第07期 · Agent 智能体:从"会说话"到"会行动"的 AI 进化
系列 :每日 AI 知识点
期数 :第 07 期
主题 :Agent 智能体
难度 :⭐⭐⭐(进阶)
一句话:Agent 是能够自主规划、调用工具、完成多步骤任务的 AI 系统。它让 AI 从"被动回答"进化为"主动完成"。
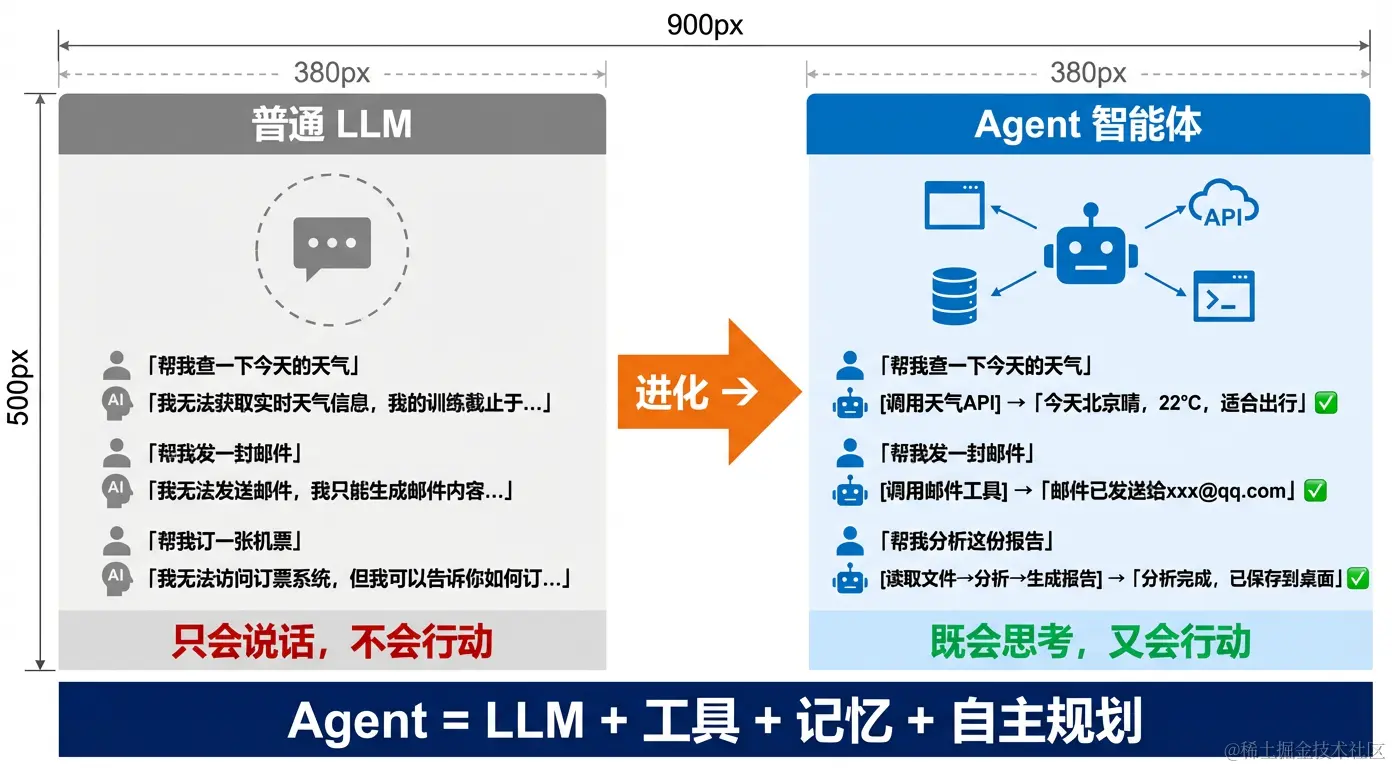
一、为什么需要 Agent?
普通 LLM 的根本局限
即使是最强的 LLM,在没有 Agent 框架的情况下,也只能做一件事:根据输入生成输出。
markdown
用户:「帮我查一下今天的股价,分析一下是否值得买入,
如果决定买入就帮我下单」
普通 LLM:「我无法获取实时股价,也无法执行交易操作。
但我可以告诉你如何分析股票...」LLM 是一个"嘴"------它能说,但不能做。
Agent 的进化
Agent(智能体) 给 LLM 加上了"手"和"眼":
ini
用户:「帮我查一下今天的股价,分析一下是否值得买入」
Agent:
[调用股价API] → 获取最新价格:¥128.5,较昨日+2.3%
[调用K线工具] → 分析30日走势:上升通道,RSI=62
[调用新闻工具] → 搜索相关新闻:公司刚发布好季报
[综合分析] → 基于以上数据,短期看涨,但需注意...
「根据实时数据分析:当前股价¥128.5,处于上升通道...
建议关注,但注意设置止损位...」二、Agent vs 普通 LLM 的核心区别
| 对比维度 | 普通 LLM | Agent |
|---|---|---|
| 行动能力 | 只能生成文本 | 可以调用工具执行操作 |
| 信息获取 | 只有训练时的知识 | 可以实时获取最新信息 |
| 任务复杂度 | 单步骤,一问一答 | 多步骤,自主规划执行 |
| 错误处理 | 无法自我纠正 | 失败时自动调整策略 |
| 记忆能力 | 仅限当前对话 | 可以有持久化记忆 |
| 并行能力 | 单线程 | 可以并行调用多个工具 |
三、Agent 的工作原理:ReAct 循环
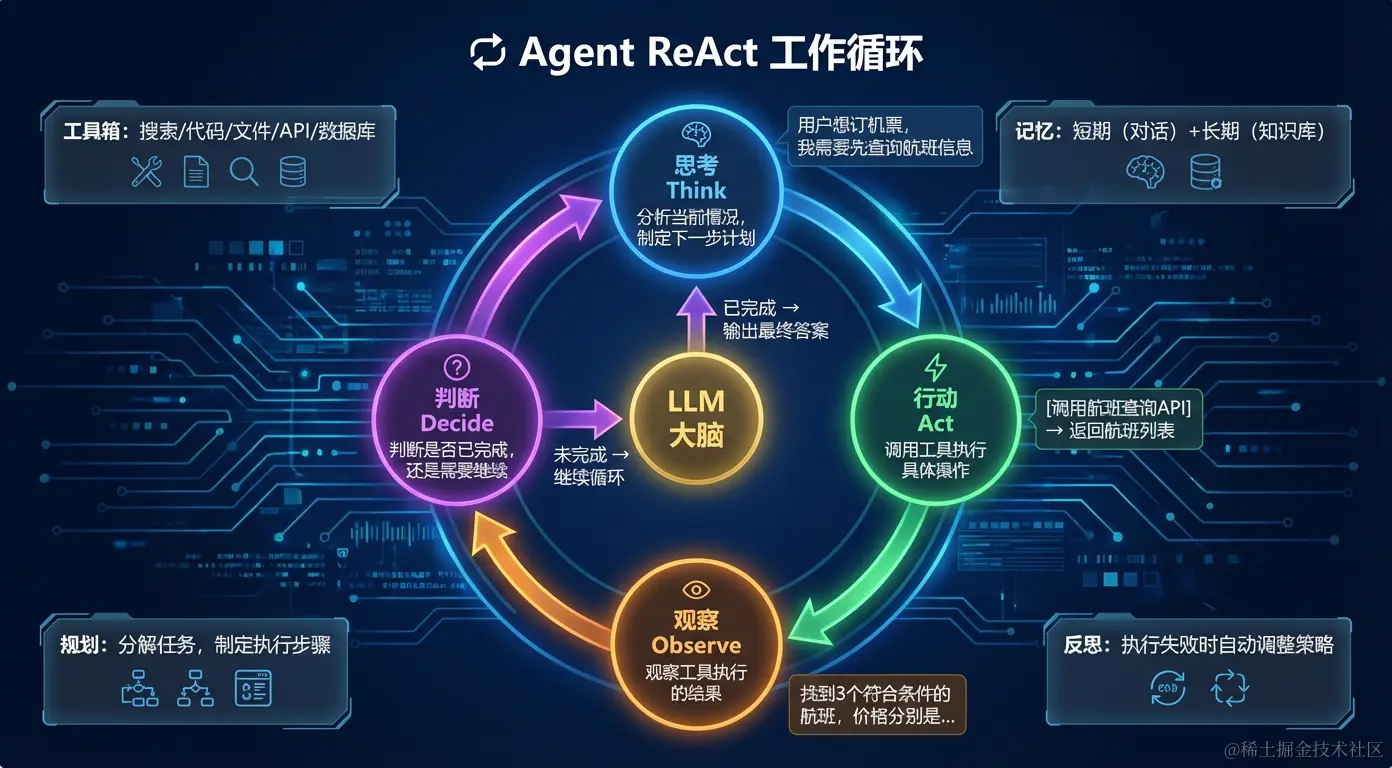
Agent 的核心工作模式叫 ReAct(Reasoning + Acting):
完整的 ReAct 循环示例
用户任务:「帮我整理一份本周的测试缺陷报告,包括缺陷数量、严重程度分布和主要问题总结」
ini
循环 1:
思考:我需要从缺陷管理系统获取本周的数据
行动:[调用 TAPD API] 查询本周新增缺陷
观察:返回 47 条缺陷,包含详细字段
判断:数据获取完成,继续分析
循环 2:
思考:需要统计各严重程度的分布
行动:[执行数据分析代码] 统计 P0/P1/P2/P3 数量
观察:P0: 3个, P1: 12个, P2: 22个, P3: 10个
判断:统计完成,继续分析主要问题
循环 3:
思考:需要总结主要问题类型
行动:[调用 LLM] 对47条缺陷标题进行聚类分析
观察:主要分为:网络相关(15)、UI问题(12)、数据一致性(8)、其他(12)
判断:分析完成,可以生成报告
循环 4:
思考:生成最终报告
行动:[生成 Markdown 报告]
观察:报告已生成
判断:任务完成,输出最终结果
最终输出:完整的测试缺陷周报ReAct 的关键特性
特性一:自主规划 Agent 不需要用户告诉它每一步怎么做,它会自己分解任务、制定计划。
特性二:自我纠错
css
循环 N:
行动:[调用 API] 查询数据
观察:API 返回 401 错误(认证失败)
思考:认证失败,可能是 Token 过期,尝试刷新 Token
行动:[刷新 Token] → [重新调用 API]
观察:成功获取数据特性三:动态调整 根据中间步骤的结果,动态调整后续计划,而不是死板地执行预设流程。
四、Agent 的工具箱
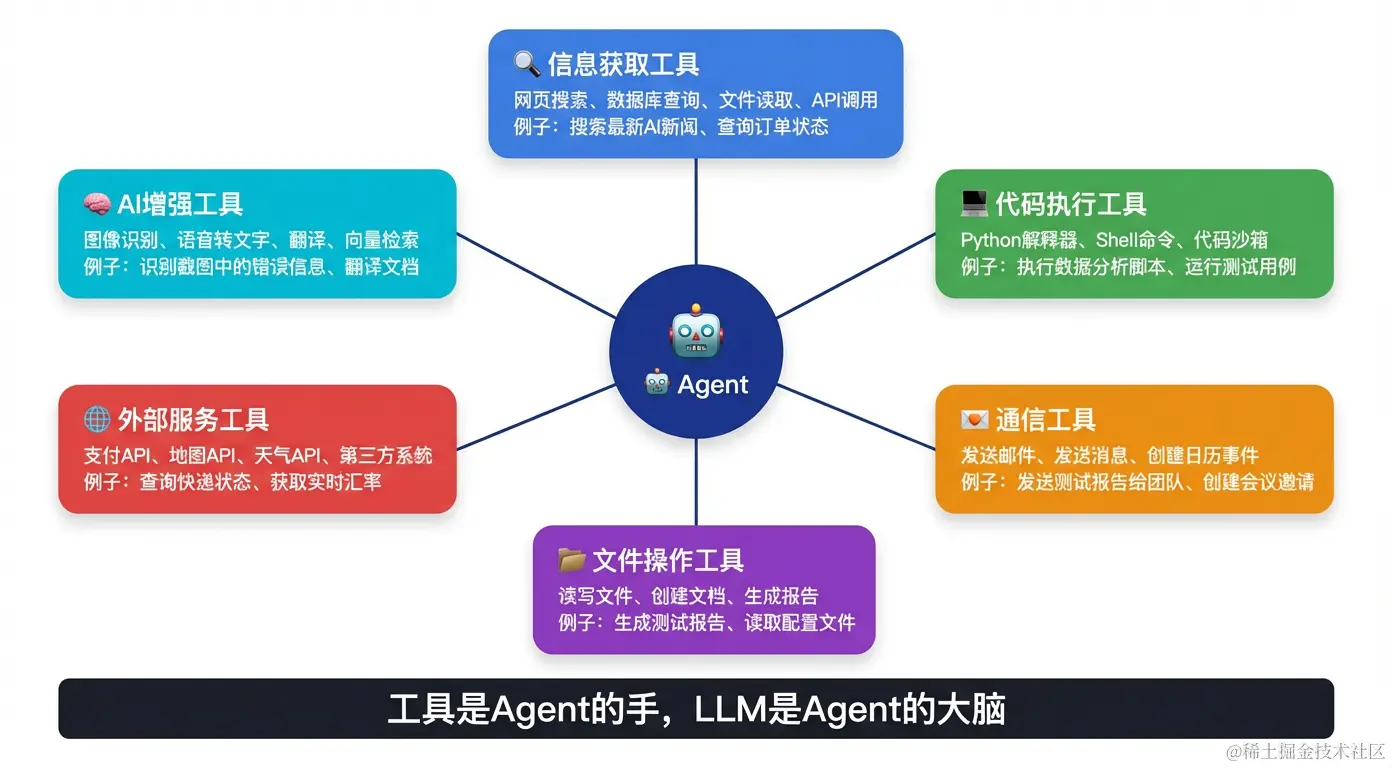
工具类型详解
信息获取工具:
python
# 网页搜索
result = search_web("刷掌支付最新技术进展")
# 数据库查询
data = query_db("SELECT * FROM alarms WHERE date > '2024-01-01'")
# 文件读取
content = read_file("/path/to/test_report.pdf")
# API 调用
response = call_api("GET", "https://api.example.com/devices")代码执行工具:
python
# Python 沙箱执行
code = """
import pandas as pd
df = pd.read_csv('data.csv')
result = df.groupby('type').count()
print(result)
"""
output = execute_python(code)
# 安全沙箱,防止恶意代码执行通信工具:
python
# 发送邮件
send_email(
to="team@company.com",
subject="本周测试报告",
body=report_content,
attachments=["report.pdf"]
)
# 发送企业微信消息
send_wechat_message(group="测试团队", content="告警处理完成")文件操作工具:
python
# 创建报告
create_document("test_report.md", content)
# 读取配置
config = read_config("/etc/app/config.yaml")
# 保存结果
save_result("analysis_result.json", data)五、Agent 的记忆系统
Agent 有四种记忆机制:
短期记忆:对话上下文
diff
当前对话中的所有消息,包括:
- 用户的指令
- AI 的思考过程
- 工具调用的输入和输出
- 中间结果
限制:受上下文窗口大小限制(通常 8K-200K Token)工作记忆:临时存储
python
# Agent 在执行任务时的临时存储
workspace = {
"task": "生成测试报告",
"step": 3,
"collected_data": {...},
"intermediate_results": [...]
}长期记忆:知识库
diff
通过 RAG 技术,Agent 可以访问:
- 历史对话记录
- 用户偏好和习惯
- 过去完成的任务结果
- 企业知识库外部存储:数据库/文件
python
# 将重要信息持久化存储
db.save("user_preferences", {"language": "zh", "format": "markdown"})
db.save("task_history", {"task_id": "xxx", "result": "..."})六、Multi-Agent:多智能体协作
复杂任务往往需要多个 Agent 协作完成:
markdown
用户任务:「完整分析本月的产品质量,生成分析报告并发送给管理层」
主 Agent(协调者):
├── 数据收集 Agent:从各系统收集数据
│ ├── 调用 TAPD API 获取缺陷数据
│ ├── 调用监控系统获取性能数据
│ └── 调用用户反馈系统获取投诉数据
│
├── 分析 Agent:对收集的数据进行深度分析
│ ├── 趋势分析
│ ├── 根因分析
│ └── 风险评估
│
├── 报告生成 Agent:将分析结果组织成报告
│ ├── 生成图表
│ ├── 撰写文字说明
│ └── 格式化输出
│
└── 分发 Agent:将报告发送给相关人员
├── 发送邮件
└── 推送到企业微信Multi-Agent 的优势:
- 任务并行执行,大幅提升效率
- 每个 Agent 专注于特定领域,专业度更高
- 一个 Agent 失败,不影响整体流程
七、Agent 在测试工作中的实际应用
应用一:自动化测试报告生成
python
# Agent 工作流
1. 从 TAPD 获取本周缺陷数据
2. 从监控系统获取性能指标
3. 从测试平台获取用例执行结果
4. 用 Python 进行数据分析和可视化
5. 生成 Markdown 格式的测试报告
6. 发送到企业微信群
# 原来:需要 2 小时人工整理
# Agent:5 分钟自动完成应用二:智能告警处理
python
# 告警触发 → Agent 自动处理
1. 接收告警信息
2. 查询知识库:是否有类似历史告警?
3. 查询监控系统:当前设备状态如何?
4. 分析根因:最可能的原因是什么?
5. 执行初步处理:重启服务/清理缓存等
6. 如果无法自动处理,生成详细报告并通知人工
# 原来:人工处理每个告警,平均 30 分钟
# Agent:80% 的告警自动处理,人工只需处理复杂情况应用三:测试用例自动维护
python
# 代码变更 → Agent 自动更新测试用例
1. 监听代码仓库的 PR 变更
2. 分析变更的代码范围
3. 从知识库找到相关测试用例
4. 评估哪些用例需要更新
5. 生成更新建议,提交给测试工程师审核
# 减少因代码变更导致的测试用例过时问题八、Agent 的局限性与风险
局限一:任务失控风险
Agent 在自主执行时,可能做出超出预期的操作:
css
用户:「帮我清理一下测试服务器上的临时文件」
Agent:[删除了所有 .tmp 文件] → 意外删除了某个重要的临时缓存文件
教训:对有破坏性的操作(删除、修改生产数据),
必须要求 Agent 先展示计划,人工确认后再执行局限二:工具调用失败的级联效应
步骤1:获取数据 ✅
步骤2:分析数据 ✅
步骤3:调用邮件API ❌(超时)
→ 前面所有工作白费,需要重试机制局限三:成本控制
Agent 每次执行可能调用大量 LLM 和工具,成本可能超出预期。需要设置:
- 最大循环次数限制
- 工具调用次数限制
- 成本预算上限
九、一句话总结
Agent = LLM(大脑)+ 工具(手和眼)+ 记忆(经验)+ ReAct 循环(行动逻辑)。它让 AI 从"回答问题"进化为"完成任务",是 AI 工程化落地的最重要范式。
延伸阅读
- 论文 :ReAct: Synergizing Reasoning and Acting in Language Models
- 框架 :LangGraph --- 最成熟的 Agent 框架
- 实践 :AutoGen --- 微软的 Multi-Agent 框架
下一期预告:第08期 · MCP 协议 --- Agent 需要工具,工具需要标准接口。MCP(Model Context Protocol)是 Anthropic 提出的 AI 工具集成统一标准,正在成为行业规范。