检索、审查、测试、监控、分析、补充信息,但不要一起直接写代码。最终写入和合并决策应收束到一个主 Agent。
可以总结成一句话:
text
多 Agent 可以贡献 intelligence;
主 Agent 负责单线程落笔。
多 Agent 架构不是简单地多开几个模型,而是一种工程权衡。单体 Agent 的优势是上下文连续、通信成本低、链路简单,所以应当优先使用。多 Agent 本质上是用额外的 Token、延迟和系统复杂度,换取更高的信息覆盖度、更强的上下文隔离和更明确的专业化能力。
在架构设计时,我会先判断瓶颈来源:如果只是上下文太长,优先做上下文压缩;如果是工具太多,优先做 Tool Search 或工具路由;如果是质量不稳定,优先加入 Verifier Agent;只有当任务天然可并行、需要长期上下文积累、流程分支爆炸,或者中间发现需要实时共享时,才进一步演进到 Agent Teams、Message Bus 或 Shared State。
同时,我不会让多个 Agent 同时直接写代码。代码写入是强耦合动作,容易产生隐含决策冲突。更合理的方式是写入单线程,由主 Agent 负责最终代码修改和合并决策,其他 Agent 只贡献规划、审查、测试、检索、风险发现等 intelligence。
所以,多 Agent 的核心不是 Agent 数量,而是上下文边界、信息流结构、验证机制和可观测性设计。
最后再用一句话总结全文:
text
多 Agent 架构不是银弹。
默认单体 Agent,必要时按上下文拆分;
验证先行,写入单线程;
根据真实瓶颈逐步演进到 Orchestrator-Subagent、Agent Teams、Message Bus 或 Shared State。真正难的不是"调用模型",而是:
text
上下文怎么切
信息怎么流
谁来写入
谁来验证
怎么观测
怎么收敛这才是 Agent 工程化的核心。来个图串联整个文章:
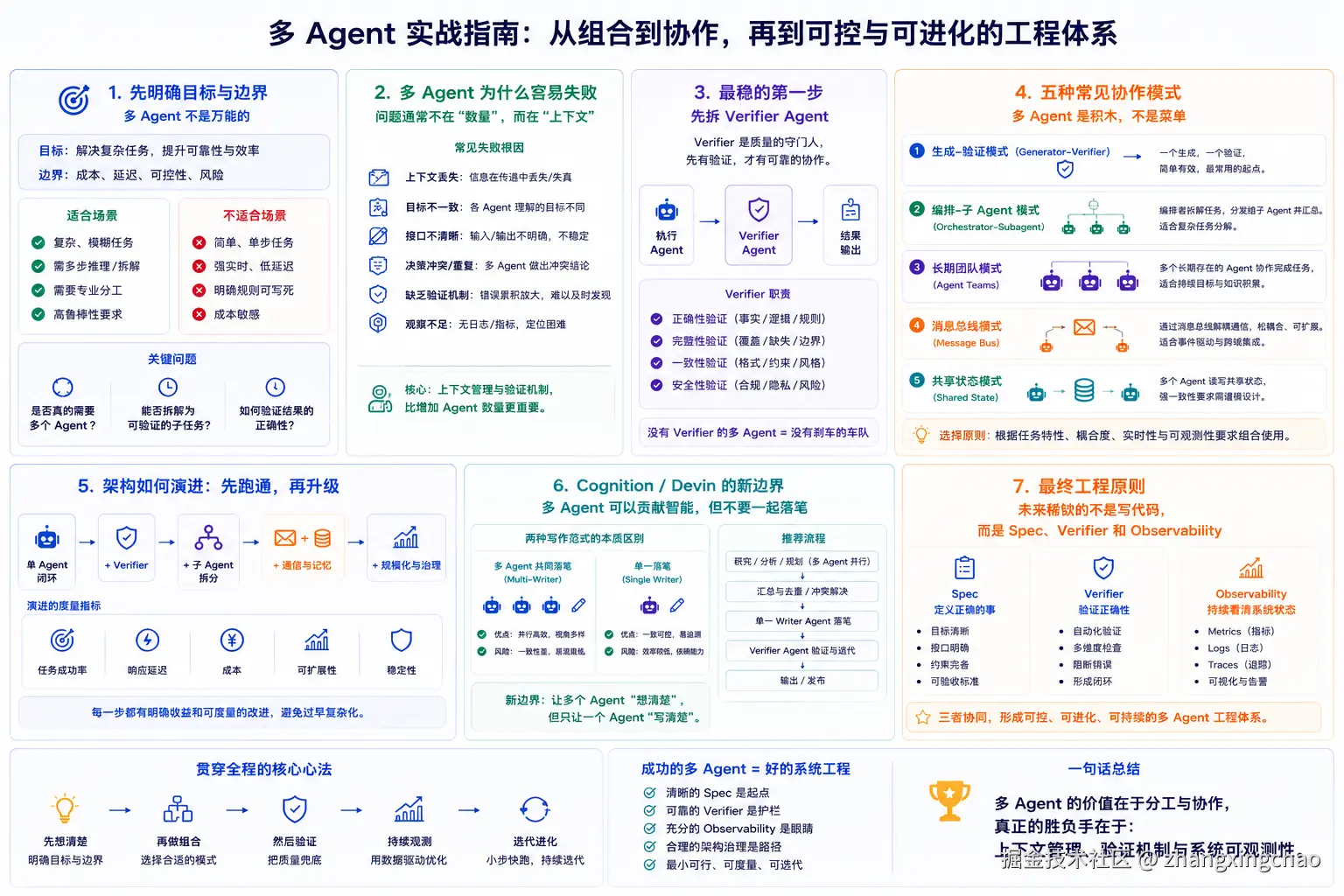 来个图
来个图