第11期 · AI 工程化实践:从原型到生产的全栈指南
系列 :每日 AI 知识点
期数 :第 11 期
主题 :AI 工程化实践
难度 :⭐⭐⭐⭐(高级)
一句话:把 LLM、RAG、Agent 等技术组合成稳定可靠的生产级 AI 应用,需要系统化的工程化思维和实践。
一、AI 工程化技术栈全景
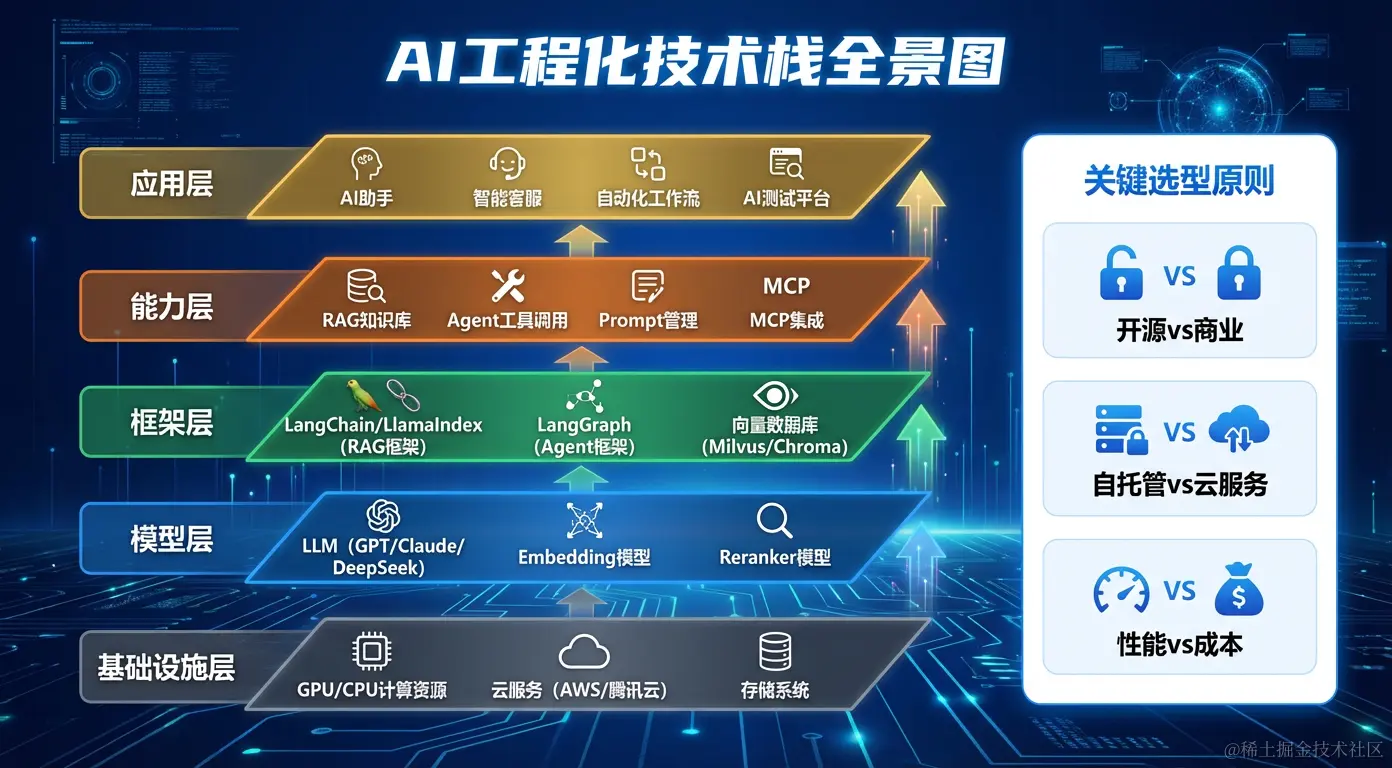
一个完整的生产级 AI 应用由五层技术栈组成:
第一层:基础设施层
计算资源:
GPU 集群(模型推理)| CPU 集群(向量检索)
云服务:
腾讯云 / AWS / 阿里云(弹性扩缩容)
存储:
对象存储(文档原件)| 向量数据库(Embedding)| 关系数据库(元数据)第二层:模型层
arduino
LLM 选型原则:
┌─────────────────────────────────────────┐
│ 任务类型 │ 推荐模型 │ 原因 │
├─────────────────────────────────────────┤
│ 通用问答 │ Claude 3.5 Sonnet │ 综合强 │
│ 代码生成 │ Claude 3.5 Sonnet │ 代码强 │
│ 中文处理 │ DeepSeek-V3 │ 中文优 │
│ 成本敏感 │ DeepSeek-V3 │ 价格低 │
│ 私有部署 │ LLaMA 3 / Qwen │ 开源 │
└─────────────────────────────────────────┘
Embedding 模型:
中文场景:BGE-M3(开源,中文优化)
通用场景:text-embedding-3-small(OpenAI)
Reranker 模型:
bge-reranker-v2-m3(开源,效果好)第三层:框架层
RAG 框架:
LangChain --- 功能最全,生态最丰富
LlamaIndex --- 专注 RAG,更轻量
Agent 框架:
LangGraph --- 基于图的 Agent 框架,可控性强
AutoGen --- 微软的 Multi-Agent 框架
向量数据库:
Milvus --- 企业级,高性能(推荐)
Chroma --- 开源轻量,适合原型
Pinecone --- 云服务,易用第四层:能力层
css
RAG 知识库 → 让 AI 基于私有文档回答
Agent 工具调用 → 让 AI 执行具体操作
Prompt 管理 → 版本控制、A/B 测试
MCP 集成 → 标准化工具接入第五层:应用层
AI 助手(对话式)
智能客服(问答式)
自动化工作流(任务式)
AI 测试平台(专业工具式)二、AI 应用工程化生命周期
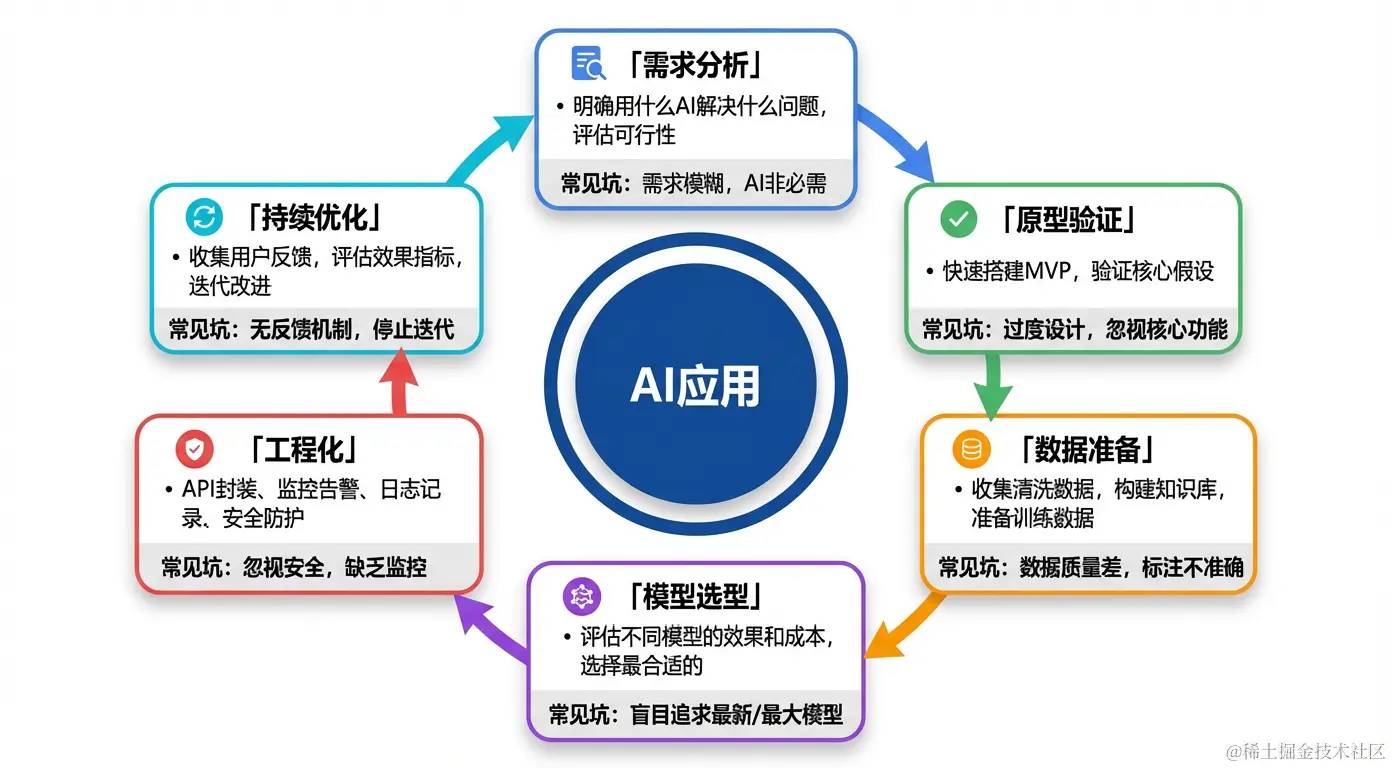
阶段一:需求分析
关键问题:
markdown
1. 用 AI 解决什么问题?
- 明确问题边界(AI 能解决什么,不能解决什么)
- 量化成功标准(准确率 >85%?响应时间 <2s?)
2. 有没有更简单的非 AI 方案?
- 如果规则匹配就能解决,不要用 AI
- AI 适合:模糊匹配、语义理解、内容生成
3. 数据准备好了吗?
- 有没有足够的文档/数据?
- 数据质量如何?需要清洗吗?
4. 成本预算是多少?
- API 调用费用(按 Token 计费)
- 向量数据库费用
- 工程开发和维护成本阶段二:原型验证(最重要!)
快速验证核心假设:
python
# 用最简单的方式验证 RAG 效果
# 不需要完整架构,先跑通核心流程
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import ChatOpenAI
# 1. 加载几个文档
docs = load_documents("test_docs/")
# 2. 向量化存储
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())
# 3. 测试检索效果
results = vectorstore.similarity_search("刷掌设备激活流程", k=3)
# 4. 测试 LLM 回答质量
chain = RetrievalQA.from_chain_type(ChatOpenAI(), retriever=vectorstore.as_retriever())
answer = chain.run("刷掌设备激活流程是什么?")
print(answer)原型验证的目标:
- 2 天内验证核心功能是否可行
- 用 20 个典型问题测试效果
- 确认技术路线是否正确
阶段三:数据准备
这是最容易被低估的阶段:
erlang
数据准备工作量占比(经验值):
需求分析:5%
原型验证:10%
数据准备:30% ← 通常被低估
工程化开发:25%
测试优化:20%
上线运维:10%数据准备清单:
□ 文档收集:确认覆盖所有业务场景
□ 格式处理:PDF 扫描版需要 OCR
□ 质量过滤:去除重复、过时、低质量内容
□ 结构整理:确保文档有清晰的标题和章节
□ 脱敏处理:去除个人信息、商业机密
□ 版本管理:建立文档更新机制
□ 测试集准备:准备 100 个典型问题和标准答案阶段四:模型选型
评估维度:
python
# 模型评估框架
evaluation_metrics = {
"accuracy": {
"weight": 0.4, # 准确率最重要
"test_cases": 100,
"threshold": 0.85
},
"latency": {
"weight": 0.2,
"p95_target": 2000, # ms
"p99_target": 5000
},
"cost": {
"weight": 0.2,
"monthly_budget": 10000 # 元
},
"safety": {
"weight": 0.2,
"test_cases": 50 # 安全红线测试
}
}
# 对每个候选模型跑评估
for model in ["claude-3.5-sonnet", "gpt-4o", "deepseek-v3"]:
score = evaluate_model(model, evaluation_metrics)
print(f"{model}: {score}")阶段五:工程化
从原型到生产的关键工作:
python
# 生产级 AI 应用的必备组件
# 1. 错误处理和重试
@retry(max_attempts=3, backoff=exponential)
def call_llm(prompt: str) -> str:
try:
return llm.invoke(prompt)
except RateLimitError:
raise # 触发重试
except Exception as e:
logger.error(f"LLM 调用失败: {e}")
return fallback_response()
# 2. 流式输出(提升用户体验)
async def stream_response(query: str):
async for chunk in llm.astream(query):
yield chunk.content
# 3. 缓存热点问题(降低成本)
@lru_cache(maxsize=1000)
def get_cached_answer(query_hash: str) -> Optional[str]:
return cache.get(query_hash)
# 4. 并发控制
semaphore = asyncio.Semaphore(10) # 最多 10 个并发请求
# 5. 超时控制
response = await asyncio.wait_for(
call_llm(prompt),
timeout=30.0 # 30 秒超时
)阶段六:持续优化
建立反馈闭环:
markdown
用户使用 → 收集反馈 → 分析问题 → 优化改进 → 重新评估
反馈收集方式:
1. 显式反馈:用户点赞/踩
2. 隐式反馈:用户是否追问(说明第一次没回答好)
3. 日志分析:哪些问题召回率低?哪些问题用户不满意?
4. 定期评测:每周用标准测试集跑评估三、AI 应用监控与质量保障
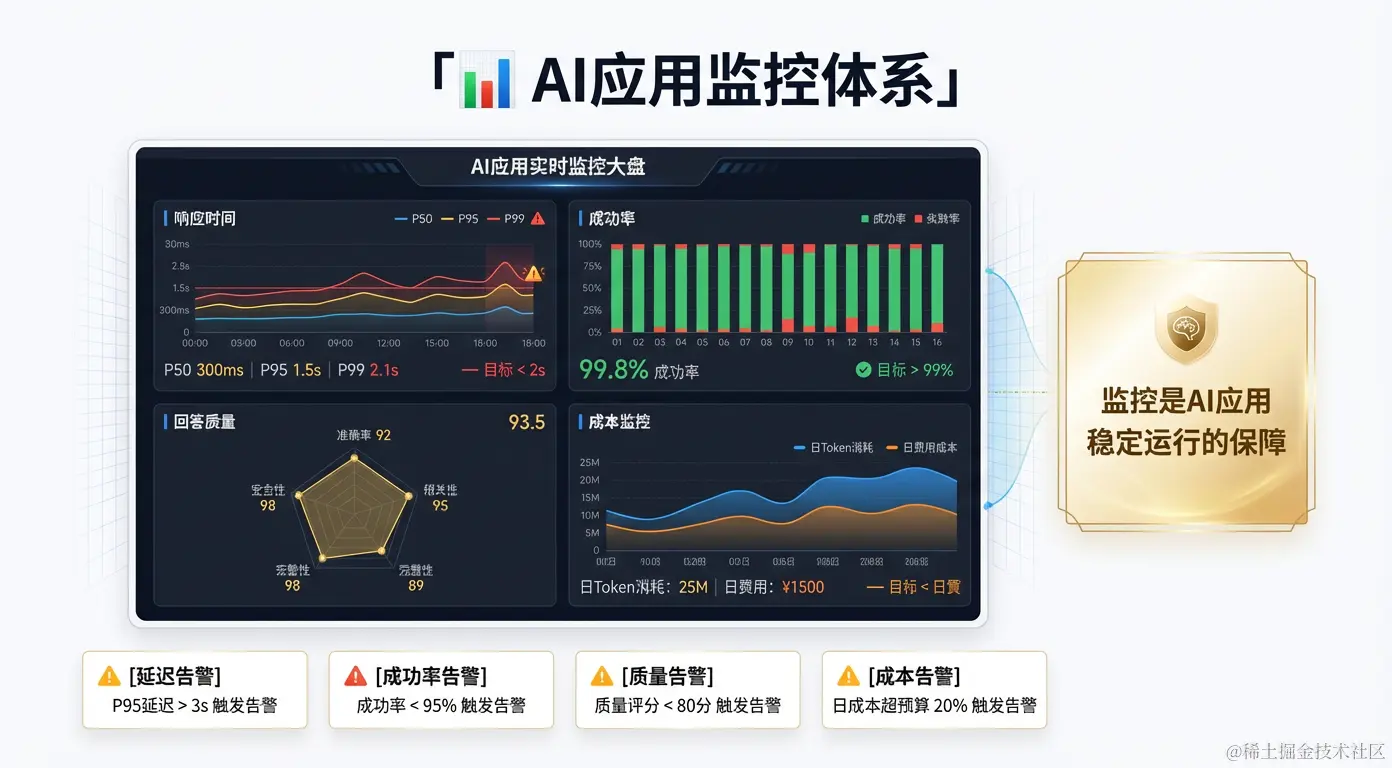
监控指标体系
性能指标:
python
# 关键性能指标
metrics = {
"latency_p50": "50%的请求响应时间",
"latency_p95": "95%的请求响应时间(用户体验关键)",
"latency_p99": "99%的请求响应时间(异常检测)",
"success_rate": "请求成功率",
"token_usage": "每日Token消耗量",
"cost_per_query": "每次查询的平均成本"
}
# 告警阈值
alerts = {
"latency_p95 > 3000ms": "P1告警",
"success_rate < 95%": "P1告警",
"success_rate < 90%": "P0告警",
"daily_cost > budget * 1.2": "P2告警"
}质量指标:
python
# AI 回答质量评估(自动化)
quality_metrics = {
"relevance": "回答与问题的相关性(0-1)",
"faithfulness": "回答是否忠实于检索到的文档(0-1)",
"completeness": "是否完整回答了问题(0-1)",
"safety": "是否包含不安全内容(0/1)"
}
# 使用 RAGAS 框架自动评估
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy
score = evaluate(
dataset=test_dataset,
metrics=[faithfulness, answer_relevancy]
)日志设计
python
# 结构化日志,便于分析
import structlog
logger = structlog.get_logger()
def handle_query(query: str, user_id: str):
start_time = time.time()
# 记录请求
logger.info("query_received",
query=query[:100], # 截断避免日志过大
user_id=user_id,
session_id=session_id
)
# 执行查询
retrieved_docs = retriever.retrieve(query)
response = llm.generate(query, retrieved_docs)
# 记录结果
latency = (time.time() - start_time) * 1000
logger.info("query_completed",
latency_ms=latency,
retrieved_doc_count=len(retrieved_docs),
response_length=len(response),
top_doc_score=retrieved_docs[0].score if retrieved_docs else None
)
return response四、成本优化策略
AI 应用的成本主要来自 LLM API 调用,以下是常用的优化策略:
策略一:问题分级路由
python
def route_query(query: str) -> str:
"""根据问题复杂度选择不同的模型"""
complexity = estimate_complexity(query)
if complexity == "simple":
# 简单问题用便宜的模型
return "deepseek-v3" # 成本约 GPT-4 的 1/20
elif complexity == "medium":
return "claude-3-haiku"
else:
# 复杂问题用强模型
return "claude-3.5-sonnet"策略二:缓存常见问题
python
# 对相似问题返回缓存结果
def get_answer_with_cache(query: str) -> str:
# 检查语义相似的缓存
cache_hit = semantic_cache.search(query, threshold=0.95)
if cache_hit:
logger.info("cache_hit", query=query[:50])
return cache_hit.answer
# 缓存未命中,调用 LLM
answer = call_llm(query)
semantic_cache.store(query, answer)
return answer实测效果:热点问题缓存可以减少 30-50% 的 API 调用成本。
策略三:Prompt 压缩
python
# 压缩过长的上下文,减少 Token 消耗
def compress_context(context: str, max_tokens: int = 2000) -> str:
if count_tokens(context) <= max_tokens:
return context
# 用 AI 摘要压缩(用便宜的模型)
summary = cheap_llm.summarize(context, max_tokens=max_tokens)
return summary五、安全与合规
输入安全
python
# Prompt 注入防护
def sanitize_input(user_input: str) -> str:
# 检测 Prompt 注入攻击
injection_patterns = [
"ignore previous instructions",
"you are now",
"act as",
"jailbreak"
]
for pattern in injection_patterns:
if pattern.lower() in user_input.lower():
raise SecurityError(f"检测到潜在的 Prompt 注入攻击")
return user_input输出安全
python
# 敏感信息过滤
def filter_output(response: str) -> str:
# 过滤手机号
response = re.sub(r'1[3-9]\d{9}', '[手机号已隐藏]', response)
# 过滤身份证号
response = re.sub(r'\d{17}[\dXx]', '[身份证已隐藏]', response)
# 过滤内部 IP 地址
response = re.sub(r'10\.\d+\.\d+\.\d+', '[内网IP已隐藏]', response)
return response六、一句话总结
AI 工程化 = 正确的技术选型 + 高质量的数据准备 + 完善的监控体系 + 持续的迭代优化。技术只是 20%,数据质量和工程规范才是决定 AI 应用成败的 80%。
延伸阅读
- 框架 :LangChain | LlamaIndex
- 评估工具 :RAGAS --- RAG 质量评估
- 监控 :LangSmith --- LLM 应用监控平台
下一期预告:第12期 · AI + 测试/研发场景 --- 系列收官之作!把前11期的所有知识点串联起来,展示 AI 在测试和研发工作中的完整应用场景和实践案例。