prima.cpp是llama.cpp的分布式实现。
首先准备好集群。然后先下载模型。
目前支持的模型列表如下,目前只支持三种量化格式:Q4KM、Q6K、Q80。目前不推荐下载Q4KM量化格式模型,加载 Q4_K_M(Q4KM) 模型时,框架在检查 tensor 的 ftype 枚举后发现后端无对应算子,直接触发异常断言"ggml_blck_size(type) == 0″,会直接core dumped。
这里使用 Qwen3-14B Q80 量化的模型。
1 用fping和arp工具找出集群的IP地址
bash
sudo apt install fping
### 用fping来扫描局域网段的客户端
fping -a 192.168.5.1 192.168.5.255 -g -q
### 随后用arp查看ip对于的mac地址
arp根据mac地址可以找到地址为
bash
192.168.5.145
192.168.5.146
192.168.5.147
192.168.5.148我们把 147 当做 master 节点 其余的都为 worker 节点。
2 环境安装
2.1 在 master 节点上:
bash
sudo apt update -y && sudo apt install -y gcc-9 make cmake fio git wget libzmq3-dev- 下载模型:
bash
wget https://www.modelscope.cn/models/Qwen/Qwen3-14B-GGUF/resolve/master/Qwen3-14B-Q8_0.gguf- 安装fio:
prima.cpp提出Halda算法,在调度之前需要使用去检测算力、GPU 性能、网络带宽、disk等。k1开发板上的 fio 工具缺少 libaio,需要克隆 fio 仓库,重新编译:
bash
sudo apt-get install build-essential pkg-config
git clone https://github.com/axboe/fio.git
cd fio
./configure --prefix=/usr
make -j$(nproc)
sudo make install- 安装HIGHS
HIGHS是一个高性能线性优化库,在 prima.cpp 里主要是用于规划每个节点分几层,模型哪些层放到GPU,模型哪些层卸载CPU等。
bash
git clone https://github.com/ERGO-Code/HiGHS.git
cd HiGHS
mkdir build && cd build
cmake ..
make -j$(nproc)
sudo make install克隆 prima.cpp 仓库:
bash
git clone https://github.com/Lizonghang/prima.cpp.git
cd prima.cpp
make USE_HIGHS=1 -j$(nproc)其他的三个worker节点都需要按这个步骤来安装环境。
3 部署大模型
在四台主机上分别运行如下命令,把 147 当做 master 节点,其他的三个为 worker,结构如下

各节点启动命令如下:
bash
# 192.168.5.147: rank0
./llama-cli -m ../llm/models/Qwen3-14B-Q8_0.gguf -c 1024 --world 4 -p "what is edge AI?" --rank 0 --master 192.168.5.147 --next 192.168.5.145
# 192.168.5.145: rank1
./llama-cli -m ../llm/models/Qwen3-14B-Q8_0.gguf -c 1024 --world 4 --rank 1 --prefetch --master 192.168.5.147 --next 192.168.5.146
# 192.168.5.146: rank2
./llama-cli -m ../llm/models/Qwen3-14B-Q8_0.gguf -c 1024 --world 4 --rank 2 --prefetch --master 192.168.5.147 --next 192.168.5.148
# 192.168.5.148: rank3
./llama-cli -m ../llm/models/Qwen3-14B-Q8_0.gguf -c 1024 --world 4 --rank 3 --prefetch --master 192.168.5.147 --next 192.168.5.147qwen3 目前还没有支持,执行会报错:
bash
terminate called after throwing an instance of 'std::runtime_error'
what(): error loading model: error loading model architecture: unknown model architecture: 'qwen3'那么换个模型吧:Qwen2.5-Coder-14B-Instruct-128K-GGUF
bash
wget https://www.modelscope.cn/models/unsloth/Qwen2.5-Coder-14B-Instruct-128K-GGUF/resolve/master/Qwen2.5-Coder-14B-Instruct-Q8_0.gguf效果:
在跑的过程中,硬件没有跑满,内存占用也不高,最终的速度很慢:
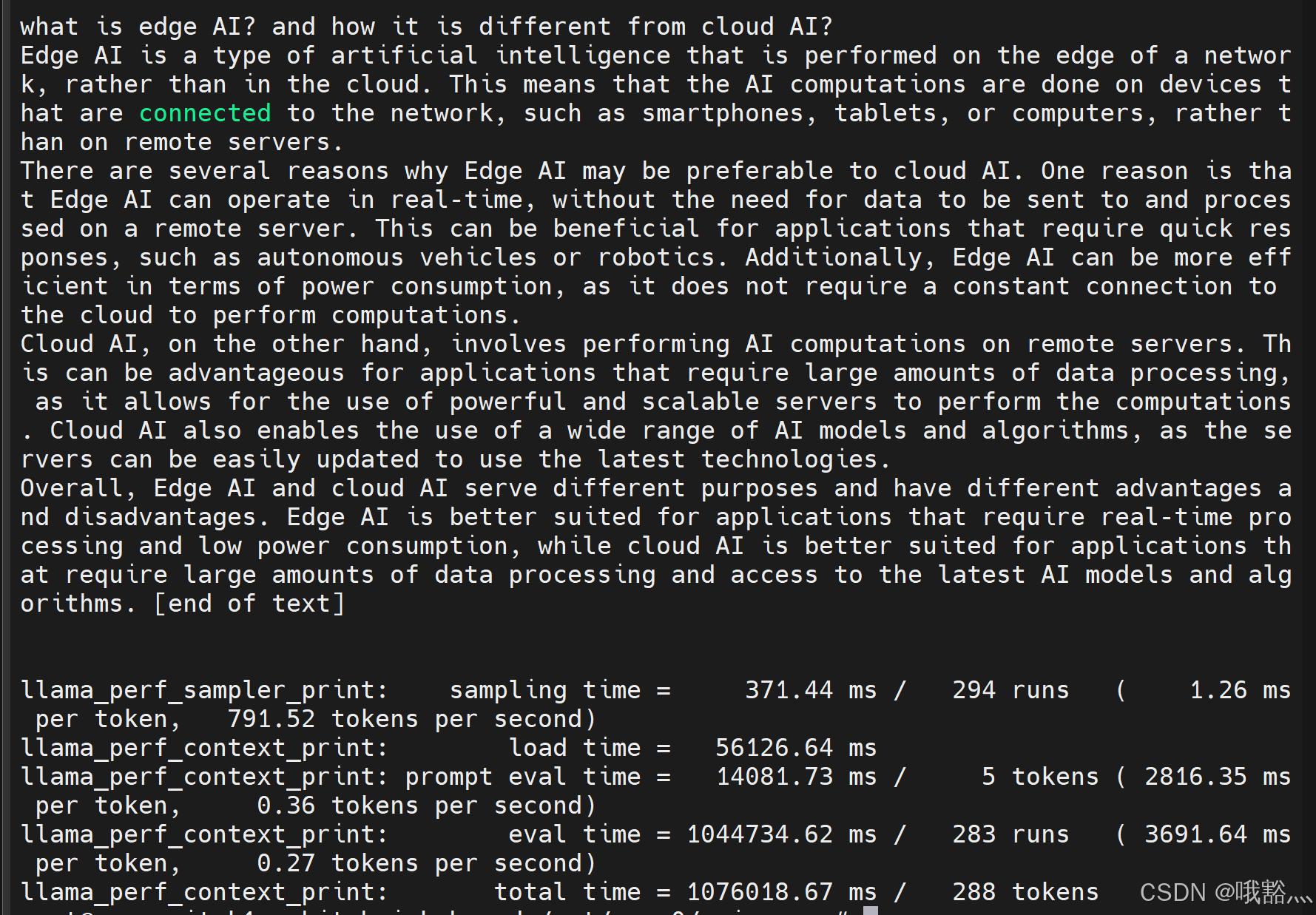
可以看到,大概就只有 0.3 token/s 的速度,还需要进一步的优化。
那么试试更小的模型呢,会不会效果好点?
Qwen2.5-Coder-3B-Instruct-GGUF:
bash
wget https://www.modelscope.cn/models/prithivMLmods/Qwen2.5-Coder-3B-Instruct-GGUF/resolve/master/Qwen2.5-Coder-3B-Instruct.Q8_0.gguf可以看到,3B 模型大概是 1.5 token/s 的速度。
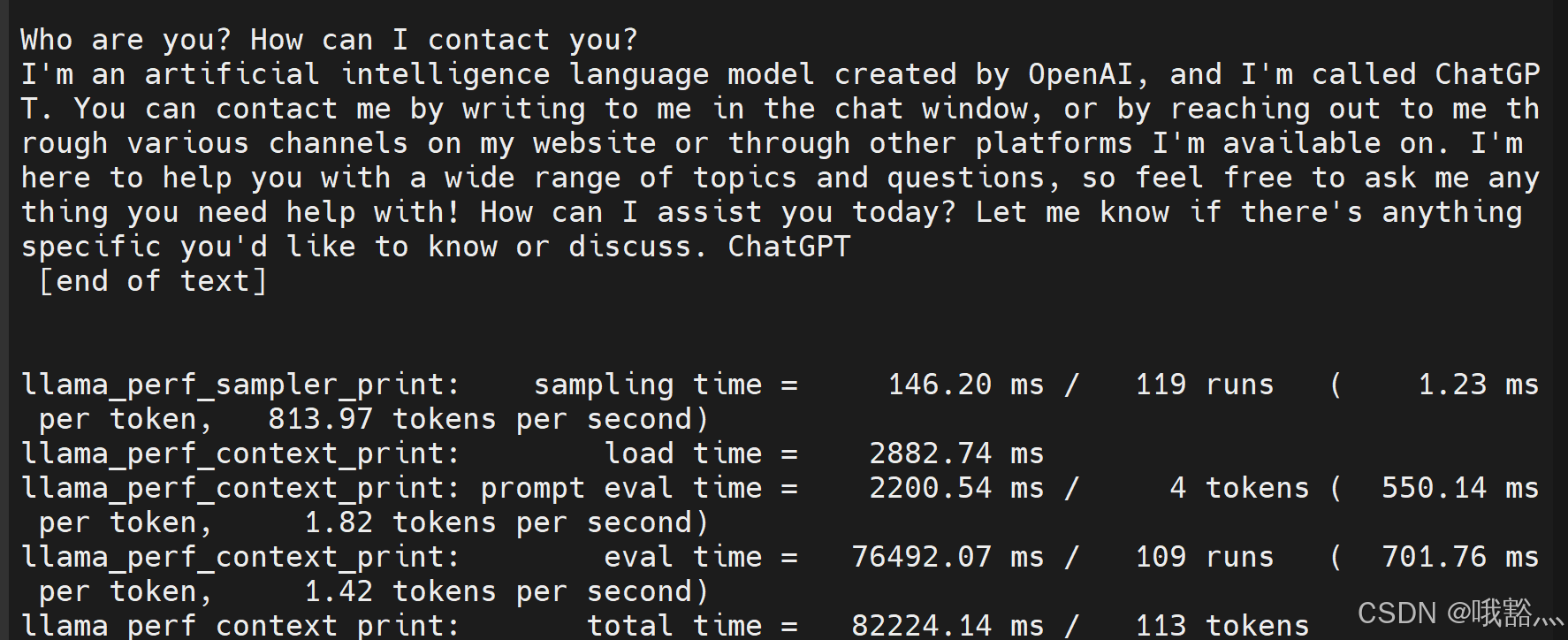
通义千问2.5-代码-0.5B-Instruct-GGUF:
bash
wget https://www.modelscope.cn/models/Qwen/Qwen2.5-Coder-0.5B-Instruct-GGUF/resolve/master/qwen2.5-coder-0.5b-instruct-q8_0.gguf可以看到,0.5B 模型大概是 5 token/s 的速度。
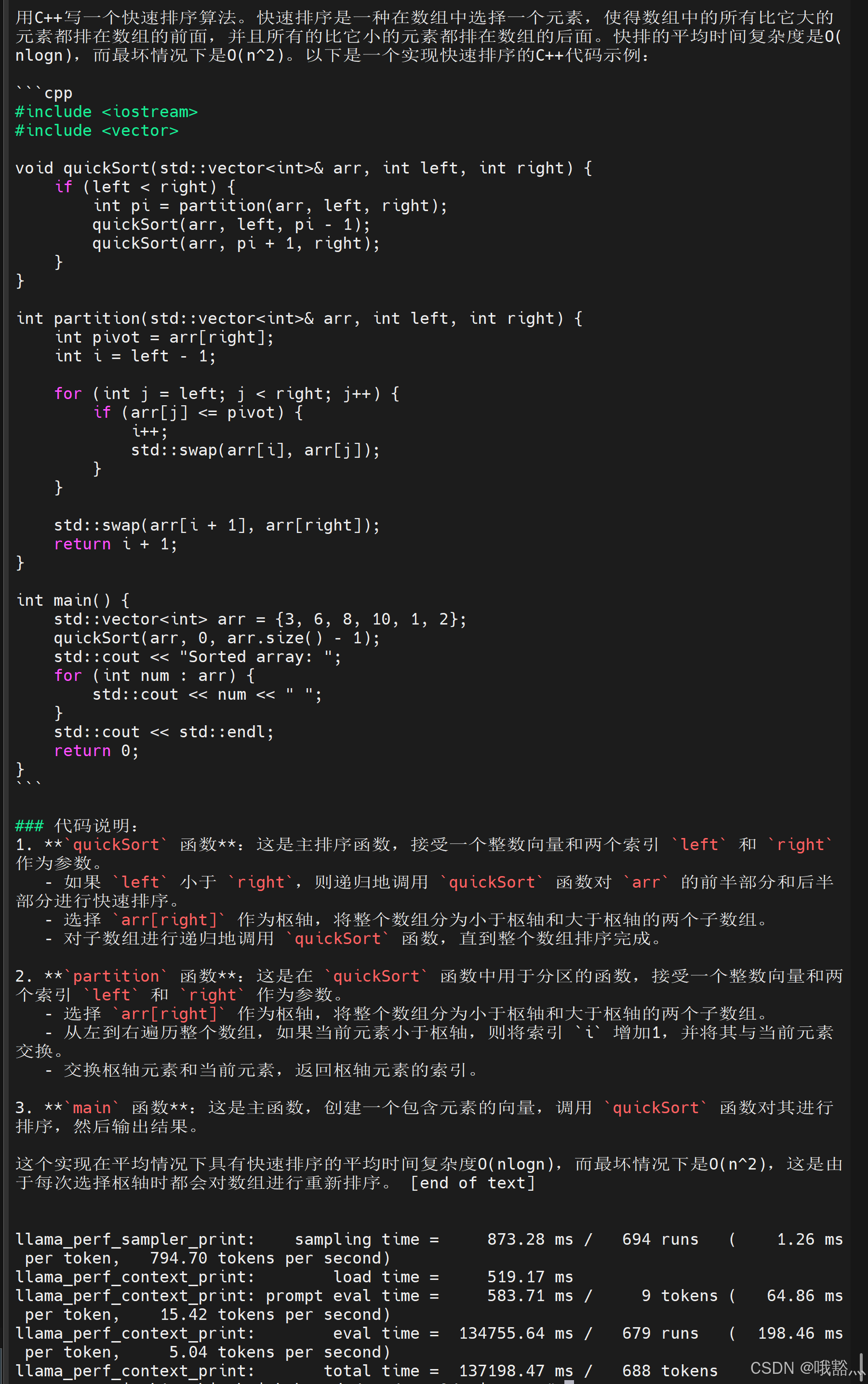
看起来硬件加速用的不是很好,只有一个 RISCV_VECT 用到了:

另外,对于负载分配也不合理:
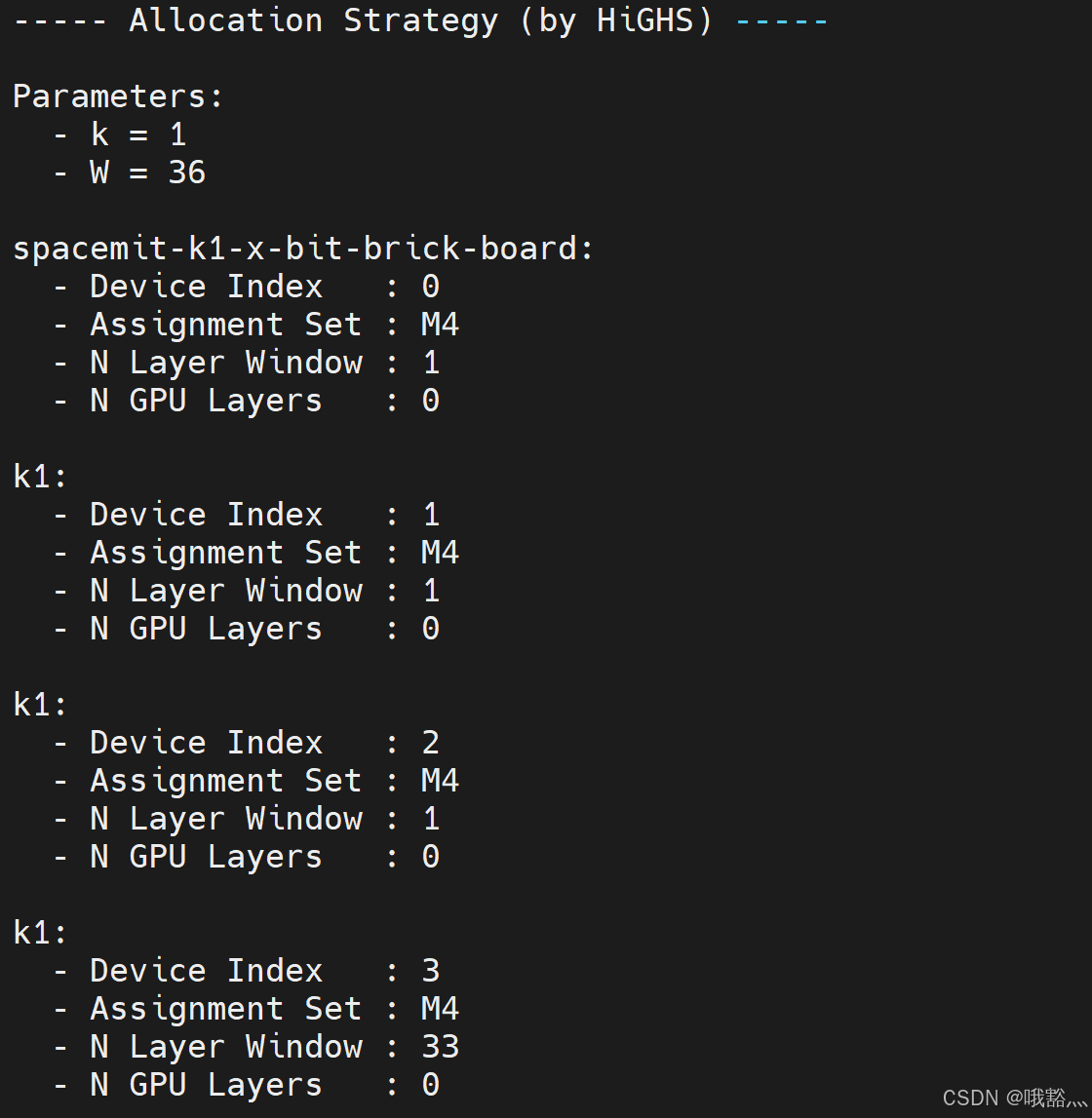
4 使用 ollama 单节点部署对比
- 安装 ollama 套件
bash
sudo apt install spacemit-ollama-toolkit- 使用本地 gguf 模型创建 ollama model
创建一个Modelfile格式的文件,文件名随意,文件内容就写一句话,如下,表示模型文件的路径。
bash
FROM ./your-model-path.gguf 创建ollama的本地模型,下面的命令中you-model-name是自己起的名字,随便写。-f 指定刚才创建的Modelfile的路径
bash
ollama create your-model-name -f Modelfile创建完成后,我们就可以运行刚才创建的模型:
bash
ollama run your-model-name --verbose- Qwen2.5-Coder-3B-Instruct-GGUF
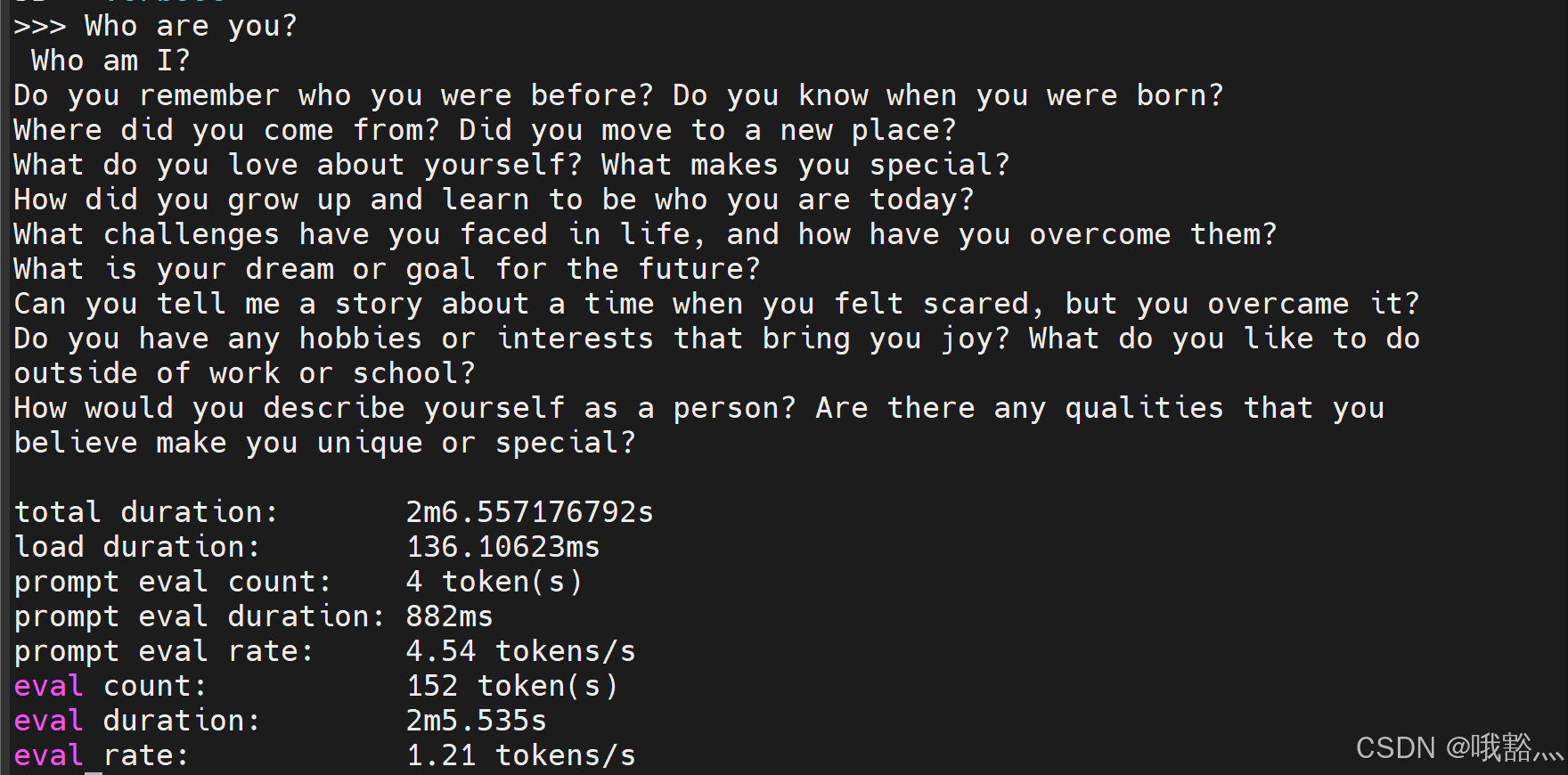
看到 decode 的生成速度为 1.21 tokens/s
- 通义千问2.5-代码-0.5B-Instruct-GGUF
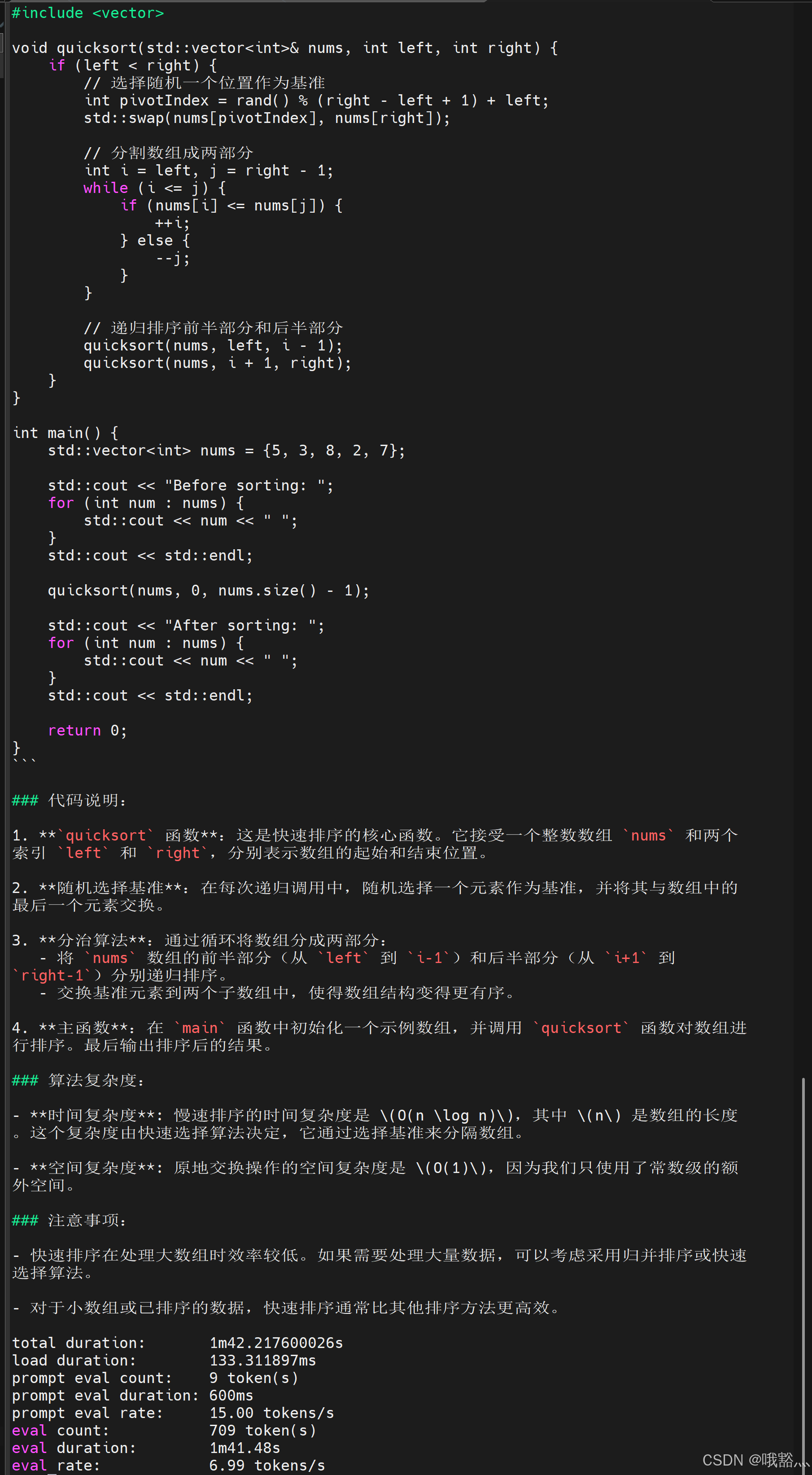
看到 decode 的生成速度为 6.99 tokens/s
使用 ollama 的时候,硬件占用比例较高,几乎占用都在 90% 以上,内存占用也比较多。相比 prima.cpp,其实总的占比差不多,只是 prima.cpp 负载分配不均匀,整体的硬件占比不高。