1. 前言
我们在上一篇文章中讲解了如何使用微信 ClawBot 连接本地 AI Agent,这一篇我们讲解如何使用飞书机器人连接本地 AI Agent。
首先我们需要创建一个飞书应用。
2. 创建飞书应用
2.1 打开飞书开放平台
访问飞书开发平台 open.feishu.cn/app 并登录。
2.2 创建应用
1.点击 创建企业自建应用
2.填写应用名称和描述
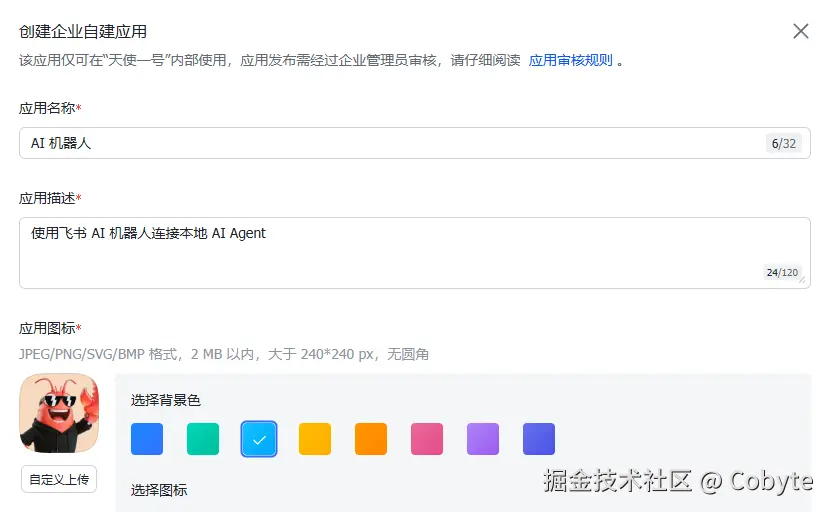
3.选择应用图标
2.3 复制凭证
在"凭证与基础信息"中复制:
- App ID
- App Secret
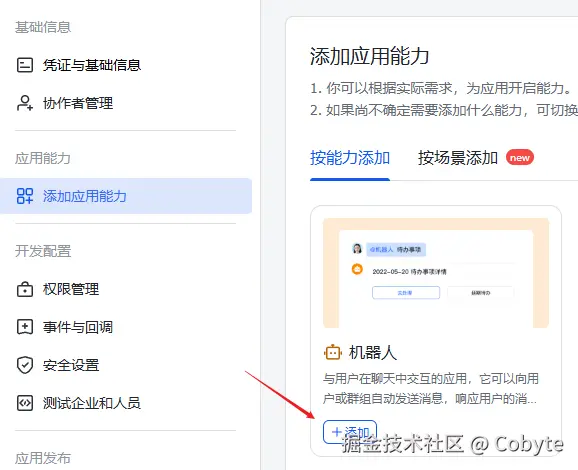
2.4 启用机器人能力
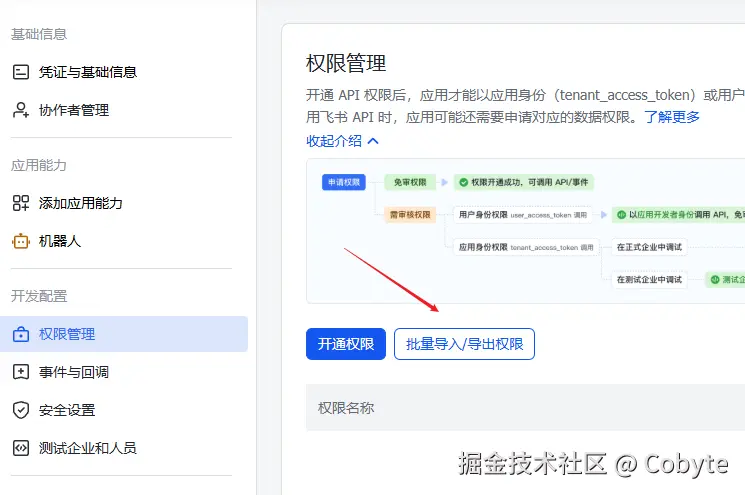
2.5 配置权限
在权限管理 中点击批量导入/导出权限按钮
然后复制粘贴以下权限:
json
{
"scopes": {
"tenant": [
"aily:file:read",
"aily:file:write",
"application:application.app_message_stats.overview:readonly",
"application:application:self_manage",
"application:bot.menu:write",
"cardkit:card:read",
"cardkit:card:write",
"contact:user.employee_id:readonly",
"corehr:file:download",
"event:ip_list",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.members:bot_access",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.p2p_msg:readonly",
"im:message:readonly",
"im:message:send_as_bot",
"im:resource"
],
"user": ["aily:file:read", "aily:file:write", "im:chat.access_event.bot_p2p_chat:read"]
}
}最后点击确定并申请开通。
2.6 配置事件订阅
在事件与回调 中进行事件配置 ,选择订阅方式为长连接,这样我们就可以在本地电脑也可以连接飞书机器人了(本质是WebSocket)。
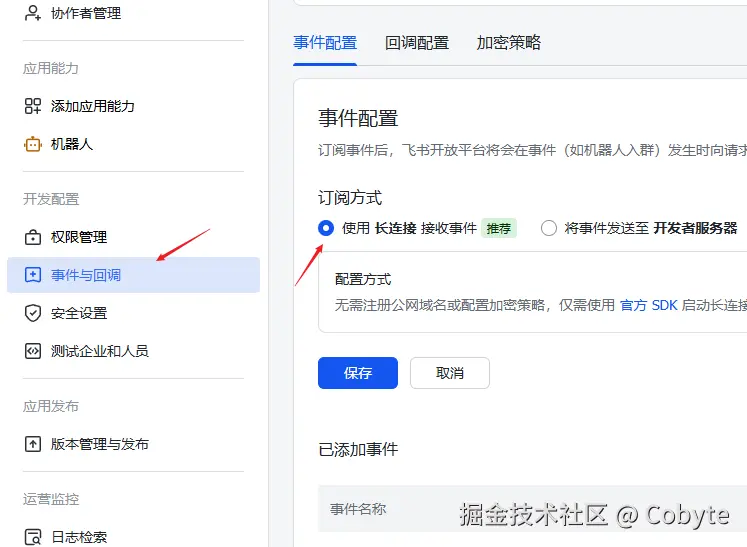
接着添加接收消息事件:im.message.receive_v1
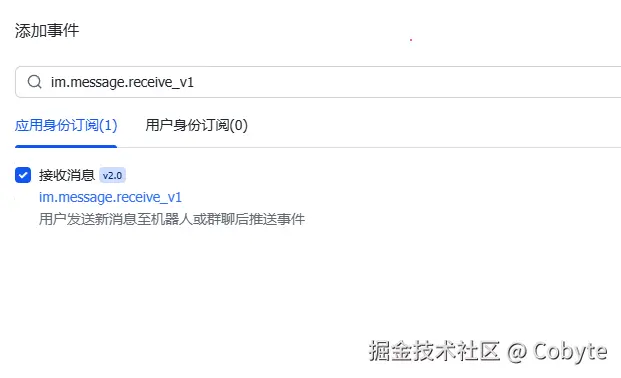
加密策略设置,这个可选项。
2.7 发布应用
接着我们在版本管理与发布中创建一个版本并发布。
一般我们在测试的时候,我们自己的飞书账号就是管理员,上述版本申请发布后会在手机飞书上收到一条审核消息,我们按提示进行操作审核即可。
这时我们就可以在手机飞书上搜索我们刚刚创建的"AI 机器人",然后点击进去就可以对话了,但目前我们还没通过代码连接它,所以还对不了话。
值得注意的是:上述飞书机器人配置也是OpenClaw的官方飞书机器人配置方案。
3. 实现飞书连接本地 Agent
3.1 构建 API Client
根据飞书开发平台开发文档的 《Python SDK 指南》,我们在通过 SDK 调用飞书开放接口之前,需要先在代码中创建一个 API Client,用来指定当前使用的应用、日志级别、HTTP 请求超时时间等基本信息。
我们的实现如下:
py
from dataclasses import dataclass
import lark_oapi as lark
@dataclass
class FeishuConfig:
"""飞书渠道配置"""
app_id: str = ""
app_secret: str = ""
encrypt_key: str = "" # 可选字段,空字符串表示不使用加密
verification_token: str = "" # 可选字段,空字符串表示不验证消息来源
class FeishuChannel:
def __init__(self, config: FeishuConfig):
self.config = config
# 构建 API Client
self._client = lark.Client.builder() \
.app_id(config.app_id) \
.app_secret(config.app_secret) \
.build()首先我们实现一个配置类来统一管理上述我们说到的 App ID 、App Secret 以及在配置事件订阅中讲到的加密策略设置的 Encrypt Key 、Verification Token。
后续我们就可以通过依赖注入模式调用 FeishuChannel 类了:
py
# 使用
config = FeishuConfig(app_id="...", app_secret="...")
channel = FeishuChannel(config=config) # 配置通过构造函数注入这样实现了配置与实现分离,将来支持热更新配置。
3.2 长连接飞书客户端
根据飞书开发平台开发文档的 《Python SDK 指南》的处理事件章节,我们的实现如下:
py
from loguru import logger
class FeishuChannel:
def __init__(self, config: FeishuConfig):
# 省略...
def start(self) -> None:
# 构建事件处理器
builder = lark.EventDispatcherHandler.builder(
self.config.encrypt_key,
self.config.verification_token
)
# 注册接收消息事件处理函数 im.message.receive_v1
handler = builder.register_p2_im_message_receive_v1(self._on_message).build()
# 初始化长连接客户端并传入事件处理器
ws_client = lark.ws.Client(
self.config.app_id,
self.config.app_secret,
event_handler=handler
)
# start() 方法会阻塞主线程,持续运行,直到手动关闭
ws_client.start()
logger.info("✅ 飞书极简版机器人已启动 (WebSocket)")
def _on_message(self, data: P2ImMessageReceiveV1) -> None:
"""接收到消息时的回调"""我们首先构建事件处理器,同时如果你在开发者后台的应用详情中,配置了 事件与回调 > 加密策略 页面内的加密信息(Encrypt Key 和 Verification Token )。则必须将加密信息的值传递到 EventDispatcherHandler.builder 方法的参数中。
接着我们注册接收消息事件处理函数。也就是我们在前面配置事件订阅小节所讲的添加的接收消息事件:im.message.receive_v1。
最后通过 lark.ws.Client() 初始化长连接客户端,必填参数为应用的 APP_ID 和 APP_SECRET。我们在上面讲述创建飞书应用的时候已经阐述过 APP_ID 和 APP_SECRET 了。
值得注意的是:飞书的长连接客户端 (ws.Client) 只能用来"接收"事件,不能用来"发送"消息!如果要主动发消息或回复消息,必须使用普通的 Open API 客户端 (lark.Client)。
3.3 接收消息事件处理函数
py
class FeishuChannel:
def __init__(self, config: FeishuConfig):
# 省略...
def start(self) -> None:
# 省略...
def _on_message(self, data: P2ImMessageReceiveV1) -> None:
"""接收到消息时的回调"""
msg = data.event.message
# 只处理用户发送的纯文本消息
if data.event.sender.sender_type == "bot" or msg.message_type != "text":
return
content = json.loads(msg.content).get("text", "")
if not content:
return
logger.info(f"收到{msg.chat_id}消息: {content}")
# 发送消息
self._process_and_reply(msg.chat_id, content)我们这里先只处理用户发送的纯文本消息。
3.4 发送消息到 AI Agent 处理并进行回复
前面说了飞书的长连接客户端 (ws.Client) 只能用来"接收"事件,不能用来"发送"消息!如果要主动发消息或回复消息,必须使用普通的 Open API 客户端 (lark.Client)。
所以根据飞书开发平台开发文档的 《Python SDK 指南》的服务器API 章节的《发送消息》,我们的实现如下:
py
import agent_loop as agent # 导入本地 AI Agent 逻辑模块
class FeishuChannel:
def __init__(self, config: FeishuConfig):
# 省略...
def start(self) -> None:
# 省略...
def _on_message(self, data: P2ImMessageReceiveV1) -> None:
# 省略...
def _process_and_reply(self, chat_id: str, content: str) -> None:
"""调用本地 AI Agent 获取结果并调用飞书 API 发送"""
try:
history = [
{"role": "system", "content": getattr(agent, "SYSTEM", "你是一个 AI 助手")},
{"role": "user", "content": content}
]
# 1. 运行 AI 思考逻辑
reply_text = agent.agent_loop(history)
if not reply_text:
return
# 2. 发送回复
receive_id_type = "chat_id" if chat_id.startswith("oc_") else "open_id"
req = CreateMessageRequest.builder().receive_id_type(receive_id_type).request_body(
CreateMessageRequestBody.builder()
.receive_id(chat_id)
.msg_type("text")
.content(json.dumps({"text": reply_text}))
.build()
).build()
resp = self._client.im.v1.message.create(req)
if resp.success():
logger.info(f"➡️ 成功回复消息到: {chat_id}")
else:
logger.error(f"❌ 回复失败: {resp.msg}")
except Exception as e:
logger.error(f"❌ 处理异常: {e}")在 _process_and_reply 方法中,我们首先构造与 AI Agent 的对话历史,调用 agent.agent_loop(history) 运行我们前面实现的 AI Agent 进行思考获取回复文本。这部分我们应该比较熟悉了。
根据飞书开发平台开发文档的 《发送消息》指南,发送消息时需要指定 receive_id_type 参数。飞书的 ID 有两种类型:
- chat_id :以
oc_开头的群聊 ID - open_id:用户个人 Open ID
我们通过简单的字符串前缀判断 chat_id.startswith("oc_") 来区分这两种类型。
构建消息请求时:
- 首先创建
CreateMessageRequest的建造者 - 设置
receive_id_type(接收者ID类型) - 通过
request_body()设置请求体,其中又使用CreateMessageRequestBody的建造者设置具体参数 - 调用
.build()方法最终构建请求对象
这里需要注意的是,飞书消息的 content 字段必须是 JSON 字符串格式,所以我们需要使用 json.dumps({"text": reply_text}) 将回复文本包装成 JSON。
最后调用 self._client.im.v1.message.create(req) 发送消息到飞书服务器,并根据响应结果记录成功或失败日志。
现在我们已经完成了飞书渠道的核心实现,接下来编写启动脚本。
4. 启动飞书机器人
我们创建一个独立的启动文件 test_feishu.py:
py
from loguru import logger
from feishu import FeishuChannel, FeishuConfig
def main():
# 1. 填入你的飞书机器人凭证
config = FeishuConfig(
app_id="xxxx", # 替换为真实的 App ID
app_secret="xxxx", # 替换为真实的 App Secret
encrypt_key="", # 如果飞书后台配置了 Encrypt Key 则填入,否则留空
verification_token="" # 如果配置了 Verification Token 则填入,否则留空
)
# 2. 初始化频道并启动长连接
channel = FeishuChannel(config=config)
logger.info("正在启动飞书机器人长连接...")
# 3. 启动并保持运行
try:
channel.start()
except KeyboardInterrupt:
logger.info("收到退出信号,正在关闭...")
if __name__ == "__main__":
main()启动脚本的实现非常简单直接:
第一步:配置飞书机器人凭证
我们需要创建 FeishuConfig 实例,填入在飞书开放平台创建应用时获取的凭证:
- app_id :应用的唯一标识,以
cli_开头 - app_secret:应用的密钥,用于 API 身份验证
- encrypt_key:可选,如果在开发者后台配置了加密策略则需要填入
- verification_token:可选,用于验证消息来源
第二步:初始化飞书频道
使用配置对象创建 FeishuChannel 实例。这里体现了依赖注入模式的优势------我们可以轻松更换不同的配置来源。
第三步:启动并保持运行
调用 channel.start() 启动飞书机器人的 WebSocket 长连接。这个方法会阻塞主线程,持续运行直到收到退出信号。
我们使用 try...except KeyboardInterrupt 捕获用户按 Ctrl+C 的中断信号,实现优雅退出。当用户想要停止机器人时,只需在终端中按 Ctrl+C,程序会记录退出日志然后正常结束。
运行机器人
在启动之前,先安装相关依赖。
requirements.txt 依赖如下:
ini
python-dotenv==1.0.1
openai==2.24.0
loguru==0.7.3
# 飞书官方 Python SDK
lark-oapi>=1.2.0执行 pip install -r requirements.txt 安装依赖。
依赖安装完毕后,在终端中执行:
python test_feishu.py你会看到以下输出:
yaml
2026-04-05 00:59:23.456 | INFO | 正在启动飞书机器人长连接...此时机器人已经启动并开始监听飞书消息了。你可以在飞书中找到你的机器人应用,发送消息进行测试。
5. 启用异步事件循环线程
5.1 Node.js 和 Python 的主线程对比
我们知道 Node.js 默认的主线程就是事件循环线程,而 Python 的主线程默认是没有事件循环的。所以我们在上面也提到了调用 channel.start() 启动飞书机器人的 WebSocket 长连接会阻塞主线程。因为飞书 Python SDK 的 lark.ws.Client 采用同步阻塞设计,其 start() 方法会启动自己的事件循环并持续运行。主要体现在 FeishuChannel 类的 start 方法中以下代码:
py
ws_client.start()
logger.info("✅ 飞书极简版机器人已启动 (WebSocket)")我们发现执行 ws_client.start() 代码后日志不打印了,因为主线程被阻塞了。
而在 Node.js 中以下的代码则不会被阻塞:
js
const WebSocket = require('ws');
function run_ws() {
const ws = new WebSocket('ws://example.com/socket');
ws.on('open', () => {
console.log('[Worker] WebSocket connected');
});
ws.on('message', (data) => {
console.log('[Worker] Received:', data.toString());
});
}
// 同步执行
run_ws();
console.log('主线程没有被阻塞');我们发现直接在 Node.js 的主线程中启动 WebSocket 连接服务是不会阻塞的,因为 Node.js 中的 WebSocket 本身是基于 Node.js 的事件循环来实现的。
5.2 通过 asyncio 启动异步事件循环
通过上一小节我们知道 Python 默认的主线程是没有事件循环的,需要显式创建运行。目前在 Python 3.7+ 推荐通过 asyncio 来启动异步事件循环。
实现很简单:
py
async def main():
# 省略...
try:
await channel.start()
except KeyboardInterrupt:
logger.info("收到退出信号,正在关闭...")
if __name__ == "__main__":
import asyncio
asyncio.run(main())上述代码的转换过程等于:
scss
主线程 (执行Python代码)
↓
调用 asyncio.run()
↓
主线程内部启动事件循环
↓
主线程 = 异步事件循环线程但现在运行会报错,因为虽然主线程启动了异步事件循环线程,但飞书 SDK 的 lark.ws.Client 内部也使用了异步事件循环,当我们在已有的 asyncio 事件循环中调用它时,会产生冲突。
所以我们需要在独立线程中运行飞书的 WebSocket 客户端,避免与主线程的事件循环冲突。修改如下:
py
class FeishuChannel:
def __init__(self, config: FeishuConfig):
# 省略...
async def start(self) -> None:
# 省略...
def run_ws():
# 为 WebSocket 客户端所在线程设置专属的事件循环,避免报错
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
import lark_oapi.ws.client
lark_oapi.ws.client.loop = loop
# 初始化长连接客户端
ws_client = lark.ws.Client(
self.config.app_id,
self.config.app_secret,
event_handler=handler
)
ws_client.start()
# 在独立线程中运行飞书的 WebSocket 客户端,避免与主线程的事件循环冲突
threading.Thread(target=run_ws, daemon=True).start()
logger.info("✅ 飞书极简版机器人已启动 (WebSocket)")
# 保持主协程存活
while True:
await asyncio.sleep(1)主要修改了 FeishuChannel 类的 start 方法,通过 threading.Thread 在独立线程中运行飞书的 WebSocket 客户端,避免与主线程的事件循环冲突,并为飞书 WebSocket 客户端所在线程设置专属的事件循环,避免报错。
5.3 防止 AI 处理阻塞消息接收
无论是 Python 还是 Node.js,都需要防止耗时的 AI 处理阻塞消息接收。所以我们需要修改 _on_message 方法:
py
class FeishuChannel:
def __init__(self, config: FeishuConfig):
# 省略...
async def start(self) -> None:
# 省略...
def _on_message(self, data: P2ImMessageReceiveV1) -> None:
# 省略...
# 启动独立线程处理 AI 逻辑和回复,防止阻塞 WebSocket 接收循环
threading.Thread(
target=self._process_and_reply,
args=(msg.chat_id, content)
).start()我们看到在上述代码中启动一个独立线程处理 AI 逻辑和回复,防止阻塞 WebSocket 接收消息循环。
这时我们再次启动代码,我们可以看到 start 方法中的日志同步打印了:
yaml
2026-04-05 01:20:01.456 | INFO | 正在启动飞书机器人长连接...
2026-04-05 01:20:01.457 | INFO | ✅ 飞书极简版机器人已启动 (WebSocket)6. 总结
至此,我们已经完整实现了通过飞书机器人连接本地 AI Agent。通过上述实践,我们不仅掌握了具体的实现步骤,更重要的是理解了背后的技术原理:
- Node.js vs Python 事件循环:Node.js 主线程本身就是事件循环线程,天生异步;Python 则需要显式创建事件循环,主线程默认同步执行
- Python 异步架构:深入理解了 asyncio 事件循环与多线程的协作模式,以及如何通过线程隔离解决 SDK 的冲突
记住:技术的最佳学习方式就是动手实践。现在就去飞书开放平台创建你的应用,启动这个机器人,感受 AI 与即时通讯结合的魅力吧!
我是程序员Cobyte,欢迎添加 v: icobyte,学习交流 AI 全栈。