文章目录
- 前言
- 一、Flink是什么?
-
- (一)基本概念
- (二)框架
- (三)Flink分层API
-
- 1.有状态流处理
- [2. DataStream API(流处理)和DataSet API(批处理)](#2. DataStream API(流处理)和DataSet API(批处理))
- [3. Table API](#3. Table API)
- 4.最高层语言SQL
- 二、有界流和无界流
- 二、Flink的发展历史
- 三、Flink的特点
- [四、Flink vs Spark Streaming](#四、Flink vs Spark Streaming)
-
- [(一) Spark以批处理为根本](#(一) Spark以批处理为根本)
- (二)Flink以流处理为根本
- 五、应用场景
- 总结
前言
随着分布式技术不断发展,工程师们正试图将这些技术推向极限。过去,人们在寻找更快、更便宜的数据处理方式。这一需求在Hadoop的引入中得到了满足。大家都开始用Hadoop,开始用Hadoop绑定的生态系统工具替换ETL。如今这一需求得到满足,Hadoop 已被许多公司用于生产环境,新的需求是以流式方式处理数据,催生了 Apache Spark 和 Flink 等技术。诸如快速处理引擎、快速扩展能力以及支持机器学习和图技术等功能正在开发者社区中推广这些技术。
一、Flink是什么?
(一)基本概念
- Apache Flink是一个用于处理无界和有界数据流 的分布式计算框架和引擎,可在所有常见的集群环境中运行,以内存速度 和任意规模进行运算。
- 核心目标:是"数据流上的有状态计算"(Stateful Computations over Data Streams)。
- Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
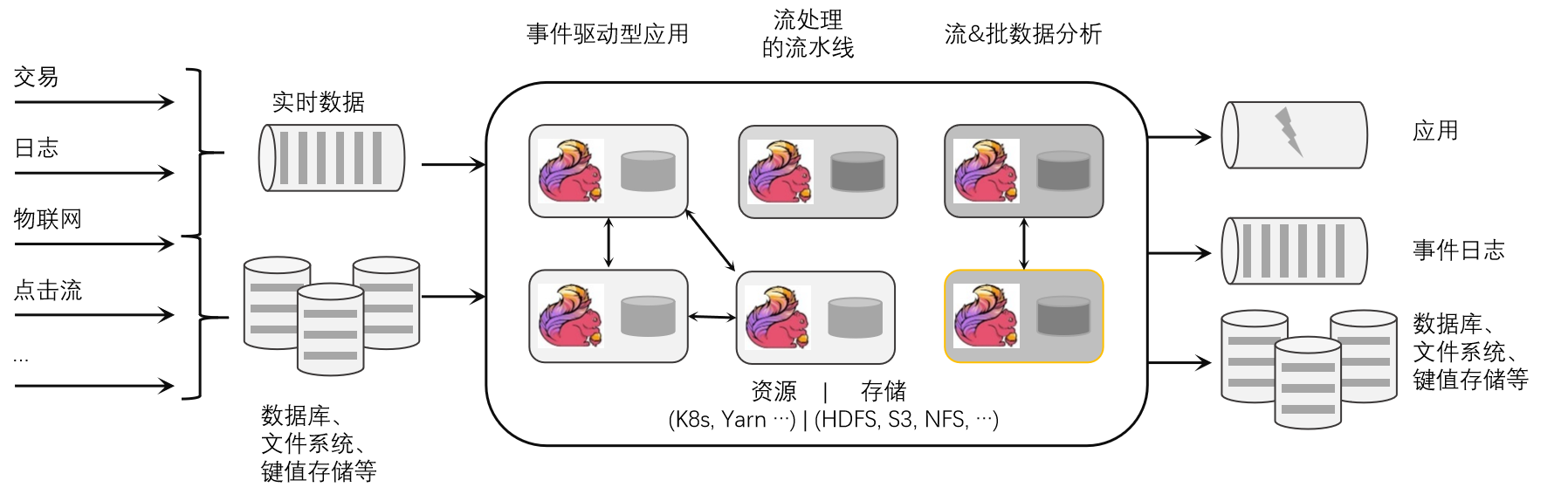
(二)框架
-
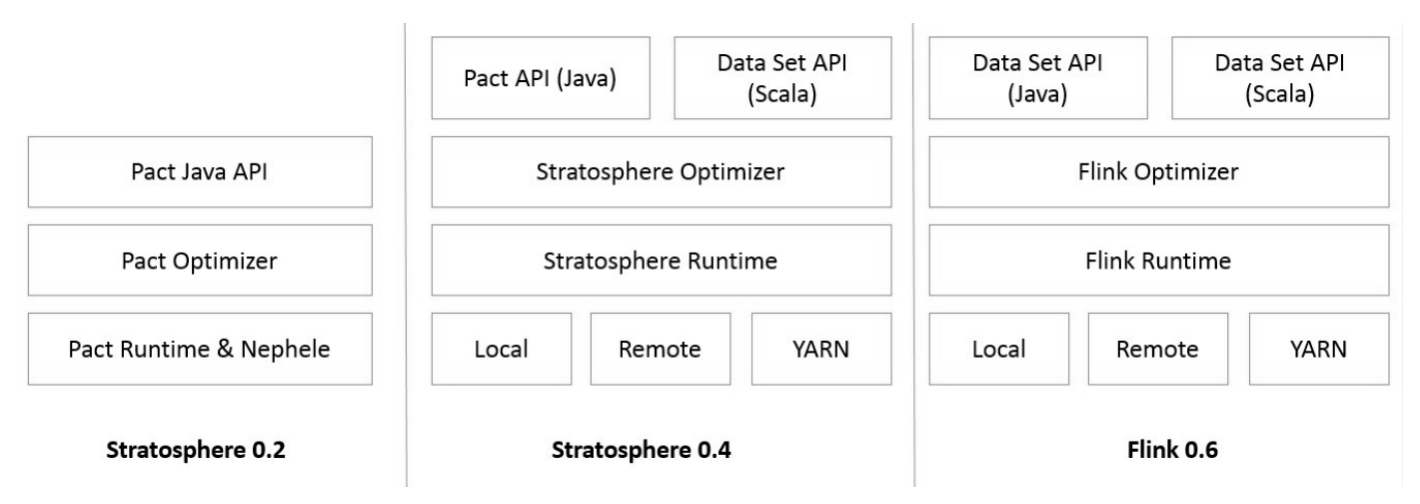
Flink 1.X 的架构由部署、核心处理和 API 等多个组件组成。我们可以很容易地将最新的架构与Stratosphere的架构进行比较,看到其演变。下图展示了组件、API 和库:
-
DataStream和DataSet API是程序员可以用来定义作业的接口。JobGgraph是在编译程序时由这些API生成的。编译后,DataSet API允许优化器生成最佳执行计划,而Datastream API使用流构建来实现高效的执行计划。
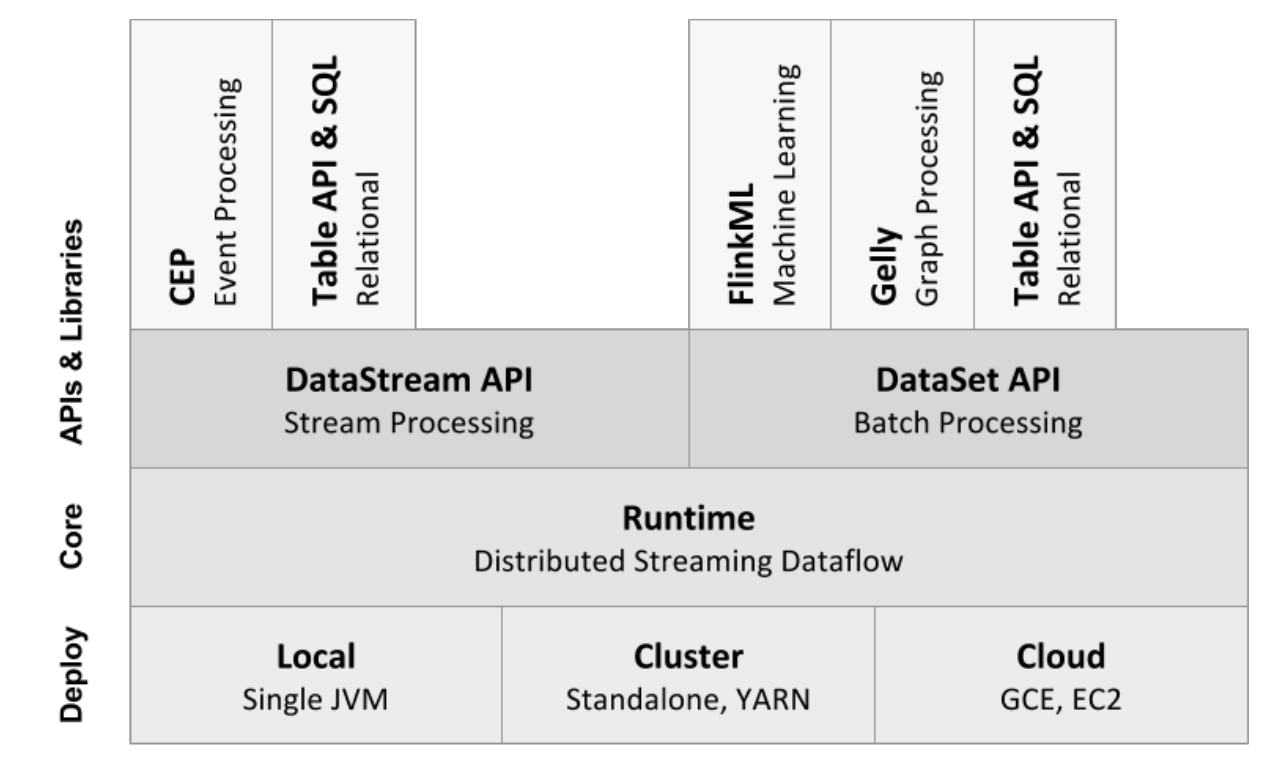
(三)Flink分层API
- 越顶层越抽象,表达含义越简明,使用越方便
- 越底层越具体,表达能力越丰富,使用越灵活
1.有状态流处理
- 通过底层API(处理函数),对最原始数据加工处理。底层API与DataStream API相集成,可以处理复杂的计算。
2. DataStream API(流处理)和DataSet API(批处理)
- 封装了底层处理函数,提供了通用的模块,比如转换(t
ransformations,包括map、flatmap等),连接(joins),聚合(aggregations),窗口(windows)操作等。注意:Flink1.12以后,DataStream API已经实现真正的流批一体,所以DataSet API已经过时。
3. Table API
- 是以表为中心的声明式编程 ,其中表可能会动态变化。Table API遵循关系模型:表有二维数据结构 ,类似于关系数据库中的表;同时API提供可比较的操作 ,例如:
select、project、join、group-by、aggregate等。我们可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
4.最高层语言SQL
- SQL这一层在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
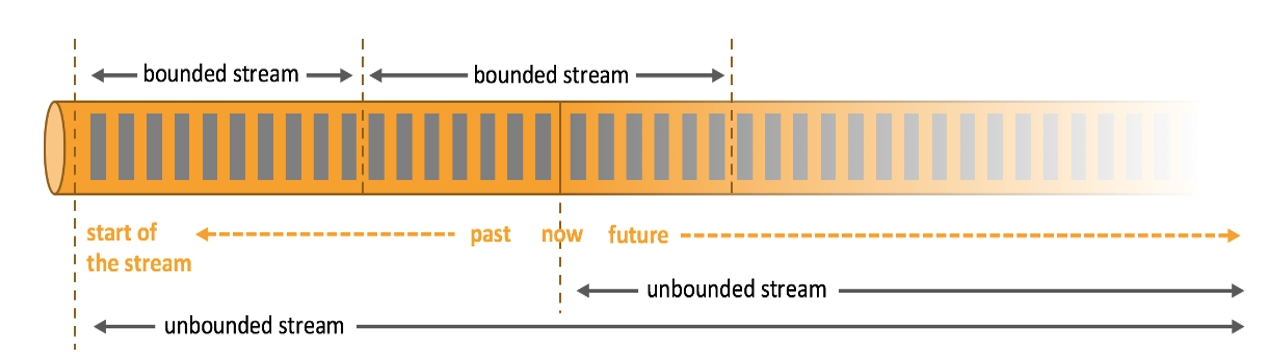
二、有界流和无界流
(一)有界数据流
1. 特点
- 也被称为批处理
2. 概念
- 1.有定义流的开始 ,也有定义流的结束;
- 2.有界流可以在摄取所有数据后再进行计算;
- 3.有界流所有数据可以被排序,所以并不需要有序摄取;
(二) 无界数据流
- 有定义流的开始,但没有定义流的结束;(== 仅有开始==)
- 无休止的产生数据
- 无界流的数据必须持续处理。即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的。
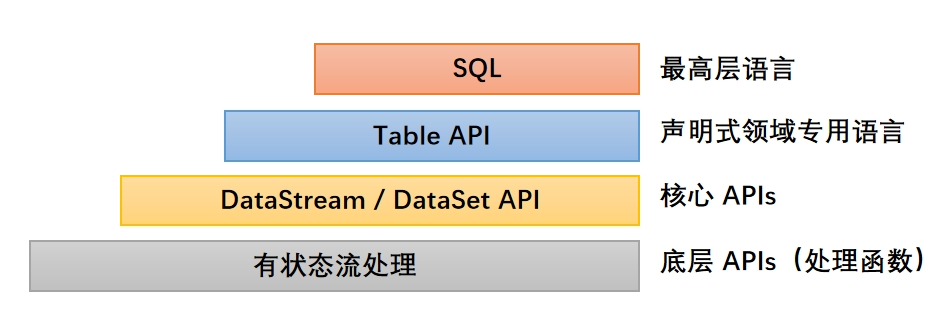
(三)有状态流处理
1.概念
把流处理需要的额外数据保存成一个"状态" ,然后针对这条数据进行处理,并且更新状态 。这就是所谓的"有状态的流处理"。
- 状态在内存中:优点,速度快;缺点,可靠性差。
- 状态在分布式系统中:优点,可靠性高;缺点,速度慢。
二、Flink的发展历史
- Flink起源于一个叫作Stratosphere的项目 ,它是由3所地处柏林的大学和欧洲其他一些大学在2010~2014年共同进行的研究项目,由柏林理工大学的教授
沃克尔·马尔科(Volker Markl)领衔开发。

- 2014年4月16日,Stratosphere的代码被复制并捐赠给了Apache软件基金会,Flink就是在此基础上被重新设计出来的。
-
2014年8月,Flink第一个版本0.6正式发布,自0.6版本起,Stratosphere更名为Flink,与此同时Fink的几位核心开发者创办Data Artisans公司;
-
2014年12月,Flink项目完成孵化
-
2015年4月,Flink发布了里程碑式的重要版本0.9.0;
-
2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artisans 公司;
-
2019年8月,阿里巴巴将内部版本Blink开源,合并入Flink 1.9.0版本。
三、Flink的特点
(一)处理数据的目标
低延迟、高吞吐 、结果的准确性 和良好的容错性。
(二)特点
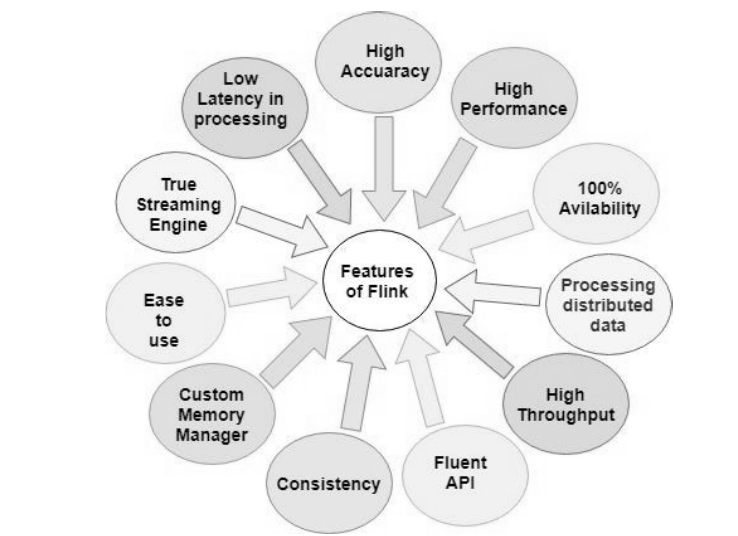
1.高吞吐和低延迟
每秒可以处理数百万个事件,毫秒级延迟
2.结果的准确性
Flink中提供了事件时间(event time)和处理时间(processing time)语义,对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
3.精确一次(exactly-once)
(exactly-once)的状态一致性保证
4.可以连接到最常用的外部系统
eg.Kafka,Hive,JDBC,HDFS,Redis等
5.高可用性
本身高可用的设置,加上与K8s,YARN和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7×24全天候运行。
6.内存管理
Flink 在 JVM 中提供了自己的内存管理功能,通过预分配内存存储序列化后的数据,并手动控制内存的分配与释放从而减少java对象的数量,显著降低GC的开销和停顿时间。
7.库资源
Flink拥有丰富的库,可用于机器学习、图处理、关系数据处理等。由于其架构,执行复杂的事件处理和警报非常容易。
四、Flink vs Spark Streaming
(一) Spark以批处理为根本
1.Spark数据模型
- Spark 采用 RDD 模型 ,Spark Streaming 的 DStream 实际上也就是一组组小批数据 RDD 的集合(
微小式批处理)
2.Spark运行时架构
- Spark 是批计算 ,将 DAG 划分为不同的 stage,一个完成后才可以计算下一个

(二)Flink以流处理为根本
- 1.Flink数据模型:Flink 基本数据模型是数据流 ,以及事件(Event) 序列
- 2.Flink运行时架构:Flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
| 属性 | Flink | Streaming |
|---|---|---|
| 计算模型 | 流计算 | 微批处理 |
| 时间语义 | 事件时间、处理时间 | 处理时间 |
| 窗口 | 多、灵活少 | 不灵活 (窗口必须是批次的整数倍) |
| 流式SQL | 有 | 没有 |
五、应用场景
Flink在国内各个企业中大量使用。一些行业中的典型应用有:
- 电商和市场营销:实时 数据报表、广告投放、实时推荐
- 物联网(IOT):传感器实时数据采集和显示、实时报警,交通运输业

-
物流配送和服务业:订单状态实时更新 、通知信息推送

-
银行和金融业:实时结算和通知推送,实时检测异常行为
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。