01 什么是质性数据?
质性数据(Qualitative Data) ,也叫定性数据,是以文字(如访谈记录、田野笔记)作为最小单位呈现的信息。与之相对的,是以数字作为最小单位的定量数据(Quantitative Data)。
简单来说,定量数据回答"多少",质性数据回答"是什么"和"为什么"。
通过网盘分享的文件:nvivo15安装包和教程.zip
链接: https://pan.baidu.com/s/1RgQU-i27mqEgGNeiRDIb5Q?pwd=mikd提取码: mikd

02 研究的底层逻辑
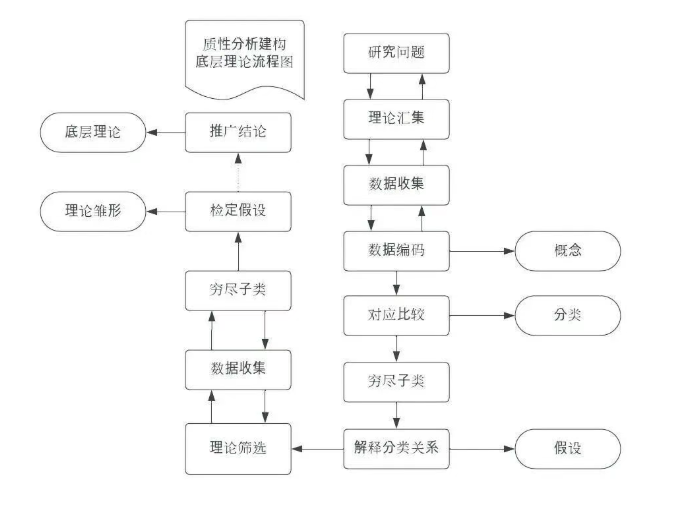
质性研究建立在归纳推理(Inductive Analysis)的认识论基础上。 它不预设假设去验证(那是定量研究中的演绎推理),而是**从具体的、特殊的现象出发,逐步构建底层理论。**这种方法论被称为 "扎根理论"(Grounded Theory) ------让理论从数据中"长"出来。
03 数据从哪儿来?
质性数据的采集方式灵活多样,常见的有:
05 分析方法:主题分析
主题分析(Thematic Analysis) 是质性研究中最常用的方法之一。它的核心在于:根据研究问题,从访谈记录中提取、建立主题与次主题,从而抽象形成初步理论。
当然,如果你需要验证确切的研究假设,也可以参考实证主义的思路,采用分析归纳法(Analytic Induction)。
06 实战工具:NVivo 操作指南
面对大量的访谈记录,手动翻阅不仅繁琐,还容易遗漏关键信息。这时候就需要专业软件的辅助。NVivo(以及Atlas)是目前主流的质性分析软件。
它的本质作用是:建立系统化的档案管理,减少重复性劳动,让研究者把脑力集中在梳理人际网络、厘清概念和构建理论上。
第一步:材料准备与导入
你需要准备:
文件命名规范至关重要。建议格式:访谈01-受访者A-2024年3月1日-xx市xx地
如果前期没有规范整理,可先利用NVivo的编辑模式进行文本排序。
第二步:试建编码
从最有代表性的一篇访谈记录开始(通常是信息量最大或最精彩的那篇)。逐句阅读,用2-3个字概括涉及的主题。
举例:
"我们人年纪大了不想留在城里,打一阵工就回老家。"------受访者A
你可以建立主题:市民化有关的要素------年龄
关于"前设"的处理:
如果你已有较强的概念性前设(即读过的文献已为你提供框架),可以采用"分析归纳法"。此时需要在一开始就列明文献中呈现的主次编码。
举例:
根据Zhao (2023)的研究:年龄是影响市民化意愿重要因素。
建立不同层级的主次编码。此时可以借助NVivo右侧的编码栏(Coding Bar)对照文本进行高亮参考,直观地观察不同编码在采访中出现的频率。
第四步:整合编码
将零散的编码整合成不同的主题与次主题,尝试归纳更概括的理论。
举例:
在研究"市民化意愿"时,你会发现它跟年龄、城市等级、本地人排斥、受教育程度、性别、住房条件、户口等一系列因素都有联系。虽然文本中各种因素交错,但通过编码整合,就能梳理出清晰的脉络。
第五步:查漏补缺
导出编码文档进行备份,对编码进行初步的写作(Write-up)。记得及时存档
第三步:主题编码
-
访谈(Interview)
-
参与式观察(Participatory Observation)
-
档案检索与查询
-
系统文献综述
-
民族志(Ethnography)
04 主要应用领域
-
社会科学
-
教育学
-
社会学
-
人类学
-
已整理好的Word访谈记录
-
明确的研究问题
-
建立主题:市民化意愿
-
建立次主题:年龄
-
对应数据:"我们人年纪大了不想留在城里,打一阵工就回老家。"------受访者A
07 进阶功能:概念图与抽样
NVivo不仅仅是编码工具。通过抽样调查(Sampling)功能,你还可以绘制思维概念图、任务关系图,让整个定性分析流程更清晰、更合理、更有力!
08 经典案例推荐
如果你想深入学习,不妨从这三个经典质性研究案例入手:
-
**人类学:**费孝通的《乡土中国》与《江村经济》
-
**社会学:**项飙的《跨越边界的社区:北京"浙江村"的生活史》
-
**芝加哥学派:**城市研究部分案例