目录
[1.1 基本语法](#1.1 基本语法)
[1.2 复杂更新示例](#1.2 复杂更新示例)
[2.1 DELETE 语句](#2.1 DELETE 语句)
[2.2 TRUNCATE 语句](#2.2 TRUNCATE 语句)
[2.3 DELETE 与 TRUNCATE 区别](#2.3 DELETE 与 TRUNCATE 区别)
[3.1 使用 DISTINCT](#3.1 使用 DISTINCT)
[3.2 实际去重方法](#3.2 实际去重方法)
[4.1 常用聚合函数](#4.1 常用聚合函数)
[4.2 使用示例](#4.2 使用示例)
[4.3 常见错误](#4.3 常见错误)
[5.1 基本分组](#5.1 基本分组)
[六、HAVING 筛选](#六、HAVING 筛选)
[6.1 基本用法](#6.1 基本用法)
[6.2 WHERE 与 HAVING 的区别](#6.2 WHERE 与 HAVING 的区别)
[6.3 综合示例](#6.3 综合示例)
[7.1 INSERT ... ON DUPLICATE KEY UPDATE](#7.1 INSERT ... ON DUPLICATE KEY UPDATE)
[7.2 REPLACE](#7.2 REPLACE)
[8.1 表达式查询](#8.1 表达式查询)
[8.2 别名 (AS)](#8.2 别名 (AS))
[8.3 WHERE 子句运算符](#8.3 WHERE 子句运算符)
[8.4 执行顺序问题](#8.4 执行顺序问题)
[8.5 排序 (ORDER BY)](#8.5 排序 (ORDER BY))
[8.6 分页显示 (LIMIT)](#8.6 分页显示 (LIMIT))
一、数据更新 (UPDATE)
1.1 基本语法
-- 将表中所有行的 name 改为 'a'
UPDATE t1 SET name = 'a';
-- 将 id 为 3 的行 name 改为 'b'
UPDATE t1 SET name = 'b' WHERE id = 3;1.2 复杂更新示例
需求:将成绩总分倒数前3名同学的数学分数加30分
UPDATE exam_result
SET math = math + 30
ORDER BY chinese + math + english ASC
LIMIT 3;说明 :
SET左侧为列名,右侧可以是表达式。
二、数据删除 (DELETE)
2.1 DELETE 语句
-- 删除名字为 'a' 的学生成绩记录
DELETE FROM exam_result WHERE name = 'a';特点 :使用 DELETE 删除带有 AUTO_INCREMENT 的表后,AUTO_INCREMENT 值不会重置。
-- 查看表结构,auto_increment 值未变
SHOW CREATE TABLE t2 \G;
2.2 TRUNCATE 语句
TRUNCATE TABLE t2;
特点 :删除 AUTO_INCREMENT 表后,计数器重置为 0。
2.3 DELETE 与 TRUNCATE 区别
| 特性 | DELETE | TRUNCATE |
|---|---|---|
| 日志记录 | 记录到日志 | 不记录日志 |
| 执行速度 | 慢 | 快 |
| 回滚能力 | 可以回滚 | 不能回滚 |
| 自增索引 | 不重置 | 重置 |
三、去重操作
3.1 使用 DISTINCT
SELECT DISTINCT * FROM t5;注意 :
DISTINCT仅用于查询显示,不会实际删除表中的重复数据。
3.2 实际去重方法
-- 1. 创建空表,插入去重数据
INSERT INTO t6 SELECT DISTINCT * FROM t5;
-- 2. 重命名表
RENAME TABLE t5 TO no;
RENAME TABLE t6 TO t5;四、聚合函数
4.1 常用聚合函数
| 函数 | 作用 |
|---|---|
| COUNT | 计数 |
| SUM | 求和 |
| AVG | 平均值 |
| MAX | 最大值 |
| MIN | 最小值 |
4.2 使用示例
-- 统计总行数
SELECT COUNT(*) FROM exam_result;
SELECT COUNT(1) FROM exam_result; -- 同样效果原理 :
SELECT 1 FROM exam_result会生成一列全为 1 的临时表,行数与exam_result相同。
-- 计算总成绩平均分
SELECT AVG(math + english + chinese) AS 平均分 FROM exam_result;4.3 常见错误
-- 错误示例:name 是多行,AVG 是单值,无法一起显示
SELECT name, AVG(math + english + chinese) AS 平均分 FROM exam_result; -- 报错
-- 正确:查找大于70分的最低数学分数
SELECT MIN(math) FROM exam_result WHERE math > 70;五、分组查询 (GROUP BY)
5.1 基本分组
需求:查询每个部门、每个工作的平均薪资和最高薪资
SELECT MAX(sal) AS 最高, AVG(sal) AS 平均
FROM emp
GROUP BY deptno, job;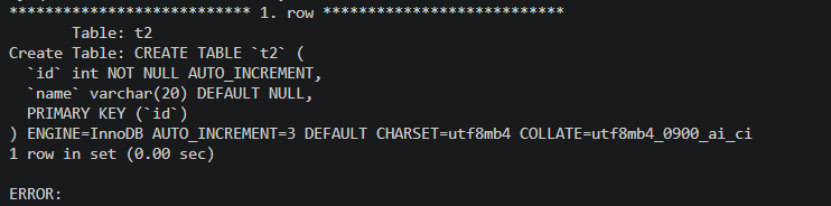
显示分组字段:
SELECT deptno, job, MAX(sal) AS 最高, AVG(sal) AS 平均
FROM emp
GROUP BY deptno, job;
注意 :
GROUP BY只使用了deptno和job两个属性,因此SELECT中只能直接显示这两个字段,其他字段会出现多对一问题。
六、HAVING 筛选
6.1 基本用法
需求:找出平均薪资小于 2000 的部门
-- 步骤1:统计各部门平均薪资
SELECT deptno, AVG(sal) AS 平均 FROM emp GROUP BY deptno;
-- 步骤2:筛选小于2000的部门
SELECT deptno, AVG(sal) AS 平均
FROM emp
GROUP BY deptno
HAVING 平均 < 2000;6.2 WHERE 与 HAVING 的区别
| 关键字 | 筛选时机 | 适用场景 |
|---|---|---|
| WHERE | 原始数据过滤(分组前) | 对原始行进行条件筛选 |
| HAVING | 结果过滤(分组后) | 对聚合结果进行条件筛选 |
6.3 综合示例
需求:员工 JONES 不参与统计,统计平均薪资小于 2000 的部门
SELECT deptno, job, MAX(sal) AS 最高, AVG(sal) AS 平均
FROM emp
WHERE ename != 'JONES' -- 1. 原始数据筛选
GROUP BY deptno, job -- 2. 分组
HAVING 平均 < 2000; -- 3. 结果筛选执行顺序:
-
FROM emp--- 选取表 -
WHERE ename != 'JONES'--- 原始数据筛选 -
GROUP BY--- 分组 -
AVG、SUM等 --- 聚合计算 -
HAVING--- 结果筛选
核心理念:MySQL 可以看作"一切皆表",每一个步骤的结果都可以视为一张表。
七、其他插入语法
7.1 INSERT ... ON DUPLICATE KEY UPDATE
当插入时遇到主键或唯一键重复,执行更新操作:
-- 如果 id=1 存在,则更新;否则插入
INSERT INTO t1 (id, name) VALUES (1, '2')
ON DUPLICATE KEY UPDATE id = 3, name = 'c';注意 :如果
id=3仍然重复,照样插入失败。
7.2 REPLACE
-- 有重复时替换,无重复时插入
REPLACE INTO t1 (id, name) VALUES (2, 'c');返回结果说明:
-
2 rows affected--- 有冲突,先删除后插入 -
1 row affected--- 无冲突,直接插入
八、查询详解 (SELECT)
8.1 表达式查询
SELECT 1 + 2; -- 可以查询表达式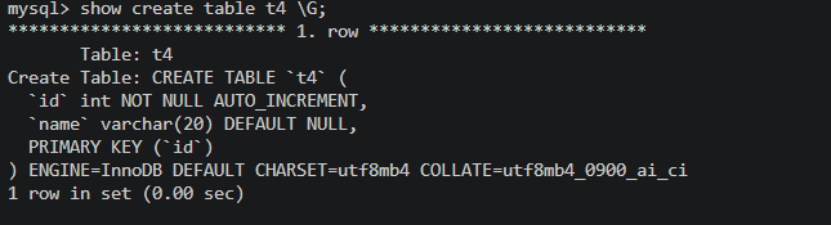
sql
-- 查询指定列
SELECT name, chinese FROM exam_result;
建议 :避免使用
SELECT *,因为数据库可能在远端服务器,数据量大时会消耗大量带宽。
8.2 别名 (AS)
SELECT chinese + math + english AS sum FROM exam_result;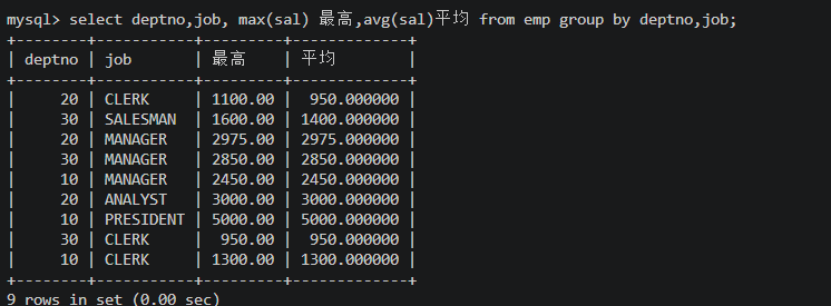
-- 配合 DISTINCT 去重
SELECT DISTINCT chinese + math + english AS sum FROM exam_result;8.3 WHERE 子句运算符
| 运算符 | 说明 |
|---|---|
= |
普通相等(NULL = NULL 返回 NULL) |
<=> |
安全相等(NULL <=> NULL 返回真) |
!= 或 <> |
不等于 |
BETWEEN a AND b |
区间 [a, b] |
IN (a0, a1, ...) |
值在列表中 |
AND / OR / NOT |
逻辑运算 |
LIKE |
模糊匹配(% 任意字符,_ 单个字符) |
使用示例:
-- 数学成绩接近满分(97,98,99)
SELECT name, math + chinese + english
FROM exam_result
WHERE math IN (97, 98, 99);
-- 姓孙的学生
SELECT name, math + chinese + english
FROM exam_result
WHERE name LIKE '孙%';
-- 姓孙且名字只有一个字
SELECT name, math + chinese + english
FROM exam_result
WHERE name LIKE '孙_';8.4 执行顺序问题
-- 错误示例:别名在 WHERE 中不可用
SELECT name, math + chinese + english AS sum
FROM exam_result
WHERE sum < 300; -- 报错!执行顺序 :FROM → WHERE → 重命名(AS)→ SELECT
因此
WHERE无法识别AS定义的别名,必须使用原始表达式。
-- 正确写法
SELECT name, math + chinese + english AS sum
FROM exam_result
WHERE math + chinese + english < 300;8.5 排序 (ORDER BY)
-- 多列排序(未指定时行为未定义,建议明确)
SELECT name, math, english, chinese
FROM exam_result
ORDER BY math DESC, english DESC, chinese DESC;
-- 使用别名排序(ORDER BY 优先级在别名之后)
SELECT name, math + english + chinese AS sum
FROM exam_result
ORDER BY sum DESC;-
DESC--- 降序 -
ASC--- 升序(默认)
8.6 分页显示 (LIMIT)
-- 显示前3行
SELECT name, math + english + chinese AS sum
FROM exam_result
ORDER BY sum DESC
LIMIT 3;
-- 从索引2(第3行)开始,显示3行
SELECT name, math + english + chinese AS sum
FROM exam_result
ORDER BY sum DESC
LIMIT 2, 3;优先级 :
LIMIT在所有数据处理完成后最后执行,属于"临门一脚"的显示操作。