1. 引言:音视频处理的技术全景与商业价值
在数字媒体时代,视频内容承载着丰富的信息,但有时我们只需要其中的音频部分。从技术角度看,音视频分离不仅仅是一个简单的格式转换问题,它涉及数字信号处理、多媒体编码、文件格式解析、音频优化等多个专业领域。
1.1 技术应用场景全景

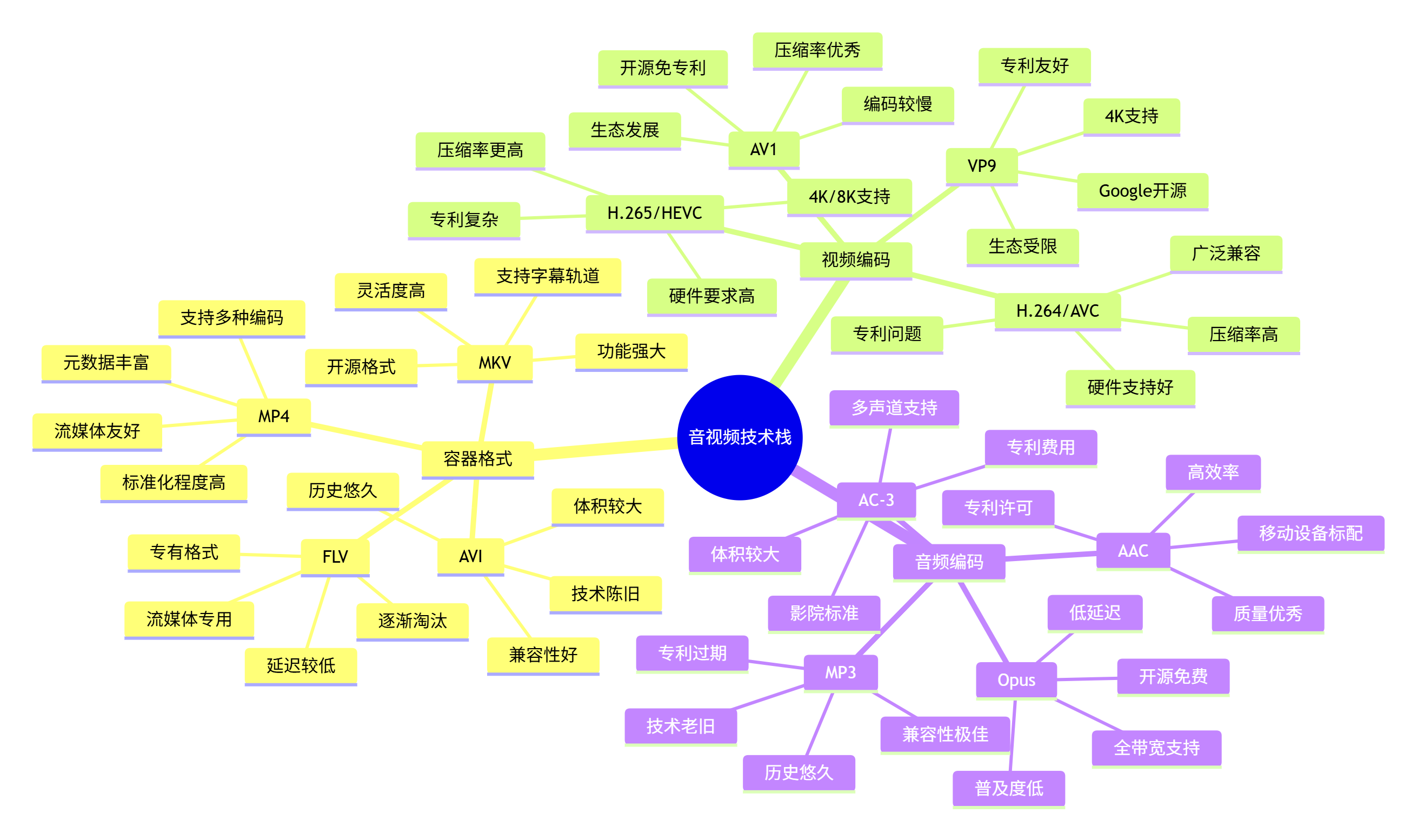
1.2 音视频容器与编码技术栈
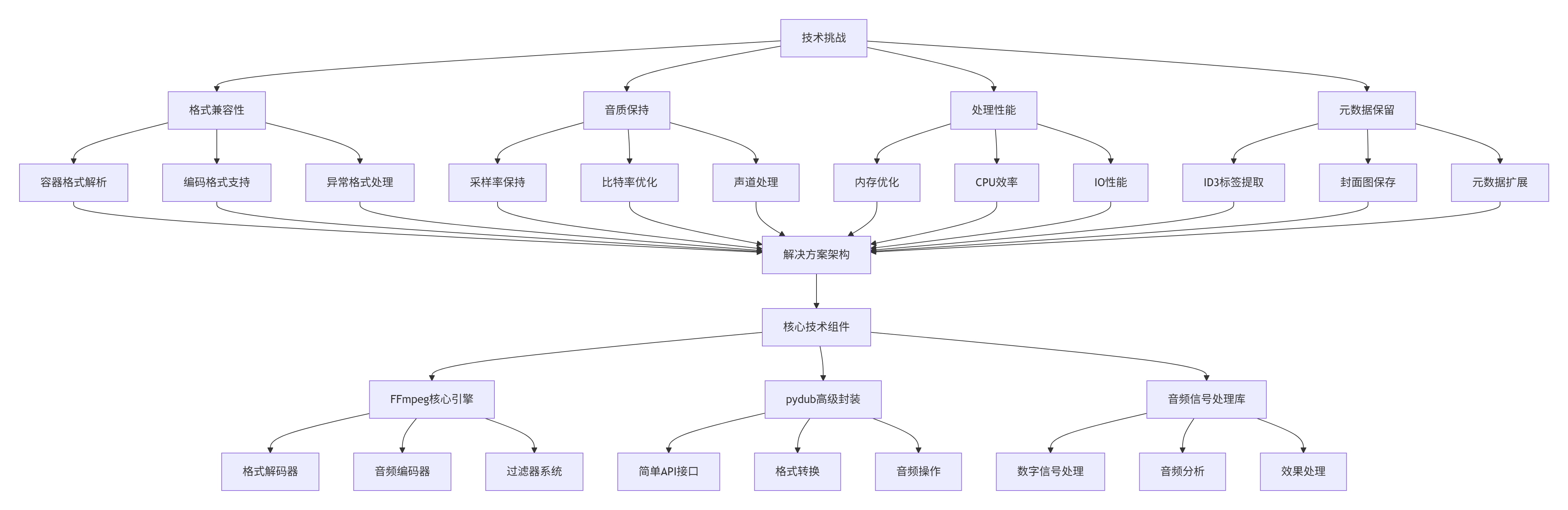
1.3 技术挑战与解决方案架构
从MP4视频中提取高质量音频面临的技术挑战是多层次的,我们的解决方案需要综合考虑技术实现、用户体验和法律合规:
2. 音视频处理技术深度剖析
2.1 MP4容器格式技术解析
MP4(MPEG-4 Part 14)是目前最流行的多媒体容器格式,理解其内部结构对于高效提取音频至关重要。
2.1.1 MP4文件结构详解
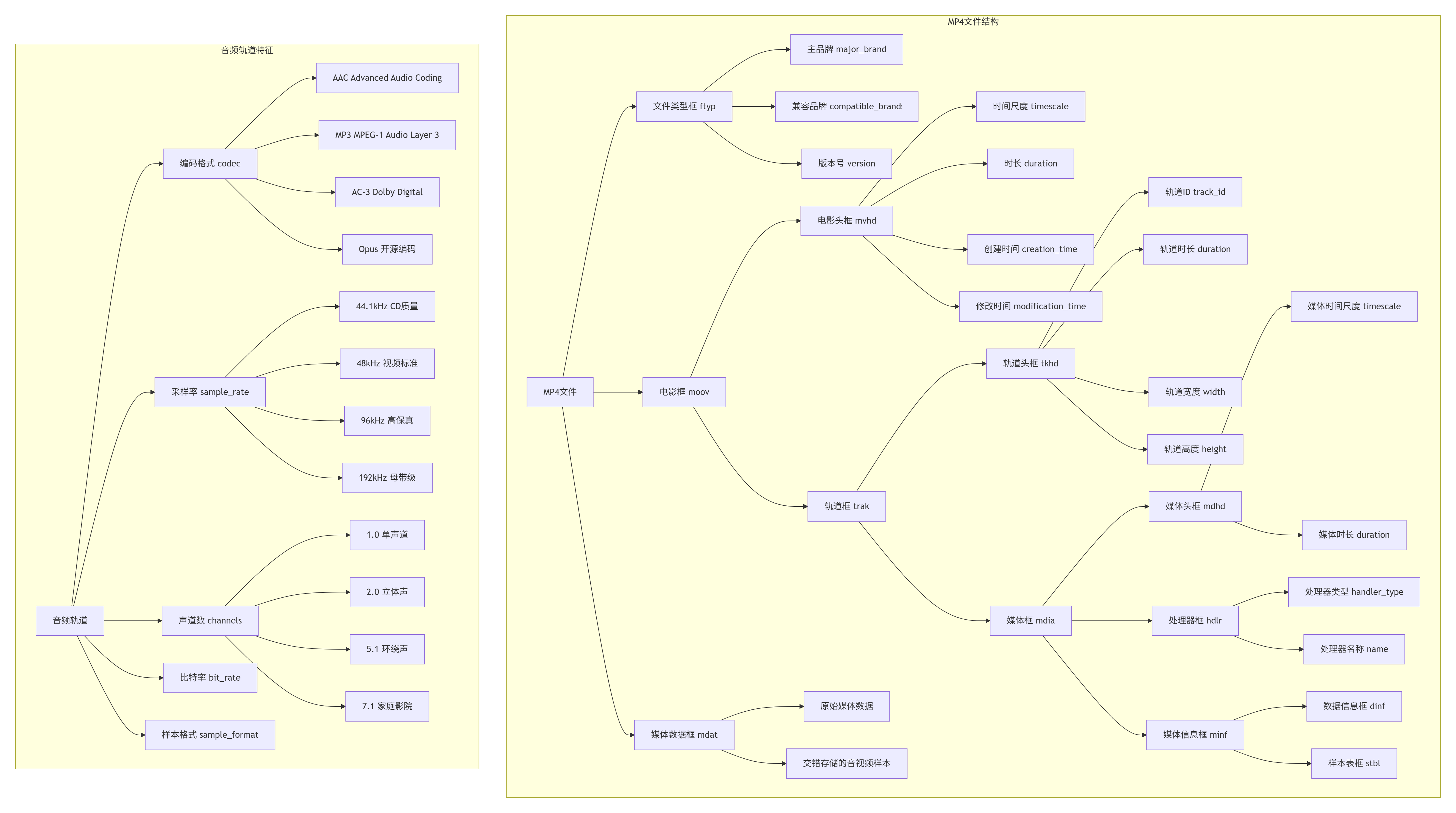
2.1.2 音频编码技术对比分析
python
"""
音频编码技术深度分析与性能对比
包含主流音频编码格式的技术特性和适用场景
"""
from dataclasses import dataclass, asdict
from enum import Enum, auto
from typing import Dict, List, Tuple, Optional
import json
import math
class AudioCodec(Enum):
"""音频编码格式枚举"""
AAC = "aac" # Advanced Audio Coding
MP3 = "mp3" # MPEG-1 Audio Layer 3
OPUS = "opus" # Opus Codec
VORBIS = "vorbis" # Ogg Vorbis
FLAC = "flac" # Free Lossless Audio Codec
ALAC = "alac" # Apple Lossless Audio Codec
WAV = "wav" # Waveform Audio File Format
PCM = "pcm" # Pulse-Code Modulation
class CompressionType(Enum):
"""压缩类型"""
LOSSY = "lossy" # 有损压缩
LOSSLESS = "lossless" # 无损压缩
UNCOMPRESSED = "uncompressed" # 未压缩
@dataclass
class CodecFeature:
"""编码器特性"""
psychoacoustic_model: bool # 是否使用心理声学模型
variable_bitrate: bool # 支持可变比特率
constant_bitrate: bool # 支持恒定比特率
multichannel: bool # 支持多声道
low_delay: bool # 低延迟支持
error_resilience: bool # 错误恢复能力
@dataclass
class AudioCodecProfile:
"""音频编码格式配置文件"""
codec: AudioCodec
compression: CompressionType
typical_bitrate: Tuple[int, int] # 典型比特率范围 (bps)
typical_samplerate: List[int] # 典型采样率
typical_channels: List[int] # 典型声道数
patent_status: str # 专利状态
open_source: bool # 是否开源
features: CodecFeature
file_extensions: List[str] # 文件扩展名
mime_types: List[str] # MIME类型
def get_quality_score(self, bitrate: int) -> float:
"""计算质量评分 (0-100)"""
if self.compression == CompressionType.LOSSLESS:
return 100.0
min_bitrate, max_bitrate = self.typical_bitrate
if bitrate <= min_bitrate:
quality = 60.0
elif bitrate >= max_bitrate:
quality = 95.0
else:
# 对数映射
quality = 60 + 35 * math.log10(bitrate / min_bitrate) / math.log10(max_bitrate / min_bitrate)
return min(quality, 100.0)
def get_compression_ratio(self) -> float:
"""获取压缩比估计"""
if self.compression == CompressionType.UNCOMPRESSED:
return 1.0
elif self.compression == CompressionType.LOSSLESS:
return 2.0 # 无损压缩通常约为2:1
else: # LOSSY
# 有损压缩比,基于典型比特率
pcm_bitrate = 1411200 # 44.1kHz, 16-bit, 立体声 PCM
avg_bitrate = sum(self.typical_bitrate) / 2
return pcm_bitrate / avg_bitrate
class AudioCodecAnalyzer:
"""音频编码分析器"""
def __init__(self):
self.profiles = self._initialize_profiles()
def _initialize_profiles(self) -> Dict[AudioCodec, AudioCodecProfile]:
"""初始化编码器配置文件"""
return {
AudioCodec.AAC: AudioCodecProfile(
codec=AudioCodec.AAC,
compression=CompressionType.LOSSY,
typical_bitrate=(64000, 320000), # 64-320 kbps
typical_samplerate=[8000, 11025, 12000, 16000, 22050, 24000, 32000, 44100, 48000],
typical_channels=[1, 2, 5.1, 7.1],
patent_status="Licensed, but widely supported",
open_source=False,
features=CodecFeature(
psychoacoustic_model=True,
variable_bitrate=True,
constant_bitrate=True,
multichannel=True,
low_delay=True,
error_resilience=True
),
file_extensions=[".aac", ".m4a", ".mp4"],
mime_types=["audio/aac", "audio/mp4", "audio/m4a"]
),
AudioCodec.MP3: AudioCodecProfile(
codec=AudioCodec.MP3,
compression=CompressionType.LOSSY,
typical_bitrate=(32000, 320000), # 32-320 kbps
typical_samplerate=[8000, 11025, 12000, 16000, 22050, 24000, 32000, 44100, 48000],
typical_channels=[1, 2],
patent_status="Patents expired, now freely usable",
open_source=True,
features=CodecFeature(
psychoacoustic_model=True,
variable_bitrate=True,
constant_bitrate=True,
multichannel=False,
low_delay=False,
error_resilience=False
),
file_extensions=[".mp3"],
mime_types=["audio/mpeg", "audio/mp3"]
),
AudioCodec.OPUS: AudioCodecProfile(
codec=AudioCodec.OPUS,
compression=CompressionType.LOSSY,
typical_bitrate=(6000, 510000), # 6-510 kbps
typical_samplerate=[8000, 12000, 16000, 24000, 48000],
typical_channels=[1, 2, 5.1, 7.1],
patent_status="Royalty-free, open standard",
open_source=True,
features=CodecFeature(
psychoacoustic_model=True,
variable_bitrate=True,
constant_bitrate=True,
multichannel=True,
low_delay=True,
error_resilience=True
),
file_extensions=[".opus"],
mime_types=["audio/opus"]
),
AudioCodec.FLAC: AudioCodecProfile(
codec=AudioCodec.FLAC,
compression=CompressionType.LOSSLESS,
typical_bitrate=(600000, 1000000), # 600-1000 kbps
typical_samplerate=[44100, 48000, 96000, 192000],
typical_channels=[1, 2, 5.1, 7.1],
patent_status="Open source, patent-free",
open_source=True,
features=CodecFeature(
psychoacoustic_model=False,
variable_bitrate=True,
constant_bitrate=False,
multichannel=True,
low_delay=False,
error_resilience=True
),
file_extensions=[".flac"],
mime_types=["audio/flac"]
),
AudioCodec.WAV: AudioCodecProfile(
codec=AudioCodec.WAV,
compression=CompressionType.UNCOMPRESSED,
typical_bitrate=(1411200, 4608000), # 44.1kHz-192kHz, 16-24bit
typical_samplerate=[44100, 48000, 96000, 192000],
typical_channels=[1, 2, 5.1, 7.1],
patent_status="Open standard, no patents",
open_source=True,
features=CodecFeature(
psychoacoustic_model=False,
variable_bitrate=False,
constant_bitrate=True,
multichannel=True,
low_delay=True,
error_resilience=False
),
file_extensions=[".wav"],
mime_types=["audio/wav", "audio/wave"]
)
}
def analyze_format_compatibility(self) -> Dict[str, List[str]]:
"""分析格式兼容性"""
compatibility = {
"universal": ["mp3", "wav"], # 几乎无处不在
"modern_web": ["aac", "opus", "mp3"], # 现代浏览器
"mobile_native": ["aac", "mp3", "flac"], # 移动设备原生支持
"high_quality": ["flac", "alac", "wav"], # 高质量音频
"streaming": ["aac", "opus"], # 流媒体服务常用
"open_source": ["opus", "flac", "vorbis"] # 开源生态
}
return compatibility
def calculate_file_size(self, duration_seconds: float,
codec: AudioCodec,
bitrate: int = 128000) -> float:
"""计算预估文件大小"""
# 基本公式: 文件大小(字节) = 比特率(bps) × 时长(秒) ÷ 8
base_size = (bitrate * duration_seconds) / 8
# 根据编码格式调整
profile = self.profiles.get(codec)
if profile:
if profile.compression == CompressionType.UNCOMPRESSED:
# WAV/PCM 有额外的头部信息
base_size *= 1.1
elif profile.compression == CompressionType.LOSSLESS:
# 无损压缩通常有更好的压缩率
base_size /= profile.get_compression_ratio()
return base_size # 字节
def recommend_codec(self, requirements: Dict) -> AudioCodecProfile:
"""根据需求推荐编码格式"""
requirements.setdefault("quality", "high")
requirements.setdefault("file_size", "medium")
requirements.setdefault("compatibility", "universal")
requirements.setdefault("open_source", False)
candidates = []
for codec, profile in self.profiles.items():
score = 0
# 质量要求匹配
if requirements["quality"] == "highest":
if profile.compression in [CompressionType.LOSSLESS, CompressionType.UNCOMPRESSED]:
score += 30
elif requirements["quality"] == "high":
if profile.codec in [AudioCodec.AAC, AudioCodec.OPUS, AudioCodec.FLAC]:
score += 20
elif requirements["quality"] == "medium":
score += 10
# 文件大小要求
if requirements["file_size"] == "small":
if profile.compression == CompressionType.LOSSY:
score += 20
elif requirements["file_size"] == "medium":
score += 10
# 兼容性要求
compatibility = self.analyze_format_compatibility()
if requirements["compatibility"] == "universal":
if profile.codec.value in compatibility["universal"]:
score += 25
elif requirements["compatibility"] == "modern":
if profile.codec.value in compatibility["modern_web"]:
score += 20
# 开源要求
if requirements["open_source"] and profile.open_source:
score += 15
candidates.append((score, profile))
# 返回得分最高的
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
def generate_comparison_table(self) -> str:
"""生成编码器对比表格(Markdown格式)"""
table = "| 编码格式 | 压缩类型 | 比特率范围 | 采样率 | 声道 | 开源 | 质量评分 |\n"
table += "|----------|----------|------------|--------|------|------|----------|\n"
for codec, profile in self.profiles.items():
min_rate, max_rate = profile.typical_bitrate
bitrate_range = f"{min_rate//1000}-{max_rate//1000} kbps"
samplerate_str = f"{min(profile.typical_samplerate)//1000}-{max(profile.typical_samplerate)//1000}kHz"
channels = "/".join([str(int(c)) if isinstance(c, float) and c.is_integer() else str(c)
for c in profile.typical_channels])
quality = profile.get_quality_score(max_rate)
table += f"| {codec.value.upper()} | {profile.compression.value} | {bitrate_range} | {samplerate_str} | {channels} | {'✓' if profile.open_source else '✗'} | {quality:.1f} |\n"
return table
# 使用示例
if __name__ == "__main__":
analyzer = AudioCodecAnalyzer()
print("音频编码格式对比分析")
print("=" * 80)
print(analyzer.generate_comparison_table())
print("\n格式兼容性分析:")
compatibility = analyzer.analyze_format_compatibility()
for category, formats in compatibility.items():
print(f" {category}: {', '.join(formats)}")
print("\n编码器推荐示例:")
requirements = {
"quality": "high",
"file_size": "medium",
"compatibility": "universal",
"open_source": True
}
recommended = analyzer.recommend_codec(requirements)
print(f" 推荐格式: {recommended.codec.value.upper()}")
print(f" 压缩类型: {recommended.compression.value}")
print(f" 文件扩展名: {', '.join(recommended.file_extensions)}")
# 计算文件大小
duration = 300 # 5分钟
filesize = analyzer.calculate_file_size(duration, AudioCodec.AAC, 256000)
print(f"\n5分钟AAC音频(256kbps)预估大小: {filesize/1024/1024:.2f} MB")2.2 音频信号处理基础理论
2.2.1 数字音频处理流程
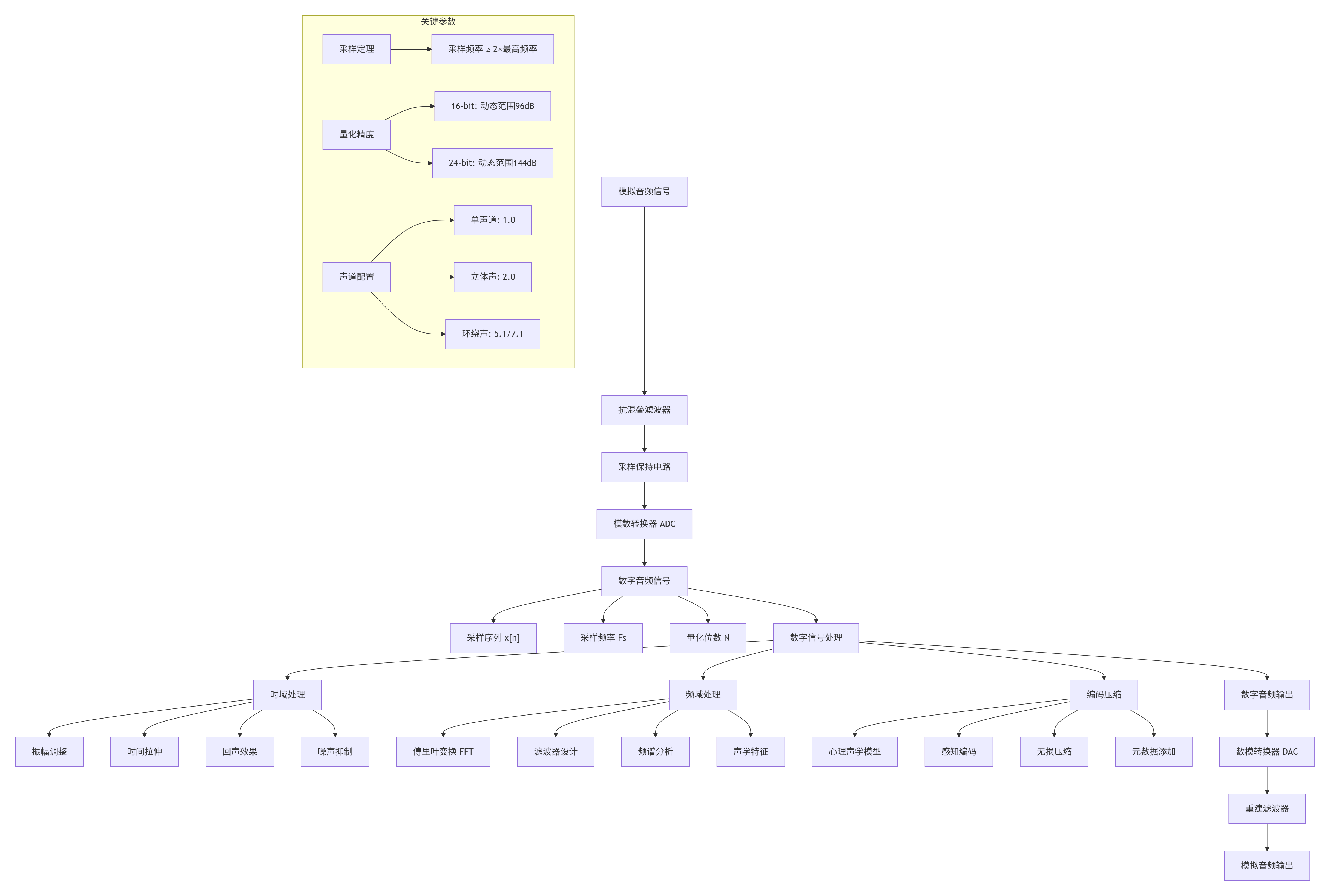
2.2.2 心理声学模型与有损压缩
有损音频压缩的核心是心理声学模型,它基于人耳听觉特性去除听觉冗余信息。
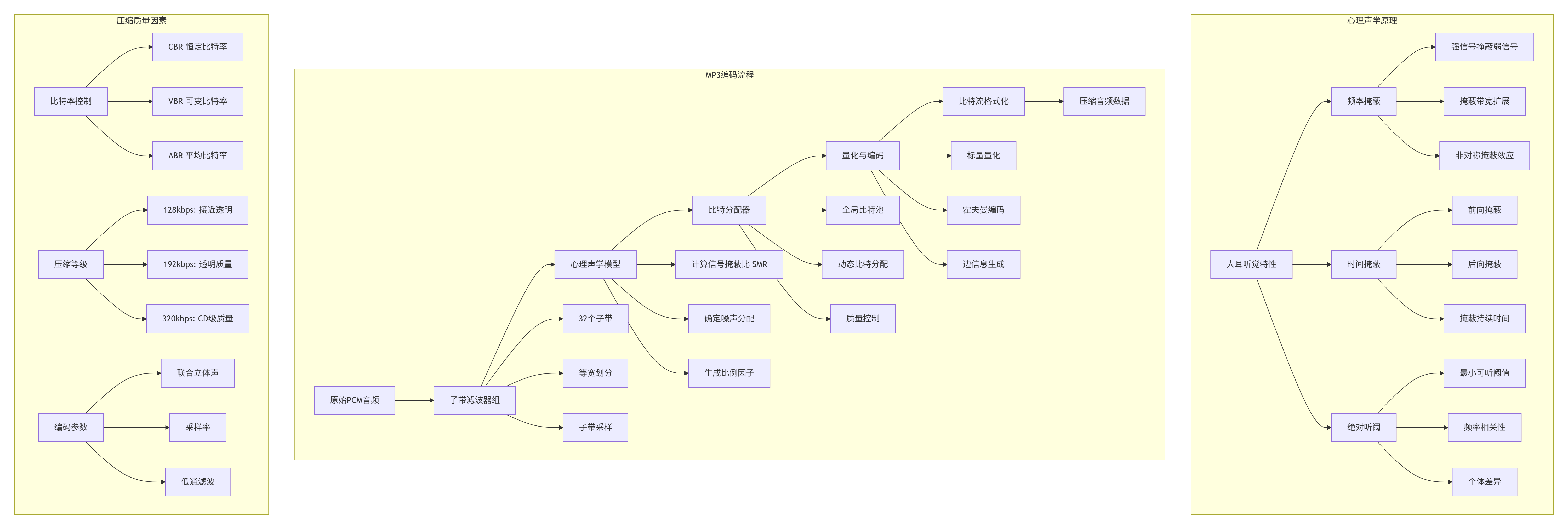
3. 完整实现:MP4音频提取与处理系统
3.1 单文件完整实现
python
#!/usr/bin/env python3
"""
MP4音频提取与处理系统
单文件完整实现,支持多种音频格式和高级处理功能
"""
import os
import sys
import re
import json
import time
import math
import wave
import struct
import hashlib
import random
import asyncio
import aiofiles
import argparse
import subprocess
import tempfile
import mimetypes
import threading
import concurrent.futures
from typing import Dict, List, Tuple, Optional, Any, Union, BinaryIO
from dataclasses import dataclass, asdict, field
from enum import Enum, auto
from pathlib import Path
from datetime import datetime, timedelta
from collections import defaultdict, deque
import logging
import traceback
import warnings
# 第三方库导入检查
try:
import numpy as np
NUMPY_AVAILABLE = True
except ImportError:
NUMPY_AVAILABLE = False
warnings.warn("numpy not available, some advanced features disabled")
try:
from pydub import AudioSegment
from pydub.effects import normalize, compress_dynamic_range
from pydub.silence import detect_silence, split_on_silence
PYDUB_AVAILABLE = True
except ImportError:
PYDUB_AVAILABLE = False
warnings.warn("pydub not available, advanced audio processing disabled")
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('audio_extractor.log', encoding='utf-8'),
logging.StreamHandler(sys.stdout)
]
)
logger = logging.getLogger(__name__)
# 常量定义
class AudioFormat(Enum):
"""音频输出格式枚举"""
MP3 = "mp3"
WAV = "wav"
FLAC = "flac"
AAC = "aac"
OGG = "ogg"
M4A = "m4a"
OPUS = "opus"
class AudioQuality(Enum):
"""音频质量预设"""
LOW = "low" # 低质量,小文件
MEDIUM = "medium" # 中等质量
HIGH = "high" # 高质量
LOSSLESS = "lossless" # 无损质量
class ChannelLayout(Enum):
"""声道布局"""
MONO = "mono" # 单声道
STEREO = "stereo" # 立体声
SURROUND_5_1 = "5.1" # 5.1环绕声
SURROUND_7_1 = "7.1" # 7.1环绕声
@dataclass
class AudioMetadata:
"""音频元数据"""
title: str = ""
artist: str = ""
album: str = ""
year: int = 0
genre: str = ""
track_number: int = 0
composer: str = ""
comments: str = ""
duration: float = 0.0
bitrate: int = 0
samplerate: int = 0
channels: int = 0
format: str = ""
def to_dict(self) -> Dict:
"""转换为字典"""
return asdict(self)
def to_id3_dict(self) -> Dict:
"""转换为ID3标签字典"""
return {
'title': self.title,
'artist': self.artist,
'album': self.album,
'date': str(self.year) if self.year else '',
'genre': self.genre,
'track': str(self.track_number) if self.track_number else '',
'composer': self.composer,
'comment': self.comments
}
@dataclass
class AudioStats:
"""音频统计信息"""
duration_seconds: float = 0.0
file_size_bytes: int = 0
bitrate_kbps: float = 0.0
sample_rate_hz: int = 0
channels: int = 0
bits_per_sample: int = 0
format: str = ""
def calculate_dynamic_range(self) -> float:
"""计算动态范围(dB)"""
if self.bits_per_sample > 0:
return 6.02 * self.bits_per_sample + 1.76
return 0.0
def calculate_data_rate(self) -> float:
"""计算数据率(字节/秒)"""
return self.sample_rate_hz * self.channels * self.bits_per_sample / 8
def to_human_readable(self) -> Dict:
"""转换为可读格式"""
return {
'duration': str(timedelta(seconds=int(self.duration_seconds))),
'file_size': self._format_size(self.file_size_bytes),
'bitrate': f"{self.bitrate_kbps:.1f} kbps",
'sample_rate': f"{self.sample_rate_hz / 1000:.1f} kHz",
'channels': f"{self.channels} channels",
'bit_depth': f"{self.bits_per_sample}-bit",
'data_rate': f"{self.calculate_data_rate() / 1024:.1f} KB/s"
}
@staticmethod
def _format_size(size_bytes: int) -> str:
"""格式化文件大小"""
for unit in ['B', 'KB', 'MB', 'GB']:
if size_bytes < 1024.0:
return f"{size_bytes:.2f} {unit}"
size_bytes /= 1024.0
return f"{size_bytes:.2f} TB"
class AudioExtractor:
"""音频提取器主类"""
# 格式映射
FORMAT_EXTENSIONS = {
AudioFormat.MP3: '.mp3',
AudioFormat.WAV: '.wav',
AudioFormat.FLAC: '.flac',
AudioFormat.AAC: '.m4a',
AudioFormat.OGG: '.ogg',
AudioFormat.M4A: '.m4a',
AudioFormat.OPUS: '.opus'
}
# 质量预设
QUALITY_PRESETS = {
AudioQuality.LOW: {
'mp3': {'bitrate': '128k', 'vbr': False},
'aac': {'bitrate': '96k', 'profile': 'aac_low'},
'opus': {'bitrate': '64k', 'complexity': 5},
'flac': {'compression': 0}
},
AudioQuality.MEDIUM: {
'mp3': {'bitrate': '192k', 'vbr': True},
'aac': {'bitrate': '128k', 'profile': 'aac_he'},
'opus': {'bitrate': '96k', 'complexity': 8},
'flac': {'compression': 5}
},
AudioQuality.HIGH: {
'mp3': {'bitrate': '320k', 'vbr': True},
'aac': {'bitrate': '256k', 'profile': 'aac_he_v2'},
'opus': {'bitrate': '128k', 'complexity': 10},
'flac': {'compression': 8}
},
AudioQuality.LOSSLESS: {
'flac': {'compression': 12},
'wav': {}
}
}
def __init__(self,
ffmpeg_path: str = None,
ffprobe_path: str = None,
output_dir: str = "./audio_output",
temp_dir: str = None,
max_concurrent: int = 3,
keep_temp_files: bool = False):
# 路径设置
self.ffmpeg_path = ffmpeg_path or self._find_ffmpeg()
self.ffprobe_path = ffprobe_path or self._find_ffprobe()
self.output_dir = Path(output_dir)
self.output_dir.mkdir(parents=True, exist_ok=True)
# 临时目录
self.temp_dir = Path(temp_dir) if temp_dir else Path(tempfile.gettempdir()) / "audio_extract"
self.temp_dir.mkdir(parents=True, exist_ok=True)
# 配置
self.max_concurrent = max_concurrent
self.keep_temp_files = keep_temp_files
# 状态
self.processing_tasks = {}
self.completed_tasks = {}
self.failed_tasks = {}
# 统计
self.stats = {
'total_processed': 0,
'total_success': 0,
'total_failed': 0,
'total_size': 0,
'start_time': None
}
# 线程池
self.executor = concurrent.futures.ThreadPoolExecutor(max_workers=max_concurrent)
# 验证依赖
self._verify_dependencies()
def _find_ffmpeg(self) -> str:
"""查找FFmpeg可执行文件"""
# 检查常见位置
possible_paths = [
'ffmpeg',
'ffmpeg.exe',
'/usr/bin/ffmpeg',
'/usr/local/bin/ffmpeg',
'C:/ffmpeg/bin/ffmpeg.exe'
]
for path in possible_paths:
try:
result = subprocess.run([path, '-version'],
capture_output=True,
text=True)
if result.returncode == 0:
return path
except (FileNotFoundError, PermissionError):
continue
raise RuntimeError("FFmpeg not found. Please install FFmpeg and ensure it's in PATH.")
def _find_ffprobe(self) -> str:
"""查找FFprobe可执行文件"""
possible_paths = [
'ffprobe',
'ffprobe.exe',
'/usr/bin/ffprobe',
'/usr/local/bin/ffprobe',
'C:/ffmpeg/bin/ffprobe.exe'
]
for path in possible_paths:
try:
result = subprocess.run([path, '-version'],
capture_output=True,
text=True)
if result.returncode == 0:
return path
except (FileNotFoundError, PermissionError):
continue
# 如果找不到ffprobe,尝试使用ffmpeg
logger.warning("FFprobe not found, using FFmpeg for metadata extraction")
return self.ffmpeg_path
def _verify_dependencies(self):
"""验证依赖"""
# 检查FFmpeg
try:
result = subprocess.run([self.ffmpeg_path, '-version'],
capture_output=True,
text=True)
if result.returncode != 0:
raise RuntimeError(f"FFmpeg check failed: {result.stderr}")
version_match = re.search(r'ffmpeg version (\S+)', result.stdout)
if version_match:
logger.info(f"FFmpeg version: {version_match.group(1)}")
except Exception as e:
raise RuntimeError(f"Failed to verify FFmpeg: {e}")
# 检查pydub
if not PYDUB_AVAILABLE:
logger.warning("pydub not available, advanced audio processing disabled")
# 检查numpy
if not NUMPY_AVAILABLE:
logger.warning("numpy not available, some analysis features disabled")
def get_media_info(self, input_path: Path) -> Dict:
"""获取媒体文件信息"""
try:
cmd = [
self.ffprobe_path,
'-v', 'quiet',
'-print_format', 'json',
'-show_format',
'-show_streams',
str(input_path)
]
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode != 0:
raise RuntimeError(f"FFprobe error: {result.stderr}")
info = json.loads(result.stdout)
return info
except Exception as e:
logger.error(f"Failed to get media info: {e}")
raise
def extract_audio_info(self, input_path: Path) -> Dict:
"""提取音频流信息"""
media_info = self.get_media_info(input_path)
audio_streams = []
video_streams = []
for stream in media_info.get('streams', []):
if stream.get('codec_type') == 'audio':
audio_streams.append(stream)
elif stream.get('codec_type') == 'video':
video_streams.append(stream)
format_info = media_info.get('format', {})
return {
'format': format_info,
'audio_streams': audio_streams,
'video_streams': video_streams,
'duration': float(format_info.get('duration', 0)),
'size': int(format_info.get('size', 0)),
'bit_rate': int(format_info.get('bit_rate', 0))
}
def extract_audio(self,
input_path: Path,
output_format: AudioFormat = AudioFormat.MP3,
quality: AudioQuality = AudioQuality.HIGH,
output_filename: str = None,
metadata: AudioMetadata = None,
start_time: float = None,
end_time: float = None,
channels: ChannelLayout = ChannelLayout.STEREO) -> Optional[Path]:
"""提取音频主函数"""
if not input_path.exists():
logger.error(f"Input file not found: {input_path}")
return None
# 获取媒体信息
logger.info(f"Analyzing media file: {input_path}")
try:
media_info = self.extract_audio_info(input_path)
except Exception as e:
logger.error(f"Failed to analyze media file: {e}")
return None
if not media_info['audio_streams']:
logger.error("No audio stream found in the media file")
return None
# 选择音频流
audio_stream = self._select_audio_stream(media_info['audio_streams'])
logger.info(f"Selected audio stream: {audio_stream.get('codec_name', 'unknown')}")
# 生成输出路径
if not output_filename:
base_name = input_path.stem
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_filename = f"{base_name}_{timestamp}"
output_path = self._generate_output_path(
output_filename,
output_format,
metadata
)
# 构建FFmpeg命令
ffmpeg_cmd = self._build_ffmpeg_command(
input_path=input_path,
output_path=output_path,
audio_stream=audio_stream,
output_format=output_format,
quality=quality,
metadata=metadata,
start_time=start_time,
end_time=end_time,
channels=channels
)
logger.info(f"Starting audio extraction: {input_path.name} -> {output_path.name}")
logger.debug(f"FFmpeg command: {' '.join(ffmpeg_cmd)}")
# 执行提取
task_id = f"{input_path.stem}_{int(time.time())}"
self.processing_tasks[task_id] = {
'input': input_path,
'output': output_path,
'start_time': time.time(),
'status': 'processing'
}
try:
result = subprocess.run(
ffmpeg_cmd,
capture_output=True,
text=True,
check=True
)
# 验证输出文件
if not output_path.exists() or output_path.stat().st_size == 0:
raise RuntimeError("Output file is empty or not created")
# 更新元数据
if metadata:
self._update_metadata(output_path, metadata)
# 计算统计信息
audio_stats = self._calculate_audio_stats(output_path)
# 记录成功
self.processing_tasks[task_id]['status'] = 'completed'
self.processing_tasks[task_id]['end_time'] = time.time()
self.processing_tasks[task_id]['stats'] = audio_stats
self.completed_tasks[task_id] = self.processing_tasks[task_id]
del self.processing_tasks[task_id]
self.stats['total_success'] += 1
self.stats['total_processed'] += 1
logger.info(f"✓ Audio extraction completed: {output_path.name}")
logger.info(f" Duration: {audio_stats.duration_seconds:.1f}s, Size: {audio_stats.file_size_bytes/1024/1024:.1f}MB")
return output_path
except subprocess.CalledProcessError as e:
logger.error(f"FFmpeg process failed: {e}")
logger.error(f"FFmpeg stderr: {e.stderr}")
self.processing_tasks[task_id]['status'] = 'failed'
self.processing_tasks[task_id]['error'] = str(e)
self.processing_tasks[task_id]['end_time'] = time.time()
self.failed_tasks[task_id] = self.processing_tasks[task_id]
del self.processing_tasks[task_id]
self.stats['total_failed'] += 1
self.stats['total_processed'] += 1
return None
except Exception as e:
logger.error(f"Audio extraction failed: {e}")
self.processing_tasks[task_id]['status'] = 'failed'
self.processing_tasks[task_id]['error'] = str(e)
self.processing_tasks[task_id]['end_time'] = time.time()
self.failed_tasks[task_id] = self.processing_tasks[task_id]
del self.processing_tasks[task_id]
self.stats['total_failed'] += 1
self.stats['total_processed'] += 1
return None
def _select_audio_stream(self, audio_streams: List[Dict]) -> Dict:
"""选择最佳的音频流"""
if not audio_streams:
raise ValueError("No audio streams available")
# 评分系统
best_stream = None
best_score = -1
for stream in audio_streams:
score = 0
# 编解码器评分
codec = stream.get('codec_name', '').lower()
if codec in ['aac', 'flac', 'alac', 'opus']:
score += 30
elif codec in ['mp3', 'ac3', 'dts']:
score += 20
elif codec in ['pcm', 'wav']:
score += 25
# 比特率评分
bit_rate = int(stream.get('bit_rate', 0))
if bit_rate > 256000:
score += 25
elif bit_rate > 128000:
score += 20
elif bit_rate > 64000:
score += 15
# 采样率评分
sample_rate = int(stream.get('sample_rate', 0))
if sample_rate >= 48000:
score += 20
elif sample_rate >= 44100:
score += 15
elif sample_rate >= 22050:
score += 10
# 声道数评分
channels = int(stream.get('channels', 0))
if channels >= 6:
score += 15
elif channels >= 2:
score += 10
else:
score += 5
# 选择最高分的流
if score > best_score:
best_score = score
best_stream = stream
return best_stream
def _generate_output_path(self,
base_name: str,
output_format: AudioFormat,
metadata: AudioMetadata = None) -> Path:
"""生成输出文件路径"""
# 清理文件名
safe_name = self._sanitize_filename(base_name)
# 添加元数据信息
if metadata and metadata.artist and metadata.title:
filename = f"{metadata.artist} - {metadata.title}"
else:
filename = safe_name
# 添加格式扩展名
extension = self.FORMAT_EXTENSIONS[output_format]
filename = f"{filename}{extension}"
# 确保文件名唯一
output_path = self.output_dir / filename
counter = 1
while output_path.exists():
new_name = f"{safe_name}_{counter}{extension}"
output_path = self.output_dir / new_name
counter += 1
return output_path
def _sanitize_filename(self, filename: str) -> str:
"""清理文件名,移除非法字符"""
# Windows和Unix都不允许的字符
illegal_chars = r'[<>:"/\\|?*]'
# 替换为下划线
sanitized = re.sub(illegal_chars, '_', filename)
# 限制长度
if len(sanitized) > 200:
sanitized = sanitized[:200]
return sanitized
def _build_ffmpeg_command(self,
input_path: Path,
output_path: Path,
audio_stream: Dict,
output_format: AudioFormat,
quality: AudioQuality,
metadata: AudioMetadata = None,
start_time: float = None,
end_time: float = None,
channels: ChannelLayout = ChannelLayout.STEREO) -> List[str]:
"""构建FFmpeg命令"""
cmd = [self.ffmpeg_path, '-y', '-hide_banner', '-loglevel', 'info']
# 输入文件
cmd.extend(['-i', str(input_path)])
# 时间范围
if start_time is not None:
cmd.extend(['-ss', str(start_time)])
if end_time is not None:
cmd.extend(['-to', str(end_time)])
# 选择音频流
cmd.extend(['-map', '0:a:0']) # 选择第一个音频流
# 声道处理
if channels == ChannelLayout.MONO:
cmd.extend(['-ac', '1'])
elif channels == ChannelLayout.STEREO:
cmd.extend(['-ac', '2'])
# 5.1和7.1需要特殊处理
# 根据格式和质量设置编码参数
format_str = output_format.value
quality_preset = self.QUALITY_PRESETS[quality].get(format_str, {})
cmd.extend(self._get_codec_params(format_str, quality_preset))
# 元数据
if metadata:
metadata_dict = metadata.to_id3_dict()
for key, value in metadata_dict.items():
if value:
cmd.extend(['-metadata', f'{key}={value}'])
# 输出文件
cmd.append(str(output_path))
return cmd
def _get_codec_params(self, format_str: str, quality_preset: Dict) -> List[str]:
"""获取编码器参数"""
params = []
if format_str == 'mp3':
params.extend(['-c:a', 'libmp3lame'])
if quality_preset.get('vbr', True):
# VBR模式
bitrate = quality_preset.get('bitrate', '192k')
if bitrate.endswith('k'):
bitrate_value = int(bitrate[:-1])
if bitrate_value >= 256:
params.extend(['-q:a', '0']) # 最高质量
elif bitrate_value >= 192:
params.extend(['-q:a', '2'])
elif bitrate_value >= 128:
params.extend(['-q:a', '4'])
else:
params.extend(['-q:a', '7'])
else:
# CBR模式
params.extend(['-b:a', quality_preset.get('bitrate', '192k')])
params.extend(['-id3v2_version', '3']) # ID3v2.3标签
elif format_str == 'flac':
params.extend(['-c:a', 'flac'])
compression = quality_preset.get('compression', 5)
params.extend(['-compression_level', str(compression)])
elif format_str in ['aac', 'm4a']:
params.extend(['-c:a', 'aac'])
params.extend(['-b:a', quality_preset.get('bitrate', '128k')])
profile = quality_preset.get('profile', 'aac_he')
if profile == 'aac_he':
params.extend(['-profile:a', 'aac_he'])
elif profile == 'aac_he_v2':
params.extend(['-profile:a', 'aac_he_v2'])
elif format_str == 'opus':
params.extend(['-c:a', 'libopus'])
params.extend(['-b:a', quality_preset.get('bitrate', '96k')])
complexity = quality_preset.get('complexity', 10)
params.extend(['-compression_level', str(complexity)])
elif format_str == 'ogg':
params.extend(['-c:a', 'libvorbis'])
params.extend(['-q:a', '5']) # VBR质量 0-10
elif format_str == 'wav':
params.extend(['-c:a', 'pcm_s16le']) # 16-bit PCM
return params
def _update_metadata(self, audio_path: Path, metadata: AudioMetadata):
"""更新音频文件元数据"""
if not PYDUB_AVAILABLE:
logger.warning("pydub not available, cannot update metadata")
return
try:
audio = AudioSegment.from_file(str(audio_path))
# 这里可以添加自定义元数据处理
# 注意:pydub的元数据支持有限
# 保存时可能会丢失一些格式特性
# 更好的方法是使用专门的库如mutagen
logger.info(f"Metadata would be updated for: {audio_path.name}")
except Exception as e:
logger.warning(f"Failed to update metadata: {e}")
def _calculate_audio_stats(self, audio_path: Path) -> AudioStats:
"""计算音频统计信息"""
try:
if PYDUB_AVAILABLE:
audio = AudioSegment.from_file(str(audio_path))
return AudioStats(
duration_seconds=len(audio) / 1000.0, # pydub使用毫秒
file_size_bytes=audio_path.stat().st_size,
bitrate_kbps=(audio_path.stat().st_size * 8) / (len(audio) / 1000.0) / 1000,
sample_rate_hz=audio.frame_rate,
channels=audio.channels,
bits_per_sample=audio.sample_width * 8,
format=audio_path.suffix[1:].upper()
)
else:
# 使用FFprobe获取信息
info = self.get_media_info(audio_path)
format_info = info.get('format', {})
stream_info = info.get('streams', [{}])[0]
return AudioStats(
duration_seconds=float(format_info.get('duration', 0)),
file_size_bytes=int(format_info.get('size', 0)),
bitrate_kbps=int(format_info.get('bit_rate', 0)) / 1000,
sample_rate_hz=int(stream_info.get('sample_rate', 0)),
channels=int(stream_info.get('channels', 0)),
bits_per_sample=int(stream_info.get('bits_per_sample', 0)),
format=audio_path.suffix[1:].upper()
)
except Exception as e:
logger.warning(f"Failed to calculate audio stats: {e}")
return AudioStats()
async def batch_extract(self,
input_files: List[Path],
output_format: AudioFormat = AudioFormat.MP3,
quality: AudioQuality = AudioQuality.HIGH) -> Dict:
"""批量提取音频"""
self.stats['start_time'] = time.time()
tasks = []
results = {
'success': [],
'failed': [],
'total': len(input_files)
}
logger.info(f"Starting batch extraction of {len(input_files)} files")
# 创建异步任务
for input_file in input_files:
task = asyncio.create_task(
self._async_extract_audio(
input_file, output_format, quality
)
)
tasks.append((input_file, task))
# 等待所有任务完成
for input_file, task in tasks:
try:
result = await task
if result:
results['success'].append(result)
logger.info(f"✓ Completed: {input_file.name}")
else:
results['failed'].append(str(input_file))
logger.error(f"✗ Failed: {input_file.name}")
except Exception as e:
results['failed'].append(str(input_file))
logger.error(f"✗ Error processing {input_file.name}: {e}")
# 统计
elapsed = time.time() - self.stats['start_time']
results['elapsed_time'] = elapsed
results['success_rate'] = len(results['success']) / len(input_files) if input_files else 0
logger.info(f"Batch extraction completed in {elapsed:.1f}s")
logger.info(f"Success: {len(results['success'])}/{len(input_files)} "
f"({results['success_rate']:.1%})")
return results
async def _async_extract_audio(self,
input_path: Path,
output_format: AudioFormat,
quality: AudioQuality) -> Optional[Path]:
"""异步提取音频"""
loop = asyncio.get_event_loop()
try:
# 在线程池中运行阻塞操作
result = await loop.run_in_executor(
self.executor,
lambda: self.extract_audio(
input_path=input_path,
output_format=output_format,
quality=quality
)
)
return result
except Exception as e:
logger.error(f"Async extraction failed for {input_path.name}: {e}")
return None
def analyze_audio_quality(self, audio_path: Path) -> Dict:
"""分析音频质量"""
if not PYDUB_AVAILABLE or not NUMPY_AVAILABLE:
logger.warning("pydub or numpy not available, quality analysis disabled")
return {}
try:
audio = AudioSegment.from_file(str(audio_path))
# 转换为numpy数组进行分析
samples = np.array(audio.get_array_of_samples())
if audio.channels == 2:
# 分离左右声道
left_channel = samples[0::2]
right_channel = samples[1::2]
mono_samples = (left_channel + right_channel) / 2
else:
mono_samples = samples
# 计算统计指标
max_amplitude = np.max(np.abs(mono_samples))
rms = np.sqrt(np.mean(mono_samples**2))
dynamic_range = 20 * math.log10(max_amplitude / (rms + 1e-10))
# 频谱分析
fft_size = 2048
if len(mono_samples) > fft_size:
segment = mono_samples[:fft_size]
spectrum = np.abs(np.fft.rfft(segment))
frequencies = np.fft.rfftfreq(len(segment), 1/audio.frame_rate)
# 找到主要频率成分
peak_freq = frequencies[np.argmax(spectrum)]
else:
peak_freq = 0
quality_metrics = {
'max_amplitude': float(max_amplitude),
'rms_amplitude': float(rms),
'dynamic_range_db': float(dynamic_range),
'peak_frequency_hz': float(peak_freq),
'sample_rate_hz': audio.frame_rate,
'channels': audio.channels,
'duration_seconds': len(audio) / 1000.0,
'sample_width': audio.sample_width
}
return quality_metrics
except Exception as e:
logger.error(f"Failed to analyze audio quality: {e}")
return {}
def cleanup(self):
"""清理资源"""
self.executor.shutdown(wait=True)
if not self.keep_temp_files and self.temp_dir.exists():
import shutil
try:
shutil.rmtree(self.temp_dir)
logger.info(f"Cleaned up temp directory: {self.temp_dir}")
except Exception as e:
logger.warning(f"Failed to cleanup temp directory: {e}")
def get_status(self) -> Dict:
"""获取状态信息"""
status = {
'processing': len(self.processing_tasks),
'completed': len(self.completed_tasks),
'failed': len(self.failed_tasks),
'stats': self.stats.copy()
}
if self.stats.get('start_time'):
status['stats']['elapsed_time'] = time.time() - self.stats['start_time']
return status
class AdvancedAudioProcessor:
"""高级音频处理器"""
def __init__(self, extractor: AudioExtractor):
self.extractor = extractor
def split_by_silence(self,
audio_path: Path,
min_silence_len: int = 1000,
silence_thresh: int = -40,
keep_silence: int = 100) -> List[Path]:
"""根据静音分割音频"""
if not PYDUB_AVAILABLE:
logger.error("pydub required for silence detection")
return []
try:
audio = AudioSegment.from_file(str(audio_path))
# 检测静音
chunks = split_on_silence(
audio,
min_silence_len=min_silence_len,
silence_thresh=silence_thresh,
keep_silence=keep_silence
)
logger.info(f"Detected {len(chunks)} chunks in {audio_path.name}")
# 保存每个片段
output_files = []
for i, chunk in enumerate(chunks):
output_path = audio_path.parent / f"{audio_path.stem}_part{i+1:03d}.mp3"
chunk.export(str(output_path), format="mp3")
output_files.append(output_path)
return output_files
except Exception as e:
logger.error(f"Failed to split by silence: {e}")
return []
def normalize_audio(self, audio_path: Path, target_dBFS: float = -20.0) -> Optional[Path]:
"""标准化音频音量"""
if not PYDUB_AVAILABLE:
logger.error("pydub required for normalization")
return None
try:
audio = AudioSegment.from_file(str(audio_path))
# 计算当前音量
current_dBFS = audio.dBFS
logger.info(f"Current volume: {current_dBFS:.1f} dBFS")
# 标准化
normalized = normalize(audio, headroom=target_dBFS - audio.dBFS)
# 保存
output_path = audio_path.parent / f"{audio_path.stem}_normalized{audio_path.suffix}"
normalized.export(str(output_path), format=audio_path.suffix[1:])
logger.info(f"Normalized to: {normalized.dBFS:.1f} dBFS")
return output_path
except Exception as e:
logger.error(f"Failed to normalize audio: {e}")
return None
def compress_dynamic_range(self,
audio_path: Path,
threshold: float = -20.0,
ratio: float = 4.0,
attack: float = 5.0,
release: float = 50.0) -> Optional[Path]:
"""压缩动态范围"""
if not PYDUB_AVAILABLE:
logger.error("pydub required for dynamic range compression")
return None
try:
audio = AudioSegment.from_file(str(audio_path))
# 应用压缩
compressed = compress_dynamic_range(
audio,
threshold=threshold,
ratio=ratio,
attack=attack,
release=release
)
# 保存
output_path = audio_path.parent / f"{audio_path.stem}_compressed{audio_path.suffix}"
compressed.export(str(output_path), format=audio_path.suffix[1:])
logger.info(f"Dynamic range compression applied to: {audio_path.name}")
return output_path
except Exception as e:
logger.error(f"Failed to compress dynamic range: {e}")
return None
def convert_sample_rate(self,
audio_path: Path,
target_sample_rate: int = 44100) -> Optional[Path]:
"""转换采样率"""
if not PYDUB_AVAILABLE:
logger.error("pydub required for sample rate conversion")
return None
try:
audio = AudioSegment.from_file(str(audio_path))
# 获取当前采样率
current_rate = audio.frame_rate
logger.info(f"Current sample rate: {current_rate} Hz")
# 转换采样率
converted = audio.set_frame_rate(target_sample_rate)
# 保存
output_path = audio_path.parent / f"{audio_path.stem}_{target_sample_rate}Hz{audio_path.suffix}"
converted.export(str(output_path), format=audio_path.suffix[1:])
logger.info(f"Converted to {target_sample_rate} Hz")
return output_path
except Exception as e:
logger.error(f"Failed to convert sample rate: {e}")
return None
def main():
"""主函数"""
parser = argparse.ArgumentParser(
description='高级音频提取与处理工具',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
使用示例:
# 提取单个视频的音频
%(prog)s video.mp4
# 提取为高质量FLAC
%(prog)s video.mp4 -f flac -q high
# 批量提取目录中的所有视频
%(prog)s -i videos/ -o audio_output/
# 处理时间片段
%(prog)s video.mp4 --start 60 --end 300
# 高级处理
%(prog)s video.mp4 --normalize --split-silence
"""
)
parser.add_argument(
'input',
nargs='?',
help='输入视频文件或目录'
)
parser.add_argument(
'-i', '--input-dir',
help='输入目录(批量处理)'
)
parser.add_argument(
'-o', '--output-dir',
default='./audio_output',
help='输出目录(默认: ./audio_output)'
)
parser.add_argument(
'-f', '--format',
choices=['mp3', 'wav', 'flac', 'aac', 'ogg', 'm4a', 'opus'],
default='mp3',
help='输出音频格式(默认: mp3)'
)
parser.add_argument(
'-q', '--quality',
choices=['low', 'medium', 'high', 'lossless'],
default='high',
help='音频质量(默认: high)'
)
parser.add_argument(
'--start',
type=float,
help='开始时间(秒)'
)
parser.add_argument(
'--end',
type=float,
help='结束时间(秒)'
)
parser.add_argument(
'--channels',
choices=['mono', 'stereo', '5.1', '7.1'],
default='stereo',
help='声道布局(默认: stereo)'
)
parser.add_argument(
'--normalize',
action='store_true',
help='标准化音频音量'
)
parser.add_argument(
'--split-silence',
action='store_true',
help='根据静音分割音频'
)
parser.add_argument(
'--compress',
action='store_true',
help='压缩动态范围'
)
parser.add_argument(
'--resample',
type=int,
help='重采样到指定频率(Hz)'
)
parser.add_argument(
'--metadata-json',
help='包含元数据的JSON文件'
)
parser.add_argument(
'--keep-temp',
action='store_true',
help='保留临时文件'
)
parser.add_argument(
'--concurrent',
type=int,
default=3,
help='最大并发任务数(默认: 3)'
)
parser.add_argument(
'-v', '--verbose',
action='store_true',
help='详细输出'
)
args = parser.parse_args()
# 设置日志级别
if args.verbose:
logger.setLevel(logging.DEBUG)
# 验证输入
if not args.input and not args.input_dir:
parser.print_help()
return
# 初始化提取器
try:
extractor = AudioExtractor(
output_dir=args.output_dir,
max_concurrent=args.concurrent,
keep_temp_files=args.keep_temp
)
except Exception as e:
logger.error(f"初始化失败: {e}")
sys.exit(1)
try:
# 收集输入文件
input_files = []
if args.input:
input_path = Path(args.input)
if input_path.is_file():
input_files.append(input_path)
elif input_path.is_dir():
input_files.extend(list(input_path.glob("*.mp4")))
input_files.extend(list(input_path.glob("*.mkv")))
input_files.extend(list(input_path.glob("*.avi")))
input_files.extend(list(input_path.glob("*.mov")))
else:
logger.error(f"输入路径不存在: {args.input}")
return
if args.input_dir:
input_dir = Path(args.input_dir)
if input_dir.is_dir():
input_files.extend(list(input_dir.glob("*.mp4")))
input_files.extend(list(input_dir.glob("*.mkv")))
input_files.extend(list(input_dir.glob("*.avi")))
input_files.extend(list(input_dir.glob("*.mov")))
else:
logger.error(f"输入目录不存在: {args.input_dir}")
return
if not input_files:
logger.error("没有找到有效的输入文件")
return
# 去重
input_files = list(set(input_files))
logger.info(f"找到 {len(input_files)} 个媒体文件")
# 加载元数据
metadata = None
if args.metadata_json:
try:
with open(args.metadata_json, 'r', encoding='utf-8') as f:
metadata_dict = json.load(f)
metadata = AudioMetadata(**metadata_dict)
except Exception as e:
logger.error(f"加载元数据失败: {e}")
# 转换参数
audio_format = AudioFormat(args.format)
audio_quality = AudioQuality(args.quality)
channel_layout = ChannelLayout(args.channels)
# 高级处理器
processor = AdvancedAudioProcessor(extractor)
# 处理每个文件
success_count = 0
for input_file in input_files:
logger.info(f"处理: {input_file.name}")
try:
# 提取音频
output_path = extractor.extract_audio(
input_path=input_file,
output_format=audio_format,
quality=audio_quality,
metadata=metadata,
start_time=args.start,
end_time=args.end,
channels=channel_layout
)
if not output_path:
logger.error(f"提取失败: {input_file.name}")
continue
success_count += 1
# 高级处理
if args.normalize:
logger.info("标准化音频音量...")
normalized_path = processor.normalize_audio(output_path)
if normalized_path:
output_path = normalized_path
if args.compress:
logger.info("压缩动态范围...")
compressed_path = processor.compress_dynamic_range(output_path)
if compressed_path:
output_path = compressed_path
if args.resample:
logger.info(f"重采样到 {args.resample}Hz...")
resampled_path = processor.convert_sample_rate(output_path, args.resample)
if resampled_path:
output_path = resampled_path
if args.split_silence:
logger.info("根据静音分割音频...")
chunks = processor.split_by_silence(output_path)
if chunks:
logger.info(f"分割为 {len(chunks)} 个片段")
# 分析音频质量
quality_metrics = extractor.analyze_audio_quality(output_path)
if quality_metrics:
logger.info(f"音频质量分析:")
logger.info(f" 动态范围: {quality_metrics.get('dynamic_range_db', 0):.1f} dB")
logger.info(f" 峰值频率: {quality_metrics.get('peak_frequency_hz', 0):.0f} Hz")
# 获取统计信息
stats = extractor._calculate_audio_stats(output_path)
if stats:
human_stats = stats.to_human_readable()
logger.info(f"输出文件信息:")
for key, value in human_stats.items():
logger.info(f" {key}: {value}")
logger.info(f"✓ 处理完成: {output_path.name}\n")
except Exception as e:
logger.error(f"处理文件时发生错误: {e}")
logger.error(traceback.format_exc())
continue
# 添加延迟,避免资源争用
if len(input_files) > 1:
time.sleep(1)
# 打印最终统计
status = extractor.get_status()
logger.info("=" * 60)
logger.info("处理完成!")
logger.info(f"成功: {success_count}/{len(input_files)}")
logger.info(f"失败: {len(input_files) - success_count}")
if status['stats'].get('elapsed_time'):
logger.info(f"总耗时: {status['stats']['elapsed_time']:.1f} 秒")
# 清理资源
extractor.cleanup()
except KeyboardInterrupt:
logger.info("\n用户中断处理")
extractor.cleanup()
except Exception as e:
logger.error(f"处理过程中发生错误: {e}")
logger.error(traceback.format_exc())
extractor.cleanup()
sys.exit(1)
if __name__ == "__main__":
main()4. 高级音频处理技术深度解析
4.1 音频信号处理算法实现
python
"""
高级音频信号处理算法实现
包含FFT频谱分析、滤波器设计、音频特征提取等
"""
import numpy as np
from typing import List, Tuple, Dict, Optional
from dataclasses import dataclass
from enum import Enum
import math
import warnings
class FilterType(Enum):
"""滤波器类型"""
LOWPASS = "lowpass" # 低通滤波器
HIGHPASS = "highpass" # 高通滤波器
BANDPASS = "bandpass" # 带通滤波器
BANDSTOP = "bandstop" # 带阻滤波器
PEAKING = "peaking" # 峰值滤波器
LOW_SHELF = "low_shelf" # 低架滤波器
HIGH_SHELF = "high_shelf" # 高架滤波器
@dataclass
class FilterDesign:
"""滤波器设计参数"""
filter_type: FilterType
cutoff_freq: float # 截止频率 (Hz)
sample_rate: int # 采样率
order: int = 4 # 滤波器阶数
bandwidth: float = 1.0 # 带宽 (倍频程)
gain_db: float = 0.0 # 增益 (dB)
class AudioSignalProcessor:
"""音频信号处理器"""
def __init__(self, sample_rate: int = 44100):
self.sample_rate = sample_rate
self.fft_size = 2048
self.hop_size = 512
def compute_fft(self, audio_data: np.ndarray,
window_type: str = 'hann') -> Tuple[np.ndarray, np.ndarray]:
"""
计算音频信号的FFT频谱
"""
if len(audio_data) < self.fft_size:
# 零填充
audio_data = np.pad(audio_data, (0, self.fft_size - len(audio_data)))
# 应用窗函数
if window_type == 'hann':
window = np.hanning(self.fft_size)
elif window_type == 'hamming':
window = np.hamming(self.fft_size)
elif window_type == 'blackman':
window = np.blackman(self.fft_size)
else:
window = np.ones(self.fft_size)
windowed = audio_data[:self.fft_size] * window
# 计算FFT
spectrum = np.fft.rfft(windowed)
magnitudes = np.abs(spectrum)
frequencies = np.fft.rfftfreq(self.fft_size, 1/self.sample_rate)
return frequencies, magnitudes
def compute_spectrogram(self, audio_data: np.ndarray,
window_type: str = 'hann') -> np.ndarray:
"""
计算声谱图
"""
num_frames = (len(audio_data) - self.fft_size) // self.hop_size + 1
spectrogram = []
for i in range(num_frames):
start = i * self.hop_size
end = start + self.fft_size
if end > len(audio_data):
break
frame = audio_data[start:end]
freqs, mags = self.compute_fft(frame, window_type)
spectrogram.append(mags)
return np.array(spectrogram).T
def design_filter(self, design: FilterDesign) -> np.ndarray:
"""
设计IIR或FIR滤波器
返回滤波器系数
"""
# 归一化频率
nyquist = self.sample_rate / 2
normalized_freq = design.cutoff_freq / nyquist
if design.filter_type == FilterType.LOWPASS:
# 低通滤波器设计 (Butterworth)
b, a = self._butterworth_lowpass(normalized_freq, design.order)
elif design.filter_type == FilterType.HIGHPASS:
# 高通滤波器设计
b, a = self._butterworth_highpass(normalized_freq, design.order)
elif design.filter_type == FilterType.BANDPASS:
# 带通滤波器设计
bandwidth = design.bandwidth
low_freq = max(0, design.cutoff_freq - bandwidth/2) / nyquist
high_freq = min(nyquist, design.cutoff_freq + bandwidth/2) / nyquist
b, a = self._butterworth_bandpass(low_freq, high_freq, design.order)
else:
raise ValueError(f"不支持的滤波器类型: {design.filter_type}")
return b, a
def _butterworth_lowpass(self, cutoff: float, order: int) -> Tuple[np.ndarray, np.ndarray]:
"""Butterworth低通滤波器设计"""
# 简单实现,实际应用中应使用scipy.signal.butter
k = np.tan(np.pi * cutoff)
q = 1.0 / k
# 二阶节系数
b0 = 1.0 / (1.0 + np.sqrt(2)*q + q*q)
b1 = 2.0 * b0
b2 = b0
a0 = 1.0
a1 = 2.0 * b0 * (1.0 - q*q)
a2 = b0 * (1.0 - np.sqrt(2)*q + q*q)
# 扩展为指定阶数
b = np.array([b0, b1, b2])
a = np.array([a0, a1, a2])
for _ in range(order // 2 - 1):
b = np.convolve(b, np.array([b0, b1, b2]))
a = np.convolve(a, np.array([a0, a1, a2]))
return b, a
def _butterworth_highpass(self, cutoff: float, order: int) -> Tuple[np.ndarray, np.ndarray]:
"""Butterworth高通滤波器设计"""
# 低通到高通的转换
b_lp, a_lp = self._butterworth_lowpass(cutoff, order)
# 频谱反转
b_hp = b_lp.copy()
for i in range(1, len(b_hp), 2):
b_hp[i] = -b_hp[i]
return b_hp, a_lp
def _butterworth_bandpass(self, low_cutoff: float, high_cutoff: float,
order: int) -> Tuple[np.ndarray, np.ndarray]:
"""Butterworth带通滤波器设计"""
# 级联低通和高通
b_lp, a_lp = self._butterworth_lowpass(high_cutoff, order)
b_hp, a_hp = self._butterworth_highpass(low_cutoff, order)
# 串联连接
b_bp = np.convolve(b_lp, b_hp)
a_bp = np.convolve(a_lp, a_hp)
return b_bp, a_bp
def apply_filter(self, audio_data: np.ndarray,
b: np.ndarray, a: np.ndarray) -> np.ndarray:
"""
应用IIR滤波器
使用直接II型转置结构
"""
filtered = np.zeros_like(audio_data)
# 滤波器状态
zi = np.zeros(max(len(a), len(b)) - 1)
for i in range(len(audio_data)):
# 直接II型转置实现
filtered[i] = b[0] * audio_data[i] + zi[0]
# 更新状态
for j in range(1, len(zi)):
zi[j-1] = b[j] * audio_data[i] - a[j] * filtered[i] + zi[j]
if len(zi) > 0:
zi[-1] = b[-1] * audio_data[i] - a[-1] * filtered[i]
return filtered
def compute_loudness(self, audio_data: np.ndarray,
window_ms: float = 400.0) -> np.ndarray:
"""
计算响度 (EBU R128标准)
"""
window_size = int(self.sample_rate * window_ms / 1000)
hop_size = window_size // 4
num_windows = (len(audio_data) - window_size) // hop_size + 1
loudness = np.zeros(num_windows)
for i in range(num_windows):
start = i * hop_size
end = start + window_size
if end > len(audio_data):
break
window = audio_data[start:end]
# K-weighting滤波 (简化的)
# 实际应使用完整的K-weighting滤波器
window_filtered = window
# 计算RMS
rms = np.sqrt(np.mean(window_filtered**2))
# 转换为LUFS
if rms > 0:
loudness_lufs = 20 * np.log10(rms) - 0.691
else:
loudness_lufs = -np.inf
loudness[i] = loudness_lufs
return loudness
def detect_silence(self, audio_data: np.ndarray,
threshold_db: float = -40.0,
min_silence_ms: float = 100.0) -> List[Tuple[int, int]]:
"""
检测静音段
返回静音段的起止索引列表
"""
min_silence_samples = int(self.sample_rate * min_silence_ms / 1000)
# 计算能量
window_size = 1024
hop_size = 512
num_frames = (len(audio_data) - window_size) // hop_size + 1
energy = np.zeros(num_frames)
for i in range(num_frames):
start = i * hop_size
end = start + window_size
if end > len(audio_data):
break
window = audio_data[start:end]
rms = np.sqrt(np.mean(window**2))
if rms > 0:
energy_db = 20 * np.log10(rms)
else:
energy_db = -np.inf
energy[i] = energy_db
# 检测静音
silence_segments = []
in_silence = False
silence_start = 0
for i, energy_db in enumerate(energy):
if energy_db < threshold_db and not in_silence:
in_silence = True
silence_start = i * hop_size
elif energy_db >= threshold_db and in_silence:
in_silence = False
silence_end = i * hop_size
if silence_end - silence_start >= min_silence_samples:
silence_segments.append((silence_start, silence_end))
# 处理最后一段
if in_silence:
silence_end = len(audio_data)
if silence_end - silence_start >= min_silence_samples:
silence_segments.append((silence_start, silence_end))
return silence_segments
def extract_features(self, audio_data: np.ndarray) -> Dict[str, float]:
"""
提取音频特征
"""
features = {}
# 时域特征
features['rms'] = float(np.sqrt(np.mean(audio_data**2)))
features['peak'] = float(np.max(np.abs(audio_data)))
if features['rms'] > 0:
features['crest_factor'] = features['peak'] / features['rms']
else:
features['crest_factor'] = 0.0
# 零交叉率
zero_crossings = np.sum(np.abs(np.diff(np.sign(audio_data)))) / 2
features['zero_crossing_rate'] = zero_crossings / len(audio_data)
# 频谱特征
freqs, mags = self.compute_fft(audio_data)
if len(mags) > 0:
# 频谱质心
if np.sum(mags) > 0:
features['spectral_centroid'] = float(np.sum(freqs * mags) / np.sum(mags))
else:
features['spectral_centroid'] = 0.0
# 频谱带宽
if features['spectral_centroid'] > 0 and np.sum(mags) > 0:
features['spectral_bandwidth'] = float(
np.sqrt(np.sum(mags * (freqs - features['spectral_centroid'])**2) / np.sum(mags))
)
else:
features['spectral_bandwidth'] = 0.0
# 频谱滚降点
total_energy = np.sum(mags)
cumsum = np.cumsum(mags)
rolloff_idx = np.where(cumsum >= 0.85 * total_energy)[0]
if len(rolloff_idx) > 0:
features['spectral_rolloff'] = float(freqs[rolloff_idx[0]])
else:
features['spectral_rolloff'] = 0.0
return features
class AudioNormalizer:
"""音频标准化器"""
def __init__(self, target_loudness_lufs: float = -16.0):
self.target_loudness = target_loudness_lufs
def normalize_loudness(self, audio_data: np.ndarray,
sample_rate: int) -> np.ndarray:
"""
基于响度的标准化 (EBU R128)
"""
processor = AudioSignalProcessor(sample_rate)
# 计算当前响度
loudness = processor.compute_loudness(audio_data)
if len(loudness) > 0:
# 使用积分响度
integrated_loudness = np.mean(loudness)
# 计算增益
gain_db = self.target_loudness - integrated_loudness
gain_linear = 10 ** (gain_db / 20)
# 应用增益
normalized = audio_data * gain_linear
# 限制峰值
max_sample = np.max(np.abs(normalized))
if max_sample > 1.0:
normalized = normalized / max_sample * 0.99
return normalized
return audio_data
def normalize_peak(self, audio_data: np.ndarray,
target_peak: float = 0.99) -> np.ndarray:
"""
基于峰值的标准化
"""
peak = np.max(np.abs(audio_data))
if peak > 0:
gain = target_peak / peak
return audio_data * gain
return audio_data
# 使用示例
if __name__ == "__main__":
# 生成测试音频信号
sample_rate = 44100
duration = 5.0
t = np.linspace(0, duration, int(sample_rate * duration), endpoint=False)
# 生成多频信号
freq1 = 440 # A4
freq2 = 880 # A5
freq3 = 1760 # A6
signal = 0.5 * np.sin(2 * np.pi * freq1 * t)
signal += 0.3 * np.sin(2 * np.pi * freq2 * t)
signal += 0.2 * np.sin(2 * np.pi * freq3 * t)
# 添加噪声
noise = np.random.normal(0, 0.1, len(signal))
signal += noise
# 创建处理器
processor = AudioSignalProcessor(sample_rate)
print("音频特征分析:")
features = processor.extract_features(signal)
for key, value in features.items():
print(f" {key}: {value:.4f}")
print("\n滤波器设计示例:")
# 设计低通滤波器
filter_design = FilterDesign(
filter_type=FilterType.LOWPASS,
cutoff_freq=1000.0,
sample_rate=sample_rate,
order=4
)
b, a = processor.design_filter(filter_design)
print(f"滤波器系数:")
print(f" b (分子): {b[:5]}...")
print(f" a (分母): {a[:5]}...")
# 计算频谱
print("\n频谱分析:")
freqs, mags = processor.compute_fft(signal[:2048])
# 找到峰值频率
peak_idx = np.argmax(mags)
print(f"主要频率: {freqs[peak_idx]:.1f} Hz")
print(f"幅度: {mags[peak_idx]:.4f}")
# 计算声谱图
print("\n计算声谱图...")
spectrogram = processor.compute_spectrogram(signal[:sample_rate]) # 1秒数据
print(f"声谱图形状: {spectrogram.shape}")
print(f"时间分辨率: {spectrogram.shape[1] * processor.hop_size / sample_rate:.2f} 秒")
print(f"频率分辨率: {sample_rate / processor.fft_size:.1f} Hz")5. 总结与展望
5.1 核心技术总结
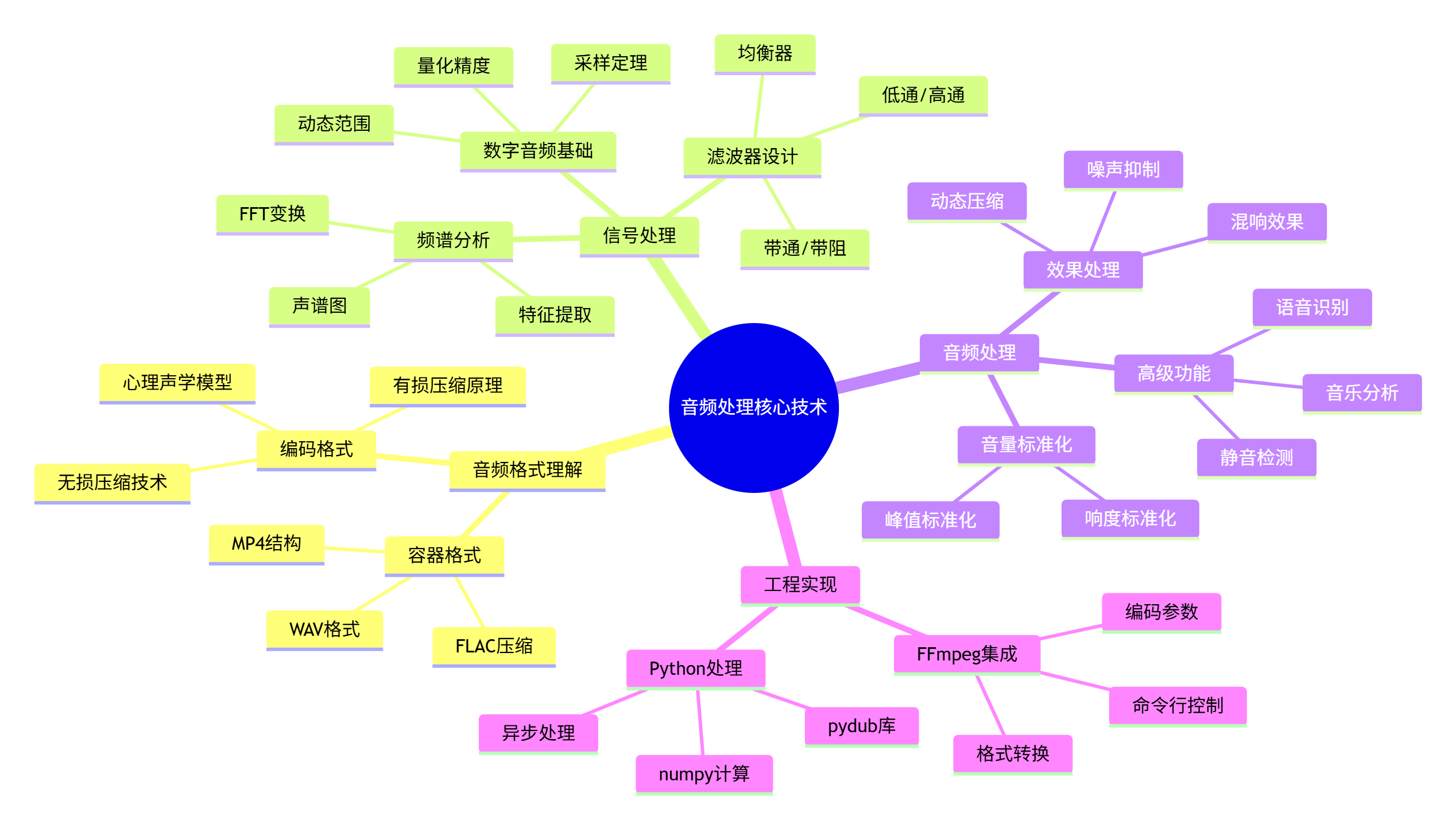
通过本篇文章,我们深入探讨了音频提取与处理的核心技术:
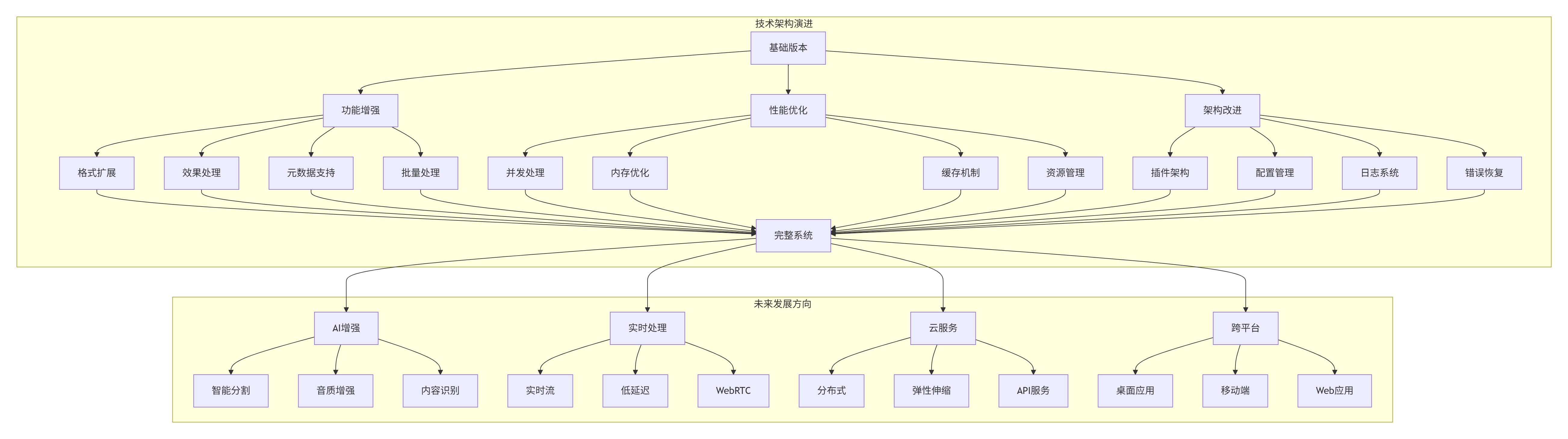
5.2 技术架构演进
5.3 最佳实践建议
在实际项目开发中,建议遵循以下最佳实践:
-
代码质量
-
使用类型注解提高可维护性
-
编写单元测试和集成测试
-
遵循PEP 8编码规范
-
添加详细的文档字符串
-
-
性能优化
-
使用异步处理提高并发性能
-
合理管理内存和文件句柄
-
实现缓存机制减少重复计算
-
监控资源使用情况
-
-
错误处理
-
实现细粒度的异常处理
-
添加重试机制处理临时故障
-
记录详细的日志信息
-
设计降级策略保证可用性
-
-
用户体验
-
提供详细的进度反馈
-
支持中断和恢复
-
设计直观的命令行界面
-
生成清晰的处理报告
-
5.4 学习资源推荐
-
书籍推荐
-
《数字音频处理基础》- 理解音频信号处理原理
-
《FFmpeg从入门到精通》- 掌握多媒体处理工具
-
《Python高级编程》- 提升Python工程能力
-
-
在线资源
-
FFmpeg官方文档:最权威的多媒体处理参考
-
PyDub文档:Python音频处理库指南
-
NumPy/SciPy文档:科学计算基础
-
-
开源项目
-
Audacity:优秀的开源音频编辑器
-
SoX:强大的音频处理工具
-
Librosa:专业的音频分析库
-