Rank Mixer
- 主要是硬件效率优化,token mixer其实就是一个转置融合操作
- per token ffn
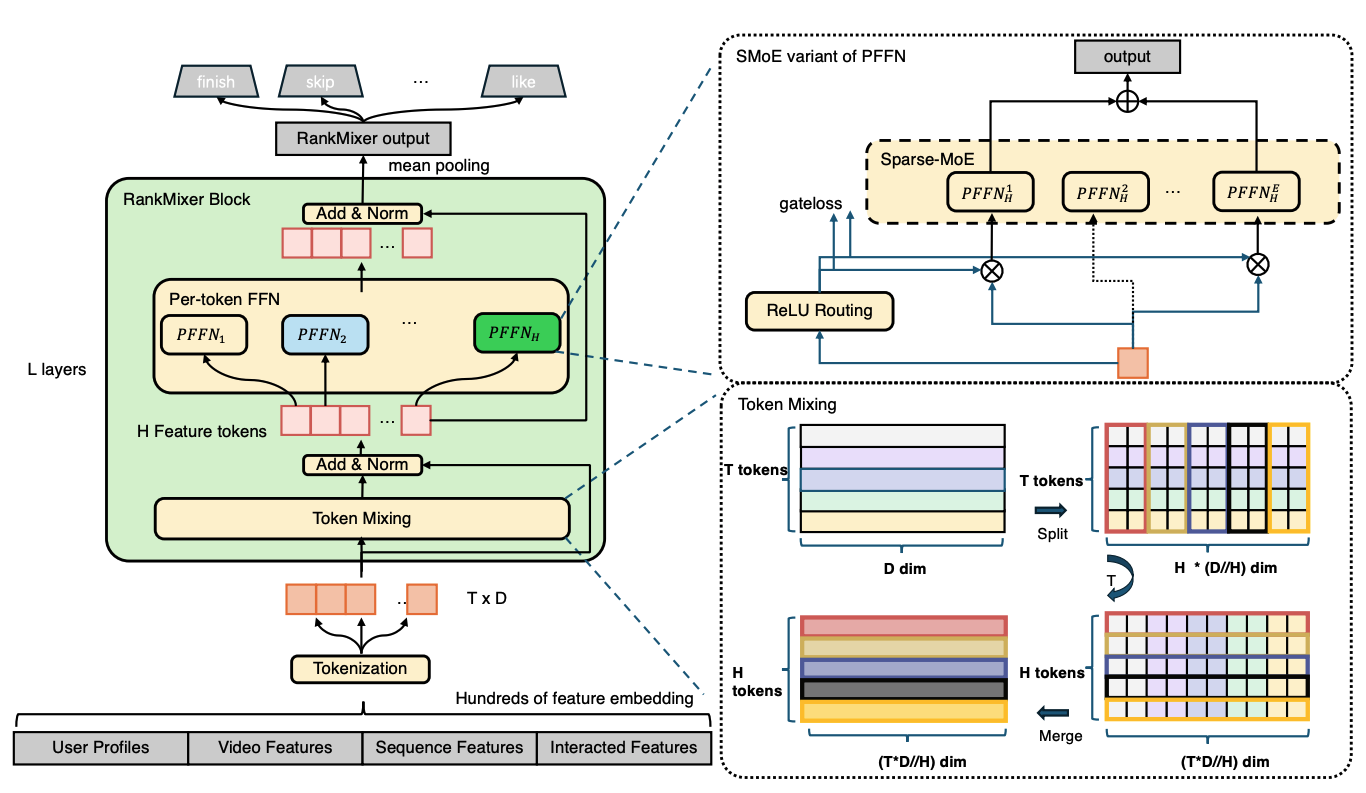
OneTrans
- 模型核心在于不断压缩序列提取核心信息,然后输出信息。
- sequence Feature共享参数,表示同质信息使用同样的参数
- non- sequence feature使用多组参数表示异质信息使用不同参数
模型结构
1. OneTrans Block (金字塔堆叠)
- 多个Block堆叠,每个Block逐步压缩序列长度(Lq递减)
- 每个Block包含:
- RMSNorm → Pyramid Mixed Causal Attention → 残差连接 → RMSNorm → Mixed FFN → 残差连接
2. 核心创新 - Pyramid Mixed Causal Attention (Eq.14)
- Q 从尾部集合获取(长度Lq)
- K/V 从完整序列获取(长度L)
- 输出 仅保留尾部(长度Lq)
- 应用因果掩码(Causal Mask)
3. 混合参数化 (Mixed Parameterization)
- 尾部token(min(L, LNS)):使用token-specific权重(WqNS, WkNS, WvNS)
- 前部token:使用共享权重(WqS, WkS, WvS)
4. 输出层
- Task Tower进行多任务预测(如CTR和CVR)
- 输出维度:
[B, n_task, D]
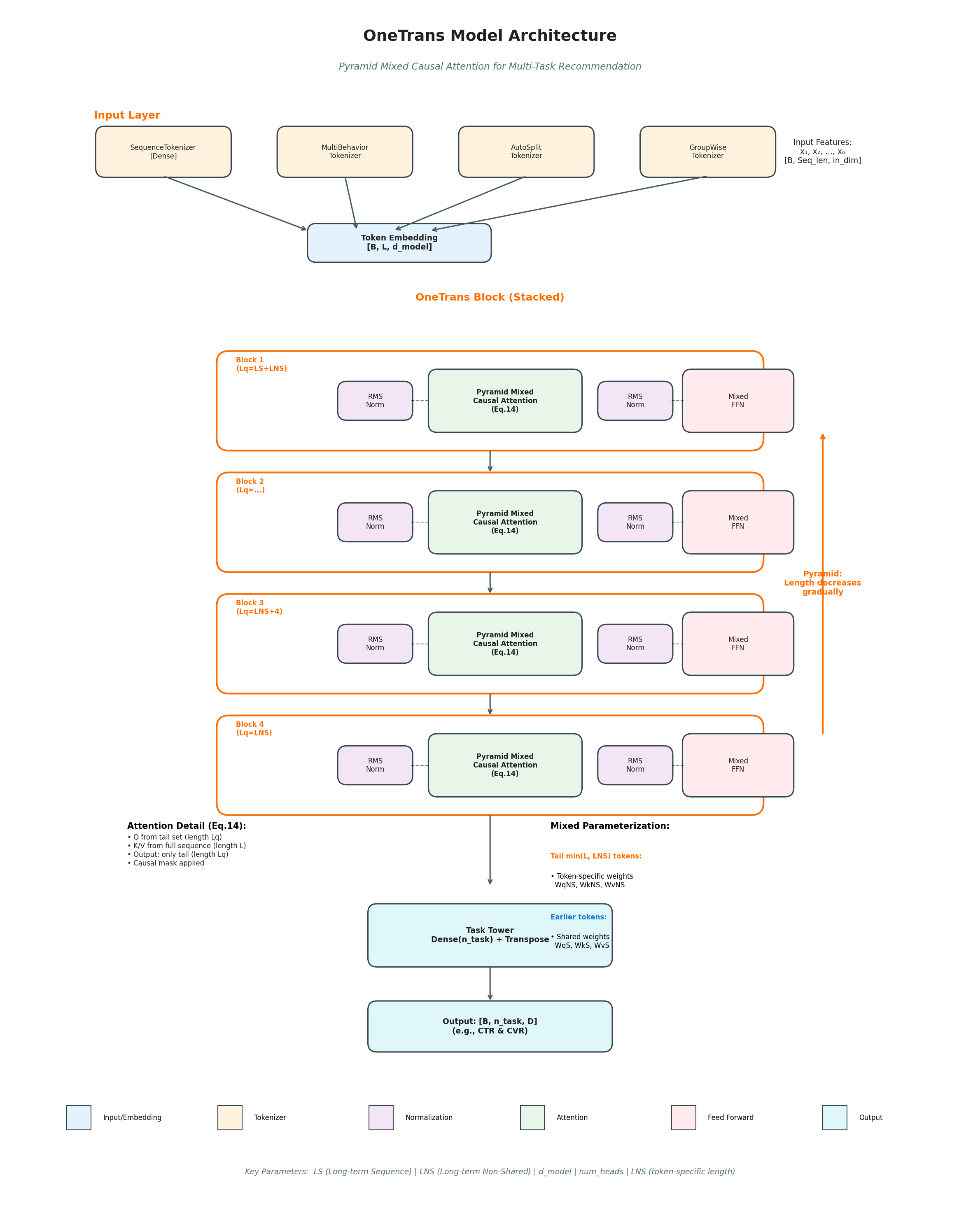
TokenMixer-Large
OneRec v1/v2
https://datawhalechina.github.io/fun-rec/chapter_7_gr_e2e/1.recommendation.html
OneSug
- 前缀-查询语义对齐
- 前缀表示增强(PRE 模块)
- 输入encoder进行编码得到encoder后的embedding
- 然后自回归生成
- 奖励加权排序策略,定义奖励层级,然后构造对比偏好对,DPO学习
EGA(广告竞价)
- 预训练:让模型回答:"给定用户的历史行为,他接下来可能对哪些 POI 和创意感兴趣?"
- 排列感知奖励模型,位置外部性(位置效应:同一个广告在位置 1 的 CTR 远高于位置 5,因为用户注意力随滚动衰减,相邻效应:如果位置 3 和位置 4 都是餐饮广告,用户可能只点击一个,导致两者相互抑制,对比效应:高质量广告后紧跟低质量广告,会导致后者 CTR 下降(对比鲜明))
- 第一阶段预训练拥有基本生成能力
- 第二阶段对齐业务目标
a. 奖励模型训练,ctr,cvr这些
b. pg优化生成概率,使得高奖励的 POI 获得更高的生成概率。
c. 支付网络优化,兼顾激励相容性, Lagrangian 对偶方法和ex-post regret近似保证
GPR(Generative Pre-trained Recommender)
- RQ-kmeans+生成sid,解决codebook collapse问题,rq-kmeans初始化,残差连接+端到端微调
- 阶段一:MTP 预训练------学习通用兴趣表示
- 阶段二:Value-Aware Fine-tuning------引入业务监督
- 阶段三:HEPO(Hierarchy Enhanced Policy Optimization)------层次化策略优化
前两个阶段通过监督学习建立了生成能力和价值预估能力,但模型的优化目标仍然是"拟合历史数据",而非"最大化业务收益"。第三阶段通过强化学习,让模型学会生成能够最大化平台收益的广告序列
LC-Rec
- Sinkhorn-Knopp算法求解码本分配概率降低索引冲突率
- 语义对齐训练
-- 序列物品预测
-- 索引到文本的映射
-- 基于意图的物品预测
PLUM
- 多分辨率码本
- 掩码重建任务
- 持续预训练进行语义对齐
OneRec-Think
- 加权融合替换简单embedding拼接
- 逐层内容描述生成
- 推理激活
- 推理增强
- Think-Ahead Architecture
RecZero/RecOne
- 纯强化学习推理探索
- 基于规则奖励建模
- RecOne用一些少量样本进行建模
DiffuASR
-
训练阶段:从原有数据集中选择长度大于 M 的序列,将前 M 个物品作为增强目标,其余作为 。这样可以利用真实的前序数据来监督扩散模型的学习。
-
增强阶段:对于每个用户序列,执行引导的反向去噪过程,生成前序 ,并与原序列拼接形成增强后的训练数据 。与其他序列增强方法相比,DiffuASR生成的序列可以直接用于训练任何序列推荐模型,无需修改模型架构,具有很强的通用性。
Diff-MSR
Diff-MSR包含以下四个阶段。
-
预训练阶段:使用所有场景的数据训练一个多场景推荐骨干模型(如MMoE),得到共享的嵌入层。这一步获取跨场景通用的特征表示。
-
扩散阶段:针对每个冷启动场景,分别训练两个扩散模型------一个用于正样本(点击),一个用于负样本(未点击)。输入是用户特征和物品属性的嵌入拼接 。这些扩散模型学习冷启动场景的数据分布。
-
分类阶段:训练一个二分类器,判断给定的(加噪)嵌入是来自冷启动场景还是数据丰富场景。关键操作是:对数据丰富场景的样本进行不同程度的加噪,然后用分类器判断。如果某个加噪样本被误判为冷启动场景,说明它的"轮廓"与冷启动场景相似,可以被利用。
-
微调阶段:
-- 使用三类数据微调冷启动场景的模型参数:
-- 从误分类的丰富场景加噪样本出发,用冷启动场景的扩散模型去噪得到的伪样本
-- 从纯高斯噪声出发生成的伪样本
-- 冷启动场景的真实数据
AsymDiffRec
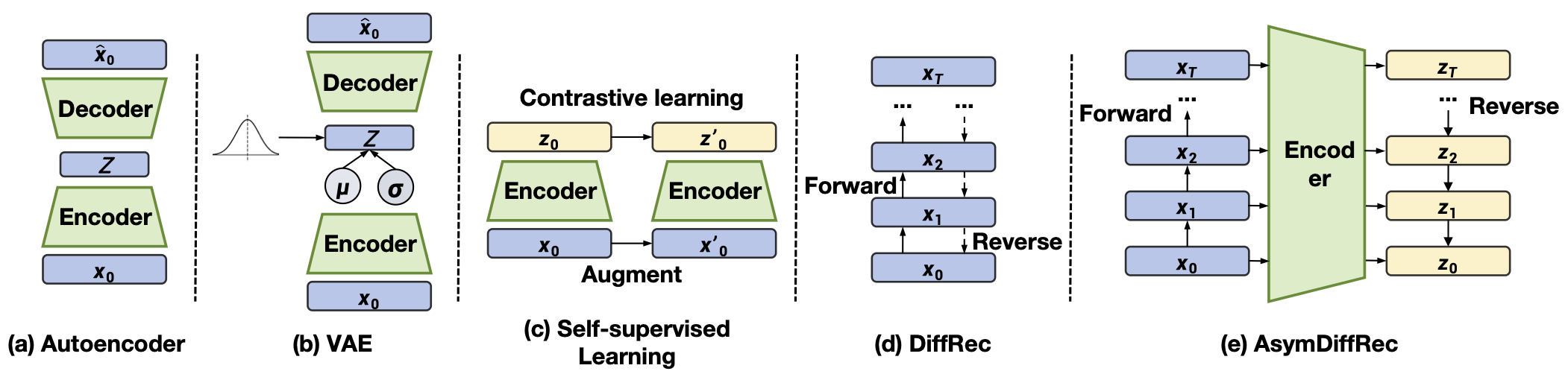

DMSG:多样性优化
- 预测速度
- DMSG则利用扩散模型的随机采样特性,在保证推荐相关性的同时提升了内容多样性和新鲜度。