本文需要借助工具:fontcreator,或者在线网站:字体设计在线网站
字体反爬介绍
字体反爬是网站常用的前端反爬手段,核心逻辑是用自定义字体文件替代明文文本,爬虫自动化也无法拿到正确的明文数据
字体反爬原理
本文主要讲解的是css层面的字体反爬,css中定义自定义字体的规则叫做@font-face 规则,通过@font-face这个标签会读取字体文件,字体文件中会有对应的映射关系,然后通过映射关系将密文字体转化为明文
字体反爬解决方法以及步骤
解决方法:
1.找字体映射关系
- 找到字体文件发现字体文件中映射关系少且不变,可以自己手写映射关系
- 当网页字体映射关系会变时,需要找规律,找出文字映射关系变化逻辑(很难,需要对字体有很深的研究)现在也可以拿下来十个八个文件丢给ai让ai找规律
2.通过坐标描画文字然后用识别库识别来写出映射关系(orc识别)
3.通过on(极少用)
解决步骤:
我们这里主要讲第二种解决方法的步骤,案例地址:shixi僧:

**↑**字体文件
第一步,通过请求拿到字体文件并转换
通过请求拿下来字体文件,然后保存到本地:
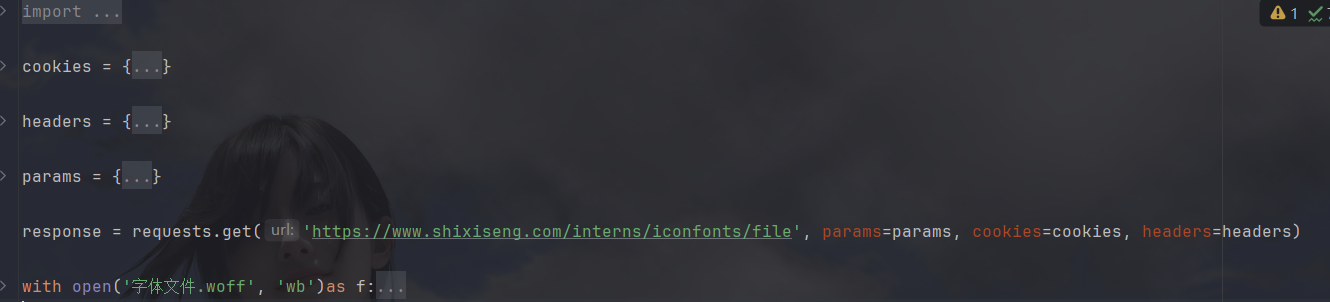
转换成xml(xml是结构化数据,可以直接用.key(拿到标签),也可以用xpath语法):
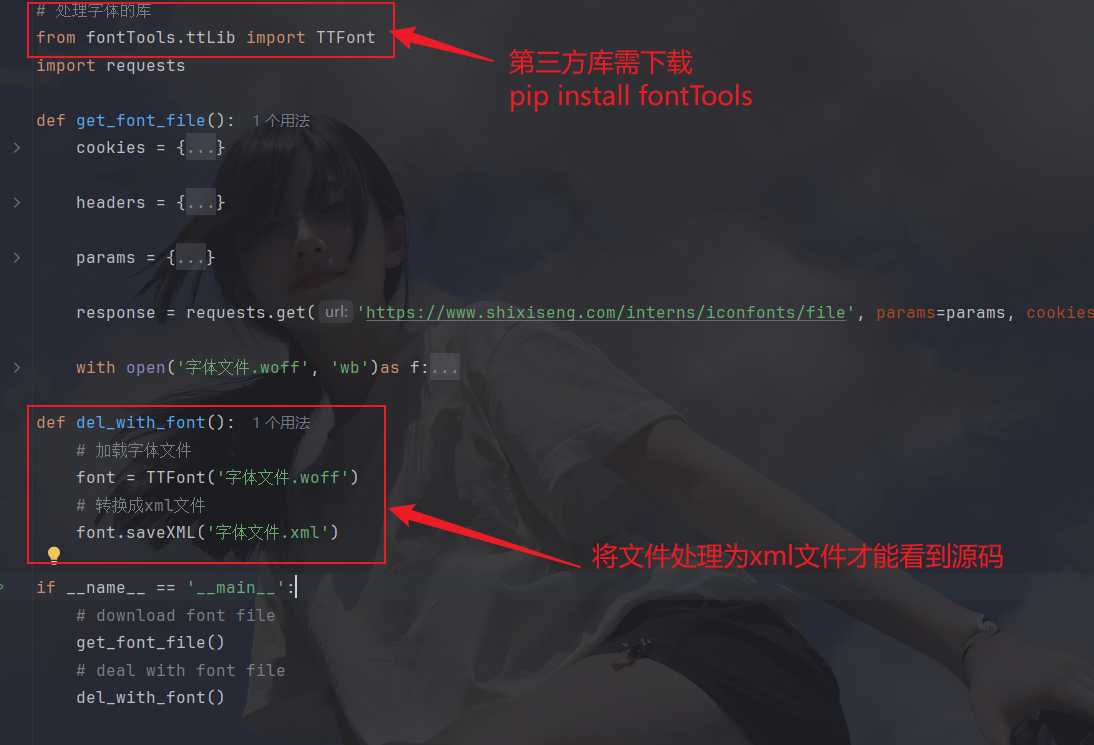
源码文件(需注意两个标签):
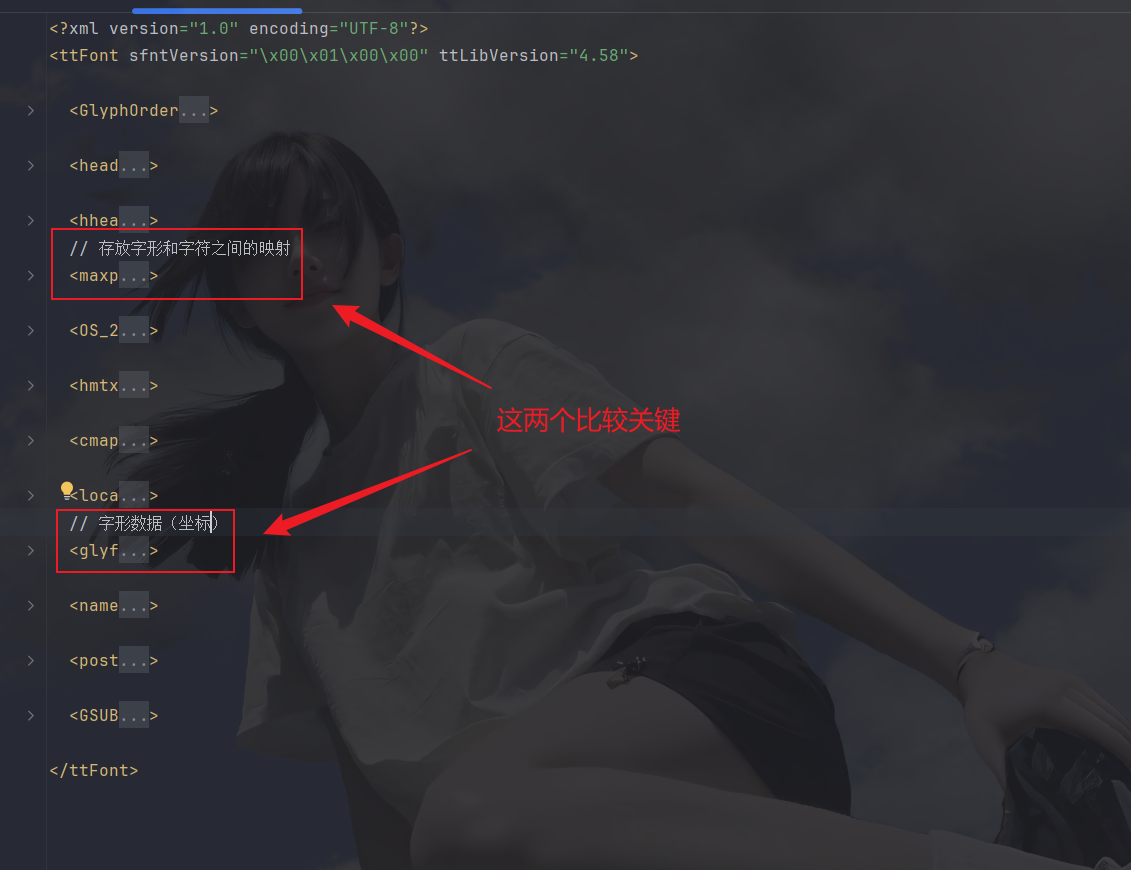
cmap主要是到时候对应网站上的'乱码'和我们字典中的key,替换'乱码'为正常的字:
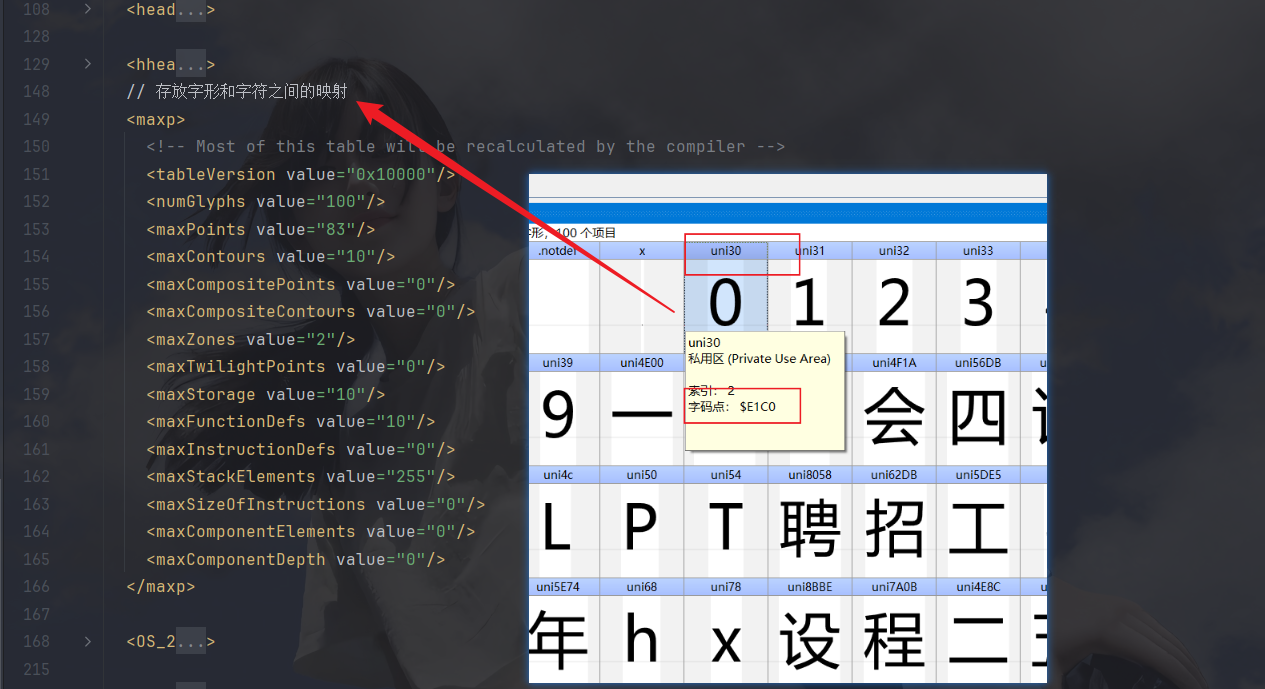
glyf中的contour主要是坐标与直曲线,到时按此画图然后识别出文字:
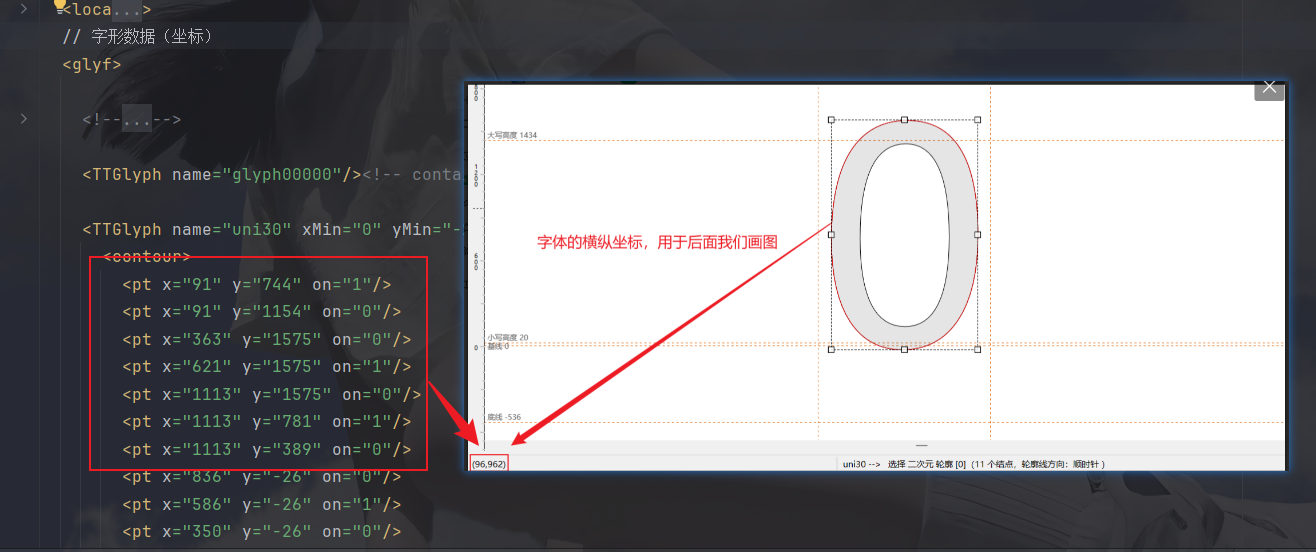
第二步,封装画图加识别的py文件
首先读取文件:
plain
# 解析xml所需库
from lxml import etree
# 读取xml文件(xml文件里会有声明:<?xml version="1.0" encoding="UTF-8"?>需要解码:f.read().encode('utf-8'))
with open('字体文件.xml', 'r', encoding='utf-8') as f:
xml_code = f.read().encode('utf-8')
# 解析xml文件(fromstring直接处理xml文件,转换为字符串)
font_parser = etree.fromstring(xml_code)然后xpath解析,提取以及整理名字和坐标:
plain
# xpath语法提取坐标列表
TTGlyph_list = font_parser.xpath('//glyf/TTGlyph')
# print(TTGlyph_list)
x_y_list = []
for TTGlyph in TTGlyph_list[1:-1]:
# print(TTGlyph)
if TTGlyph.xpath('./contour[1]'):
# print('contour中有数据')
font_name = TTGlyph.xpath('./@name') # 拿到名字,即网页字体乱码的映射
contour_list = TTGlyph.xpath('./contour[1]') # 这里是内存地址
# 循环提取contour,然后用xpath提取x y坐标值
for contour in contour_list:
x_y = [(x, y) for x, y in zip(contour.xpath('./pt/@x'), contour.xpath('./pt/@y'))] # 这里zip是将x y循环得出的每一个对应位置的元素绑在一起
# 画图需要首尾相连,此处将第一个坐标写入列表尾部
x_y.append(x_y[0])
# print(x_y)
# 将所有文字装进一个列表
x_y_list.append(x_y)
# print(x_y_list)然后画图并保存:
plain
# 画图
plt.figure(figsize=(10, 10)) # 创建一个画布,figsize=(10, 10)表示画布的宽和高都是 10 英寸
# 遍历每个图案
for shape in x_y_list:
x, y = zip(*[(int(point[0]), (int(point[1]))) for point in shape]) # *是解包运算符,将元组解包再用zip重新分配
# print(x, y)
# 绘制多边形
plt.plot(x, y, marker='o') # 连接点的多边形
plt.fill(x, y, alpha=0.3) # 填充多边形
# 隐藏刻度标签
plt.xticks([])
plt.yticks([])
# 设置绘图属性
plt.axis('equal') # 坐标轴比例一致
plt.grid(True)
# 保存图片
plt.savefig('图片/' + f'{font_name}.png')通过ddddocr库识别图片
plain
ocr = ddddocr.DdddOcr()
with open('图片/' + f'{font_name}.png', 'rb') as f:
image = f.read()
res = ocr.classification(image)
print(res)封装此文件成类,方便主py文件调用:
plain
# 解析xml所需库
from lxml import etree
import matplotlib
# 画图库
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
# 识别图片的库
import ddddocr
class PaintIdentify:
def __init__(self, file_path):
self.file_path = file_path # 传递xml文件地址
def parse_file(self, TTGlyph):
if TTGlyph.xpath('./contour[1]'):
x_y_list = []
# print('contour中有数据')
font_name = TTGlyph.xpath('./@name') # 拿到名字,即网页字体乱码的映射
contour_list = TTGlyph.xpath('./contour') # 这里是内存地址
# 循环提取contour,然后用xpath提取x y坐标值
for contour in contour_list:
x_y = [(x, y) for x, y in zip(contour.xpath('./pt/@x'), contour.xpath('./pt/@y'))] # 这里zip是将x y循环得出的每一个对应位置的元素绑在一起
# 画图需要首尾相连,此处将第一个坐标写入列表尾部
x_y.append(x_y[0])
# print(x_y)
# 将所有文字装进一个列表
x_y_list.append(x_y)
self.paint(x_y_list, font_name)
res = self.identify(font_name)
return (font_name[0], res)
return None
def paint(self, x_y_list, font_name):
# 画图
plt.figure(figsize=(10, 10)) # 创建一个画布,figsize=(10, 10)表示画布的宽和高都是 10 英寸
# 遍历每个图案
for shape in x_y_list:
x, y = zip(*[(int(point[0]), (int(point[1]))) for point in shape]) # *是解包运算符,将元组解包再用zip重新分配
# print(x, y)
# 绘制多边形
plt.plot(x, y, marker='o') # 连接点的多边形
plt.fill(x, y, alpha=0.3) # 填充多边形
# 隐藏刻度标签
plt.xticks([])
plt.yticks([])
# 设置绘图属性
plt.axis('equal') # 坐标轴比例一致
plt.grid(True)
# 保存图片
plt.savefig('图片/' + f'{font_name}.png')
def identify(self, font_name):
ocr = ddddocr.DdddOcr()
with open('图片/' + f'{font_name}.png', 'rb') as f:
image = f.read()
res = ocr.classification(image)
return res
def main(self):
name_character_dic = {}
# 读取xml文件(xml文件里会有声明:<?xml version="1.0" encoding="UTF-8"?>需要解码:f.read().encode('utf-8'))
with open(self.file_path, 'r', encoding='utf-8') as f:
xml_code = f.read().encode('utf-8')
# 解析xml文件(fromstring直接处理xml文件,转换为字符串)
font_parser = etree.fromstring(xml_code)
# xpath语法提取坐标列表
TTGlyph_list = font_parser.xpath('//glyf/TTGlyph')
for TTGlyph in TTGlyph_list[1:-1]:
key, value = self.parse_file(TTGlyph)
name_character_dic[key] = value
return name_character_dic
if __name__ == '__main__':
paint_identify = PaintIdentify('字体文件.xml')
paint_identify.main()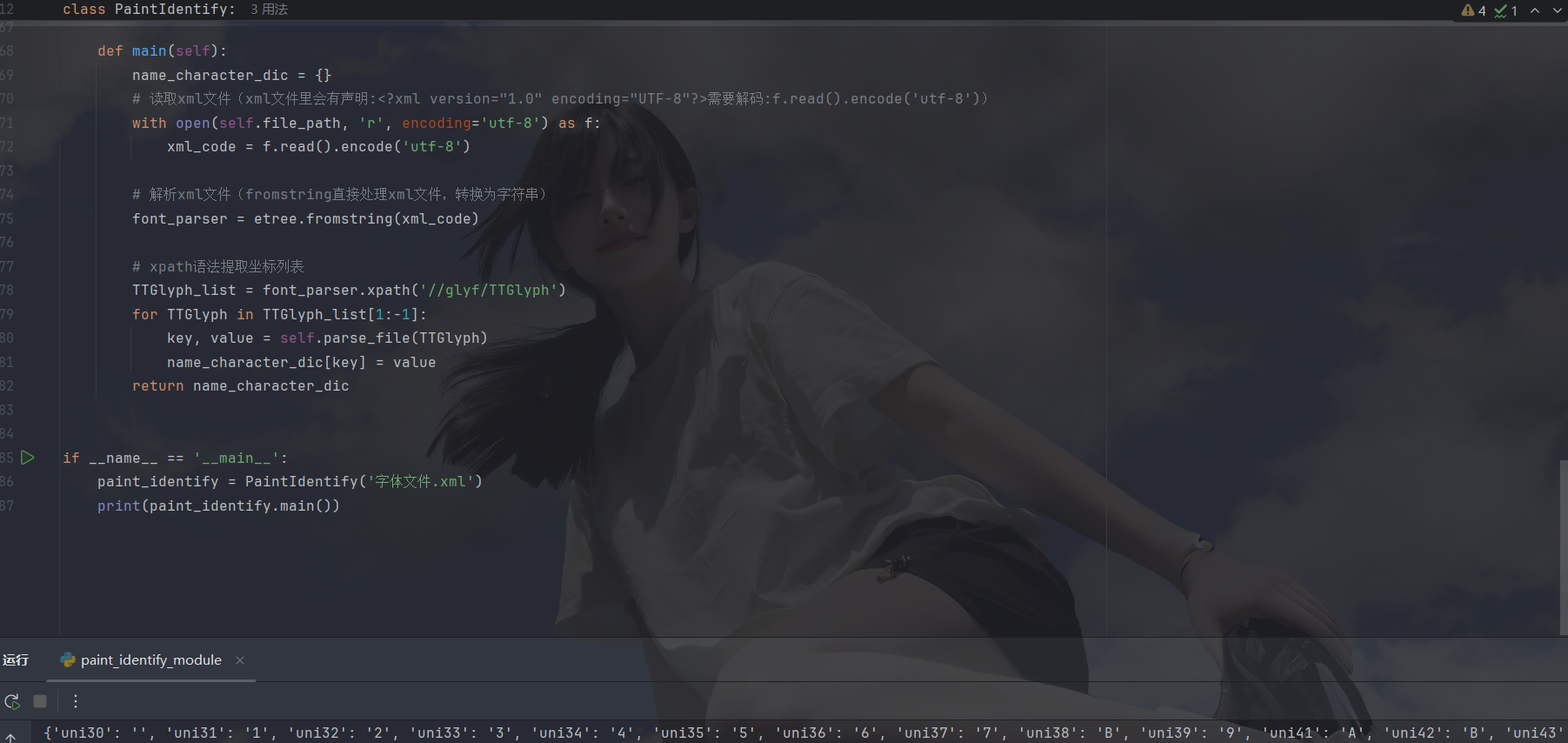
第三步,导入封装库
导入模块,按自己的py文件运行入口的写法写就行:
第四步,根据网页需要的数据进行匹配
经过观察所需的数据来对我们字体映射名来进行调整,然后替换到我们所需的数据中
小结
本文就到此结束,关键步骤已经列出,如有问题及时提出,一起讨论,加油加油