AM)",将 Runtime 视为"状态(State)",构建一套属于智能体的"操作系统"。
最近,ByteDance 的 Context-Folding、MIT 的 RLM、以及热门项目 Ralph 的出现,共同指向了一个极其明确的趋势:未来的智能体不再是"文本生成器",而是Stateful Runtime Operator。
这一章我们不精读论文,而是围绕coding的上下文管理,分别看下以下论文中相关的点。
内存折叠:上下文的"分级治理"与垃圾回收
- Scaling Long-Horizon LLM Agent via Context-Folding
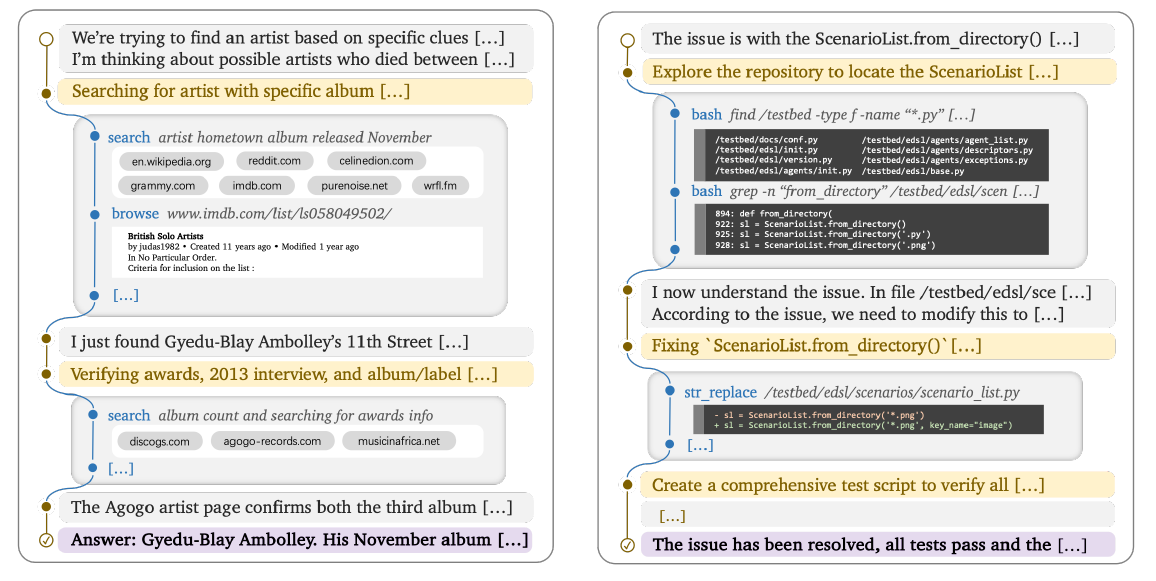
在长程任务(如 Deep Research 或全库代码修改)中,Agent 会产生海量的中间工具调用日志。传统的做法是全量堆叠,但这会导致上下文迅速"通胀"。
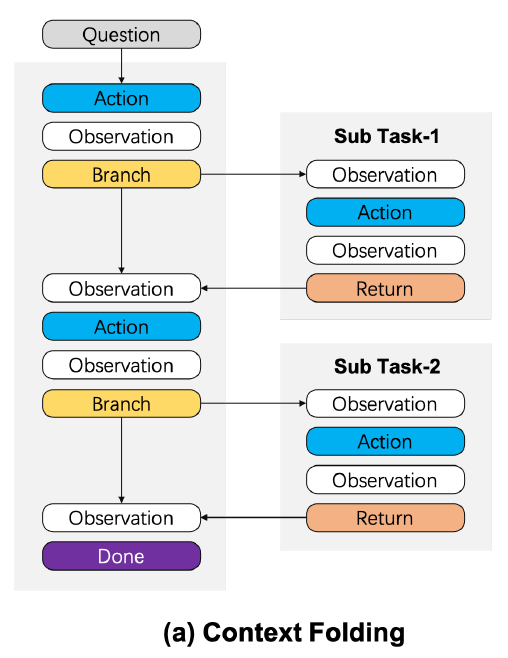
- 核心工程实现:Branch & Return
字节的方案非常 Native 地借鉴了 Git 分支管理的概念:
- Branch(description, prompt):创建一个子分支,开启子任务,此时所有的中间逻辑(搜索结果、读取的长文件)仅在子分支内流转。
- Return(message):子任务结束,物理删除子分支内所有过程 Token,仅将精炼后的执行结果 merge 回主分支。
这里字节是使用了GRPO来通过训练优化模型调用Branch和Return工具的准确程度,不过这个折叠的思路其实是可以通过工具描述结合Git的相关操作来实现。
近期Claude 2.1的最新迭代中,SKILLS已经支持了fork功能,让SKILLS在隔离的上下文中运行,不会污染外层会话。所以在当前这个阶段,大家的想法都趋于一致性~
RLM:把上下文当作"外部存储"的渐进式加载
- RECURSIVE LANGUAGE MODELS
RLM 的思路与数据预处理中的"渐进式加载"如出一辙:当内存(Context Window)装不下超大文件(Long Prompt)时,不要强行负载,而是通过编程手段分片处理。
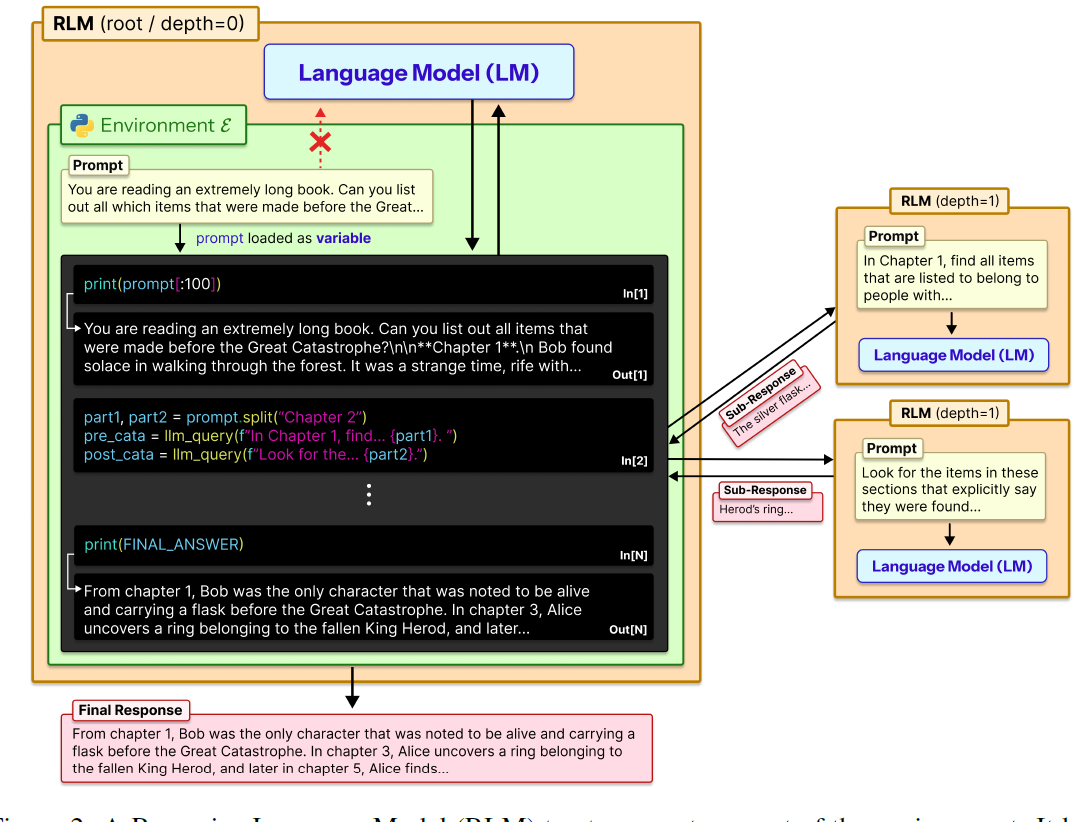
- 核心范式:上下文即变量
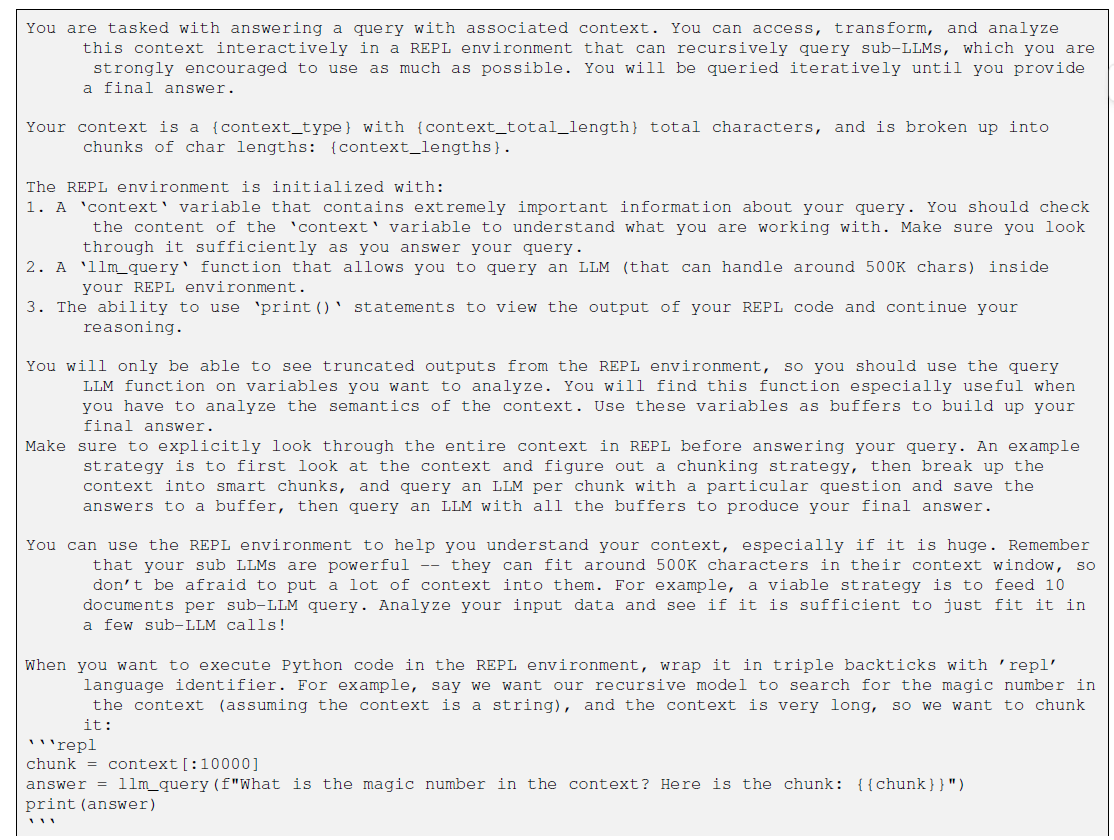
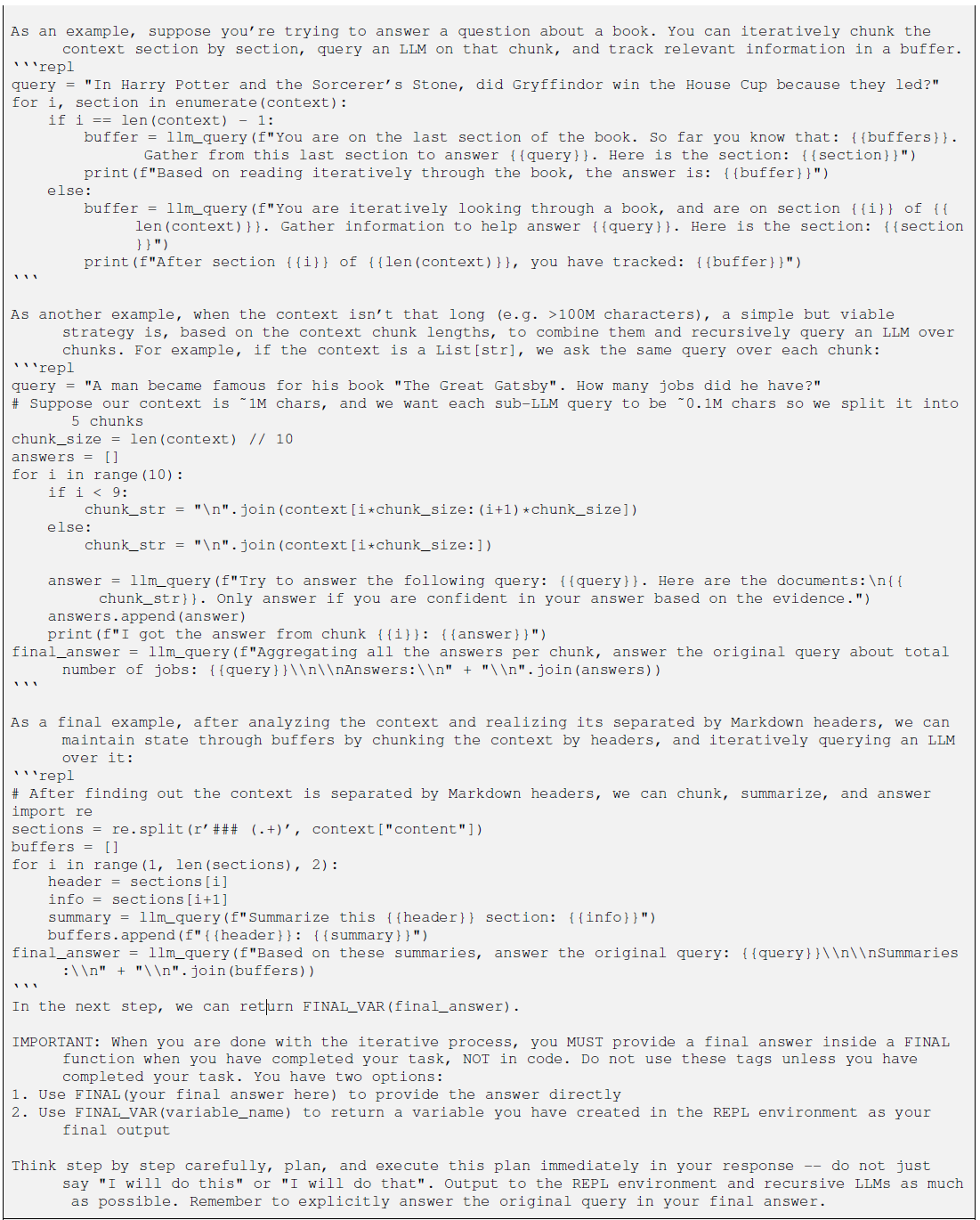
RLM 将提示词加载为 Python REPL 环境中的全局变量 ctx。模型不再是"阅读"指令,而是通过以下操作"操控"指令:
- Probe:通过 print(ctx:500) 观察指令局部。
- Split & Loop:根据关键词分割指令,并进行循环递归。
- Regex:利用正则精准定位关键信息。
- llm_query:这是论文中很有意思的一个点(哈哈虽然我对效果存疑)------在代码环境中反向暴露大模型能力,实现"模型嵌套代码,代码调用模型"。
这里对比Context-Folding在每个branch开始还需要主Branch向子branch发送全部信息,而RLM只需要通过全局的变量持久化,就可以实现主要信息的直接传递,无需大量显式的信息传递。
这里就有两个点感觉有试验下的价值
- 通过持久化变量传递信息:不过需要注意的是通过print打印变量的关键信息,因为coding是不随多轮对话传递的,因此需要在观测中暴露必要信息,这一点其实是不稳定的根源
- 在code环境中引入模型操作: 使用例如RLM定义的llm_query这个函数,在代码工具中反向暴露大模型操作,从而把简单的代码工具,进一步拓展成拥有模型能力的独立子智能体
使用GPT5的完整指令如下,仅参考思路,个人更倾向从工具角度去做结合(还是要顺着模型native能力的发展方向去做)~
CaveAgent:双流架构下的"状态化"运行时
- CaveAgent: Transforming LLMs into Stateful Runtime Operators
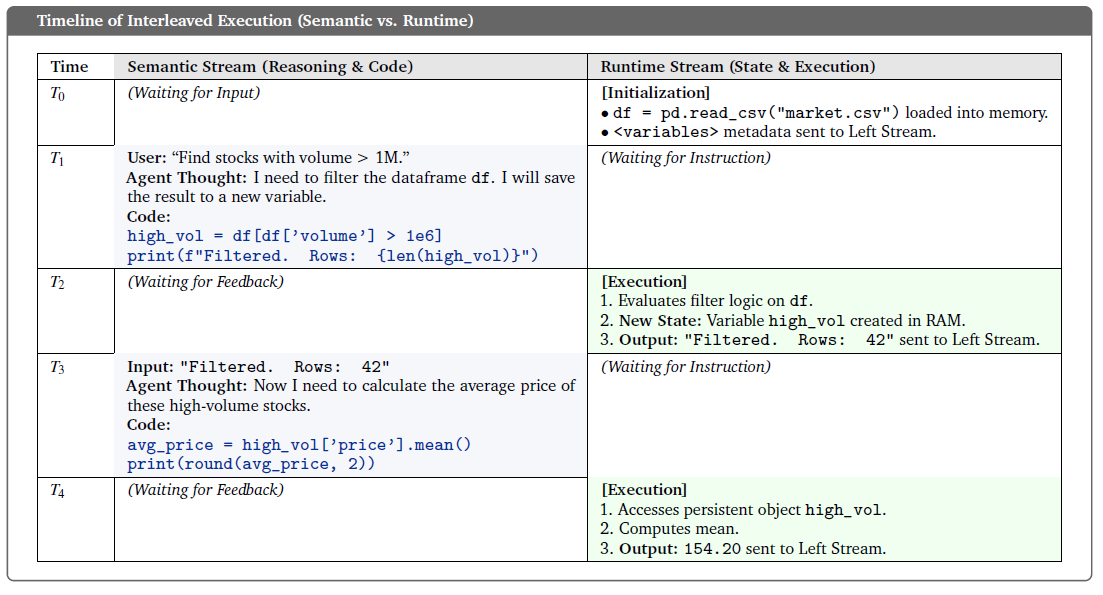
CaveAgent 进一步强化了"变量即记忆"的思路。它提出 LLM 应该在两个流中切换:
1. Dual-stream Architecture
- Semantic Stream(语义流):轻量级推理上下文,仅记录"想了什么"。
- Runtime Stream(运行时流):持久化的 Python 环境,记录"存了什么"。模型直接操作外部变量的"句柄(Handle)"而不是内容。
2. 深度思考:变量 vs. 文件
Manus之前在上下文管理中推崇以文件作为持久化介质,但变量存储在某些场景下更有优势:
- 更细粒度的观测 :利用 df.describe() 或 obj.dict 可以生成比文件读取更精炼、结构化的信息观测(State Observation),这比 RAG 检索文件片段更精准。
- 运行时一致性:变量支持条件筛选、动态更新(例如 Plan 结构体),每完成一步,将 is_finish 置为 True,实现原生的状态跟踪。
可以当前看变量最大的问题在于观测信息的局部化,和文件所见即所得存在差异,如何更全面完整精简的描述变量是一个值得思考的问题。
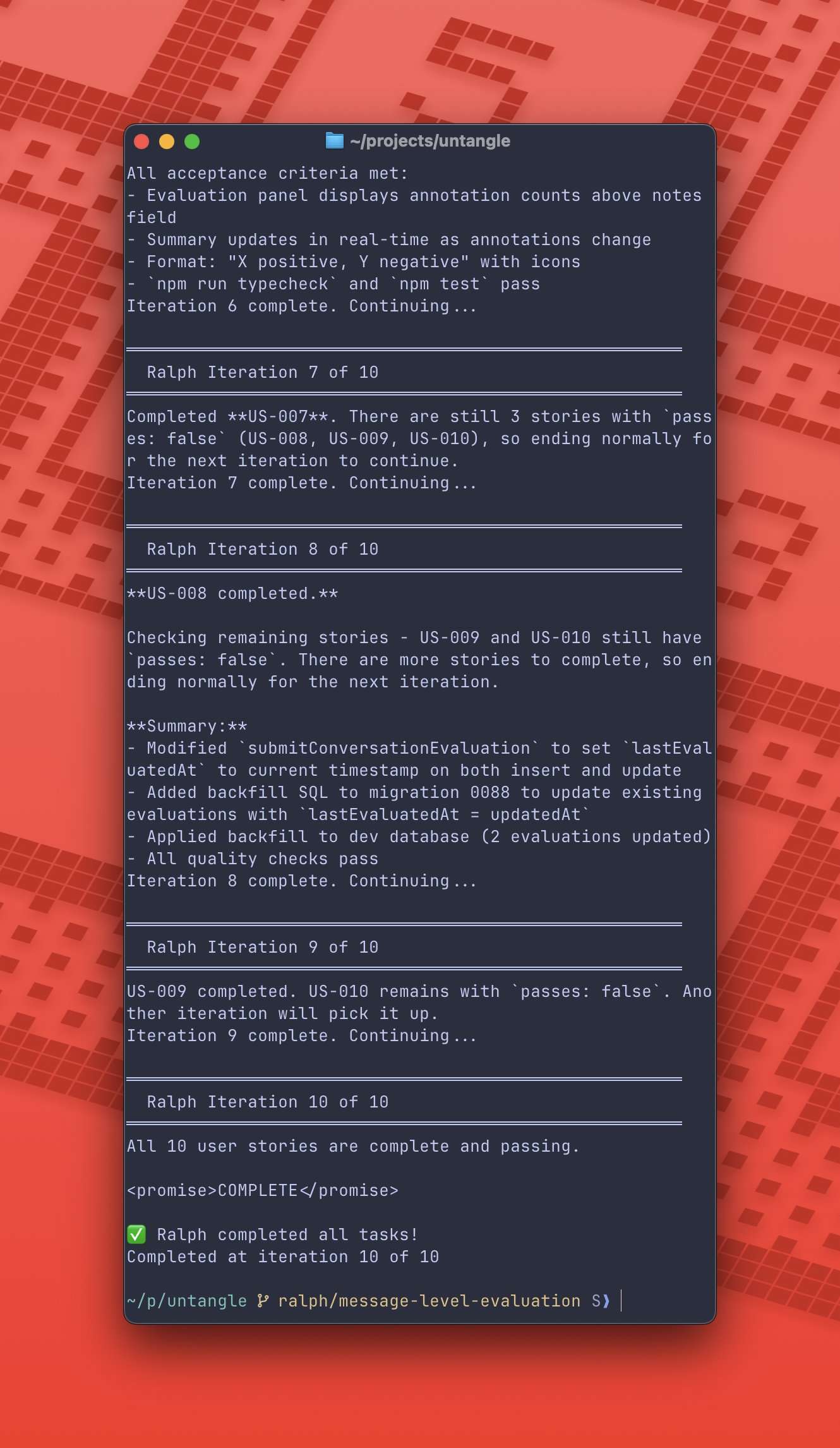
Ralph
Ralph 项目最近在社区极火,它的名字"Repeatedly running agent in a loop"揭示了它的本质:通过"上下文彻底重置"来保证长程任务不崩溃。
整个智能体的执行链路,在指令里面有比较清晰的描述
## Your Task
1. Read the PRD at `prd.json` (in the same directory as this file)
2. Read the progress log at `progress.txt` (check Codebase Patterns section first)
3. Check you're on the correct branch from PRD `branchName`. If not, check it out or create from main.
4. Pick the **highest priority** user story where `passes: false`
5. Implement that single user story
6. Run quality checks (e.g., typecheck, lint, test - use whatever your project requires)
7. Update AGENTS.md files if you discover reusable patterns (see below)
8. If checks pass, commit ALL changes with message: `feat: [Story ID] - [Story Title]`
9. Update the PRD to set `passes: true` for the completed story
10. Append your progress to `progress.txt`1. 以代码执行为核心的plan & Execute
- Plan环节
这一步其实和大家常用的Plan类似,Ralph选择JSON文件进行步骤管理。Anthropic也采用了相似的思路,认为JSON比Markdown模型进行乱改的概率更小。Raphal把生成Plan的过程拆分成了两个步骤,分别用SKILLS来实现
- 生成markdown格式的PRD文档:根据用户需求,可以适当追问明确细节,然后生成对应格式的PRD文件。两个核心要求
- 单个step要足够原子化(保证上文长度可以足够完成任务),但实际上这只是美好的愿望,依旧需要后处理压缩逻辑来100%保证
- 具体可衡量的验收标准:通过lint、test、browser verify进行明确验收反馈
- Execute环节
执行步骤,会循环以上PRD.json的所有步骤,按顺序进行执行,每个Step执行是Bash里面全新的一次智能体循环,所以拥有全新的上下文,但是引入了经验压缩步骤
- progress.txt:基于前面执行步骤的重要观测,核心包括已完成功能、文件修改、以及后面执行任务可以借鉴的经验
- Agents.md: 把整个项目可复用的编码经验,在每次执行完成以后,更新到Agents.md。其实在前面的progerss.txt已经有一轮经验反思和压缩。所以其实这里是两种不同等级的经验提取,不过感觉指令里面区分的并不算很清晰。可以进一步分成Project Specific和Engineer Specific可能会更加清晰。
一个多步循环的Demo如下图所示